1. Introduction
Nowadays, one of the most popular and common communication services is the short message service, known as SMS. SMS traffic volumes have risen from 1.46 billion in 2000 to 7.9 trillion in 2012 [
1]. SMS-capable mobile phone users had reached 6.1 billion users by the year 2015 [
2]. The growth of mobile users has generated a great deal of revenue [
1]. Based on the latest statistics [
3], global SMS revenue is predicted to hit 83.2 billion dollars in 2022 even though the revenue has continued to decrease after 2017. In addition, about half (43 billion dollars) of the global SMS revenue belongs to the global P2P (person-to-person) SMS messages market and the other half (40.2 billion dollars) belongs to A2P (application-to-person). A2P messages are sent by companies, such as bulksmsonline.com and bulksms.com, who provide bulk SMS sending services for commercial needs, e.g., verification codes, e-commercial notifications, express delivery notifications.
While enjoying the convenience of communication via electronic devices, unexpected advertising or even malicious information has flooded our email and phone message boxes. This spam information is usually unwanted or unsolicited electronic messages sent in bulk to a group of recipients [
4]. It is being sent by spammers or even criminals who are driven by these most profitable spamming businesses. Spam first spread explosively but mainly in emails in the first decade of the 21th century, indicated by the statistical results provided in [
5]. As SMS is low-cost, bulk-sending, and reliably reaches the receiver, spam began moving to this most popular and globally used SMS service. The companies hosting the bulk SMS sending service have to continuously improve their spam filtering technology to combat against spam SMS. However, it is a challenging task as SMS contains limited words including abbreviations, etc. In addition, SMS spammers tend to use legitimate words to increase its rank in spam filters and use obfuscated words to confuse the spam filters.
Antispam techniques have been developed for decades. Many methods for antispam emails have been applied in the antispam SMS field. Traditional machine learning methods for spam detection including naïve Bayes (NB) [
6,
7], vector space model (VSM) [
8], and support vector machine (SVM) [
9], and novel methods such as long short-term memory (LSTM) [
10] and the convolutional neural network (CNN) [
11] all stand on the well-known bag of words (BoW) model, which assumes documents are an unordered collection of words. Based on this assumption, word or term occurrences are the only concern but the order of words in the document is ignored. Based on the BoW assumption, many feature extraction algorithms [
12,
13,
14] were invented to make use of term frequency, such as TF.IDF (stands for term frequency and inversed document frequency) and word distribution. However, these algorithms do not work well in SMS spam detection, because of the strict length limitation of SMS. Most of the terms (words) occur only once in a single SMS. Human language is actually sequential data. Word order is critical information for SMS spam detection.
Motivated to address the aforementioned issues, we propose a new method based on the discrete hidden Markov model (HMM) for spam SMS detection in this paper. An HMM is a statistical model with two stochastic processes [
15]. The underlying stochastic process that has the Markov property is a sequence of hidden states, and the observable stochastic process is a sequence of observation states that reflect the hidden states through some probabilistic distribution. HMMs are a formal foundation for building probabilistic models of linear sequence labeling problems [
16]. In this paper, the SMS messages are preprocessed by removing the recommended stop words (e.g.,
#>,
<,
\\,
&,
that,
shall,
is) and punctuation to form the observation sequence with original word order. The HMM is trained by the labeled observation sequence. Then, the SMS classification is a typical decoding problem in HMM by using the Viterbi algorithm. To the best of our knowledge, this is the first research on applying HMM for SMS spam detection based on word order.
The main contributions of this research are threefold:
We first propose to use a hidden Markov model for spam SMS detection based on word order. This method uses the word order information that consists of the key importance for human language, but it has been ignored by many traditional methods based on the BoW model.
This research solves the issue where the TF.IDF algorithm for word weighting does not work well in SMS spam detection, due to the extremely low term frequency.
The proposed method can be applied to alphabetic text (e.g., English) and hieroglyphic text (e.g., Chinese). It is not language-sensitive.
The rest of the paper is organized as follows. Related work is discussed in
Section 2. The problem formulation and the proposed SMS spam detection method based on the discrete HMM are presented in
Section 3. The experimental results and performance comparisons with well-known models are outlined in
Section 4. The conclusions are drawn and future work is discussed in
Section 5.
3. The Discrete HMM for SMS Spam Detection
3.1. Problem Formulation and Notations
A typical SMS contains sequential words with punctuation. In English, as words are divided by blank spaces, English SMS is easy to be split, whereas in some other languages, e.g., Chinese, there are no blank spaces between words. These SMS messages have to first feed into a segmentation algorithm to extract words. In any case, each SMS text is first split or segmented into sequential words with punctuation at the very beginning.
Not all words are suitable for NLP. Punctuation and words only for positioning do not have much semantic information. Especially for SMS, many informal words, shortened and abbreviated words, social media acronyms, and some strange character sequences often appear in SMS. Part of them is also meaningless. They are called the stop words. Therefore, these stop words and punctuation are removed from the sequential words.
After these preprocesses, each SMS is refined to a word sequence, which is full of meaningful words. Let
denote the total number of all rest meaningful words in SMS including the duplicated ones. This set with
N sequential words is the observation sequence denoted as
. The corresponding hidden state sequence is denoted as
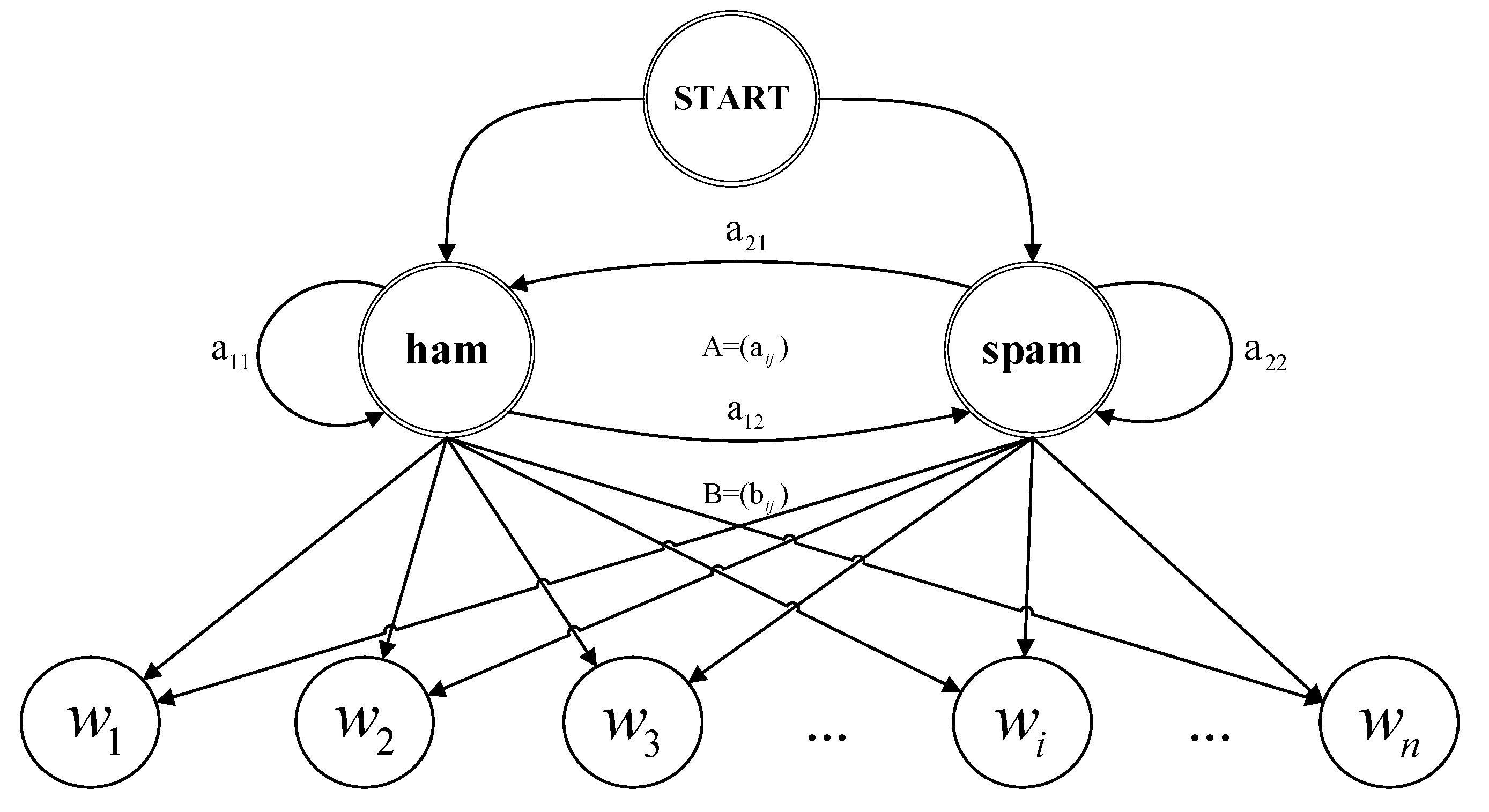
, satisfying the Markov property. The structure of these two sequences is represented by the directed graph in
Figure 1.
The HMM, denoted by
λ, can be defined by a three-tuple:
where
is the initial probability distribution,
A is the state transition probability matrix, and
B is the observation probability distribution matrix.
For SMS spam detection, the set of hidden states is . Thus, , where , for and , for .
Let denote the set of observation states, which includes all different words in every spam and ham SMS. is the total number of different words in both sets. Thus, , where , for .
is a 2 × 1 initial probability distribution over the state, , , and .
The proposed hidden Markov model for spam detection is shown in
Figure 2.
3.2. Observation States and Observation Sequence
The SMS can be represented as the rest meaningful sequential words in the set of observation states : , (). is the total number of SMS. is one of the meaningful words in the SMS.
For example, take the following two SMS messages from the UCI repository dataset, which can be downloaded from
http://www.dt.fee.unicamp.br/~tiago/smsspamcollection. The same dataset has been used in [
2,
4,
8,
9,
10,
11,
13,
21,
23,
25,
31,
46,
52,
53,
54,
55,
56,
57] for performance evaluations.
ham: What you thinked about me. First time you saw me in class.
Please note that the example dataset only contains 2 SMS messages and words you and me are duplicated in the two SMS messages.
The two SMS messages can be segmented as word and punctuation sequences with the original order: [What, you, thinked, about, me, ., First, time, you, saw, me, in, class, .] and [Are, you, unique, enough, ?, Find, out, from, 30th, August, ., www, ., areyouunique, ., co, ., uk]. After removing stop words and punctuation, the word sequences also keep its order and become refined ones: [What, you, thought, me, First, time, you, saw, me, class] and [Are, you, unique, enough, Find, 30th, August, www, areyouunique, co, uk].
Then, the observation states set is generated, i.e., = {What, you, thought, me, First, time, saw, class, Are, unique, enough, Find, 30th, August, www, areyouunique, co, uk}. Each word in appears in ham and spam SMS sets with a certain frequency. These occurrence frequencies will be used to obtain the observation probability distribution.
In addition, the refined two-word sequences combine together to form the observation sequence . In this example, = {What, you, thinked, me, First, time, you, saw, me, class, Are, you, unique, enough, Find, 30th, August, www, areyouunique, co, uk}. It is obvious that the original word order is kept.
Therefore, the observation sequence
can be represented as
Please note that different SMSs may have different lengths. All sequential words in each SMS combine together to form the final observation sequence .
3.3. Label Each Word in Observation Sequence for HMM Learning
Among these training SMS from the UCI repository dataset, some of them are labeled as spam and the others are labeled as ham. The labeled SMS dataset can be described as:
Take a look at the instances above again. The SMS,
What you thinked about me. First time you saw me in class., is labeled as
ham and the other one,
Are you unique enough? Find out from 30th August. www.areyouunique.co.uk, is labeled as spam. Thus, it is represented as [
What, you, thinked, me, First, time, you, saw, me, class] with the label
ham and [
Are, you, unique, enough, Find, 30th, August, www, areyouunique, co, uk] with the label
spam.
However, each word in the observation sequence should be marked as ham or spam for the HMM learning. As the UCI repository dataset only has a label for each SMS, we use a compromised method to label all words in the observation sequence, i.e., labeling the words in the SMS based on the label of the SMS. The labels for the observation sequence can be represented as:
For the instances above, as the first SMS is a ham one, each word in the refined sequence is labeled as ham. As the second SMS is a spam one, each word in the sequence is labeled as spam. That is, the part of observation sequence [What, you, thought, me, First, time, you, saw, me, class] is labeled as [ham, ham, ham, ham, ham, ham, ham, ham, ham, ham] and [Are, you, unique, enough, Find, 30th, August, www, areyouunique, co, uk] is labeled as [spam, spam, spam, spam, spam, spam, spam, spam, spam, spam, spam].
3.4. Observation Probability Distribution
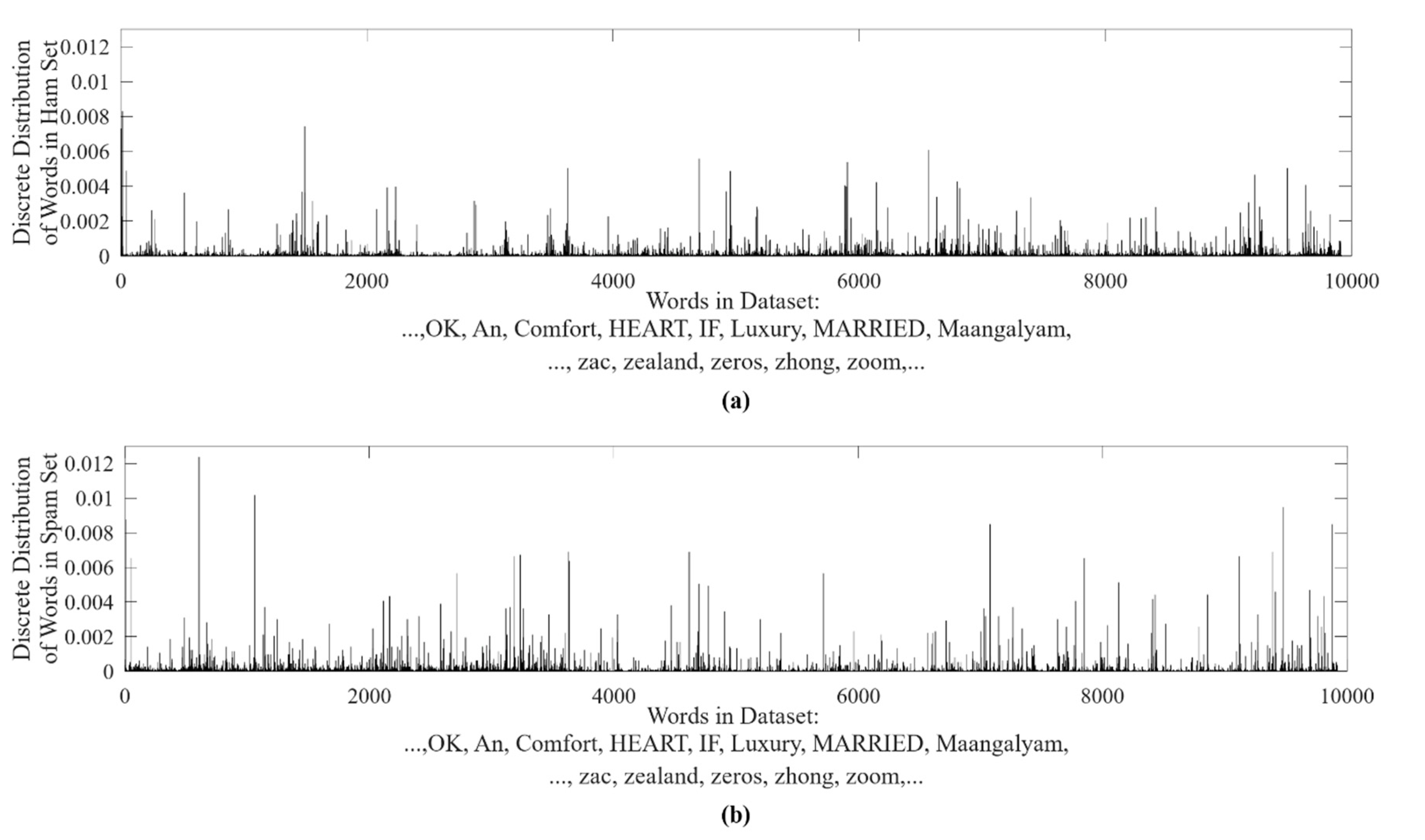
We calculate the probability of each observation state, i.e., each word in
W, appearing in ham and spam SMS sets. The probability distribution is depicted in
Figure 3. The word order in
W is fixed for easy comparison, as shown in
Figure 3.
The higher the frequency of a certain word, the higher the probability in the distribution. As the word order in
W is fixed in
Figure 3, we can compare the probability of each word in ham and spam sets visibly. It is found that:
As some words only have probability in a single dataset and their probability is equal to zero in another dataset, this indicates that these words only appear in the spam messages set or ham messages set;
As the probabilities of many words are quite different in different datasets, it is referred that these words appear in both sets with much different word frequencies;
Only a very small portion of them appear in both sets evenly.
It is true that the BoW also took advantage of this information to design term weights algorithms. However, the TF algorithm does not work well in the SMS scenario, because of the shortage of term occurrence.
In this paper, we first calculate two observation state distributions in spam and ham subsets. The two distributions are combined together to form the initial value of the HMM observation probability distribution matrix, .
3.5. HMM Learning
The Baum–Welch algorithm [
15] is typically used for finding HMM parameters
. That is, given HMM with initial parameters
and observation sequence
to update
iteratively and find parameters that maximize the likelihood of observed data, i.e.,
The initial parameters are initialized as:
indicates that the state can start from ham or spam with the same probability.
means each state transmission has the same probability.
infers the initial observation probability distribution calculated in
Section 3.4.
The Baum–Welch algorithm starts with initial parameters and then repeatedly takes two steps: Expectation step (E-step) and maximization step (M-step) until convergence (i.e., the difference of log-likelihood is less than small number
d), as shown in
Figure 4.
3.6. SMS Property Prediction
Given the observation sequence and the trained hidden Markov model to find the optimal hidden state sequence, this is a typical decoding problem in HMM. The Viterbi algorithm [
15] is applied to find the most likely hidden state sequence based on the input of each word sequence of the testing SMS. In formalization, we are given the testing observation sequence
and trained HMM with parameters
to find the most likely state sequence. That is,
Via the Viterbi decoding algorithm, for each word sequence of the testing SMS, the optimal hidden state sequence is produced. The state sequence is the combination of ham and spam. The prediction of the SMS property is based on the majority role, i.e., an SMS will be labeled as ham if the optimal hidden state sequence has more hams than spams. Otherwise, the SMS will be labeled as spam.
3.7. The Workflow of the Discrete HMM for SMS Spam Detection
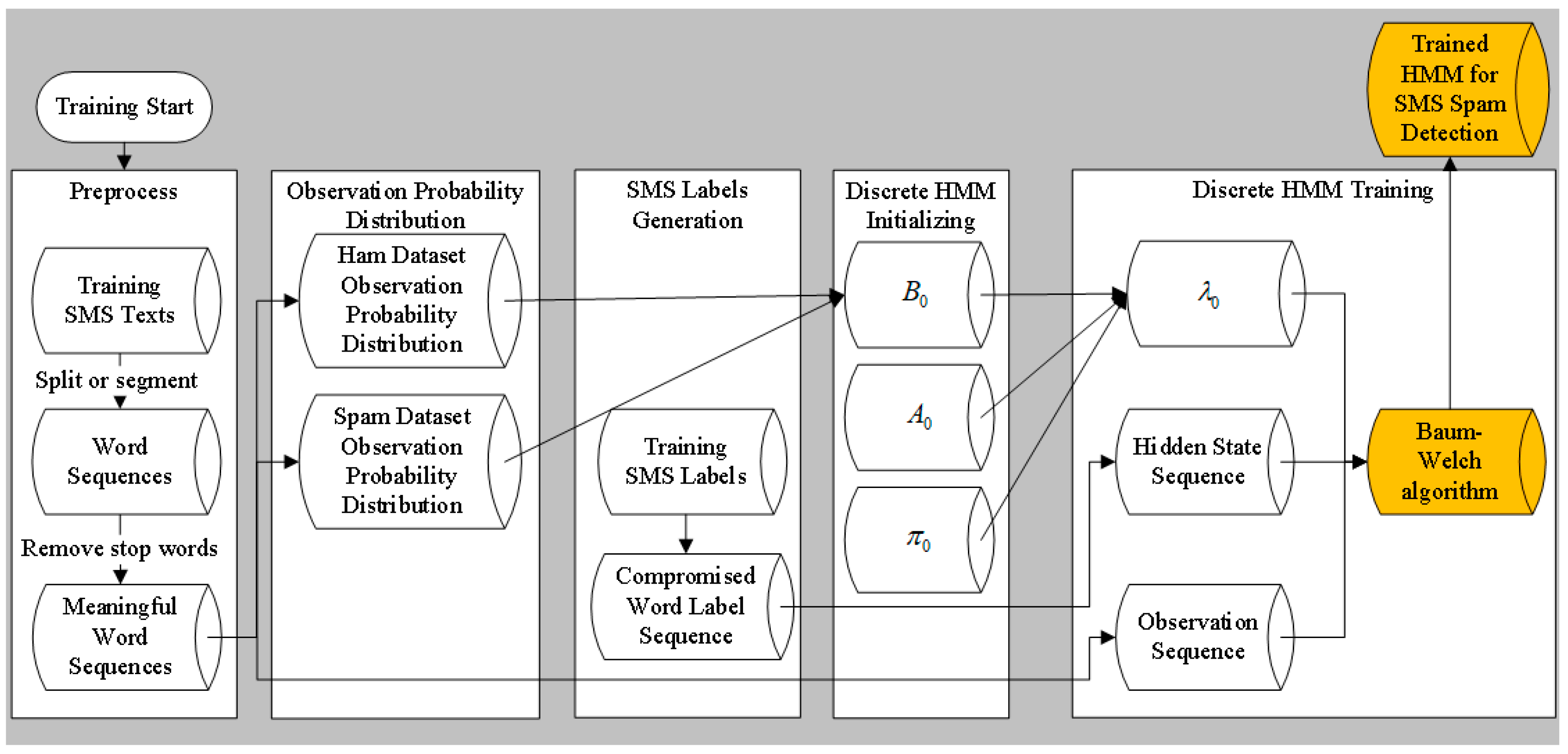
3.7.1. Data Preparation and HMM Learning
Step 1: Training an SMS dataset by first splitting or segmenting it into word sequences to keep their original order. Then, stop words are removed from the sequence and rest meaningful words form the observation sequence.
Step 2: Observation state probability distributions in ham and spam datasets are statistically analyzed and obtained.
Step 3: The compromised word label sequences are generated based on the labeled training SMS messages.
Step 4: The discrete HMM model is initialized as
. The initial parameters are given in
Section 3.5.
Step 5: The hidden state sequence and the observation sequence feed the discrete HMM. The discrete HMM is optimized by the Baum–Welch algorithm until convergence.
The training process workflow is shown in
Figure 5.
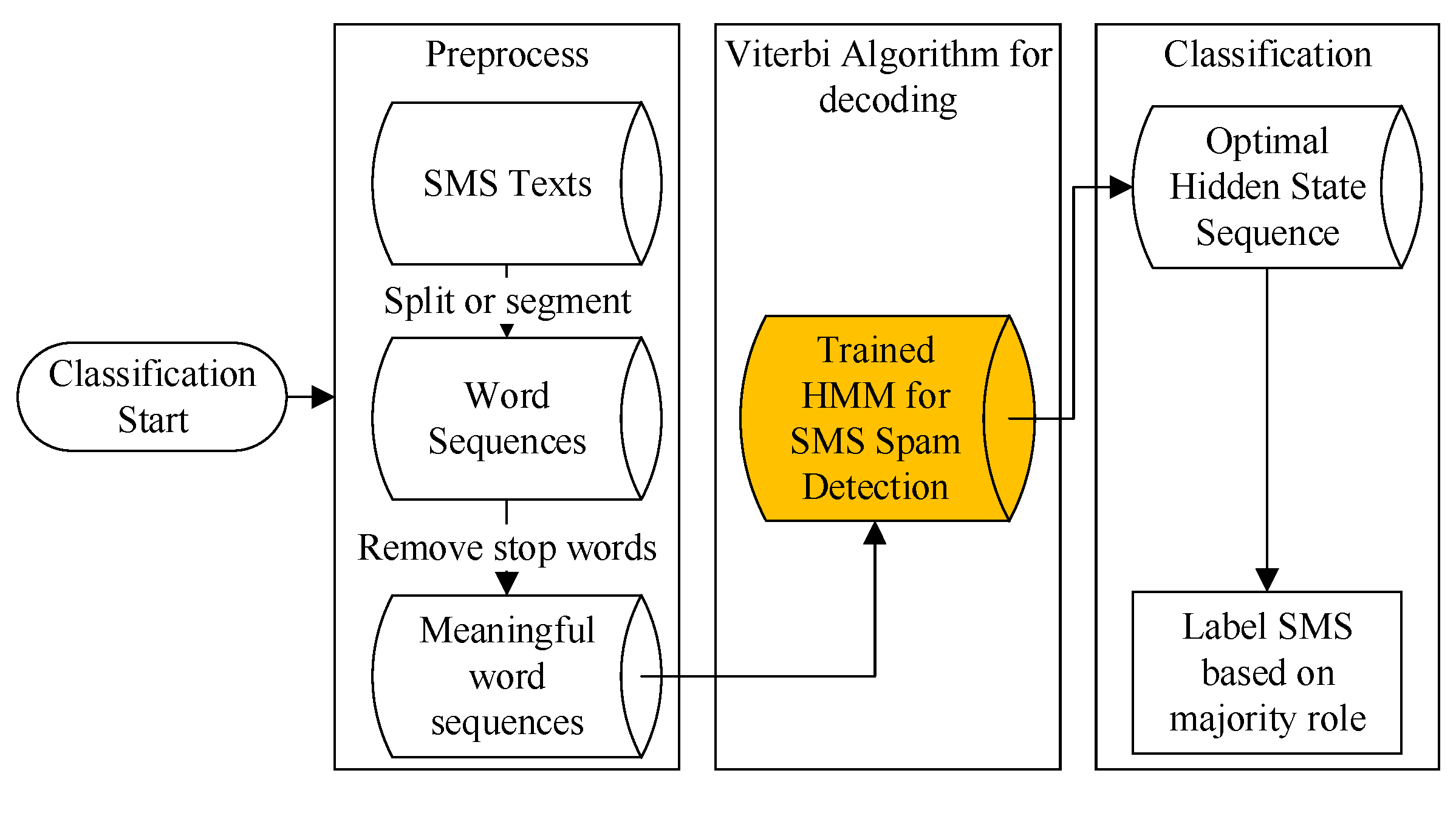
3.7.2. SMS Classification
Given the trained HMM and observation sequence, the classification process involved finding out the optimal hidden state sequence and making a prediction of the SMS property based on the majority role. The SMS classification workflow is shown in
Figure 6.
Step 1: Like the preprocess in the training workflow, the SMS dataset for classification is also first split or segmented into word sequences to keep their original word order. Then, stop words are removed from the sequence and the observation sequence is formed.
Step 2: Use the Viterbi decoding algorithm to find the optimal hidden state sequence for each SMS.
Step 3: Predict the SMS property based on the majority role.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}