Fi-Fo Detector: Figure and Formula Detection Using Deformable Networks

 ,
,  , ,
, , 

Abstract
1. Introduction
- A hybrid approach that glues traditional computer vision approaches with deep-learning for refined representation learning to detect heterogeneous objects in document images, figures and formulas in particular.
- Refinement of the ICDAR-2017 POD dataset to eliminate disproportions and confusions.
- Ablation study of the proposed method on a large publicly available dataset ICDAR-2017 POD to justify the efficacy of the proposed approach.
2. Related Work
3. Fi-Fo Detector
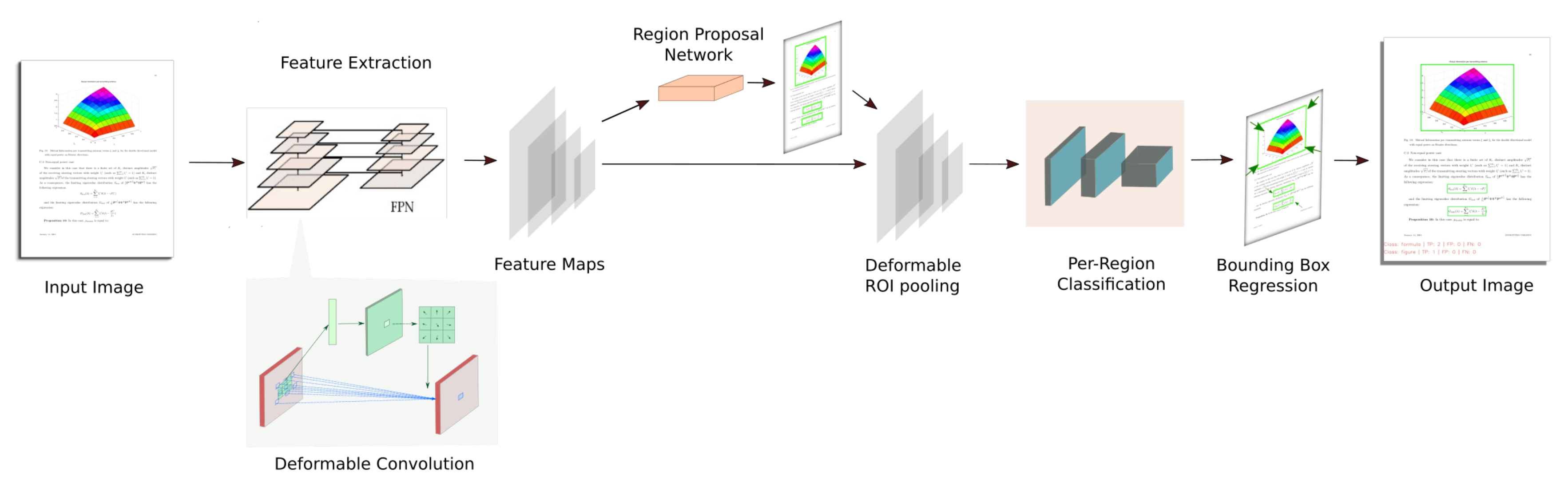
3.1. System Overview
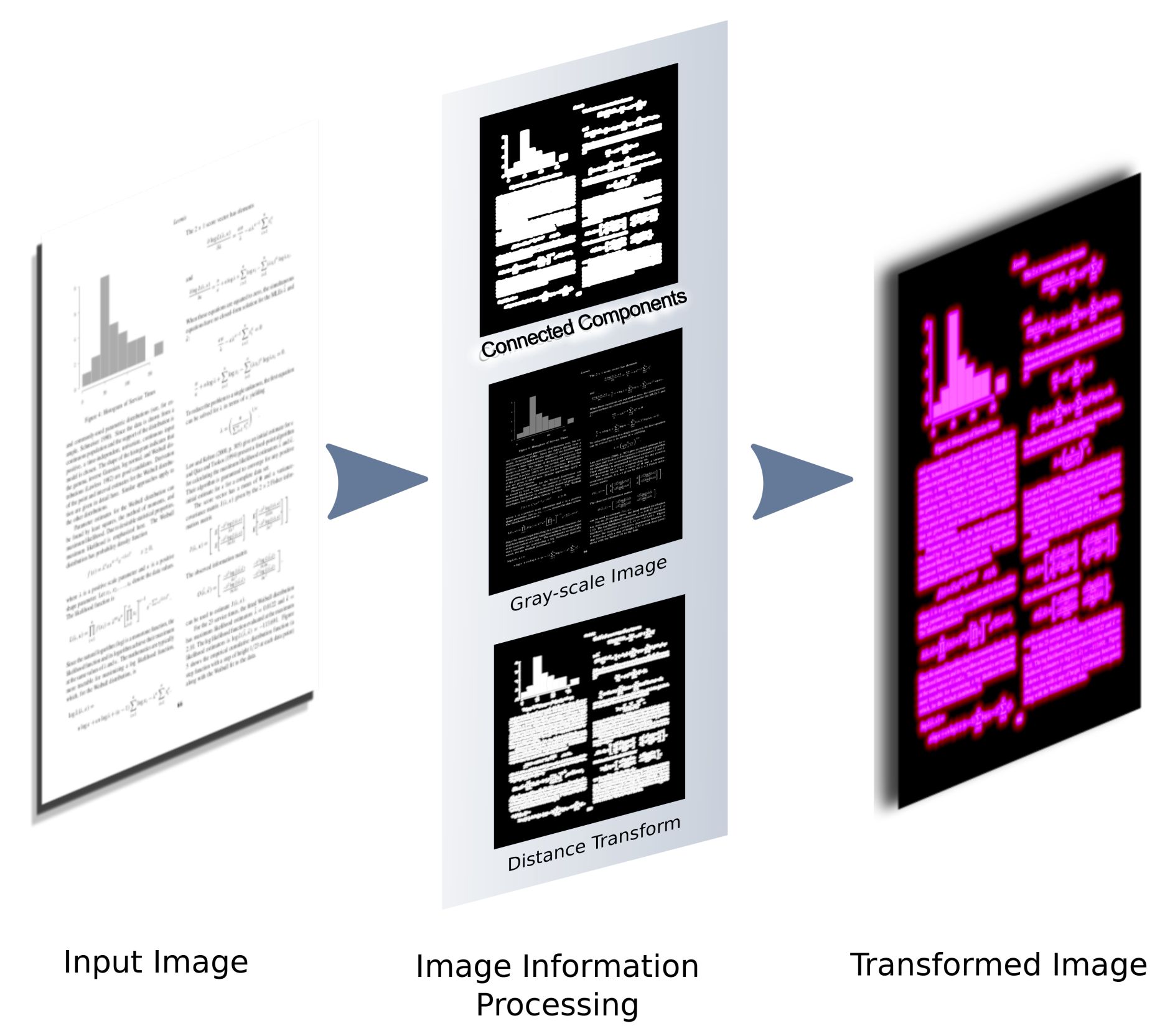
3.2. Fi-Fo Image Representation
3.3. Fi-Fo Architecture
3.4. ResNet-101
3.5. Deformable Convolutional Network (DCN)
3.6. Network Architecture
4. Experimental Results
4.1. Dataset
4.1.1. Faulty Annotations
4.1.2. ICDAR-2017 POD (Corrected)
4.2. Model Configuration
4.3. Evaluation Protocol
4.4. Results and Discussions
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kieninger, T.; Dengel, A. The T-Recs Table Recognition and Analysis System. In Document Analysis Systems: Theory and Practice; Springer: Berlin/Heidelberg, Germany, 1999; pp. 255–270. [Google Scholar]
- Younas, J.; Afzal, M.Z.; Malik, M.I.; Shafait, F.; Lukowicz, P.; Ahmed, S. D-StaR: A Generic Method for Stamp Segmentation from Document Images. In Proceedings of the 14th International Conference on Document Analysis and Recognition, Kyoto, Japan, 10–15 November 2017; Volume 1, pp. 248–253. [Google Scholar]
- Siddiqui, S.A.; Malik, M.I.; Agne, S.; Dengel, A.; Ahmed, S. DeCNT: Deep Deformable CNN for Table Detection. IEEE Access 2018, 6, 74151–74161. [Google Scholar] [CrossRef]
- Ahmed, S.; Shafait, F.; Liwicki, M.; Dengel, A. A Generic Method for Stamp Segmentation Using Part-Based Features. In Proceedings of the 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 708–712. [Google Scholar]
- Smith, R. An Overview of the Tesseract OCR Engine. In Proceedings of the 9th International Conference on Document Analysis and Recognition, Parana, Brazil, 23–26 September 2007; Volume 2, pp. 629–633. [Google Scholar]
- Breuel, T. The OCRopus Open Source OCR System; International Society for Optics and Photonics: Bellingham, WA, USA, 2008; Volume 6815, p. 68150. [Google Scholar]
- Haralick, R.M.; Phillips, I.T. Recursive X-Y cut using bounding boxes of connected components. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, USA, 14–16 August 1995; Volume 2, pp. 952–955. [Google Scholar] [CrossRef]
- Das, A.K.; Chowdhury, S.P.; Mandal, S.; Chanda, B. Automated Segmentation of Math-Zones from Document Images. In Proceedings of the 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; Volume 3, p. 755. [Google Scholar] [CrossRef]
- Li, X.H.; Yin, F.; Liu, C.L. Page Object Detection from PDF Document Images by Deep Structured Prediction and Supervised Clustering. In Proceedings of the 24th International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; pp. 3627–3632. [Google Scholar]
- Yi, X.; Gao, L.; Liao, Y.; Zhang, X.; Liu, R.; Jiang, Z. CNN Based Page Object Detection in Document Images. In Proceedings of the 14th Internation Conference on Document Analysis and Recognition, Kyoto, Japan, 10–15 November 2017; Volume 1, pp. 230–235. [Google Scholar] [CrossRef]
- Gilani, A.; Qasim, S.R.; Malik, M.I.; Shafait, F. Table Detection Using Deep Learning. In Proceedings of the 14th Internation Conference on Document Analysis and Recognition, Kyoto, Japan, 10–15 November 2017; pp. 771–776. [Google Scholar] [CrossRef]
- Schreiber, S.; Agne, S.; Wolf, I.; Dengel, A.; Ahmed, S. DeepDeSRT: Deep Learning for Detection and Structure Recognition of Tables in Document Images. In Proceedings of the 14th Internation Conference on Document Analysis and Recognition, Kyoto, Japan, 10–15 November 2017; pp. 1162–1167. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Iwatsuki, K.; Sagara, T.; Hara, T.; Aizawa, A. Detecting In-line Mathematical Expressions in Scientific Documents. In Proceedings of the 2017 ACM Symposium on Document Engineering, Valletta, Malta, 4–7 September 2017; pp. 141–144. [Google Scholar] [CrossRef]
- Phong, B.H.; Hoang, T.M.; Le, T. A new method for displayed mathematical expression detection based on FFT and SVM. In Proceedings of the 4th NAFOSTED Conference on Information and Computer Science, Hanoi, Vietnam, 24–25 November 2017; pp. 90–95. [Google Scholar] [CrossRef]
- Kavasidis, I.; Pino, C.; Palazzo, S.; Rundo, F.; Giordano, D.; Messina, P.; Spampinato, C. A Saliency-Based Convolutional Neural Network for Table and Chart Detection in Digitized Documents; Springer: Cham, Switzerland, 2019; pp. 292–302. [Google Scholar]
- Chiu, P.; Chen, F.; Denoue, L. Picture Detection in Document Page Images. In Proceedings of the 10th ACM Symposium on Document Engineering, Manchester, UK, 21–24 September 2010; pp. 211–214. [Google Scholar] [CrossRef]
- Gao, L.; Yi, X.; Liao, Y.; Jiang, Z.; Yan, Z.; Tang, Z. A Deep Learning-Based Formula Detection Method for PDF Documents. In Proceedings of the 14th Internation Conference on Document Analysis and Recognition, Kyoto, Japan, 10–15 November 2017; Volume 1, pp. 553–558. [Google Scholar]
- Gao, L.; Yi, X.; Jiang, Z.; Hao, L.; Tang, Z. ICDAR2017 Competition on Page Object Detection. In Proceedings of the 14th International Conference on Document Analysis and Recognition, Kyoto, Japan, 10–15 November 2017; Volume 1, pp. 1417–1422. [Google Scholar]
- Saha, R.; Mondal, A.; Jawahar, C.V. Graphical Object Detection in Document Images. In Proceedings of the 15th Internation Conference on Document Analysis and Recognition, Sydney, Australia, 22–27 September 2019. [Google Scholar]
- Siegel, N.; Horvitz, Z.; Levin, R.; Divvala, S.; Farhadi, A. FigureSeer: Parsing Result-Figures in Research Papers; Computer Vision—ECCV 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 664–680. [Google Scholar]
- Clark, C.; Divvala, S. PDFFigures 20: Mining Figures from Research Papers. In Proceedings of the JCDL ’16 16th ACM/IEEE-CS on Joint Conference on Digital Libraries, Newark, NJ, USA, 19–23 June 2016; pp. 143–152. [Google Scholar] [CrossRef]
- Siegel, N.; Lourie, N.; Power, R.; Ammar, W. Extracting Scientific Figures with Distantly Supervised Neural Networks. In Proceedings of the JCDL ’18 18th ACM/IEEE on Joint Conference on Digital Libraries, Fort Worth, TX, USA, 3–7 June 2018; pp. 223–232. [Google Scholar] [CrossRef]
- Bukhari, S.; Al Azawi, M.; Shafait, F.; Breuel, T. Document Image Segmentation Using Discriminative Learning over Connected Components. In Proceedings of the 9th International Workshop on Document Analysis Systems, Boston, MA, USA, 9–11 June 2010; pp. 183–190. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets v2: More Deformable, Better Results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Yosinski, J.; Clune, J.; Nguyen, A.M.; Fuchs, T.J.; Lipson, H. Understanding Neural Networks Through Deep Visualization. arXiv 2015, arXiv:1506.06579. [Google Scholar]
- Bau, D.; Zhou, B.; Khosla, A.; Oliva, A.; Torralba, A. Network Dissection: Quantifying Interpretability of Deep Visual Representations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3319–3327. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Advances in Neural Information Processing Systems. arXiv 2015, arXiv:1506.01497. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. Advances in Neural Information Processing Systems 29. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | ICDAR-2017 POD | ICDAR-2017 POD | # of Files |
|---|---|---|---|
| (Corrected) | Modified | ||
| Figure | 2939 | 2912 | 135 |
| Formula | 5427 | 5463 | 156 |
| Table | 1016 | 1053 | 30 |
| ICDAR-2017 POD | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | Class | ||||||||
| Precison | Recall | F1-Score | AP | Precision | Recall | F1-Score | AP | ||
| NLPR-PAL [19] | Formula | 0.901 | 0.929 | 0.915 | 0.839 | 0.888 | 0.916 | 0.902 | 0.816 |
| Figure | 0.920 | 0.933 | 0.927 | 0.849 | 0.892 | 0.904 | 0.898 | 0.805 | |
| Li et al. [9] ICDAR-2017 POD | Formula | 0.93 | 0.953 | 0.942 | 0.878 | 0.921 | 0.944 | 0.932 | 0.863 |
| Figure | 0.948 | 0.940 | 0.944 | 0.896 | 0.921 | 0.913 | 0.917 | 0.85 | |
| Deformable Faster R-CNN | Formula | 0.882 | 0.738 | 0.803 | 0.660 | 0.638 | 0.534 | 0.582 | 0.337 |
| Figure | 0.929 | 0.872 | 0.899 | 0.660 | 0.855 | 0.802 | 0.828 | 0.720 | |
| Deformable R-FCN | Formula | 0.914 | 0.918 | 0.916 | 0.915 | 0.832 | 0.836 | 0.834 | 0.826 |
| Figure | 0.904 | 0.920 | 0.912 | 0.903 | 0.86 | 0.875 | 0.867 | 0.864 | |
| Fi-Fo Detector | Formula | 0.909 | 0.927 | 0.918 | 0.911 | 0.856 | 0.878 | 0.867 | 0.854 |
| Figure | 0.918 | 0.883 | 0.90 | 0.894 | 0.871 | 0.838 | 0.854 | 0.861 | |
| Trained: ICDAR-2017 POD, Tested: ICDAR-2017 POD (Corrected) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | Class | ||||||||
| Precison | Recall | F1-score | AP | Precision | Recall | F1-Score | AP | ||
| Li et al. [9] | Formula | 0.935 | 0.331 | 0.489 | 0.312 | 0.877 | 0.310 | 0.459 | 0.274 |
| Figure | 0.918 | 0.292 | 0.443 | 0.271 | 0.888 | 0.283 | 0.429 | 0.253 | |
| Fi-Fo Detector | Formula | 0.949 | 0.945 | 0.947 | 0.967 | 0.897 | 0.893 | 0.895 | 0.941 |
| Figure | 0.930 | 0.932 | 0.931 | 0.97 | 0.899 | 0.900 | 0.899 | 0.952 | |
| ICDAR-2017 POD | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | Image Representation | Class | ||||||||
| Precison | Recall | F1-Score | AP | Precision | Recall | F1-Score | AP | |||
| Fi-Fo Detector Deformable | Raw | Formula | 0.867 | 0.918 | 0.892 | 0.893 | 0.780 | 0.826 | 0.802 | 0.780 |
| Figure | 0.860 | 0.869 | 0.864 | 0.847 | 0.818 | 0.827 | 0.822 | 0.799 | ||
| Fi-Fo Detector Non Deformable | Fi-Fo | Formula | 0.867 | 0.874 | 0.871 | 0.917 | 0.712 | 0.694 | 0.703 | 0.837 |
| Figure | 0.856 | 0.821 | 0.838 | 0.929 | 0.801 | 0.739 | 0.769 | 0.889 | ||
| Fi-Fo Detector Deformable | Fi-Fo | Formula | 0.909 | 0.927 | 0.918 | 0.911 | 0.856 | 0.878 | 0.867 | 0.854 |
| Figure | 0.918 | 0.883 | 0.90 | 0.894 | 0.871 | 0.838 | 0.854 | 0.861 | ||
| ICDAR-2017 POD (Corrected) | ||||||||||
| Fi-Fo Detector Deformable | Raw | Formula | 0.949 | 0.945 | 0.947 | 0.973 | 0.897 | 0.893 | 0.895 | 0.967 |
| Figure | 0.930 | 0.932 | 0.931 | 0.971 | 0.897 | 0.90 | 0.899 | 0.959 | ||
| Fi-Fo Detector Non Deformable | Fi-Fo | Formula | 0.910 | 0.927 | 0.918 | 0.953 | 0.860 | 0.877 | 0.868 | 0.928 |
| Figure | 0.879 | 0.822 | 0.850 | 0.948 | 0.847 | 0.792 | 0.819 | 0.958 | ||
| Fi-Fo Detector Deformable | Fi-Fo | Formula | 0.957 | 0.952 | 0.954 | 0.949 | 0.913 | 0.908 | 0.910 | 0.898 |
| Figure | 0.931 | 0.913 | 0.922 | 0.905 | 0.901 | 0.885 | 0.893 | 0.870 | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Younas, J.; Siddiqui, S.A.; Munir, M.; Malik, M.I.; Shafait, F.; Lukowicz, P.; Ahmed, S. Fi-Fo Detector: Figure and Formula Detection Using Deformable Networks. Appl. Sci. 2020, 10, 6460. https://doi.org/10.3390/app10186460
Younas J, Siddiqui SA, Munir M, Malik MI, Shafait F, Lukowicz P, Ahmed S. Fi-Fo Detector: Figure and Formula Detection Using Deformable Networks. Applied Sciences. 2020; 10(18):6460. https://doi.org/10.3390/app10186460
Chicago/Turabian StyleYounas, Junaid, Shoaib Ahmed Siddiqui, Mohsin Munir, Muhammad Imran Malik, Faisal Shafait, Paul Lukowicz, and Sheraz Ahmed. 2020. "Fi-Fo Detector: Figure and Formula Detection Using Deformable Networks" Applied Sciences 10, no. 18: 6460. https://doi.org/10.3390/app10186460
APA StyleYounas, J., Siddiqui, S. A., Munir, M., Malik, M. I., Shafait, F., Lukowicz, P., & Ahmed, S. (2020). Fi-Fo Detector: Figure and Formula Detection Using Deformable Networks. Applied Sciences, 10(18), 6460. https://doi.org/10.3390/app10186460