Grammar Guided Genetic Programming for Network Architecture Search and Road Detection on Aerial Orthophotography

 ,
,  ,
,  and
and 
Featured Application
Abstract
1. Introduction
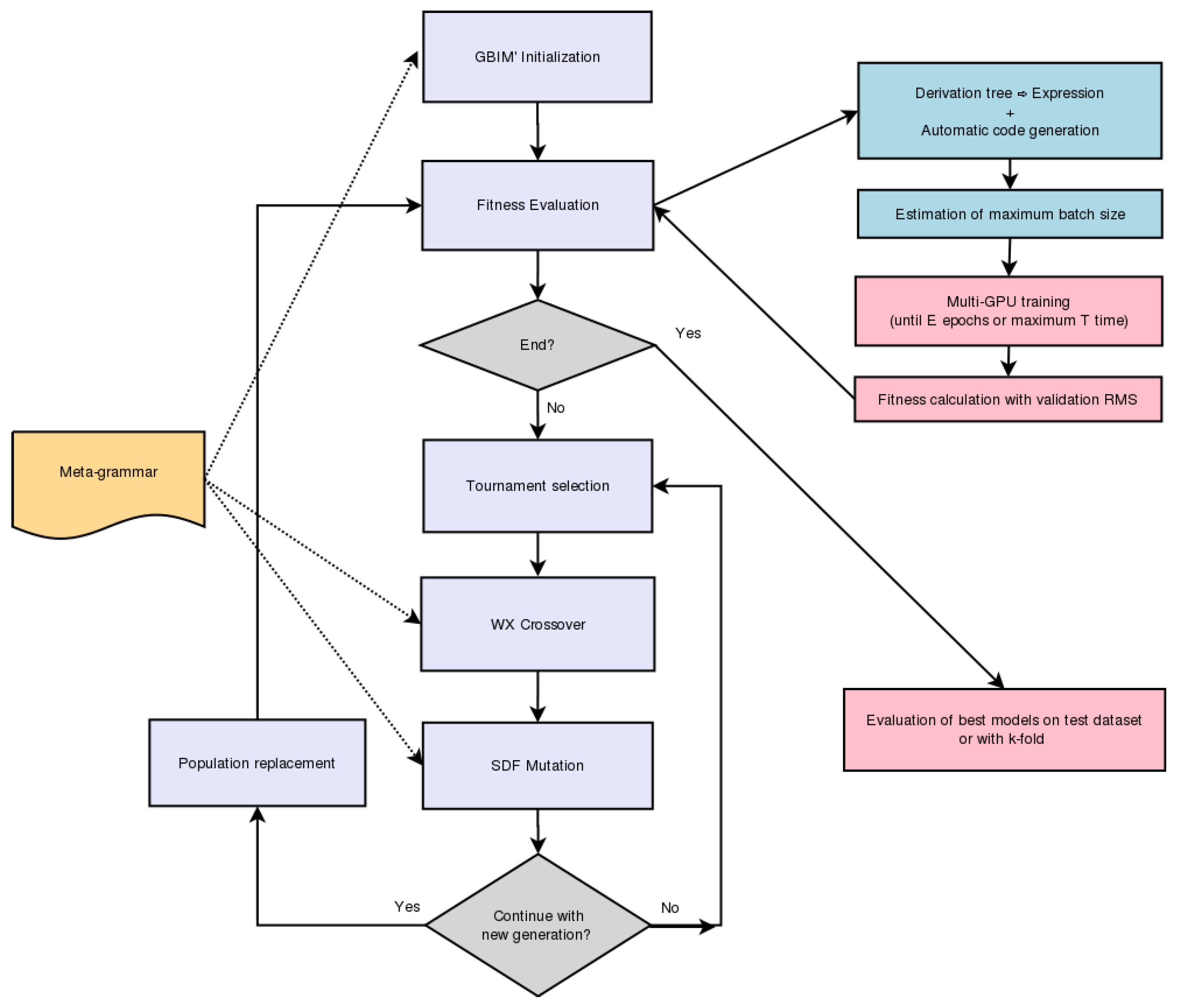
2. Methods
- We define a coding system to represent the candidate solutions (individuals) for a given problem and a context-free grammar that defines restrictions to their structure.
- A population (a set) of initial solutions is created following the grammar rules.
- We check the fitness (a measure of how well they solve the problem at hand) of the individuals to see if we have found an acceptable solution (given some stop criterion or goal to reach) and should stop the process or continue the search.
- If the stop criterion is not met, we create a new population as follows:
- (a)
- Select solutions (called parents), usually by pairs, with regard to their fitness value. Better solutions have higher chances of being selected.
- (b)
- With certain probability, combine the parents (or leave them unchanged) to obtain new solutions (offspring) using a crossover operator. The goal here is to combine the information contained in each parent to try and find better solutions. In our scenario, subtrees are exchanged between the parents to generate the offspring.
- (c)
- With certain probability, the offspring individuals are checked to add some random variations (constrained once again by the grammar rules) to improve the exploration of new solutions (new areas of the search space).
- We go back to step 3 with the new population we created.
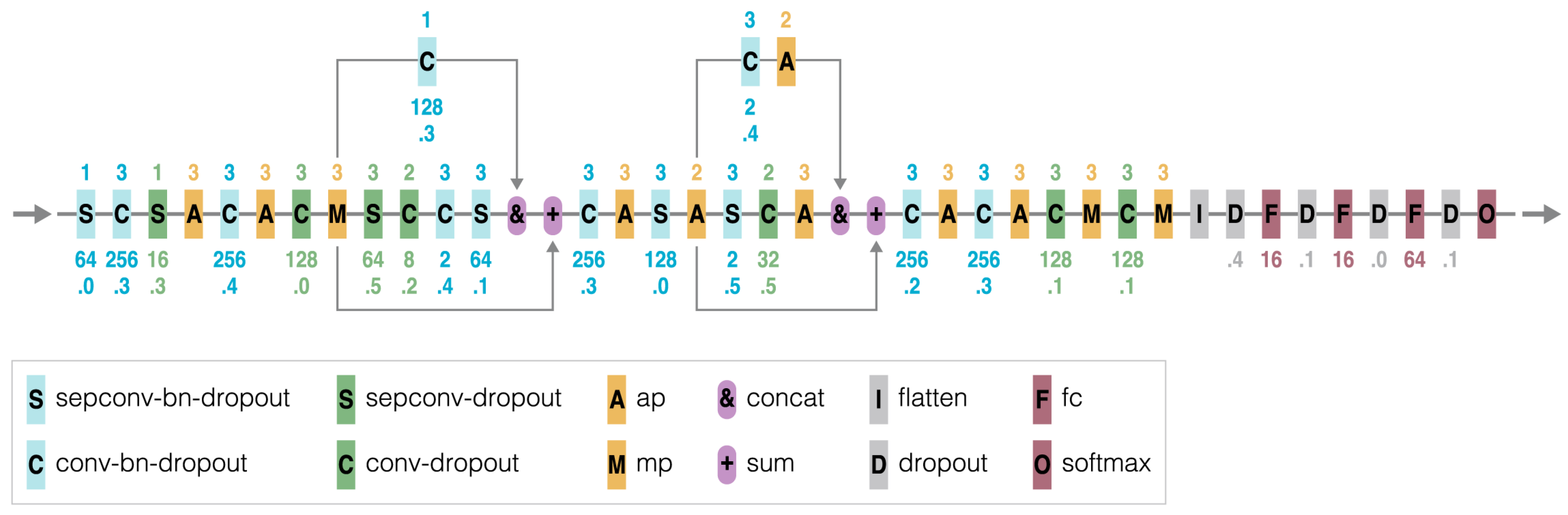
2.1. Codification Scheme
2.1.1. Expression Language
- “in”, “out”: They represent the network input and output, respectively.
- “[”, “]”: Start and end of parallel branches of processing that share the same input (branches are separated by “,”).
- “direct”: Connection between two network points without any operator being applied (residual-like connection).
- Processing nodes with two main types:
- -
- Traditional operators: convolutions (“conv”), max or average poolings (“mp” or “ap”), “dropout” [78], fully-connected layers (“fc”), “softmax” and “flatten”.
- -
- Aggregation operators: concatenation (“concat”) or zero-padded sum (“sum”). The last one adds the features of all branches with the same channel index and concatenates the rest. Both aggregation operators are applied immediately after the closing of parallel processing branches to unify the results.
- “conv-i-j-k l”: i (dimension), j (number of generated features), k (stride) and l (normalization used). Currently, only Batch Normalization (“bn”) [79] or no normalization are supported by our system. We also performed some tests including both regular (“conv”) and separable convolutions (“sepconv”).
- “mp-m-k” and “ap-m-k”: m (dimension) and k (stride).
- “dropout-r”: r (rate).
- “fc-s”: s (size).
2.1.2. Meta-grammar
- Input layer: Dimensions are given by the images of the dataset being used.
- Sequence of high-level structural blocks. Each block is chosen from the following set:
- Convolutional block. Sequence of convolution, optional batch normalization, dropout and optional pooling.
- Inception-based blocks. Parallel convolutional branches with their outputs being concatenated (all branches are constrained to apply the same spatial dimensional reduction or none).
- ResNet-based blocks. Consists of two parallel processing branches. A convolutional sequence and residual connection with their outputs being aggregated by zero padded sum (to allow for different number of features between the two branches).
- Inception-ResNet-based blocks. Here, we have an Inception-based block and a residual connection with aggregation of both their outputs via a zero padded sum.
- Sequence of fully connected layers (leaky-ReLU activation function) alternated with dropouts. Before the first FC layer, a flatten operation is automatically performed.
- Output layer: softmax layer with one output per class.
- FC layers; maximum number of layers and set of dimensions allowed: fM, fS.
- Convolutions; sets of dimensions and number of features allowed: cD, cF.
- Pooling; sets of pooling types and dimensions: pT (e.g., MP and AP), pD.
- Convolution and pooling; set of valid strides: cpS.
- Normalizations; set of allowed normalizations: norm.
- Dropout allowed rates: dR.
2.2. Diversity Control via Structural Schema Clusters
2.3. Schema Diversity Factor Mutation
2.4. Fitness
3. Experiments and Results
3.1. Experimental Setup
- Maximum number of fully connected layers was set to 1 in order to reduce the memory and computational cost of training the network during the evolutive design stage. The maximum number of neurons on those layers was kept small for the same reason (8, 16, 32).
- Only convolutions of dimensions (1, 2, 3) were allowed, according to findings in [45] regarding factorized convolutions. The number of features is a set of typical used values in the range [2,256].
- We allowed the use of the two most frequently used types of pooling (max-pooling and average-pooling).
- Regarding the stride of convolutions and poolings, we used 1 to keep spatial dimensions and 2 to allow their reduction at certain parts of the architecture (those places are specified inside the meta-grammar restrictions).
- For the dropout rates, valid values for the drop-rate parameter were set inside the interval [0, 0.5] with increments of 0.1. Here, 0.0 is interpreted as an inactive dropout operator. The higher value 0.5 was set empirically to avoid TensorFlow-Keras warnings obtained for values above 0.5.
- We allowed the use of no normalization operation or Batch Normalization (BN) to let the design process choose where to place the BN operations.
- On all cases during design, the network was trained for its evaluation only for a maximum of 20 epochs (early stop if during 5 there was no improvement on the training metrics).
- Maximum number of FC layers was 3 instead of 1.
- Bigger dimensions for FC layers (up to 256).
- Separable 2D convolutions (“sepconv”) were used in addition to regular convolutions.
- BN momentum was empirically set to 0.5 (due to average size of training batches caused by GPU number and available memory).
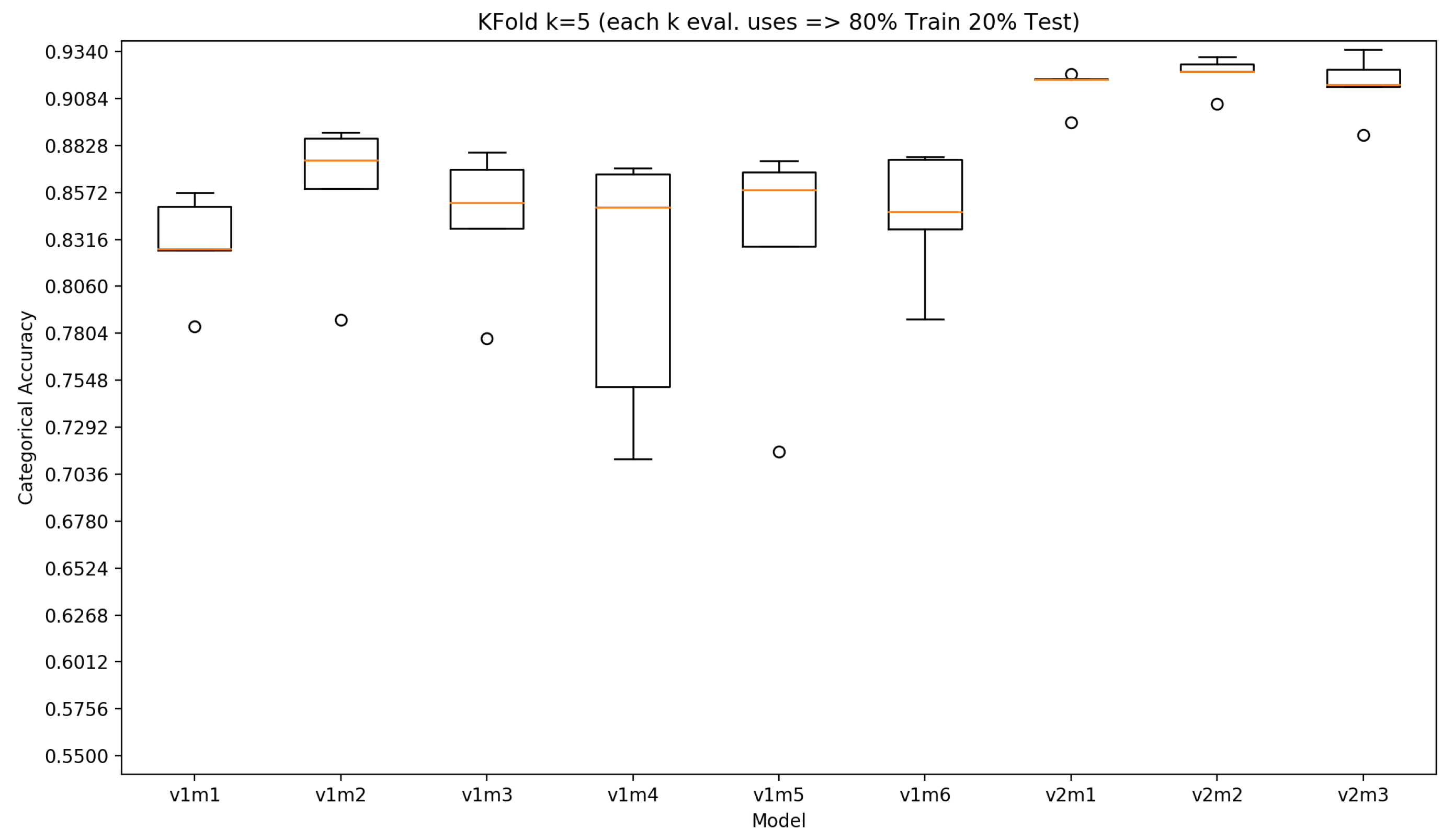
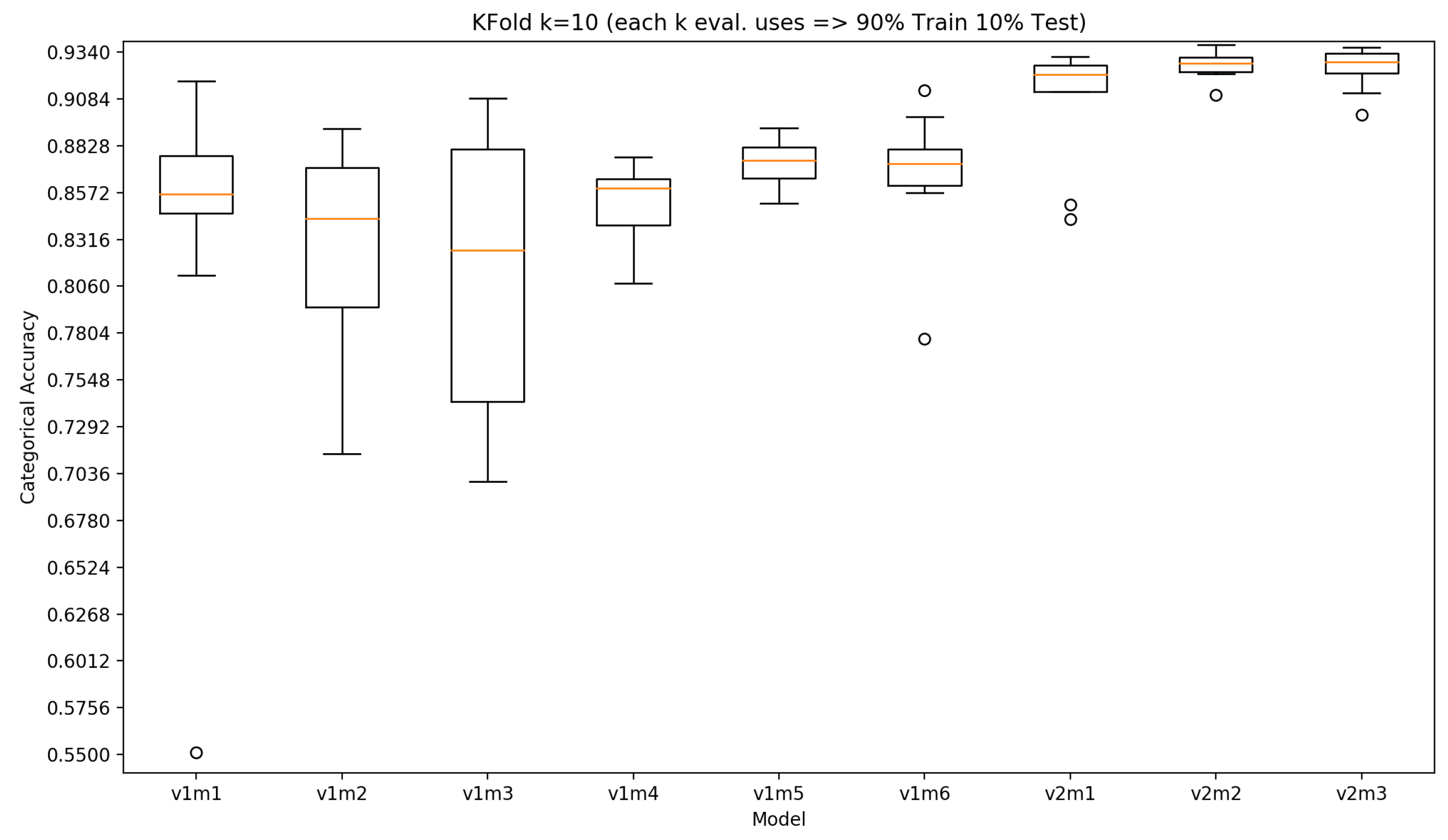
3.2. Results
4. Discussion and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Risojević, V.; Momić, S.; Babić, Z. Gabor descriptors for aerial image classification. In International Conference on Adaptive and Natural Computing Algorithms; Springer: London, UK, 2011; pp. 51–60. [Google Scholar]
- Topouzelis, K.; Papakonstantinou, A.; Doukari, M. Coastline change detection using Unmanned Aerial Vehicles and image processing technique. Fresen. Environ. Bull. 2017, 26, 5564–5571. [Google Scholar]
- Korzeniowska, K.; Bühler, Y.; Marty, M.; Korup, O. Regional snow-avalanche detection using object-based image analysis of near-infrared aerial imagery. Nat. Hazards Earth Syst. Sci. 2017, 17, 1823–1836. [Google Scholar] [CrossRef]
- Yuan, C.; Ghamry, K.; Liu, Z.; Zhang, Y. Unmanned aerial vehicle based forest fire monitoring and detection using image processing technique. In Proceedings of the 2016 IEEE Chinese Guidance, Navigation and Control Conference (CGNCC), Nanjing, China, 12–14 August 2016. [Google Scholar]
- Zacharie, M.; Fuji, S.; Minori, S. Rapid Human Body Detection in Disaster Sites Using Image Processing from Unmanned Aerial Vehicle (UAV) Cameras. In Proceedings of the 2018 International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS), Bangkok, Thailand, 21–24 October 2018. [Google Scholar]
- Selim, S.; Sonmez, N.; Coslu, M.; Onur, I. Semi-automatic tree detection from images of unmanned aerial vehicle using object-based image analysis method. J. Indian Soc. Remote Sens. 2019, 47, 193–200. [Google Scholar] [CrossRef]
- Buters, T.; Belton, D.; Cross, A. Seed and seedling detection using unmanned aerial vehicles and automated image classification in the monitoring of ecological recovery. Drones 2019, 3, 53. [Google Scholar] [CrossRef]
- Alidoost, F.; Arefi, H. A CNN-Based Approach for Automatic Building Detection and Recognition of Roof Types Using a Single Aerial Image. PFG–J. Photogramm. Remote Sens. Geoinf. Sci. 2018, 86, 235–248. [Google Scholar] [CrossRef]
- Dutta, T.; Sharma, H.; Vellaiappan, A.; Balamuralidhar, P. Image analysis-based automatic detection of transmission towers using aerial imagery. In Iberian Conference on Pattern Recognition and Image Analysis; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Tragulnuch, P.; Chanvimaluang, T.; Kasetkasem, T.; Ingprasert, S.; Isshiki, T. High Voltage Transmission Tower Detection and Tracking in Aerial Video Sequence using Object-Based Image Classification. In Proceedings of the 2018 International Conference on Embedded Systems and Intelligent Technology International Conference on Information and Communication Technology for Embedded Systems (ICESIT-ICICTES), Khon Kaen, Thailand, 7–9 May 2018. [Google Scholar]
- Lu, J.; Ma, C.; Li, L.; Xing, X.; Zhang, Y.; Wang, Z.; Xu, J. A Vehicle Detection Method for Aerial Image Based on YOLO. J. Comput. Commun. 2018, 6, 98–107. [Google Scholar] [CrossRef]
- Cao, Y.; Wang, G.; Yan, D.; Zhao, Z. Two algorithms for the detection and tracking of moving vehicle targets in aerial infrared image sequences. Remote Sens. 2016, 8, 28. [Google Scholar] [CrossRef]
- Malof, J.; Bradbury, K.; Collins, L.; Newell, R.G.; Serrano, A.; Wu, H.; Keene, S. Image features for pixel-wise detection of solar photovoltaic arrays in aerial imagery using a random forest classifier. In Proceedings of the 2016 IEEE International Conference on Renewable Energy Research and Applications (ICRERA), Birmingham, UK, 20–23 November 2016. [Google Scholar]
- Yu, J.; Wang, Z.; Majumdar, A.; Rajagopal, R. DeepSolar: A Machine Learning Framework to Efficiently Construct a Solar Deployment Database in the United States. Joule 2018, 2, 2605–2617. [Google Scholar] [CrossRef]
- Shorter, N.; Kasparis, T. Automatic vegetation identification and building detection from a single nadir aerial image. Remote Sens. 2009, 1, 731–757. [Google Scholar] [CrossRef]
- Fortier, A.; Ziou, D.; Armenakis, C.; Wang, S. Survey of Work on Road Extraction in Aerial and Satellite Images; Technical Report; Center for Topographic Information Geomatics: Ottawa, ON, Canada, 1999; Volume 241. [Google Scholar]
- Wang, J.; Qin, Q.; Gao, Z.; Zhao, J.; Ye, X. A new approach to urban road extraction using high-resolution aerial image. ISPRS Int. J. Geo-Inf. 2016, 5, 114. [Google Scholar] [CrossRef]
- Mattyus, G.; Wang, S.; Fidler, S.; Urtasun, R. Enhancing road maps by parsing aerial images around the world. In Proceedings of the IEEE International Conference on Computer Vision, Araucano Park, Chile, 7–13 December 2015; pp. 1689–1697. [Google Scholar]
- Tsochantaridis, I.; Joachims, T.; Hofmann, T.; Altun, Y. Large margin methods for structured and interdependent output variables. J. Mach. Learn. Res. 2005, 6, 1453–1484. [Google Scholar]
- Zhou, H.; Kong, H.; Wei, L.; Creighton, D.; Nahavandi, S. Efficient road detection and tracking for unmanned aerial vehicle. IEEE Trans. Intell. Transp. Syst. 2014, 16, 297–309. [Google Scholar] [CrossRef]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef]
- Lin, Y.; Saripalli, S. Road detection from aerial imagery. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 3588–3593. [Google Scholar]
- Unsalan, C.; Sirmacek, B. Road network detection using probabilistic and graph theoretical methods. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4441–4453. [Google Scholar] [CrossRef]
- Hu, J.; Razdan, A.; Femiani, J.C.; Cui, M.; Wonka, P. Road network extraction and intersection detection from aerial images by tracking road footprints. IEEE Trans. Geosci. Remote Sens. 2007, 45, 4144–4157. [Google Scholar] [CrossRef]
- Hinz, S.; Baumgartner, A. Automatic extraction of urban road networks from multi-view aerial imagery. ISPRS J. Photogramm. Remote Sens. 2003, 58, 83–98. [Google Scholar] [CrossRef]
- Trinder, J.C.; Wang, Y. Automatic road extraction from aerial images. Digit. Signal Process. 1998, 8, 215–224. [Google Scholar] [CrossRef]
- Airault, S.; Ruskone, R.; Jamet, O. Road detection from aerial images: A cooperation between local and global methods. In Image and Signal Processing for Remote Sensing; International Society for Optics and Photonics: Bellingham, WA, USA, 1994; Volume 2315, pp. 508–518. [Google Scholar]
- Zlotnick, A.; Carnine, P. Finding road seeds in aerial images. CVGIP Image Underst. 1993, 57, 243–260. [Google Scholar] [CrossRef]
- Bastani, F.; He, S.; Abbar, S.; Alizadeh, M.; Balakrishnan, H.; Chawla, S.; Madden, S.; DeWitt, D. Roadtracer: Automatic extraction of road networks from aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4720–4728. [Google Scholar]
- Máttyus, G.; Luo, W.; Urtasun, R. Deeproadmapper: Extracting road topology from aerial images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3438–3446. [Google Scholar]
- Wang, J.; Song, J.; Chen, M.; Yang, Z. Road network extraction: A neural-dynamic framework based on deep learning and a finite state machine. Int. J. Remote Sens. 2015, 36, 3144–3169. [Google Scholar] [CrossRef]
- Mnih, V.; Hinton, G.E. Learning to detect roads in high-resolution aerial images. In European Conference on Computer Vision; Springer: London, UK, 2010; pp. 210–223. [Google Scholar]
- Hu, X.y.; Zhang, Z.x.; Zhang, J. An approach of semiautomated road extraction from aerial image based on template matching and neural network. Int. Arch. Photogramm. Remote Sens. 2000, 33, 994–999. [Google Scholar]
- Ichim, L.; Popescu, D. Road detection and segmentation from aerial images using a CNN based system. In Proceedings of the 2018 41st International Conference on Telecommunications and Signal Processing (TSP), Athens, Greece, 4–6 July 2018; pp. 1–5. [Google Scholar]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic road detection and centerline extraction via cascaded end-to-end convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- Saito, S.; Aoki, Y. Building and road detection from large aerial imagery. In Image Processing: Machine Vision Applications VIII; International Society for Optics and Photonics: Bellingham, WA, USA, 2015; Volume 9405, p. 94050K. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Rao, Y.; Liu, W.; Pu, J.; Deng, J.; Wang, Q. Roads detection of aerial image with FCN-CRF model. In Proceedings of the 2018 IEEE Visual Communications and Image Processing (VCIP), Taichung, Taiwan, 9–12 December 2018. [Google Scholar]
- Wei, Y.; Wang, Z.; Xu, M. Road structure refined CNN for road extraction in aerial image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Cui, W.; Jiang, H. Fully convolutional networks for building and road extraction: Preliminary results. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1591–1594. [Google Scholar]
- Cira, C.I.; Alcarria, R.; Manso-Callejo, M.Á.; Serradilla, F. Evaluation of Transfer Learning Techniques with Convolutional Neural Networks (CNNs) to Detect the Existence of Roads in High-Resolution Aerial Imagery. In Applied Informatics; Florez, H., Leon, M., Diaz-Nafria, J.M., Belli, S., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 185–198. [Google Scholar]
- Cira, C.I.; Alcarria, R.; Manso-Callejo, M.Á.; Serradilla, F. A Deep Convolutional Neural Network to Detect the Existence of Geospatial Elements in High-Resolution Aerial Imagery. Proceedings 2019, 19, 17. [Google Scholar] [CrossRef]
- Cira, C.I.; Alcarria, R.; Manso-Callejo, M.Á.; Serradilla, F. A Framework Based on Nesting of Convolutional Neural Networks to Classify Secondary Roads in High Resolution Aerial Orthoimages. Remote Sens. 2020, 12, 765. [Google Scholar] [CrossRef]
- Volpi, M.; Tuia, D. Dense semantic labeling of subdecimeter resolution images with convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 881–893. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural Architecture Search with Reinforcement Learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. arXiv 2017, arXiv:1707.07012. [Google Scholar]
- Pham, H.; Guan, M.Y.; Zoph, B.; Le, Q.V.; Dean, J. Efficient Neural Architecture Search via Parameter Sharing. arXiv 2018, arXiv:1802.03268. [Google Scholar]
- Liu, H.; Simonyan, K.; Vinyals, O.; Fernando, C.; Kavukcuoglu, K. Hierarchical Representations for Efficient Architecture Search. arXiv 2017, arXiv:1711.00436. [Google Scholar]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q.V. Regularized Evolution for Image Classifier Architecture Search. arXiv 2018, arXiv:1802.01548. [Google Scholar] [CrossRef]
- Liang, J.; Meyerson, E.; Hodjat, B.; Fink, D.; Mutch, K.; Miikkulainen, R. Evolutionary Neural AutoML for Deep Learning. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO-2019), Prague, Czech Republic, 13–17 July 2019. [Google Scholar]
- Assunçao, F.; Lourenço, N.; Machado, P.; Ribeiro, B. DENSER: Deep evolutionary network structured representation. Genet. Program. Evolvable Mach. 2019, 20, 5–35. [Google Scholar] [CrossRef]
- Lima, R.H.R.; Pozo, A.T.R. Evolving Convolutional Neural Networks through Grammatical Evolution. In Proceedings of the Genetic and Evolutionary Computation Conference Companion; Association for Computing Machinery: New York, NY, USA, 2019; pp. 179–180. [Google Scholar] [CrossRef]
- Couchet, J.; Manrique, D.; Porras, L. Grammar-guided neural architecture evolution. In International Work-Conference on the Interplay Between Natural and Artificial Computation; Springer: London, UK, 2007; pp. 437–446. [Google Scholar]
- Tsoulos, I.; Gavrilis, D.; Glavas, E. Neural network construction and training using grammatical evolution. Neurocomputing 2008, 72, 269–277. [Google Scholar] [CrossRef]
- Jacob, C.; Rehder, J. Evolution of neural net architectures by a hierarchical grammar-based genetic system. In Artificial Neural Nets and Genetic Algorithms; Springer: London, UK, 1993; pp. 72–79. [Google Scholar]
- Mahmoudi, M.T.; Taghiyareh, F.; Forouzideh, N.; Lucas, C. Evolving artificial neural network structure using grammar encoding and colonial competitive algorithm. Neural Comput. Appl. 2013, 22, 1–16. [Google Scholar] [CrossRef]
- Assunçao, F.; Lourenço, N.; Machado, P.; Ribeiro, B. Automatic generation of neural networks with structured Grammatical Evolution. In Proceedings of the 2017 IEEE Congress on Evolutionary Computation (CEC), San Sebastián, Spain, 5–8 June 2017; pp. 1557–1564. [Google Scholar]
- Soltanian, K.; Tab, F.A.; Zar, F.A.; Tsoulos, I. Artificial neural networks generation using grammatical evolution. In Proceedings of the 2013 21st Iranian Conference on Electrical Engineering (ICEE), Mashhad, Iran, 14–16 May 2013; pp. 1–5. [Google Scholar]
- Ahmadizar, F.; Soltanian, K.; AkhlaghianTab, F.; Tsoulos, I. Artificial neural network development by means of a novel combination of grammatical evolution and genetic algorithm. Eng. Appl. Artif. Intell. 2015, 39, 1–13. [Google Scholar] [CrossRef]
- Ahmad, Q.; Rafiq, A.; Raja, M.A.; Javed, N. Evolving MIMO Multi-Layered Artificial Neural Networks Using Grammatical Evolution. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, Limassol, Cyprus, 8–12 April 2019; pp. 1278–1285. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers, Inc.: Burlington, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–10 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. AAAI 2017, 4, 12. [Google Scholar]
- Chen, Y.; Li, J.; Xiao, H.; Jin, X.; Yan, S.; Feng, J. Dual path networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 4467–4475. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–27 July 2017; pp. 5987–5995. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Whigham, P.A. Grammatically-based genetic programming. Proc. Workshop Genet. Program. Theory-Real-World Appl. 1995, 16, 33–41. [Google Scholar]
- García-Arnau, M.; Manrique, D.; Rios, J.; Rodríguez-Patón, A. Initialization method for grammar-guided genetic programming. In International Conference on Innovative Techniques and Applications of Artificial Intelligence; Springer: London, UK, 2006; pp. 32–44. [Google Scholar]
- Koza, J.R.; Koza, J.R. Genetic Programming: On the Programming of Computers by Means of Natural Selection; MIT Press: Cambridge, MA, USA, 1992; Volume 1. [Google Scholar]
- Couchet, J.; Manrique, D.; Ríos, J.; Rodríguez-Patón, A. Crossover and mutation operators for grammar-guided genetic programming. Soft Comput. 2007, 11, 943–955. [Google Scholar] [CrossRef]
- Goldberg, D.E.; Deb, K. A Comparative Analysis of Selection Schemes Used in Genetic Algorithms; FOGA: Washington, DC, USA, 1990. [Google Scholar]
- Hingee, K.; Hutter, M. Equivalence of probabilistic tournament and polynomial ranking selection. In Proceedings of the 2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–6 June 2008; pp. 564–571. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems 28; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; pp. 91–99. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. Proc. ICML 2013, 30, 3. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: London, UK, 2013; Volume 112. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: London, UK, 2013; Volume 26. [Google Scholar]
- Molinaro, A.M.; Simon, R.; Pfeiffer, R.M. Prediction error estimation: A comparison of resampling methods. Bioinformatics 2005, 21, 3301–3307. [Google Scholar] [CrossRef] [PubMed]
- Caffo, B. Statistical Inference for Data Science; Leanpub: Victoria, BC, Canada, 2015. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Server | GPUs | CPU | RAM |
|---|---|---|---|
| IGN1 | Tesla V100 16GB | Intel(R) Xeon(R) Gold 6148@2.40GHz | 128 GB |
| Cartobot1 | RTX 2080Ti 11GB | i7-8700 3.2GHz | 64 GB |
| Model | k | Accuracy Min | Accuracy Max | Accuracy Avg | Accuracy Stdev |
|---|---|---|---|---|---|
| v1m1 | 5 | 0.784 | 0.857 | 0.829 | 0.0284 |
| 10 | 0.551 | 0.918 | 0.833 | 0.103 | |
| v1m2 | 5 | 0.788 | 0.890 | 0.860 | 0.042 |
| 10 | 0.714 | 0.892 | 0.825 | 0.058 | |
| v1m3 | 5 | 0.777 | 0.879 | 0.843 | 0.040 |
| 10 | 0.699 | 0.909 | 0.812 | 0.077 | |
| v1m4 | 5 | 0.712 | 0.871 | 0.810 | 0.073 |
| 10 | 0.808 | 0.877 | 0.852 | 0.021 | |
| v1m5 | 5 | 0.716 | 0.874 | 0.829 | 0.0657 |
| 10 | 0.851 | 0.892 | 0.874 | 0.012 | |
| v1m6 | 5 | 0.788 | 0.877 | 0.845 | 0.036 |
| 10 | 0.777 | 0.913 | 0.867 | 0.0362 | |
| v2m1 | 5 | 0.895 | 0.922 | 0.915 | 0.011 |
| 10 | 0.843 | 0.931 | 0.907 | 0.033 | |
| v2m2 | 5 | 0.906 | 0.931 | 0.922 | 0.010 |
| 10 | 0.910 | 0.938 | 0.927 | 0.007 | |
| v2m3 | 5 | 0.889 | 0.935 | 0.916 | 0.017 |
| 10 | 0.900 | 0.937 | 0.925 | 0.012 |
| Model | Test Accuracy 95% t Confidence Interval (k-fold k = 5) | Test Accuracy 95% Confidence Interval (k-fold k = 10) |
|---|---|---|
| v1m1 | 0.823 ± 0.035 = [0.793, 0.864] | 0.833 ± 0.074 = [0.759, 0.907] |
| v1m2 | 0.860 ± 0.052 = [0.808, 0.912] | 0.826 ± 0.042 = [0.784, 0.867] |
| v1m3 | 0.843 ± 0.050 = [0.793, 0.893] | 0.812 ± 0.055 = [0.757, 0.867] |
| v1m4 | 0.810 ± 0.091 = [0.719, 0.901] | 0.852 ± 0.015 = [0.836, 0.867] |
| v1m5 | 0.829 ± 0.082 = [0.747, 0.911] | 0.874 ± 0.009 = [0.865, 0.882] |
| v1m6 | 0.845 ± 0.045 = [0.800, 0.890] | 0.867 ± 0.026 = [0.842, 0.893] |
| v2m1 | 0.915 ± 0.013 = [0.901, 0.928] | 0.907 ± 0.024 = [0.884, 0.931] |
| v2m2 | 0.922 ± 0.012 = [0.910, 0.934] | 0.927 ± 0.005 = [0.922, 0.932] |
| v2m3 | 0.916 ± 0.021 = [0.894, 0.937] | 0.925 ± 0.008 = [0.917, 0.934] |
| Model | Precision | Recall | F1 Score | A.U.C. |
|---|---|---|---|---|
| v2m2 | 0.936 | 0.904 | 0.920 | 0.950 |
| v2m3 | 0.931 | 0.884 | 0.907 | 0.952 |
| Model | Accuracy Mean | Accuracy Stdev | Accuracy Mean, with Data Augmentation | Accuracy Stdev, with Data Augmentation |
|---|---|---|---|---|
| c10g49m2 | 0.911 | 0.003 | 0.918 | 0.002 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
de la Fuente Castillo, V.; Díaz-Álvarez, A.; Manso-Callejo, M.-Á.; Serradilla García, F. Grammar Guided Genetic Programming for Network Architecture Search and Road Detection on Aerial Orthophotography. Appl. Sci. 2020, 10, 3953. https://doi.org/10.3390/app10113953
de la Fuente Castillo V, Díaz-Álvarez A, Manso-Callejo M-Á, Serradilla García F. Grammar Guided Genetic Programming for Network Architecture Search and Road Detection on Aerial Orthophotography. Applied Sciences. 2020; 10(11):3953. https://doi.org/10.3390/app10113953
Chicago/Turabian Stylede la Fuente Castillo, Víctor, Alberto Díaz-Álvarez, Miguel-Ángel Manso-Callejo, and Francisco Serradilla García. 2020. "Grammar Guided Genetic Programming for Network Architecture Search and Road Detection on Aerial Orthophotography" Applied Sciences 10, no. 11: 3953. https://doi.org/10.3390/app10113953
APA Stylede la Fuente Castillo, V., Díaz-Álvarez, A., Manso-Callejo, M.-Á., & Serradilla García, F. (2020). Grammar Guided Genetic Programming for Network Architecture Search and Road Detection on Aerial Orthophotography. Applied Sciences, 10(11), 3953. https://doi.org/10.3390/app10113953