2.3. Double-Shot Transfer Learning
Transfer learning is a powerful technique that allows knowledge to be transferred across various tasks of neural networks. In transfer learning, a pre-trained network that has already learned informative features from a certain image classification task can be used as a starting point to learn a new task using a smaller number of training samples. Knowledge transferring can be done by fine-tuning some layers in the pre-trained network, such as input layer, fully-connected layer, classification layer, and train the pre-trained network on a new dataset. Fine-tuning a pre-trained network usually produces better accuracy, and it is faster than training a new network from scratch [
25]. It has been shown in a previous work that transfer learning is very effective when the source and target domains/tasks are similar. In the previous studies, instead of learning from scratch, SSTL takes advantage of knowledge that comes from previously learned datasets, especially when the training samples in the target domain are scarce. Unfortunately, SSTL has been applied without taking into account that these pre-trained models had been trained on ImageNet, which has different feature space and distribution from our target datasets. In other words, the previous works did not take into account the relationship between source and target domain when SSTL is applied. A domain can be represented as
, where
is the feature space,
is the probability distribution function, and
. A task can be represented by
, where
is the label space and
is the objective predictive function.
can be learned from the training data, which consists of pairs
, where
and
. The function
can be used to predict the corresponding label,
, of a new instance
x.
can also be considered as a conditional probability function
[
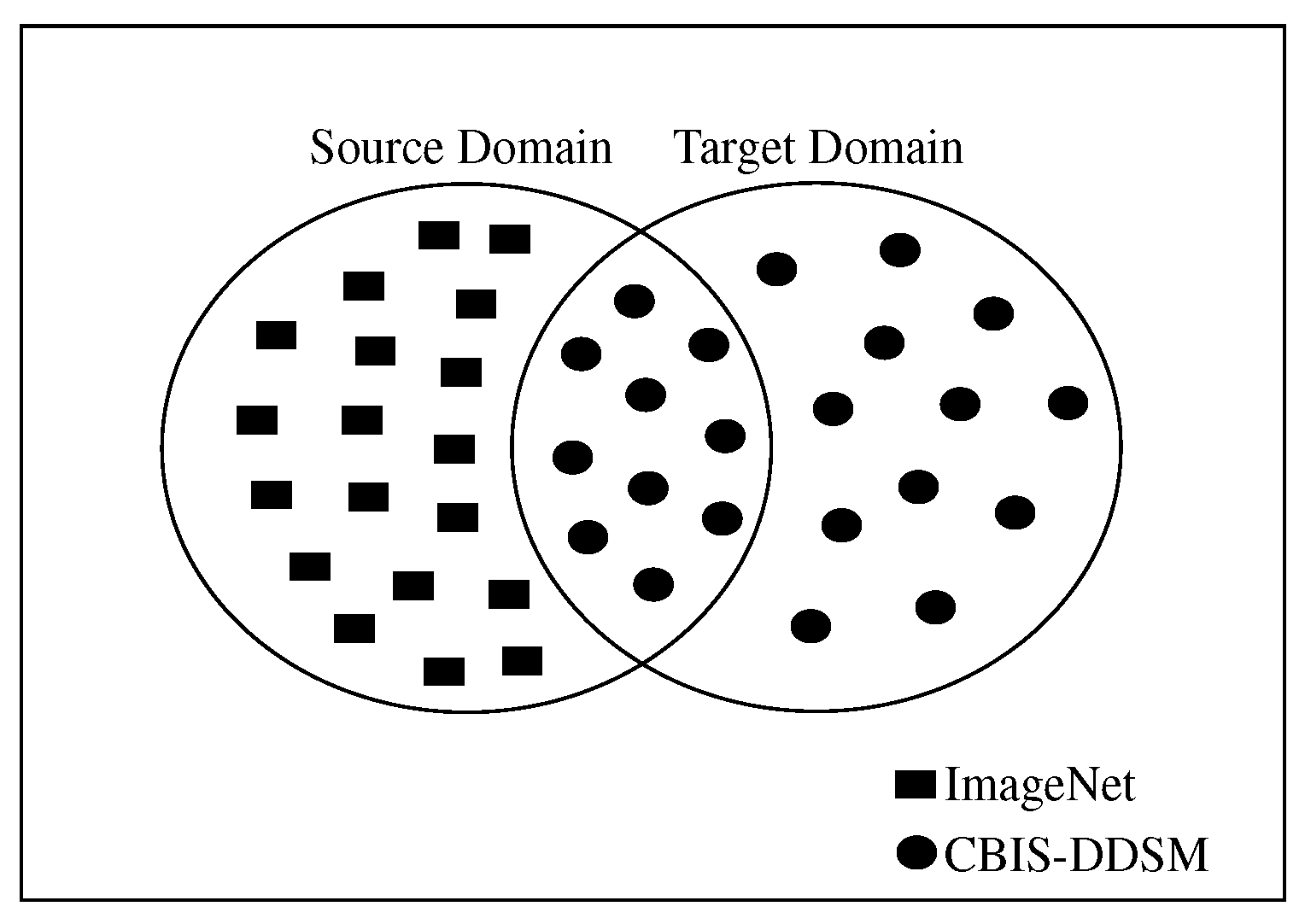
26]. In SSTL, given a domain source
for a learned task
can help to learn a target task
of the domain
. In most of the cases,
and/or
. However, the DSTL aims to bring the marginal probability distributions of both domains
and
similar to each other,
, by providing
with a large number of instances that are similar to
, especially when
has insufficient training samples. Hence, the performance of the prediction function
for learning task
can be improved. In most cases,
data are larger than
data. Unlike TrAdaBoost [
27] that filters out instances which are dissimilar to the target domain in source domains, the proposed DSTL adds new instances to the source domain
that are similar to the
to update the weights of the parameters in the pre-trained models in the
and form a distribution similar to the target domain.
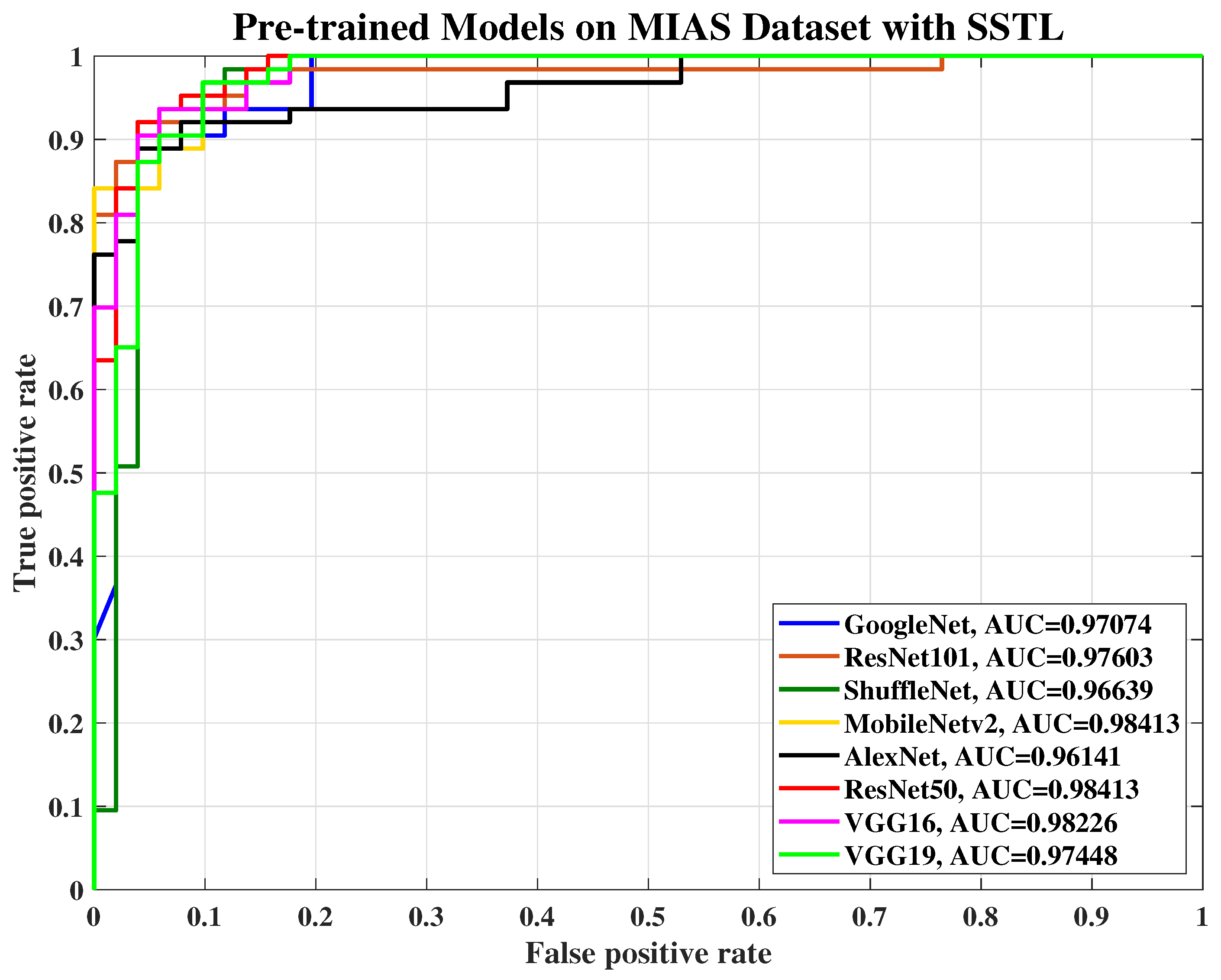
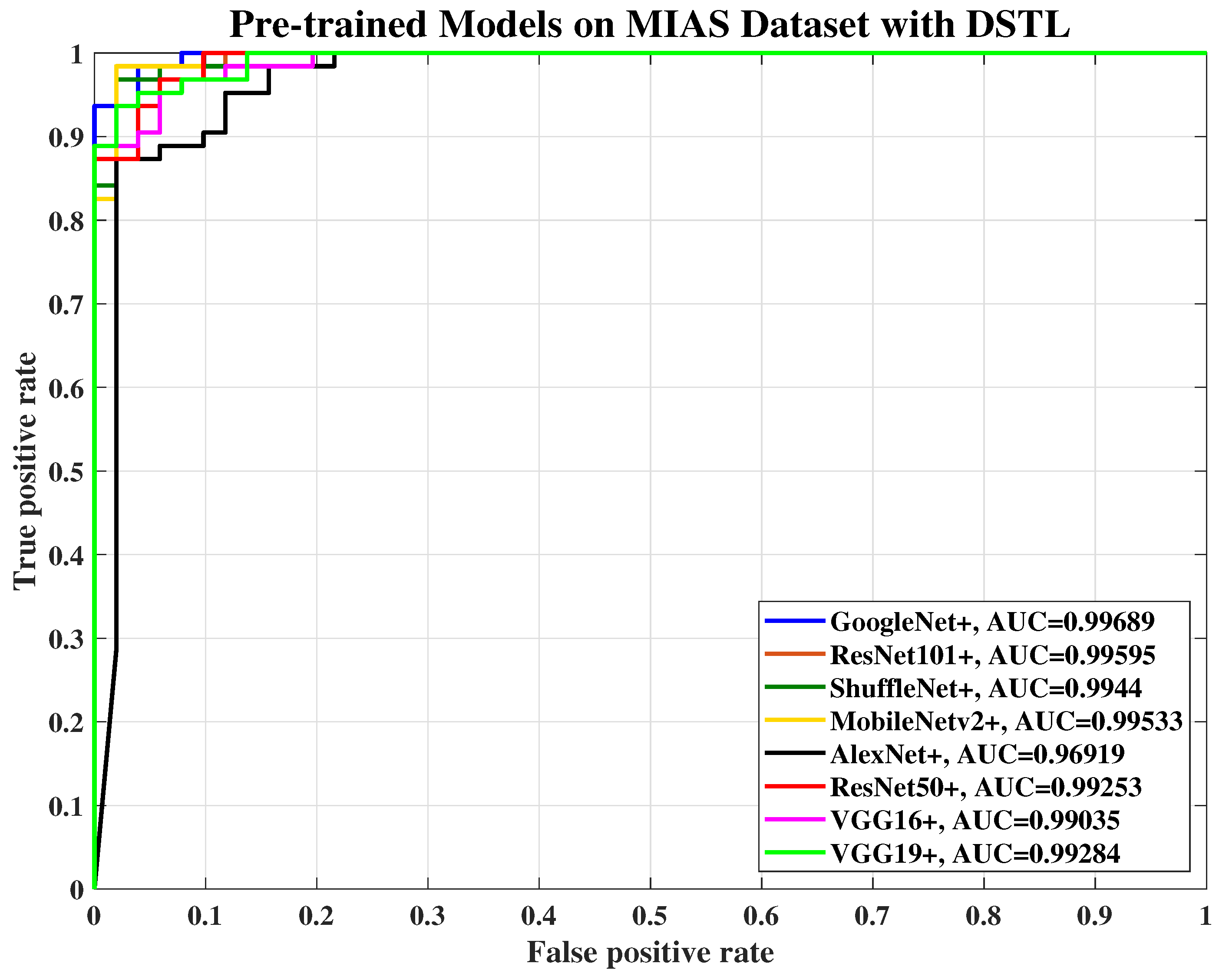
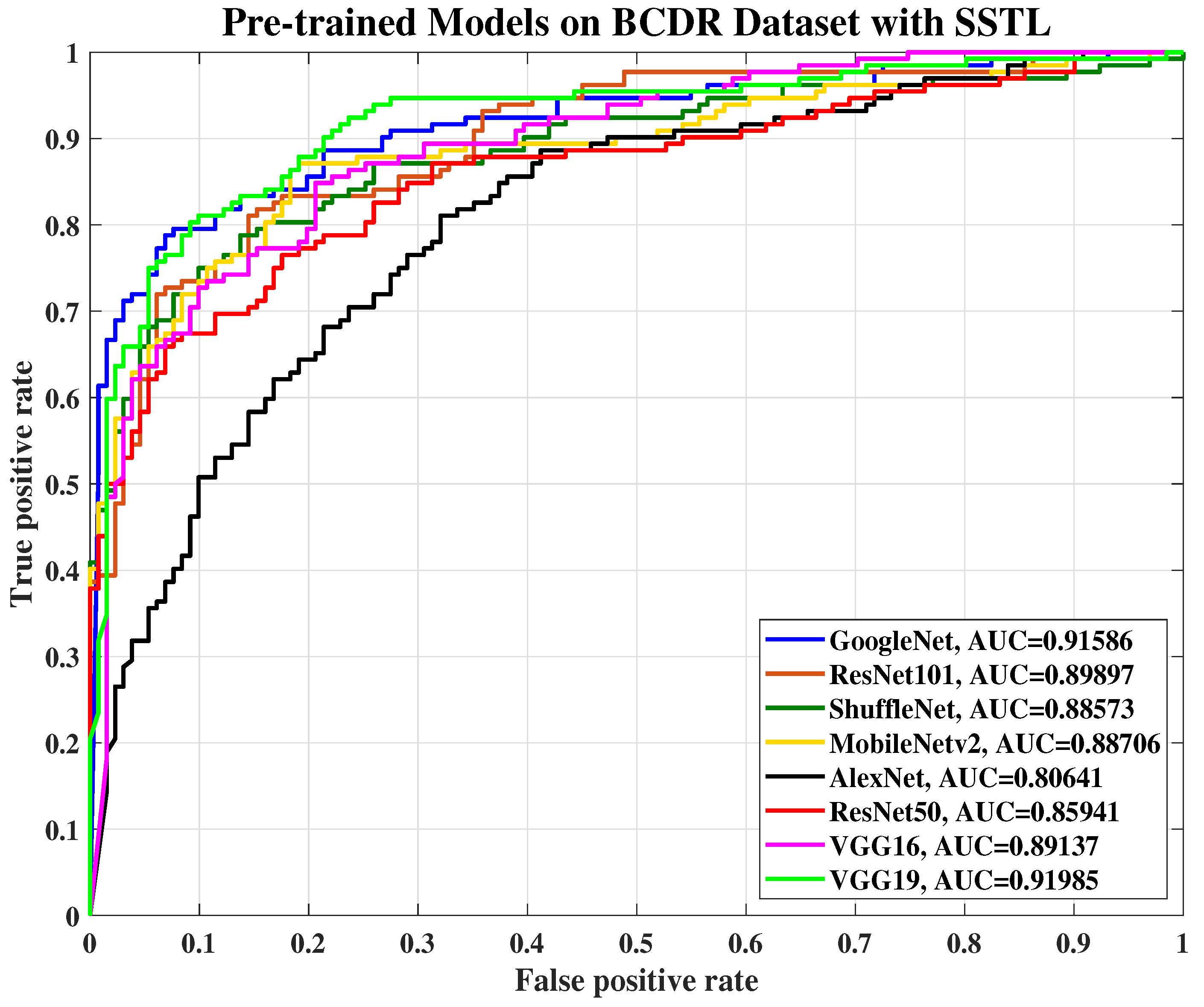
Figure 3 and
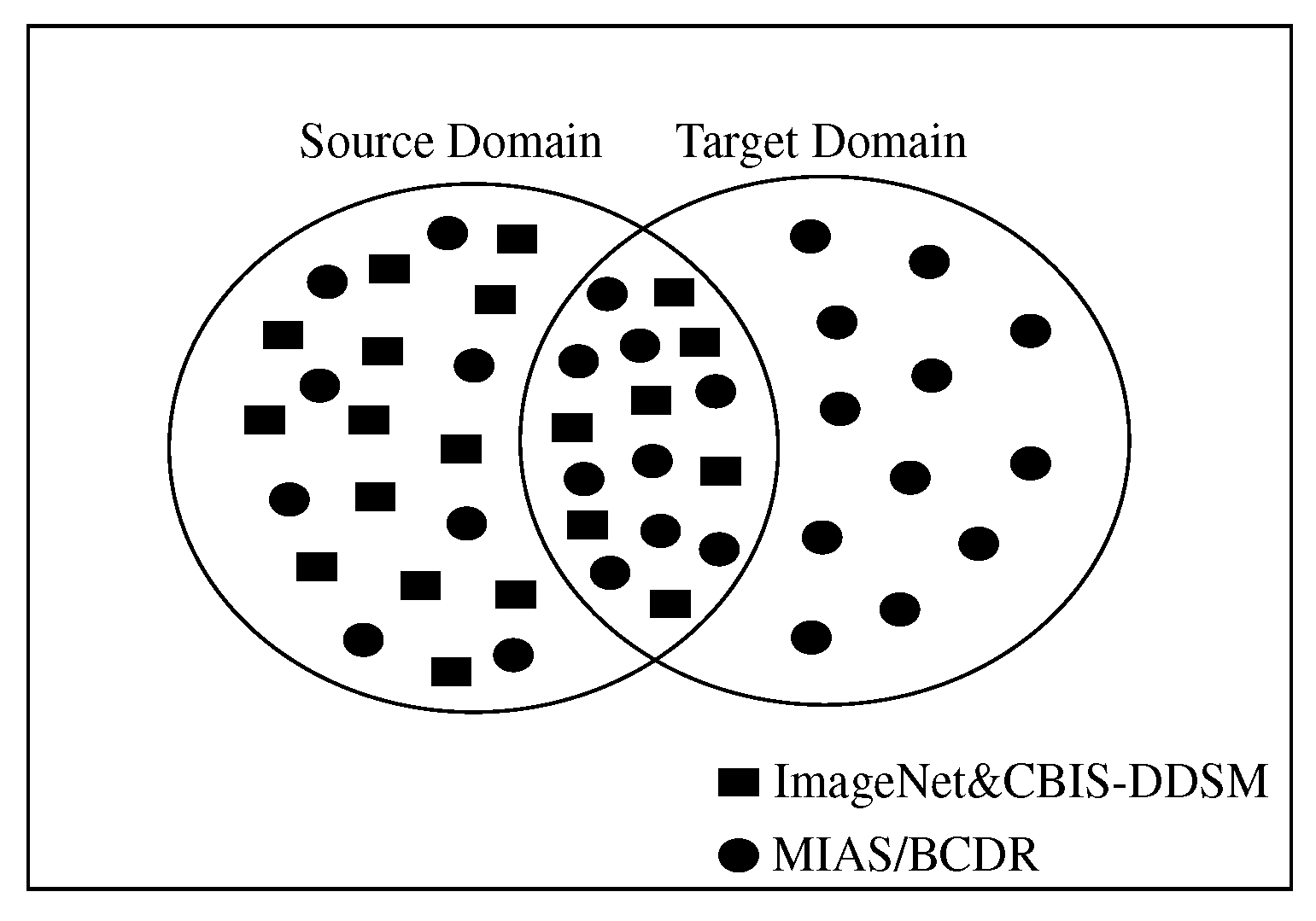
Figure 4 show a sketch of the instances transferring in SSTL and DSTL respectively.
Definition 1 (Standard Transfer Learning).
Given a source domain and learning task , a target domain and learning task , transfer learning aims to help improve the learning of the target predictive function in using the knowledge in and , where and/or . implies that either or . implies that either or .
Definition 2 (DSTL).
Given a source domain and learning task , a target domain and learning task , transfer learning aims to help improve the learning of the target predictive function in using the knowledge in and , where and . implies that and . implies that and .
In our context, the learning task is image classification (Benign or Malignant), and each pixel or weight is taken as a feature, hence is the space of all pixel vectors, is the ith pixel vector corresponding to some images and X is a specific learning sample. Additionally, is the set of all labels, which is Benign, Malignant for the classification task, and is “Benign” or “Malignant”. In our context, can be a set of weights vectors together with their associated Benign or Malignant class labels. Based on the above DSTL definition, a domain is a pair , hence, the condition implies that and . This indicates that the images features or their marginal distributions in both and are related. Similarly, a task is defined as a pair , hence, the condition implies that and . When the = and = , the learning task becomes a traditional machine learning task. Moreover, when , then either (1) or (2) but , where and . In our case, situation (1) refers to when one set of images is medical images and the other set is natural images. Situation (2) can correspond to when the and the images come from different patients or sources. Eventually, since medical images share many features in common compared to natural images, DSTL technique creates an implicit relationship between and and extracts better feature maps than the pr-trained models that have been only trained on natural images.
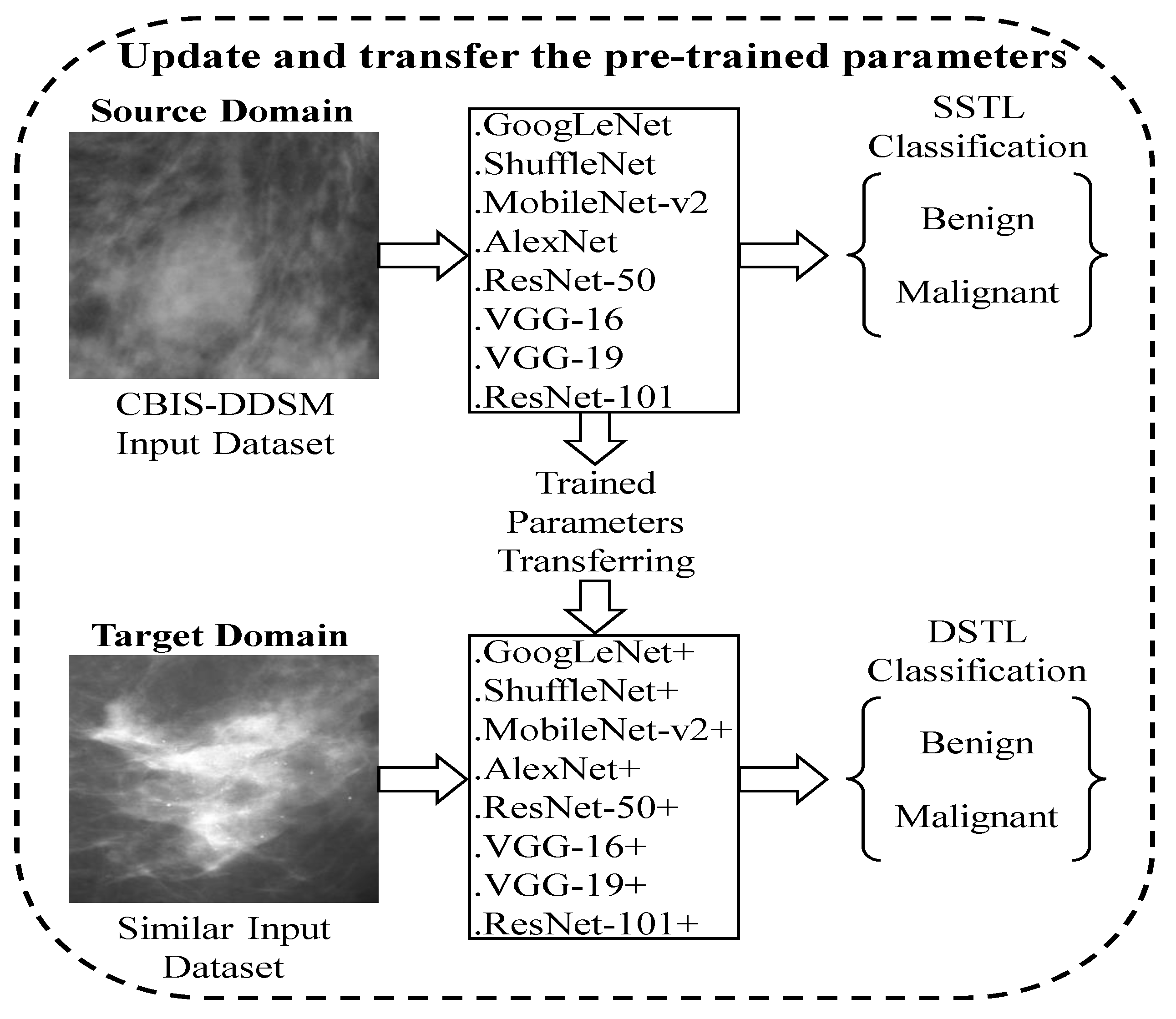
DSTL can be considered as a new strategy for adjusting the weights of the pre-trained models by mapping the instances from
and
to a new domain space. The new space will contain instances from
and
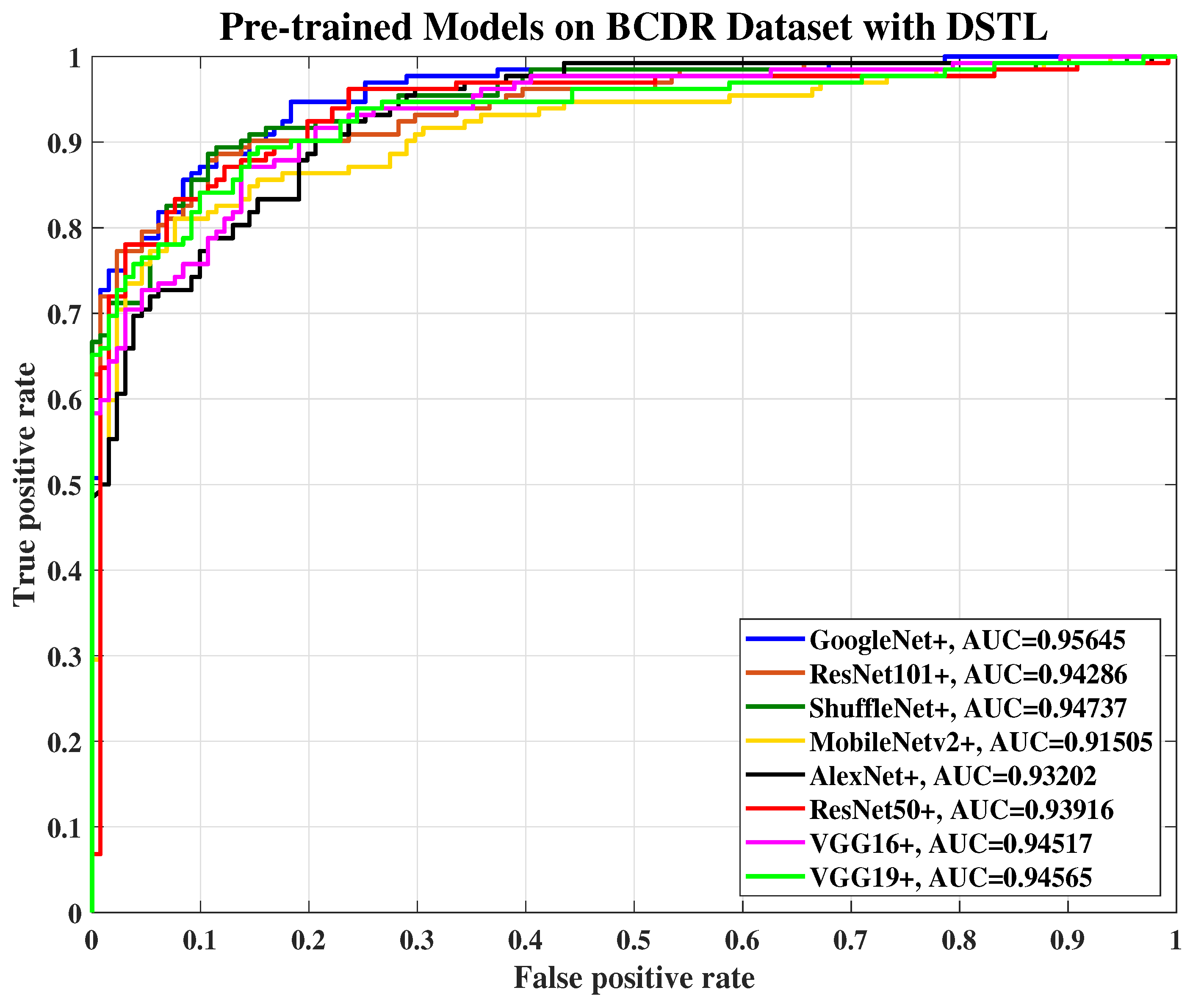
, making it domain invariant. In this research, various pr-trained models were fine-tuned on 98,967 of the augmented CBIS-DDSM dataset, and saved as the name of the original pre-trained network followed by the symbol (+) to distinguish them from the original pre-trained networks that were only trained on ImageNet dataset. Next, the updated pre-trained models (+) were fine-tuned for the second time on the augmented images of the target datasets of MIAS and BCDR.
Figure 5 illustrates the process of DSTL. All the pre-trained networks that have been used in this research share three common layers namely input layer, FC layer, and classification layer. By fine-tuning these 3 layers using the CBIS-DDSM dataset first, we can update all the learnable parameters, and then augment them on the target datasets of MIAS and BCDR datasets.
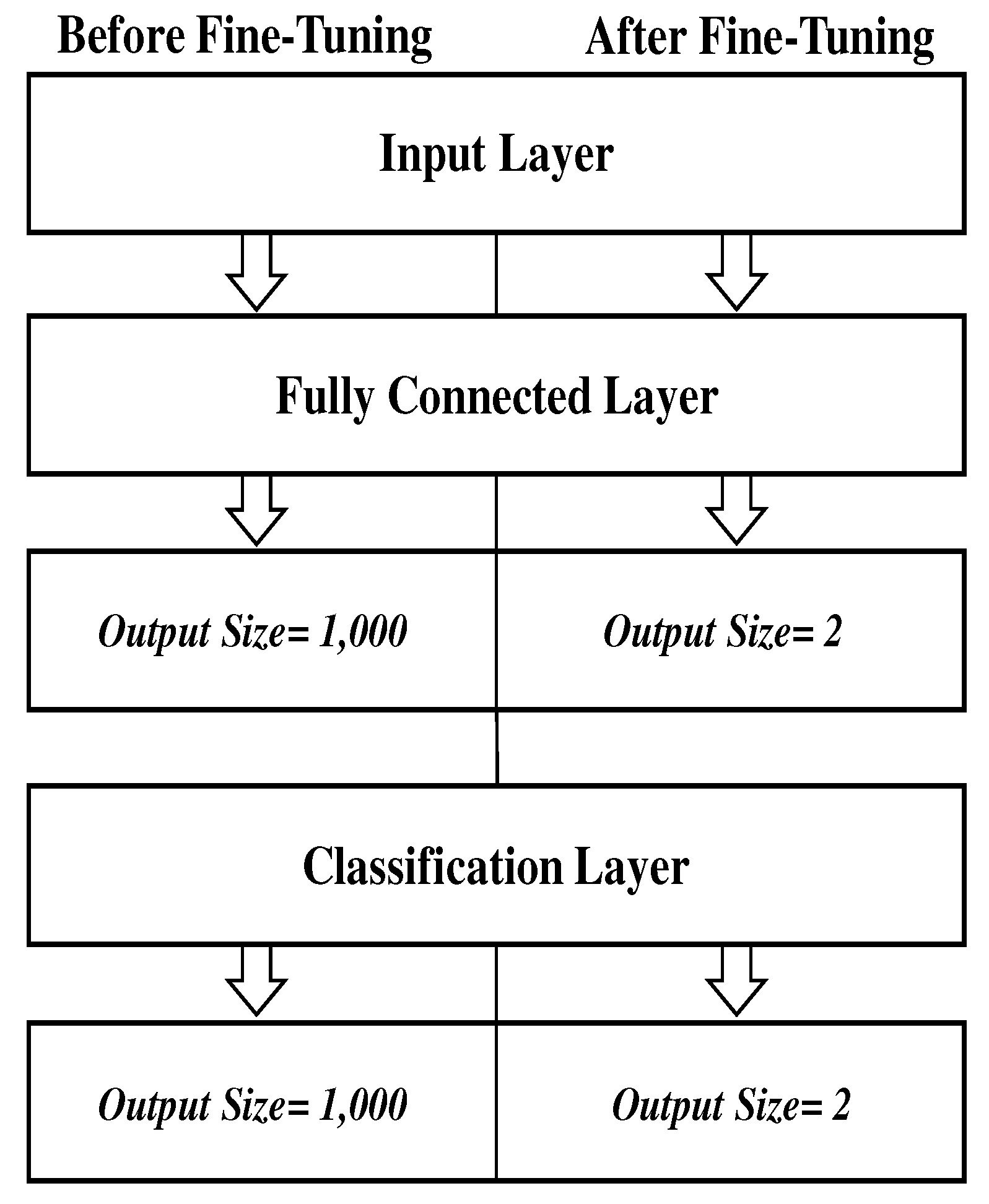
Figure 6 shows the fine-tuned layers where the input layer size is kept the same as the original one
except for Alexnet where the input size was set to
. FC and classification layers were fine-tuned in every pre-trained model. Every pre-trained model has been fine-tuned by replacing the output size parameter of FC and classification layers from classifying images of 1,000 object categories to 2 classes of benign and malignant. The classification layer computes the cross entropy loss with mutually exclusive classes. The classification layer takes the output from the Softmax layer and allocates each input to one of the
K mutually exclusive classes using the cross entropy function. In
Figure 6, we only mention the layers which have been fine-tuned respectively.
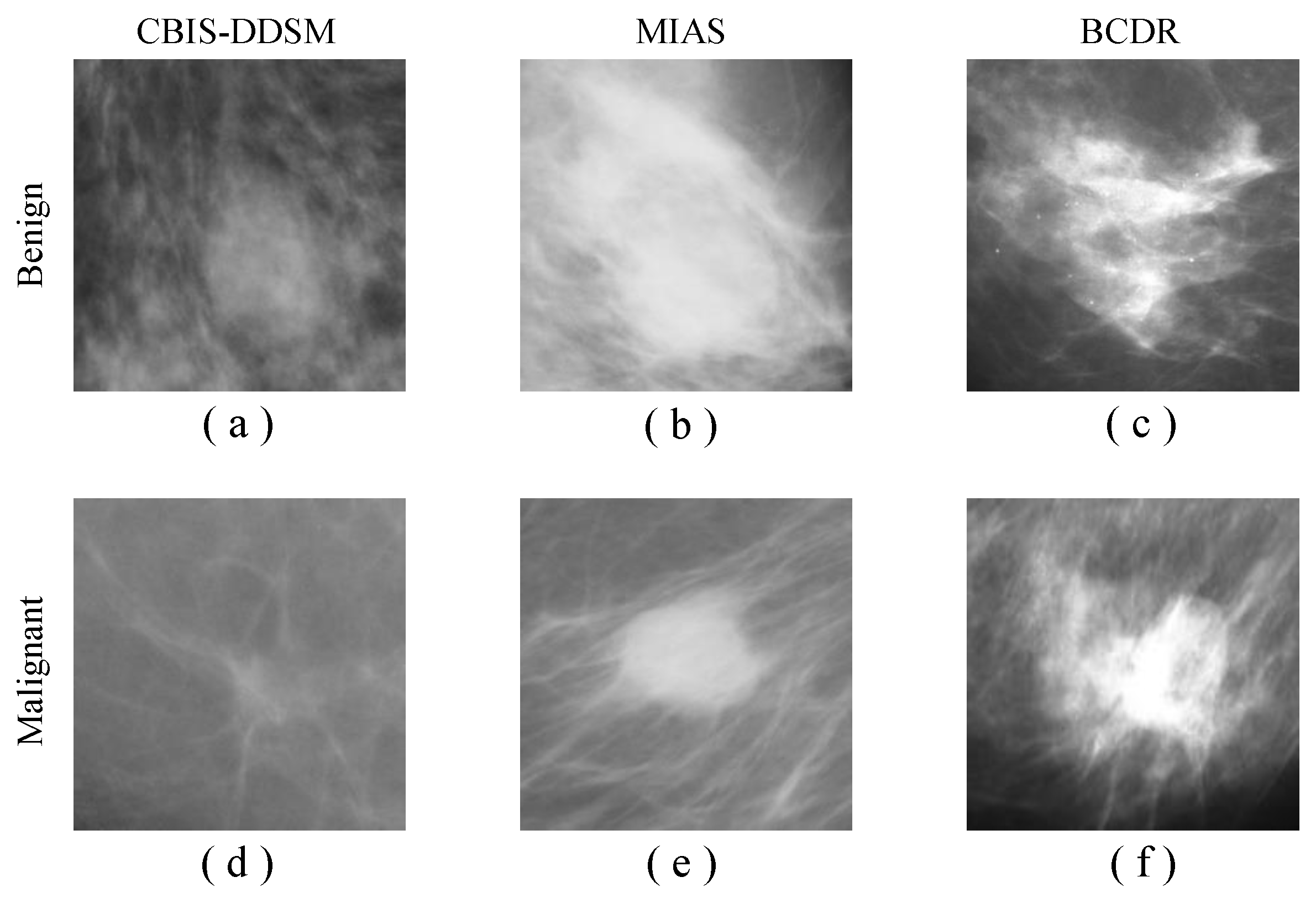
It is worth mentioning that although the CBIS-DDSM, MIAS, and BCDR datasets are similar, they come from different sources. Thus, these medical datasets have not been combined as a single dataset for this research experiment. This will shed light on the use of the DSTL technique in various medical image classification tasks such as liver cancer, lung cancer, kidney cancer, and other types of cancers, where the collection of high-quality annotated images is very expensive. However, due to the availability of the breast cancer datasets, the DSTL has been applied to the breast cancer classification.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}