A Hybrid Adversarial Attack for Different Application Scenarios †


Abstract
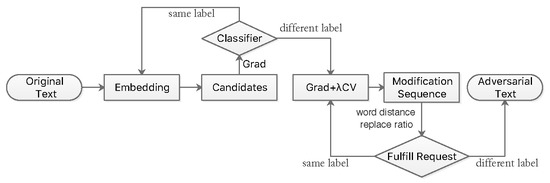
1. Introduction
- (1)
- We propose a novel black-box attack for generating adversarial text examples based on differential evolution.
- (2)
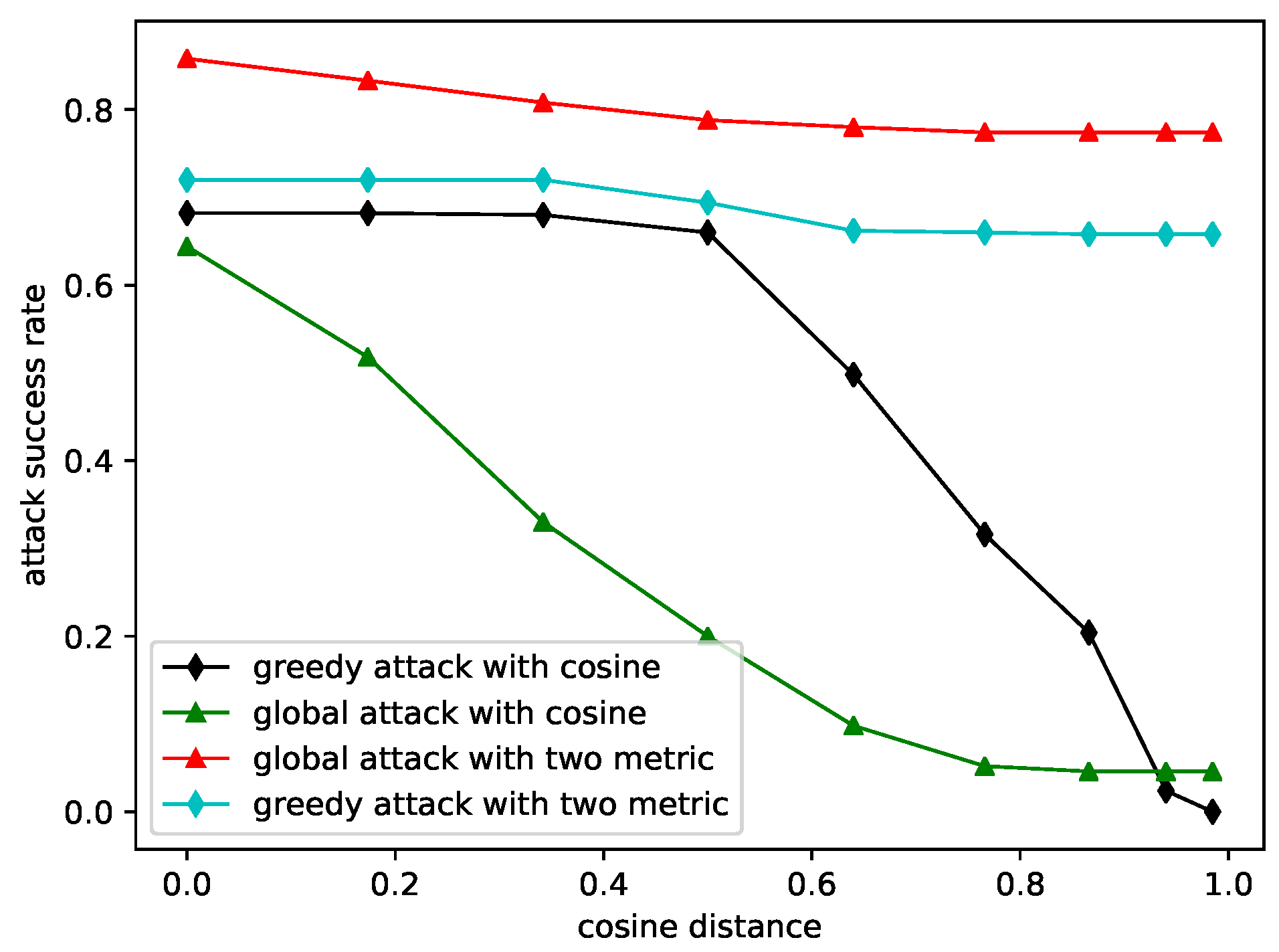
- We use a Euclidean distance and cosine distance combined metric to find the similar words when generating perturbations and candidate words; the results show that the combining metric can increase the attack success rate.
- (3)
- We propose a white-box attack to generate adversarial examples in which the modified words have high semantic relevance and their positions are more dispersed.
- (4)
- Finally, we prove that the global search attack with a coefficient of variation is more similar to the original text and more imperceptible for humans, which is verified by human evaluation.
2. Related Work
2.1. Black-Box Attack on Text
2.2. White-Box Attack on Text
2.3. Different Measures of Textual Similarity
3. Methods
3.1. Black-Box Attack on Text
| Algorithm 1: Black-box Attack on Text |
| Input: Output:
|
3.2. Greedy Search Attack
3.3. White-Box Attack on Text
| Algorithm 2: White-box Attack on Text |
| Input: Output:
|
4. Experiments
4.1. Dataset and Target Model
4.2. Evaluation
4.2.1. Black-Box Attack Based on Differential Evolution
4.2.2. White-Box Attack with the Coefficient of Variation
4.2.3. Human Evaluation
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Estrach, J.B.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. In Proceedings of the 2nd International Conference on Learning Representations (ICLR 2014), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial Examples in the Physical World. In Artificial Intelligence Safety and Security; Chapman and Hall/CRC: London, UK, 2018; pp. 99–112. [Google Scholar]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting adversarial attacks with momentum. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9185–9193. [Google Scholar]
- Liang, B.; Li, H.; Su, M.; Bian, P.; Li, X.; Shi, W. Deep text classification can be fooled. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 4208–4215. [Google Scholar]
- Alzantot, M.; Sharma, Y.S.; Elgohary, A.; Ho, B.J.; Srivastava, M.; Chang, K.W. Generating Natural Language Adversarial Examples. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Wang, X.; Jin, H.; He, K. Natural language adversarial attacks and defenses in word level. arXiv 2019, arXiv:1909.06723. [Google Scholar]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef]
- Yang, P.; Chen, J.; Hsieh, C.J.; Wang, J.L.; Jordan, M.I. Greedy attack and gumbel attack: Generating adversarial examples for discrete data. arXiv 2018, arXiv:1805.12316. [Google Scholar]
- Tsai, Y.T.; Yang, M.C.; Chen, H.Y. Adversarial Attack on Sentiment Classification. In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Florence, Italy, 28 July–2 Augusy 2019; pp. 233–240. [Google Scholar]
- Jia, R.; Liang, P. Adversarial Examples for Evaluating Reading Comprehension Systems. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 2021–2031. [Google Scholar]
- Wang, Y.; Bansal, M. Robust Machine Comprehension Models via Adversarial Training. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 575–581. [Google Scholar]
- Belinkov, Y.; Bisk, Y. Synthetic and natural noise both break neural machine translation. arXiv 2017, arXiv:1711.02173. [Google Scholar]
- Gao, J.; Lanchantin, J.; Soffa, M.L.; Qi, Y. Black-Box Generation of Adversarial Text Sequences to Evade Deep Learning Classifiers; IEEE: Piscataway, NJ, USA, 2018; pp. 50–56. [Google Scholar]
- Ren, S.; Deng, Y.; He, K.; Che, W. Generating Natural Language Adversarial Examples through Probability Weighted Word Saliency. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 Augusy 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 1085–1097. [Google Scholar] [CrossRef]
- Jin, D.; Jin, Z.; Zhou, J.T.; Szolovits, P. Is BERT Really Robust? A Strong Baseline for Natural Language Attack on Text Classification and Entailment. arXiv 2020, arXiv:2002.06261. [Google Scholar]
- Ebrahimi, J.; Rao, A.; Lowd, D.; Dou, D. HotFlip: White-Box Adversarial Examples for Text Classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Melbourne, Australia, 15–20 July 2018; pp. 31–36. [Google Scholar]
- Cheng, Y.; Jiang, L.; Macherey, W. Robust Neural Machine Translation with Doubly Adversarial Inputs. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4324–4333. [Google Scholar]
- Kuleshov, V.; Thakoor, S.; Lau, T.; Ermon, S. Adversarial Examples for Natural Language Classification Problems. 2018. Available online: https://openreview.net/forum?id=r1QZ3zbAZ (accessed on 20 May 2020).
- Lei, Q.; Wu, L.; Chen, P.Y.; Dimakis, A.; Dhillon, I.; Witbrock, M. Discrete Adversarial Attacks and Submodular Optimization with Applications to Text Classification. arXiv 2018, arXiv:1812.00151. [Google Scholar]
- Zhang, W.E.; Sheng, Q.Z.; Alhazmi, A.; Li, C. Adversarial attacks on deep learning models in natural language processing: A survey. arXiv 2019, arXiv:1901.06796. [Google Scholar]
- Wang, W.; Tang, B.; Wang, R.; Wang, L.; Ye, A. A survey on Adversarial Attacks and Defenses in Text. arXiv 2019, arXiv:1902.07285. [Google Scholar]
- Kusner, M.; Sun, Y.; Kolkin, N.; Weinberger, K. From word embeddings to document distances. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 957–966. [Google Scholar]
- Rubner, Y.; Tomasi, C.; Guibas, L.J. A Metric for Distributions with Applications to Image Databases; IEEE: Piscataway, NJ, USA, 1998. [Google Scholar]
- Mrkšic, N.; OSéaghdha, D.; Thomson, B.; Gašic, M.; Rojas-Barahona, L.; Su, P.H.; Vandyke, D.; Wen, T.H.; Young, S. Counter-fitting Word Vectors to Linguistic Constraints. In Proceedings of the NAACL-HLT, Atlanta, GA, USA, 12–17 June 2016; pp. 142–148. [Google Scholar]
- Chelba, C.; Mikolov, T.; Schuster, M.; Ge, Q.; Brants, T.; Koehn, P.; Robinson, T. One billion word benchmark for measuring progress in statistical language modeling. arXiv 2013, arXiv:1312.3005. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| GA | F = 0.1 | F = 0.3 | F = 0.5 | F = 1.2 | F = 1.5 | |
|---|---|---|---|---|---|---|
| 10% modified | 58.5% | 63% | 62.5% | 56.5% | 55% | 53% |
| 20% modified | 91% | 96% | 94.5% | 94.5% | 96% | 97.5% |
| Original Text Prediction = Positive. |
| absolutely fantastic whatever i say wouldn’t do this underrated movie the justice it deserves watch it now fantastic. |
| Adversarial Text Prediction = Negative. |
| absolutely fantastic whatever i say wouldn’t do this underestimated movie the justice it deserve watch it now fantastic. |
| Original Text Prediction = Negative. |
| poorly directed short film shot on hi def or betacam it appears it screams student film video all the way the premise is limited in scope and the short actually feels a lot longer than it runs some interesting acting moments and some decent production value but not enough to lift this film from the hole it has fallen into. |
| Adversarial Text Prediction = Positive. |
| poorly directed gunshot film shot on hi def or betacam it appears it shrieks student film video all the way the premises is limited in scope and the short actually feels a lot longest than it runs some interesting acting moments and some decent production value but not enough to lift this film from the hole it has fallen in. |
| Original Text, Prediction = Negative. |
| The Pallbearer is a disappointment and at times extremely boring with a love story that just doesn’t work partly with the casting of Gwyneth Paltrow (Julie). Gwyneth Paltrow walks through the entire film with a confused look on her face and its hard to tell what David Schwimmer even sees in her. However The Pallbearer at times is funny particularly the church scene and the group scenes with his friends are a laugh but that’s basically it. Watch the Pallbearer for those scenes only and fast forward the rest. Trust me you aren’t missing much. |
| Greedy Attack Text, Prediction = Positive. |
| on despite has given tempered well outside well surprisingly boring with a love story that just doesn’t work partly with the casting of Gwyneth Paltrow (Julie). Gwyneth Paltrow walks through the entire film with a confused look on her face and its hard to tell what David Schwimmer even sees in her. However The Pallbearer at times is funny particularly the church scene and the group scenes with his friends are a laugh but that’s basically it. Watch the Pallbearer for those scenes only and fast forward the rest. Trust me you aren’t missing much. |
| Global Attack Text, Prediction = Positive. |
| The Pallbearer is a artist and at times extremely boring with affection love story that just doesn’t work partly with the american of Paltrow Paltrow (Julie). Paltrow Paltrow walks through the entire film with a confused look on her face and its hard to tell what David Schwimmer even sees in her. However The Pallbearer at times is funny particularly the church scene and the group scenes with his friends are a laugh but that’s basically it. Watch the Pallbearer for those scenes only and fast forward the rest. Trust me you aren’t missing much. |
| Global Attack Text with CV, Prediction = Positive. |
| The Pallbearer is affection artist and at times extremely boring with a love story that just doesn’t work partly with the casting of Gwyneth Paltrow (Julie). Paltrow Paltrow walks through the entire film with a confused look on her face and its hard to tell what David Schwimmer even sees in her. However The Pallbearer at times is funny particularly the church scene and the group scenes with his friends are affection laugh but that’s basically it. Watch the Pallbearer for those scenes only and fast forward the rest. Trust me you aren’t missing much. |
| 0 | 1 | 5 | 10 | 20 | 30 | |
|---|---|---|---|---|---|---|
| CV value | 0.487 | 0.589 | 0.70 | 0.73 | 0.827 | 0.886 |
| attack rate | 77.4% | 77.6% | 76.6% | 76.8% | 77% | 76.2% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, X.; Yu, J.; Yi, Z.; Li, S.; Ma, J.; Tan, Y.; Wu, Q. A Hybrid Adversarial Attack for Different Application Scenarios. Appl. Sci. 2020, 10, 3559. https://doi.org/10.3390/app10103559
Du X, Yu J, Yi Z, Li S, Ma J, Tan Y, Wu Q. A Hybrid Adversarial Attack for Different Application Scenarios. Applied Sciences. 2020; 10(10):3559. https://doi.org/10.3390/app10103559
Chicago/Turabian StyleDu, Xiaohu, Jie Yu, Zibo Yi, Shasha Li, Jun Ma, Yusong Tan, and Qinbo Wu. 2020. "A Hybrid Adversarial Attack for Different Application Scenarios" Applied Sciences 10, no. 10: 3559. https://doi.org/10.3390/app10103559
APA StyleDu, X., Yu, J., Yi, Z., Li, S., Ma, J., Tan, Y., & Wu, Q. (2020). A Hybrid Adversarial Attack for Different Application Scenarios. Applied Sciences, 10(10), 3559. https://doi.org/10.3390/app10103559