Unsupervised Predominant Sense Detection and Its Application to Text Classification


Abstract
:1. Introduction
2. Related Work
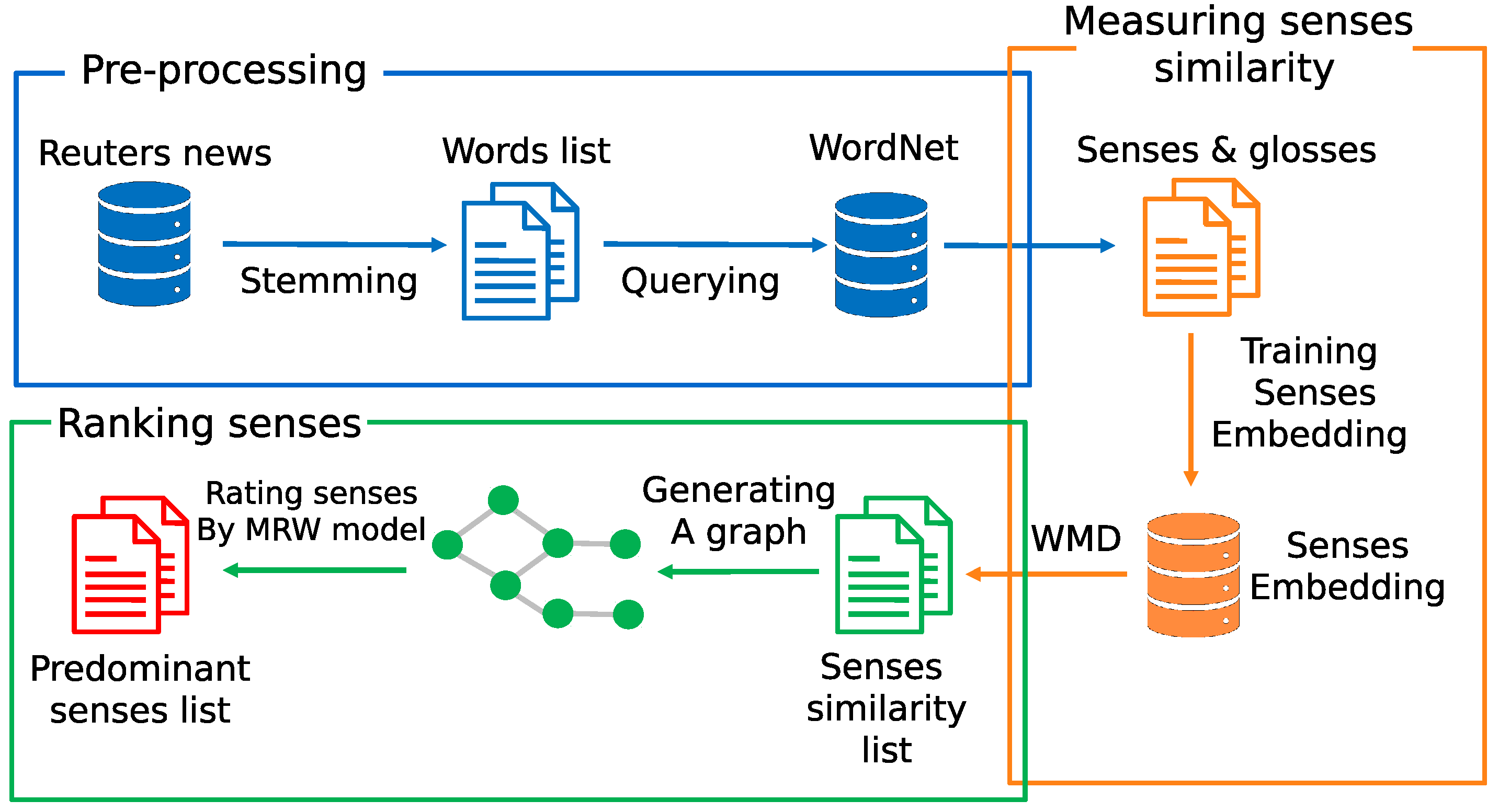
3. Acquisition of Domain-Specific Senses
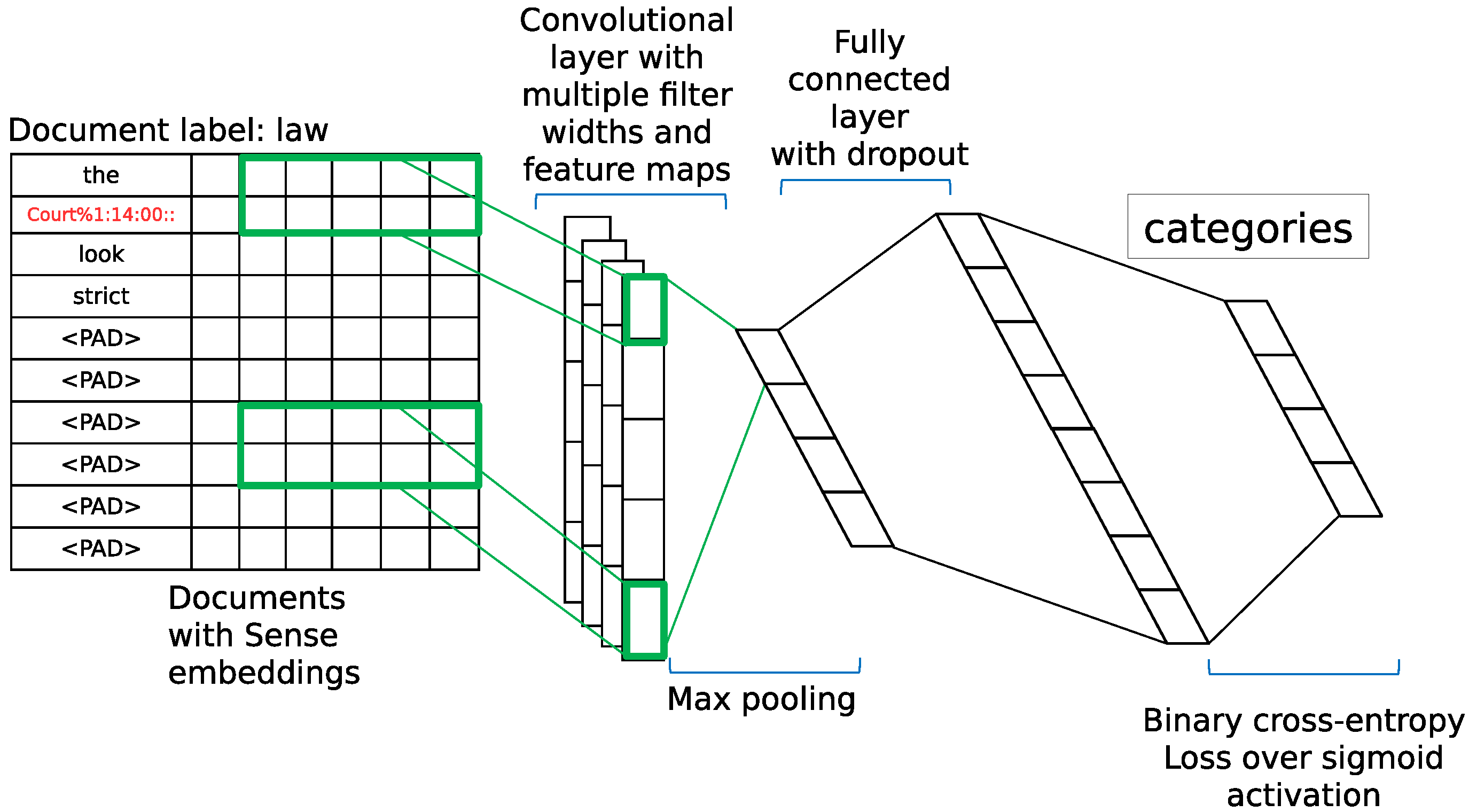
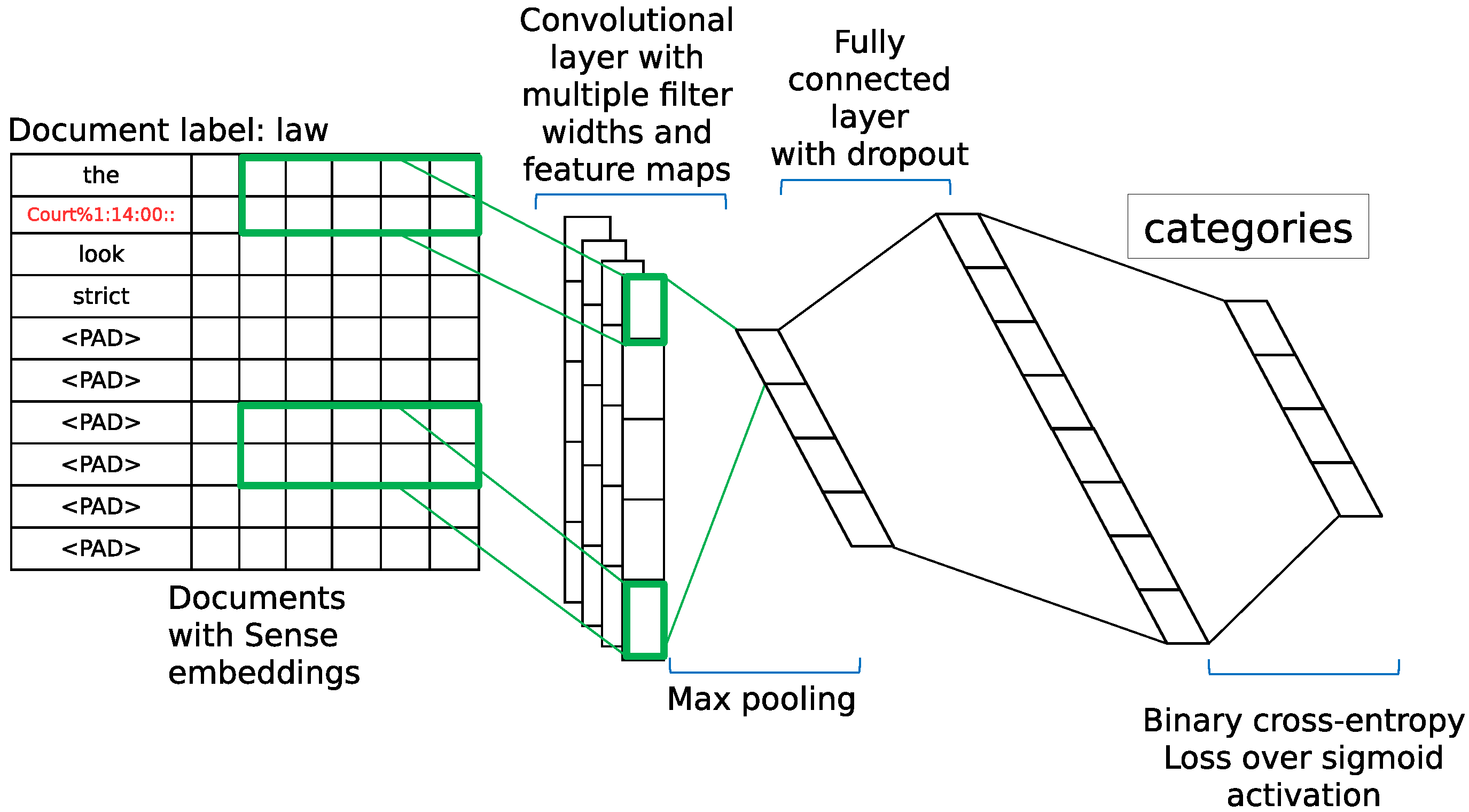
4. Application to Text Classification
5. Experiments
5.1. Acquisition of Domain-Specific Senses
5.2. Qualitative Analysis of Errors
- 1.
- The Semantic similarity measure with WMD
- 2.
- The number of domains per word
- 3.
- The closeness sense of the domains
5.3. Text Classification
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- McCarthy, D.; Koeling, R.; Weeds, J.; Carroll, J. Unsupervised Acquisition of Predominant Word Senses. Comput. Linguist. 2007, 33, 553–590. [Google Scholar] [CrossRef]
- Koeling, R.; McCarthy, D.; Carroll, J. Domain-Specific Sense Distributions and Predominant Sense Acquisition. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2015; pp. 419–426. [Google Scholar]
- Snyder, B.; Palmer, M. The English All-Words Task. In Proceedings of the SENSEVAL-3, 3rd International Workshop on the Evaluation of Systems for the Semantic Analysis of Text, Barcelona, Spain, 25–26 July 2004; pp. 41–43. [Google Scholar]
- Yarowsky, D.; Florian, R. Evaluating Sense Disambiguation Performance Across Diverse Parameter Spaces. Nat. Lang. Eng. 2002, 8, 293–310. [Google Scholar] [CrossRef]
- Miller, G.A. WordNet: A Lexical Database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Melamud, O.; Goldberger, J.; Dagan, I. context2vec: Learning Generic Context Embedding with Bidirectional LSTM. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; pp. 51–61. [Google Scholar]
- Magnini, B.; Cavaglia, G. Integrating Subject Field Codes into WordNet. In Proceedings of the Second International Conference on Language and Evaluation (LREC’00), Athens, Greece, 30 May 2000; pp. 1413–1418. [Google Scholar]
- Magnini, B.; Strapparava, C.; Pezzulo, G.; Gliozzo, A. The Role of Domain Information in Word Sense Disambiguation. Nat. Lang. Eng. 2002, 8, 359–373. [Google Scholar] [CrossRef]
- Banerjee, S.; Pedersen, T. An adapted Lesk algorithm for word sense disambiguation using WordNet. In Proceedings of the 3rd International Conference on Computational Linguistics and Intelligent Text Processing, Mexico City, Mexico, 17–23 February 2002; pp. 136–145. [Google Scholar]
- Chaplot, D.; Bhattacharyya, P.; Paranjape, A. Unsupervised word sense disambiguation using Markov Random Field and dependency parser. In Proceedings of the 29th AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2217–2223. [Google Scholar]
- Lesk, M. Automatic sense disambiguation using machine readable dictionary: How to tell a pine cone from an ice cream cone. In Proceedings of the 5th annual international conference on Systems documentation, Toronto, ON, Canada, 8–11 June 1986; pp. 24–26. [Google Scholar]
- Mihalcea, R. Co-training and self-training for Word Sense Disambiguation. In Proceedings of the 8th Conference on Computational Natural Language Learning (CoNLL-2004) at HLT-NAACL 2004, Boston, MA, USA, 6–7 May 2004; pp. 33–40. [Google Scholar]
- Niu, C.; Wei, L.; Rohini, R.K.; Huifeng, L.; Laurie, C. Context clustering for word sense disambiguation based on modeling pairwise context similarities. In Proceedings of the SENSEVAL-3, 3rd International Workshop on the Evaluation of Systems for the Semantic Analysis of Text, Barcelona, Spain, 25–26 July 2004; pp. 187–190. [Google Scholar]
- Pedersen, T. A Decision Tree of Bigrams is and Accurate Predictor of Word Sense. arXiv 2001, arXiv:cs/0103026. [Google Scholar]
- Wang, T.; Rao, J.; Hu, Q. Supervised word sense disambiguation using semantic diffusion kernel. Eng. Appl. Artif. Intell. 2014, 27, 167–174. [Google Scholar] [CrossRef]
- Agirre, E.; Lacalle, O.L.D.; Soroa, A. Knowledge-based WSD on Specific Domains: Performing better than Generic Supervised WSD. In Proceedings of the 21st International Joint Conference on Artificial Intelligence, IJCAI-09, Pasadena, CA, USA, 11–17 July 2009; pp. 1501–1506. [Google Scholar]
- Faralli, S.; Navigli, R. A New Minimally-Supervised Framework for Domain Word Sense Disambiguation. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, 12–14 July 2012; pp. 1411–1422. [Google Scholar]
- Taghipour, K.; Ng, H.T. Semi-Supervised Word Sense Disambiguation Using Word Embeddings in General and Specific Domains. In Proceedings of the 2015 Conference of the North America Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; pp. 314–323. [Google Scholar]
- Abualhaija, S.; Tahmasebi, N.; Forin, D.; Zimmermann, K. Parameter Transfer across Domains for Word Sense Disambiguation. In Proceedings of the International Conference Recent Advances in Natural Language Processing, RANLP 2017, Varna, Bulgaria, 4–6 September 2017; pp. 1–8. [Google Scholar]
- Lopez-Arevalo, I.; Sosa-Sosa, V.J.; Rojas-Lopez, F.; Tello-Leal, E. Improving Selection of Synsets from WordNet for Domain-specific Word Sense Disambiguation. Comput. Speech Lang. 2017, 41, 128–145. [Google Scholar] [CrossRef]
- McCarthy, D.; Koeling, R.; Weeds, J.; Carroll, J. Finding Predominant Word Senses in Untagged Text. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL-04), Barcelona, Spain, 21–26 July 2004; pp. 279–286. [Google Scholar]
- Rose, T.; Stevenson, M.; Whitehead, M. The Reuters Corpus Volume 1 - from Yesterday’s News to Tomorrow’s Language Resources. In Proceedings of the 3rd International Conference on Language Resources and Evaluation (LREC’02), Las Palmas, Spain, 29–31 May 2002; pp. 29–31. [Google Scholar]
- Fukumoto, F.; Suzuki, Y. Identifying Domain-specific Senses and Its Application to Text Classification. In Proceedings of the International Conference on Knowledge Engineering and Ontology Development, Valencia, Spain, 25–26 October 2010; pp. 263–268. [Google Scholar]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by Latent Semantic Analysis. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed Representations of Sentences and Documents. arXiv 2014, arXiv:1405.4053. [Google Scholar]
- Kiros, R.; Zhu, Y.; Salakhutdinov, R.; Zemel, R.S.; Torralba, A.; Urtasun, R.; Fidler, S. Skip-thought vectors. arXiv 2015, arXiv:1506.06726. [Google Scholar]
- Pagliardini, M.; Gupta, P.; Jaggi, M. Unsupervised Learning of Sentence Embeddings Using Compositional n-Gram Features. In Proceedings of the NAACL-HLT, New Orleans, LA, USA, 1–6 June 2018; pp. 528–540. [Google Scholar]
- Rubner, Y.; Tomasi, C.; Guibas, L.J. The Earth Mover’s Distance As a Metric for Image Retrieval. Int. J. Comput. Vis. 2000, 2, 99–121. [Google Scholar] [CrossRef]
- Wan, X. A Novel Document Similarity Measure Based on Earth Mover’s Distance. Inf. Sci. 2007, 177, 3718–3730. [Google Scholar] [CrossRef]
- Kusner, M.J.; Sun, Y.; Kolkin, N.L.; Weinberger, K.Q. From Word Embeddings to Document Distances. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 957–966. [Google Scholar]
- Ramage, D.; Rafferty, A.N. Random Walks for Text Semantic Similarity. In Proceedings of the 2009 Workshop on Graph-based Methods for Natural Language Processing (TextGraphs-4), Suntec, Singapore, 7 August 2009; pp. 23–31. [Google Scholar]
- Mihalcea, R. Language Independent Extractive Summarization. In Proceedings of the ACL Interactive Poster and Demonstration Sessions, Ann Arbor, MI, USA, 25–30 June 2005; pp. 49–52. [Google Scholar]
- Sinha, R.; Mihalcea, R. Unsupervised Graph based Word Sense Disambiguation using Measures of Word Semantic Similarity. In Proceedings of the International Conference on Semantic Computing, Irvine, CA, USA, 17–19 September 2007; pp. 363–369. [Google Scholar]
- Agirre, E.; Soroa, A. Personalizing Pagerank for Word Sense Disambiguation. In Proceeding of the 12th Conference of the European Chapter of the Association for Computational Linguistics, EACL’09; Association for Computational Linguistics: Athens, Greece, 2009; pp. 33–41. [Google Scholar]
- Reddy, S.; Inumella, A.; McCarthy, D.; Stevenson, M. IIITH: Domain Specific Word Sense Disambiguation. In Proceedings of the 5th International Workshop on Semantic Evaluation, Uppsala, Sweden, 15–16 July 2010; pp. 387–391. [Google Scholar]
- Dongsuk, O.; Sunjae, K.; Kyungsun, K.; Youngjoong, K. Word Sense Disambiguation Based on Word Similarity Calculation Using Word Vector Representation from a Knowledge-based Graph. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 2704–2714. [Google Scholar]
- Kutuzov, A.; Panchenko, A.; Kohail, S.; Dorgham, M.; Oliynyk, O.; Biemann, C. Learning Graph Embeddings from WordNet-based Similarity Measures. arXiv 2018, arXiv:1808.05611. [Google Scholar]
- Perozzi, B.; AI-Rfou, R.; Skiena, S. DeepWalk: Online Learning of Social Representations. arXiv 2014, arXiv:1403.6652. [Google Scholar]
- Ghosh, S.; Vinyals, O.; Strope, B.; Roy, S.; Dean, T.; Heck, L.P. Contextual LSTM(CLSTM) models for large scale NLP tasks. arXiv 2016, arXiv:1602.06291. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Kågebäck, M.; Salomonsson, H. Word Sense Disambiguation using a Bidirectional LSTM. In Proceedings of the 5th Workshop on Cognitive Aspects of the Lexicon (CogALex-V), Osaka, Japan, 12 December 2016; pp. 51–56. [Google Scholar]
- Yao, Y.; Huang, Z. Bi-directional LSTM recurrent neural network for Chinese word segmentation. arXiv 2016, arXiv:1602.04874. [Google Scholar]
- Wang, Y.; Xia, Y.; Zhao, L.; Bian, J.; Qin, T.; Liu, G.; Liu, T.-Y. Dual Transfer Learning for Neural Machine Translation with Marginal Distribution Regularization. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489.
- Johnson, R.; Zhang, T. Semi-Supervised Convolutional Neural Networks for Text Categorization via Region Embedding. arXiv 2015, arXiv:1504.01255. [Google Scholar]
- Wu, F.; Zhang, T.; Souza, A., Jr.; Fifty, C.; Yu, T.; Weinberger, Q. Simplifying Graph Convolutional Networks. arXiv 2019, arXiv:1902.07153. [Google Scholar]
- Abreu, J.; Fred, L.; Macêdo, D.; Zanchettin, C. Hierarchical Attentional Hybrid Neural Networks for Document Classification. arXiv 2019, arXiv:1901.06610. [Google Scholar]
- Zhang, R.; Lee, H.; Radev, D.R. Dependency Sensitive Convolutional Neural Networks for Modeling Sentences and Documents. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1512–1521. [Google Scholar]
- Luz de Araujo, P.H.; Campos, T.E.; Braz, F.A.; Silva, N.C. VICTOR: A dataset for Brazilian legal documents classification. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 1449–1458. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Zhang, Y.; Wallace, B.C. A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification. arXiv 2015, arXiv:1510.03820. [Google Scholar]
- Johnson, R.; Zhang, T. Effective Use of Word Order for Text Categorization with Convolutional Neural Networks. arXiv 2014, arXiv:1412.1058. [Google Scholar]
- Liu, J.; Chang, W.-C.; Wu, Y.; Yang, Y. Deep Learning for Extreme Multi-Label Text Classification. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 115–124. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics; Association for Computational Linguistics: Valencia, Spain, 2017; pp. 427–431. [Google Scholar]
- Nooralahzadeh, F.; Øvrelid, L.; Lønning, J.T. Evaluation of Domain-specific Word Embeddings using Knowledge Resources. In Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Wang, J.; Wang, Z.; Zhang, D.; Yan, J. Combining Knowledge with Deep Convolutional Neural Networks for Short Text Classification. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 2915–2921. [Google Scholar]
- Kim, Y.; Jernite, Y.; Sontag, D.; Rush, A.M. Character-aware neural language models. arXiv 2015, arXiv:1508.06615. [Google Scholar]
- Walker, D.E.; Amsler, R.A. The use of machine-readable dictionaries in sublanguage analysis. Analyzing Language in Restricted Domains. In Analyzing Language in Restricted Domains; Grishman, R., Kittredge, R., Eds.; Lawrence Erlbaum: Hillsdale, NJ, USA, 1986. [Google Scholar]
- Gale, W.A.; Church, K.W.; Yarowsky, D. One Sense Per Discourse. In Proceedings of the workshop on Speech and Natural Language, New York, NY, USA, 23–26 February 1992; pp. 233–237. [Google Scholar]
- Cristani, M.; Bertolaso, A.; Scannapieco, S.; Tomazzoli, C. Future paradigms of automated processing of business documents. Int. J. Inf. Manag. Sci. 2018, 40, 67–75. [Google Scholar] [CrossRef]
- Brin, S.; Page, L. The Anatomy of a Large-scale Hypertextual Web Search Engine. Comput. Netw. ISDN Syst. 1998, 30, 107–117. [Google Scholar] [CrossRef]
- Netlib, Netlib Repository at UTK and ORNL. 2007. Available online: http://www.netlib.org/scalapack (accessed on 1 July 2020).
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving Neural Networks by Preventing Co-Adaptation of Feature Detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; pp. 55–60. [Google Scholar]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. arXiv 2019, arXiv:1907.10902. [Google Scholar]
- Shimura, K.; Li, J.; Fukumoto, F. HFT-CNN: Learning Hierarchical Category Structure for Multi-label Short Text Categorization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 811–816. [Google Scholar]
- Wu, W.; Li, H.; Wang, H.; Zhu, K.Q. A Probabilistic Taxonomy for Text Understanding. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data, Scottsdale, AZ, USA, 20–24 May 2012; pp. 481–492. [Google Scholar]
- Pele, O.; Werman, M. Fast and Robust Earth Mover’s Distances. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 460–467. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| SFC | Reuters | # doc | # min | # max |
|---|---|---|---|---|
| Law | Legal | 11,944 | 140 | 18,781 |
| Finance | Funding | 41,829 | 151 | 63,973 |
| Industry | Production | 25,403 | 197 | 21,957 |
| Publishing | Advertising | 2084 | 27 | 5821 |
| Admin. | Management | 11,354 | 56 | 18,587 |
| Economy | Economics | 117,539 | 1139 | 99,197 |
| Art | Arts | 3801 | 67 | 4562 |
| Fashion | Fashion | 313 | 7 | 775 |
| Politics | Politics | 56,878 | 967 | 94,970 |
| Religion | Religion | 2,849 | 54 | 3746 |
| Sports | Sports | 35,317 | 222 | 26,898 |
| Tourism | Travel | 680 | 8 | 1423 |
| Military | War | 32,615 | 546 | 45,085 |
| Meteorology | Weather | 3878 | 17 | 4602 |
| Category | Sense | DSS | SFC | Correct | F-Score | IRS | P_IRS |
|---|---|---|---|---|---|---|---|
| Law | 577 | 57 | 57 | 41 | 0.719 | 3.607 | 4.628 |
| Finance | 53 | 5 | 5 | 5 | 1.000 | 2.283 | 2.283 |
| Industry | 195 | 19 | 19 | 18 | 0.947 | 3.489 | 3.548 |
| Publishing | 178 | 17 | 17 | 15 | 0.882 | 3.262 | 3.439 |
| Admin. | 302 | 30 | 30 | 16 | 0.533 | 3.192 | 3.994 |
| Economy | 531 | 53 | 53 | 34 | 0.642 | 3.981 | 4.555 |
| Art | 236 | 23 | 23 | 14 | 0.609 | 3.634 | 3.734 |
| Fashion | 289 | 28 | 28 | 23 | 0.821 | 3.703 | 3.927 |
| Politics | 522 | 52 | 52 | 24 | 0.462 | 3.348 | 4.536 |
| Religion | 501 | 50 | 50 | 38 | 0.760 | 3.129 | 4.497 |
| Sports | 306 | 30 | 30 | 19 | 0.633 | 3.382 | 3.994 |
| Tourism | 176 | 17 | 17 | 14 | 0.824 | 3.071 | 3.439 |
| Military | 528 | 52 | 52 | 37 | 0.712 | 4.037 | 4.536 |
| Meteorology | 94 | 9 | 9 | 8 | 0.889 | 2.718 | 2.829 |
| Average | 321 | 31.571 | 31.571 | 21.86 | 0.745 | 3.345 | 3.853 |
| Category | Word | Sense |
|---|---|---|
| Law | Administration | The act of meting out justice according to the law. |
| Economy | Spending | Money paid out; an amount spent. |
| Politics | Labour party | A political party formed in Great Britain in 1900; characterized by the promotion of labor’s interests and formerly the socialization of key industries. |
| Sports | Jerk | Raising a weight from shoulder height to above the head by straightening the arms. |
| Military | Redoubt | (Military) A temporary or supplementary fortification; typically square or polygonal without flanking defenses. |
| Description | Values | Description | Values |
|---|---|---|---|
| Input size | Maximum length of text × 100 | A number of output categories | 14 |
| Input word vectors | Word2Vec | Filter region size | (4,5,6) |
| Stride size | 1 | Feature maps (m) | 32 |
| Filters | 32 × 3 | Activation function | ReLu |
| Pooling | 1-max pooling | Dropout | Randomly selected |
| Dropout rate1 | 0.25 | Dropout rate2 | 0.5 |
| Hidden layers | 2048 | Batch sizes | 128 |
| Learning rate | Predicted by Adam | Epoch | 40 with early stopping |
| Loss function | BCE loss | Threshold value | |
| over sigmoid activation | for MSF | 0.5 |
| Category | CNN | WSD | DSS | SFC |
|---|---|---|---|---|
| Law | 0.846 | 0.853(+0.007) | 0.899(+0.046) | 0.908(+0.009) |
| Finance | 0.904 | 0.906(+0.002) | 0.939(+0.033) | 0.923(−0.016) |
| Industry | 0.798 | 0.796(−0.002) | 0.893(+0.097) | 0.873(−0.020) |
| Publishing | 0.738 | 0.736(−0.002) | 0.753(+0.017) | 0.739(−0.014) |
| Admin. | 0.875 | 0.875(0.000) | 0.918(+0.043) | 0.933(+0.015) |
| Economy | 0.924 | 0.930(+0.006) | 0.968(+0.038) | 0.972(+0.004) |
| Art | 0.734 | 0.741(+0.007) | 0.753(+0.012) | 0.817(+0.064) |
| Fashion | 0.608 | 0.609(+0.001) | 0.628(+0.019) | 0.775(+0.147) |
| Politics | 0.817 | 0.813(−0.004) | 0.900(+0.087) | 0.964(+0.064) |
| Religion | 0.710 | 0.639(−0.071) | 0.855(+0.216) | 0.804(-0.051) |
| Sports | 0.987 | 0.987(0.000) | 0.993(+0.006) | 0.995(+0.002) |
| Tourism | 0.342 | 0.298(−0.044) | 0.348(+0.050) | 0.469(+0.121) |
| Military | 0.873 | 0.873(0.000) | 0.917(+0.044) | 0.943(+0.026) |
| Meteorology | 0.853 | 0.848(−0.005) | 0.875(+0.027) | 0.863(−0.012) |
| Micro F-score | 0.887 | 0.889(+0.002) | 0.937(+0.048) | 0.948(+0.011) |
| Macro F-score | 0.786 | 0.779(−0.007) | 0.832(+0.053) | 0.855(+0.023) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wangpoonsarp, A.; Shimura, K.; Fukumoto, F. Unsupervised Predominant Sense Detection and Its Application to Text Classification. Appl. Sci. 2020, 10, 6052. https://doi.org/10.3390/app10176052
Wangpoonsarp A, Shimura K, Fukumoto F. Unsupervised Predominant Sense Detection and Its Application to Text Classification. Applied Sciences. 2020; 10(17):6052. https://doi.org/10.3390/app10176052
Chicago/Turabian StyleWangpoonsarp, Attaporn, Kazuya Shimura, and Fumiyo Fukumoto. 2020. "Unsupervised Predominant Sense Detection and Its Application to Text Classification" Applied Sciences 10, no. 17: 6052. https://doi.org/10.3390/app10176052
APA StyleWangpoonsarp, A., Shimura, K., & Fukumoto, F. (2020). Unsupervised Predominant Sense Detection and Its Application to Text Classification. Applied Sciences, 10(17), 6052. https://doi.org/10.3390/app10176052