1. Introduction
Object detection is a hot topic in the field of computer vision and machine learning due to their widely applications in autonomous driving, robots, video surveillance, pedestrian detection, and so on. The classical object detection techniques are mainly based on the use of manual features, which can be divided into three steps: (1) target area selection; (2) feature extraction; (3) classification. In the first step, sliding-window strategy [
1] which utilizes the sliding-windows with different dimensions and length-width ratios is widely adopted to search for candidate regions exhaustively. In the second step, the candidate regions obtained in the first step are analyzed. Several techniques can be used in this step for feature extraction, such as scale-invariant feature transform (SIFT) [
2], histogram of oriented gradients (HOG) [
3] and speeded-up robust features (SURF) [
4]. In the third step, the candidate regions are classified according to the features extracted in the previous step by using classifiers such as support vector machine (SVM) [
5] and AdaBoost [
6]. Although the classical methods have been adopted in some object detection problems, there are still some limitations that hinder their breakthrough in speed and accuracy. Firstly, since the sliding-window strategy will capture many candidate regions in the original image, and the feature of regions needs to be extracted one by one, the classical object detection approaches are time-consuming. Secondly, the classical object detection methods may lack robustness because artificially designed features are sensitive to the variance in morphology, illumination and occlusion of object.
Recently, some deep learning techniques have been applied to object detection to overcome the limitations of traditional approaches [
7,
8,
9,
10,
11,
12,
13]. The current state-of-the-art detector based on the deep learning can be roughly divided into two categories. One is two-stage methods which first form a series of candidate object proposals by Selective Search [
8], EdgeBoxes [
9], DeepMask [
12] or region proposal network (RPN) [
7], and then input the proposals into convolutional neural network for classification. The other is one-stage methods which straightforwardly predict confidences and locations of multiple objects on the whole feature map without generating candidate object proposals.
Region-based convolutional network (R-CNN) [
14], as the beginning of combining object detection and deep learning, is a representative two-stage based approach. It achieves excellent object detection accuracy by extracting CNN features from the candidate regions and applies linear SVMs as the classifier. However, since the ConvNet forward pass is performed for each object proposal independently, the computational cost of R-CNN is high. Furthermore, the multi-stage training strategy which contains feature extraction, fine-tuning network, training SVMs, and bounding-box regression also makes the training of R-CNN be slow. In [
15], a spatial pyramid pooling network (SPPNet) was proposed. Although SPPNet can speed up R-CNN by sharing computation, its training is also a multi-stage pipeline. Besides, the fine-tuning algorithm proposed in SPPNet cannot update the convolutional layer, which limits its accuracy when the networks are very deep. For the sake of further decreasing the computational cost and improving the accuracy of object detection, Ross et al. proposed a fast region-based convolutional network (Fast R-CNN) [
16]. The Fast R-CNN utilizes a novel RoI-pooling operation to extract feature vectors for each candidate region from shared convolutional feature map, which greatly improves the processing speed. In Fast R-CNN, the detection accuracy can also be enhanced by updating all network layers during training. Although SPPNet and Fast R-CNN have effectively reduced the training time of object detection networks, the region proposal computation is still considered as a bottleneck in them. To deal with this issue, Ren et al. proposed a Faster R-CNN [
7] which replaces the Selective Search method with RPN to achieve end-to-end training. RPN is a kind of fully convolutional network (FCN) [
17]. By sharing full-image convolutional features with the detection network, RPN enables nearly cost-free region proposals to solve the time-consuming problem of Fast R-CNN. However, the multiple scale proposals generated by sliding a fixed set of filters over a fixed set of convolutional feature maps in RPN may be inconsistent with the sizes of objects. Thus, Cai et al. proposed a multi-scale CNN (MS-CNN) [
18] to match the receptive fields to different scales of objects and employed a multiple output layer for object detection. Recently, for the purpose of improving the detection performance, some more state-of-the-art techniques (such as Resnet [
19] and Inception series [
20,
21,
22]) were employed to replace the standard CNN as the backbone networks of the two-stage based object detection methods, which can be found in the object detection API from google [
23].
Different from the aforementioned methods, the one-stage approaches can achieve complete single network training under the premise of guaranteeing a certain accuracy rate. You only look once (YOLO) [
24], YOLO9000 [
25], an iterative grid based object detector (G-CNN) [
26], and single shot multibox detector) [
27] are representative techniques in this category. Through treating the object detection task as a regression problem, YOLO spatially separates bounding boxes and associated class probabilities. Since the whole detection pipeline of YOLO is a single network, an end-to-end optimization of the network can be directly performed. SSD combines predictions of multiple feature maps with different resolutions to detect objects of various sizes. Since the proposal generation, subsequent pixel and feature resampling stages are eliminated in SSD, it can be easily trained. Although the running speed of one-stage methods can be significantly improved, their accuracy is always inferior to the two-stage approaches [
27]. To address this issue, the Resnet and Inception have also been utilized [
23]. Furthermore, Lin et al. replaced the standard cross entropy loss with a novel Focal loss and proposed a RetinaNet to solve the class imbalance problem in one-stage based object detection [
28].
No matter the approach belongs to one-stage or two-stage, most the aforementioned algorithms do not effectively utilize the relationship among objects, but only use the feature associated with the object itself for detection. Recently, some researchers have realized the importance of relation, and proposed some methods [
29,
30,
31] to achieve better detection results by exploring the relationships between objects. In ION [
32], Bell et al. proposed a spatial recurrent neural networks (RNNs) for exploring contextual information across the entire image. Xu et al. put forward a scene graph generation approach by iterative message passing [
33]. The network regards a single object as a point in topology, and the relationships of objects are considered as edges connecting points. Through passing information between the edges and points, it is proved that the relationship between objects has a positive impact on detection. Georgia et al. proposed a human-centric based model called InteractNet [
34], in which human is regarded as the main clue to establish a relationship with other surrounding objects. The InteractNet indicates that a person’s external behavior can provide powerful information to locate the objects they are interacting with. Liu et al. proposed a structure inference net (SIN) [
35] which explores the structure relationship between objects for detection. However, SIN only takes the spatial coordinates of object proposals into account, while the appearance feature of object proposals is neglect. Han et al. presented a relation network [
36], which considers both the appearance and geometry feature of object proposals for relation construction. Nevertheless, the scene-level feature which could provide a lot of context information for object detection [
37] is ignored in relation Nntwork.
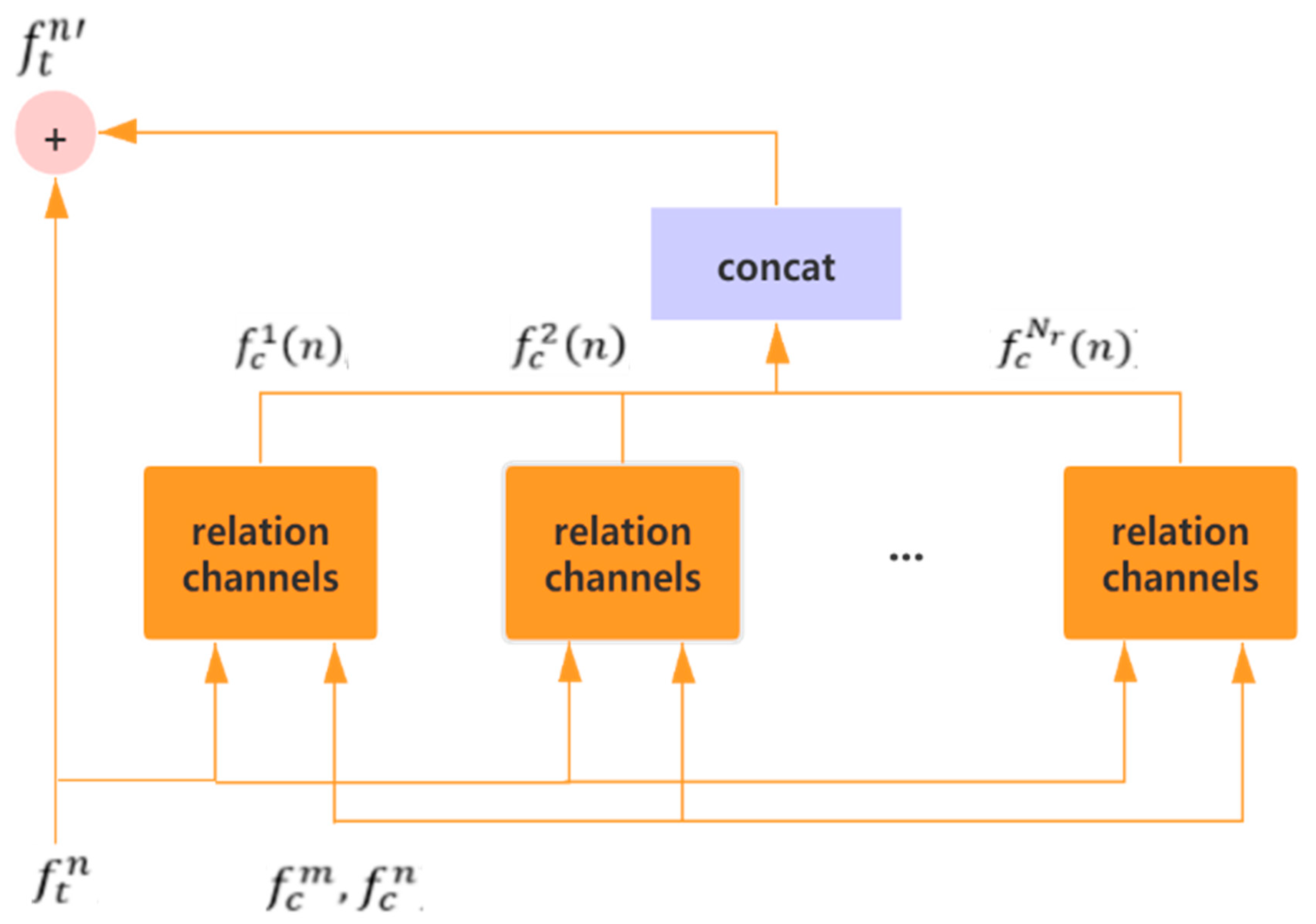
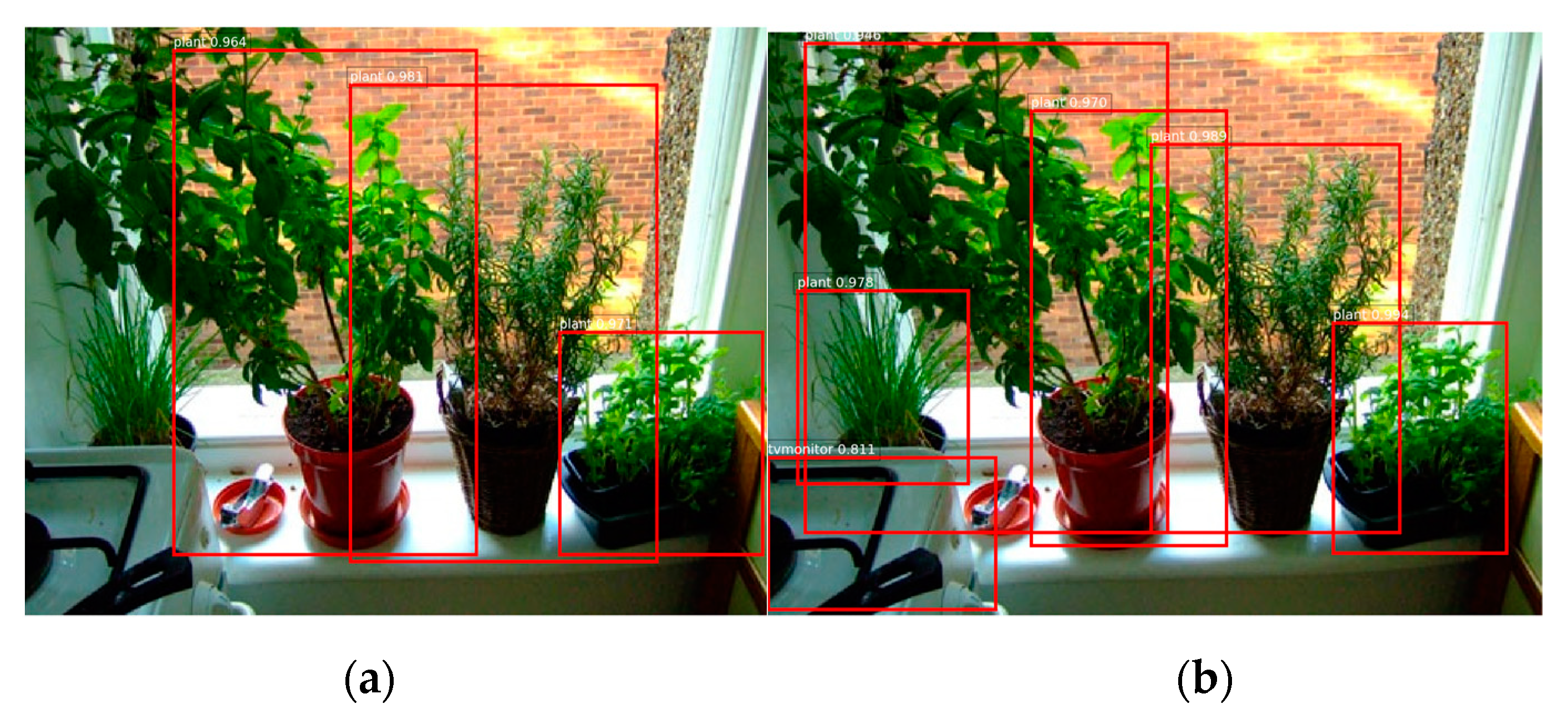
This paper proposes a novel object detection algorithm based on multiple information fusion net (MIFNet). Compared with the existing techniques, our algorithm not only adaptively establishes relationships between objects through attention mechanism [
38], but also introduces scene-level information to make the proposed approach richer in semantics. In MIFNet, the relationships between an object and all other objects are got by relation channel modules. Besides, by introducing the scene-level context [
21,
39,
40], the proposed network can enrich the object feature with scene information. The experimental results on PASCAL VOC [
41] and MS COCO [
42] databases demonstrate the effectiveness of the proposed algorithm.
The paper is structured as follows. The related work is introduced in
Section 2. The proposed MIFNet is described in
Section 3. The experimental results are given in
Section 4. The conclusion is provided in
Section 5.
2. Related Work
Context information: In real life, it is unlikely that an object can exist alone. Visual objects occur in particular environments and usually coexist with other related objects [
43]. When the object’s appearance feature is insufficient because of small object size, object occlusion, or poor image quality, a proper modeling of context will facilitate object detection and recognition task. Context information has been applied in many methods to enhance the performance of object detection [
44,
45,
46,
47,
48,
49], which can be roughly divided into two categories [
49,
50]: global information [
32,
51] (refers to the image level or scene level information), local information [
35,
36] (considers the object relationship or the interaction between the object and its surrounding area). It is proved that both the global and local context information have a positive impact on the object detection. Our proposed MIFNet has the capability of utilizing both global context (scene-level information) and local information (object relationship) to make the object’s appearance feature richer.
Attention mechanism: The attention mechanism in deep learning is inspired by the mode of human attention thinking and has been widely used in natural language processing [
52]. In attention module, an individual element can be influenced by aggregating information from other elements and the dependency between elements is modeled without excessive assumptions on their locations and feature distributions. The aggregation weights can be learned automatically, which is driven by the task goal. Recently, attention mechanism has been successfully applied in vision problems [
37,
53].
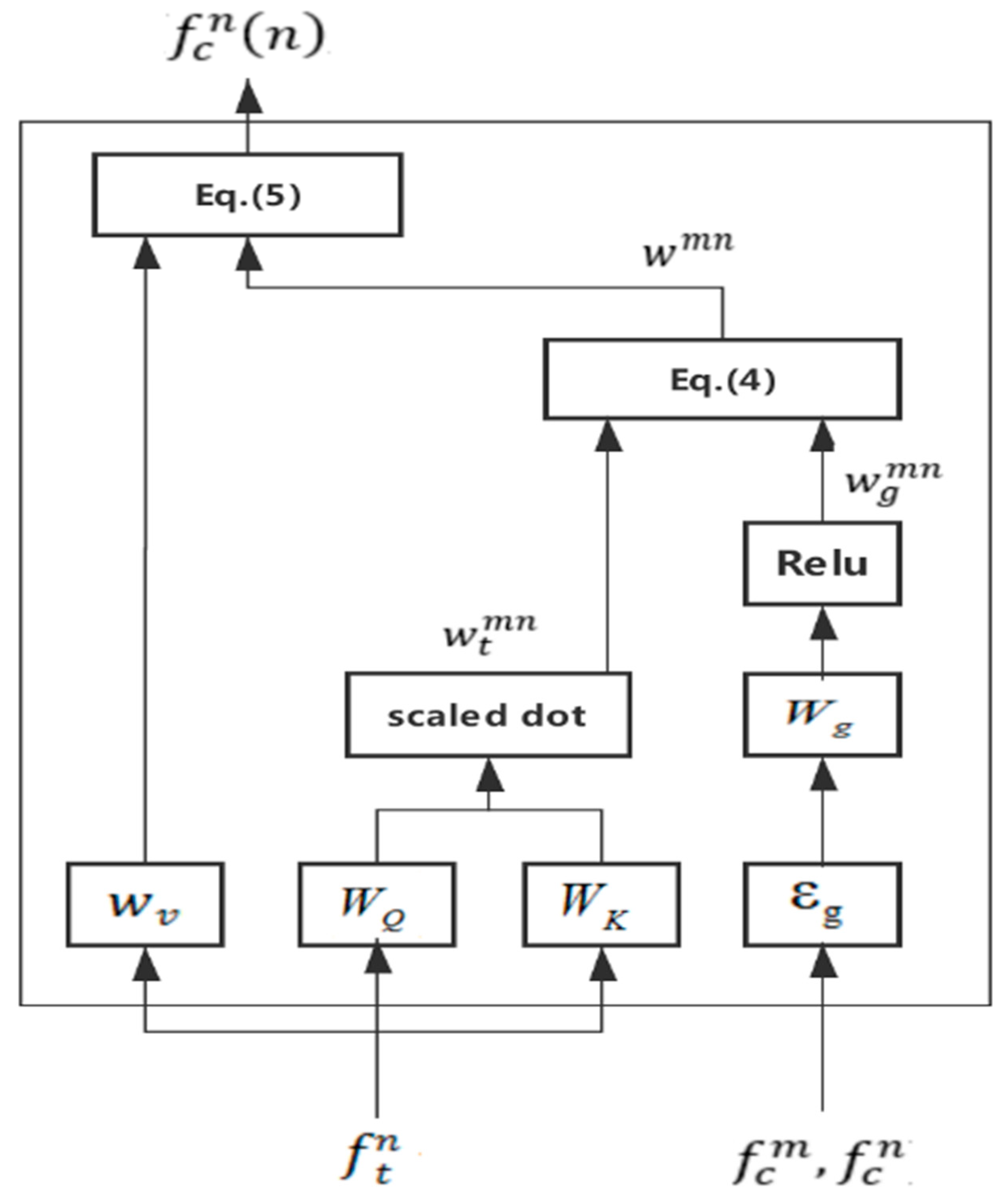
Attention mechanism can be represented as follows:
where
Q,
K,
V are three feature matrices with the same shape. In natural language processing,
Q,
K,
V represent sets of queries, keys, and values, respectively. In our work,
Q denotes the object feature,
K denotes all surrounding object feature,
V represents the all image feature (with object feature and location feature). In Equation (1), given a query
q ∈
Q and all keys
K, the dot products of
q with
K will be calculated to get the similarity between them. Then we divide dot products by a scaling factor
and the softmax function is applied to obtain the weights on all image feature (i.e., it can obtain the influence of each object on the current object). For more detailed information about the attention mechanism, the readers can refer to [
38]. In our work, the attention mechanism is utilized to get the relationship between objects.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}