SoftRec: Multi-Relationship Fused Software Developer Recommendation

Abstract
1. Introduction
- We formally define the multivariate relationships between developers and tasks, including three types: (1) developer–developer collaboration relationships, (2) developer–task interaction relationships, and (3) task–task association relationships.
- We propose a multi-relationship fused approach to recommend developers based on joint matrix factorization and generate forecast results upon the architecture of deep neural network. To our best knowledge, this is the first attempt to integrate these three implicit relationships into developer recommendation.
- We propose a fast approach to update the changes of the model efficiently and improve the recommendation efficiency, which can address the cold start issue.
- To evaluate the effectiveness of SoftRec, we conduct experiments on two real-world datasets: One from GitHub with 2517 developers and 9329 tasks, while the other from a well-known company’s GitLab with 590 developers and tasks, and we also conduct a user study in this company. By comparisons of four state-of-the-art works, the results demonstrate the advantages of the SoftRec.
2. Related Work
3. The Multi-Relationship Fused Software Developer Recommendation
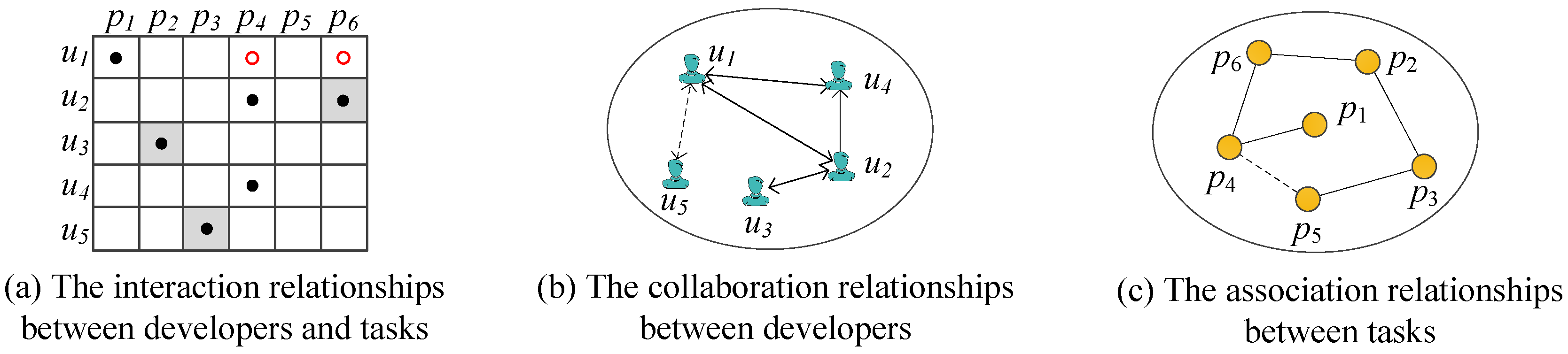
3.1. Definition of Multi-Relationships
3.1.1. Developer–Developer Collaboration Relationship
3.1.2. Developer–Task Interaction Relationship
3.1.3. Task–Task Association Relationship
3.2. Fusion of Multi-Relationships
3.3. Developer Prediction
3.4. Fast Model Update
| Algorithm 1: fastUpdate for |
 |
4. Experiment and Discussion
- RQ1
- How does SoftRec perform compared with state-of-the-art CF-based recommendation methods?
- RQ2
- How does SoftRec perform when tackling different data sparsity?
- RQ3
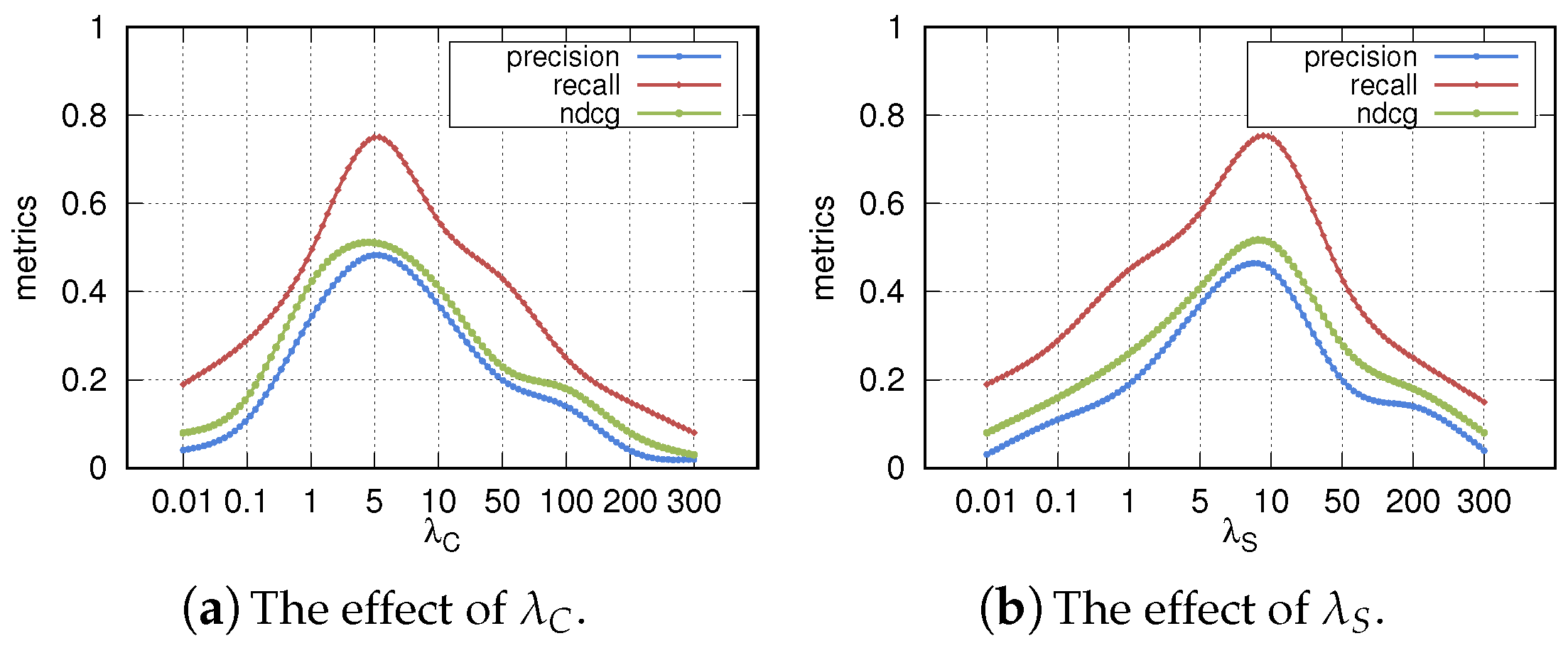
- How do developer–developer collaboration relationships and task–task association relationships (i.e., and ) affect SoftRec?
- RQ4
- How does SoftRec perform when tackling model update and does it help solve the cold start issue?
- RQ5
- Can SoftRec have practical value and be recognized by enterprise users in practice?
4.1. Experimental Settings
4.1.1. Data Collection and Preprocessing
4.1.2. Relationship Mapping
4.1.3. Approaches for Comparison
- PR-CF [4]: a typical CF-based hybrid approach that generates the latent factor models based on the developer–task explicit interaction matrix, and then combines the latent factor models with the tasks’ neighborhoods to capture the similarity between developers and tasks.
- IR+CN [20]: This approach recommends developers based on their social relationships. By mining historical comments, it constructs a weighted graph called comment network (CN) to model developers’ social relationships.
- DMF [38]: a typical matrix factorization model with neural network architecture to learn a common low dimensional space for the representations of users and items.
- NFM [31]: a typical deep learning model that unifies the strengths of factorization machines and deep neural networks for sparse rating modelling.
4.1.4. Parameter Settings
4.1.5. Scenario Description
4.1.6. Performance Evaluation
4.2. Experimental Results and Discussions
4.2.1. Overall Performance Comparison (RQ1)
4.2.2. Performance in Tackling Data Sparsity (RQ2)
4.2.3. Effects of the Multi-Relationship (RQ3)
4.2.4. Performance in Tackling Model Update (RQ4)
4.3. User Study and System Design (RQ5)
4.3.1. Effectiveness of Our Approach
4.3.2. User Interview
4.3.3. System Design
- From the viewpoint of software development, we design the framework based on a series of open source tool chains as much as possible, which follows the idea of open source software and can shield the underlying complexity and improve the development efficiency.
- From the viewpoint of system availability, the framework supports distributed data storage and parallel computing for developer recommendation, which makes it have better performance in big data environment and provide a valuable technical reference for system practice. As far as we know, this technical framework has been adopted by Neusoft Corporation and will be integrated into their commercial product (https://platform.neusoft.com/allproducts/acap) as part of their DevOps tool chains.
5. Threats to Validity
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Gousios, G.; Storey, M.A.; Bacchelli, A. Work practices and challenges in pull-based development: The contributor’s perspective. In Proceedings of the IEEE/ACM 38th International Conference on Software Engineering (ICSE), Austin, TX, USA, 14–22 May 2016; pp. 285–296. [Google Scholar]
- Hannebauer, C.; Patalas, M.; Stünkelt, S.; Gruhn, V. Automatically recommending code reviewers based on their expertise: An empirical comparison. In Proceedings of the IEEE/ACM International Conference on Automated Software Engineering (ASE), Singapore, 3–7 September 2016; pp. 99–110. [Google Scholar]
- Xia, X.; Lo, D.; Wang, X.; Yang, X. Who should review this change?: Putting text and file location analyses together for more accurate recommendations. In Proceedings of the 2015 IEEE International Conference on Software Maintenance and Evolution (ICSME), Bremen, Germany, 29 September–1 October 2015; pp. 261–270. [Google Scholar]
- Xia, Z.; Sun, H.; Jiang, J.; Wang, X.; Liu, X. A hybrid approach to code reviewer recommendation with collaborative filtering. In Proceedings of the IEEE International Workshop on Software Mining (SoftwareMining), Urbana, IL, USA, 3 November 2017; pp. 24–31. [Google Scholar]
- Liu, Z.; Xia, X.; Treude, C.; Lo, D.; Li, S. Automatic Generation of Pull Request Descriptions. In Proceedings of the 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), San Diego, CA, USA, 11–15 November 2019; IEEE: New York, NY, USA, 2019; pp. 176–188. [Google Scholar]
- Thongtanunam, P.; Tantithamthavorn, C.; Kula, R.G.; Yoshida, N.; Iida, H.; Matsumoto, K.I. Who should review my code? A file location-based code-reviewer recommendation approach for modern code review. In Proceedings of the IEEE 22nd International Conference on Software Analysis, Evolution, and Reengineering (SANER), Montreal, QC, Canada, 2–6 March 2015; pp. 141–150. [Google Scholar]
- Alami, A.; Cohn, M.L.; Wasowski, A. Why does code review work for open source software communities? In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019; IEEE: New York, NY, USA, 2019; pp. 1073–1083. [Google Scholar]
- Yan, J.; Sun, H.; Wang, X.; Liu, X.; Song, X. Profiling developer expertise across software communities with heterogeneous information network analysis. In Proceedings of the Tenth Asia-Pacific Symposium on Internetware, Beijing, China, 16 September 2018; pp. 1–9. [Google Scholar]
- Ye, L.; Sun, H.; Wang, X.; Wang, J. Personalized teammate recommendation for crowdsourced software developers. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 3–7 September 2018; pp. 808–813. [Google Scholar]
- MirsaeediFarahani, S. Mitigating Turnover with Code Review Recommendation: Balancing Expertise, Workload, and Knowledge Distribution. Ph.D. Thesis, Concordia University, Montreal, QC, Canada, 2019. [Google Scholar]
- Li, R.; Lin, H.; Shi, Y.; Wang, H. SocialST: Social Liveness and Trust Enhancement Based Social Recommendation. In Proceedings of the 2019 IEEE International Conference on Web Services (ICWS), Milan, Italy, 8–13 July 2019; pp. 139–145. [Google Scholar]
- Ye, B.; Wang, Y. Crowdrec: Trust-aware worker recommendation in crowdsourcing environments. In Proceedings of the 2016 IEEE international conference on web services (ICWS), San Francisco, CA, USA, 2–7 July 2016; pp. 1–8. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.-S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Kabbur, S.; Ning, X.; Karypis, G. Fism: Factored item similarity models for top-n recommender systems. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–13 August 2013; pp. 659–667. [Google Scholar]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 426–434. [Google Scholar]
- Xin, X.; He, X.; Zhang, Y.; Zhang, Y.; Jose, J. Relational collaborative filtering: Modeling multiple item relations for recommendation. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 125–134. [Google Scholar]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.S. Neural Graph Collaborative Filtering. arXiv 2019, arXiv:1905.08108. [Google Scholar]
- Ma, H.; Yang, H.; Lyu, M.R.; King, I. Sorec: Social recommendation using probabilistic matrix factorization. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 931–940. [Google Scholar]
- Jiang, J.; Yang, Y.; He, J.; Blanc, X.; Zhang, L. Who should comment on this pull request? Analyzing attributes for more accurate commenter recommendation in pull-based development. Inf. Softw. Technol. 2017, 84, 48–62. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, H.; Yin, G.; Wang, T. Reviewer recommendation for pull-requests in GitHub: What can we learn from code review and bug assignment? Inf. Softw. Technol. 2016, 74, 204–218. [Google Scholar] [CrossRef]
- Ahmed, T.; Bosu, A.; Iqbal, A.; Rahimi, S. SentiCR: A customized sentiment analysis tool for code review interactions. In Proceedings of the 2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE), Urbana, IL, USA, 30 October–3 November 2017; IEEE: New York, NY, USA, 2017; pp. 106–111. [Google Scholar]
- Bosu, A.; Carver, J.C. How do social interaction networks influence peer impressions formation? a case study. In IFIP International Conference on Open Source Systems; Springer: Berlin, Germany, 2014; pp. 31–40. [Google Scholar]
- Bosu, A.; Carver, J.C. Impact of peer code review on peer impression formation: A survey. In Proceedings of the 2013 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, Baltimore, MD, USA, 10–11 October 2013; pp. 133–142. [Google Scholar]
- Ouni, A.; Kula, R.G.; Inoue, K. Search-based peer reviewers recommendation in modern code review. In Proceedings of the 2016 IEEE International Conference on Software Maintenance and Evolution (ICSME), Raleigh, NC, USA, 2–7 October 2016; pp. 367–377. [Google Scholar]
- Liao, Z.; Wu, Z.; Li, Y.; Zhang, Y.; Fan, X.; Wu, J. Core-reviewer recommendation based on Pull Request topic model and collaborator social network. Soft Comput. 2020, 24, 5683–5693. [Google Scholar] [CrossRef]
- Shin, D. How do users interact with algorithm recommender systems? The interaction of users, algorithms, and performance. Comput. Hum. Behav. 2020, 26, 106344. [Google Scholar] [CrossRef]
- Shin, D.; Zhong, B.; Biocca, F.A. Beyond user experience: What constitutes algorithmic experiences? Int. J. Inf. Manag. 2020, 52, 102061. [Google Scholar] [CrossRef]
- Lin, P.; Song, Q.; Wu, Y. Fact checking in knowledge graphs with ontological subgraph patterns. Data Sci. Eng. 2018, 3, 341–358. [Google Scholar] [CrossRef]
- Zhang, S.; Yao, L.; Sun, A. Deep learning based recommender system: A survey and new perspectives. arXiv 2017, arXiv:1707.07435. [Google Scholar] [CrossRef]
- Xie, F.; Chen, L.; Ye, Y.; Zheng, Z.; Lin, X. Factorization machine based service recommendation on heterogeneous information networks. In Proceedings of the 2018 IEEE International Conference on Web Services (ICWS), San Francisco, CA, USA, 2–7 July 2018; pp. 115–122. [Google Scholar]
- He, X.; Chua, T.S. Neural factorization machines for sparse predictive analytics. In Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 355–364. [Google Scholar]
- Wang, S.; Li, C.; Zhao, K.; Chen, H. Context-aware recommendations with random partition factorization machines. Data Sci. Eng. 2017, 2, 125–135. [Google Scholar] [CrossRef]
- Sadowski, C.; Söderberg, E.; Church, L.; Sipko, M.; Bacchelli, A. Modern code review: A case study at google. In Proceedings of the 40th International Conference on Software Engineering (ICSE): Software Engineering in Practice, Gothenburg, Sweden, 27 May–3 June 2018; pp. 181–190. [Google Scholar]
- He, X.; He, Z.; Song, J.; Liu, Z.; Jiang, Y.G.; Chua, T.S. NAIS: Neural attentive item similarity model for recommendation. IEEE Trans. Knowl. Data Eng. 2018, 30, 2354–2366. [Google Scholar] [CrossRef]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, Bejing, China, 22–24 June 2014; pp. 1188–1196. [Google Scholar]
- Mnih, A.; Salakhutdinov, R.R. Probabilistic matrix factorization. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2008; pp. 1257–1264. [Google Scholar]
- Srinivasan, V.; Sankar, A.R.; Balasubramanian, V. ADINE: An adaptive momentum method for stochastic gradient descent. In Proceedings of the ACM India Joint International Conference on Data Science and Management of Data, Goa, India, 11–13 January 2018; pp. 249–256. [Google Scholar]
- Xue, H.J.; Dai, X.; Zhang, J.; Huang, S.; Chen, J. Deep Matrix Factorization Models for Recommender Systems. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), Melbourne, Australia, 19–25 August 2017; pp. 3203–3209. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; pp. 452–461. [Google Scholar]
- He, X.; He, Z.; Du, X.; Chua, T.S. Adversarial Personalized Ranking for Recommendation. In Proceedings of the SIGIR’18 41st International ACM SIGIR Conference on Research and Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 355–364. [Google Scholar] [CrossRef]
- Huang, Y.; Cui, B.; Jiang, J.; Hong, K.; Zhang, W.; Xie, Y. Real-time video recommendation exploration. In Proceedings of the ACM International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 35–46. [Google Scholar]
- He, X.; Chen, T.; Kan, M.Y.; Chen, X. Trirank: Review-aware explainable recommendation by modeling aspects. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; pp. 1661–1670. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Projects | Tasks# | Developers# | Interactions# |
|---|---|---|---|---|
| GitHub | symfony | 1023 | 1331 | 23,970 |
| akka | 1312 | 207 | 12,464 | |
| elasticsearch | 2751 | 251 | 26,272 | |
| netty | 819 | 307 | 5364 | |
| ipython | 3424 | 421 | 19,158 | |
| GitLab | Workflow | 6210 | 104 | 1035 |
| DI | 2193 | 150 | 19,737 | |
| DataViz | 2107 | 108 | 12,642 | |
| ACAP | 2311 | 125 | 25,421 | |
| APM | 2811 | 103 | 11,244 |
| Datasets | Relationships | Objects | Actions |
|---|---|---|---|
| GitHub | developers’ collaboration relationship | issue_comments, commit_comments, pull_request_comments | comment, reaction, commit |
| developer–task interaction relationship | pull_requests, pull_request_comments | comment, reaction | |
| tasks’ similarity relationship | pull_requests, pull_request_comments | - | |
| GitLab | developers’ collaboration relationship | merge_requests, issues, issue_comments | comment, reaction, commit |
| developer–task interaction relationship | issues, issue_comments, commit_comments | comment, reaction | |
| tasks’ similarity relationship | issues, issue_comments | - |
| Methods | GitHub Dataset | GitLab Dataset | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | ndcg | Precision | Recall | ndcg | |
| PR-CF | 0.3791 | 0.7154 | 0.3513 | 0.3799 | 0.7299 | 0.4135 |
| IR+CN | 0.3248 | 0.6411 | 0.3361 | 0.3145 | 0.6377 | 0.3789 |
| DMF | 0.3399 | 0.6998 | 0.3205 | 0.3615 | 0.6819 | 0.4106 |
| NFM | 0.3413 | 0.6918 | 0.3327 | 0.3369 | 0.7311 | 0.3704 |
| SoftRec | 0.4673 | 0.7633 | 0.4727 | 0.4929 | 0.7701 | 0.5109 |
| Methods | GitHub Dataset | GitLab Dataset | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | ndcg | Precision | Recall | ndcg | |
| SoftRec | 0.4673 | 0.7633 | 0.4727 | 0.4929 | 0.7701 | 0.5109 |
| SoftRec’ | 0.3113 | 0.5742 | 0.2971 | 0.2935 | 0.5707 | 0.3419 |
| Datasets | k | precision | recall | ndcg | |||
|---|---|---|---|---|---|---|---|
| fullUpdate | fastUpdate | fullUpdate | fastUpdate | fullUpdate | fastUpdate | ||
| github | 1 | 0.6991 | 0.7103 | 0.2801 | 0.2912 | 0.2911 | 0.3133 |
| 2 | 0.6622 | 0.6819 | 0.3106 | 0.3262 | 0.283 | 0.3123 | |
| 3 | 0.5523 | 0.5756 | 0.5344 | 0.5445 | 0.4391 | 0.4423 | |
| 4 | 0.4632 | 0.4911 | 0.6732 | 0.6819 | 0.5057 | 0.5212 | |
| 5 | 0.4301 | 0.4673 | 0.6903 | 0.7433 | 0.4851 | 0.4727 | |
| gitlab | 1 | 0.7439 | 0.7811 | 0.251 | 0.281 | 0.6784 | 0.6903 |
| 2 | 0.6312 | 0.6624 | 0.3643 | 0.3878 | 0.6701 | 0.6832 | |
| 3 | 0.5782 | 0.5901 | 0.5687 | 0.5911 | 0.5689 | 0.5811 | |
| 4 | 0.4613 | 0.4781 | 0.6433 | 0.6792 | 0.391 | 0.4032 | |
| 5 | 0.4697 | 0.4829 | 0.7013 | 0.770 | 0.4581 | 0.4909 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, X.; Wang, B.; Yang, X. SoftRec: Multi-Relationship Fused Software Developer Recommendation. Appl. Sci. 2020, 10, 4333. https://doi.org/10.3390/app10124333
Xie X, Wang B, Yang X. SoftRec: Multi-Relationship Fused Software Developer Recommendation. Applied Sciences. 2020; 10(12):4333. https://doi.org/10.3390/app10124333
Chicago/Turabian StyleXie, Xinqiang, Bin Wang, and Xiaochun Yang. 2020. "SoftRec: Multi-Relationship Fused Software Developer Recommendation" Applied Sciences 10, no. 12: 4333. https://doi.org/10.3390/app10124333
APA StyleXie, X., Wang, B., & Yang, X. (2020). SoftRec: Multi-Relationship Fused Software Developer Recommendation. Applied Sciences, 10(12), 4333. https://doi.org/10.3390/app10124333