1. Introduction
Automated visual inspection (AVI) is a challenging domain in the automation industry and is widely applied to production lines for quality control. Systems used in the AVI typically involve fields such as mechanical and electrical engineering, optics, mathematics, and computer science. Image analytics plays an important role in the success of a visual inspection system. During the past few decades, numerous vision-based approaches and related techniques have been presented for solving problems in the semiconductor industry, and have been widely employed for detecting defects and anomalies in major semiconductor materials and products, such as wafers and chips. A large number of studies have been conducted, including vision algorithms, performance improvements, and hardware and software development. In this study, we focus on the defective pattern detection of wafers.
Various optical inspection approaches were reviewed in [
1]; these approaches were categorized based on the inspection techniques and inspected products. The semiconductor fabrication process is typically divided into three main phases requiring different inspection algorithms. During the first phase, wafers are manufactured from raw materials using crystal growth, slicing, polishing, lapping, etching, and other steps. An integrated circuit (IC) pattern is then projected onto the wafer surface. During the second phase, a wafer acceptance test is applied to verify the effectiveness of all the individual ICs (also known as a die). Finally, the wafer is cut into chips, and the manufacturing process is completed through the packaging stage. A visual inspection is always applied during the defect detection for every die pattern prior to the IC packaging.
There has been a significant increase in the complexity of IC structures in recent years; this has increased the difficulty of die-scale wafer inspection. A template-based vision system for the inspection of a wafer die surface was presented in [
2]. Schulze et al. [
3] introduced an inspection technology based on digital holography, which records the amplitude and phase of the wave front from the target object directly to a single image acquired via a CCD camera. The technology was also proven to be effective for identifying defects on wafers. In [
4], Kim and Oh proposed a method using component tree representations of scanning electron microscopy (SEM) images. However, their method has only been evaluated qualitatively. To conduct a quantitative assessment, a large dataset must be prepared by domain experts. A method employing a two-dimensional wavelet transform approach was developed to detect visual defects, such as particles, contamination, and scratches on wafers [
5]. Magneto-optic imaging, which involves inducing eddy current into the target wafer, is used to inspect semiconductor wafers [
6]. Moreover, an algorithm comprising noise reduction, image enhancement, watershed-based segmentation, and clustering strategy was presented.
Over the past few decades, scanning acoustic microscopes (SAMs) have been extensively utilized in the inspection of semiconductor products [
7]. They are commonly used in non-destructive evaluations through a process called scanning acoustic tomography (SAT) [
8] to capture the internal features of wafers or microelectronic components. In addition, methods for enhancing the resolution and contrast of SAT images are introduced in [
9,
10]. In general, a wafer has large numbers of repeated dies on its surface. These dies are nearly duplicated in a SAT image because they have the same structure and circuit pattern. However, the defective (abnormal) dies need to be filtered out if they differ from the non-defective (normal) dies. In previous studies, visual testing and thresholding approaches have been frequently adopted for defect detection from SAT images. Traditionally, the most popular method is to apply template matching die by die. However, such template-matching-based approaches often suffer from a lack of robustness [
11]. Small perturbations of the translation, rotation, scale, and even noise significantly affect the calculation of the similarity scores. Moreover, traditional methods sometimes lead to poor results owing to the increased complexity of microelectronic structures. For this reason, the problem of identifying abnormal dies is no longer a binary thresholding problem. Accordingly, it is regarded as a classification task in the present work.
In recent years, deep-learning techniques have been extensively adopted in image classification applications. Deep architectures such as convolutional neural networks (CNNs) have verified their superiority over other existing methods. These deep architectures are currently the most popular approach for classification tasks. CNN-based models can be trained through end-to-end learning without specifying task-related feature extractors. The VGG-16 and VGG-19 models proposed in [
12] are extremely popular and significantly improve AlexNet [
13] by enlarging the filters and adding more convolution layers. However, deeper neural networks often become more difficult to train. He et al. [
14] presented a residual learning framework to simplify the training of a deep network. Their proposed residual networks (ResNets) are easy to optimize and can obtain a high level of accuracy from a remarkably increased depth of a network. The series of Inception networks presented in [
15,
16,
17] is a significant milestone in the development of CNN-based classifiers. Unlike the majority of previous networks that stack more layers for better performance, Inception networks use certain tricks to improve the speed and accuracy, such as the operation of multi-sized filters at the same level, employing an Inception module with reduced dimensions, factorization of a 5 × 5 filter into two 3 × 3 filters to decrease the time consumed, regularization through label smoothing to prevent overfitting, and utilization of a hybrid Inception module inspired by ResNets. Thus far, the use of ResNets and Inception models has been a dominant trend when facing image-classification problems. In [
18], the concern regarding increased computation efficiency was addressed, and a class of efficient models called MobileNets was presented.
The goal of this study is to inspect all die patterns on a wafer and then identify defective dies or anomalies. The main contributions and innovations of our study are briefly described below.
We propose an automatic procedure for extracting a standard template which is then utilized for detecting the die patterns from the original SAT image of a wafer.
From the detected die patterns and their spatial properties, we present a simple method to predict the locations of pattern candidates that possibly contain certain predefined patterns.
We design and implement a deep CNN-based classifier to identify all detected patterns and predicted pattern candidates. This classifier can categorize them into the background, alignment mark, normal, and abnormal classes.
Finally, the proposed method uses the obtained patterns with the spatial properties and classification results to produce a wafer map. This map provides important information to engineers in their analysis regarding the root cause of die-scale failures [
19].
The remainder of this paper is organized as follows.
Section 2 introduces the main algorithm of the proposed method. The implementation details and experimental results are described in
Section 3. Finally, some concluding remarks are presented in
Section 4.
2. The Proposed Method
In this section, we introduce the main phases of our proposed method for detecting defective and abnormal die patterns from a target wafer. For a simpler description, we consider the SAT image demonstrated in
Figure 1 as an example for presenting the proposed method, assuming that the original SAT image has a pixel resolution of
. It is evident that there are a large number of similar dies that regularly repeat on the wafer. In this study, every die is a minimum unit that needs to be analyzed. In general, the wafer is well aligned during the SAT imaging process. Template-matching methods can be used to find all dies if a reliable template is obtained in advance. Consequently, we first introduce an algorithm for automatically extracting a standard template. Thereafter, the die patterns need to be detected and classified successively. Therefore, the proposed method is divided into three main phases: (1) automatic template extraction, (2) die pattern detection and clustering, and (3) die pattern classification.
2.1. Automatic Template Extraction
The first phase of our method is to seek a reliable template. In this subsection, we describe the design of a two-step algorithm, including a template size estimation and standard template extraction, to obtain this template.
2.1.1. Template Size Estimation
Because the sizes of the die patterns are almost identical, an accurate template size helps find a reliable template. The main procedures for estimating the template size are briefly addressed as follows.
Initialize parameters: The original SAT image has a pixel resolution of
, patch image has a pixel resolution of
, and template has an initial pixel resolution of
, with a similarity threshold of
. These will be determined and discussed in
Section 3.1.
The original image is converted into a grayscale image.
An image patch with a pixel resolution of is randomly cropped near the central area from the grayscale SAT image. If the original image is not too large, it can be considered an image patch; thus, this step can be skipped.
Histogram equalization is applied to enhance the contrast on this cropped patch. Hence, for different imaging settings of the SAT, consistent performance is maintained when conducting the following steps.
Figure 2 shows the results of the cropped patch before and after histogram equalization.
An initial template
with a size of
is randomly cropped from the patch
, as shown in
Figure 3. If step 3 is skipped, we crop this initial template from the grayscale SAT image.
An ordinary template matching process is conducted to find the parts of image
that are similar to template
. This step simply slides the initial template image over the patch as in a two-dimensional convolution and calculates the following metric for comparing the template
against the local region of the patch
.
where
indicates one of the pixels covered by the template for
and
,
is the local region
of patch
, and
is the normalized cross-correlation between two evaluated images
and
. Hence, the pixel
forms a correlation map
for
and
.
Figure 4 shows the results of map
obtained from the patches shown in
Figure 2b and
Figure 3. Notably, the bright pixels indicate that a high similarity occurs at these locations.
A binary thresholding process is applied on this map to obtain a binary map
as follows:
This step sets the pixels that correspond with the relatively high correlation values to one and sets others to zero.
A morphological opening operation is conducted to reduce small noise in map
.
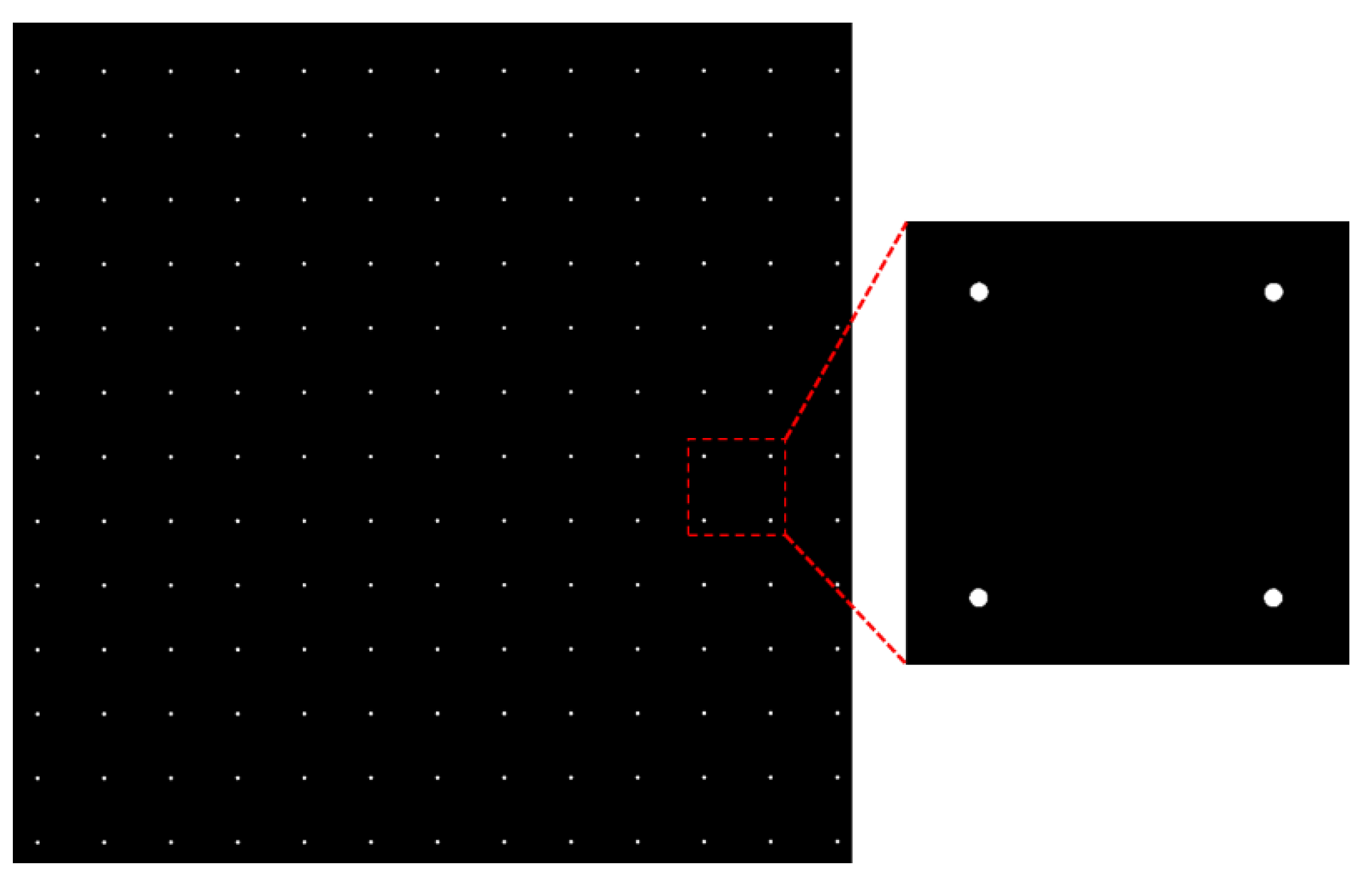
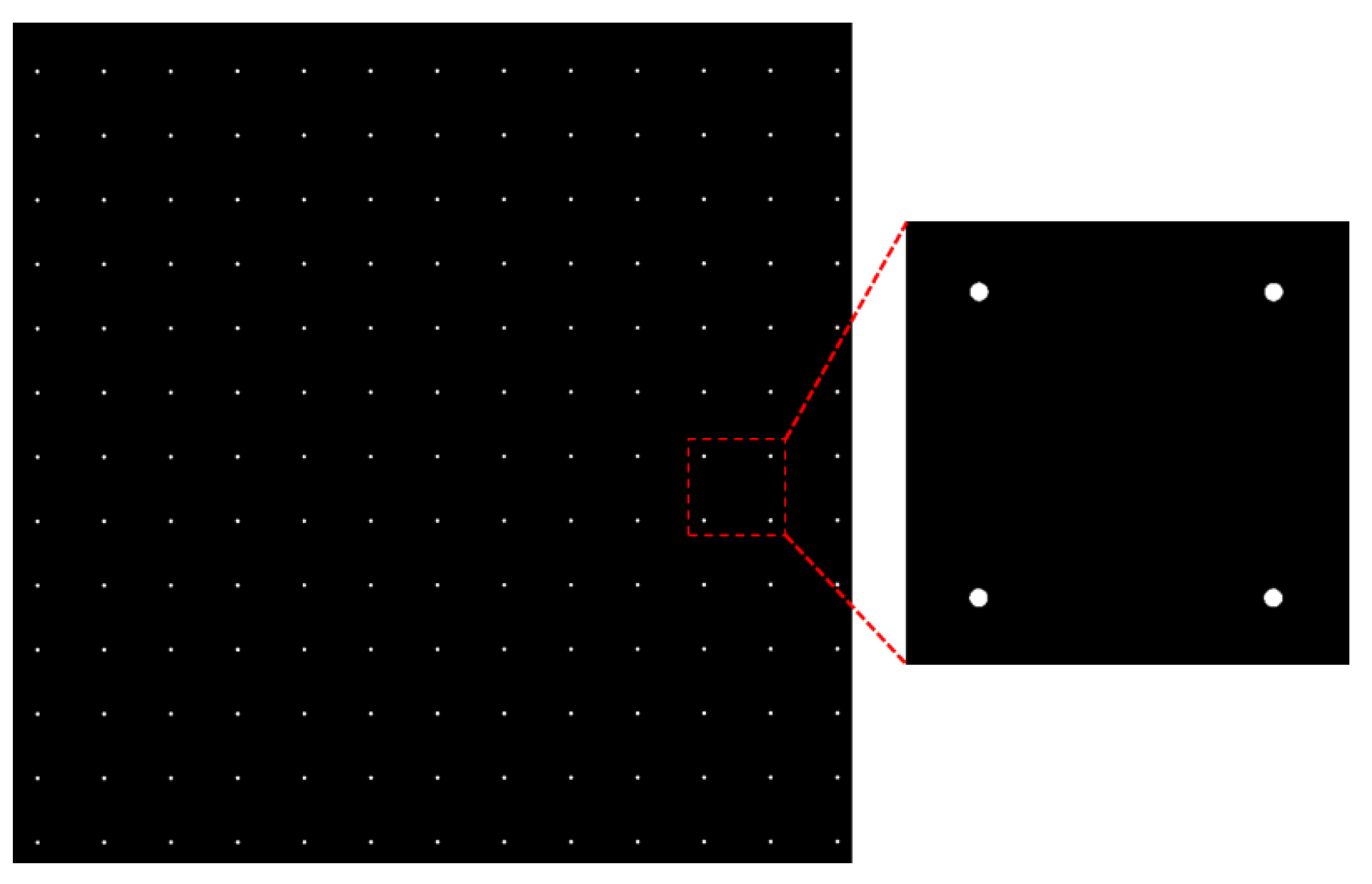
Figure 5 shows the results of this step. As observed from the enlarged region depicted on the right, each presented bright dot is an object that is formed with connected bright pixels.
The connected component method is applied to label all bright objects in map , and then calculate the centroid of every object. Here, denotes the center of the -th object, and for a total of objects obtained from .
A set of displacement tuples is found by considering every possible pair of
, for
and
.
Here, we only count under the condition satisfying
because
is equal to
.
Every displacement vector
contributes to a voting space
as follows:
Similar to the voting technique used in Hough transform, we accumulate all displacement vectors in the voting space
to determine the parameters (width and height) of the template.
Similar to steps 7–9, the centroid of every local peak is found in this voting space, and the centroid
that is nearest to the origin of
is then localized. Therefore, the template size is estimated as follows:
2.1.2. Standard Template Extraction
We now want to find regularly repeated regions inside the initial template (as shown in
Figure 3). The process of finding such a region is described in detail as follows.
The initial template is first smoothed using a two-dimensional Gaussian filter with a kernel size of 5 5 pixels. Because the weights are effectively zero out of a 5 5 filter when approximating to Gaussian function with a standard deviation , we select this kernel size in this study.
Thresholding is applied to the filtered template, where the threshold is determined using Otsu’s well-known method [
20].
Figure 6 shows the results of this step.
After labeling all bright objects, the largest one is found and its centroid is recorded.
A patch centered at
is cropped to a size of
pixels from the initial template. This cropped image can be considered the standard template. In
Figure 7, the green rectangle in subplot (a) shows the extracted template and (b) shows its close-up.
This extracted template is used to detect the die patterns in the initial template to check whether the number of detected die patterns is sufficient. If the number of patterns is insufficient, the algorithm of automatic template extraction is re-conducted.
2.2. Die Pattern Detection and Clustering
Die patterns that are similar to the standard template are expected to be detected from the original SAT image. Following steps 6–9 described in the template size estimation of
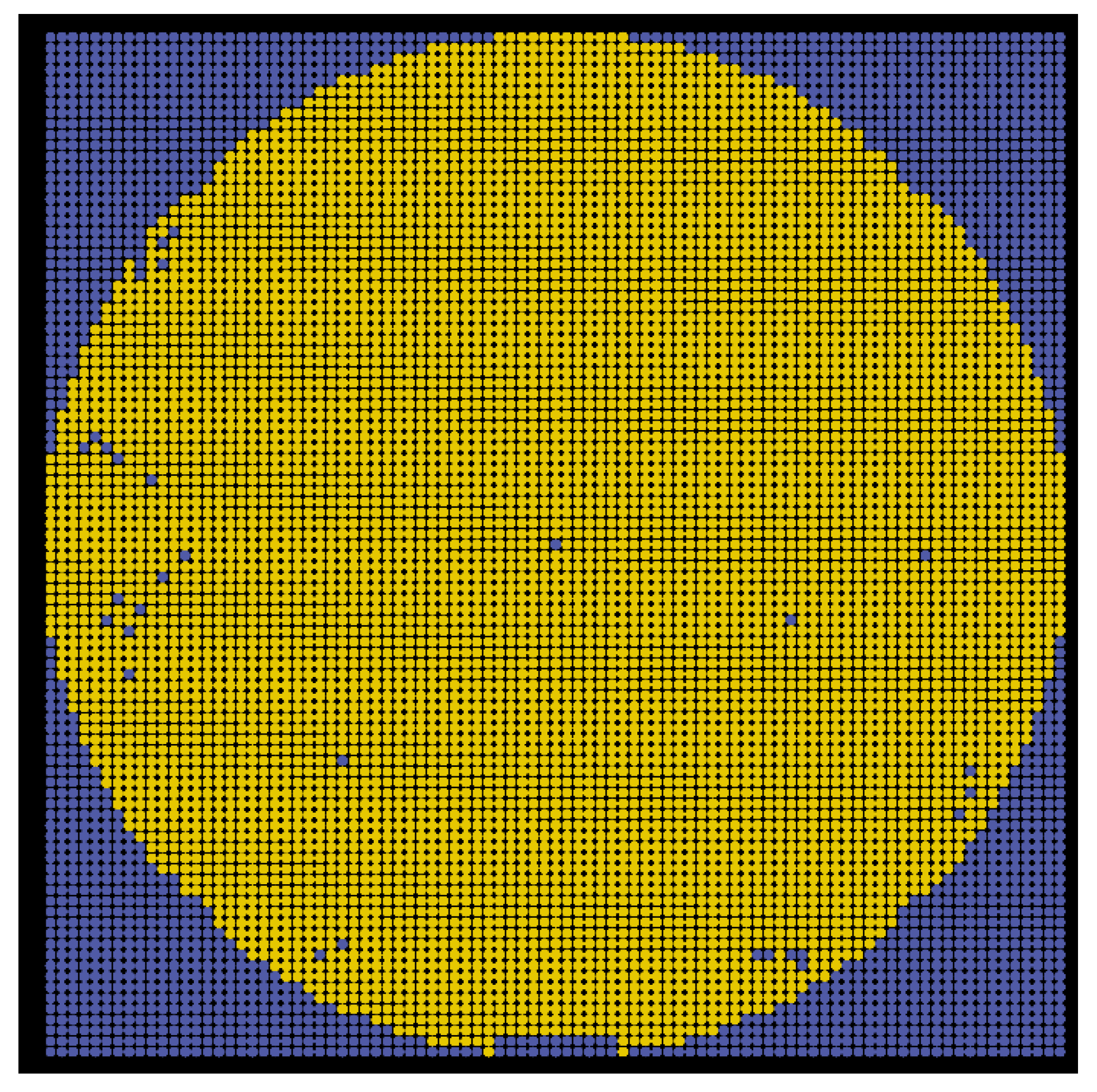
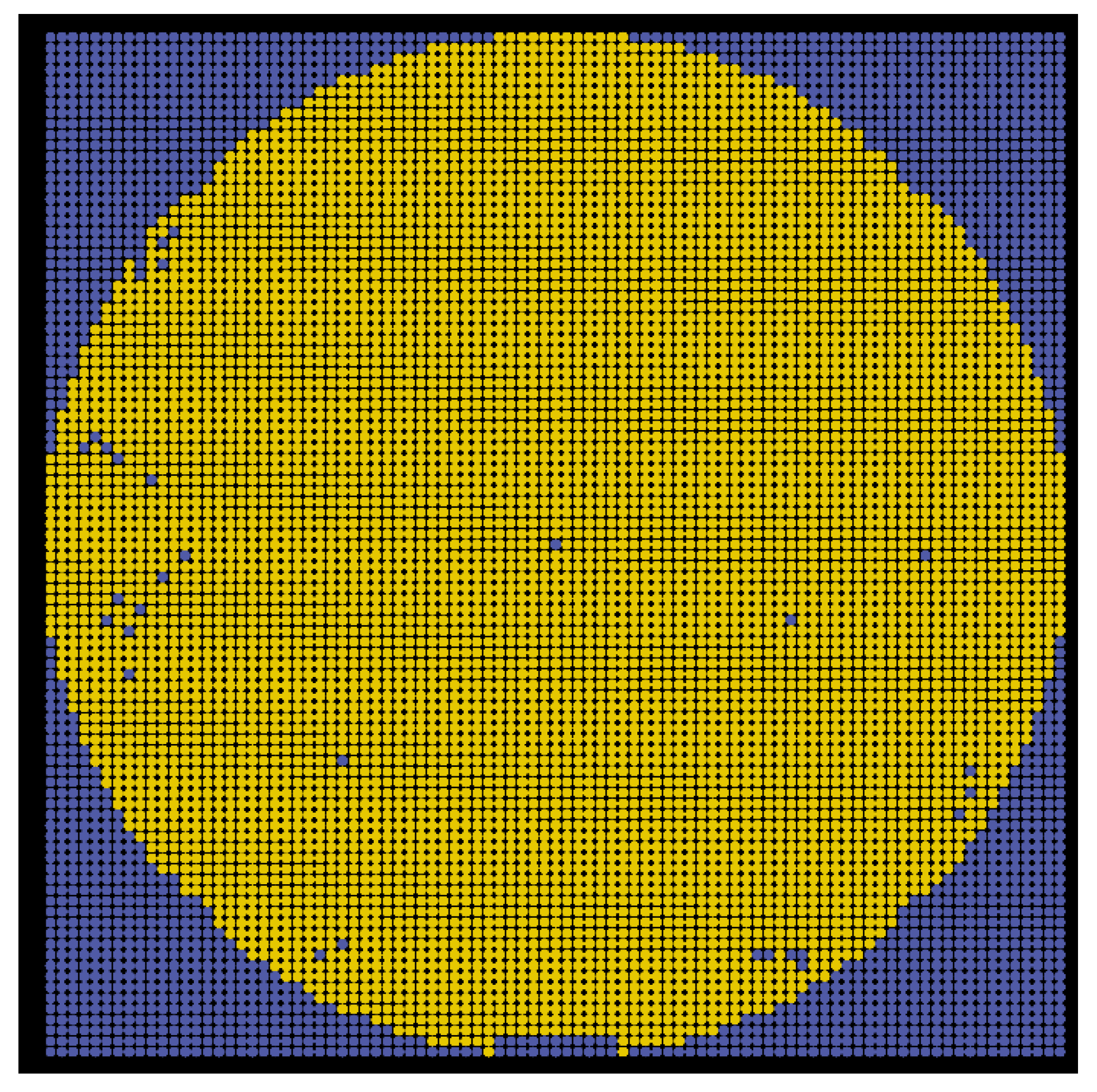
Section 2.1, regions that are highly similar to the template are obtainable. The yellow dot in
Figure 8 indicates that there is a die pattern found at that location, that is, a region similar to the template exists. Notably, some die patterns are not detected because their similarity is insufficiently high. They possibly result from imaging anomalies, wafer fabrication defects, and belonging to other pattern types such as alignment marks. From
Figure 8, it is evident that the detected die patterns are arranged in rows and columns, and the mis-detected die patterns (dark holes inside the wafer) are possibly retrieved from their neighboring dies. Therefore, this subsection presents a clustering method for obtaining the columns and rows in the arrangement by using the detected die patterns and predicting the coordinates of these rows and columns. Eventually, the positions of these mis-detected patterns can be obtained via interpolation or extrapolation approaches.
Let be the -th detected die pattern and be its top-left corner for , where is the total number of detected patterns. In general, the wafer is well aligned during the SAT imaging process; consequently, die patterns are neatly arranged in rows and columns. The die patterns in the same column (or row) possess almost the same horizontal (or vertical) location (or ). Hence, a simple clustering method using a distance metric is used for grouping along the horizontal direction, and then find the number of columns. The criterion is to produce clusters with short intra-cluster distances and long inter-cluster distances. Let us first define a distance threshold as , the index set of which is , the selected set is empty, and the cluster set is empty. The proposed algorithm for clustering is briefly introduced as follows.
Let the first coordinate point be taken as the first cluster center . Let the selected set be , and the cluster set .
Select the next point from , and compute the distance for every . Apply index into set .
Compare this distance with the threshold . If , then set belonging to cluster . Next, update center by averaging all coordinate points belonging to cluster . In contrast, let become a new prototype point, and add a new cluster with its center . Here, denotes the number of clusters in .
Repeat steps 2–3 until all coordinate points belong to their corresponding clusters.
The four steps above form an iteration obtaining the clusters with centers. Based on these clusters, a new iteration is created to assign all coordinate points to their nearest cluster in the same manner. This clustering algorithm will terminate when the clustered results of two consecutive iterations are the same. Consequently, the number and coordinates of the columns from all detected die patterns can be obtained.
Similarly, the coordinate points
are clustered in the same manner. Thus, every row and its representative coordinate are obtained. Thus far, the number of columns and rows from the detected die patterns can be obtained. Assuming that the detected patterns arrange in
columns and
rows. Let
be the top-left corner of an arbitrary die pattern in the original SAT image, where the subscript
denotes the
column and subscript
denotes the
row. Using these corners and the estimated size of the standard template, all patterns, including the die patterns and predicted pattern candidates, in the wafer image can be obtained.
This indicates the two-dimensional region of the pattern located on the
column and
row.
Figure 9 shows all patterns, in which the yellow and blue dots denote the locations of the detected and predicted patterns, respectively. Every pattern will be further categorized into normal, abnormal, or other predefined classes. At this point, the initial wafer map is produced; however, the patterns need to be identified later.
2.3. Pattern Classification for Inspection
As shown in
Figure 9, a wafer map full of the detected (yellow) and predicted (blue) patterns was produced. In this subsection, we further categorize each of them into one of the following classes: (1) background (outside the wafer), (2) alignment mark, (3) normal (non-defective die), or (4) abnormal (with some errors, such as cracks, defects, or imaging noise).
Figure 10 shows typical examples of these four classes. In addition, more cases of different abnormal patterns are shown in
Figure 11, which are caused by fabrication defects (subplots (a) to (d)), such as cracks, and imaging errors caused by voids (subplots (c) to (d)). The next task is to perform our image classification method to analyze any patterns. Here, a learning-based method composed of image feature extraction and image classification was used in our study. Numerous networks possessing a deep architecture have verified the effectiveness of the image extraction. As mentioned in
Section 1, we selected several popular image feature extraction models, including VGG-16 and VGG-19 [
12], InceptionV3 [
16], MobileNet [
18], and ResNet-50 [
14], for evaluation. ResNet-50 was finally chosen as the image extractor of our proposed method. The details of the performance comparison are described in
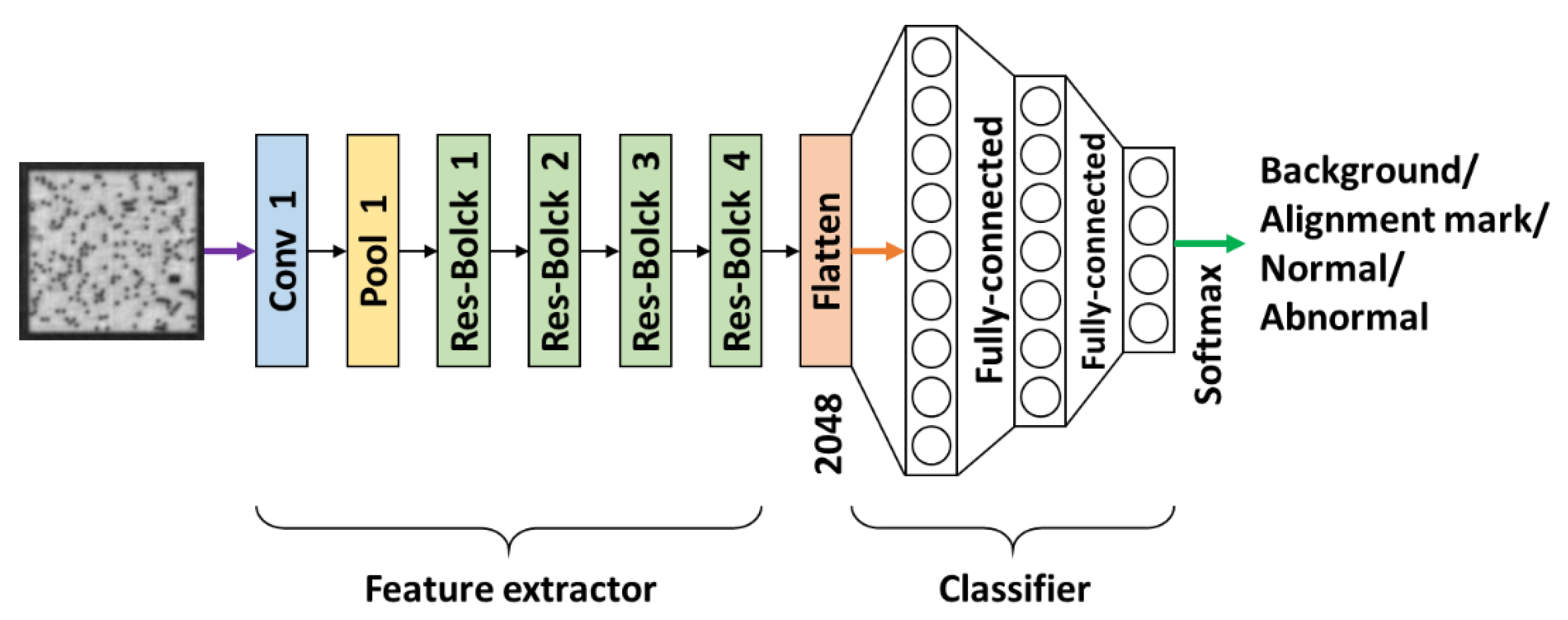
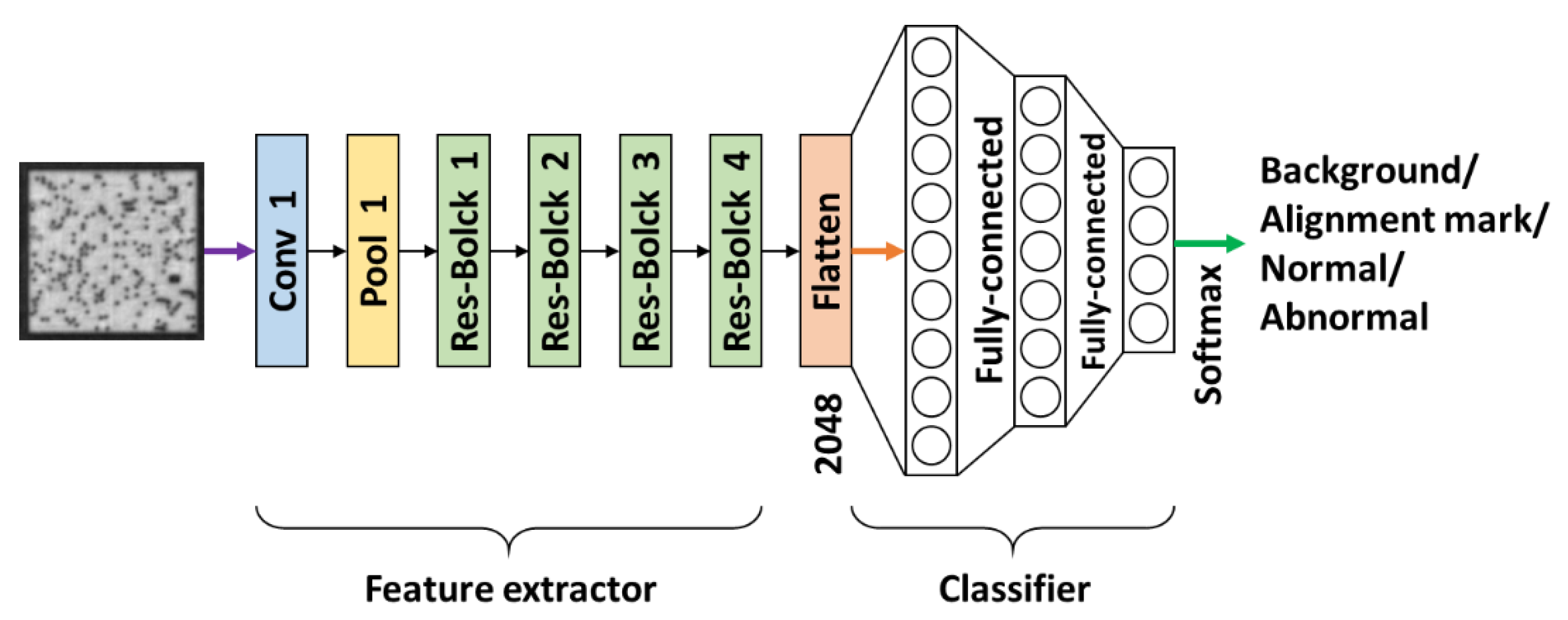
Section 3.3. This image extractor is followed by a fully-connected neural network designed for image classification. Thus, the entire architecture of our proposed method for pattern identification is as depicted in
Figure 12. The details of its implementation are provided in
Section 3.1.
3. Implementation and Experimental Results
First, three SAT images captured from different wafers (in the same batch) on the semiconductor production line were prepared for the following experiments. For convenience, we named them img01, img02, and img03. In this section, we focus on the explanation and implementation of (1) automatic template extraction, (2) the training and testing stages of our pattern classification method, and (3) a discussion on using different networks as the backbone of the image feature extractor. To meet the computational requirements when executing a deep CNN-based model, a graphics processing unit (GPU)-accelerated computer was used to implement our proposed method. We run all the experiments on the computer with an Intel Core I7-8750H CPU @ 2.2 GHz, 16G DDR4 RAM 2400 MHz, NVIDIA GeForce GTX-1060. The operating system was Windows 10. The entire algorithm was programmed in Python and used OpenCV and TensorFlow.
3.1. Experiments on Automatic Template Extraction and Die Detection
The proposed method for template extraction was verified using images img01, img02, and img03. The parameters used in this experiment are as follows:
The size of the original SAT image is: and .
The size of the image patch is: and . This size is determined to ensure that there are sufficient die patterns in this image patch. If template extraction fails, this size can be increased by , , and so on.
The size of the initial template is: and . The criterion for determining this size is to ensure that there exists one (or more) whole die pattern in this initial template. Generally, this size is big enough to detect and extract a standard template.
The similarity threshold is the 90th percentile value of the map , that is, .
The binarization thresholds are adaptively determined using Otsu’s method [
20].
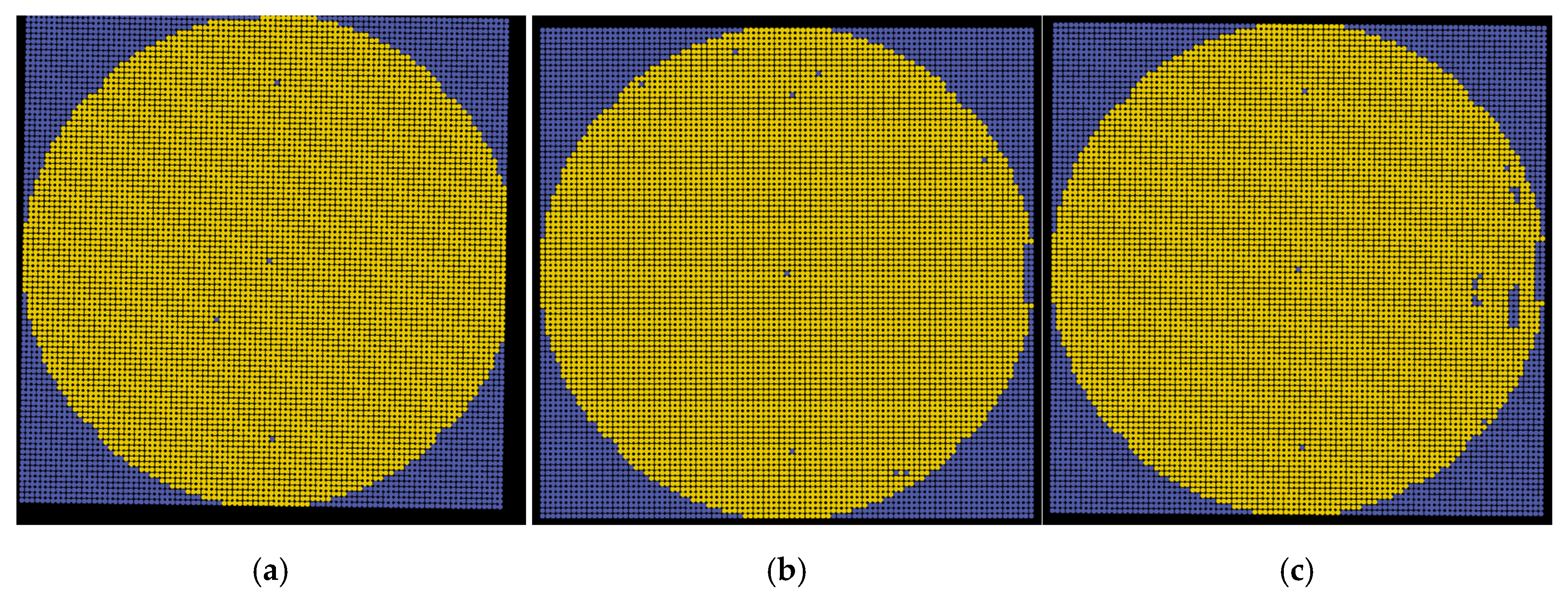
Figure 13 shows the extracted templates, in which subplots (a), (b), and (c) correspond to
img01,
img02, and
img03, respectively, and the estimated template size can be found in
Table 1. These are very similar because their original SAT images are from the same batch of wafer products. Next, we apply template matching followed by clustering to obtain an initial wafer map that contains the detected die patterns (marked by the yellow dots) and predicted pattern candidates (marked by the blue dots).
Figure 14 shows the results of the initial wafer maps for images
img01,
img02, and
img03. These wafer maps need to be further analyzed by conducting our proposed classification model for every pattern.
3.2. Implementation of Die Pattern Classification
In this subsection, the proposed pattern classification model trained using our own dataset is described. The standard network, as depicted in
Figure 12, contains over 25 million trainable parameters. The first half of the network is a ResNet-50 feature extractor, the input of which is a normalized pattern image with a size of 224
224 pixels and a feature vector output of 2048
1. The complete compositions of ResNet-50 are shown in
Table 2. The second half is a fully-connected neural network applied to conduct four-class classification, the thorough architecture of which is tabulated in
Table 3.
During this experiment, we collected a total of 2150 samples to form our own Dataset-I, and manually identified them into four categories: (1) background, (2) alignment mark, (3) normal, and (4) abnormal. Repeated random subsampling validation [
21], also known as Monte Carlo cross-validation, was adopted for evaluating accuracy during training. The Dataset-I was randomly split into training and validation sets multiple times, whereas the ratio of training data to validation data was 5:1. For each such split, the model was learned with the training set, and the accuracy was assessed using the validation set. The accuracies obtained from the splits were then averaged.
Table 4 lists the data distribution of which were 1769 samples used for learning the model and 381 samples applied for validation. Some commonly used data augmentation techniques are applied in the present work, including shifting and flipping, rotation, and brightness shifts. We set the hyper-parameters as follows: rotation range of
, spatial shifts of
, brightness shifts of
, a random zoom range of
, dropout probability of
, batch size of 8, maximum epochs of 15, optimized using Adam with commonly-used settings of
,
, and
, and the learning rate
of
.
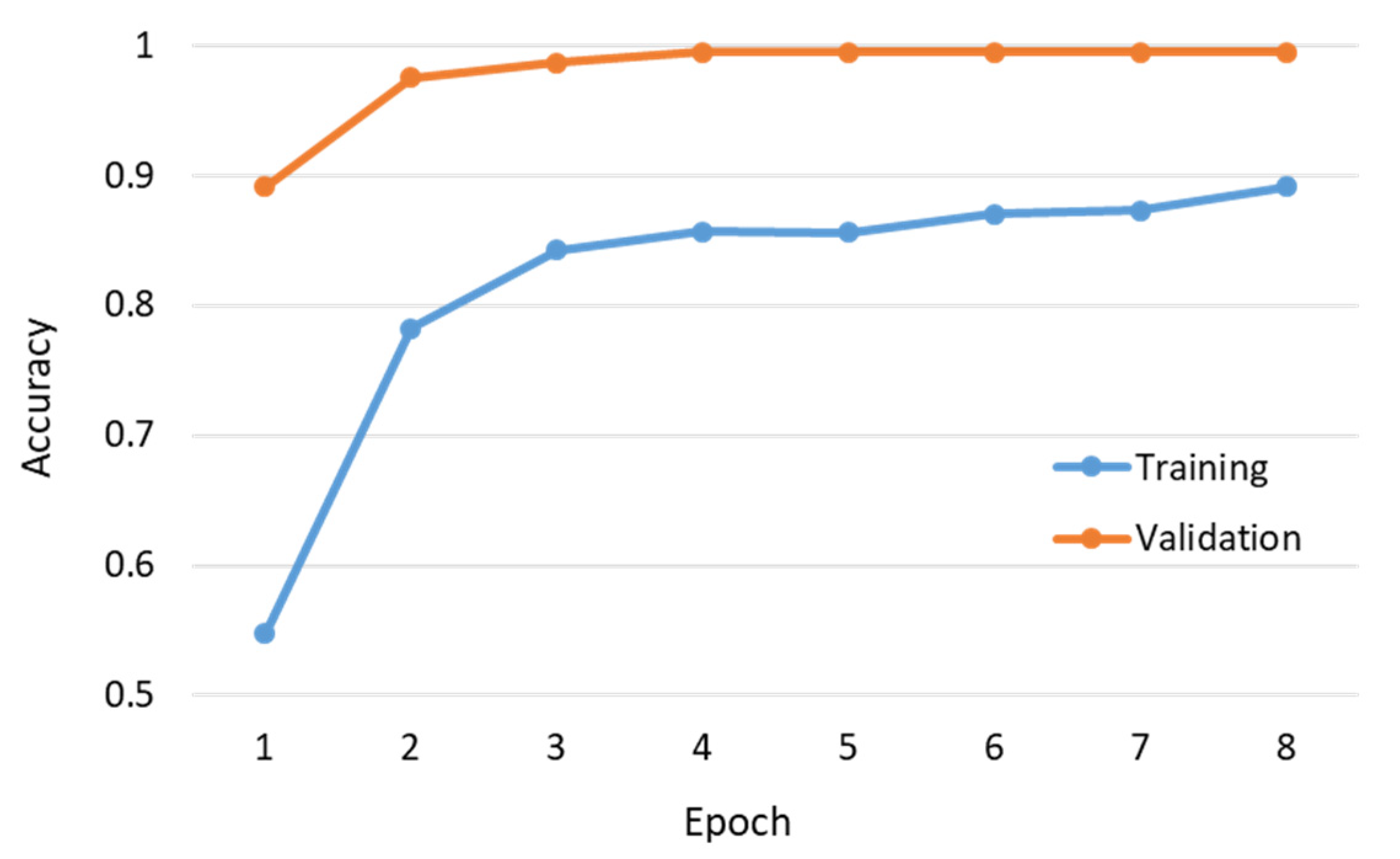
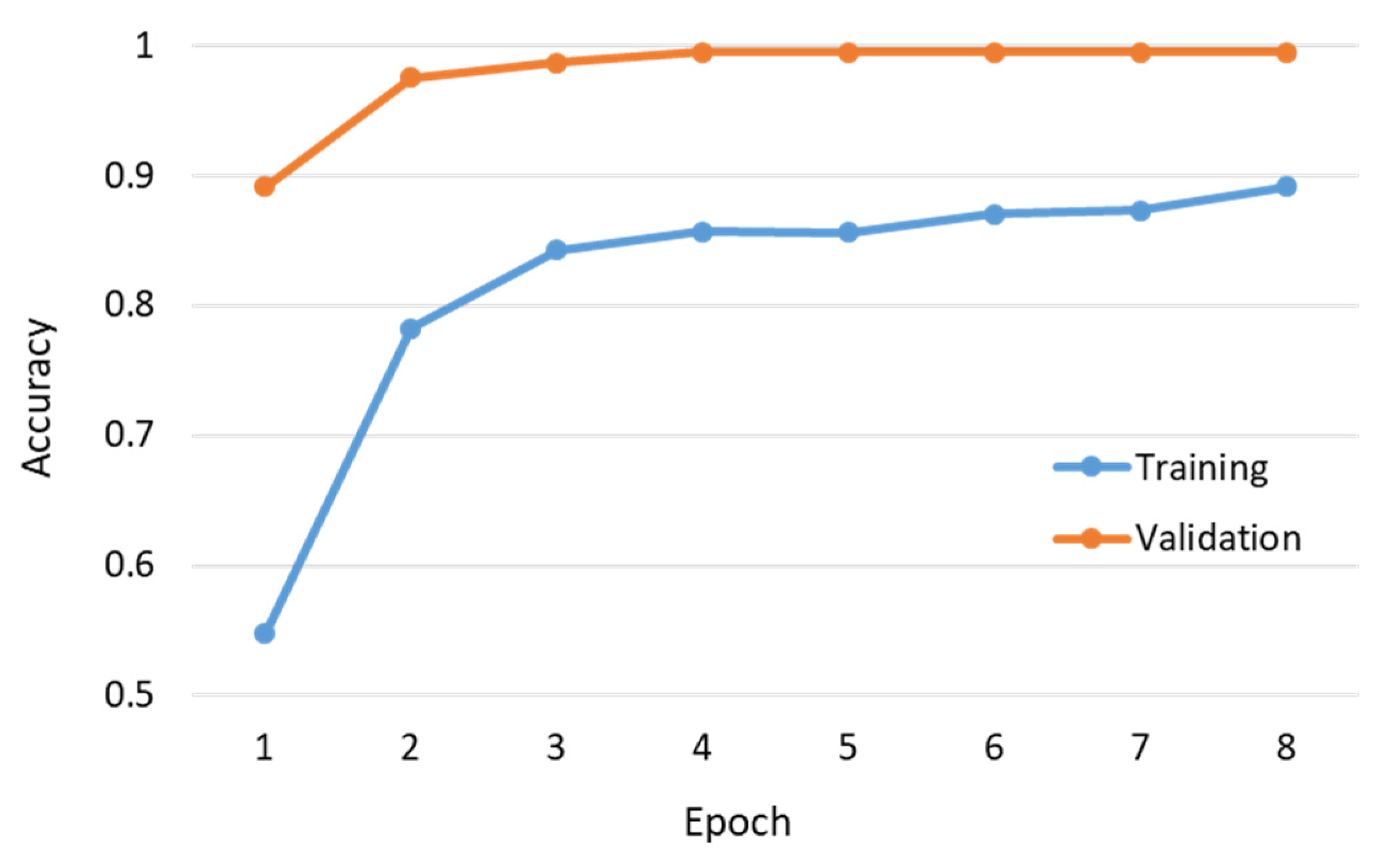
Figure 15 shows the per-epoch trend of training and validation accuracy. Note that we terminated the training process after eight epochs because the training and validation accuracy converged to 89.13% and 99.46%, respectively. As shown in the figure, the training accuracy is less than the validation accuracy; this situation can be attributed to several reasons: (1) the regularization mechanisms, such as the dropout and L1/L2 weight regularization, were turned on during training. (2) When using the Keras library in the TensorFlow, the training accuracy for an epoch is the averaged accuracy over each batch of the training data. Because the model was changing over time, the accuracy over the first batch was lower than that over the last batch. By contrast, the validation accuracy for an epoch is computed using the model as it is at the end of the epoch, resulting in a higher accuracy. (3) The techniques of data augmentation used during training probably produced certain samples that were difficult to identify. Finally, we used 370 additional test data for evaluating the learned model, the results of which are summarized in
Table 5 as a confusion matrix. Notably, the test data were collected from different batches of wafers. Only two normal samples were incorrectly identified as an abnormal class. The overall accuracy was greater than 99%, and the accuracy for the normal samples was 98.57%.
3.3. Comparison among Feature Extractors
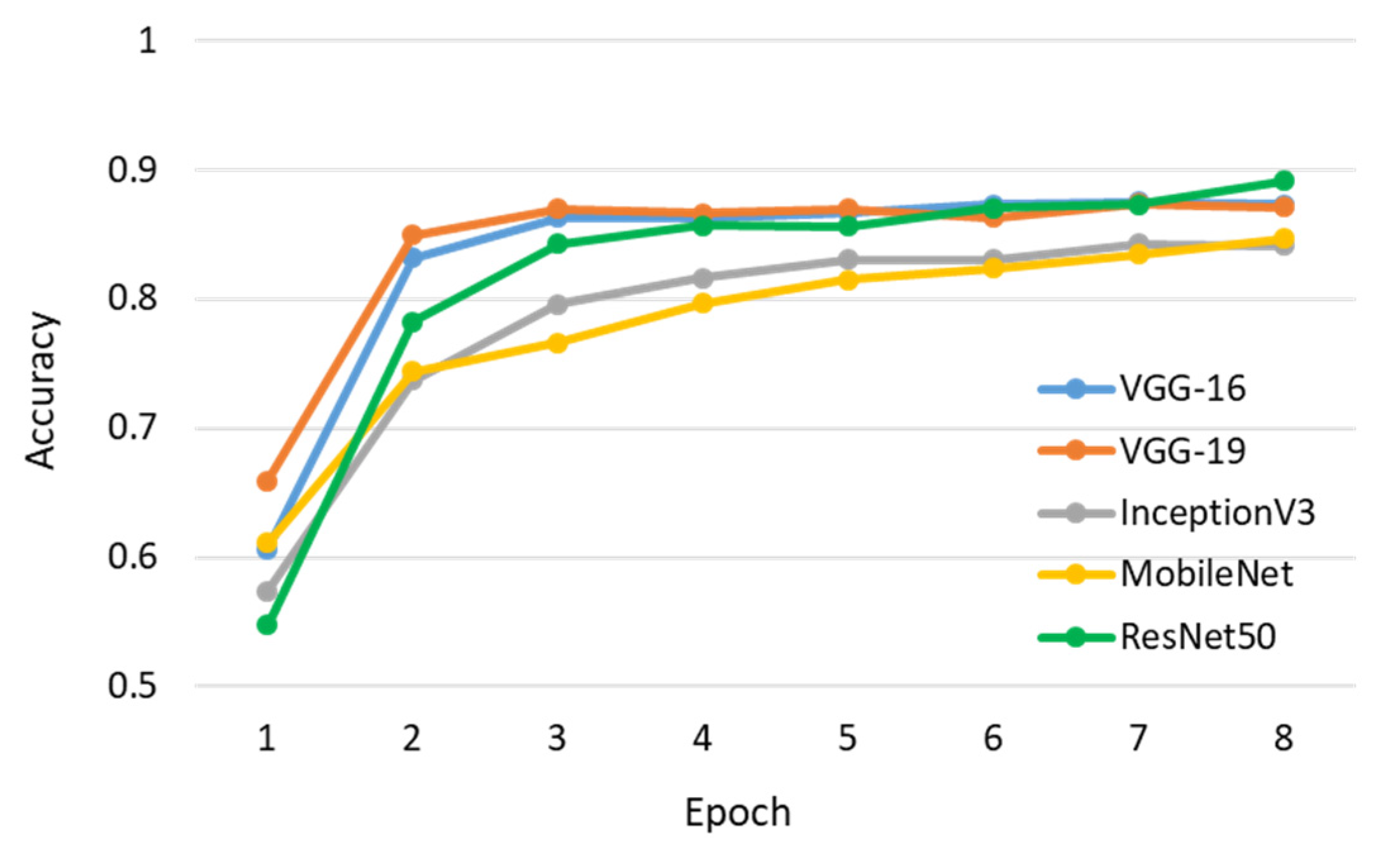
When designing the architecture of our deep model, several CNN-based models that are frequently used in image featuring were evaluated. In this subsection, five popular backbones, namely, VGG-16 and VGG-19 [
12], InceptionV3 [
16], MobileNet [
18], and ResNet-50 [
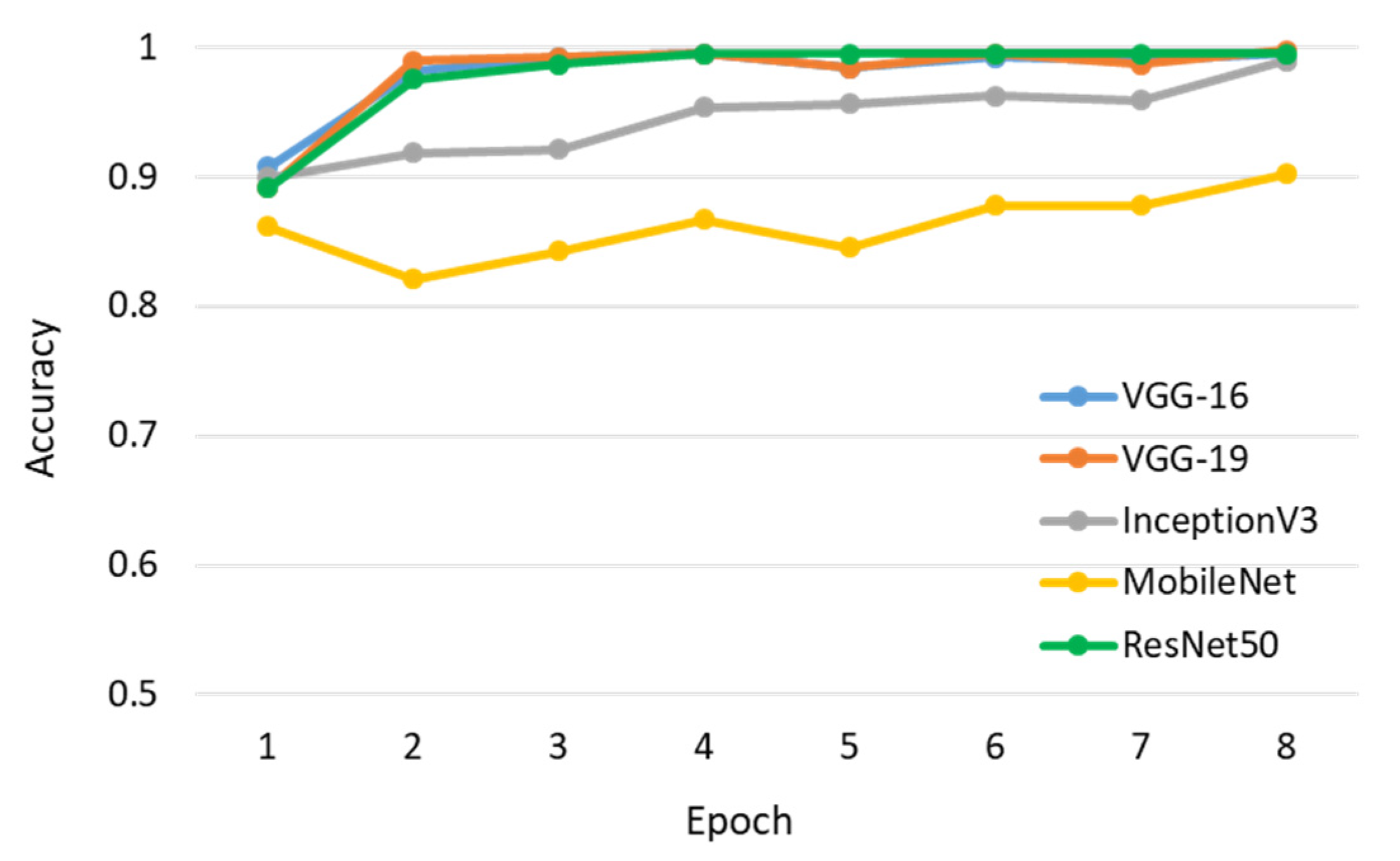
14], were chosen for comparison. For fairness, their inputs were normalized to an identical size and followed by the same classifier. Their training and validation accuracy are presented separately in
Figure 16 and
Figure 17. Notably, the training and validation accuracy were relatively high in the early epoch because these compared backbones were pre-trained on the ImageNet dataset [
22]. It can be seen that ResNet-50 outperformed other approaches after six epochs, whereas VGG-16 and VGG-19 showed comparable accuracy. Moreover, a computational comparison between these backbones is listed in
Table 6. Here, the minimum, maximum, and average computational time for identifying a pattern image and the total number of parameters of different models are also summarized. The VGG-16 and VGG-19, whose accuracies were comparable to ResNet-50, have a much larger number of model parameters. To consider the balance between accuracy and computational time, ResNet-50 was chosen as the standard subnetwork for the image feature extractor applied in our proposed method. More discussion on different CNN-based networks is provided in
Section 4.1.
3.4. Wafer Map Generation for Inspection Visualization
The final result of our proposed method is a multi-class wafer map, the classes of which can be manually defined by users. In this paper, four classes are applied: background, alignment mark, and normal and abnormal patterns. Let the original SAT image be the input; thereafter, automatic template extraction, pattern detection, and prediction steps, followed by pattern classification, are conducted. All patterns are found, and the information of each pattern, including the location, width, height, and its class is also obtained.
Figure 18 shows the final results corresponding to images
img01,
img02, and
img03. The patterns belonging to the background, alignment mark, and normal and abnormal pattern classes are plotted in gray, white, green, and red, respectively. The analyzed wafer maps are useful for visualizing defects and finding potential fabrication issues.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}