Real-Time Hand Gesture Spotting and Recognition Using RGB-D Camera and 3D Convolutional Neural Network





Abstract
1. Introduction
2. Related Works
2.1. Sensors Used for Hand Gesture Recognition Interface
2.2. Hand Gesture Recognition Using RGB-D Sensor
2.3. 3D Convolutional Neural Networks
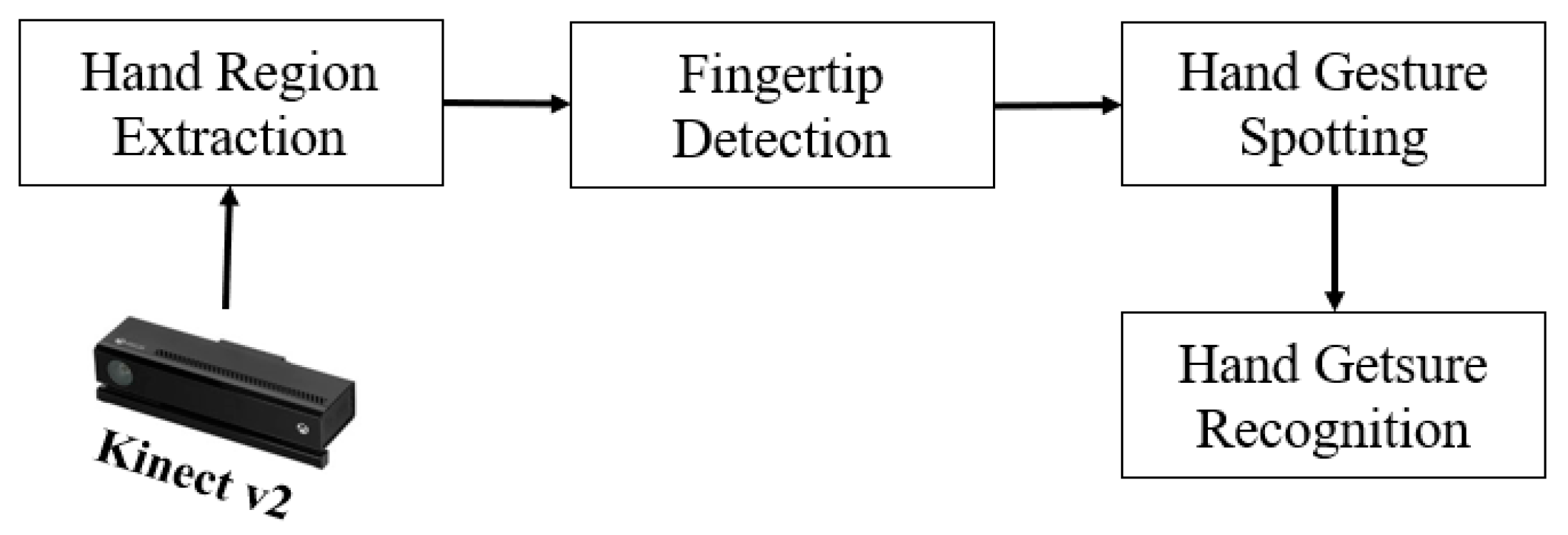
3. Proposed Method
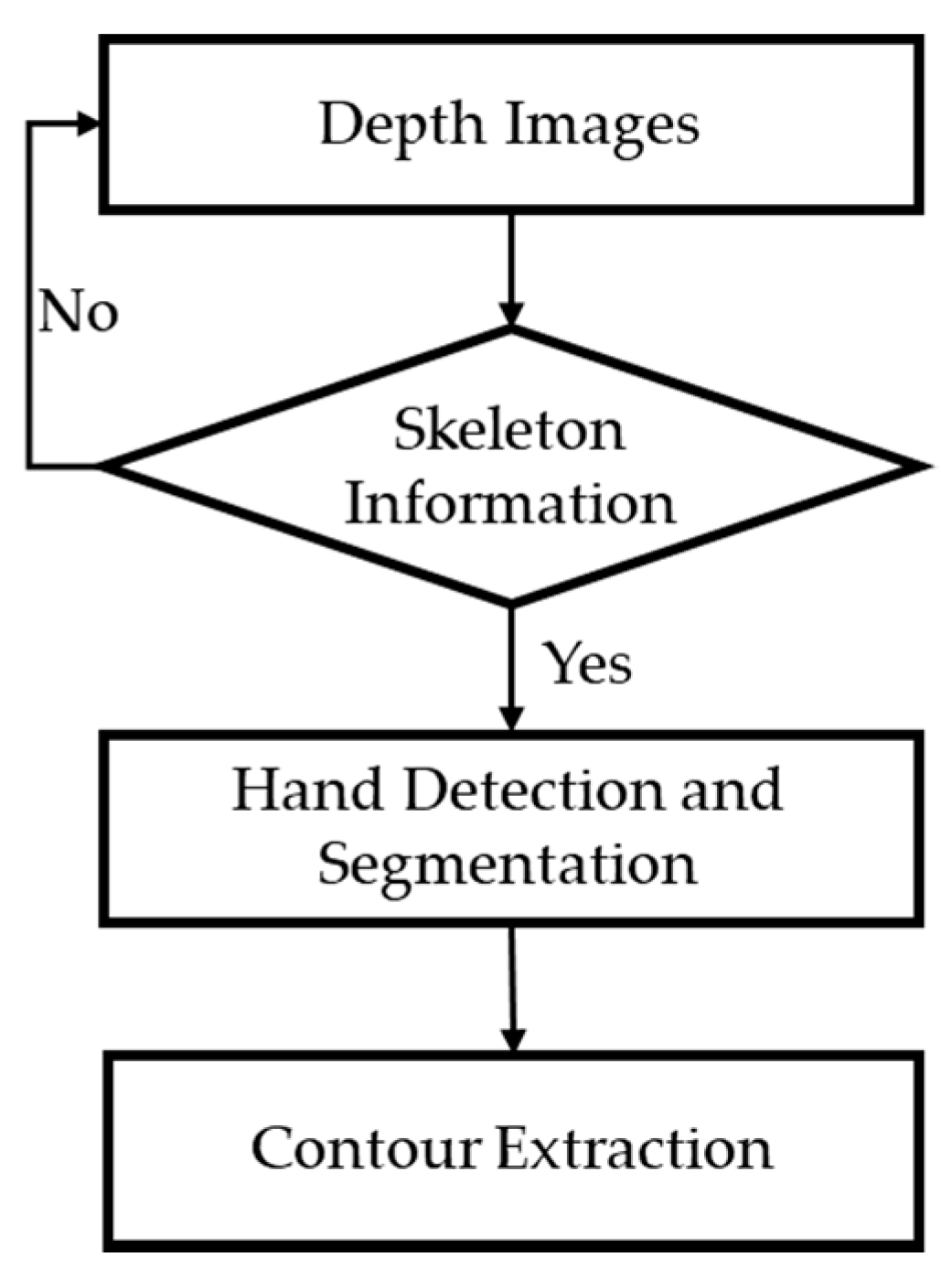
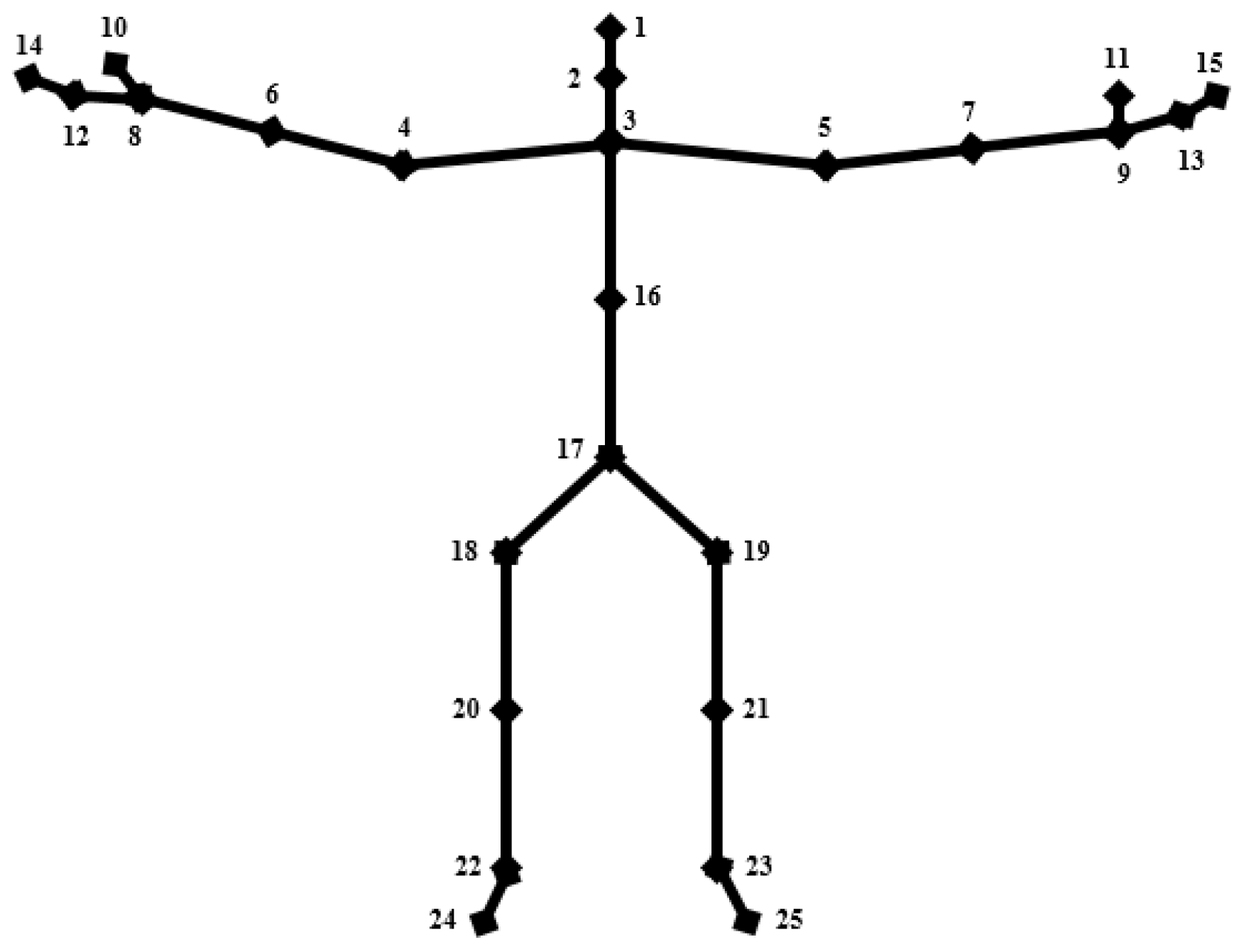
3.1. Hand Region Extraction
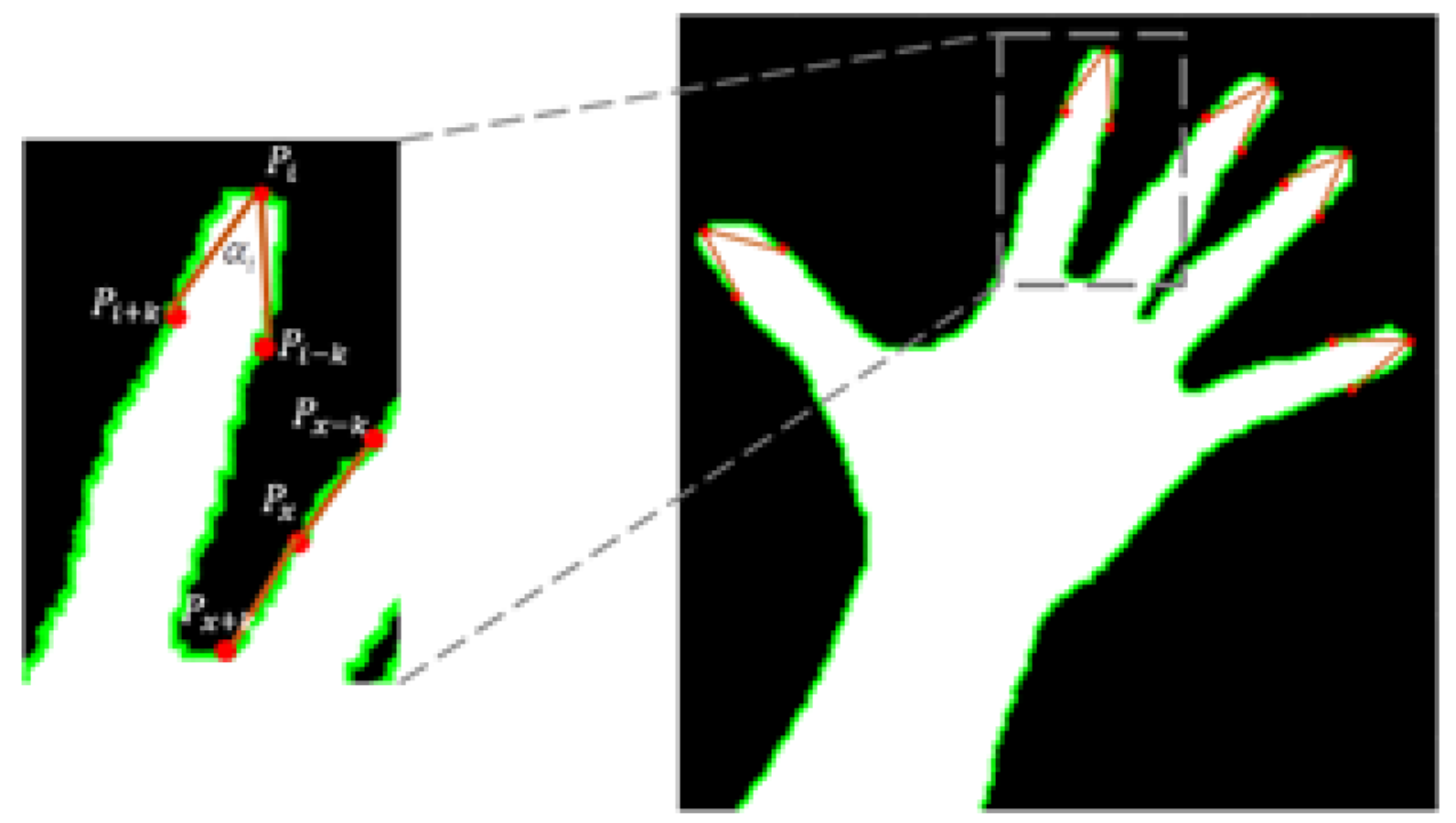
3.2. Fingertip Detection
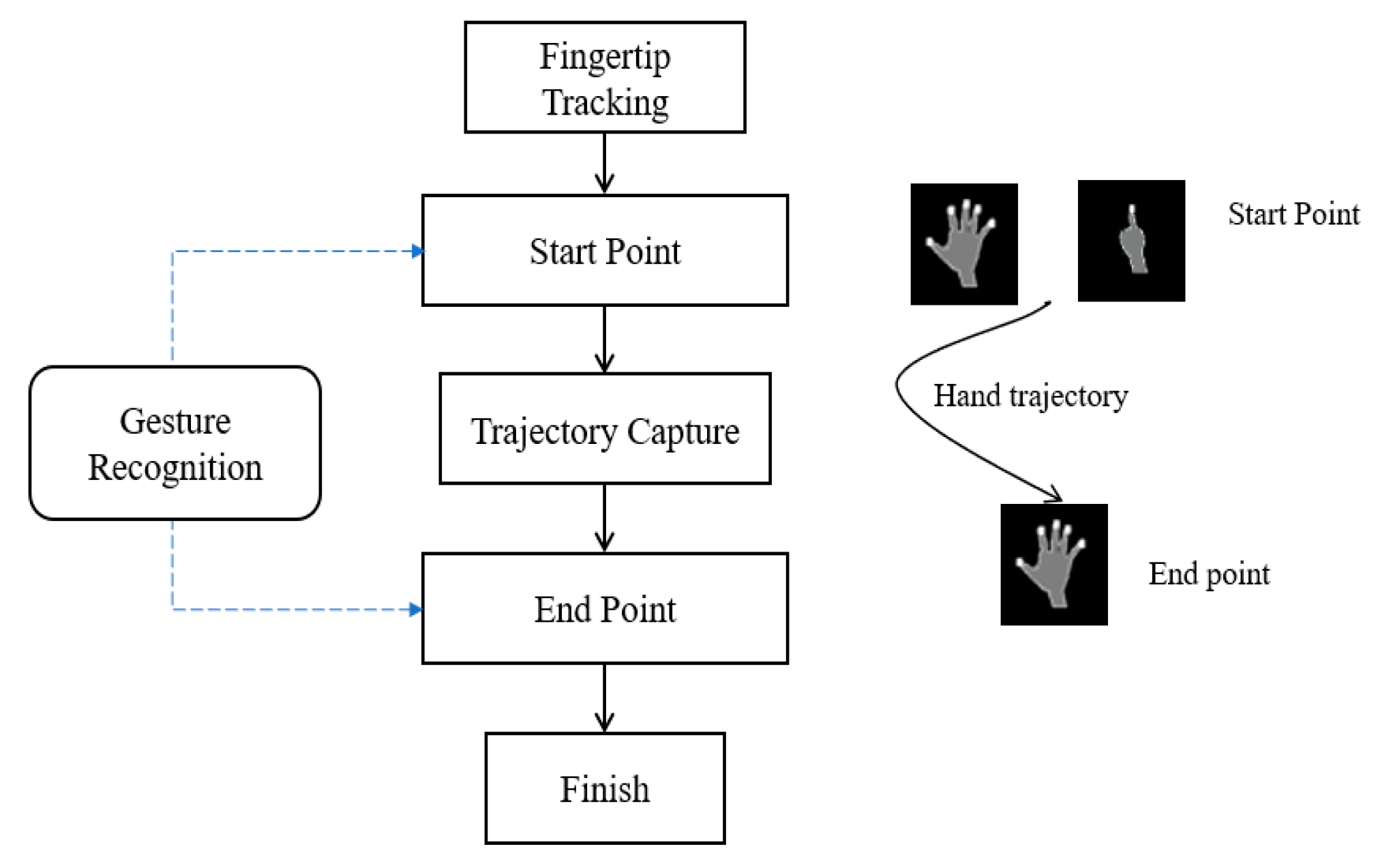
3.3. Hand Gesture Spotting
3.3.1. Target Person Locking
| Algorithm 1 Target Person Locking |
| begin |
| Require User ID, head joint coordinates (x1, y1), right hand joint coordinates (x13, y13). |
| 1: Calculation the distance between y1 and y13. |
| 2: If y13 > y1 during 10 frames |
| then process target user |
| else redo 1 |
| end begin |
3.3.2. Hand Gesture Spotting
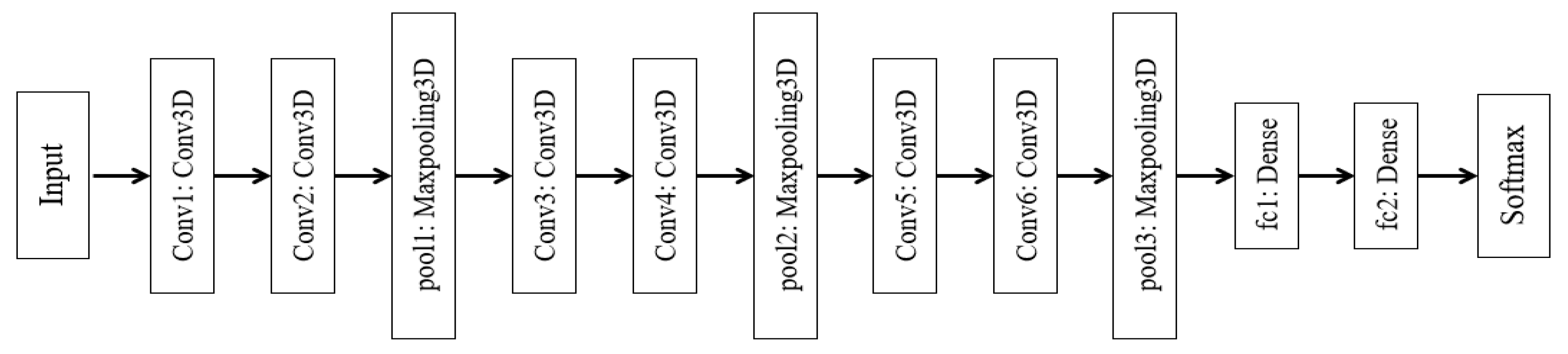
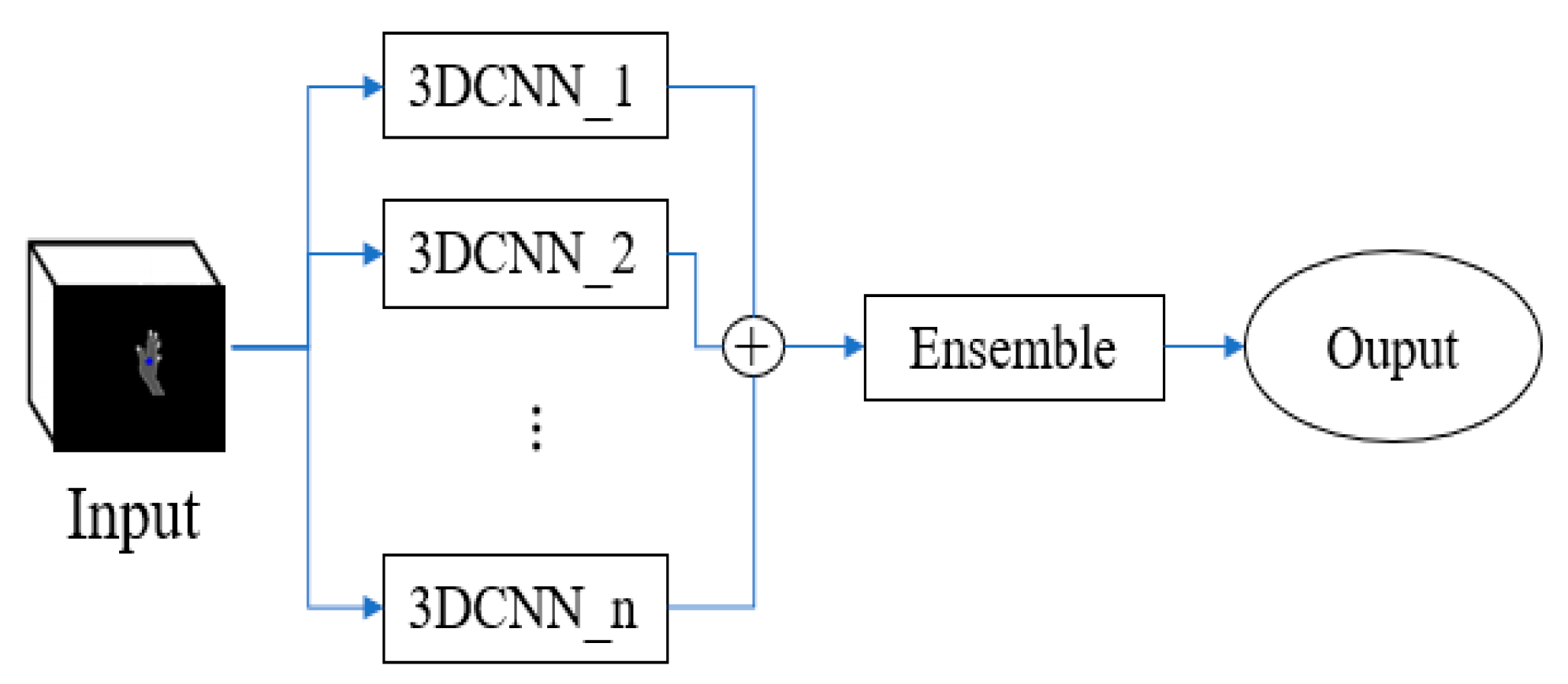
3.4. Hand Gesture Recognition
4. Experiments
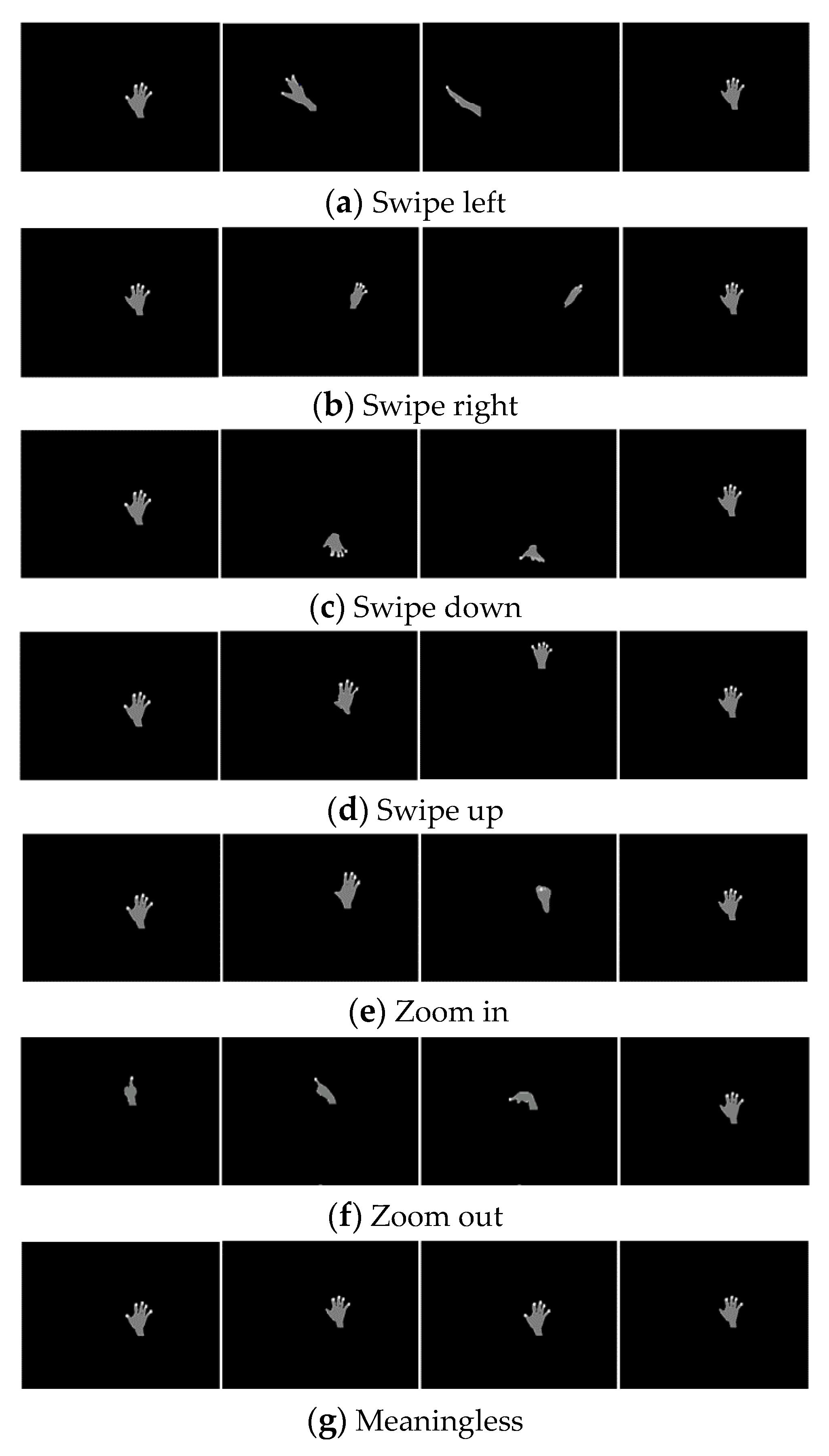
4.1. Dataset
4.2. Implementation Details
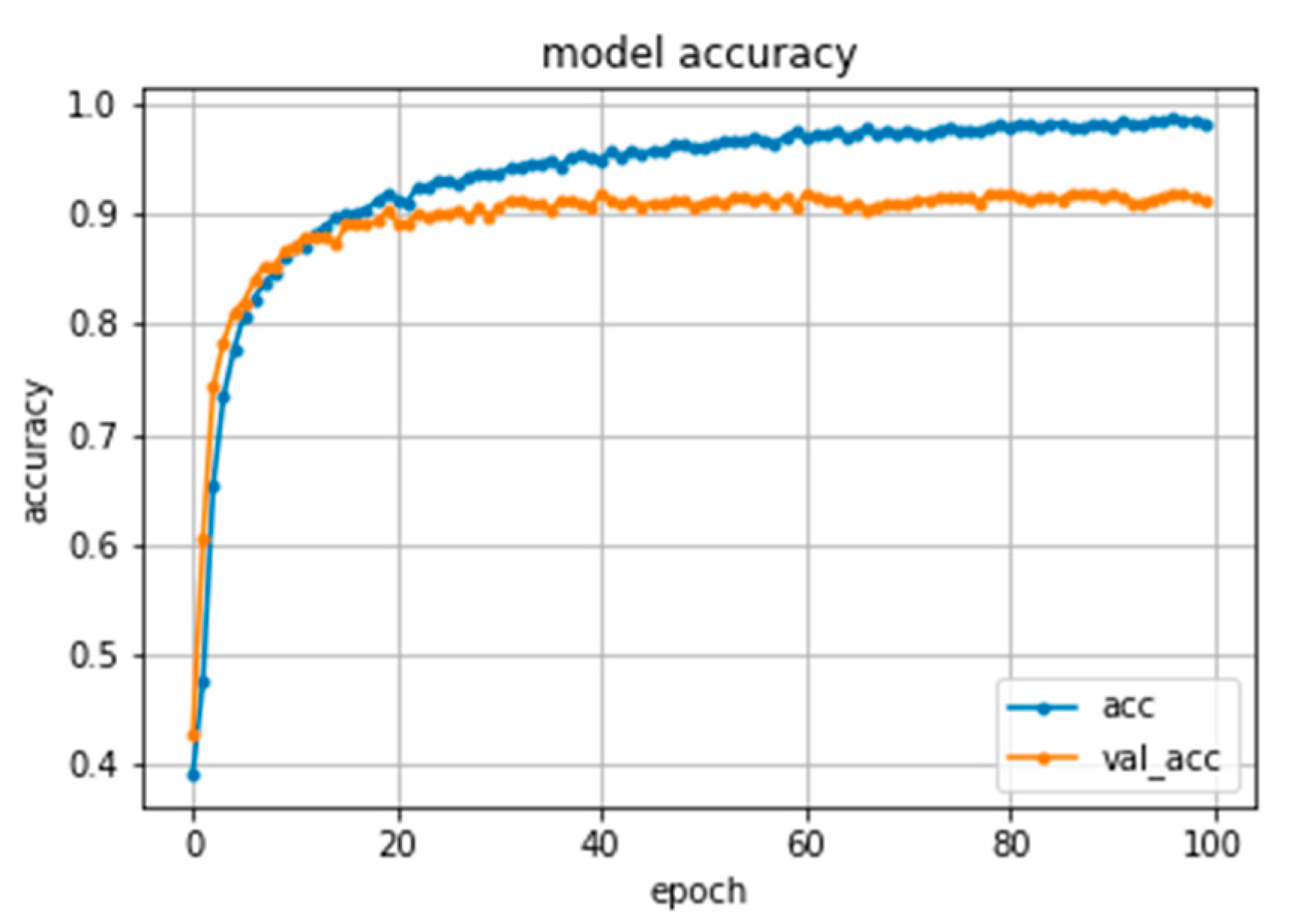
4.3. Evaluation
4.4. Results
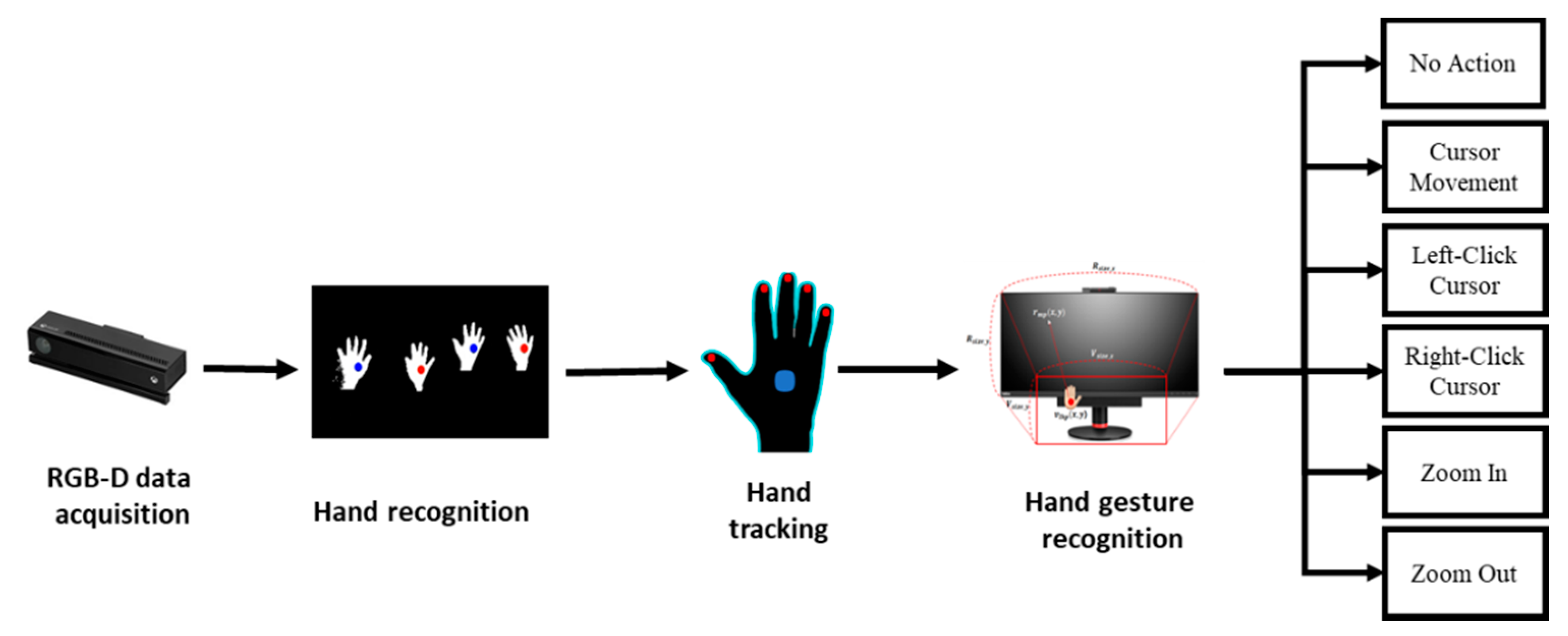
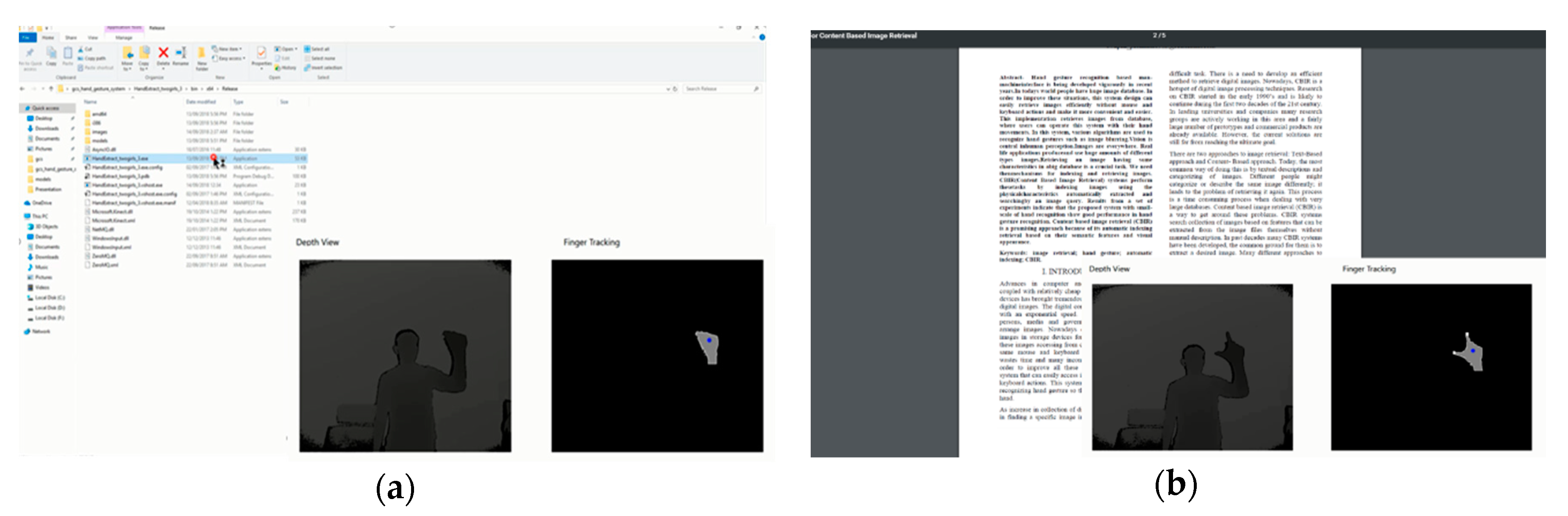
4.5. Application of the Proposed System
5. Discussions
Author Contributions
Funding
Conflicts of Interest
References
- Starner, T.; Pentland, A. Real-time american sign language recognition from video using hidden markov models. In Motion-Based Recognition; Springer: Berlin/Heidelberg, Germany, 1997; pp. 227–243. [Google Scholar]
- Malima, A.K.; Özgür, E.; Çetin, M. A Fast Algorithm for Vision-Based Hand Gesture Recognition for Robot Control. In Proceedings of the 2006 IEEE 14th Signal Processing and Communications Applications, Antalya, Turkey, 17–19 April 2006. [Google Scholar]
- Tsai, T.-H.; Huang, C.-C.; Zhang, K.-L. Embedded Virtual Mouse System by Using Hand Gesture Recognition. In Proceedings of the 2015 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW), Taipei, Taiwan, 6–8 June 2015; pp. 352–353. [Google Scholar]
- Kadam, S.; Sharma, N.; Shetty, T.; Divekar, R. Mouse Operations using Finger Tracking. Int. J. Comput. Appl. 2015, 116, 20. [Google Scholar] [CrossRef]
- Jeon, C.; Kwon, O.-J.; Shin, D.; Shin, D. Hand-Mouse Interface Using Virtual Monitor Concept for Natural Interaction. IEEE Access 2017, 5, 25181–25188. [Google Scholar] [CrossRef]
- Abhilash, S.S.; Lisho Thomas, N.W.C.C. Virtual Mouse Using Hand Gesture. Int. Res. J. Eng. Technol. 2018, 5, 4, eISSN 2395-0056, pISSN 2395-0072. [Google Scholar]
- Le, P.D.; Nguyen, V.H. Remote mouse control using fingertip tracking technique. In AETA 2013: Recent Advances in Electrical Engineering and Related Sciences; Springer: Berlin/Heidelberg, Germany, 2014; pp. 467–476. [Google Scholar]
- Reza, M.N.; Hossain, M.S.; Ahmad, M. Real Time Mouse Cursor Control Based on Bare Finger Movement Using Webcam to Improve HCI. In Proceedings of the 2015 International Conference on Electrical Engineering and Information Communication Technology (ICEEICT), Dhaka, Bangladesh, 21–23 May 2015; pp. 1–5. [Google Scholar]
- Gallo, L.; Placitelli, A.P.; Ciampi, M. Controller-Free Exploration of Medical Image Data: Experiencing the Kinect. In Proceedings of the 2011 24th International Symposium on Computer-Based Medical Systems (CBMS), Bristol, UK, 27–30 June 2011; pp. 1–6. [Google Scholar]
- Dong, G.; Yan, Y.; Xie, M. Vision-Based Hand Gesture Recognition for Human-Vehicle Interaction. In Proceedings of the International Conference on Control, Automation and Computer Vision, Singapore, 18–21 November 2018. [Google Scholar]
- Zhang, X.; Chen, X.; Wang, W.; Yang, J.; Lantz, V.; Wang, K. Hand Gesture Recognition and Virtual Game Control Based on 3D Accelerometer and EMG Sensors. In Proceedings of the 14th International Conference on Intelligent User Interfaces, Sanibel Island, FL, USA, 25 September 2009; pp. 401–406. [Google Scholar]
- Deng, L. A tutorial survey of architectures, algorithms, and applications for deep learning. APSIPA Trans. Signal Inf. Process. 2014, 3. [Google Scholar] [CrossRef]
- Wang, Y.; Neff, M. Data-driven Glove Calibration for Hand Motion Capture. In Proceedings of the 12th ACM SIGGRAPH/Eurographics Symposium on Computer Animation, Anaheim, CA, USA, 26–27 July 2013; pp. 15–24. [Google Scholar]
- Parab, P.; Kinalekar, S.; Chavan, R.; Sharan, D.; Deshpande, S. Hand Gesture Recognition using Microcontroller Flex Sensor. Int. J. Sci. Res. Educ. 2014, 2, 3. [Google Scholar]
- Parvini, F.; McLeod, D.; Shahabi, C.; Navai, B.; Zali, B.; Ghandeharizadeh, S. An Approach to Glove-Based Gesture Recognition. In Proceedings of the International Conference on Human-Computer Interaction, San Diego, CA, USA, 19–24 July 2009; pp. 236–245. [Google Scholar]
- Allevard, T.; Benoit, E.; Foulloy, L. Fuzzy Glove for Gesture Recognition. In Proceedings of the XVII IMEKO World Congress, Dubrovnik, Croatia, 22–28 June 2003; pp. 2026–2031. [Google Scholar]
- Ghunawat, M.R. Multi-Point Gesture Recognition Using LED Gloves for Interactive HCI. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 6768–6773. [Google Scholar]
- Ganzeboom, M. How Hand Gestures Are Recognized Using a Dataglove. 2009. Available online: https://pdfs.semanticscholar.org/bd6b/40dca3813367272c917e6d28a45a2f053004.pdf?_ga=2.35948259.294260165.1579427347-803309327.1579427347 (accessed on 12 December 2018).
- Vardhan, D.V.; Prasad, P.P. Hand gesture recognition application for physically disabled people. Int. J. Sci. Res. 2014, 3, 765–769. [Google Scholar]
- Rautaray, S.S.; Agrawal, A. Real time hand gesture recognition system for dynamic applications. Int. J. UbiComp 2012, 3, 21. [Google Scholar] [CrossRef]
- Murugeswari, M.; Veluchamy, S. Hand Gesture Recognition System for Real-Time Application. In Proceedings of the 2014 International Conference on Advanced Communication Control and Computing Technologies (ICACCCT), Ramanathapuram, India, 8–10 May 2014; pp. 1220–1225. [Google Scholar]
- Haria, A.; Subramanian, A.; Asokkumar, N.; Poddar, S.; Nayak, J.S. Hand gesture recognition for human computer interaction. Procedia Comput. Sci. 2017, 115, 367–374. [Google Scholar] [CrossRef]
- Chen, Z.; Kim, J.-T.; Liang, J.; Zhang, J.; Yuan, Y.-B. Real-time hand gesture recognition using finger segmentation. Sci. World J. 2014, 2014. [Google Scholar] [CrossRef] [PubMed]
- Xu, P. A Real-time Hand Gesture Recognition and Human-Computer Interaction System. arXiv 2017, arXiv:1704.07296. [Google Scholar]
- Neto, P.; Pereira, D.; Pires, J.N.; Moreira, A.P. Real-Time and Continuous Hand Gesture Spotting: An Approach Based on Artificial Neural Networks. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation (ICRA), Karlsruhe, Germany, 6–10 May 2013; pp. 178–183. [Google Scholar]
- Banerjee, A.; Ghosh, A.; Bharadwaj, K.; Saikia, H. Mouse control using a web camera based on colour detection. arXiv 2014, arXiv:1403.4722. [Google Scholar]
- Ge, L.; Ren, Z.; Li, Y.; Xue, Z.; Wang, Y.; Cai, J.; Yuan, J. 3D Hand Shape and Pose Estimation from a Single RGB Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10833–10842. [Google Scholar]
- Li, Y.; Xue, Z.; Wang, Y.; Ge, L.; Ren, Z.; Rodriguez, J. End-to-End 3D Hand Pose Estimation from Stereo Cameras. Available online: https://bmvc2019.org/wp-content/uploads/papers/0219-paper.pdf (accessed on 25 December 2019).
- Fossati, A.; Gall, J.; Grabner, H.; Ren, X.; Konolige, K. Consumer Depth Cameras for Computer Vision: Research Topics and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Sharp, T.; Keskin, C.; Robertson, D.; Taylor, J.; Shotton, J.; Kim, D.; Rhemann, C.; Leichter, I.; Vinnikov, A.; Wei, Y.; et al. Accurate, Robust, and Flexible Real-Time Hand Tracking. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; pp. 3633–3642. [Google Scholar]
- Khamis, S.; Taylor, J.; Shotton, J.; Keskin, C.; Izadi, S.; Fitzgibbon, A. Learning an Efficient Model of Hand Shape Variation from Depth Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2540–2548. [Google Scholar]
- Oikonomidis, I.; Kyriazis, N.; Argyros, A.A. Efficient Model-Based 3D Tracking of Hand Articulations Using Kinect. In Proceedings of the BmVC, Dundee, UK, 29 August–2 September 2011; Volume 1, p. 3. [Google Scholar]
- Sun, T.-H. K-Cosine Corner Detection. JCP 2008, 3, 16–22. [Google Scholar] [CrossRef]
- Bakar, M.Z.A.; Samad, R.; Pebrianti, D.; Mustafa, M.; Abdullah, N.R.H. Finger Application Using K-Curvature Method and Kinect Sensor in Real-Time. In Proceedings of the 2015 International Symposium on Technology Management and Emerging Technologies (ISTMET), Langkawai Island, Malaysia, 25–27 August 2015; pp. 218–222. [Google Scholar]
- Nguyen, H.D.; Kim, Y.C.; Kim, S.H.; Na, I.S. A Method for Fingertips Detection Using RGB-D Image and Convolution Neural Network. In Proceedings of the 2017 13th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Guilin, China, 29–31 July 2017; pp. 783–785. [Google Scholar]
- Sanchez-Riera, J.; Srinivasan, K.; Hua, K.-L.; Cheng, W.-H.; Hossain, M.A.; Alhamid, M.F. Robust rgb-d hand tracking using deep learning priors. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 2289–2301. [Google Scholar] [CrossRef]
- Molchanov, P.; Gupta, S.; Kim, K.; Kautz, J. Hand Gesture Recognition with 3D Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 1–7. [Google Scholar]
- Hoang, N.N.; Lee, G.-S.; Kim, S.-H.; Yang, H.-J. A Real-Time Multimodal Hand Gesture Recognition via 3D Convolutional Neural Network and Key Frame Extraction. In Proceedings of the 2018 International Conference on Machine Learning and Machine Intelligence, Hanoi, Vietnam, 28–30 September 2018; pp. 32–37. [Google Scholar]
- The 20BN-JESTER Dataset. Available online: https://20bn.com/datasets/jester/v1 (accessed on 10 December 2018).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Baccouche, M.; Mamalet, F.; Wolf, C.; Garcia, C.; Baskurt, A. Sequential Deep Learning for Human Action Recognition. In Proceedings of the International Workshop on Human Behavior Understanding, Amsterdam, The Netherlands, 16 November 2011; pp. 29–39. [Google Scholar]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing Human Actions: A Local SVM Approach. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 26 August 2004; Volume 3, pp. 32–36. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Shou, Z.; Wang, D.; Chang, S.-F. Temporal Action Localization in Untrimmed Videos via Multi-Stage Cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1049–1058. [Google Scholar]
- Molchanov, P.; Yang, X.; Gupta, S.; Kim, K.; Tyree, S.; Kautz, J. Online Detection and Classification of Dynamic Hand Gestures with Recurrent 3D Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4207–4215. [Google Scholar]
- Pan, Y.; Mei, T.; Yao, T.; Li, H.; Rui, Y. Jointly Modeling Embedding and Translation to Bridge Video and Language. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4594–4602. [Google Scholar]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In Proceedings of the International Workshop on Multiple Classifier Systems, Cagliari, Italy, 21–23 June 2000; pp. 1–15. [Google Scholar]
- Gonzalez, R.W.R. Digital Image Processing, 3rd ed.; Prentice Hall: Upeer Saddle River, NJ, USA, 2008. [Google Scholar]
- Pradhan, R.; Kumar, S.; Agarwal, R.; Pradhan, M.P.; Ghose, M.K. Contour line tracing algorithm for digital topographic maps. Int. J. Image Process 2010, 4, 156–163. [Google Scholar]
- Cassels, J.W.S. An Introduction to Diophantine Approximation; Cambridge University Press: Cambridge, UK, 1957; Volume 1957. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Training Time | Testing Time | Accuracy (%) |
|---|---|---|---|
| SVM | 21.94 m | 2.57 s | 60.50 |
| 2DCNN | 50.00 m | 3.46 s | 64.28 |
| 3DCNN | 1h35 | 5.29 s | 92.60 |
| Models | Accuracy (%) |
|---|---|
| 3DCNN | 92.60 |
| Ensemble model with 5 different 3DCNN networks | 96.42 |
| Ensemble model with 10 different 3DCNN networks | 96.82 |
| Ensemble model with 15 different 3DCNN networks | 97.12 |
| Target | Selected | Acc | ||||||
|---|---|---|---|---|---|---|---|---|
| SL | SR | SU | SD | ZI | ZO | M | ||
| SL | 149 | 0 | 0 | 0 | 0 | 0 | 1 | 0.99 |
| SR | 1 | 148 | 0 | 0 | 0 | 0 | 1 | 0.99 |
| SU | 1 | 0 | 145 | 0 | 2 | 0 | 2 | 0.97 |
| SD | 0 | 0 | 0 | 146 | 1 | 1 | 2 | 0.97 |
| ZI | 0 | 0 | 0 | 0 | 143 | 4 | 3 | 0.95 |
| ZO | 0 | 0 | 1 | 0 | 4 | 141 | 4 | 0.94 |
| M | 1 | 0 | 0 | 0 | 0 | 1 | 148 | 0.99 |
| 0.97 | ||||||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tran, D.-S.; Ho, N.-H.; Yang, H.-J.; Baek, E.-T.; Kim, S.-H.; Lee, G. Real-Time Hand Gesture Spotting and Recognition Using RGB-D Camera and 3D Convolutional Neural Network. Appl. Sci. 2020, 10, 722. https://doi.org/10.3390/app10020722
Tran D-S, Ho N-H, Yang H-J, Baek E-T, Kim S-H, Lee G. Real-Time Hand Gesture Spotting and Recognition Using RGB-D Camera and 3D Convolutional Neural Network. Applied Sciences. 2020; 10(2):722. https://doi.org/10.3390/app10020722
Chicago/Turabian StyleTran, Dinh-Son, Ngoc-Huynh Ho, Hyung-Jeong Yang, Eu-Tteum Baek, Soo-Hyung Kim, and Gueesang Lee. 2020. "Real-Time Hand Gesture Spotting and Recognition Using RGB-D Camera and 3D Convolutional Neural Network" Applied Sciences 10, no. 2: 722. https://doi.org/10.3390/app10020722
APA StyleTran, D.-S., Ho, N.-H., Yang, H.-J., Baek, E.-T., Kim, S.-H., & Lee, G. (2020). Real-Time Hand Gesture Spotting and Recognition Using RGB-D Camera and 3D Convolutional Neural Network. Applied Sciences, 10(2), 722. https://doi.org/10.3390/app10020722