1. Introduction
The use of web-based education systems or e-learning systems has grown exponentially in the last years, spurred by the fact that neither students nor teachers are bound to any specific location and that this form of computer-based education is virtually independent of a specific hardware platform. Adopting these e-learning systems in higher educational institution can provide us with enormous quantities of data that describe the behavior of students. In particular, Learning Management Systems (LMSs) are becoming much more common in universities, community colleges, schools, and businesses, and are even used by individual instructors in order to add web technology to their courses and supplement traditional face-to-face courses. One of the most popular LMS is Moodle [
1], a free and open-source learning management system that allows the creation of completely virtual courses (electronic learning, e-learning) or courses that are partially virtual (blended learning, b-learning). Moodle accumulate a vast amount of information, which is very valuable for analyzing students’ behavior and could create a gold mine of educational data. Moodle keeps detailed logs of all events that students perform and keeps track of what materials students have accessed. However, due to the huge quantities of log data that Moodle can generate daily, it is very difficult to analyze them, thus, it is necessary to use Educational Data Mining (EDM) and Learning Analytics (LA) tools [
2]. EDM and LA techniques discover useful, new, valid, and comprehensible knowledge from educational data in order to resolve educational problems [
3]. There is a wide range of EDM/LA tasks or applications, but one of the oldest and most important ones is to predict student performance [
4]. The objective of prediction is to estimate the unknown value of a variable that describes the student. In education the values normally predicted are performance, knowledge, score, or mark [
5]. This value can be numerical/continuous value (regression task) or categorical/discrete value (classification task). In fact, nowadays, there is a great interest in analyzing and mining students’ usage/interaction information gathered by Moodle for predicting students’ final mark in blended learning [
6,
7]. Blended learning combines the e-learning and the classical face-to-face learning environments. It has been termed as blended learning, hybrid, or mixed learning [
8]. Since either pure e-learning or traditional learning hold some weaknesses and strengths, it is better to mix the strengths of both learning environments into a new method of instruction delivery called blended learning.
Most of the research about predicting students’ performance has focused on scenarios that assume that the training and test data are drawn from the same course [
9]. As a matter of fact, the obtained/discovered models are mostly built on the samples that researchers have ready at hand, whether it is the current population of students at a university developing a model, the current user base of the adaptive learning system for which the model is being built, or just students who are relatively easy to survey or observe [
10]. However, in real educational environments, we historical data are not always available from all the courses. Let us imagine, for example, the case of a new course that is taught for the first time in an institution. Here, we would not have data for training model for predicting student performance. Yet, it is fair that the tutors and students of this new subject have the chance to work with predictive models that notify them of possible unwanted at risk situations such as student drop out. Thus, model portability can be very useful to create and use transferable models of other similar course in which we have a prediction model.
The idea of Portability is that knowledge extracted from a specific environment can be applied directly to another different environment. Within the educational sphere, this idea has great applicability, as it permits to use a model discovered on a previous course (source) to an ongoing course (target) that does not have a model for any reason whatsoever, and to apply these models with certain guarantees to this new course [
11]. Most of the previous works related with model portability use a Transfer Learning (TL) approach in which there is a tune-up process, usually based on deep learning approaches, so that the updated model is transferred from one course to another, as shown in [
12,
13]. Other different works use a Generalization approach that tries to discover one single general model that fit to all the exited courses [
14,
15]. This is the reason why, in this paper, we have used the term “portability” instead of the related terms “transferability” and “generalization”, since we think that it better describes the direct application of a model obtained with one dataset to a different dataset. In this regard, the goal of this research is to study the portability of predictive models between courses taught via blended-learning (b-learning) in formal university education. These predictive models try to predict whether a student will succeed or not in a certain course (pass or fail) starting to the log data generated from the student interactions with Moodle LMS. Specifically, the problem we want to resolve is: if we have available data for different university courses, could we use or apply the performance prediction model obtained in one specific course in other different course (in which we do not have enough data or we do not have a prediction model) without losing much accuracy. However, due to that the number of courses in a University can be large, and thus, the number of combinations will be huge, and it seems logical to think that good model portability only occurs between similar courses. This is why, in this paper, we propose to group courses in two different ways; our main objective in this paper is to answer the following two research questions:
Can the models obtained in one (source) course be used in other different similar (target) courses of the same degree, while maintaining an acceptable predictive quality?
Can the models obtained in one (source) course be used in other different (target) courses that make a similar level of usage of Moodle activities/resources?
The rest of the document is arranged in the following order:
Section 2 reviews the literature related to this research.
Section 3 describes the data and experiments. The results are shown in
Section 4.
Section 5 discusses the results obtained. Finally,
Section 6 presents the conclusions and suggests future lines of research.
2. Background
Within the EDM and LA scientific community, several works have been published that discuss the difficulty of achieving generalizable and portable models. In [
14], the authors suggested that it is imperative for learning analytics research to account for the diverse ways technology is adopted and applied in a course-specific context. The differences in technology use, especially those related to whether and how learners use the learning management system, require consideration before the log-data can be merged to create a generalized model for predicting academic success. In [
16], the authors stated that the portability of the prediction models across courses is low. In addition, they show that for the purpose of early intervention or when in-between assessment grades are taken into account, LMS data are of little (additional) value.
Nevertheless, Baker [
10] considered that one of the challenges for the future of EDM is what he called the “Generalizability” problem or “The New York City and Marfa” problem. In his words, Learning Analytics models are mostly built on the samples that we have ready at hand, whether it is the current population of students at a university developing a model, the current user base of the adaptive learning system we are building the model for, or just students who are relatively easy to survey or observe. However, what happens when the population changes? He defined this problem in three steps: (1) Build an automated detector for a commonly-seen outcome or measure; (2) Collect a new population distinct from the original population; and (3) Demonstrate that the detector works for the new population with degradation of quality under 0.1 in terms of AUC ROC (Area Under the ROC -Receiver Operating Characteristic- Curve) and remaining better than chance (AUC ROC > 0.5).
In this regard, there are works that have demonstrated the possibility of replicating EDM models. In [
17], they presented an open-source software toolkit, the MOOC (Massive Open Online Course) Replication Framework (MORF), and show that it is useful for replication of machine learned models in the domain of the learning sciences, in spite of experimental, methodological, and data barriers. This work demonstrates an approach to end-to-end machine learning replication, which is relevant to any domain with large, complex, or multi-format, privacy-protected data with a consistent schema.
What Baker [
10] defined as “Generalizability” is, in reality, closely related to the concept of Transfer Learning (TL). Boyer and Veeramachaneni [
11] defined TL as the attempt to transfer information (training data samples or models) from a previous course to establish a predictive model for an ongoing course. According to Hunt et al. [
18], TL enables us to transfer the knowledge from a related (source) task that has already been learned, to a new (target) task. This idea breaks with the traditional view of attempting to learn a predictive model from the data from the on-going course itself, known as in-situ learning.
As listed in [
11], there are various types of TL, among which are: (a) Naive Transfer Learning, when using samples from a previous course to help predict students’ performance in a new course; (b) Inductive Transfer Learning, when certain class labels are available as attributes for the target course; and (c) Transductive Transfer Learning, where no labels are available for the target course data.
Transfer learning has been applied in the field of EDM and LA in different applications. In [
18], they proposed an approach for predicting graduation rates in degree programs by leveraging data across multiple degree programs. There are also TL-based works for dropout prediction. In [
12], they developed a framework to define classification problems across courses, provide proof that ensemble methods allow for the development of high-performing predictive models, and show that these techniques can be used across platforms, as well as across courses. Nevertheless, this study neither mentions each course topic nor does it analyze the transferability of the models. However, in [
13] they proposed two alternative transfer methods based on representation learning with auto-encoders: a passive approach using transductive principal component analysis and an active approach that uses a correlation alignment loss term. With these methods, they investigate the transferability of dropout prediction across similar and dissimilar MOOCs and compare with known methods. Results show improved model transferability and suggest that the methods are capable of automatically learning a feature representation that expresses common predictive characteristics of MOOCs. A detailed description of the most relevant works in TL can be found in the survey presented in [
9], and more recently, in the survey described in [
19].
Domain Adaptation (DA) has gained ground in TL, being a particular case of TL that leverages labeled data in one or more related source domains, to learn a classifier for unseen or unlabeled data in a target domain [
20]. In this regard, [
21] propose an algorithm, called DiAd, which adapts a classifier trained on a course with labelled data by selectively choosing instances from a new course (with no label data) that are most dissimilar to the course with labelled data and on which the classifier is very confident of classification. A complete review of DA techniques can be found in [
20] and [
22].
Contextualizing our work in relation to the rest of the related research, we may affirm that our research is innovative and very interesting because it deals with one of the six challenges on EDM/LA community recently presented by Baker [
10] named the “The New York City and Marfa Problem”. Our work focuses on traditional university courses that use blended learning, while most of the previous works focus on MOOCs [
11,
12,
13,
21]. Although our research is very related to TL, as it fits the definitions of [
11,
18], it is not our goal to propose or study a specific tune-technique, similar to the latest research on DA [
21], but only to study the direct portability of prediction models. To do so, we will follow the idea demonstrated in [
13], but instead of carrying out tests with two subjects to prove the reliability of the method, our goal is to carry out a complete study with a greater number of courses in order to study the degree of model portability between subjects. Given that our study does not focus on any concrete technique, rather it studies the degree of portability of models; we use a direct transfer, also called Naive in [
11]. This type of transfer has innumerable benefits such as simplicity and immediacy, which can aid other researchers in easily replicating our study with their own data. Additionally, studies such as [
13] have demonstrated that this type of direct approach obtains better results than other approaches such as instance-based learning and even in-situ learning approaches. Taking all of this into account, and based on the extent of the authors’ knowledge, this is the first study that measures the degree of model portability in blended learning university courses (not MOOCs), focusing on how portability of model is affected when using course of the same degrees and courses with similar level of usage of Moodle.
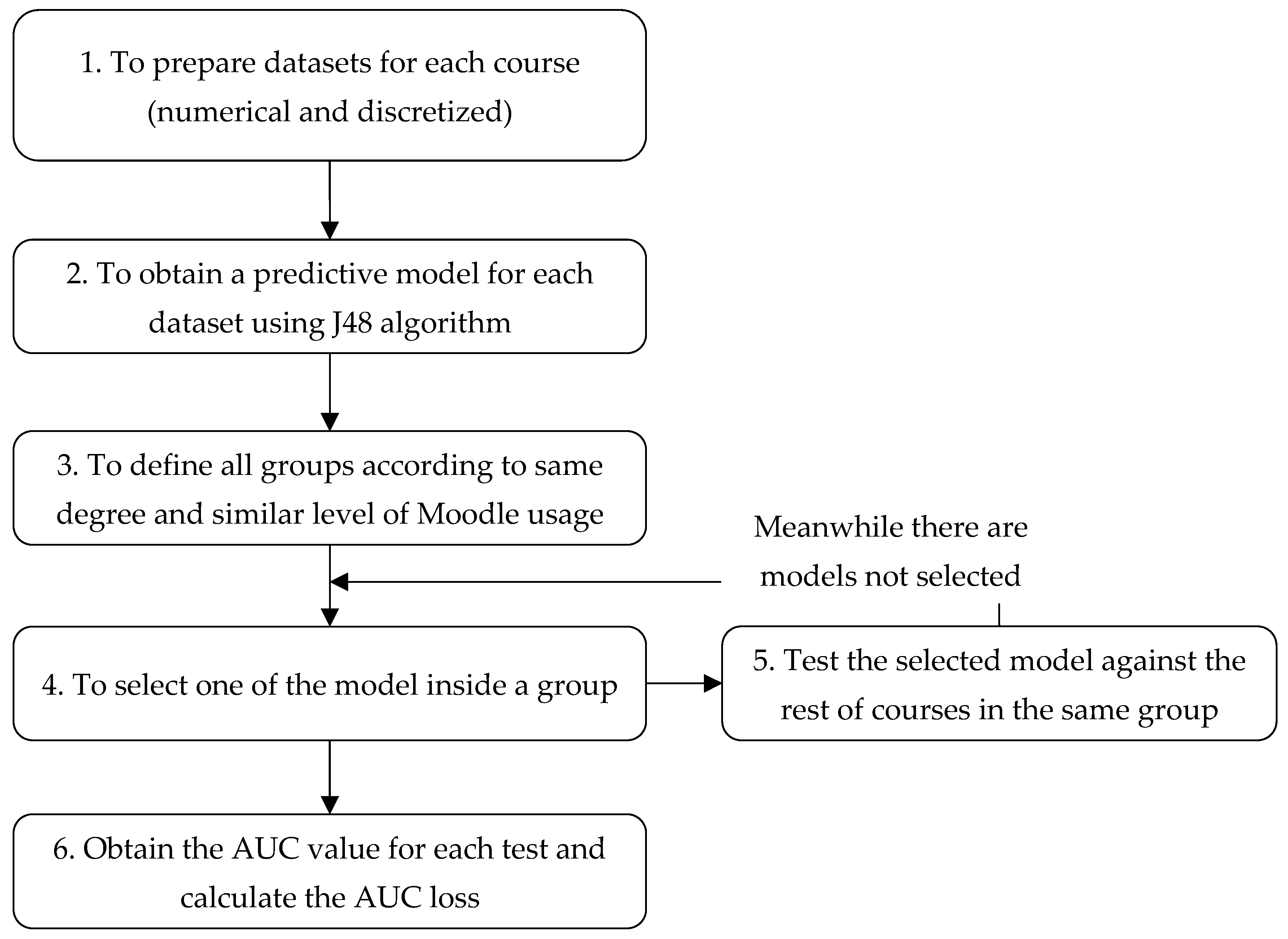
4. Results
In this section we show the results obtained from the two sets of experiments carried out. We present the AUC and the loss of AUC in four different matrixes (two for numerical datasets and two for discretized datasets) for each group of similar courses (see
Figure 2). In the upper part, we show two matrixes containing the AUC metric values that we have obtained when testing each course model (row) against the rest of the courses datasets (columns) using the numerical and the discretized datasets. The matrix main diagonal values correspond to the tests carried out for each course model against its own dataset, which means those AUC values (the highest ones) constitute the reference value (in green color) when compared with the rest of the courses. We have also calculated the average AUC values for each course (column denoted as “
avg” in the tables) and the overall mean value for the group (cell denoted as “
avg mean” in the tables). In the lower part, we show two matrixes showing the difference values between the highest AUC (row), which is considered to be the reference value, and the AUC values obtained when applying the corresponding model to each of the rest of the courses in the same group (column) using the numerical and the discretized datasets. Finally, our analysis focused on finding the best or highest AUC values and the best or lowest rates of AUC loss in each group of similar courses. Thus, we highlighted (in bold) the highest AUC values (without considering the reference value) and the lowest AUC loss values, which will represent the lowest portability loss, and thus the best results.
4.1. Experiment 1
In this experiment we assess the portability of prediction models between courses belonging to the same degree, having considered four different groups (Computer, Education, Engineering, and Physics). Firstly, we have obtained 24 prediction models (one for each course) and then we have tested them with the other courses’ datasets of the same group, which in this case is a total of 174 numerical and 174 discretized datasets. Thus, we have carried out a total of 348 executions of J48 algorithm for obtaining each AUC value and then calculated the AUC loss versus the reference model.
For the Computer group, we can observe from
Table 5 that the best AUC value (0.896) when transferring a prediction model to a different course corresponds to the PM (refer to
Table 1 for course names abbreviations) course model when tested against the DB course numerical dataset. However, we can observe that the overall mean value for AUC measure with discretized datasets is 0.56, which means that the predictive ability of models when used in other subjects of this group is lightly above randomness. Something similar happens with numerical datasets, where the average value is 0.57. We can also observe that the lowest (best) AUC loss in discretized dataset is close to the perfect portability (0.006). This value is obtained when using the PM model against the RE subject. Overall, we can observe that AUC loss is better in the discretized dataset than in the numerical one (0.23 versus 0.33 in average). We can also highlight that the best average values in terms of portability loss are obtained for DB course in numerical dataset and PM course in discretized datasets (0.10 in both cases).
For the Education group, we can observe from
Table 6 that the best AUC value (0.708) is obtained when using the prediction model of PESS course against the SSCM course discretized datasets. The overall average AUC for this group’s discretized dataset (0.56) is very similar to that for the numerical datasets (0.57). In addition, we noticed that portability loss (AUC loss) is near-perfect (0.003) when testing the PEPI model against HWA course dataset in the discretized datasets. The overall average portability loss for discretized dataset experiments is 0.29, much better than the mean value obtained for numerical dataset experiments (0.39). We can also highlight that the best average values in terms of portability loss correspond to PEPI course (0.30 for numerical datasets and 0.11 for discretized datasets).
For the Engineering group, we can observe from
Table 7 that the best AUC value (0.636) is obtained for ICS2 course prediction model when tested against ICS1 course discretized dataset. In this experiment, we can observe that the overall average value of AUC is again better in the numerical dataset (0.59) than in the discretized one (0.56), with both values staying above randomness. In addition, we can observe that the best portability loss value of 0.126 is obtained for ICS2 course model when tested against ICS1 course dataset in discretized datasets. Again, we obtain better results in the discretized than in the numerical dataset (0.24 versus 0.30) in terms of portability loss. We can also highlight that the best course average portability loss values are obtained for ICS3 in numerical dataset (0.20) and for ICS1 subject in discretized dataset (0.22).
Finally, for the Physics group, we can see in
Table 8 that the highest AUC value (0.641) corresponds to the MM course prediction model when tested against the MA2 course numerical dataset. This value is very close to the overall mean value for the numerical dataset (0.68), which outperforms the overall AUC mean value for the discretized dataset (0.60). If we look at the portability loss values, we notice that the best (the lowest) AUC loss value of 0.009 is obtained when testing the MM course model against MA1 course discretized dataset. In this group, again, the global mean values are better for the discretized dataset than for the numerical one (0.09 versus 0.28), which means that the portability loss rate is particularly lower in this experiment in the discretized dataset compared to the numerical one. We can also highlight that the best course portability loss values are obtained for MM course model in both the numerical (0.21) and discretized (0.04) datasets.
4.2. Experiment 2
In this experiment we assess the portability of prediction models between courses with a similar level of usage of Moodle activities. In fact, we have considered three different groups (High, Medium, and Low). Firstly, we have obtained 24 prediction models (one for each course), and then, we tested them with other courses datasets of the same group, in this case a total of 204 numerical and 204 discretized datasets. Thus, we have carried out a total of 400 executions of J48 algorithm for obtaining each AUC value and then calculating the AUC loss versus the reference model.
For the high level group, as we can see from
Table 9, the best value for AUC measure (0.656) is obtained when testing the IS course prediction model against the PM course discretized dataset. In this experiment (and equal than in the previous ones), the overall AUC means values are very similar for numerical (0.58) and discretized datasets (0.57). If we have a look at portability loss values, we can see that the best AUC loss value (0.061) is obtained when testing the ICS2 model against IS discretized dataset. In general, the average mean of AUC loss is better for the discretized datasets than for the numerical datasets (0.24 versus 0.37). Finally, we highlighted the average values of AUC loss for the ICS2 course, which are the lowest both in numerical datasets (0.25) and in discretized datasets (0.10).
For the medium level group, we can observe from
Table 10 that the best AUC value of 0.792 corresponds to the prediction model of SDC course when tested against the discretized dataset of the SSCM course. The global average AUC value for this discretized category (0.53) is very similar to the global AUC value for numerical datasets (0.55). Regarding portability loss, we can see that the best value (0.009) belongs to DB prediction model when tested against PEPI discretized dataset. Moreover, again, the portability loss is better in the discretized datasets (0.25) than in the numerical datasets (0.38). Finally, we would also like to highlight the good average AUC loss results obtained by the InS course prediction model with the numerical datasets (0.12) and DB course prediction model in the discretized datasets (0.14).
Finally, for the low level group, we can see from
Table 11 that the best AUC measure value (0.758) is obtained when testing the ICS3 prediction model against the HWA numerical dataset. The global average value for the numerical dataset (0.57) is a bit better than the obtained value by the discretized dataset (0.54). We can also notice that the best portability loss value is obtained when testing the MM model against HWA discretized dataset (0.028). The overall mean value for portability loss measure is also better for discretized than for numerical datasets (0.22 versus 0.34). Additionally, the best course prediction model on average values in terms of portability loss correspond to KSCE for numerical dataset (0.16) and MM for the discretized dataset (0.12).
5. Discussion
About the obtained accuracy of the student performance prediction models, as we can see in previous section tables for Experiments 1 and 2, it is noticeable that average AUC values are always a little better in the case of the numerical datasets than the discretized datasets. It is logical and expected that the models’ predictive power is higher when we use numerical values. In Experiment 1, the average AUC highest values are obtained for the Physics group, having 0.68 for the numerical dataset and 0.60 for the discretized one. In Experiment 2 the highest values are found in the High group, obtaining values of 0.58 for the numerical dataset and 0.57 for the discretized dataset. Thus, in general the average AUC values are not high and only a little higher than a change (0.5). If we have a look at the maximum values for AUC, there is not a clear rule that we can obtain since we have found similar good values in both experiments: 0.89 in Computer group of experiment 1 with numerical datasets and 0.79 in medium level group of experiment 2 with discretized datasets. We can conclude that the accuracy of the prediction models when we transfer them to other different courses are not very high (but higher than a chance, AUC > 0.5), it is a little higher when using numerical values (but only slightly) and similar results are obtained in both experiments. We think that this can be in part due to the number of students vary a lot of from one course to another, ranging from 50 (minimum) to 302 (maximum) and the number of attributes vary from one dataset to another.
When assessing the models’ portability, we have also used the AUC loss as an indicator of portability loss. According to Baker [
10], prediction models are portable as long as their portability loss values stay around 0.1 (and AUC is kept above randomness). In general, in our two experiments, we have only obtained these good values in one group, namely, the Physics group with discrete datasets with 0.60 AUC average value and 0.09 AUC loss average. Thus, this group of courses fit the Baker’s rule for model portability. However, if we look at specific cases, we also found that some specific models that applied to specific courses datasets obtain good results and fit the Baker’s rule. For instance, in Experiment 1, the minimum values of portability loss was 0.008 for the numerical dataset (Computer group; DB transfer to SE) and 0.006 for discretized dataset (Computer group; PM transfer to RE). In Experiment 2, the minimum value of portability loss was 0.021 for numerical dataset (Medium group; InS transfer to PESS) and 0.009 for discretized dataset (Medium group; DB transfer to PEPI). These results indicate that some particular prediction models are applicable to some other different courses. However, we are more interested in finding if a model can be correctly transferred to all the rest of the courses in its group, and thus, we have a look at portability loss average values (“
avg” loss column). In this regard, we have also found some good results, and the best four prediction models are described below. In Experiment 1, we have obtained good average results for the DB prediction model in the numerical dataset (average loss of 0.10) and the MM prediction model in the discretized dataset (0.04). Some similar results were obtained in Experiment 2 with InS prediction model in the numerical case (0.12) and ICS2 prediction model in the case of discretized dataset (0.10). It is important to highlight that those best four models not only present average portability loss values close to 0.10, but they all also keep average values of AUC above randomness. Thus, it indicates that those models are portables and they can be used to correctly predict in the rest of the courses in their group and we can conclude that they meet the conditions established in the portability challenge defined by Baker in The Baker Learning Analytics Prizes [
10]. We also checked if these courses are very similar (number of students, number of types of activity, teachers in charge of the course, etc.), having only found some similarities in the group of Physics (which obtained the best average mean AUC Loss). In particular, we noticed that the instructors in charge of the three Mathematics courses in the Physics group were the same and they used the same methodology and evaluation approach in all their courses.
Next, we will show and comment those best four decision trees prediction models. The discovered knowledge from a decision tree can be extracted and presented in the form of classification IF-THEN rules. One rule is created for each path from the root to a leaf node. Each attribute-value pair along a given path forms a conjunction in the rule antecedent (IF part). The leaf node holds the class prediction, forming the rule consequent (THEN) part. In our case, we will show the J48 pruned tree that Weka provides when training a classification prediction model. We have added the word “THEN” to the output of Weka in order to make easier the reading of each rule.
5.1. Best Models of Experiment 1
In
Figure 3 we can see the best decision tree for Computer group with numerical datasets that is the prediction model of DB course. It is a big tree (27 nodes in total) that consists of eight leaf nodes or rules for the
Pass class and six rules for the
Fail class. We can see that all the attributes or Moodle events counts are about assignment, choice, forum, page, and resource. In most of the branches that lead to
Pass leaf nodes, we can see “greater than” conditions over attributes and “less or equal than” condition in the attributes of branches that lead to
Fail classification. Thus, we can conclude that in this prediction model to have a minimum threshold number of events in these activities seem to be much related with students’ success in the course.
Figure 4 shows the best decision tree in the Physic group with discretized dataset, that is, the prediction model of the MM course. It is a small decision tree (11 nodes in total) with five leaf nodes labeled with the
Pass value and only one leaf node with the label
Fail. The attributes or events that appear in the tree are about page, resource, and forum. Thus, thanks to the little number or rules and the high comprehensibility of the two labels (HIGH and LOW) the tree is very interpretable and usable by an instructor. For example, if we analyze the branch leading to that
Fail leaf node, we can see that students that showed a low number of events with pages, resources, and forums are quite likely to fail the course.
5.2. Best Models of Experiment 2
In
Figure 5, we show the best decision tree in the medium level group with numerical datasets, that is, the prediction model of the Ins course. It is a medium size tree (15 nodes in total) that has three rules or leaf nodes for
Pass class and five rules for
Fail. The attributes or events that appear in this tree are about forum, page, and choice. Most of the branches that lead to
Pass show that students must have a greater number of events in these attributes than a specific threshold. The rest of paths lead to students’ fail.
Figure 6 show the best decision tree obtained in the high level group with discretized dataset, which is the prediction model of ICS2 course. It is a small tree (only nine nodes in total) that has three leaf nodes or rules for predicting when the students
Pass and two rules for
Fail. In this model, the attributes or Moodle events that appear in the rules are about forum, resource, and choice activities. Again, most of the branches that lead to
Pass show that student must have a greater number of events in these attributes than a specific threshold. The rest of paths lead to students’ fail.
6. Conclusions and Future Research
This paper presents a detailed study about the portability of predictive models between universities courses. To our knowledge, this work is one of the first exhaustive studies about portability of performance prediction models with blended university courses, and thus, we hope that it can be of help to other researchers who are also interested in developing models for portability solutions in their educational institutions.
In order to answer to our two research questions, we have carried out two experiments executing the J48 classification algorithms over 24 courses in order to obtain the AUC and AUC loss of the models when applying to different courses of the same group by using numerical and discretized datasets. Starting of the results obtained in our experiments, the answers to our two research questions are:
How feasible it is to directly apply predictive models between courses belonging to the same degree. By analyzing the results shown in
Table 5,
Table 6,
Table 7 and
Table 8, we can see that the average AUC values are not very high (both in numerical and discretized datasets), but when we used discretized datasets, the obtained models are better in terms of AUC loss or portability loss, in spite of the fact that numerical datasets present the best AUC values, which is something that we expected in advance. In fact, portability loss values are inside the interval from 0.09 to 0.28 for the discretized datasets and we obtained good portability loss results in the Computer group and in the Physics group.
How feasible it is to directly apply predictive models between courses that make a similar level of usage of Moodle. By analyzing the results shown in
Table 9,
Table 10 and
Table 11, we can see that again, the best AUC values are obtained with the numerical datasets but they are not very high. However, the best lowest portability loss values are obtained with the discretized datasets in the range from 0.22 to 0.25. In this experiment, we did not find results as good as in the first one, but nevertheless, the results obtained are inside an acceptable range.
In conclusion, the results obtained in our experiments with our 24 university courses show that it is only feasible to directly transfer predictive models or apply them to different courses with an acceptable accuracy and without losing portability under some circumstances. In our case, only when we have used discretized datasets and the transfer is between courses of the same degree, although only in two specific degrees of the four degrees tested, the loss portability is feasible. Additionally, we have shown the four best prediction models obtained in each experiment (1 and 2) and type of dataset (numerical and discretized). We have obtained that the most important attributes or Moodle events that appear in the decision trees are about forums, assignments, choices, resource, and page. However, it is important to remark that prediction models when using discretized datasets not only provide the lowest AUC loss values, that is, the best portability, but they also provide smaller decision trees than numerical ones and they only use two comprehensible values (HIGH and LOW) in their attributes (instead of continues values with threshold) that make them much easier to interpret and transfer to other courses.
A limitation of this work is the fact that the best obtained models (decision trees) might not be directly actionable by the teachers of the other courses since those models may include activities or actions that their courses do not have. We have technically solved this problem by executing J48 as Wrapper classifier that addresses incompatible training and test data by building a mapping between the training data that a classifier has been built with and the incoming test instances’ structure. Model attributes that are not found in the incoming instances receive missing values. We have to do it because there are some cases when the source course and the target course do not exactly use the same attributes (they do not have the same events in their logs). We also think that this issue can be one of the reasons why we have obtained low accuracy values when applying a model to other courses that use different activities.
Finally, this work is a first step in our research. The experimental results obtained show that new strategies must be explored in order to get more conclusive results. In the future, we want to carry out new experiments by using much more additional courses and other degrees in order to check how generalizable our results can be. We are also very interested in the next potential lines or future research lines:
To use a low number of higher-level attributes proposed by pedagogues and instructors (such as ontology-based attributes) in order to analyze whether using only few high level semantic sets that remain same in all the course datasets has a positive influence on portability results.
To use other factors (apart from the degree and the level of Moodle usage) that can be used to group different courses and analyze how portable the models are inside those groups, for example, the number of students, the number of assessment tasks, the methodology used by the instructor, etc. Furthermore, if we have a higher number of different courses, we can do groups inside groups, for example, for each degree, to group the course by the level of Moodle usage and the same used activities.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}