ExtendAIST: Exploring the Space of AI-in-the-Loop System Testing



Abstract
1. Introduction
- The AI-in-the-loop system is proposed to discuss the differences between testing ordinary system and AI-in-the-loop system in terms of testing coverage, test data, testing property, and testing technique based on the distinct nature of AI modules.
- The testing workflow of AI-in-the-loop system is presented to show the individual step including dataset generation, training and testing for AI-in-the-loop system.
- To the best of our knowledge, this is the first time researchers explore the design space of AI-in-the-loop system testing and present an extendable framework ExtendAIST. This framework provides five extension points, 19 sub-extension points, and existing techniques that researchers can use directly or extend further new techniques for corresponding testing requirements.
2. Motivation
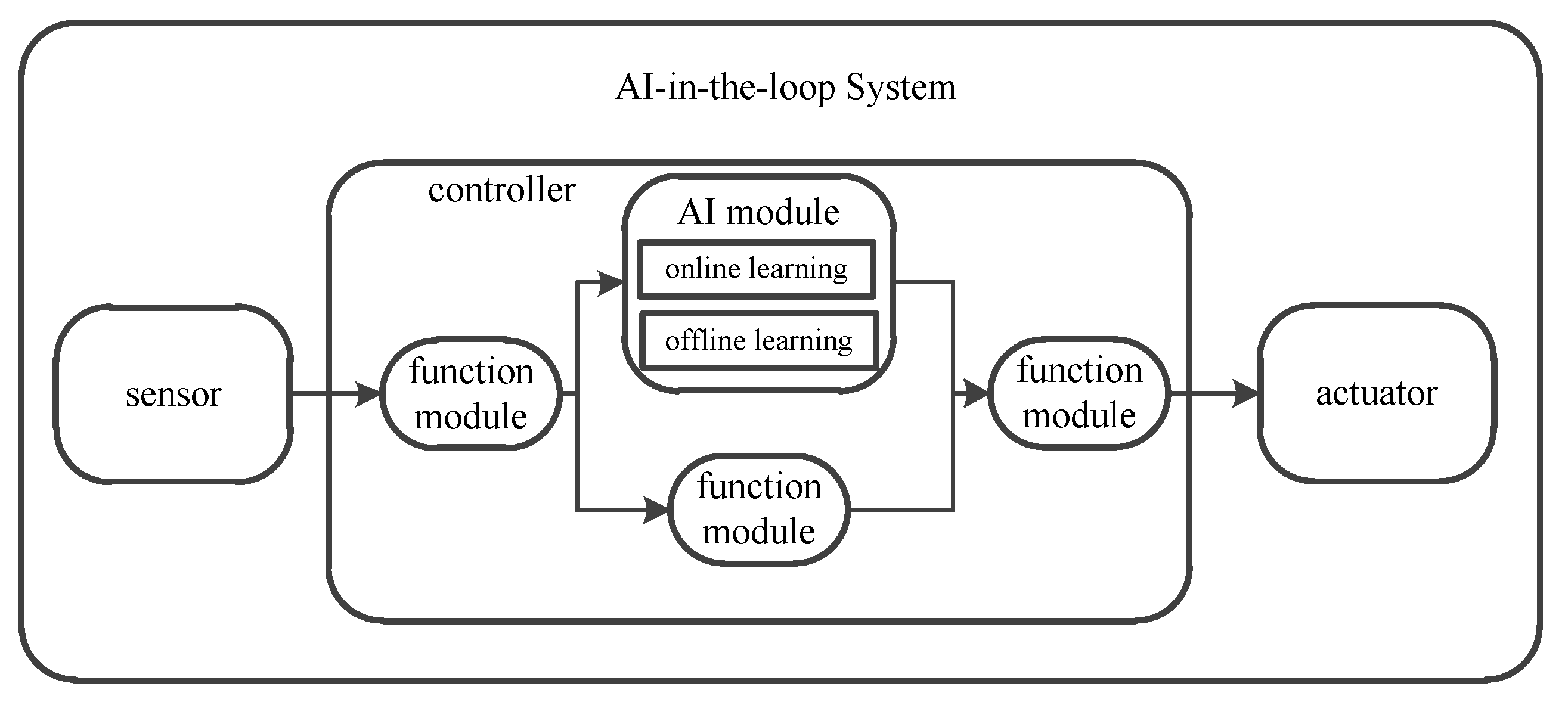
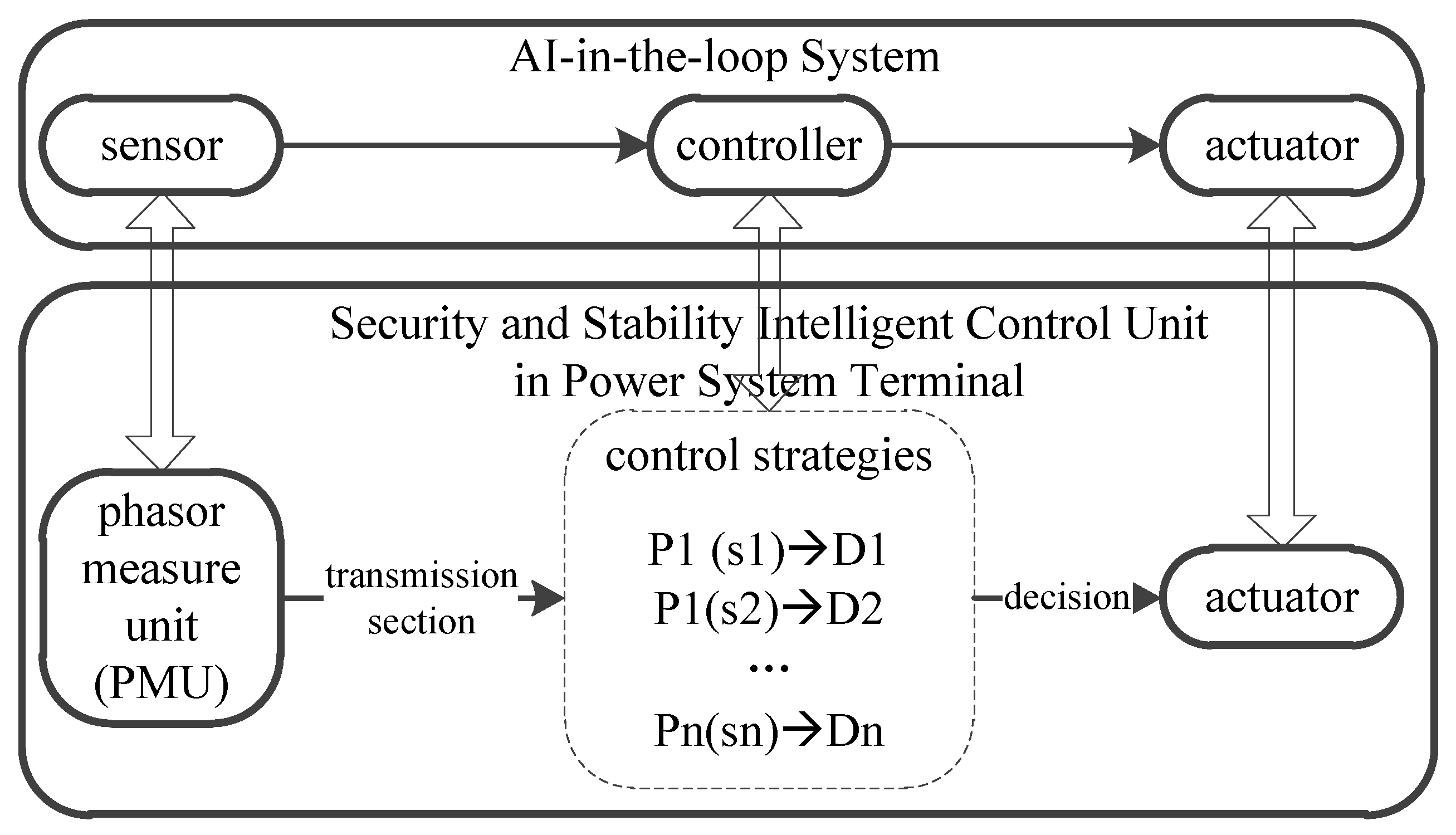
2.1. AI-in-the-Loop System
2.2. AI-in-the-Loop System Testing
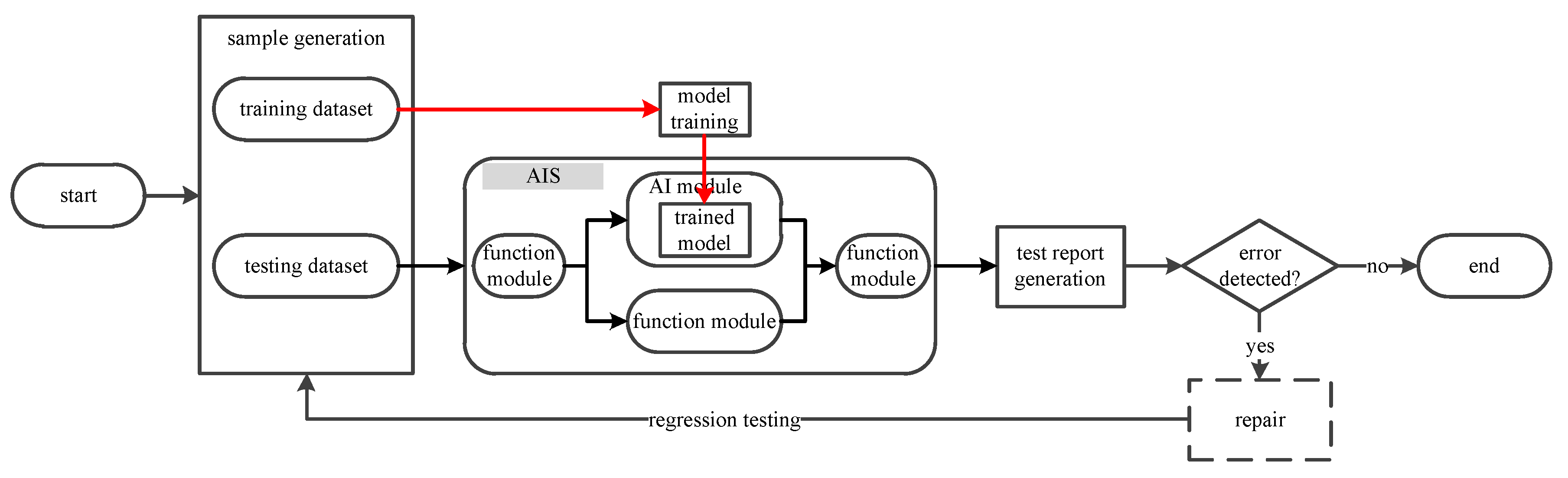
- Generate the test sample, including training dataset and testing dataset, through some test data generation algorithms. The training dataset can be selected from the common benchmarks or designed for some special application areas to train the learning model. The testing dataset is generated with the requirement of test coverage to test the trained model.
- When testing the ordinary system, the testing procedure follows the black arrowlines in Figure 2. The system executes the testing dataset and outputs the deterministic decision according to the predefined rules.
- When testing the AI-in-the-loop system, the testing procedure follows the red and black arrowlines in Figure 2 for AI module and other function modules, respectively. The trained model is learnt from the training dataset under the training model. Then, the AIS executes the testing dataset and outputs the predicted non-deterministic decision.
- After test execution procedure, the test report is generated to indicate the test results. The failed test demonstrates an erroneous behavior of system, and the passed test shows the behavior consistency.
- If some errors are detected during the testing procedure, then conduct the regression testing after all errors are repaired to make sure that no new error is introduced.
- If no error is detected, then terminate the testing procedure.
3. ExtendAIST
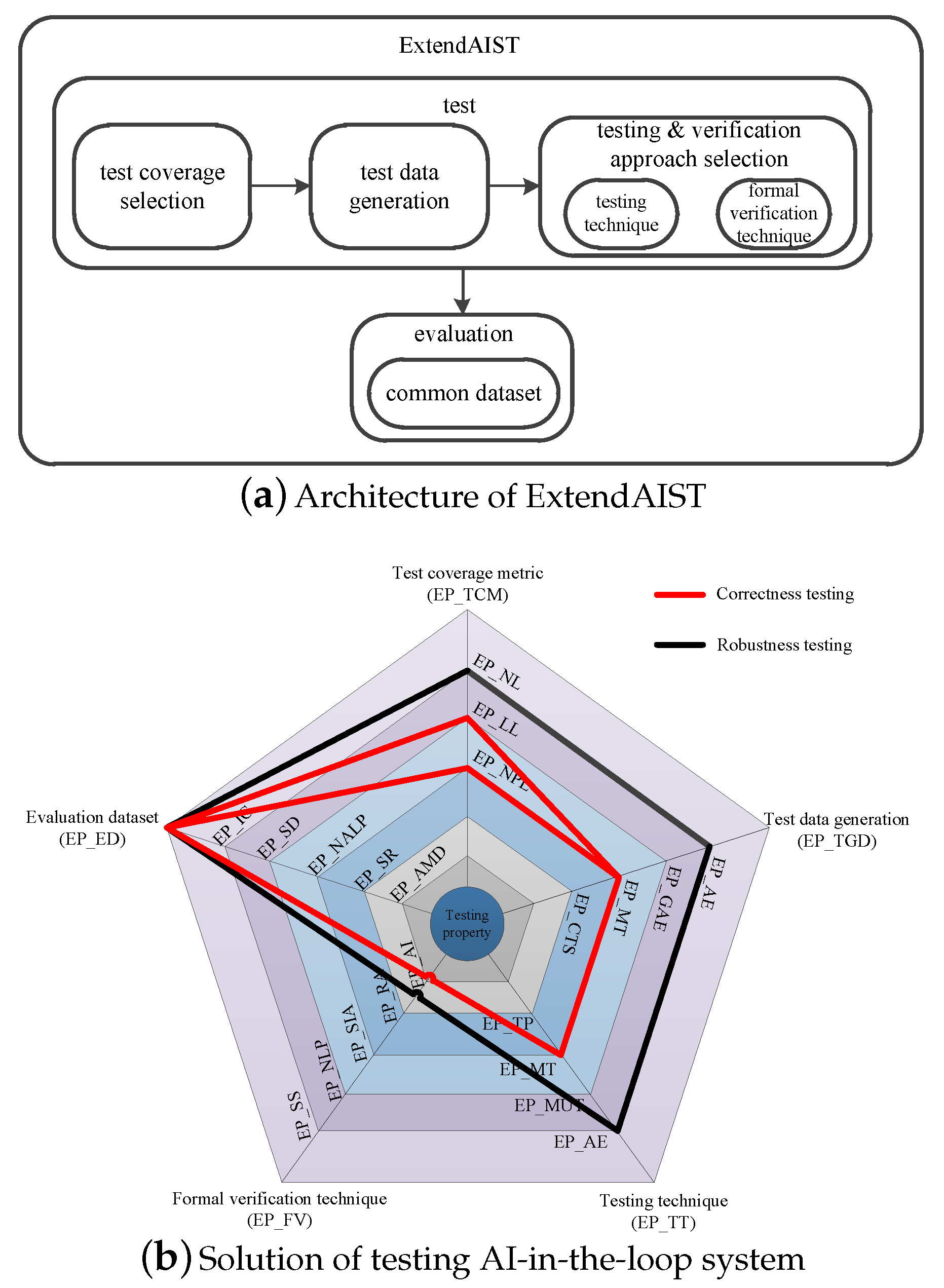
3.1. Architecture
3.2. Design
| Algorithm 1 Execution steps of testing AI-in-the-loop system in ExtendAIST. |
| Require: Testing requirement set R of AI-in-the-loop system under test Ensure: Testing strategy
|
3.3. Illustration
4. Extension Points and Sub-Extension Points
4.1. Test Coverage Metric (EP_TCM)
4.1.1. Description
4.1.2. Neuron Level (EP_NL)
- Activated neuron coverage. A neuron is considered activated if the neuron output is greater than the neuron activation threshold and makes contribution to neural network’s behaviors including major function and corner-case behaviors. As shown in Equation (1), the activated neuron coverage [13,14] is the rate of the number of neurons activated and the number of neurons in the whole DNN.
- -multisection neuron coverage. Ma et al. [15] proposed using neuron output value range to distinguish the major function region and corner-case region. Then, we can measure the coverage of major function region by dividing this region into equal subsections. As shown in Equation (2), -multisection neuron coverage for a neuron , is the rate of the number of subsections covered by and the total number of subsections, in which is a test input in dataset , is the output of neuron with test input , and is the set of values in the th subsection. The -multisection neuron coverage for the neural network , , is based on the -multisection neuron coverage of all neurons in network, which is defined in Equation (3).
- Neuron boundary coverage. In some cases, neuron output . That is, may locate , which is referred to as the corner-case region of neuron . Therefore, the neuron boundary coverage , the rate of the number of neurons falling in corner-case region and the total number of corner cases as in Equation (4), is used to measure how many corner-case regions are covered by test dataset . is the set of neurons located in the upper corner-case region, and is the set of neurons located in the lower corner-case region. The total number of corner cases of neuron boundary coverage is equal to , because and are mutually exclusive and neuron cannot fall in two regions at the same time.
- Strong neuron activation coverage. Because hyperactive corner-case neurons affect the training of DNN significantly, it is essential to measure the coverage of hyperactive corner-case neurons, namely strong neuron activation coverage. Similar to the neuron boundary coverage, strong neuron activation coverage is the rate of the number of neurons falling in the upper corner-case region and the total number of corner cases as in Equation (5).
4.1.3. Layer Level (EP_LL)
- Top- neuron coverage. Given test input and neurons and in the same layer, if , then is more active than . Here, the top- neuron coverage is designed to measure how many neurons are activated as the most neurons in each layer by the input test dataset . As shown in Equation (6), is the set of first neurons, which are ranked in descending order of their outputs.
4.1.4. Neuron Pair Level (EP_NPL)
- Sign–Sign cover. The sign change of condition neuron and signs of other neurons in the th layer not changing affect the sign of decision neuron in the next layer. That is, if , we say that is sign–sign covered by and which is denoted as .
- Distance–Sign cover. The small distance change of neurons in the th layer can cause the sign change of decision neuron in the next layer. Namely, if , we say that is distance–sign covered by and , denoted as .
- Sign–Value cover. Similar to sign–sign cover, the sign change of condition neuron and signs of other neurons in the th layer not changing affect the value of decision neuron in the next layer. That is, if , we say that is sign–value covered by and , denoted as .
- Distance–Value cover. Similar to distance–sign cover, the small distance change of neurons in the th layer leads to the value change of decision neuron in the next layer. Namely, if , then is distance–value covered by and , denoted as .
4.2. Test Data Generation (EP_TDG)
4.2.1. Description
4.2.2. Adversarial Examples (EP_AE)
- FGSM. To generate adversarial examples in a quick way, Goodfellow et al. [23] presented the Fast Gradient Sign Method (FGSM) based on the norm . As shown in Equation (8), the adversarial example depends on the single-step and the gradient sign of loss function , which determines the direction that increases the probability of the targeted class t.
- BIM. To improve the accuracy of adversarial examples, Kurakin et al. [24] proposed the Basic Iterative Method (BIM) by replacing single-step in FGSM with multiple smaller steps and minimizing the loss function for directing at the targeted label t. Equation (9) indicates that the adversarial example generated from the ith step depends on that from the last step iteratively.
- ILCM. Kurakin [25] further proposed the Iterative Least-likely Class Method (ILCM) by taking the target label with the least likelihood that is the most difficult to attack rather than the label with the most possibility in BIM.
- JSMA. Papernot et al. [26] proposed the Jacobian-based Saliency Map Attack (JSMA) to obtain a saliency map, which indicates the influence of each pixel on target label classification. Therefore, adversarial example can be generated with small perturbation by changing pixels with the greatest influence.
- One pixel attack. The one pixel attack [77] is presented extremely to generate adversarial image by changing only one pixel of the seeded image.
- C&W attack. To get an adversarial image with less distortion on the seeded image, Carlini and Wagner [78] proposed applying three distance metrics—, , and norms—to have a target attack on neural network.
4.2.3. Generative Adversarial Examples (EP_GAE)
- Generative adversarial nets. The Generative Adversarial Nets (GAN) [19], including a generative model G and a discriminative model D, are proposed to generate samples by learning and try to fool the discriminative model. The purpose of generative model is producing samples by learning the training data distribution that causes the discriminative model making a mistake. The discriminative model must determine whether the input sample is from training data or generative model G.
4.2.4. Metamorphic Testing Based Strategy (EP_MT)
- DeepTest. To test DNN-based self-driving system, DeepTest [14] takes the property that the output steering angle should keep unchanged under different real-world driving environments as the metamorphic relation to generate new test cases and determine whether the self-driving system satisfies the MR.
- Effect of noise outside ROI. Zhou et al. [22] investigated the effect of noise outside of the drivable area on the obstacle perception inside of the region of interest (ROI). The MR of obstacle perception system is that the noise in the region outside ROI would not cause the obstacles inside ROI undetectable.
4.2.5. Concolic Testing Based Strategy (EP_CTS)
- DeepConcolic. The DeepConcolic [27] leverages concolic testing to generate adversarial examples with high coverage. Given a DNN under test, a set of coverage requirements ℜ, an unsatisfied requirement r, and the initial test suite T, in the phase of concrete execution, a test input is identified to satisfy requirement r. Then, in the phase of symbolic execution, a new test input close to one of the test input t from T, is generated to satisfy requirement r and distance constraint . Then is added to the test suite T. is repeatedly generated until all requirements are satisfied or no more requirements in ℜ can be satisfied.
4.3. Testing Technique (EP_TT)
4.3.1. Description
4.3.2. Adversarial Attack (EP_AE)
- Targeted and Non-Targeted Adversarial Attack. According to the classification results for individual adversarial example, adversarial attack is divided into two categories: targeted and non-targeted adversarial attack [28,29]. Targeted attack indicates that the input adversarial example is misclassified as a specific label, while non-targeted attack indicates that the input adversarial example is assigned as any label not equal to the correct one.
- -norm attack. (Equation (12)) equals the Euclidean distance between original data and adversarial example. A lower indicates a smaller perturbation between the individual feature data and a higher similarity between original data and adversarial example. Hence, is also used to solve the problem of overfitting in adversarial example.
- -norm attack. (Equation (13)) represents the maximum difference among all feature data, which is utilized to control the maximum perturbation between original data and adversarial example.
4.3.3. Mutation Testing (EP_MUT)
- MuNN. MuNN [30] proposes five kinds of mutation operators according to the structure of neural network, including deleting neurons in the input layer and hidden layers, changing the bias, weights, and activation functions. A mutant neural network is said to be killed once its output is distinct from the output of the original network. More mutant networks being killed indicates a powerful test suite for DNN testing.
- DeepMutation. Since a trained model is obtained from the training program and training data, Ma et al. [31] proposed a further study on mutation testing of AI module from two perspectives: (1) generating mutant trained models based on the source-level mutation operators on the training data or training program; and (2) generating mutant trained models directly based on the model-level mutation operators on the original trained model, similar to MuNN.
4.3.4. Metamorphic Testing (EP_MT)
- DeepTest. Nine transformation based MRs have been proposed in DeepTest, namely changing brightness, contrast, translation, scaling, horizontal shearing, rotation, blurring, fog, and rain on the images, to test the robustness of autonomous vehicles. Take images from camera as the source images, and create the follow-up images by one or more transformation MRs on source images. The DNN under test takes source and follow-up images as inputs and outputs the source and follow-up steering angles under different real-world weather conditions, namely , . Strictly speaking, the steering angles should keep unchanged under these transformations. That is, . However, a small variation of steering angles, , in real-world driving environment would not affect the driving behaviors. Thus, the variations within the error ranges are allowed, as shown in Equation (14), in which .
4.3.5. Test Prioritization (EP_TP)
- DeepGini [32]. Take binary classification as example; given a test data t and the output feature vector , execute DNN to compute the probability of each feature for t. If the probability classified as is , and is , then the feature vector B has the highest purity and t is more likely to be classified correctly. In contrast, if , , then B has the lowest purity, and t is more likely to be misclassified. is defined as the metric of impurity and the likelihood of t being misclassified. As shown in Equation (15), is the probability of test case t being classified as class i. A lower indicates a higher impurity and a higher likelihood to misclassify t.
4.4. Formal Verification Technique (EP_FV)
4.4.1. Description
4.4.2. Satisfiability Solver (EP_SS)
- Safety verification. Given a neural network N, an input image x, a region around x with the same class, N is said to be safe for input x and if the classification of images in is invariant to x. That is, . In more depth, modifying the input image x with a family of manipulations , N is said to be safe for input x, , and manipulations if the classification of region keeps invariant to x under manipulations , namely . If , then the image classifier is vulnerable to these manipulations or adversarial perturbations.
4.4.3. Non-linear Problem (EP_NLP)
- Piecewise linear network verification. Since some activation functions are non-linear, the formal verification is transformed into a Mixed Integer Program (MIP) with the value of binary variables , where . The binary variable indicates the phase of activation function ReLU. If , the activation function is blocked and the output of related neuron will be 0; otherwise, the activation function is passed and the output of related neuron will be equal to its input value.
4.4.4. Symbolic Interval Analysis (EP_SIA)
- ReluVal. Given an input range X, subintervals of X and security property P. DNN is secure if no value in range X and its subintervals violate property P, that is, any value from range X satisfies P; otherwise DNN is insecure if there exists one adversarial example in X violating P, that is, there exists at least one subinterval containing an adversarial example to make property P unsatisfied.
4.4.5. Reachability Analysis (EP_RA)
- DeepGo. If all values in the output range, the lower and upper bounds , correspond to an input in input subspace , then the network f is reachable and the reachability diameter is . The network f is said to be safe for the input if all inputs in have the same label to x, as shown in Equation (16).
4.4.6. Abstract Interpretation (EP_AI)
- AI2. AI2 [37] proposes to employ the zonotope domain to represent the abstract elements in neural network and output the abstract elements in each layer. Finally, the safety of network is determined by verifying whether the label of abstract output in the output layer is consistent with that of the concrete output.
- Symbolic propagation. To improve the precision and efficiency of DNN safety verification, Yang et al. [38] proposed a symbolic propagation method based on the abstract interpretation by representing the values of neurons symbolically and propagating them from the input layer to output layer forwardly. A more precise range of output layer is computed by the interval abstract domain based on the symbolic representation of output layer.
4.5. Evaluation Dataset (EP_ED)
4.5.1. Description
4.5.2. Image Classification (EP_IC)
- MNIST. MNIST [39,40] is a dataset for recognizing handwritten digits (0–9) including 70,000 images originating from the NIST database [98]. The MNIST dataset is composed of a training dataset with 60,000 images and a test dataset with 10,000 images, each of which contains half clear digits written by government staff and half blurred digits written by students.
- EMNIST. EMNIST [41,42] is an extension dataset of MNIST for identifying handwritten digits (0–9) and letters (a–z and A–Z). Therefore, there are totally 62 classes in EMNIST, including 10 classes of digits and 52 classes of letters. However, some uppercases and lowercases cannot be distinguished easily (e.g., C and c and K and k), then the letters are merged into 37 classes.
- CIFAR-10/CIFAR-100. CIFAR-10 and CIFAR-100 [47] are labeled image datasets consisting of 60,000 32 × 32 color images, 50,000 of which are training images and 10,000 are test images. CIFAR-10 is divided into 10 classes, and there are 5000 training images and 1000 test images for each class. CIFAR-100 is divided into 100 fine classes, and each class contains 500 training images and 100 test images.
4.5.3. Self Driving (EP_SD)
- Udacity Challenge. Udacity Challenge dataset [48] is a set of images for training and testing the objects detection models in the Udacity Challenge competition to measure the performance of each participating model in terms of detection capability and classification precision. The Udacity Challenge dataset contains two parts according to its classification. One consists of 9420 images in three classes: car, truck, and pedestrian; and the other consists of 15,000 images in five classes: car, truck, pedestrian, traffic light, and bycicle.
- MSCOCO 2015. MSCOCO 2015 [49,50] is a dataset gathered from the daily scenes of common objects in the real-world environment, which aims at object recognition and localization. This dataset contains 165,482 training images, 81,208 verification images and 81,434 testing images in 91 classes, such as animal, vegetable, and human.
- KITTI. KITTI dataset [51,52,53] contains the realistic images captured from the real-world driving environments such as mid-size city, rural area, and highway. All these images are divided into five classes: road, city, residence, campus, and human. Evaluation tasks include stereo, optical flow, visual odometry, object detection, and tracking.
- Baidu Apollo. The Baidu Apollo [54] open platform provides the massive annotation data and simulation for training and testing autonomous driving tasks, such as obstacle detection and classification, traffic light detection, road hackers, obstacle trajectory prediction, and scene analysis under different street views and vehicle movement images.
4.5.4. Natural Language Processing (EP_NALP)
- Enron. Enron [55] is an email dataset collected from 150 senior managers of Enron, which contains about 500,000 real email messages. All emails from one manager are organized into a folder, which contains the information of message-ID, date, sender, recipient, and messages.
- bAbI. bAbI [56] is a dataset from Facebook AI Research with 20 toy question-answering tasks. Each task contains 1000 training examples and 1000 test examples, which aims at reasoning or answering questions after training.
- Common Crawl. The Common Crawl corpus [57] contains petabytes of data including raw web page data, metadata extracts, and text extracts by web crawling. This corpus provides web-scaled data for developing or evaluating natural language processing algorithms empirically.
4.5.5. Speech Recognition (EP_SR)
- Speech Commands. Speech Commands [60,61] is an audio dataset for detecting single keyword from a set of spoken words. This dataset focuses on the audio of on-device trigger phrases and contains 105,829 utterances of 35 words in format of WAVE files. All these utterance were recorded from 2618 speakers, and each utterance is one second or less.
- Free Spoken Digit Dataset. FSDD [62] is a dataset of 2000 audio recordings of spoken English digits in format of WAVE files. These speeches were recorded by four speakers with 50 recordings of each digit per speaker.
4.5.6. Android Malware Detection (EP_AMD)
- VirusTotal. VirusTotal [72] is a dataset of mobile Apps samples for analyzing suspicious files and URLs to detect types of malware including viruses, worms, and trojans.
- Contagio. The Contagio [73] is a platform for collecting the most recent malware, thus it can be used to analyze and help detect unknown malware.
5. Discussion
6. Conclusions
- EP_TCM. Training and testing procedure should be enhanced to adapt to different systems with more complex networks. Thus, the extension point EP_TCM provides the first opportunity to increase the testing coverage on different scaled AI-in-the-loop systems with regard to the traditional software testing coverage metrics.
- EP_ED. Since enormous test data involve powerful computing ability and expensive computing cost, the extension point EP_ED provides the second opportunity to design a dataset with relatively smaller size for various application areas.
- EP_TT and EP_FV. AI-in-the-loop system testing techniques currently focus on assuring the system correctness, safety, and robustness. This is the third opportunity provided by EP_TT and EP_FV to design new testing approach to test more properties for AI-in-the-loop system including efficiency, interpretability, and stiffness.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Badue, C.; Guidolini, R.; Carneiro, R.V.; Azevedo, P.; Cardoso, V.B.; Forechi, A.; Jesus, L.F.R.; Berriel, R.F.; Paixão, T.M.; Mutz, F.; et al. Self-driving cars: A survey. arXiv 2019, arXiv:1901.04407. [Google Scholar]
- Hains, G.; Jakobsson, A.; Khmelevsky, Y. Towards formal methods and software engineering for deep learning: Security, safety and productivity for dl systems development. In Proceedings of the 2018 Annual IEEE International Systems Conference (SysCon), Vancouver, BC, Canada, 23–26 April 2018; pp. 1–5. [Google Scholar]
- Masuda, S.; Ono, K.; Yasue, T.; Hosokawa, N. A Survey of Software Quality for Machine Learning Applications. In Proceedings of the 2018 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW), Xi’an, China, 9–13 April 2018; pp. 279–284. [Google Scholar]
- Braiek, H.B.; Khomh, F. On testing machine learning programs. arXiv 2018, arXiv:1812.02257. [Google Scholar]
- Ma, L.; Juefei-Xu, F.; Xue, M.; Hu, Q.; Chen, S.; Li, B.; Liu, Y.; Zhao, J.; Yin, J.; See, S. Secure Deep Learning Engineering: A Software Quality Assurance Perspective. arXiv 2018, arXiv:1810.04538. [Google Scholar]
- Huang, X.; Kroening, D.; Kwiatkowska, M.; Ruan, W.; Sun, Y.; Thamo, E.; Wu, M.; Yi, X. Safety and Trustworthiness of Deep Neural Networks: A Survey. arXiv 2018, arXiv:1812.08342. [Google Scholar]
- Zhang, J.M.; Harman, M.; Ma, L.; Liu, Y. Machine Learning Testing: Survey, Landscapes and Horizons. arXiv 2019, arXiv:1906.10742. [Google Scholar]
- Martinez, M.; Monperrus, M. Astor: Exploring the design space of generate-and-validate program repair beyond GenProg. J. Syst. Softw. 2019, 151, 65–80. [Google Scholar] [CrossRef]
- Barr, E.T.; Harman, M.; Mcminn, P.; Shahbaz, M.; Yoo, S. The Oracle Problem in Software Testing: A Survey. IEEE Trans. Softw. Eng. 2015, 41, 507–525. [Google Scholar] [CrossRef]
- Koopman, P.; Wagner, M. Challenges in autonomous vehicle testing and validation. SAE Int. J. Transp. Saf. 2016, 4, 15–24. [Google Scholar] [CrossRef]
- Goodfellow, I.; Papernot, N. The Challenge of Verification and Testing of Machine Learning. Available online: http://www.cleverhans.io/security/privacy/ml/2017/06/14/verification.html (accessed on 15 May 2019).
- Koopman, P.; Wagner, M. Autonomous vehicle safety: An interdisciplinary challenge. IEEE Intell. Transp. Syst. Mag. 2017, 9, 90–96. [Google Scholar] [CrossRef]
- Pei, K.; Cao, Y.; Yang, J.; Jana, S. Deepxplore: Automated whitebox testing of deep learning systems. In Proceedings of the 26th Symposium on Operating Systems Principles, Shanghai, China, 28–31 October 2017; pp. 1–18. [Google Scholar]
- Tian, Y.; Pei, K.; Jana, S.; Ray, B. Deeptest: Automated testing of deep-neural-network-driven autonomous cars. In Proceedings of the 40th International Conference on Software Engineering, Gothenburg, Sweden, 27 May–3 June 2018; pp. 303–314. [Google Scholar]
- Ma, L.; Juefei-Xu, F.; Zhang, F.; Sun, J.; Xue, M.; Li, B.; Chen, C.; Su, T.; Li, L.; Liu, Y.; et al. Deepgauge: Multi-granularity testing criteria for deep learning systems. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 3–7 September 2018; pp. 120–131. [Google Scholar]
- Sun, Y.; Huang, X.; Kroening, D. Testing deep neural networks. arXiv 2018, arXiv:1803.04792. [Google Scholar]
- Fort, S.; Nowak, P.K.; Narayanan, S. Stiffness: A new perspective on generalization in neural networks. arXiv 2019, arXiv:1901.09491. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Annual Conference on Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Xie, X.; Ho, J.; Murphy, C.; Kaiser, G.; Xu, B.; Chen, T.Y. Application of metamorphic testing to supervised classifiers. In Proceedings of the 2009 Ninth International Conference on Quality Software, Jeju, Korea, 24–25 August 2009; pp. 135–144. [Google Scholar]
- Xie, X.; Ho, J.W.; Murphy, C.; Kaiser, G.; Xu, B.; Chen, T.Y. Testing and validating machine learning classifiers by metamorphic testing. J. Syst. Softw. 2011, 84, 544–558. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.Q.; Sun, L. Metamorphic testing of driverless cars. Commun. ACM 2019, 62, 61–67. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial examples in the physical world. arXiv 2016, arXiv:1607.02533. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial machine learning at scale. arXiv 2016, arXiv:1611.01236. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrucken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar]
- Sun, Y.; Wu, M.; Ruan, W.; Huang, X.; Kwiatkowska, M.; Kroening, D. Concolic testing for deep neural networks. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 3–7 September 2018; pp. 109–119. [Google Scholar]
- Akhtar, N.; Mian, A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Poursaeed, O.; Katsman, I.; Gao, B.; Belongie, S. Generative adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2018; pp. 4422–4431. [Google Scholar]
- Shen, W.; Wan, J.; Chen, Z. MuNN: Mutation Analysis of Neural Networks. In Proceedings of the 2018 IEEE International Conference on Software Quality, Reliability and Security Companion (QRS-C), Lisbon, Portugal, 16–20 July 2018; pp. 108–115. [Google Scholar]
- Ma, L.; Zhang, F.; Sun, J.; Xue, M.; Li, B.; Juefei-Xu, F.; Xie, C.; Li, L.; Liu, Y.; Zhao, J.; et al. Deepmutation: Mutation testing of deep learning systems. In Proceedings of the 2018 IEEE 29th International Symposium on Software Reliability Engineering (ISSRE), Memphis, TN, USA, 15–18 October 2018; pp. 100–111. [Google Scholar]
- Shi, Q.; Wan, J.; Feng, Y.; Fang, C.; Chen, Z. DeepGini: Prioritizing Massive Tests to Reduce Labeling Cost. arXiv 2019, arXiv:1903.00661. [Google Scholar]
- Huang, X.; Kwiatkowska, M.; Wang, S.; Wu, M. Safety verification of deep neural networks. In Proceedings of the International Conference on Computer Aided Verification, Heidelberg, Germany, 24–28 July 2017; pp. 3–29. [Google Scholar]
- Bunel, R.; Turkaslan, I.; Torr, P.H.; Kohli, P.; Kumar, M.P. A Unified View of Piecewise Linear Neural Network Verification. arXiv 2017, arXiv:1711.00455. [Google Scholar]
- Wang, S.; Pei, K.; Whitehouse, J.; Yang, J.; Jana, S. Formal security analysis of neural networks using symbolic intervals. In Proceedings of the 27th {USENIX} Security Symposium ({USENIX} Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 1599–1614. [Google Scholar]
- Ruan, W.; Huang, X.; Kwiatkowska, M. Reachability analysis of deep neural networks with provable guarantees. arXiv 2018, arXiv:1805.02242. [Google Scholar]
- Gehr, T.; Mirman, M.; Drachsler-Cohen, D.; Tsankov, P.; Chaudhuri, S.; Vechev, M. Ai2: Safety and robustness certification of neural networks with abstract interpretation. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 21–23 May 2018; pp. 3–18. [Google Scholar]
- Yang, P.; Liu, J.; Li, J.; Chen, L.; Huang, X. Analyzing Deep Neural Networks with Symbolic Propagation: Towards Higher Precision and Faster Verification. arXiv 2019, arXiv:1902.09866. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- LeCun, Y.; Cortes, C.; Burges, C.J. The MNIST Database of Handwritten Digits. 1998. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 15 May 2019).
- Cohen, G.; Afshar, S.; Tapson, J.; van Schaik, A. EMNIST: An extension of MNIST to handwritten letters. arXiv 2017, arXiv:1702.05373. [Google Scholar]
- EMNIST. 2017. Available online: https://www.westernsydney.edu.au/bens/home/reproducible_research/emnist (accessed on 15 May 2019).
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Fashion-MNIST. 2017. Available online: https://github.com/zalandoresearch/fashion-mnist (accessed on 15 May 2019).
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- ImageNet. 2009. Available online: http://www.image-net.org/ (accessed on 15 May 2019).
- CIFAR. 2014. Available online: http://www.cs.toronto.edu/~kriz/cifar.html (accessed on 15 May 2019).
- Udacity-Challenge 2016. Using Deep Learning to Predict Steering Angles. 2016. Available online: https://github.com/udacity/self-driving-car (accessed on 15 May 2019).
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- MSCOCO. 2015. Available online: http://cocodataset.org/ (accessed on 15 May 2019).
- KITTI. 2015. Available online: http://www.cvlibs.net/datasets/kitti/index.php (accessed on 15 May 2019).
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Baidu Apollo. 2017. Available online: http://apolloscape.auto/ (accessed on 15 May 2019).
- Enron. 2015. Available online: https://www.cs.cmu.edu/~./enron/ (accessed on 15 May 2019).
- The bAbI Dataset. Available online: https://research.facebook.com/research/babi/ (accessed on 15 May 2019).
- Common Crawl. Available online: http://commoncrawl.org/the-data/ (accessed on 15 May 2019).
- Bowman, S.R.; Angeli, G.; Potts, C.; Manning, C.D. A large annotated corpus for learning natural language inference. arXiv 2015, arXiv:1508.05326. [Google Scholar]
- Stanford Natural Language Inference. Available online: https://nlp.stanford.edu/projects/snli/ (accessed on 15 May 2019).
- Warden, P. Speech Commands: A dataset for Limited-Vocabulary speech recognition. arXiv 2018, arXiv:1804.03209. [Google Scholar]
- Speech Commands. 2017. Available online: https://download.tensorflow.org/data/speech_commands_v0.01.tar.gz (accessed on 15 May 2019).
- Free Spoken Digit Dataset. Available online: https://github.com/Jakobovski/free-spoken-digit-dataset (accessed on 15 May 2019).
- Million Song Dataset. Available online: http://millionsongdataset.com/ (accessed on 15 May 2019).
- Bertin-Mahieux, T.; Ellis, D.P.W.; Whitman, B.; Lamere, P. The Million Song Dataset. In Proceedings of the International Society for Music Information Retrieval Conference, Porto, Portugal, 8–12 October 2012. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Queensland, Australia, 19–24 April 2015. [Google Scholar]
- LibriSpeech. Available online: http://www.openslr.org/12/ (accessed on 15 May 2019).
- Drebin. Available online: https://www.sec.cs.tu-bs.de/~danarp/drebin/index.html (accessed on 15 May 2019).
- Arp, D.; Spreitzenbarth, M.; Hubner, M.; Gascon, H.; Rieck, K.; Siemens, C. Drebin: Effective and explainable detection of android malware in your pocket. Ndss 2014, 14, 23–26. [Google Scholar]
- Spreitzenbarth, M.; Freiling, F.; Echtler, F.; Schreck, T.; Hoffmann, J. Mobile-sandbox: Having a deeper look into android applications. In Proceedings of the 28th Annual ACM Symposium on Applied Computing, Coimbra, Portugal, 18–22 March 2013; pp. 1808–1815. [Google Scholar]
- Zhou, Y.; Jiang, X. Dissecting Android Malware: Characterization and Evolution. In Proceedings of the 33rd IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–23 May 2012. [Google Scholar]
- Android Malware Genome Project. Available online: http://www.malgenomeproject.org/ (accessed on 15 May 2019).
- VirusTotal. Available online: https://www.virustotal.com/ (accessed on 15 May 2019).
- Contagio Malware Dump. Available online: http://contagiodump.blogspot.com/ (accessed on 15 May 2019).
- Yuan, X.; He, P.; Zhu, Q.; Li, X. Adversarial examples: Attacks and defenses for deep learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2805–2824. [Google Scholar] [CrossRef]
- Biggio, B.; Roli, F. Wild patterns: Ten years after the rise of adversarial machine learning. Pattern Recognit. 2018, 84, 317–331. [Google Scholar] [CrossRef]
- Zhang, S.; Zuo, X.; Liu, J. The problem of the adversarial examples in deep learning. J. Comput. 2018, 41, 1–21. [Google Scholar] [CrossRef]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; pp. 39–57. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1765–1773. [Google Scholar]
- Sarkar, S.; Bansal, A.; Mahbub, U.; Chellappa, R. UPSET and ANGRI: Breaking high performance image classifiers. arXiv 2017, arXiv:1707.01159. [Google Scholar]
- Mopuri, K.R.; Garg, U.; Venkatesh, B.R. Fast Feature Fool: A data independent approach to universal adversarial perturbations. arXiv 2017, arXiv:1707.05572. [Google Scholar]
- Chen, T.Y.; Cheung, S.C.; Yiu, S.M. Metamorphic Testing: A New Approach for Generating Next Test Cases; Technical Report; Technical Report HKUST-CS98-01; Department of Computer Science: Hong Kong, China, 1998. [Google Scholar]
- Segura, S.; Fraser, G.; Sanchez, A.B.; Ruiz-Cortés, A. A survey on metamorphic testing. IEEE Trans. Softw. Eng. 2016, 42, 805–824. [Google Scholar] [CrossRef]
- Chen, T.Y.; Kuo, F.C.; Liu, H.; Poon, P.L.; Towey, D.; Tse, T.; Zhou, Z.Q. Metamorphic testing: A review of challenges and opportunities. ACM Comput. Surv. (CSUR) 2018, 51, 4. [Google Scholar] [CrossRef]
- Cadar, C.; Sen, K. Symbolic execution for software testing: three decades later. Commun. ACM 2013, 56, 82–90. [Google Scholar] [CrossRef]
- Yi, P.; Wang, K.; Huang, C.; Gu, S.; Zou, F.; Li, J. Adversarial attacks in artificial intelligence: A survey. J. Shanghai Jiao Tong Univ. 2018, 52, 1298–1306. [Google Scholar]
- Jia, Y.; Harman, M. An analysis and survey of the development of mutation testing. IEEE Trans. Softw. Eng. 2010, 37, 649–678. [Google Scholar] [CrossRef]
- Katz, G.; Barrett, C.; Dill, D.L.; Julian, K.; Kochenderfer, M.J. Reluplex: An efficient SMT solver for verifying deep neural networks. In Proceedings of the International Conference on Computer Aided Verification, Heidelberg, Germany, 24–28 July 2017; pp. 97–117. [Google Scholar]
- Pulina, L.; Tacchella, A. An abstraction-refinement approach to verification of artificial neural networks. In Proceedings of the International Conference on Computer Aided Verification, Edinburgh, UK, 15–19 July 2010; pp. 243–257. [Google Scholar]
- Narodytska, N.; Kasiviswanathan, S.; Ryzhyk, L.; Sagiv, M.; Walsh, T. Verifying properties of binarized deep neural networks. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Cheng, C.H.; Nührenberg, G.; Huang, C.H.; Ruess, H. Verification of Binarized Neural Networks via Inter-Neuron Factoring. arXiv 2017, arXiv:1710.03107. [Google Scholar]
- Lomuscio, A.; Maganti, L. An approach to reachability analysis for feed-forward relu neural networks. arXiv 2017, arXiv:1706.07351. [Google Scholar]
- Cheng, C.H.; Nührenberg, G.; Ruess, H. Maximum resilience of artificial neural networks. In Proceedings of the International Symposium on Automated Technology for Verification and Analysis, Pune, India, 3–6 October 2017; pp. 251–268. [Google Scholar]
- Xiang, W.; Tran, H.D.; Johnson, T.T. Output reachable set estimation and verification for multilayer neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5777–5783. [Google Scholar] [CrossRef] [PubMed]
- Mirman, M.; Gehr, T.; Vechev, M. Differentiable abstract interpretation for provably robust neural networks. In Proceedings of the International Conference on Machine Learning, Jinan, China, 26–28 May 2018; pp. 3575–3583. [Google Scholar]
- Cousot, P.; Cousot, R. Abstract interpretation: A unified lattice model for static analysis of programs by construction or approximation of fixpoints. In Proceedings of the 4th ACM SIGACT-SIGPLAN Symposium on Principles Of Programming Languages, Los Angeles, CA, USA, 17–19 January 1977; pp. 238–252. [Google Scholar]
- Cousot, P.; Cousot, R. Abstract interpretation frameworks. J. Logic Comput. 1992, 2, 511–547. [Google Scholar] [CrossRef]
- Grother, P.J. NIST Special Database 19 Handprinted Forms and Characters Database; Technical Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 1995.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Extension Point | Sub-Extension Point | Description | Existing Technique |
|---|---|---|---|
| Test Coverage Metric (EP_TCM) | Neuron level (EP_NL) | The coverage of activated neurons for the major and corner-case behaviors | Activated neuron coverage [13,14], Major and corner-case coverage [15] |
| Layer level (EP_LL) | The number of the most active neurons in each layer | Top- neuron coverage [15] | |
| Neuron pair level (EP_NPL) | The sign (or distance) change of neuron (or layer ) affects the sign (or value) of neuron | Sign/Distance–Sign/ Value cover [16] | |
| Test Data Generation (EP_TDG) | Metamorphic testing based strategy (EP_MT) | Generate follow-up test data with the noise from the metamorphic relation | Classifier testing [20,21], DeepTest [14], noise effect [22] |
| Adversarial examples (EP_AE) | Generate test data with imperceptible perturbations to the input | L-BFGS [18], FGSM [23], BIM [24], ILCM [25], JSMA [26] | |
| Generative adversarial examples (EP_GAE) | Generate test data using generative adversarial nets | Generative adversarial nets [19] | |
| Concolic testing based strategy (EP_CTS) | Generate test data with the smallest distance to the input by the concrete execution and symbolic execution | DeepConcolic [27] | |
| Testing Technique (EP_TT) | Adversarial attack (EP_AE) | Reveal the defects in DNN by executing adversarial examples | Targeted, non-targeted, -norm attack [28,29] |
| Mutation testing (EP_MUT) | Evaluate the testing adequacy by mutating training data, training program and trained model | MuNN [30], DeepMutation [31] | |
| Metamorphic testing (EP_MT) | Determine the system correctness by checking whether the metamorphic relation is satisfied | DeepTest [14] | |
| Test prioritization (EP_TP) | Measure the correctness of classification by the purity of test data | DeepGini [32] | |
| Formal Verification Technique (EP_FV) | Satisfiability Solver (EP_SS) | Transform the safety verification to satisfiability solver problem | Safety verification [33] |
| Non-linear problem (EP_NLP) | Transform the safety verification to non-linear problem | Piecewise linear network verification [34] | |
| Symbolic interval analysis (EP_SIA) | Transform the safety verification by analyzing symbolic interval | ReluVal [35] | |
| Reachability analysis (EP_RA) | Transform the safety verification by analyzing the reachability problem | DeepGo [36] | |
| Abstract interpretation (EP_AI) | Transform the safety verification to abstract interpretation | AI2 [37], Symbolic propagation [38] | |
| Evaluation Dataset (EP_ED) | Image classification (EP_IC) | Dataset for image recognition | MNIST [39,40], EMNIST [41,42], Fashion-MNIST [43,44], ImageNet [45,46], CIFAR-10/CIFAR-100 [47] |
| Self driving (EP_SD) | Dataset for training and testing autonomous car system | Udacity Challenge [48], MSCOCO 2015 [49,50], KITTI [51,52,53], Baidu Apollo [54] | |
| Natural language processing (EP_NALP) | Dataset for text processing | Enron Email Dataset [55], bAbI [56], Text Classification Datasets [57], SNLI [58,59] | |
| Speech recognition (EP_SR) | Dataset for speech recognition | Speech Commands [60,61], Free Spoken Digit Dataset [62], Million Song Dataset [63,64], LibriSpeech [65,66] | |
| Android malware detection (EP_AMD) | Dataset for Android malware detection | Drebin [67,68,69], Genome [70,71], VirusTotal [72], Contagio [73] |
| Testing Requirement | Test Coverage Metric (EP_TCM) | Test Data Generation (EP_TDG) | Testing Technique (EP_TT) | Formal Verification Technique (EP_FV) | Evaluation Dataset (EP_ED) | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EP_NL | EP_LL | EP_NPL | EP_MT | EP_AE | EP_GAE | EP_CTS | EP_AE | EP_MUT | EP_MT | EP_TP | EP_SS | EP_NLP | EP_SIA | EP_RA | EP_AI | EP_IC | EP_SD | EP_NALP | EP_SR | EP_AMD | |
| Neuron coverage | √ | ||||||||||||||||||||
| Network layer coverage | √ | ||||||||||||||||||||
| Layers influence coverage | √ | ||||||||||||||||||||
| Correctness | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | |||||||||
| Robustness | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | |||||||||
| Safety | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | ||||||||
| Image processing | √ | √ | |||||||||||||||||||
| Text processing | √ | ||||||||||||||||||||
| Audio processing | √ | ||||||||||||||||||||
| Malware detection | √ | ||||||||||||||||||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, T.; Dong, Y.; Zhang, Y.; Singa, A. ExtendAIST: Exploring the Space of AI-in-the-Loop System Testing. Appl. Sci. 2020, 10, 518. https://doi.org/10.3390/app10020518
Wu T, Dong Y, Zhang Y, Singa A. ExtendAIST: Exploring the Space of AI-in-the-Loop System Testing. Applied Sciences. 2020; 10(2):518. https://doi.org/10.3390/app10020518
Chicago/Turabian StyleWu, Tingting, Yunwei Dong, Yu Zhang, and Aziz Singa. 2020. "ExtendAIST: Exploring the Space of AI-in-the-Loop System Testing" Applied Sciences 10, no. 2: 518. https://doi.org/10.3390/app10020518
APA StyleWu, T., Dong, Y., Zhang, Y., & Singa, A. (2020). ExtendAIST: Exploring the Space of AI-in-the-Loop System Testing. Applied Sciences, 10(2), 518. https://doi.org/10.3390/app10020518