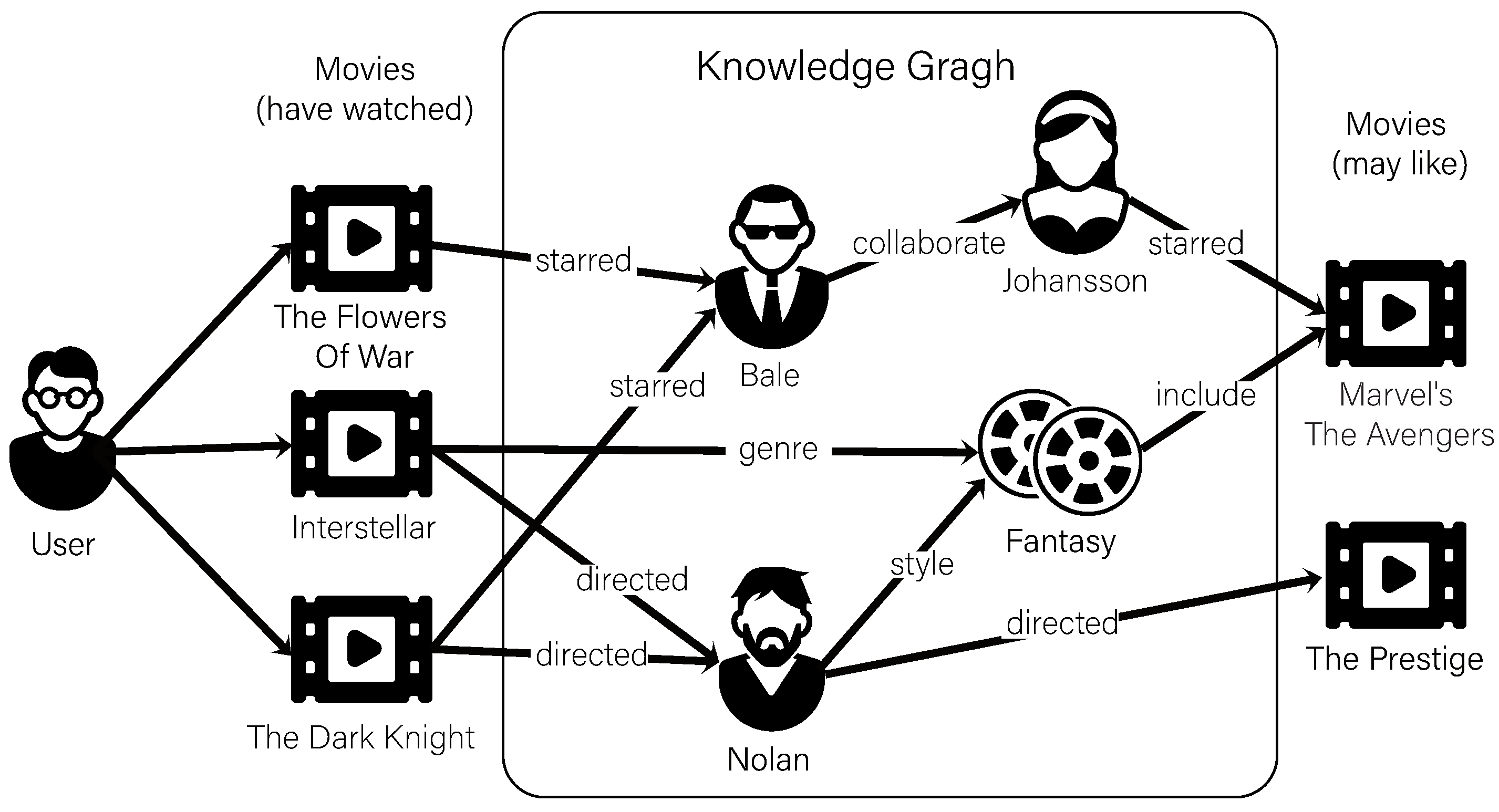
3.1. Knowledge Graph Introduction
Our work is based on the knowledge graph for extraction of users’ interest and items’ recommendation. We define the KG for a particular recommendation scenario as G = (E,R) = (h<e>, r<r>, t<e>), where E and R are entities and relations in the knowledge graph respectively and h<e>, r<r> and t<e> represent the head, relation and tail of a knowledge triple. In the recommendation scenario, the KG consists of a set of items and their related entities (such as item’s attributes, external knowledge, etc.). For example, for the <<Titanic>> (Titanic, film.film), the KG has a knowledge triple (Titanic, film.film.star, Leonardo) indicating that Leonardo DiCaprio is the star of the <<Titanic>>.
It is worth mentioning that our model is based on user-centered extraction through the knowledge graph. But the original knowledge graph does not include the user’s entity. In this work, we embed the user as a new entity type into the knowledge graph and define a new relation type to connect the users to interacted item entity. For example, Mike has seen
<<Dark Knight>>, so we added a new triple
(Mike,film.film.watch, The Dark Knight) in the KG of movie. The following
Table 1 shows the key symbols and their meanings in this paper.
3.2. Model Framework Introduction
The NACF model has four parts of input: the user , the item , the user–item interaction matrix M and the corresponding knowledge graph G. Under the above conditions, NACF discovers the potential interest of users in KG and extracts hidden features between the various entities.
Specifically, given the user ID
u, the item ID
i and the neighbor set
of each entity in the KG, NACF predicts whether
u has potential interest in the
i that
u has not contacted. The user’s neighbors of KG is composed of item entities in user–item interaction record. The whole process is to learn the following prediction function:
where
represents the probability that user
u will participate in item
i,
F represents the recommendation function and
w represents the trainable parameter of
F.
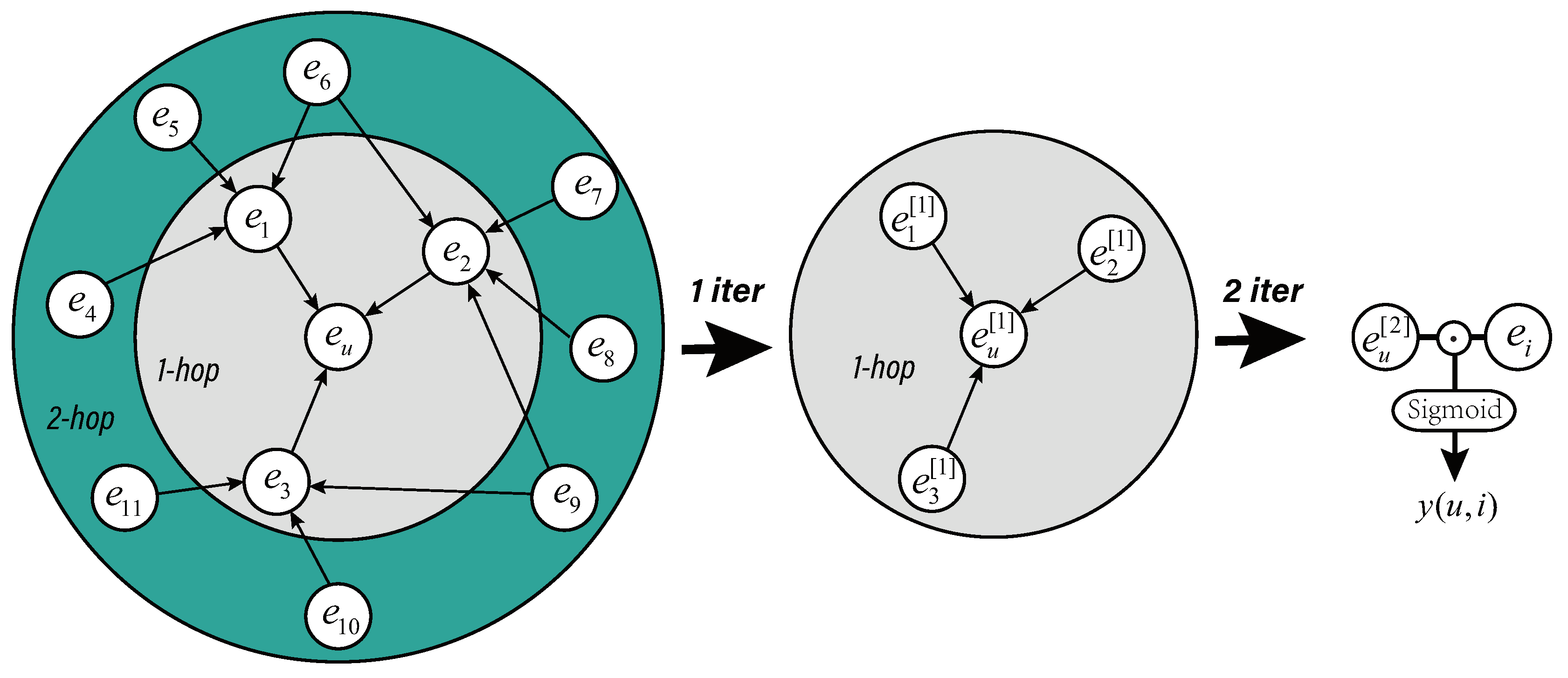
For each particular user–item pair, the neighbor features of the user are iteratively aggregated onto the entity . It includes three steps: neighborhood construction, neighborhood aggregation and prediction.
- (1)
Neighborhood Construction
We take into account the entities in
n-hop range of KG when extracting the users’ features. As shown in
Figure 2 left sub-picture, the neighbors in the
1-hop range of
(
) are composed of directly connected entities (items with interactive record), the neighbors in the
2-hop range (
) are composed of neighbors of directly connected entities in
1-hop and so on. Assuming the
n-hop neighbor set of
is
, neighborhood construction of
is as follows:
Such a construction method has the obvious advantage that the model expands the physical neighborhood through the KG and can explore the potential interests of the user more broadly and deeply. The range of neighborhood construction has a great impact on the final results of feature extraction. The goal of this step is to find the right range of neighborhood to fully exploit the potential knowledge without introducing too much noise.
- (2)
Neighborhood Aggregation
Before neighborhood aggregation, NACF initializes all entities and relations as trainable and random vectors (d-dimensions). If the neighborhood of entity includes n-hop (n layers), the aggregation of the entity is iterated n times in total. In the h-th iteration, all entities in the n-h layer perform aggregation of neighboring information and update the embedding vector. After one aggregation operation is completed, the updated representation of entity comes from the fusion of itself and the neighboring entities. We call such an aggregation operation as sub-aggregation . Until the model is iterated n times (the knowledge graph neighborhood converges to ), the neighborhood aggregation of user is complete.
In a
n layer neighborhood,
will update a total of
n-1 times and the final representation of
is
. For example, in a
2-hop aggregation scenario in
Figure 2, the first iteration updates the
to
, and the
is updated to
, which we call the first-order representation of entity. In the second iteration, the
is updated to
, which we call the second-order representation of entity. The specific sub-aggregation
will be described in the
Section 3.3.
- (3)
Prediction
When the neighborhood aggregation of is completed, the user’s embedding entity and the item’s entity perform a point multiplication to generate a prediction score. Finally, this score will be normalized by the sigmoid function to the predicted click rate .
The NACF framework is shown in Algorithm 1:
| Algorithm 1: NACF algorithm. |
 |
3.3. Aggregation Process
The aggregation of user-item pairs (
,
) includes the sub-aggregation of all entities in the current neighborhood
. Sub-aggregation is a single process of aggregating information from directly connected neighbors to entity. As shown in Algorithm 1, given user id
u and item id
i, we define the
h-th sub-aggregation process
Agg of
as following:
where
and
is initial
.
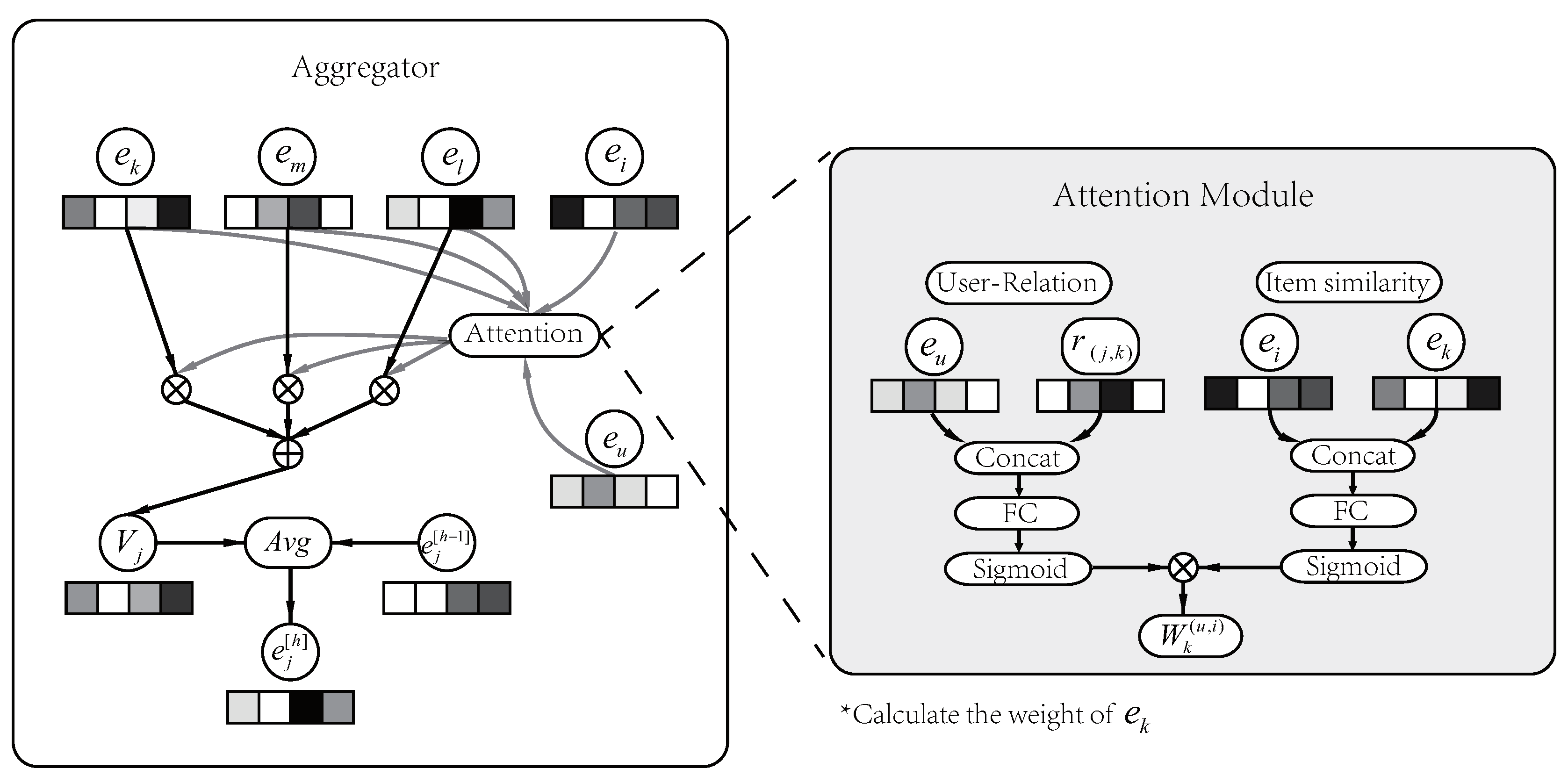
As shown in
Figure 3, we use the neighboring sub-aggregation process of the
as an example to illustrate the
in NACF. We use
to represent the collection of entities that are directly connected to
and assume that
.
represents the relation between
and
. The corresponding link relations are
,
,
.
First we design a attention module to assign different weights to entities in the neighbor collection, since we believe that aggregation without distinction can introduce too much noise and is unreasonable. In NACF, we consider the degrees of users’ interest in different relations and the similarity between neighboring entities and recommended entity. In this way, the weights of different entities in the aggregation have been confirmed.
The attention module for calculating the weight is shown on the right sub-picture of
Figure 3. For the weight calculation of the entity
, two parts of weight (
and
) are calculated separately in the attention module.
represents the user’s attention to
. For example, one user may be more inclined to choose a particular singer when listening to music; another may care more about the style of the music.
is the similarity between the current neighbor
and the recommended item
. We believe that entities with high similarity to recommended entity have a greater impact on user’s choice. Finally, the weight of neighboring entities
is two-part (
and
) multiplication result. The process is as follows:
where
and
are trainable vectors with
-dimensions.
and
are one-dimensional trainable vectors.
In order to integrate the neighborhood information of
, we perform an cumulative operation on the weighted neighbors to generate an aggregated vector
. The final step of the sub-aggregation is to calculate the mean of the original entity representation
and neighborhood representation
, and update the entity representation of
to
. The update process of
is as follows:
In the actual knowledge graph, there may be significant differences in the number of neighbors for each entity. To facilitate more efficient batch operation of the model, we extract a fixed-size neighbor set as a sample for each entity instead of its complete neighbor set. Specifically, the real neighborhood of the entity in the knowledge graph is . We set its calculation neighbor set to . samples K neighbors from , and K is a hyper-parameter.
3.4. Complete Loss Function
In order to better learn the NACF parameters and knowledge graph embedding representation, we designed the following complete loss function:
The loss function is divided into three parts. The first part represents the model prediction loss, and
is the cross entropy loss function. The second part is the
regularization of the trainable parameter
w in the model. The third part is the
regularization of the knowledge graph embedding, where
E and
R are the embedding vectors of all entities and relations in KG respectively.
and
in
are configurable hyper-parameters. Because the above optimization problem is complicated, we use Adam [
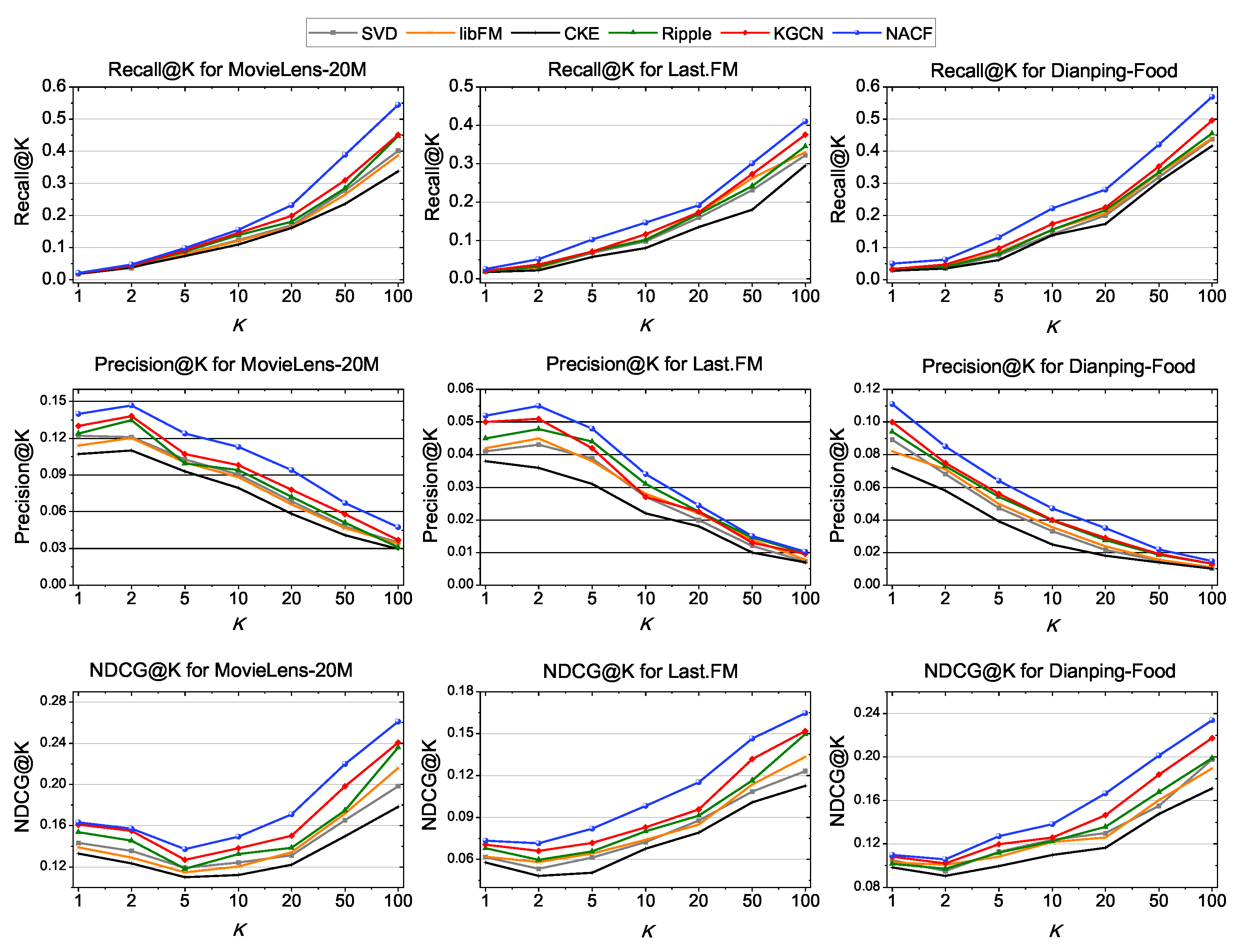
29] to iteratively optimize the loss function. We will discuss the choice of hyper-parameters in the experimental section.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}