Sound Event Detection Using Derivative Features in Deep Neural Networks

Abstract
:1. Introduction
2. Feature Extraction
2.1. Preprocessing
2.2. Derivative Features
3. Network Architecture
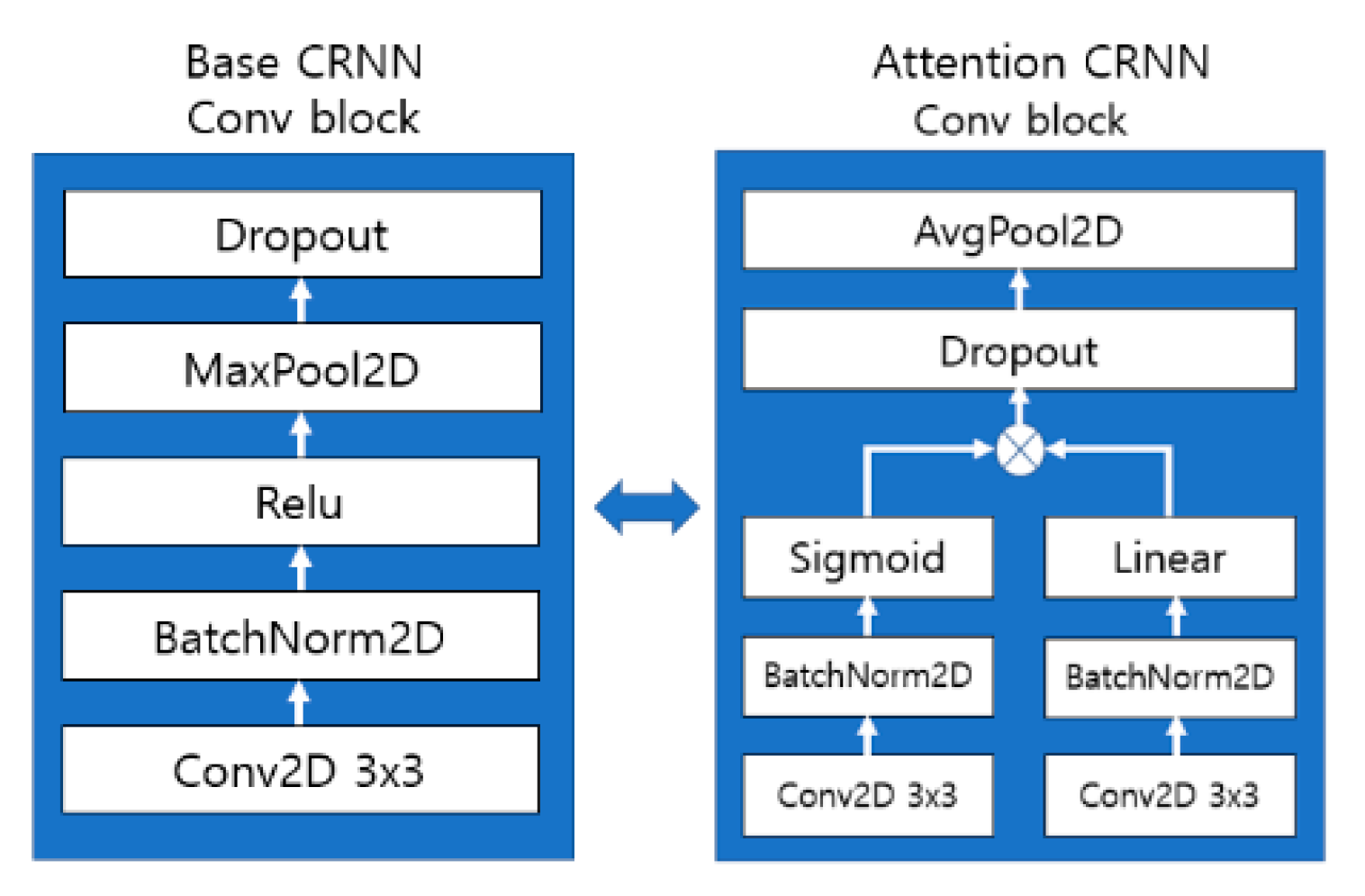
3.1. Basic CRNN
3.2. Mean-Teacher Model
4. Experimental Results
4.1. Database
4.2. Evaluation Metrics
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Turpault, N.; Serizel, R.; Shah, A.; Salamon, J. Sound event detection in domestic environments with weakly labeled data and soundscape synthesis. In Proceedings of the Workshop on Detection and Classification of Acoustic Scenes and Events, New York, NY, USA, 25–26 October 2019. hal-02160855v2. [Google Scholar]
- Nandwana, M.K.; Ziaei, A.; Hansen, J. Robust unsupervised detection of human screams in noisy acoustic environments. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing, Brisbane, Australia, 19–24 April 2015; pp. 161–165. [Google Scholar]
- Crocco, M.; Cristani, M.; Trucco, A.; Murino, V. Audio surveillance: A systematic review. ACM Comput. Surv. 2016, 48, 1–46. [Google Scholar] [CrossRef]
- Salamon, J.; Bello, J.P. Feature learning with deep scattering for urban sound analysis. In Proceedings of the 23rd European Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2015; pp. 724–728. [Google Scholar]
- Ntalampiras, S.; Potamitis, I.; Fakotakise, N. On acoustic surveillance of hazardous situations. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Taipei, Taiwan, 19–24 April 2009; pp. 165–168. [Google Scholar]
- Wang, Y.; Neves, L.; Metze, F. Audio-based multimedia event detection using deep recurrent neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 2742–2746. [Google Scholar]
- Dekkers, G.; Vuegen, L.; Waterschoot, T.; Vanrumste, B.; Karsmakers, P. DCASE 2018 challenge—Task 5: Monitoring of domestic activities based on multi-channel acoustics. arXiv 2018, arXiv:1807.11246. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Stateline, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Graves, A.; Mohamed, A.; Hinton, G. Speech recognition with deep recurrent neural Networks. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Cho, K.; Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Cakir, E.; Parascandolo, G.; Heittola, T.; Huttunen, H.; Virtanen, T. Convolutional recurrent neural networks for polyphonic sound event detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1291–1303. [Google Scholar] [CrossRef] [Green Version]
- Cakir, E.; Heittola, T.; Huttunen, H.; Virtanen, T. Polyphonic sound event detection using multilabel deep neural networks. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–16 July 2015; pp. 1–7. [Google Scholar]
- McLoughlin, I.; Zhang, H.; Xie, Z.; Song, Y.; Xiao, W. Robust sound event classification using deep neural networks. IEEE/ACM Tran. Audio Speech Lang. Process. 2015, 23, 540–552. [Google Scholar] [CrossRef] [Green Version]
- Bahdanau, D.; Chorowski, J.; Serdyuk, D.; Brakel, P.; Bengio, Y. End-to-end attention-based large vocabulary speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shaghai, China, 20–25 March 2016; pp. 4945–4949. [Google Scholar]
- Xu, Y.; Kong, Q.; Huang, Q.; Wang, W.; Plumbley, M.D. Attention and localization based on a deep convolutional recurrent model for weakly supervised audio tagging. In Proceedings of the International Conference on Spoken Language Processing (Interspeech), Stockholm, Sweden, 20–24 August 2017; pp. 3083–3087. [Google Scholar]
- Chorowski, K.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-based models for speech recognition. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 577–585. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Harb, R.; Pernkopf, F. Sound event detection using weakly labeled semi-supervised data with GCRNNs, VAT and self-adaptive label refinement. arXiv 2018, arXiv:1810.06897. [Google Scholar]
- JiaKai, L. Mean teacher convolution system for DCASE 2018 task 4. In Proceedings of the Workshop on Detection and Classification of Acoustic Scenes and Events, Surrey, UK, 19–20 November 2018. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1195–1204. [Google Scholar]
- Hamid, O.A.; Mohamed, A.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional neural networks for speech recognition. IEEE/ACM Tran. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef] [Green Version]
- Mesaros, A.; Heittola, T.; Virtanen, T. Metrics for polyphonic sound event detection. Appl. Sci. 2016, 6, 162. [Google Scholar] [CrossRef]
- Serizel, R.; Turpault, N.; Eghbal-Zadeh, H.; Shah, A.P. Large-Scale Weakly Labeled Semi-Supervised Sound Event Detection in Domestic Environments. In Proceedings of the Workshop on Detection and Classification of Acoustic Scenes and Events, Surrey, UK, 19–20 November 2018. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label Type | Weak Label | Strong Label | Unlabeled |
|---|---|---|---|
| No. of clips | 1578 | 2045 | 14,412 |
| Properties | Clip-level | Frame-level | None |
| Clip length | 10 s | ||
| Classes (10) | Speech, Dog, Cat, Alarm bell ring, Dishes, Frying, Blender, Running water, Vacuum cleaner, Electric shaver toothbrush | ||
| DCASE 2018 Test Set | DCASE 2019 Test Set | |
|---|---|---|
| No. of clips | 288 | 1168 |
| Properties | Frame-level | |
| Clip length | 10 s | |
| Classes | Same as training data | |
| DCASE 2018 Test Set | ||||
|---|---|---|---|---|
| Single Channel | Three Channels | |||
| F-Score (%) | ER | F-Score (%) | ER | |
| [weakly + unlabeled] (DCASE 2018 baseline) | 12.79 (14.06) | 1.44 (1.54) | 14.48 - | 1.42 - |
| [weakly + unlabeled + strongly] | 17.57 | 2.42 | 18.85 | 2.41 |
| [strongly] | 14.99 | 2.41 | 16.62 | 2.51 |
| [weakly + strongly] | 15.25 | 2.42 | 17.83 | 2.37 |
| Average | 15.15 | 2.17 | 16.95 | 2.18 |
| Average relative improvement | - | - | 11.6% | 0.5% |
| DCASE 2019 Test Set | ||||
|---|---|---|---|---|
| Single Channel | Three Channels | |||
| F-Score (%) | ER | F-Score (%) | ER | |
| [weakly + unlabeled] | 11.28 | 1.55 | 11.93 | 1.54 |
| [weakly + unlabeled+ strongly] | 13.80 | 2.99 | 14.63 | 2.92 |
| [strongly] | 12.85 | 3.07 | 13.11 | 3.09 |
| [weakly + strongly] | 13.39 | 2.98 | 14.41 | 2.91 |
| Average | 12.83 | 2.65 | 13.52 | 2.62 |
| Average relative improvement | - | - | 5.3% | 1.1% |
| Max Epoch = 100 | ||||
|---|---|---|---|---|
| Single Channel | Three Channels | |||
| F-Score (%) | ER | F-Score (%) | ER | |
| DCASE 2018 test set | 30.88 | 1.35 | 31.82 | 1.35 |
| Relative Improvement | - | - | 3% | 0% |
| DCASE 2019 test set (DCASE 2019 baseline) | 25.95 23.70 | 1.52 - | 27.09 - | 1.53 - |
| Relative Improvement | - | - | 4.4% | 0% |
| Strongly labeled training set | 68.53 | 0.58 | 70.28 | 0.54 |
| Relative Improvement | - | - | 2.5% | 6.8% |
| Max Epoch = 200 | ||||
|---|---|---|---|---|
| Single Channel | Three Channels | |||
| F-Score (%) | ER | F-Score (%) | ER | |
| DCASE 2018 test set | 31.12 | 1.32 | 32.68 | 1.27 |
| Relative Improvement | - | - | 5% | 3.8% |
| DCASE 2019 test set | 25.45 | 1.51 | 27.36 | 1.46 |
| Relative Improvement | - | - | 7.5% | 3.3% |
| Strongly labeled training set | 73.08 | 0.49 | 75.17 | 0.45 |
| Relative Improvement | - | - | 2.9% | 8.1% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwak, J.-Y.; Chung, Y.-J. Sound Event Detection Using Derivative Features in Deep Neural Networks. Appl. Sci. 2020, 10, 4911. https://doi.org/10.3390/app10144911
Kwak J-Y, Chung Y-J. Sound Event Detection Using Derivative Features in Deep Neural Networks. Applied Sciences. 2020; 10(14):4911. https://doi.org/10.3390/app10144911
Chicago/Turabian StyleKwak, Jin-Yeol, and Yong-Joo Chung. 2020. "Sound Event Detection Using Derivative Features in Deep Neural Networks" Applied Sciences 10, no. 14: 4911. https://doi.org/10.3390/app10144911
APA StyleKwak, J.-Y., & Chung, Y.-J. (2020). Sound Event Detection Using Derivative Features in Deep Neural Networks. Applied Sciences, 10(14), 4911. https://doi.org/10.3390/app10144911