Abstract
In the image forgery problems, previous works has been chiefly designed considering only one of two forgery types: copy-move and splicing. In this paper, we propose a scheme to handle both copy-move and splicing image forgery by concurrently classifying the image forgery types and localizing the forged regions. The structural correlations between images are employed in the forgery clustering algorithm to assemble relevant images into clusters. Then, we search for the matching of image regions inside each cluster to classify and localize tampered images. Comprehensive experiments are conducted on three datasets (MICC-600, GRIP, and CASIA 2) to demonstrate the better performance in forgery classification and localization of the proposed method in comparison with state-of-the-art methods. Further, in copy-move localization, the source and target regions are explicitly specified.
1. Introduction
In an era of globalization, social networks such as Facebook, Twitter, and Instagram are widely used in our daily lives and a huge number of photos are uploaded to these networks everyday. Further, it becomes easy even for unpracticed users to manipulate digital images without leaving any perceptible trace. Copy-move and image splicing are two most popular image manipulation methods. In the copy-move forgery (CMF), one or more regions are copied from an authentic image and then pasted into other regions of that image. The authentic image used to compose the copy-move image is called the host image. On the other hand, in image splicing, some regions are copied from a source image (the donor image) and pasted into a target image (the host image) [1]. Examples of copy-move and spliced images are given in Figure 1.

Figure 1.
Examples of image forgery in the top row, the corresponding host images are in the middle row, and the groundtruth images of forged regions are in the bottom row. Copy-move images are shown in (a,b), while spliced images are shown in (c,d).
In the image forgery scenario, a tampered region might not be exactly the same as the original region since it usually undergoes a sequence of post-processing operations such as rotation, scaling, edge softening, blurring, denoising, and smoothing for a better visual appearance [1]. Therefore, human beings may easily be deceived by tampered images and it is difficult to manually verify the authenticity of images.
Many researchers have put considerable effort into detecting and localizing tampered regions of image forgery. However, in most cases, forgery detection and localization algorithms were designed considering only one of two forgery types, copy-move and image splicing. In this paper, we propose an image forgery detection and localization algorithm that can handle both types of image forgeries simultaneously. The proposed method utilizes the bag-of-features (BOF) image representation and Hamming Embedding (HE) based image retrieval. The image forgery clustering algorithm classifies input images into distinct clusters, each of which consists of one authentic image and all the spliced and copy-move images which were composed using that authentic image as the host image. The algorithm also determines the authentic image based on structure and luminance similarity between images and assigns it as the centroid of the cluster. The cluster centroid is used to classify the image forgeries and localize the tampered regions. The experimental results show that the proposed method outperforms state-of-the-art techniques in image forgery classification and localization accuracy. In addition, we distinguish the source and target regions in copy-move tampering localization.
The further part of this paper is organized as follows. Section 2 provides a brief review of image splicing and copy-move detection and localization methods. In Section 3, we present the image retrieval algorithm based on HE and BOF. The proposed image clustering algorithm is introduced in Section 4. Section 5 presents the image forgery detection and localization. The experimental results are discussed in Section 6. Finally, Section 7 concludes the paper.
2. Related Works
In the literature, image splicing forgery detection problem has been addressed efficiently [2,3,4]. In recent years, a substantial attention has been paid to deep learning based approaches [5,6] for localizing image splicing [7,8,9,10,11,12,13,14,15] wherein convolutional neural network (CNN) has been widely used [8,9,10,11,12]. Bondi et al. [8] extracted and employed features capturing characteristic traces from different camera models to localize a tampered mask by an iterative clustering algorithm. Region proposal network and condition random field are the main components of the model developed in Chen et al. [10]. The noise levels difference between spliced and original regions was utilized to find the splicing traces [11,13]. Non-linear camera response function was used in Yao et al. [11] and was combined with noise level function to exploit the strong relationship between two functions to localize the forged edges using a CNN. Mayer et al. [12] used a similarity network and a CNN-based feature extractor to determine whether image patches contain different traces or being captured by different camera models. Zeng et al. [13] estimated the noise levels using the principal component analysis and then clustered using k-means algorithm to localize the spliced regions. Matern et al. [15] utilized the gradient-based illumination descriptor to detect the illumination inconsistency and object color change, which helped localize image splicing traces. Wang et al. [16] used gamma transformation to detect splicing forgery and localize spliced region by estimating the probabilities of sliding window based overlapping blocks being gamma transformed.
CMF detection is the problem of detecting the tampered regions in copy-move images, is called CMF localization (CMFL) in this paper, to distinguish from CMF classification. CMFL has also been actively studied in many researches, which can be divided into three categories: block-based methods [17,18,19,20,21,22], keypoints-based methods [23,24,25,26,27,28], and segmentation-based methods [29,30,31,32]. Park et al. [17] introduced the upsampled log-polar Fourier descriptor, which is invariant to rotation and scaling, to robustly detect various types of tampering attacks. Wu et al. [18] proposed a two-branch deep neural network to detect potential manipulation via visual artifacts and visually similar regions, which helps specify the copied and pasted regions. Park et al. [19] used the scale space representation of scale-invariant feature transform (SIFT) to handle different geometric transformation. PatchMatch, an algorithm used to search for approximate nearest neighbors, was combined with Zernike moments to detect copy-move attacks in [23,24] whereas SIFT was utilized in [25,26,27]. In segmentation-based approaches, the input image was semantically segmented into non-overlapped regions [29,30,31,32]. Li et al. [29] developed two stages of matching to detect the copy-move regions. Firstly the affine transformation matrix between segmented regions was roughly estimated and then iteratively refined by using an expectation-maximization algorithm-based probability model. However, the major disadvantage of this method is its high computational complexity. Zheng et al. [30] classified smooth regions and non-smooth regions (keypoint regions) to be apply two different techniques. On the one hand, SIFT was used in a keypoint-based method to detect forgery in non-smooth regions. On the other hand, Zernike moments were extracted in a block-based method to handle smooth regions. The CMFL was effectively performed by the fusion of above-mentioned techniques.
3. Bag-of-Features and Hamming Embedding Based Image Retrieval
In image retrieval, images are represented by descriptive features. The features are used to evaluate similarity or dissimilarity between images. In the image forgery, since the forged regions may be rotated, scaled, and translated in different manners, the features of the images should be invariant to these transformations. The features generated by SIFT [33] have such noteworthy characteristics and the proposed algorithm utilizes the SIFT features to represent images [34,35].
In this section, we briefly review the image retrieval method based on BOF [36,37,38] and HE encoding [38,39]. Suppose that a query image is represented by a set of N descriptors, . All of these descriptors are mapped into a visual vocabulary set by a K-means vector quantizer q. For example, q maps to the closest visual word , where . We define a set of descriptor indexes, which assigns descriptors of to a particular visual word as .
A matching model HE is used to estimate the matching of descriptors to a visual word. HE represents each descriptor as D-dimensional binary signatures [38]. Let , is a single bit binary code used to represent , then is a binary signature of descriptor . The Hamming distance between two descriptors, and , is computed using their binary signatures as follows:
Let us denote be the set of descriptors of the database image . The probability that two sets of descriptors, and are assigned to the same visual word is defined as:
where the weighting function for a Hamming distance h is calculated as a Gaussian function [38]:
The number of dimensions for the binary signatures is typically set to , and the Gaussian bandwidth parameter [38,40] is set to .
In order to retrieve images, an inverted index file is built in the image indexing process. The inverted file consists a list of entries. In each entry, a visual word is stored along with the identifier of associated images, descriptors of those images which are assigned to the visual word and the HE used for matching measurement. When the query of is performed, the entries of visual words associated to are searched in the inverted file. The score of a database image in this query is calculated by accumulating the Hamming distances between two sets of descriptors’ signatures for all the shared visual words of two images. Specifically, the similarity between and is defined as follows:
where the constant is the inverse document frequency [41] of a visual word in . Suppose that is the probability of occurring in , then .
4. Image Forgery Clustering
In this section, we give an exposition of the proposed image forgery clustering algorithm. Suppose that we have an input dataset including authentic and tampered images. The proposed algorithm classifies images into separate clusters, where each cluster consists of tampered images which were composed using an identical host image and that host image. Subsequently, the proposed algorithm finds the host image to be the centroid of each image cluster. The details of images clustering and centroid determination are provided in Algorithm 1.
Firstly, we randomly select a query image in the dataset. The ranking score of a database image in the query of is denoted as and calculated as the similarity between two images according to Equation (4). The retrieval results are a list of images arranged in descending order of ranking scores. A cut-off threshold is set to obtain the set of images. Let us denote as the host image of the image in the dataset. An authentic image is considered as the host image of itself. We need to retrieve all the relevant images to the query satisfying . To this end, we set the threshold to a relatively low value. This low threshold value leads to the case where also some irrelevant images may be retrieved together. Note that, the irrelevantly retrieved images will be discarded in the last step of the iteration. Due to the insignificant processing time of these operations, we can easily handle the case of a large number of images in a cluster. Further, we perform an additional query to ensure that all the relevant images to are retrieved. Notice that the top ranked image in retrieved list , image is identical to the query image . Therefore, the second highest ranked result in , image , is selected as the query image. The score threshold is also used in this query, then we obtain the set of retrieved images .
The image cluster is the union of two sets of retrieved images, i.e., . The centroid of is determined based on two criteria which measure the correlations in structure and luminance among images in the cluster. In this work, we extract SIFT features [33] in images and use Random Sample Consensus [42] to find the matching. Let denote the set of matched keypoints between two images and in where is a pair of keypoints. Then is the number of matching keypoints between and . We denote by the pixel coordinates of in . The number of matching keypoints in the corresponding positions of and , denoted by , is calculated as follows:
where is the Kronecker delta function:
We define the ratio as the structural similarity between and .
| Algorithm 1: Image forgery clustering |
 |
In addition, we denote by the luminance value of image at pixel , which can be calculated as follows [43]:
where are the red, green, and blue color values of at pixel , respectively. We define , the luminance similarity image between and as follows:
where H and W are height and width of , respectively and
We determine , the centroid of image cluster as follows:
Afterwards, we refine the image cluster by discarding irrelevant images to where as follows
Therefore, all the retrieved authentic images, with the exception of the centroid image , are discarded from the cluster. In other words, is the unique authentic image in . Figure 2 illustrates an example of discarding an image from the cluster according to Equation (11).

Figure 2.
Image (d,e) are the illustrations of keypoints matching between couples of images (a,b), (b,c), respectively. Although (b,c) have many matching keypoints, the positions of those keypoints in relative images are different. In this example, image (c) is discarded from the cluster.
Figure 3 depicts an example of image database indexing and one iteration of the proposed image forgery clustering algorithm to obtain one image cluster with. After each iteration of the proposed clustering algorithm, all the images of the new cluster are excluded from the image database. We repeatedly perform querying and clustering process until the database is empty. Finally, each input image belongs to only one cluster.
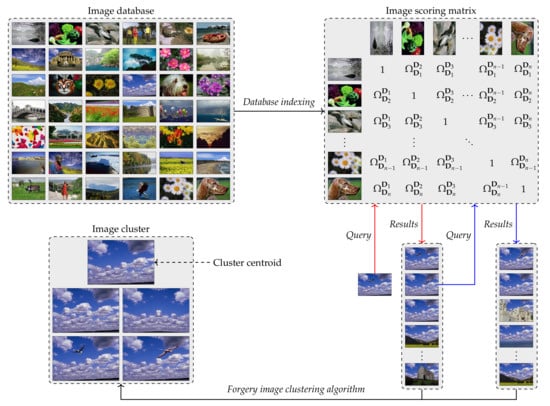
Figure 3.
The illustration of image database indexing and one iteration of the proposed image forgery clustering algorithm.
5. Image Forgery Classification and Localization
Given the centroid and an image in the cluster, we can easily estimate the mask of forged regions of based on . Specifically, denotes the image region including all image pixels that and jointly have, and denotes the image region in but not in .
Consequently, two image regions and are extracted as shown in Figure 4. These image regions are refined by using median filter to remove salt and pepper noise.
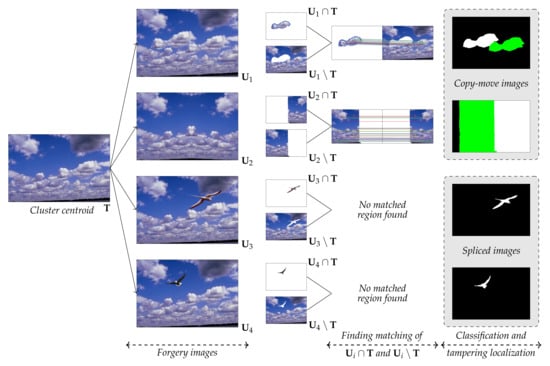
Figure 4.
Image forgery classification and localization in an image cluster.
We use SIFT to find the matched regions of and . 3 pairs of matched keypoints are utilized to calculate the affine transformation matrix, and subsequently, a warped image is generated for each transformation matrix. To localize the duplicated regions, the zero mean normalized cross-correlation method is adopted [19]. If we can find such regions, the image is classified as a copy-move image; otherwise, the tampered image is classified as a spliced image. In Figure 4, images and are classified as copy-move images and the detected forgery regions are illustrated in the last column. The previously detected regions, , are the target regions in white, and the newly found matched regions are the source of the copy-move operation, which are represented in green. In the last two examples of Figure 4, the spliced regions of images and , are highlighted in white.
6. Experimental Results
6.1. Datasets
There exist several benchmarking datasets for evaluating the performance of image forgery detection algorithms. In our experiments, we used three challenging datasets MICC-600 [25], GRIP [23], and CASIA 2.0 [44] for the evaluation.
6.1.1. MICC-600
MICC-600 is a dataset of 600 high resolution images with various sizes from to pixels. There are 440 original images and 160 copy-move images. As shown in Figure 5, multiple scenarios of copy-move operations were performed in this dataset:

Figure 5.
Examples of CMFL in MICC-600 dataset. First row: original images, second row: copy-move images, third row: ground truth images, and fourth row: source regions (green) and target regions (white) detected by the proposed method.
6.1.2. GRIP
GRIP is a small dataset with copy-move and original images. All the images in this dataset have either resolution or . The target regions in copy-move images were composed using different attacks, such as compression, noise addition, rotation, scaling.
6.1.3. CASIA 2
CASIA 2 is a big dataset with more than 12,000 images in three categories: authentic, spliced and copy-move images. The images in this dataset are in low resolution with the sizes vary from to pixels. Among three datasets in our simulations, CASIA 2 is the only dataset which has both types of forgery: splicing and copy-move.
6.2. Evaluation Metrics
In the experiments, we evaluate the performance of image retrieval and image forgery classification and localization.
6.2.1. Metrics for Image Retrieval
To evaluate the performance of the proposed image forgery clustering algorithm, we use the mean average precision () metric used in image retrieval problem. For a query q, let us denote the number of retrieved images, the number of relevant images, and the number of relevant images in top k retrieved results. The precision and recall of query q at cut-off k, denoted by and , are calculated as follows:
Then, the average precision for query q is computed as follows:
where is the change in recall from items to k. Note that . Finally, for all the queries is defined as follows:
where Q is the number of queries.
6.2.2. Metrics for Image Forgery Classification and Localization
Since we concurrently classify image forgery types and localize the forged regions, the evaluation is performed in both image and pixel levels.
To quantitatively evaluate the performance of forgery localization, we adopt two metrics for tampered regions of a classified tampered image [19], localization precision and localization recall , which are defined as follows:
Similarly, we define the classification precision , and recall at image level:
In order to balance between precision and recall, we consider both of these quantities by computing their harmonic mean, called localization F-measure, as follows:
The metrics precision, recall, and F-measure at pixel level are used for all 3 datasets in this work. Nevertheless, the metrics at image level are only used to evaluate performance of the proposed method in MICC-600 and GRIP datasets. To evaluate the classification performance in CASIA 2, which contains 3 classes, we use confusion matrix.
6.3. Image Retrieval Results
To evaluate the performance of the proposed image forgery clustering algorithm, we carry out the experiments to estimate of image retrieval in 3 different scenarios related to cluster formation of Algorithm 1. In the first case, only one query is performed to compose the cluster. In the second case, the second query is performed to augment the retrieved results. In the third case, the cluster refinement using structural correlation of Algorithm 1 is conducted after two queries to form the image forgery cluster. We denote these cases by case A, case B, and case C, respectively. Figure 6 shows the retrieval performance of 3 above-mentioned cases in 3 datasets. It is clear that significantly increases from case A to case C in all 3 datasets to prove the efficiency of the proposed image retrieval based clustering algorithm.
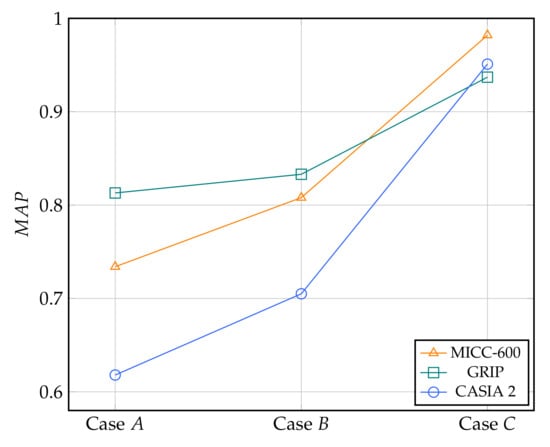
Figure 6.
The mean average precision obtained by 3 scenarios of image retrieval performed by the proposed clustering algorithm.
We present the average ratios that the host image of the query is retrieved in 3 cases in Table 1. The results ensure that by using image forgery clustering algorithm, we can generally retrieve the host images of query images into the clusters.

Table 1.
Average ratios when the host image of the query image is retrieved (%).
6.4. Forgery Detection and Localization Results on MICC-600 Dataset
Table 2 presents the performance of the proposed method in comparison with state-of-the-art on MICC-600 dataset. Our classification F-measure outperforms Li. et al. [29] and is slightly lower than Li. et al. [27]. In term of localization performance, our method surpasses other methods with . Visual examples of CMFL are shown in Figure 5 where we distinguish the source and target regions in green and white, respectively.
Table 2.
Performance comparison on MICC-600 dataset (%).
6.5. Forgery Detection and Localization Results on GRIP Dataset
Table 3 summarizes the performance on GRIP dataset where the proposed method exceeds other methods in both classification and localization indexes. The evaluations in different types of copy-move situations are also considered. Specifically, 4 attacks includes Gaussian noise addition and JPEG compression to the copy-move images, rotation and scaling to the copied regions. Figure 7a indicates that our method is better than other methods in term of localization F-measure with different levels of Gaussian noise added to the copy-move images. Figure 7b shows that different CMFL methods handling JPEG compression situation with a slight difference. In case the copied regions are rotated or scaled, Chen et al. [20], Chen et al. [32], and our method sequentially perform better than the rest (Figure 7c,d). The proposed method performs better than other methods when the changes of the copied regions are small. On the contrary, its performance declines for larger rotation angle and scaling factor. Figure 8 illustrates the CMFL examples of the proposed method on GRIP dataset.
Table 3.
Performance comparison on GRIP dataset (%).
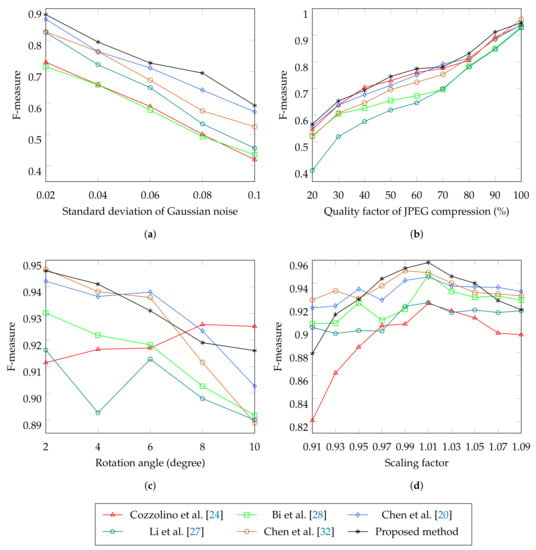
Figure 7.
Pixel level F-measure comparison in the GRIP dataset with different types of copy-move attacks.

Figure 8.
Examples of copy-move forgery detection in GRIP dataset. First row: original images, second row: copy-move images, third row: ground truth images, and forth row: source regions (green) and target regions (white) detected by the proposed method.
6.6. Forgery Detection and Localization Results on CASIA 2 Dataset
Table 4 summarizes the 3-class classification results of the proposed method on the CASIA 2 dataset. To the best of our knowledge, all of the previous researches on forgery detection of this dataset are binary classification. Therefore, only the results of our work are reported. The detection accuracy of authentic images achieve 96.9%, which is higher than two image forgery types. 6.7% of copy-move images are classified as spliced images. By contrast, 4.4% of spliced images are mistakenly detected as copy-move images.
Table 4.
Performance of image forgery classification in CASIA 2 dataset (%).
Table 5 and Table 6 compare the proposed method with other researches on localization performance of spliced images and copy-move images of CASIA 2 dataset, respectively. Examples of CMFL results of the proposed method are shown in Figure 9. Since CASIA 2 is the most challenging dataset in our experiments with many small and smooth tampered regions, the proposed method occasionally fails to search for matching regions.
Table 5.
Performance of image splicing localization on CASIA 2 (%).
Table 6.
Performance of copy-move images localization on CASIA 2 (%).

Figure 9.
Examples of splicing forgery detection in CASIA 2 dataset. Columns (a–c): copy-move images, columns (d–f): spliced images. First row: original images, second row: spliced images, third row: ground truth images, and forth row: tampered regions detected by the proposed method.
7. Conclusions
This paper introduces a novel method to detect and localize authentic images and two types of tampered images: copy-move and spliced images. We propose a robust algorithm to divide relevant images into cluster using BOF and HE based image retrieval. From image clusters, by exploiting the structural correlation between images, the proposed algorithm determines the cluster centroid, which is the only authentic image in the cluster. Afterwards, the image forgery are classified, and the forged regions are localized. The experimental results show that this method achieves higher performance in both forgery detection and localization in comparison with state-of-the-art methods. Notably, the proposed method can indicate the source and target regions of copy-move images.
Author Contributions
Conceptualization, N.T.P., J.-W.L., and C.-S.P.; methodology, N.T.P.; software, N.T.P.; formal analysis, N.T.P.; resources, J.-W.L.; data curation, N.T.P.; writing—original draft preparation, N.T.P.; writing—review and editing, J.-W.L. and C.-S.P.; visualization, N.T.P.; supervision, J.-W.L. and C.-S.P.; project administration, J.-W.L. and C.-S.P.; funding acquisition, J.-W.L. and C.-S.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the MSIT (Ministry of Science and ICT), Korea, under the ITRC (Information Technology Research Center) support program (IITP-2020-2016-0-00312) supervised by the IITP (Institute for Information & communications Technology Planning & Evaluation). This work was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science and Technology (NRF-2019R1F1A1055593).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CMF | Copy-Move Forgery |
| CNN | Convolutional Neural Network |
| CMFL | Copy-Move Forgery Localization |
| SIFT | Scale Invariant Feature Transform |
| BOF | bag-of-features |
| HE | Hamming Embedding |
| mean average precision |
References
- Pham, N.T.; Lee, J.W.; Kwon, G.-R.; Park, C.-S. Hybrid Image-Retrieval Method for Image-Splicing Validation. Symmetry 2019, 11, 83. [Google Scholar] [CrossRef]
- Chen, B.; Qi, X.; Sun, X.; Shi, Y.-Q. Quaternion pseudo-Zernike moments combining both of RGB information and depth information for color image splicing detection. J. Vis. Commun. Image Represent 2017, 49, 283–290. [Google Scholar] [CrossRef]
- He, Z.; Lu, W.; Sun, W.; Huang, J. Digital image splicing detection based on Markov features in DCT and DWT domain. Pattern Recognit. 2012, 45, 4292–4299. [Google Scholar] [CrossRef]
- Pham, N.T.; Lee, J.W.; Kwon, G.-R.; Park, C.-S. Efficient image splicing detection algorithm based on Markov features. Multimedia Tools Appl. 2018, 78, 12405–12419. [Google Scholar] [CrossRef]
- Vo, A.H.; Le, T.; Vo, M.T.; Le, T. A Novel Framework for Trash Classification Using Deep Transfer Learning. IEEE Access 2019, 7, 178631–178639. [Google Scholar] [CrossRef]
- Le, T.; Vo, M.T.; Kieu, T.; Hwang, E.; Rho, S.; Baik, S. Multiple Electric Energy Consumption Forecasting Using a Cluster-Based Strategy for Transfer Learning in Smart Building. Sensors 2020, 20, 2668. [Google Scholar] [CrossRef]
- Zampoglou, M.; Papadopoulos, S.; Kompatsiaris, Y.; Kompatsiaris, I. Large-scale evaluation of splicing localization algorithms for web images. Multimedia Tools Appl. 2016, 76, 4801–4834. [Google Scholar] [CrossRef]
- Bondi, L.; Lameri, S.; Güera, D.; Bestagini, P.; Delp, E.; Tubaro, S. Tampering Detection and Localization Through Clustering of Camera-Based CNN Features. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1855–1864. [Google Scholar]
- Shi, Z.; Shen, X.; Kang, H.; Lv, Y. Image Manipulation Detection and Localization Based on the Dual-Domain Convolutional Neural Networks. IEEE Access 2018, 6, 69472–69480. [Google Scholar] [CrossRef]
- Chen, B.; Qi, X.; Wang, Y.; Zheng, Y.; Shim, H.J.; Shi, Y.-Q. An Improved Splicing Localization Method by Fully Convolutional Networks. IEEE Access 2018, 6, 69472–76453. [Google Scholar] [CrossRef]
- Yao, H.; Wang, S.; Zhang, X.; Qin, C.; Wang, J. Detecting Image Splicing Based on Noise Level Inconsistency. Multimedia Tools Appl. 2017, 76, 12457–124797. [Google Scholar] [CrossRef]
- Mayer, O.; Stamm, M.C. Forensic Similarity for Digital Images. IEEE Trans. Inf. Forensics Secur. 2020, 15, 1331–1346. [Google Scholar] [CrossRef]
- Zeng, H.; Zhan, Y.; Kang, X.; Lin, X. Image splicing localization using PCA-based noise level estimation. Multimedia Tools Appl. 2017, 76, 4783–4799. [Google Scholar] [CrossRef]
- Zheng, Y.; Cao, Y.; Chang, C.-H. A PUF-Based Data-Device Hash for Tampered Image Detection and Source Camera Identification. IEEE Trans. Inf. Forensics Secur. 2020, 15, 620–634. [Google Scholar] [CrossRef]
- Matern, F.; Riess, C.; Stamminger, M. Gradient-Based Illumination Description for Image Forgery Detection. IEEE Trans. Inf. Forensics Secur. 2020, 15, 1303–13170. [Google Scholar] [CrossRef]
- Wang, P.; Liu, F.; Yang, C.; Luo, X. Blind forensics of image gamma transformation and its application in splicing detection. J. Vis. Commun. Image Represent. 2018, 55, 80–90. [Google Scholar] [CrossRef]
- Park, C.-S.; Kim, C.; Lee, J.; Kwon, G.-R. Rotation and scale invariant upsampled log-polar fourier descriptor for copy-move forgery detection. Multimedia Tools Appl. 2016, 75, 16577–16595. [Google Scholar] [CrossRef]
- Wu, Y.; Abd-Almageed, W.; Natarajan, P. BusterNet: Detecting Copy-Move Image Forgery with Source/Target Localization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 October 2018; pp. 170–186. [Google Scholar]
- Park, C.-S.; Choeh, J.Y. Fast and robust copy-move forgery detection based on scale-space representation. Multimedia Tools Appl. 2017, 77, 16795–16811. [Google Scholar] [CrossRef]
- Chen, B.; Yu, M.; Su, Q.; Shim, H.J.; Shi, Y.-Q. Fractional Quaternion Zernike Moments for Robust Color Image Copy-Move Forgery Detection. IEEE Access 2018, 6, 56637–56646. [Google Scholar] [CrossRef]
- Zhong, J.-L.; Pun, C.-M. An End-to-End Dense-InceptionNet for Image Copy-Move Forgery Detection. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2134–2146. [Google Scholar] [CrossRef]
- Wu, Y.; Abd-Almageed, W.; Natarajan, P. Image Copy-Move Forgery Detection via an End-to-End Deep Neural Network. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1907–1915. [Google Scholar]
- Cozzolino, D.; Poggi, G.; Verdoliva, L. Copy-move forgery detection based on PatchMatch. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 6–10 July 2013; pp. 5312–5316. [Google Scholar]
- Cozzolino, D.; Poggi, G.; Verdoliva, L. Efficient Dense-Field Copy–Move Forgery Detection. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2284–2297. [Google Scholar] [CrossRef]
- Amerini, I.; Ballan, L.; Caldelli, R.; Del Bimbo, A.; Del Tongo, L.; Serra, G. Copy-move forgery detection and localization by means of robust clustering with J-Linkage. Signal Process. Image Commun. 2013, 28, 659–669. [Google Scholar] [CrossRef]
- Jin, G.; Wan, X. An improved method for SIFT-based copy–move forgery detection using non-maximum value suppression and optimized J-Linkage. Signal Process. Image Commun. 2017, 57, 113–125. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, J. Fast and Effective Image Copy-Move Forgery Detection via Hierarchical Feature Point Matching. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1307–1322. [Google Scholar] [CrossRef]
- Bi, X.; Pun, C.-M. Fast copy-move forgery detection using local bidirectional coherency error refinement. Pattern Recognit. 2018, 81, 161–175. [Google Scholar] [CrossRef]
- Li, J.; Li, X.; Yang, B.; Sun, X. Segmentation-Based Image Copy-Move Forgery Detection Scheme. IEEE Trans. Inf. Forensics Secur. 2015, 10, 507–518. [Google Scholar]
- Zheng, J.; Liu, Y.; Ren, J.; Zhu, T.; Yan, Y.; Yang, H. Fusion of block and keypoints based approaches for effective copy-move image forgery detection. Multidimens. Syst. Signal Process. 2016, 27, 989–1005. [Google Scholar] [CrossRef]
- Pun, C.-M.; Yuan, X.; Bi, X.-L. Image Forgery Detection Using Adaptive Oversegmentation and Feature Point Matching. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1705–1716. [Google Scholar]
- Chen, B.; Yu, M.; Su, Q.; Li, L. Fractional quaternion cosine transform and its application in color image copy-move forgery detection. Multimedia Tools Appl. 2018, 78, 8057–8073. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Manzo, M. Graph-Based Image Matching for Indoor Localization. Mach. Learn. Knowl. Extr. 2019, 1, 785–804. [Google Scholar] [CrossRef]
- Manzo, M.; Pellino, S. Bag of ARSRG Words (BoAW). Mach. Learn. Knowl. Extr. 2019, 1, 871–882. [Google Scholar] [CrossRef]
- Tolias, G.; Avrithis, Y.; Jégou, H. To Aggregate or Not to aggregate: Selective Match Kernels for Image Search. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, NSW, Australia, 1–8 December 2013; pp. 1401–1408. [Google Scholar]
- Arandjelović, R.; Zisserman, A. DisLocation: Scalable Descriptor Distinctiveness for Location Recognition. In Proceedings of the Asian Conference on Computer Vision (ACCV), Singapore, 1–5 November 2014; pp. 188–2044. [Google Scholar]
- Jegou, H.; Douze, M.; Schmid, C. Hamming Embedding and Weak Geometric Consistency for Large Scale Image Search. In Proceedings of the European Conference on Computer Vision (ECCV), Marseille, France, 12–18 October 2008; pp. 304–317. [Google Scholar]
- Sattler, T.; Havlena, M.; Schindler, K.; Pollefeys, M. Large-Scale Location Recognition and the Geometric Burstiness Problem. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1582–1590. [Google Scholar]
- Jegou, H.; Douze, M.; Schmid, C. On the burstiness of visual elements. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 1169–1176. [Google Scholar]
- Robertson, S. Understanding inverse document frequency: On theoretical arguments for IDF. J. Doc. 2004, 60, 503–520. [Google Scholar] [CrossRef]
- Fischler, M.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Woods, R.E. Image Compression. In Digital Image Processing, 3rd ed.; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2008; p. 608. [Google Scholar]
- Dong, J.; Wang, Y.; Tan, T. CASIA Image Tampering Detection Evaluation Database. In Proceedings of the 2013 IEEE China Summit and International Conference on Signal and Information Processing (ChinaSIP), Beijing, China, 6–10 July 2013; pp. 422–426. [Google Scholar]









© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).