Dialogue Enhanced Extended Reality: Interactive System for the Operator 4.0



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Background
2.1. Industrial Augmented Reality Systems
2.2. Spoken Dialogue Systems
3. Conceptual System
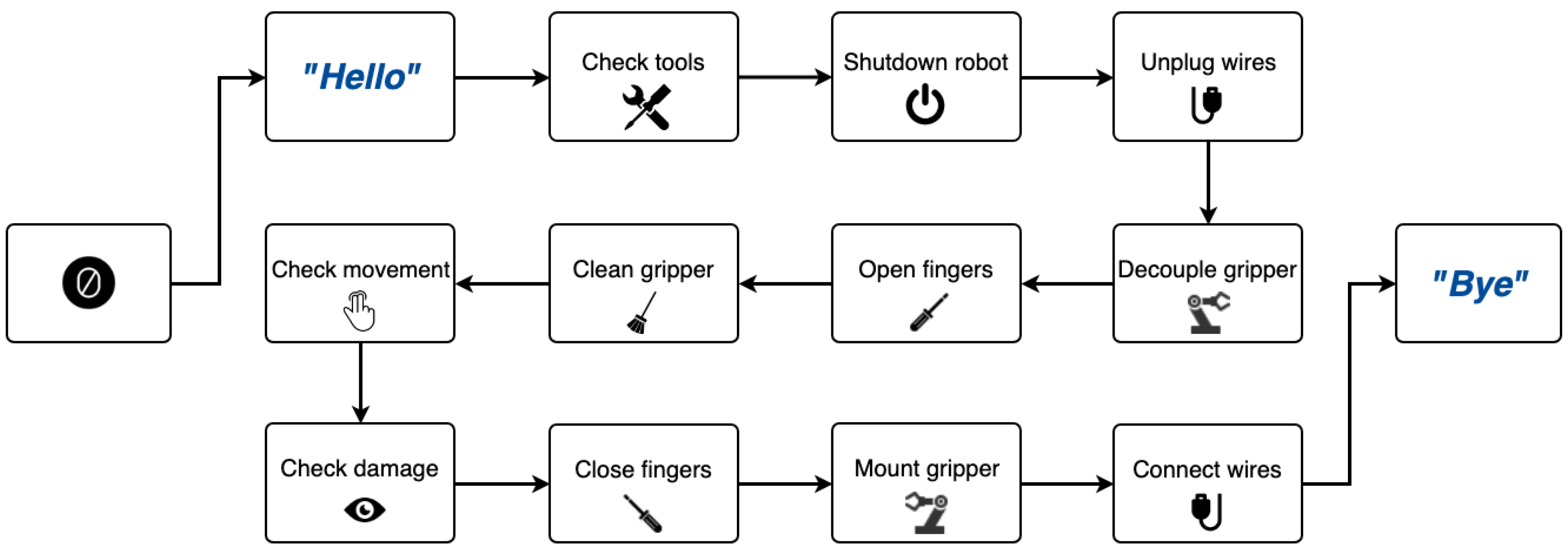
Conceptual Workflow
4. Use Cases
4.1. Use Case 1: Universal Robot’s Gripper Maintenance
4.2. Use Case 2: Industrial Electrical Wiring
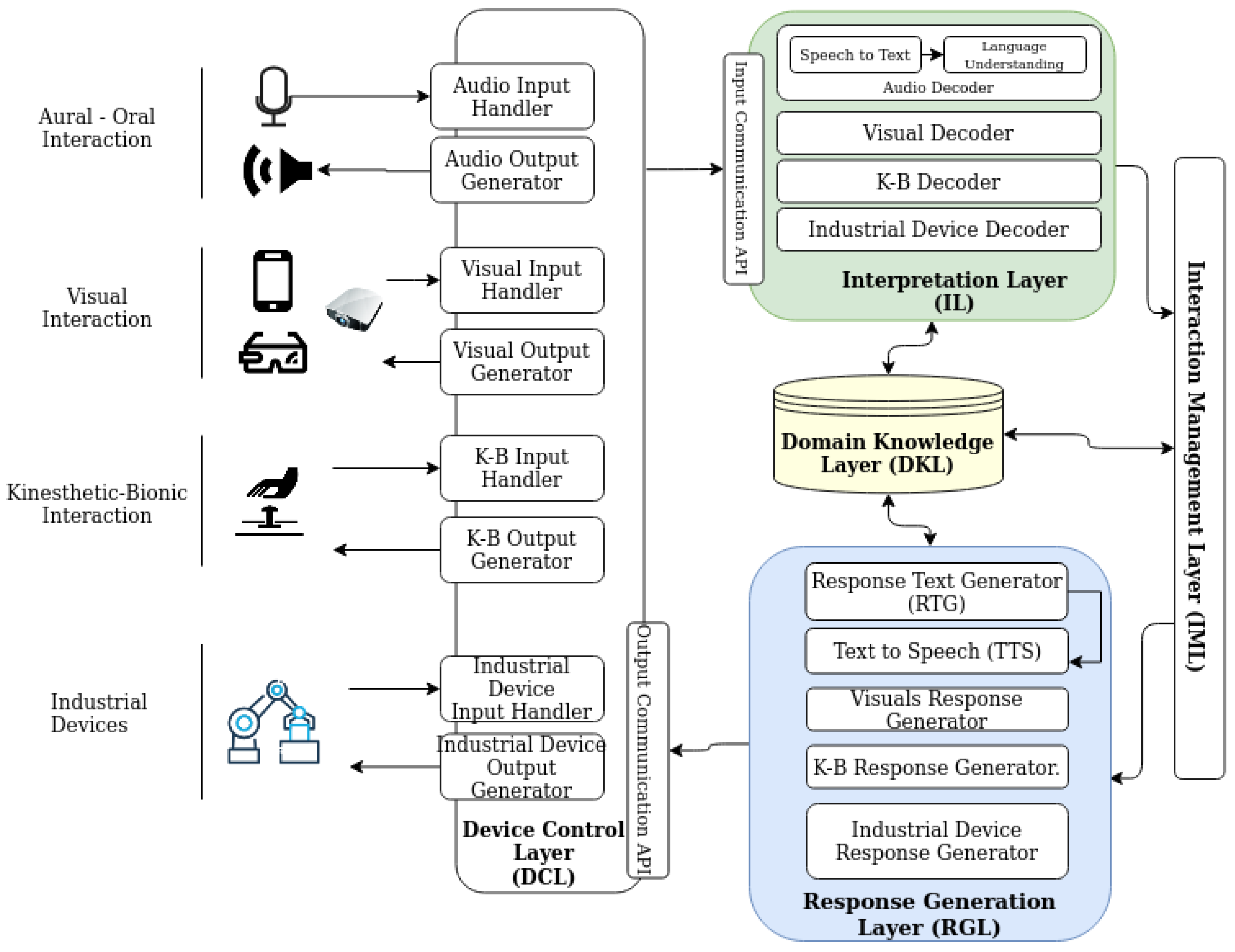
5. System Implementation
- The DCL is responsible for gathering the operators’ input to communicate with the system. For the proposed use cases, the first one uses only voice input while the second one combines additional devices such as optical readers too. For the voice interaction, microphones with noise cancellation capture the audio signals. These signals are streamed using media streaming libraries such as FFmpeg into an energy-based automata that discards any silent or noisy audio segment. The remaining audio segment is sent to the Input Communication API.
- The IL has to encode the raw and unstructured data into formats that can be interpreted by machines and ontologies. In the presented use cases, the audio segments are transcribed to text by the Speech-to-Text module. The Language Understanding module encodes transcriptions into a semantic structure that can be easily interpreted by the IML. As it is commonly done for Spoken Dialogue Systems, we use a scheme based on act-slot-value sets for representing symbolic semantic meaning of the operator input. The semantic representation of the user action is dispatched to the IML for processing. For the optical reader input, the detected wires’ label is transferred to the IML to contextualise the interaction.
- The DKL works both as the persistence layer and as semantic ontology for each system. The persistence layer stores the interaction context of each operator to be kept turn-by-turn, as well as the specific domain knowledge encoded in an ontology. In both use cases, this ontology describes the know-how of the steps to perform in the process and their sequence, the physical devices that interact during the task and their properties (e.g., screwdriver size, or wire’s location). In addition, it encodes the physical devices tied to each step of the interaction to handle ambiguous questions, for example, if the operator asks "Which size?" in the Open fingers step of the first use case, the ontology relations are used by the system’s IML to understand that the operator refers to the size of the tool required to this specific step, the precision screwdriver, and not to the hex key used in the Decouple gripper step.
- The IML plans and selects the next action to be performed by the system using both contextual information and the semantic concepts received from the IL. First, it retrieves the task information and the planning rules to complete the task from the Domain Knowledge Layer, and then it defines a strategy to reach the user’s objectives. In other words, it consists of a set of expert rules that evaluate events x and the interaction context into system actions y and the also updates the context based on the Attributed Probabilistic Finite State Bi-Automata schema as in [33,43,46]. This context, which the IML reads from and writes to the DKL, is maintained and updated through the interaction. In our particular tasks, the input x corresponds to the user semantic representation and the context c, which takes into account the interaction state (e.g., current step), the history of shown AR animations or the selected wire.
- The RGL translates the IML’s output actions into understandable interactions for the users, for example, answering the information in natural language or augmenting the user’s surroundings with visuals. For our particular use case, the system uses the Text-to-Speech module to generate synthesised audio when speech modality is required, using the module described in AhoTTS [47]. Additionally, this layer computes suitable visual properties for the action, which include animation selection, as well as feedback duration.
- The commands given by the RLG are dispatched to the DCL, which interfaces with the output devices. For the presented use cases, visual and aural interfaces are used to communicate with the operators.
6. Results
- Self-confidence: this dimension involves those questions related to the ability to solve the problems that arise during the industrial processes without the help of any element other than the system itself.
- Learning Curve: this dimension measures how hard it was for the operators to adopt the proposed systems and to learn the required concepts and practices to use them.
- Efficiency: this dimension involves those questions related to the perceived efficiency by the users, i.e., if they find the system useful and helpful to improve their work processes.
- Ease-of-use: this dimension involves questions regarding the systems’ difficulty. This is related to the naturalness of the system and whether it was perceived as intuitive by the operators.
- Consistency: this dimension measures how predictable the usage of the system is in terms of user experience.
Usability Results
7. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Barfield, W.; Williams, A. Cyborgs and enhancement technology. Philosophies 2017, 2, 4. [Google Scholar] [CrossRef]
- Aneesh, A. Virtual Migration: The Programming of Globalization; Duke University Press: Durham, NC, USA, 2006. [Google Scholar]
- Simões, B.; De Amicis, R.; Barandiaran, I.; Posada, J. Cross reality to enhance worker cognition in industrial assembly operations. Int. J. Adv. Manuf. Technol. 2019, 105, 1–14. [Google Scholar] [CrossRef]
- Posada, J.; Zorrilla, M.; Dominguez, A.; Simoes, B.; Eisert, P.; Stricker, D.; Rambach, J.; Döllner, J.; Guevara, M. Graphics and media technologies for operators in industry 4.0. IEEE Comput. Graph. Appl. 2018, 38, 119–132. [Google Scholar] [CrossRef] [PubMed]
- Segura, Á.; Diez, H.V.; Barandiaran, I.; Arbelaiz, A.; Álvarez, H.; Simões, B.; Posada, J.; García-Alonso, A.; Ugarte, R. Visual computing technologies to support the Operator 4.0. Comput. Ind. Eng. 2018, 139, 105550. [Google Scholar] [CrossRef]
- Girard, J.; Girard, J. Defining knowledge management: Toward an applied compendium. Online J. Appl. Knowl. Manag. 2015, 3, 1–20. [Google Scholar]
- Schmidt, B.; Borrison, R.; Cohen, A.; Dix, M.; Gärtler, M.; Hollender, M.; Klöpper, B.; Maczey, S.; Siddharthan, S. Industrial Virtual Assistants: Challenges and Opportunities. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018; ACM: New York, NY, USA, 2018; pp. 794–801. [Google Scholar]
- Caudell, T.P.; Mizell, D.W. Augmented reality: An application of heads-up display technology to manual manufacturing processes. In Proceedings of the Twenty-Fifth Hawaii International Conference on System Sciences, Kauai, HI, USA, 7–10 January 1992; IEEE: Piscataway, NJ, USA, 1992; Volume 2, pp. 659–669. [Google Scholar]
- Kollatsch, C.; Schumann, M.; Klimant, P.; Wittstock, V.; Putz, M. Mobile augmented reality based monitoring of assembly lines. Procedia CIRP 2014, 23, 246–251. [Google Scholar] [CrossRef]
- Sand, O.; Büttner, S.; Paelke, V.; Röcker, C. smart. assembly–projection-based augmented reality for supporting assembly workers. In International Conference on Virtual, Augmented and Mixed Reality; Springer: Berlin, Germany, 2016; pp. 643–652. [Google Scholar]
- Rodriguez, L.; Quint, F.; Gorecky, D.; Romero, D.; Siller, H.R. Developing a mixed reality assistance system based on projection mapping technology for manual operations at assembly workstations. Proc. Comput. Sci. 2015, 75, 327–333. [Google Scholar] [CrossRef]
- Petersen, N.; Pagani, A.; Stricker, D. Real-time modeling and tracking manual workflows from first-person vision. In Proceedings of the 2013 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Adelaide, Australia, 1–4 October 2013; pp. 117–124. [Google Scholar] [CrossRef]
- Álvarez, H.; Lajas, I.; Larrañaga, A.; Amozarrain, L.; Barandiaran, I. Augmented reality system to guide operators in the setup of die cutters. Int. J. Adv. Manuf. Technol. 2019, 103, 1543–1553. [Google Scholar] [CrossRef]
- Baumeister, J.; Ssin, S.Y.; ElSayed, N.A.; Dorrian, J.; Webb, D.P.; Walsh, J.A.; Simon, T.M.; Irlitti, A.; Smith, R.T.; Kohler, M.; et al. Cognitive Cost of Using Augmented Reality Displays. IEEE Trans. Vis. Comput. Graph. 2017, 23, 2378–2388. [Google Scholar] [CrossRef]
- Industrial Augmented Reality. Industrial Augmented Reality—Wikipedia, The Free Encyclopedia. 2019. Available online: https://en.wikipedia.org/wiki/Industrial_augmented_reality (accessed on 6 June 2012).
- Malỳ, I.; Sedláček, D.; Leitão, P. Augmented reality experiments with industrial robot in industry 4.0 environment. In Proceedings of the 2016 IEEE 14th International Conference on Industrial Informatics (INDIN), Poitiers, France, 18–21 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 176–181. [Google Scholar]
- Song, P.; Goh, W.B.; Hutama, W.; Fu, C.W.; Liu, X. A handle bar metaphor for virtual object manipulation with mid-air interaction. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Poitiers, France, 18–21 July 2012; ACM: New York, NY, USA, 2012; pp. 1297–1306. [Google Scholar]
- Zander, T.O.; Gaertner, M.; Kothe, C.; Vilimek, R. Combining eye gaze input with a brain–computer interface for touchless human–computer interaction. Int. J. Hum.-Comput. Inter. 2010, 27, 38–51. [Google Scholar] [CrossRef]
- Parker, C.L.; O’hanlon, M.L.W.; Lovitt, A.; Farmer, J.R. Interaction and Management of Devices Using Gaze Detection. US Patent 9,823,742, 21 November 2017. [Google Scholar]
- Stokic, D.; Kirchhoff, U.; Sundmaeker, H. Ambient intelligence in manufacturing industry: Control system point of view. In Proceedings of the 8th IASTED International Conference on Control and Applications, Montreal, QC, Canada, 26 May 2006; pp. 24–26. [Google Scholar]
- De Amicis, R.; Ceruti, A.; Francia, D.; Frizziero, L.; Simões, B. Augmented Reality for virtual user manual. Int. J. Interact. Des. Manuf. IJIDeM 2018, 12, 689–697. [Google Scholar] [CrossRef]
- Simões, B.; Álvarez, H.; Segura, A.; Barandiaran, I. Unlocking augmented interactions in short-lived assembly tasks. In Proceedings of the 13th International Conference on Soft Computing Models in Industrial and Environmental Applications, San Sebastian, Spain, 3–8 June 2018; Springer: Berlin, Germany, 2018; pp. 270–279. [Google Scholar]
- Gupta, L.; Ma, S. Gesture-based interaction and communication: Automated classification of hand gesture contours. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2001, 31, 114–120. [Google Scholar] [CrossRef]
- Gorin, A.L.; Riccardi, G.; Wright, J.H. How may I help you? Speech Commun. 1997, 23, 113–127. [Google Scholar] [CrossRef]
- Abella, A.; Brown, M.; Buntschuh, B. Developing principles for dialog-based interfaces. In Proceedings of the ECAI Spoken Dialog Systems Workshop, Budapest, Hungary, 13 August 1996. [Google Scholar]
- Lemon, O.; Gruenstein, A.; Battle, A.; Peters, S. Multi-tasking and collaborative activities in dialogue systems. In Proceedings of the 3rd SIGdial Workshop on Discourse and Dialogue, Philadelphia, PA, USA, 11–12 July 2002; pp. 113–124. [Google Scholar]
- Serras, M.; Perez, N.; Torres, M.I.; Del Pozo, A. Entropy-driven dialog for topic classification: Detecting and tackling uncertainty. In Dialogues with Social Robots; Springer: Berlin, Germany, 2017; pp. 171–182. [Google Scholar]
- Bohus, D.; Rudnicky, A.I. LARRI: A language-based maintenance and repair assistant. In Spoken Multimodal Human-Computer Dialogue in Mobile Environments; Springer: Berlin, Germany, 2005; pp. 203–218. [Google Scholar]
- Bohus, D.; Rudnicky, A.I. Error handling in the RavenClaw dialog management framework. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Stroudsburg, PA, USA, 2005; pp. 225–232. [Google Scholar]
- Li, T.J.J.; Labutov, I.; Myers, B.A.; Azaria, A.; Rudnicky, A.I.; Mitchell, T.M. An End User Development Approach for Failure Handling in Goal-oriented Conversational Agents. In Studies in Conversational UX Design; Springer: Berlin, Germany, 2018. [Google Scholar]
- Dowding, J.; Hockey, B.; Rayner, M.; Hieronymus, J.; Bohus, D.; Boven, B.; Blaylock, N.; Campana, E.; Early, S.; Gorrell, G.; et al. Talking through Procedures: An Intelligent Space Station Procedure Assistant. Demonstrations. 2003. Available online: https://www.aclweb.org/anthology/E03-2001/ (accessed on 6 June 2020).
- Raux, A.; Bohus, D.; Langner, B.; Black, A.W.; Eskenazi, M. Doing research on a deployed spoken dialogue system: One year of Let’s Go! experience. In Proceedings of the 9th International Conference on Spoken Language Processing, Pittsburgh, PA, USA, 17–21 September 2006. [Google Scholar]
- Serras, M.; Torres, M.I.; Del Pozo, A. Online learning of attributed bi-automata for dialogue management in spoken dialogue systems. In Iberian Conference on Pattern Recognition and Image Analysis; Springer: Berlin, Germany, 2017; pp. 22–31. [Google Scholar]
- Crook, P.A.; Keizer, S.; Wang, Z.; Tang, W.; Lemon, O. Real user evaluation of a POMDP spoken dialogue system using automatic belief compression. Comput. Speech Lang. 2014, 28, 873–887. [Google Scholar] [CrossRef]
- Pineau, J.; Montemerlo, M.; Pollack, M.; Roy, N.; Thrun, S. Towards robotic assistants in nursing homes: Challenges and results. Robot. Auton. Syst. 2003, 42, 271–281. [Google Scholar] [CrossRef]
- López Zorrilla, A.; Velasco Vázquez, M.D.; Irastorza, J.; Olaso Fernández, J.M.; Justo Blanco, R.; Torres Barañano, M.I. EMPATHIC: Empathic, Expressive, Advanced Virtual Coach to Improve Independent Healthy-Life-Years of the Elderly. Procesamiento del Lenguaje Natural 2018, 61, 167–170. [Google Scholar]
- Lubold, N.; Walker, E.; Pon-Barry, H. Effects of voice-adaptation and social dialogue on perceptions of a robotic learning companion. In Proceedings of the 2016 11th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Christchurch, New Zealand, 7–10 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 255–262. [Google Scholar]
- Reidsma, D.; Charisi, V.; Davison, D.; Wijnen, F.; van der Meij, J.; Evers, V.; Cameron, D.; Fernando, S.; Moore, R.; Prescott, T.; et al. The EASEL project: Towards educational human-robot symbiotic interaction. In Conference on Biomimetic and Biohybrid Systems; Springer: Berlin, Germany, 2016; pp. 297–306. [Google Scholar]
- Graesser, A.C.; VanLehn, K.; Rosé, C.P.; Jordan, P.W.; Harter, D. Intelligent tutoring systems with conversational dialogue. AI Mag. 2001, 22, 39. [Google Scholar]
- Agarwal, S.; Dusek, O.; Konstas, I.; Rieser, V. A Knowledge-Grounded Multimodal Search-Based Conversational Agent. arXiv 2018, arXiv:1810.11954. [Google Scholar]
- Young, S.J. Probabilistic methods in spoken–dialogue systems. Philos. Trans. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 2000, 358, 1389–1402. [Google Scholar] [CrossRef]
- Chen, H.; Liu, X.; Yin, D.; Tang, J. A survey on dialogue systems: Recent advances and new frontiers. ACM SIGKDD Explor. Newsl. 2017, 19, 25–35. [Google Scholar] [CrossRef]
- Serras, M.; Torres, M.I.; del Pozo, A. User-aware dialogue management policies over attributed bi-automata. Pattern Anal. Appl. 2018. [Google Scholar] [CrossRef]
- Posada, J.; Wundrak, S.; Stork, A.; Toro, C. Semantically controlled LMV techniques for plant Design review. In Proceedings of the ASME 2004 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Salt Lake City, UT, USA, 28 September–2 October 2004; American Society of Mechanical Engineers Digital Collection: New York NY, USA, 2004; pp. 329–335. [Google Scholar]
- Kildal, J.; Martín, M.; Ipiña, I.; Maurtua, I. Empowering assembly workers with cognitive disabilities by working with collaborative robots: A study to capture design requirements. Procedia CIRP 2019, 81, 797–802. [Google Scholar] [CrossRef]
- Serras, M.; Torres, M.I.; del Pozo, A. Goal-conditioned User Modeling for Dialogue Systems using Stochastic Bi-Automata. In Proceedings of the 8th International Conference on Pattern Recognition Applications and Methods–Volume 1: ICPRAM, INSTICC; SciTePress: Setúbal, Portugal, 2019; pp. 128–134. [Google Scholar] [CrossRef]
- Hernaez, I.; Navas, E.; Murugarren, J.L.; Etxebarria, B. Description of the AhoTTS system for the Basque language. In Proceedings of the 4th ISCA Tutorial and Research Workshop (ITRW) on Speech Synthesis, Perthshire, UK, 29 August–1 September 2001. [Google Scholar]
- Brooke, J. System Usability Scale (SUS): A Quick-and-Dirty Method of System Evaluation User Information; Digital Equipment Co Ltd.: Reading, UK, 1986; pp. 1–7. [Google Scholar]







© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Serras, M.; García-Sardiña, L.; Simões, B.; Álvarez, H.; Arambarri, J. Dialogue Enhanced Extended Reality: Interactive System for the Operator 4.0. Appl. Sci. 2020, 10, 3960. https://doi.org/10.3390/app10113960
Serras M, García-Sardiña L, Simões B, Álvarez H, Arambarri J. Dialogue Enhanced Extended Reality: Interactive System for the Operator 4.0. Applied Sciences. 2020; 10(11):3960. https://doi.org/10.3390/app10113960
Chicago/Turabian StyleSerras, Manex, Laura García-Sardiña, Bruno Simões, Hugo Álvarez, and Jon Arambarri. 2020. "Dialogue Enhanced Extended Reality: Interactive System for the Operator 4.0" Applied Sciences 10, no. 11: 3960. https://doi.org/10.3390/app10113960
APA StyleSerras, M., García-Sardiña, L., Simões, B., Álvarez, H., & Arambarri, J. (2020). Dialogue Enhanced Extended Reality: Interactive System for the Operator 4.0. Applied Sciences, 10(11), 3960. https://doi.org/10.3390/app10113960