Neural Architecture Search for a Highly Efficient Network with Random Skip Connections

Abstract
:1. Introduction
2. Related Work
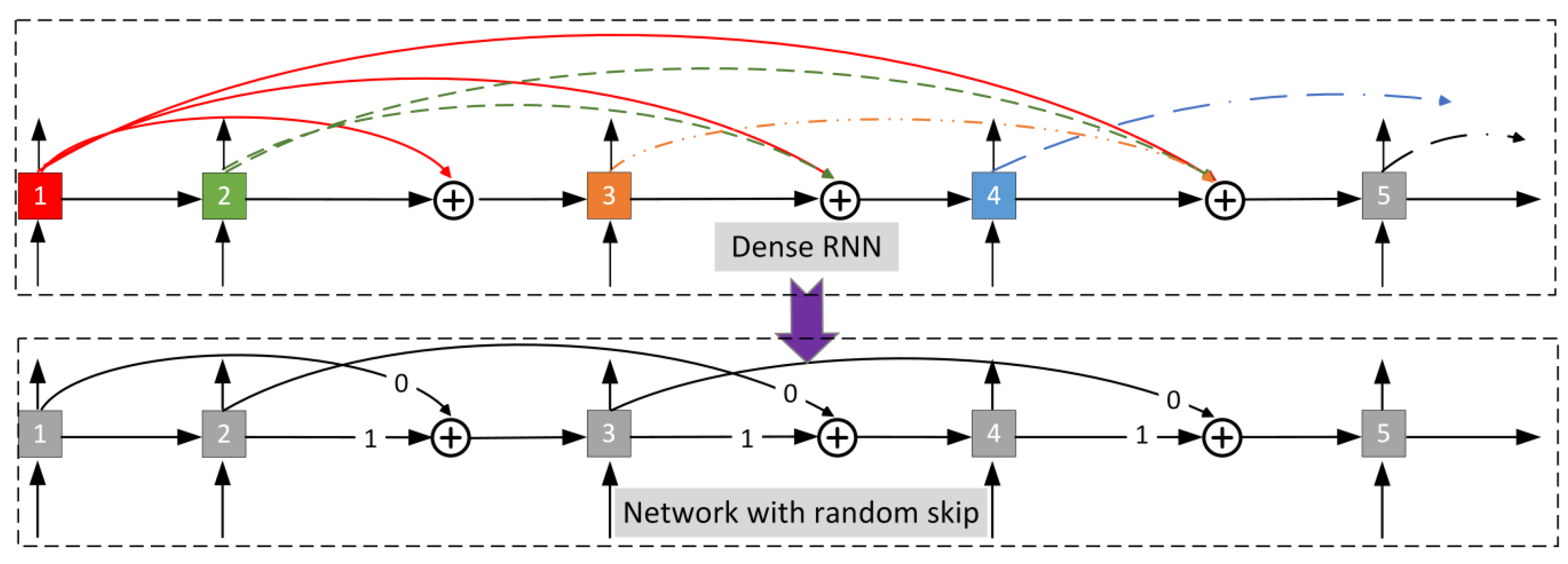
3. A Highly Efficient Network with Random Skip Connections
3.1. Architecture Generation via a Neural Architecture Search
3.2. Initialization of the Auto-Generated Network
4. Experimental Results
4.1. Benefits Regarding Memory and Computational Power
4.2. Adding Task
4.3. Copy Task
4.4. Frequency Discrimination
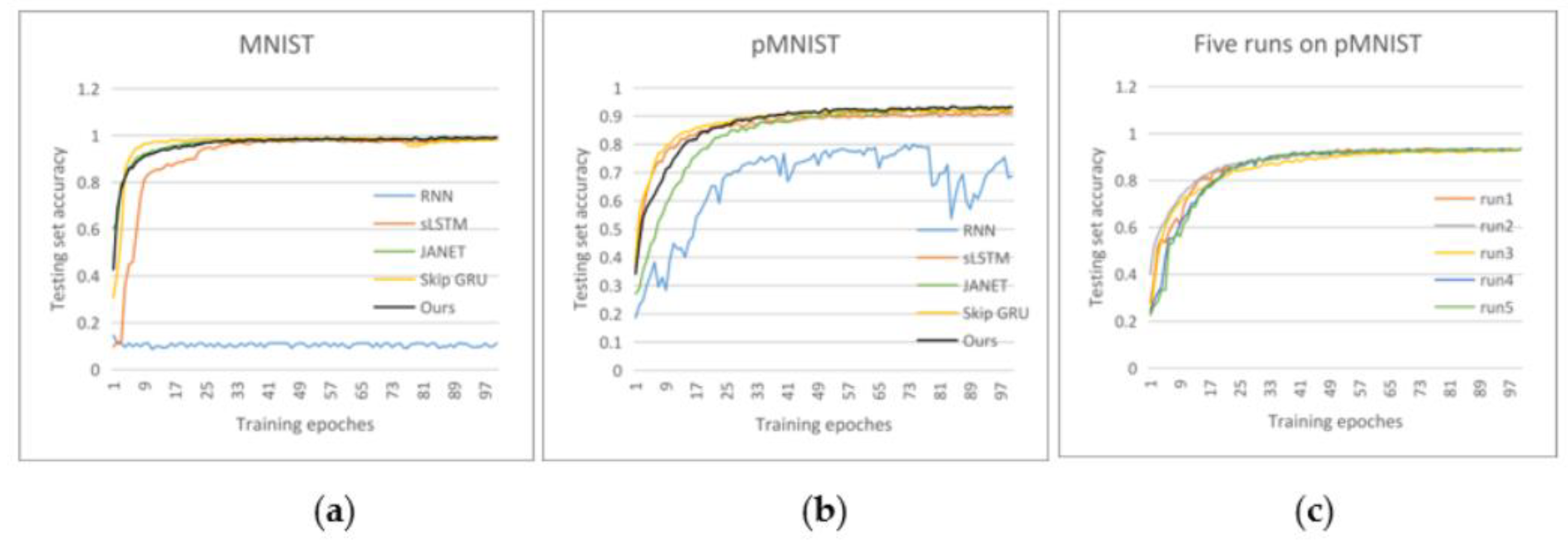
4.5. Classification Using MNIST and Permuted MNIST
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Dai, A.M.; Le, Q.V. Semi-supervised Sequence Learning. arXiv 2015, arXiv:1511.01432. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Yao, K.; Cohn, T.; Vylomova, K.; Duh, K.; Dyer, C. Depth-gated recurrent neural networks. arXiv 2015, arXiv:1508.03790. [Google Scholar]
- Westhuizen, J.V.D.; Lasenby, J. The unreasonable effectiveness of the forget gate. arXiv 2018, arXiv:1804.04849. [Google Scholar]
- Campos Camunez, V.; Jou, B.; Giro-i-Nieto, X.; Torres, J.; Chang, S.F. Skip rnn: Learning to skip state updates in recurrent neural networks. In Proceedings of the Sixth International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–17. [Google Scholar]
- Chang, S.; Zhang, Y.; Han, W.; Yu, M.; Guo, X.; Tan, W.; Cui, X.; Witbrock, M.; Hasegawa-Johnson, M.A.; Huang, T.S. Dilated recurrent neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 77–87. [Google Scholar]
- Chung, J.; Ahn, S.; Bengio, Y. Hierarchical multiscale recurrent neural networks. arXiv 2016, arXiv:1609.01704. Available online: http://arxiv.org/abs/1609.01704 (accessed on 6 May 2016).
- Elsken, T.; Hendrik Metzen, J.; Hutter, F. Neural architecture search: A survey. arXiv 2018, arXiv:1808.05377. [Google Scholar]
- Bello, I.; Zoph, B.; Vasudevan, V.; Le, Q.V. Neural optimizer search with reinforcement learning. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Brock, A.; Lim, T.; Ritchie, J.M.; Weston, N. SMASH: One-shot model architecture search through hypernetworks. arXiv 2017, arXiv:1708.05344. Available online: http://arxiv.org/abs/1708.05344 (accessed on 17 August 2017).
- Tallec, C.; Ollivier, Y. Can recurrent neural networks warp time? arXiv 2018, arXiv:1804.11188. [Google Scholar]
- Neil, D.; Pfeiffer, M.; Liu, S.C. Phased lstm: Accelerating recurrent network training for long or event-based sequences. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3882–3890. [Google Scholar]
- El Hihi, S.; Bengio, Y. Hierarchical recurrent neural networks for long-term dependencies. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 2–5 December 1996; pp. 493–499. [Google Scholar]
- Zhang, S.; Wu, Y.; Che, T.; Lin, Z.; Memisevic, R.; Salakhutdinov, R.; Bengio, Y. Architectural complexity measures of recurrent neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Available online: http://arxiv.org/abs/1602.08210 (accessed on 12 November 2016).
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A critical review of recurrent neural networks for sequence learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Le, Q.V.; Jaitly, N.; Hinton, G.E. A simple way to initialize recurrent networks of rectified linear units. arXiv 2015, arXiv:1504.00941. Available online: http://arxiv.org/abs/1504.00941 (accessed on 7 April 2015).
- Arjovsky, M.; Shah, A.; Bengio, Y. Unitary evolution recurrent neural networks. In Proceedings of the 33rd International Conference on Machine Learning (ICML 2016), New York, NY, USA, 19–24 June 2016; pp. 1120–1128. Available online: http://jmlr.org/proceedings/papers/v48/arjovsky16.html (accessed on 25 May 2016).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. Available online: http://arxiv.org/abs/1412.6980 (accessed on 22 December 2014).
- Razvan Pascanu, T.M.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 2342–2350. [Google Scholar]
- Adolf, R.; Rama, S.; Reagen, B.; Wei, G.; Brooks, D.M. Fathom: Reference work-loads for modern deep learning methods. In Proceedings of the 2016 IEEE International Symposium on Workload Characterization (IISWC), Providence, RI, USA, 25–27 September 2016; Available online: http://arxiv.org/abs/1608.06581 (accessed on 23 September 2016).


{kind=link}
{kind=link}
| Model | RNN | sLSTM | JANET | Skip GRU | Ours |
|---|---|---|---|---|---|
| MSE | 4.37 × 10−4 | 6.43 × 10−5 | 6.03 × 10−5 | 1.11 × 10−4 | 3.44 × 10−5 |
| 8.55 × 10−2 | 9.03 × 10−5 | 3.91 × 10−5 | 4.76 × 10−3 | 2.83 × 10−5 | |
| 3.40 × 10−3 | 1.23 × 10−4 | 3.12 × 10−5 | 4.44 × 10−4 | 2.77 × 10−5 | |
| 4.79 × 10−4 | 1.90 × 10−4 | 6.64 × 10−5 | 3.14 × 10−4 | 4.93 × 10−5 | |
| 2.62 × 10−3 | 2.41 × 10−5 | 4.97 × 10−5 | 5.20 × 10−4 | 4.08 × 10−5 | |
| Mean | 1.85 × 10−2 | 9.83 × 10−5 | 4.93 × 10−5 | 1.23 × 10−3 | 3.61 × 10−5 |
| Std | 3.75 × 10−2 | 6.27 × 10−5 | 1.45 × 10−5 | 1.98 × 10−3 | 9.09 × 10−6 |
| Model Task | Copy (len = 120) | Frequency (len = 120) |
|---|---|---|
| RNN | 0.1475 | 86.4% |
| sLSTM | 0.1263 | 81.2% |
| JANET | 0.0886 | 89.8% |
| Skip GRU | 0.1147 | 90.4% |
| Ours | 0.0829 | 91.2% |
| Model Dataset | Accuracy on MNIST | Accuracy on pMNIST |
|---|---|---|
| RNN | 10.8 ± 0.689 | 67.8 ± 20.18 |
| sLSTM | 98.5 ± 0.183 | 91.0 ± 0.518 |
| JANET | 99.0 ± 0.120 | 92.5 ± 0.767 |
| Skip GRU | 98.9 ± 0.099 | 92.7 ± 0.738 |
| Ours | 99.1 ± 0.093 | 93.2 ± 0.483 |
| iRNN [16] | 97.0 | 82.0 |
| uRNN [17] | 95.1 | 91.4 |
| TANH-RNN [16] | 35.0 | – |
| LSTM [15] | 98.9 | – |
| BN-LSTM [15] | 99.0 | – |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shan, D.; Zhang, X.; Shi, W.; Li, L. Neural Architecture Search for a Highly Efficient Network with Random Skip Connections. Appl. Sci. 2020, 10, 3712. https://doi.org/10.3390/app10113712
Shan D, Zhang X, Shi W, Li L. Neural Architecture Search for a Highly Efficient Network with Random Skip Connections. Applied Sciences. 2020; 10(11):3712. https://doi.org/10.3390/app10113712
Chicago/Turabian StyleShan, Dongjing, Xiongwei Zhang, Wenhua Shi, and Li Li. 2020. "Neural Architecture Search for a Highly Efficient Network with Random Skip Connections" Applied Sciences 10, no. 11: 3712. https://doi.org/10.3390/app10113712
APA StyleShan, D., Zhang, X., Shi, W., & Li, L. (2020). Neural Architecture Search for a Highly Efficient Network with Random Skip Connections. Applied Sciences, 10(11), 3712. https://doi.org/10.3390/app10113712