In an effort to improve the transmission efficiency of satellite communication and mobile communication systems, the systems should consider adaptive changing parameters such as a modulation scheme, a transmission rate and a carrier frequency according to a channel state [
1,
2]. As part of this study, in order to effectively classify the modulation scheme, an automatic modulation classification (AMC) method has been widely studied [
3,
4]. Generally, the receiver can estimate the modulation scheme of the transmitted signal in the commercial system. However, since the communication parameters of the enemy cannot be accurately estimated in military communications, the research has been oriented to estimate the communication parameters by using only the received signals [
5]. Thus, in order to improve the jamming performance against the enemy communication system, various research works have been undertaken to classify the modulation scheme by the AMC method [
6]. The techniques for the AMC can be roughly classified into two types. The first type maximizes the likelihood function based on the statistical model from the received signal. However, this method has poor performance due to the error that occurs when there is a change in the channel characteristics in the real environment. Moreover, considering different models, the computation of the algorithm becomes very complicated and the calculation effort becomes large [
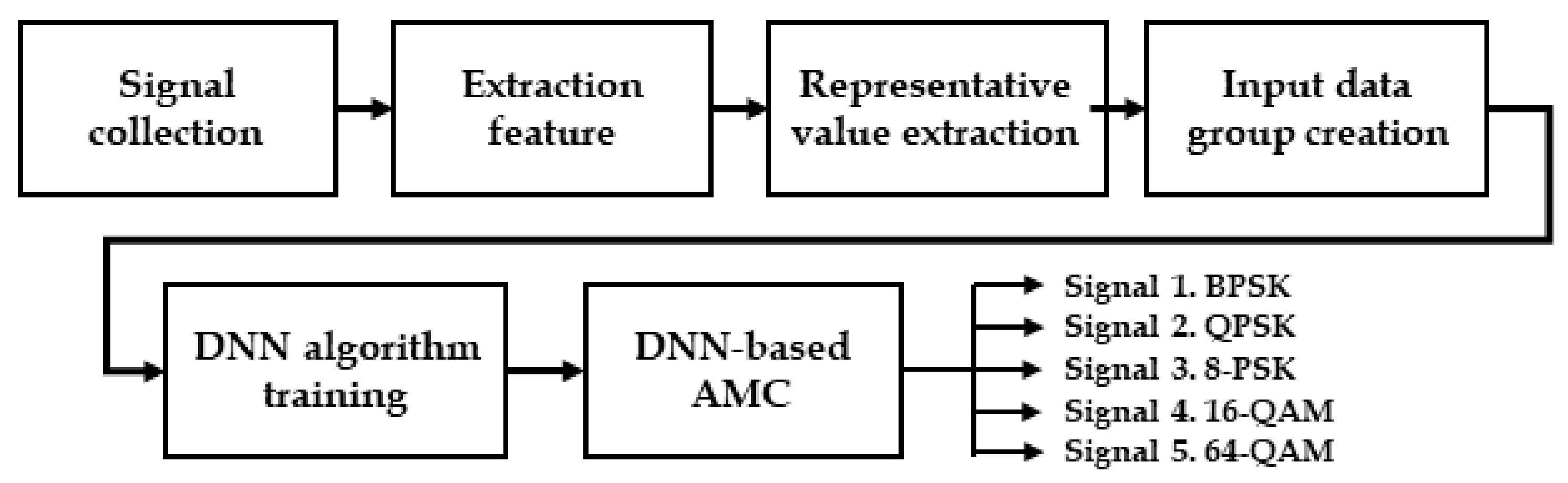
7]. The second type uses the machine-learning technique. This method uses training data to train machine learning models to classify modulation type. Assuming that the training data is similar to the actual data, it can demonstrate good performance even though the computational complexity is lower than the likelihood method. Therefore, in order to classify the modulation type quickly and accurately, the machine-learning algorithm is mainly used. The AMC scheme based on machine learning consists of a feature extraction step that extracts features from the received signal and a signal classification step that classifies the modulation type.
There are various techniques such as a deep neural network (DNN) [
8], a convolutional neural network (CNN) [
9] and a recurrent neural network (RNN) [
10] for the AMC that have been studied. The CNN algorithm is a method that shows excellent performance in image processing. The research has been carried out to classify the signals by using the constellation images of the received signals as the features and to classify the signals by imaging the statistical characteristics [
9]. The RNN algorithm is an excellent method for analyzing time-series data but requires algorithmic complexity and high calculation effort compared to performance [
10]. On the other hand, the DNN algorithm can learn complex structures from various data and shows good performance for various machine-learning problems in recent years. The features frequently used in the AMC technique based on machine learning use the higher-order statistic cumulant and signal size, frequency, phase dispersion, and wavelet coefficient [
11,
12]. Therefore, in this paper, the cumulant is used as a feature for the AMC and as input data of the DNN algorithm. Various research works have focused on machine-learning methods, rather than analyzing features used as input data. Therefore, in this paper, we use only the features that greatly affect the classification performance through the proposed algorithm to reduce the computational complexity and to identify the received signal quickly while using the basic DNN structure algorithm. In reference [
13], we have confirmed the difference of signal classification performance according to the features used as input data in the DNN algorithm and confirmed the features with high and low importance. Based on this, an effective feature selection method using a correlation coefficient is exploited to obtain the representative values and to verify the classification performance [
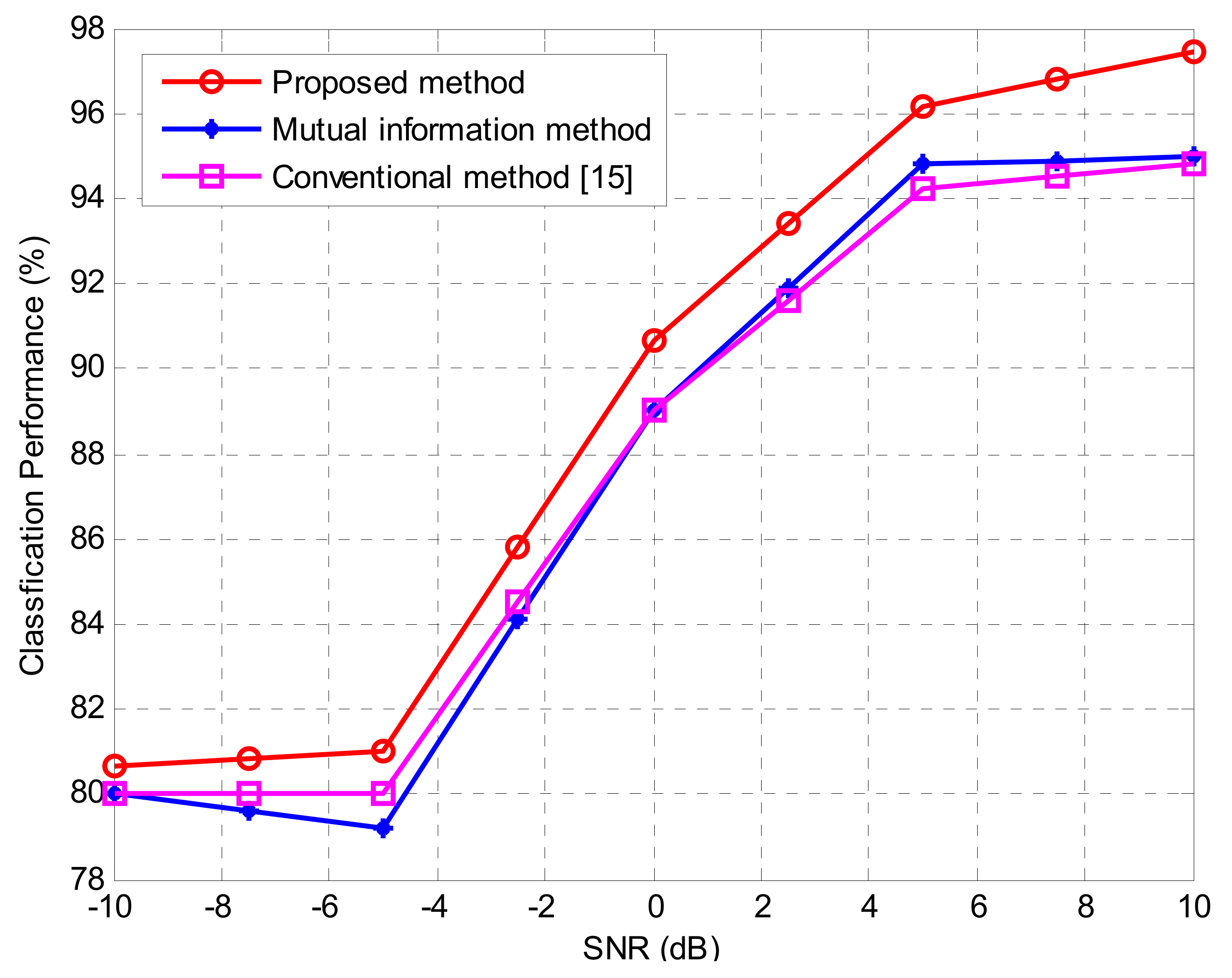
14]. The proposed method is more effective than the conventional method, which uses mutual information and correlation coefficients in selecting five features [
15,
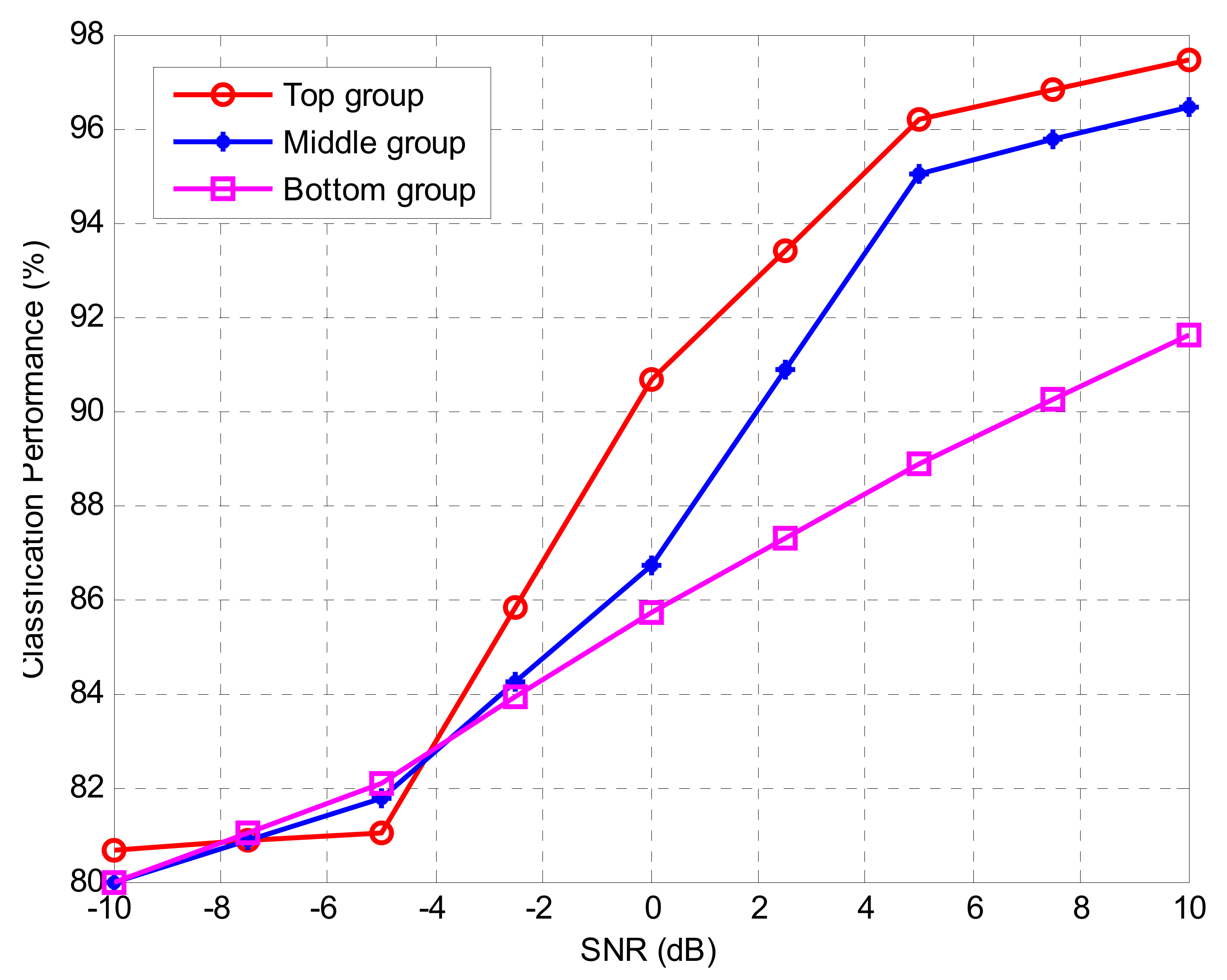
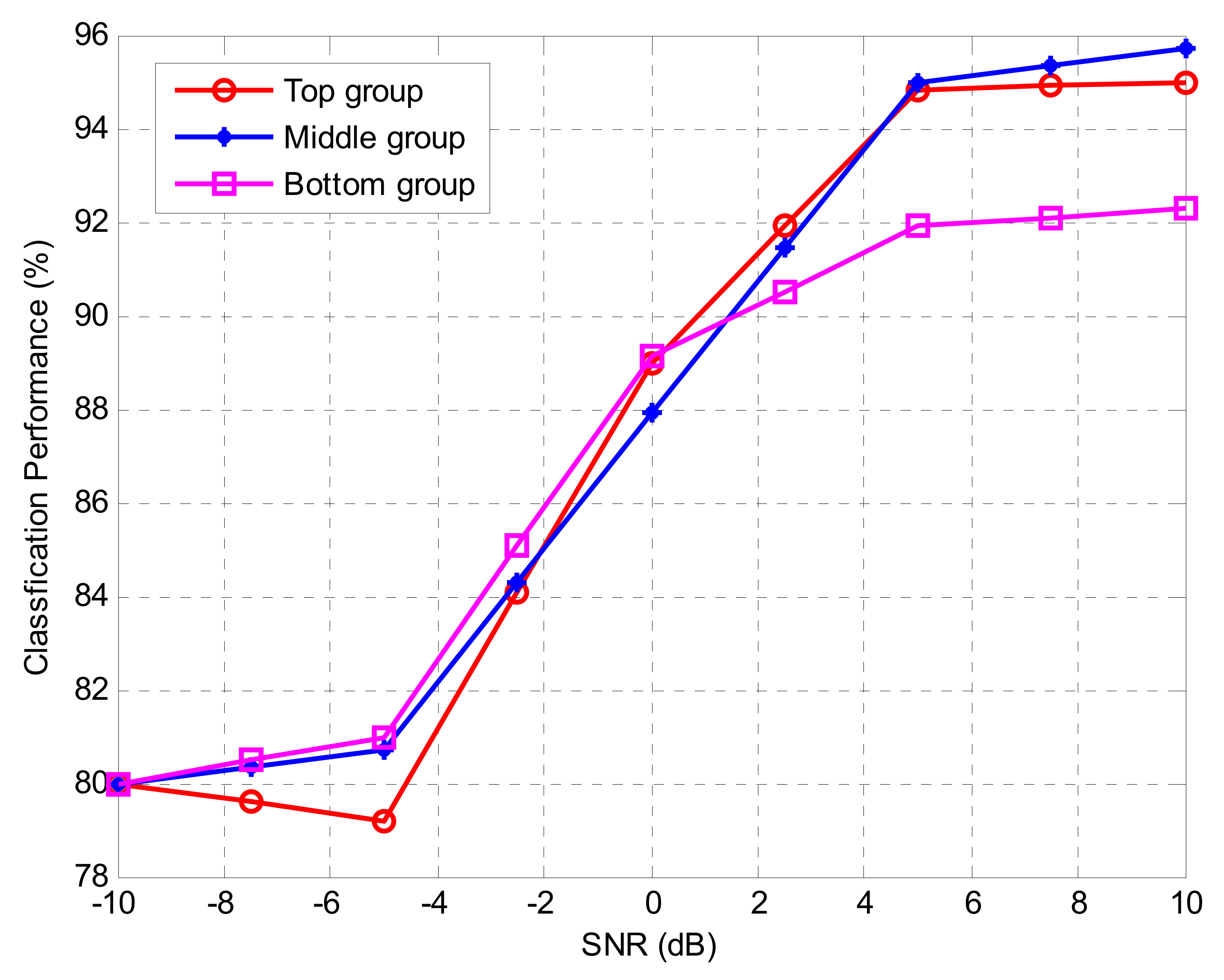
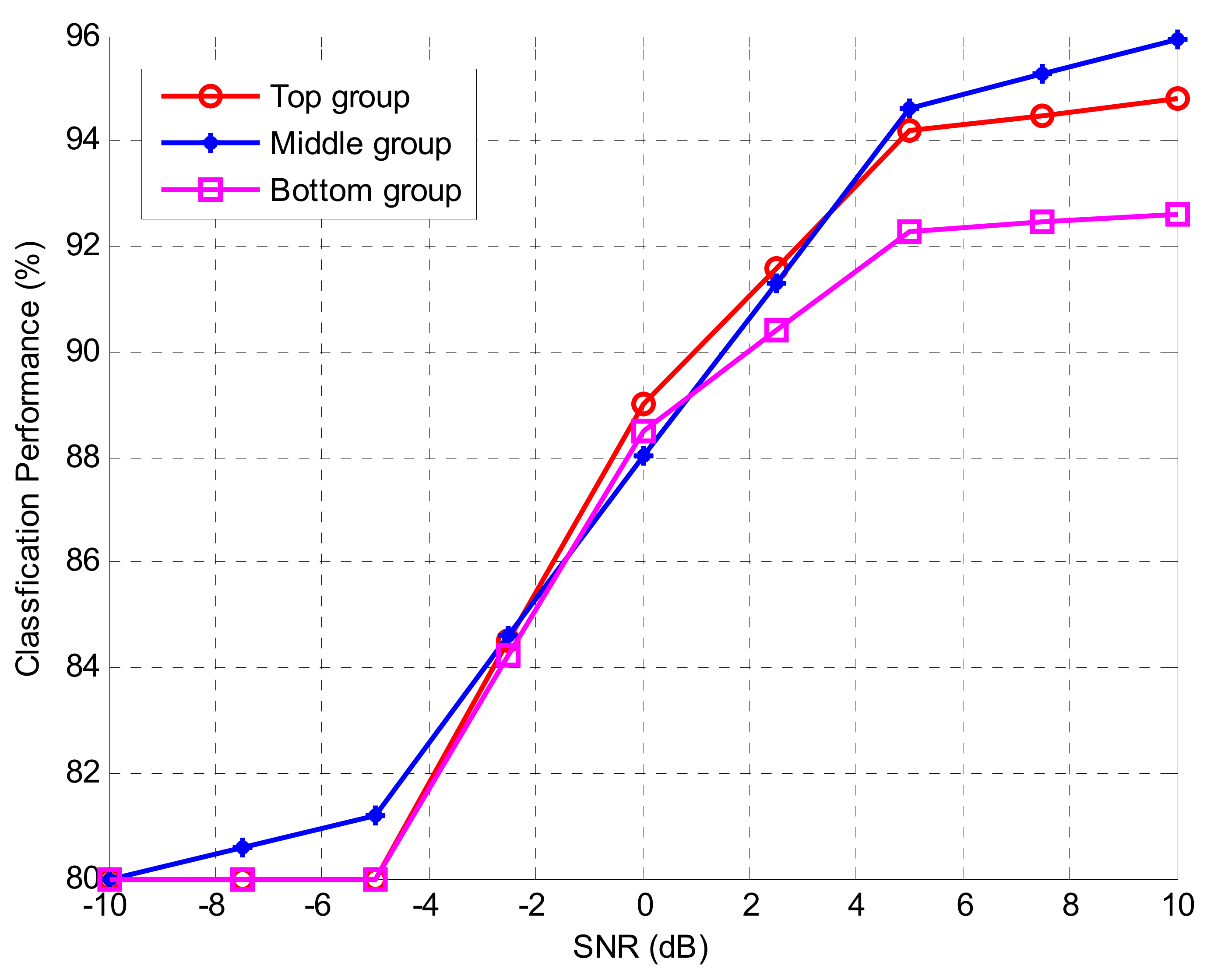
16]. In this paper, we compare the performance of the proposed method using only the correlation coefficient in various environments, the conventional method using mutual information and correlation coefficients, and three methods using only mutual information. In addition, we confirmed the performance of the proposed method with the addition of four kinds of sixth-order cumulants with large variability in the low signal-to-noise ratio (SNR) environment besides the second and fourth-order cumulant. In order to evaluate the proposed method, the representative value was selected from various cumulants by using each method and two kinds of the simulation were conducted. In the first simulation, in order to find the effective features values, we ranked the cumulants based on the calculation from each method. Then, we sequentially measured the classification performance by excluding the feature values one by one. In the second set of simulations, in order to measure the classification performance according to the group, the cumulants were divided into three groups (top, middle, and bottom) based on the ranking obtained from the efficient features extraction method. The following is a summary of how each group is divided.
The cumulants in each group were used as the input data of the DNN algorithm to measure the classification performance. The three AMC environments that use the features of each group as input values were implemented and the superiority of the proposed method was confirmed according to the group performance.
The rest of the paper is organized as follows. In
Section 2, we explain the features and data analysis method. In
Section 3, we introduce the proposed method and the conventional method. In
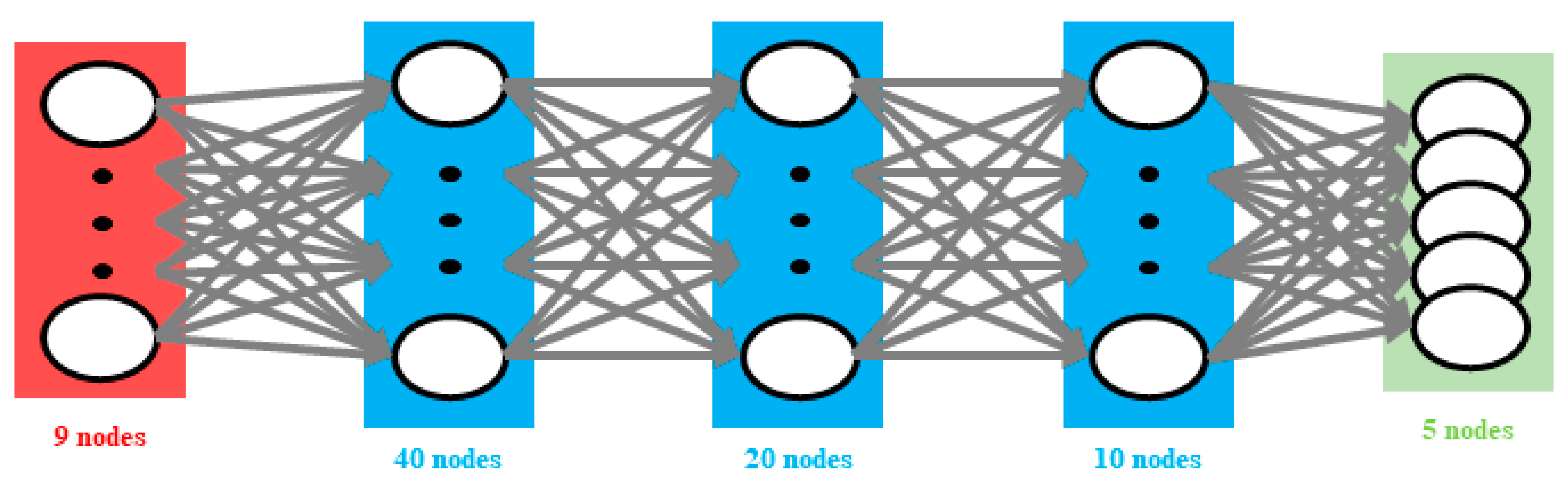
Section 4 we describe the DNN structure used in this paper and present the simulation results. Finally,
Section 5 provides the conclusions of the paper.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}