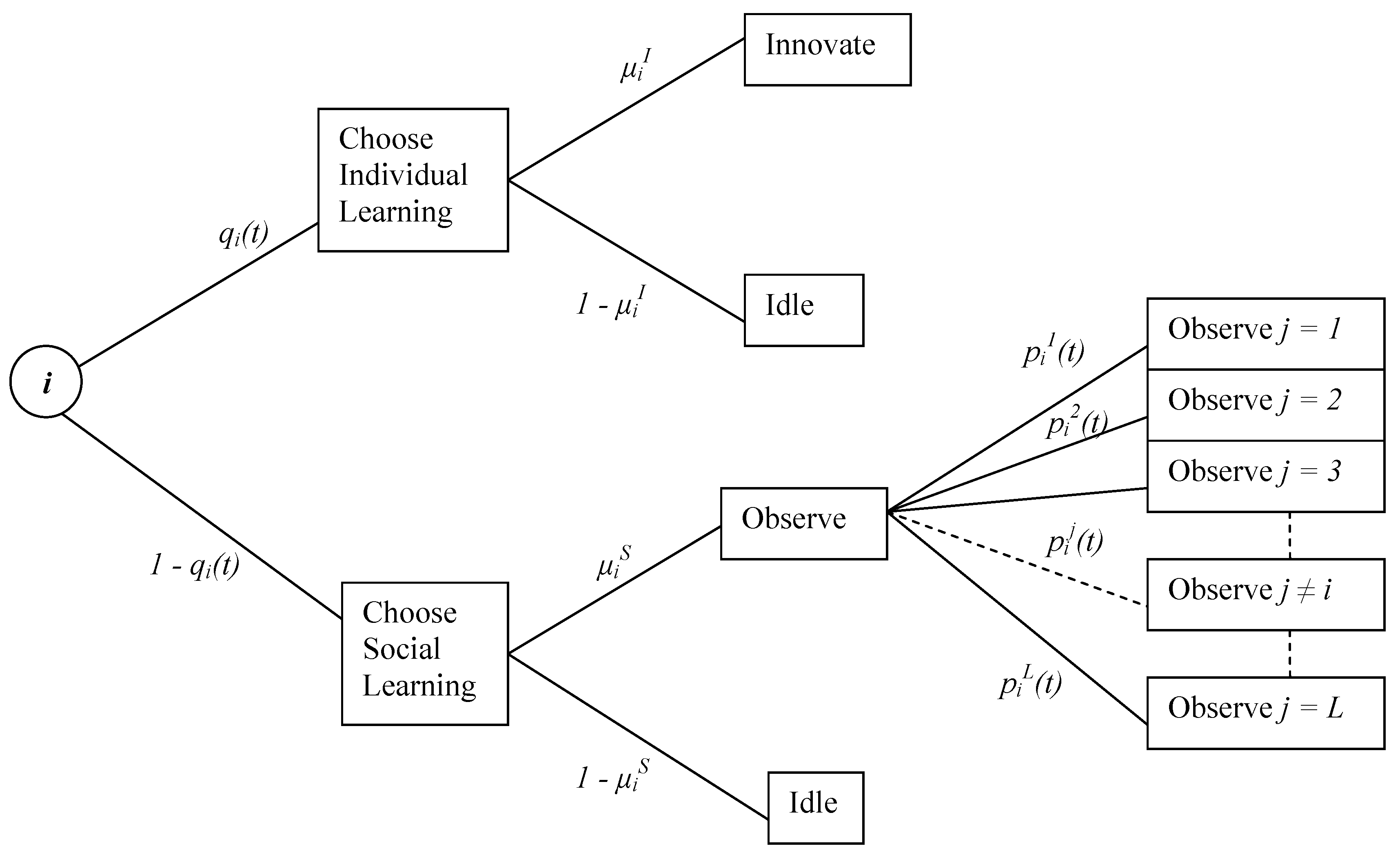
We first consider “small” populations by which is meant those with two or three agents. The reason for initially focusing on these cases is that the vector of probabilities (of an agent being in the individual learning mode) can be depicted graphically which quite effectively illustrates what is going on. In the next section, larger populations are considered and, using different methods for reporting results, we show that much of the insight of this section extends. Note that, with only two agents, each agent has only one other agent to observe when she chooses social learning so the structure of the social network is not an issue. The endogeneity of the network is an issue, however, when there are three agents. Procedurally, we will first report results for when there are two agents and then show that the same property holds for when there are three agents.
4.1. Emergence of Specialization
To establish a baseline for comparative analyses, we ran the computational experiment with the following set of parameter values: and . Both agents are capable of generating an idea every period, whether it is through individual learning or through social learning. There is a probability of 0.8 that the problem environment will be stable from t to . If the environment changes, which occurs with the probability of 0.2, it involves a change in only one randomly chosen task.
The two agents are initially homogeneous in all aspects. They have identical levels of skills in individual and social learning so that and . They start out equally likely to choose individual learning and social learning so that .
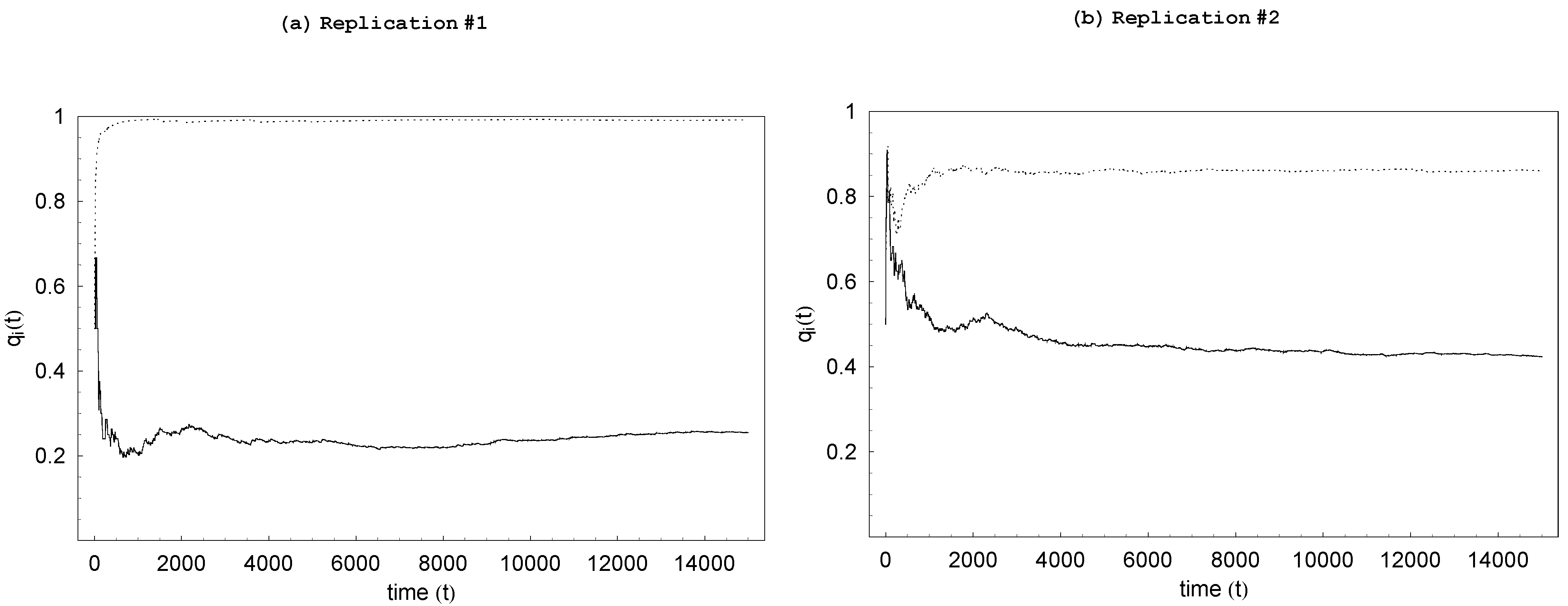
Given the baseline parameter configuration,
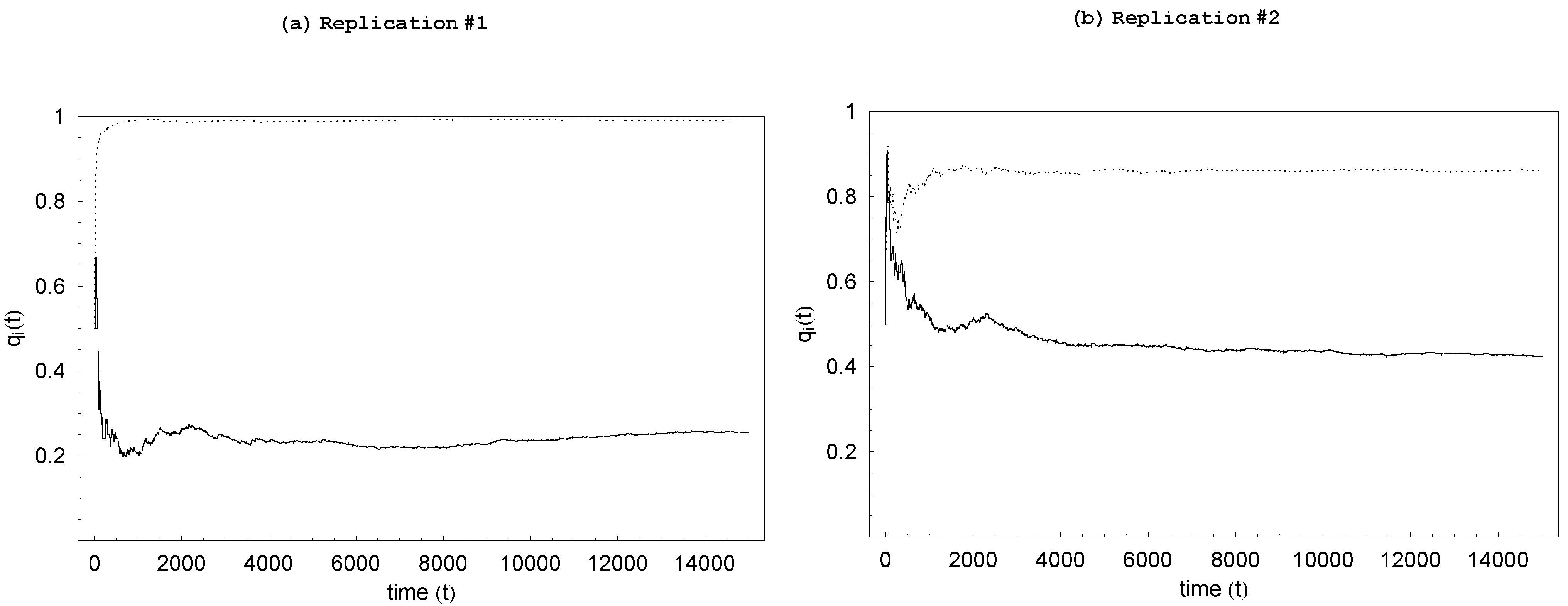
Figure 2 shows the typical time paths of
s for
which are generated from two independent replications. The time paths captured in these figures, which are typical of all replications carried out in this work, clearly indicate that our definition of the steady-state as the 5,000 period between
and
is more than adequate: While there is a brief initial transient phase in which
s fluctuate somewhat widely, they tend to stabilize rather quickly. It is clear that these probabilities exhibit high degrees of persistence. What is more striking, however, is the way
s diverge from one another in the long run: the agents tend to concentrate on distinct learning mechanisms—agent
i specializing in individual learning (high value of
) and agent
j specializing in social learning (low value of
) and, thus, free-riding on agent
i for knowledge acquisition.
Figure 2.
Typical time paths of s from two replications ( and ).
Figure 2.
Typical time paths of s from two replications ( and ).
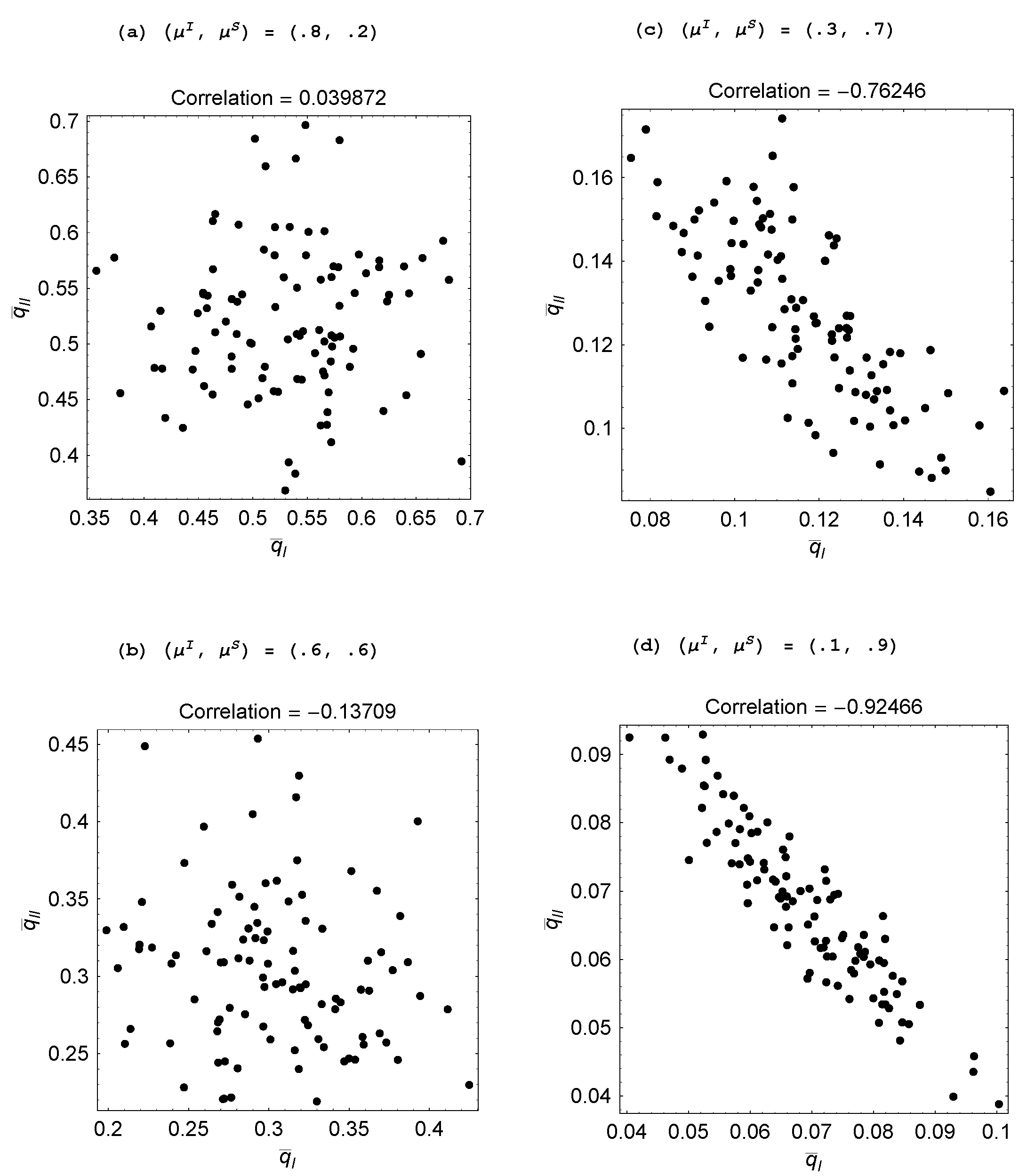
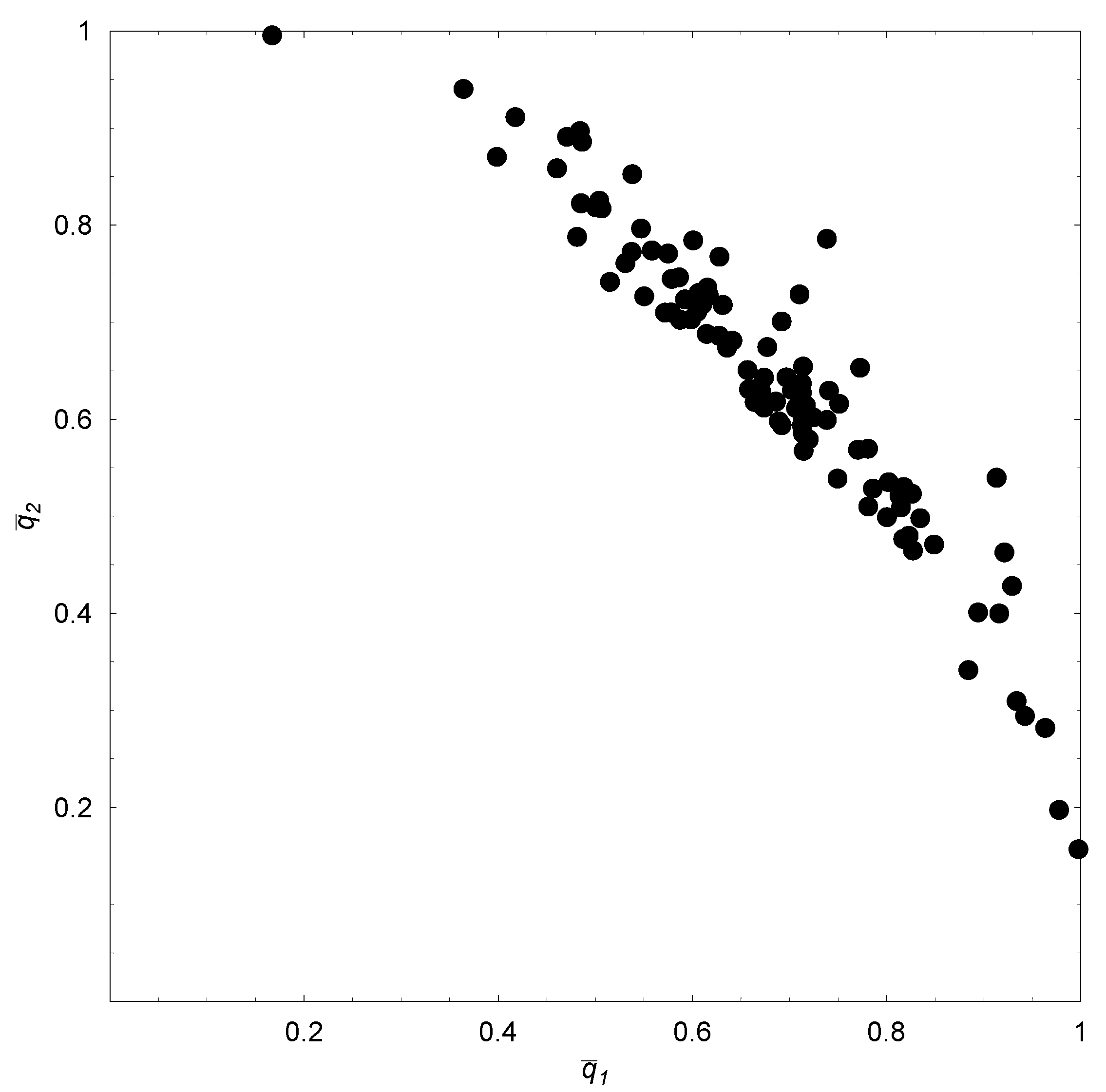
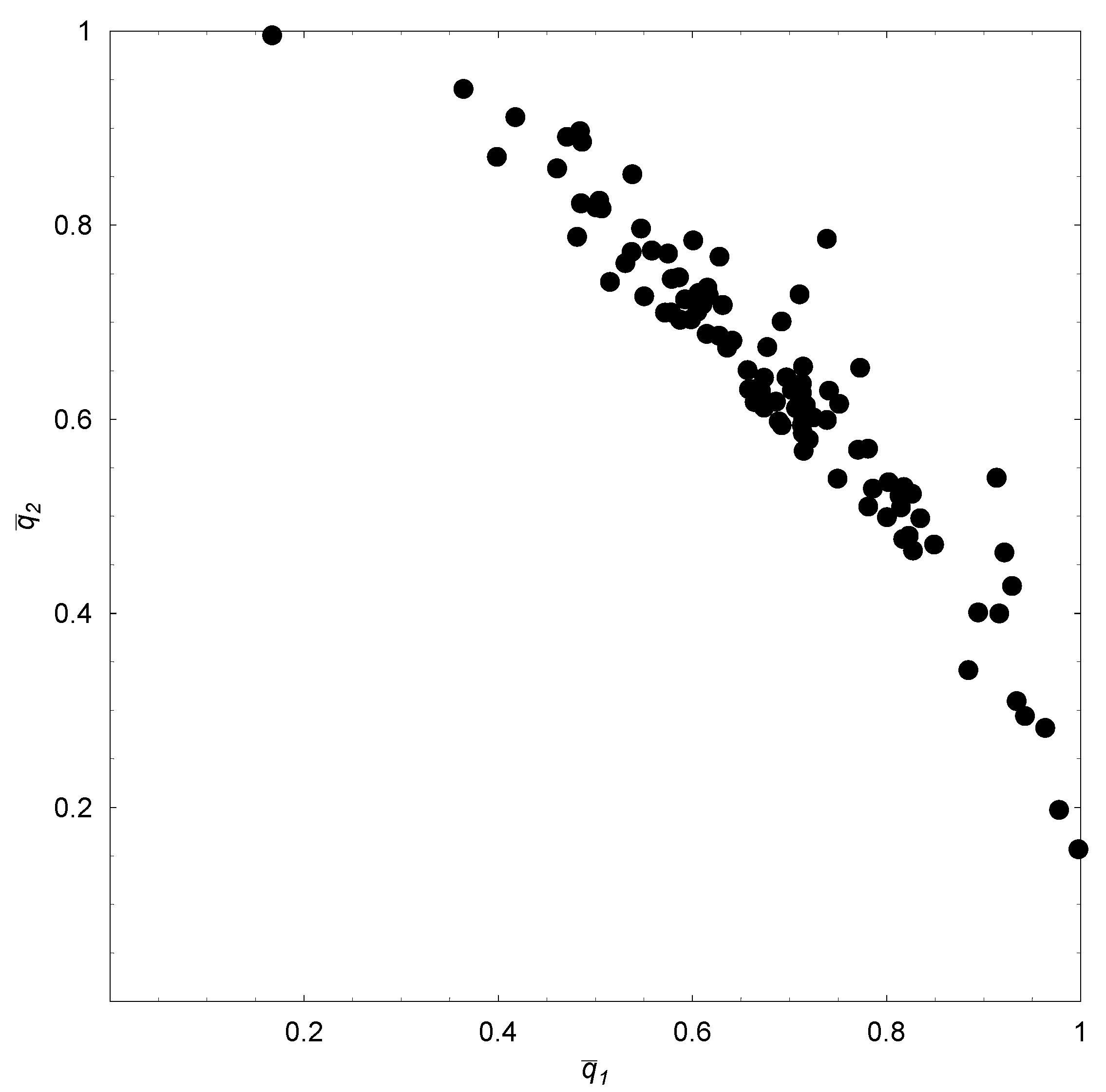
To confirm the tendency for the agents to specialize, we ran 100 replications for the baseline set of parameter values, each replication with a fresh set of random numbers. The
steady-state probabilities for the two agents,
and
, were then computed for each replication, thereby giving us 100 realizations of the probability pair. In
Figure 3, these realizations are plotted in a probability space. Note the strongly negative correlation between
and
. More intensive individual (social) learning by an agent induces the other agent to pursue more intensive social (individual) learning. As this property is confirmed by results reported below for other parameter configurations and when there are three agents, we state:
Property 1 For populations with two or three agents, there emerges a divergence in the choices of learning modes: When one agent chooses individual learning with a higher probability, the other agent(s) chooses social learning with a higher probability.
The implication is that social learners free-ride on an individual learner and an individual learner accommodates such behavior by concentrating on generating new ideas.
Figure 3.
(, )’s with over 100 replications ( ).
Figure 3.
(, )’s with over 100 replications ( ).
To establish the robustness of this phenomenon of specialization and explore its determinants, the same exercise was performed for
and for both two-agent and three-agent populations.
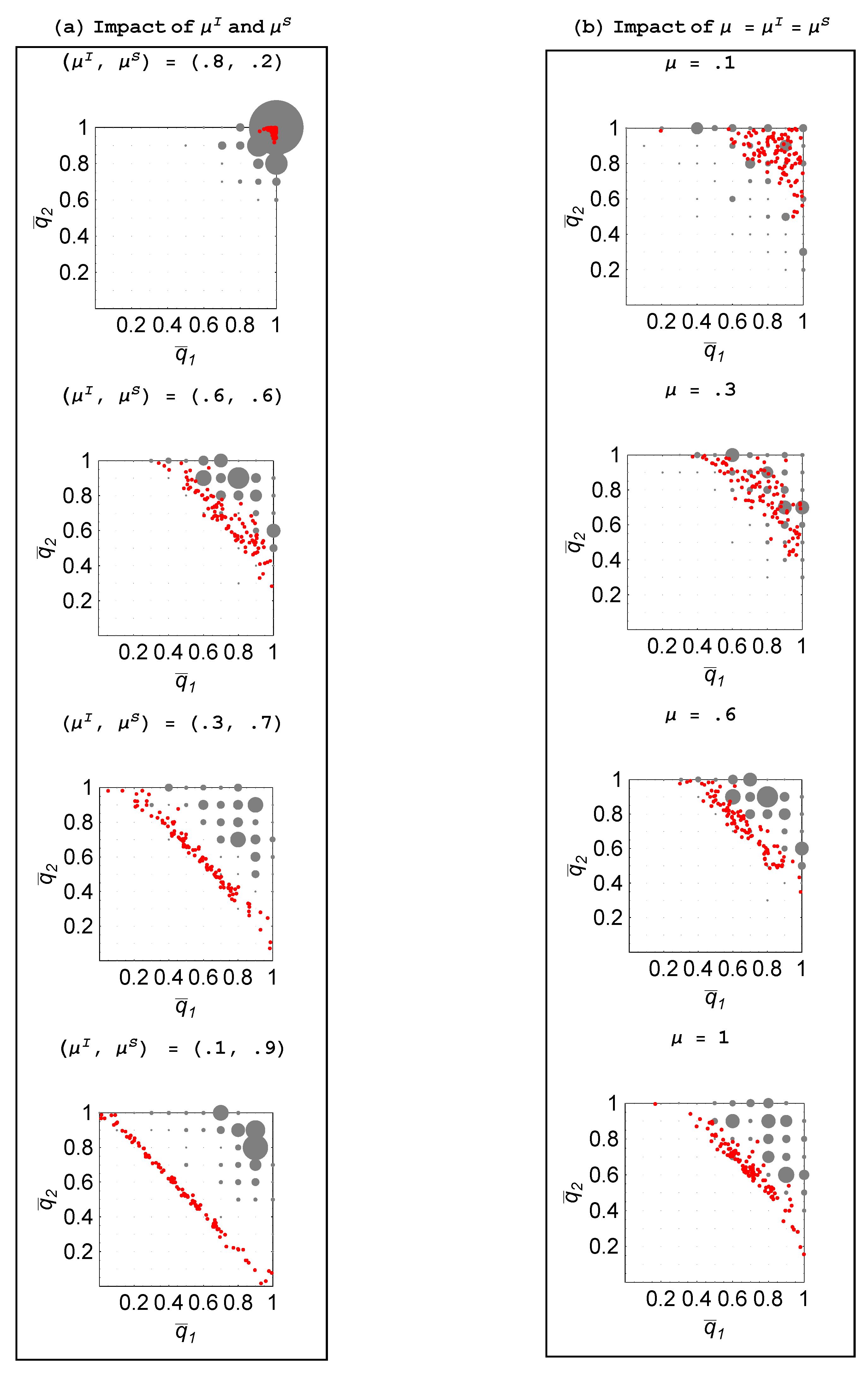
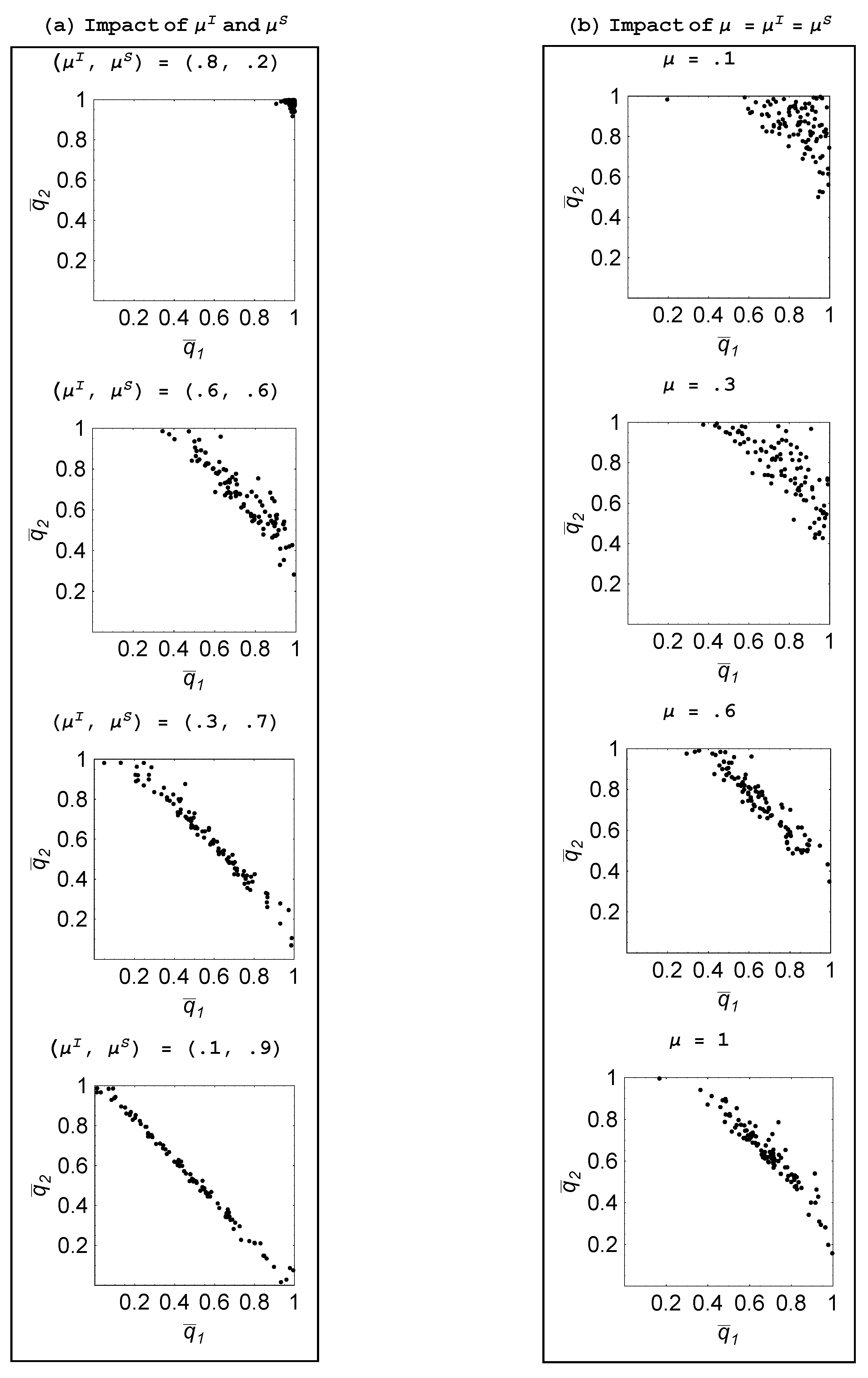
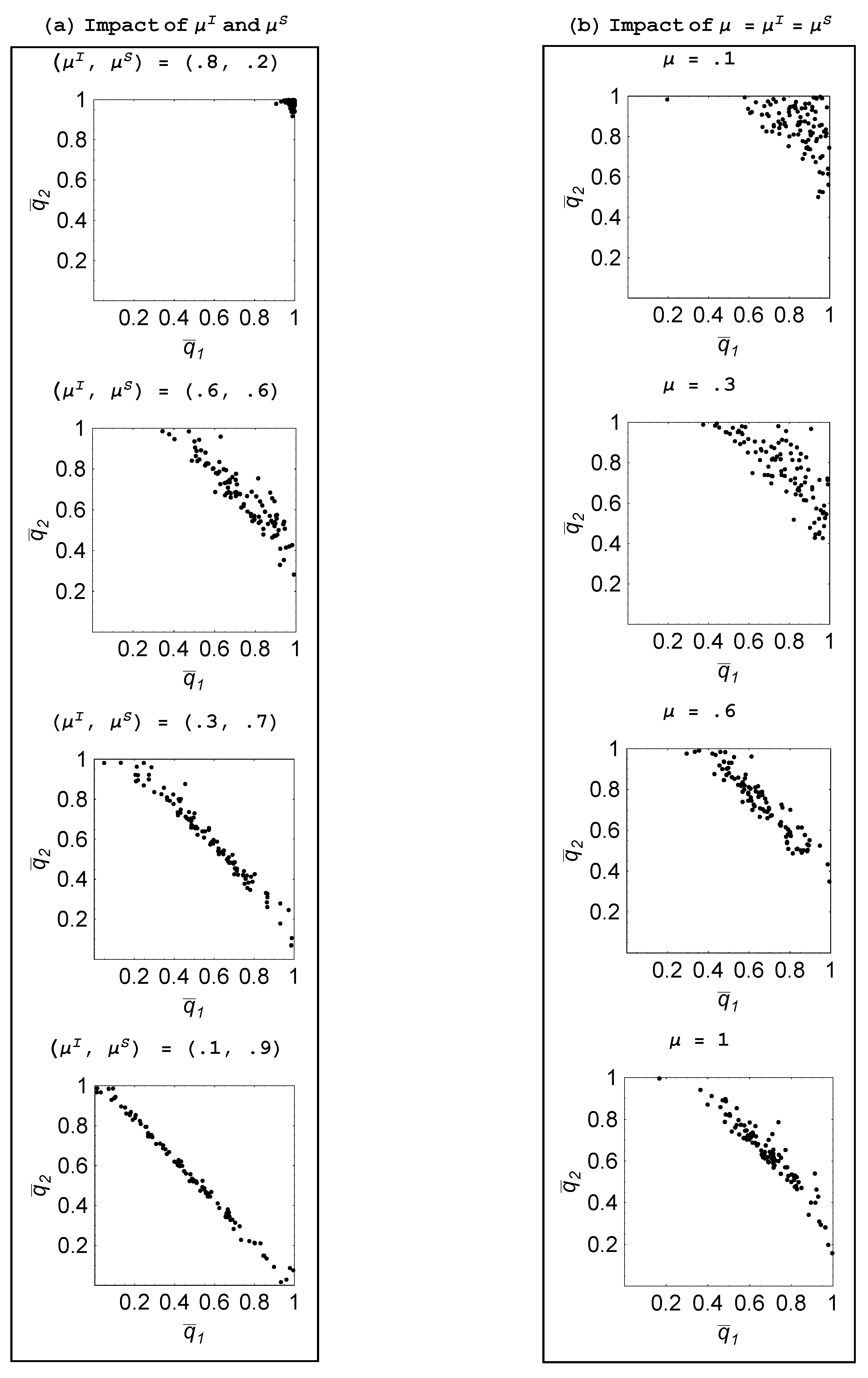
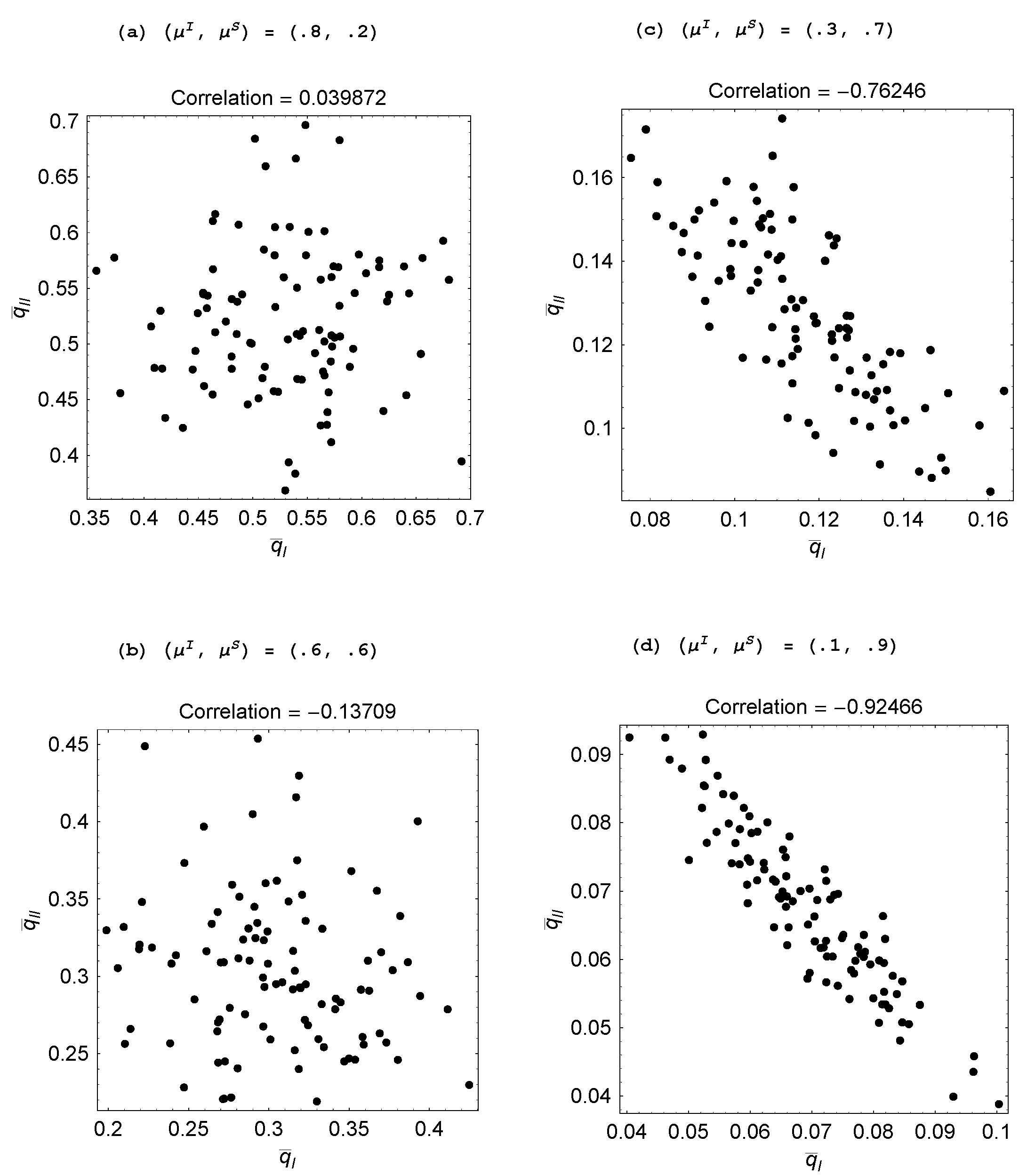
Figure 4(a) plots the 100 realizations of the steady-state probability pairs for
Starting with
— so that agents are quite effective at individual learning but inadequate at social learning—we find that there is little social learning as both agents focus on trying to come up with ideas on their own. As
is raised and
is reduced—so that agents become relatively more proficient at social learning—we naturally find that agents spend less time in the individual learning mode. This is reflected in the steady-state probabilities shifting in towards the origin. What is more interesting is that the structure of specialization begins to emerge, whereby one agent focuses on individual learning and the other focuses on social learning. This is also shown for a three-agent population in
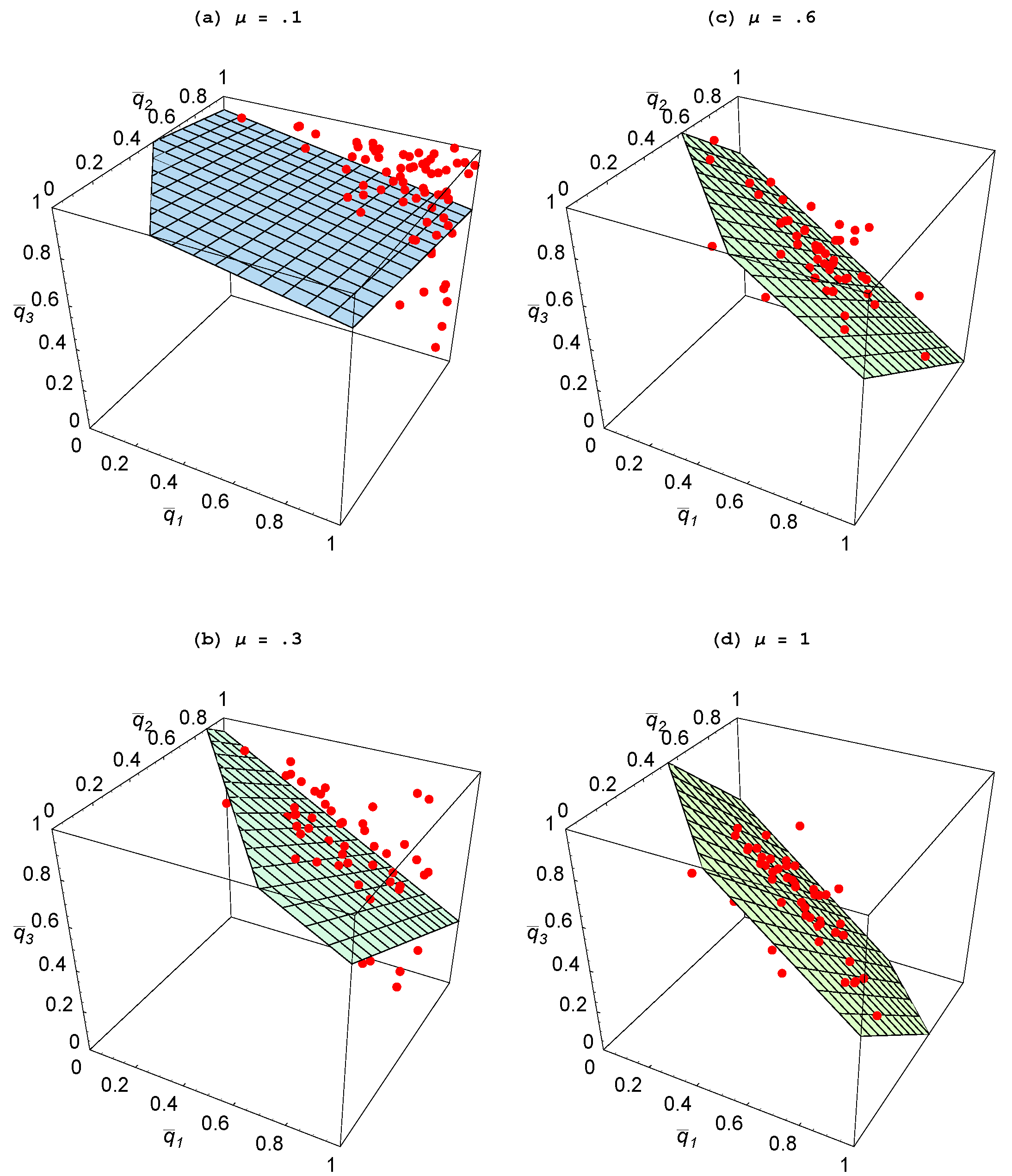
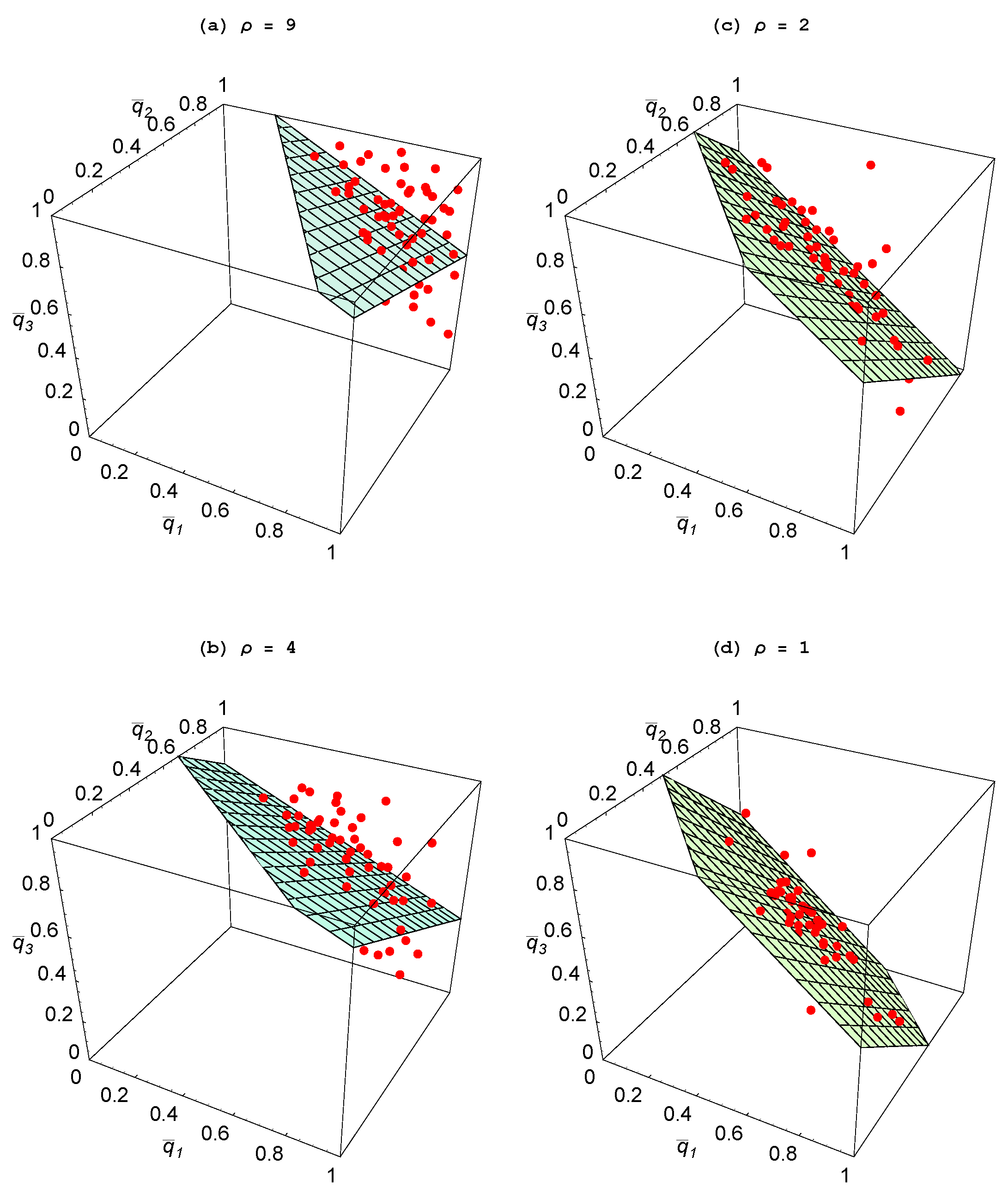
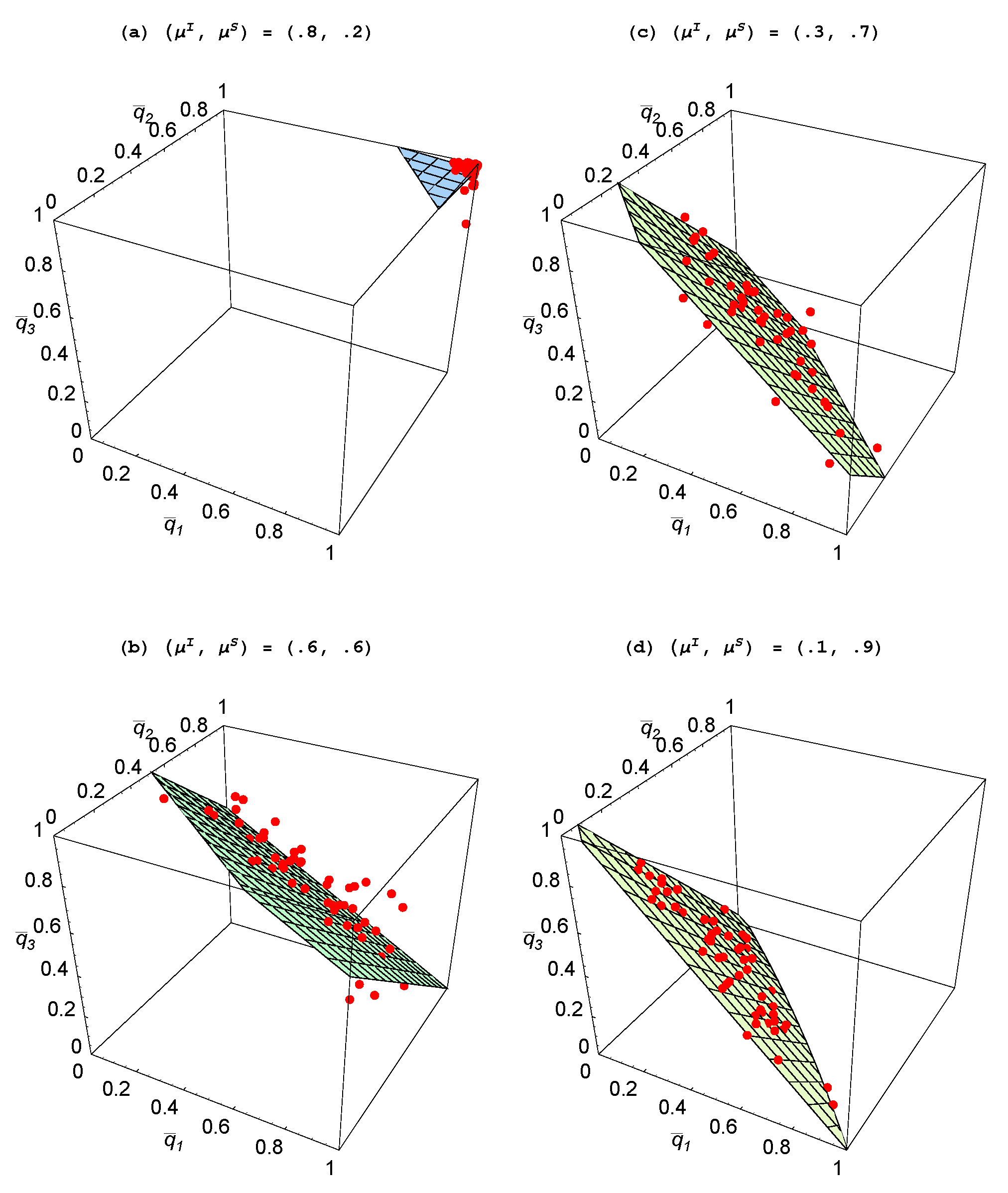
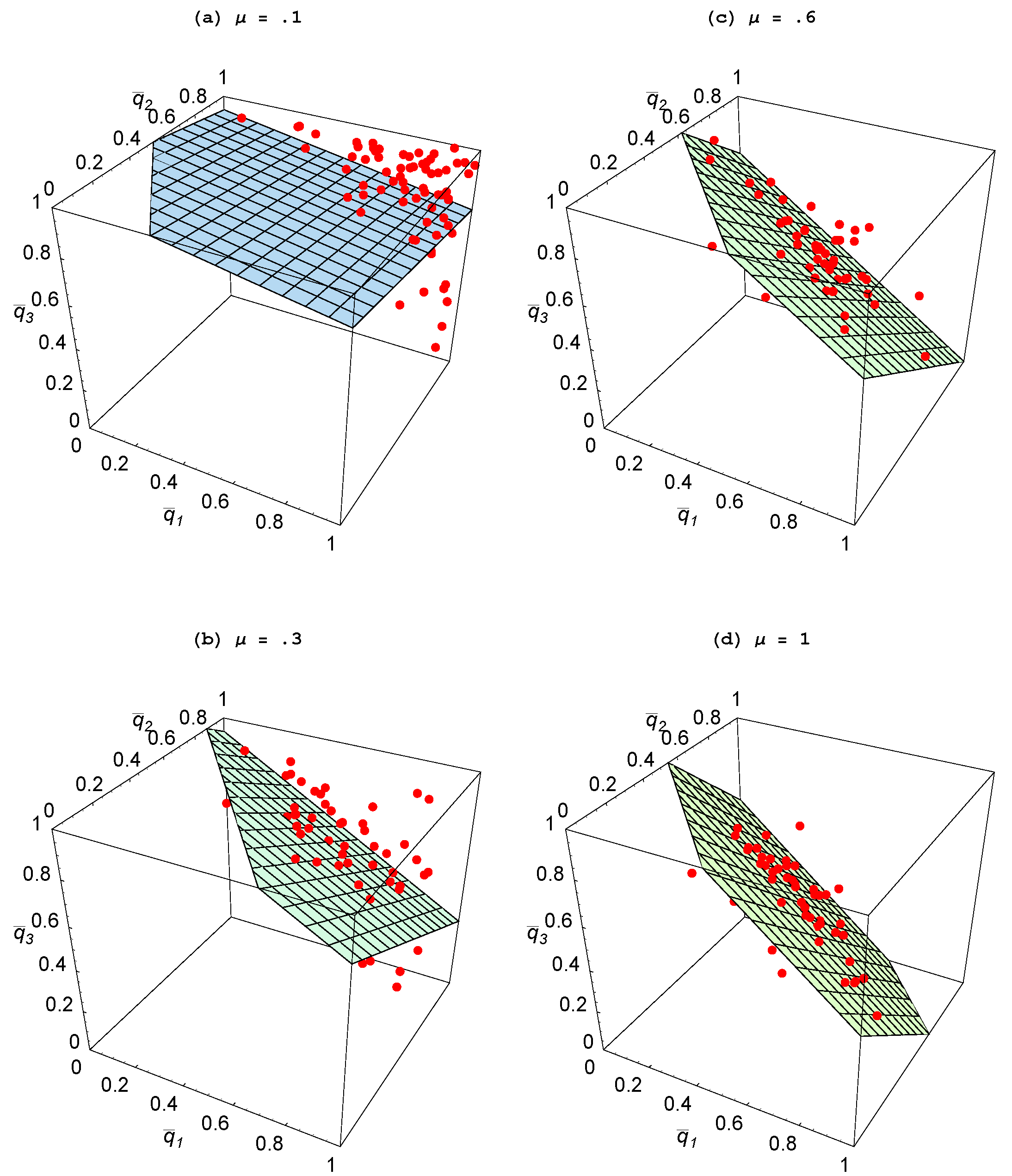
Figure 5 where we have plotted
To better visualize the relationship between these values, a two-dimensional plane has been fitted to these points using ordinary least squares. Analogous to that in
Figure 4(a), as the relative productivity of agents in social learning rises, the fitted plane shifts in and moves toward the unit simplex. Hence, once again, structure emerges in the form of specialization so that when one agent is heavily focusing on individual learning, the other agents are largely engaged in social learning.
When is relatively low and is relatively high, it is clear that it would not be best for all agents to largely engage in social learning as then there would be few new ideas arising and thus little to imitate. Though it could so happen that all agents choose to engage in some individual learning—such as with the replications that end up with —what also emerges in some replications is that one agent chooses to largely focus on individual learning. As then there are many new ideas streaming into the population, the other two agents focus on imitating and end up spreading the ideas of others. The result is a dramatic divergence in the choice of learning mechanisms, indicating a sharp division of cognitive labor.
Property 2 For populations with two or three agents, specialization is greater when agents are relatively more skilled in social learning than in individual learning.
Figure 4.
Impact of learning skills ( ).
Figure 4.
Impact of learning skills ( ).
Figure 5.
Impact of learning skills ( ).
Figure 5.
Impact of learning skills ( ).
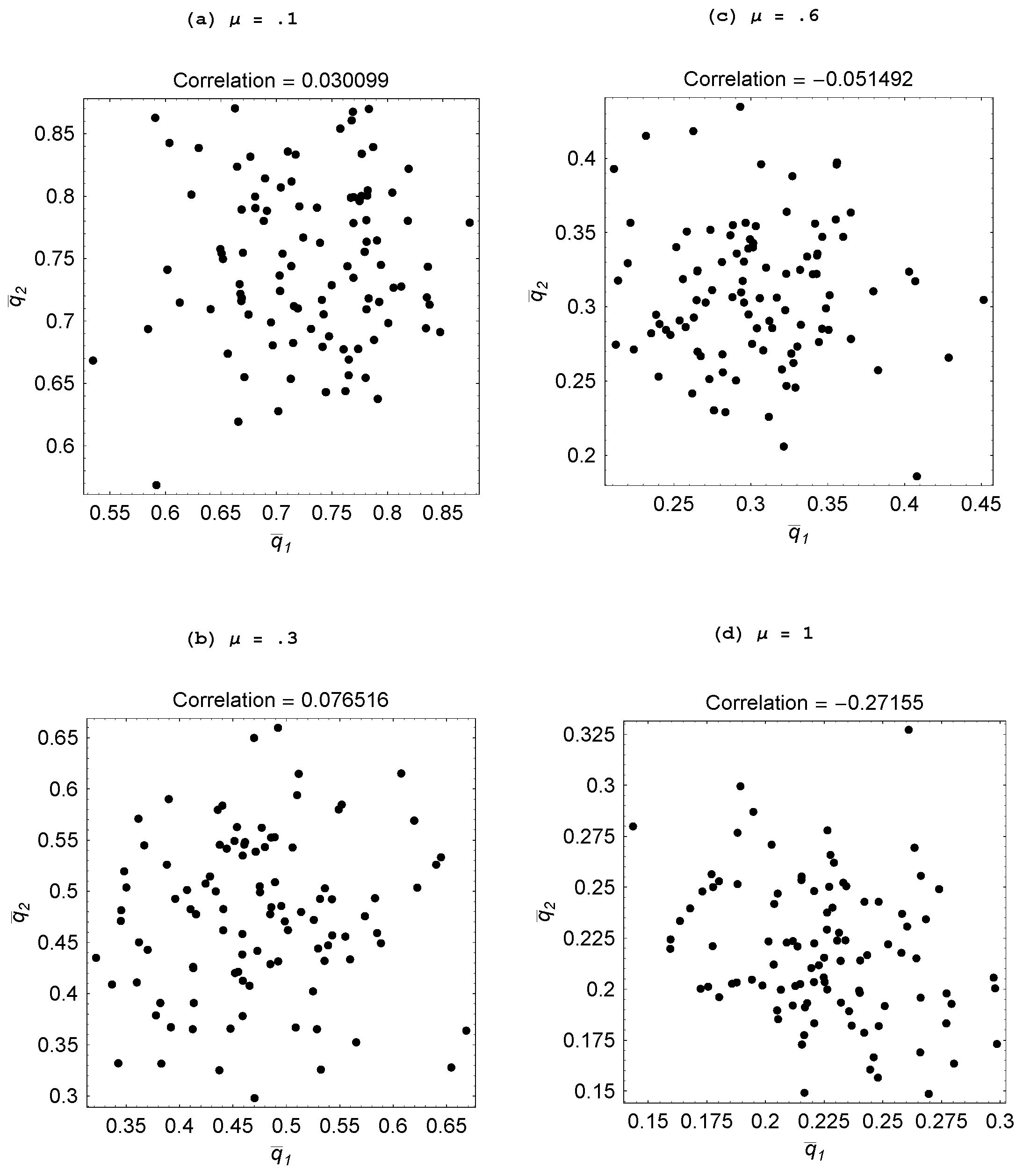
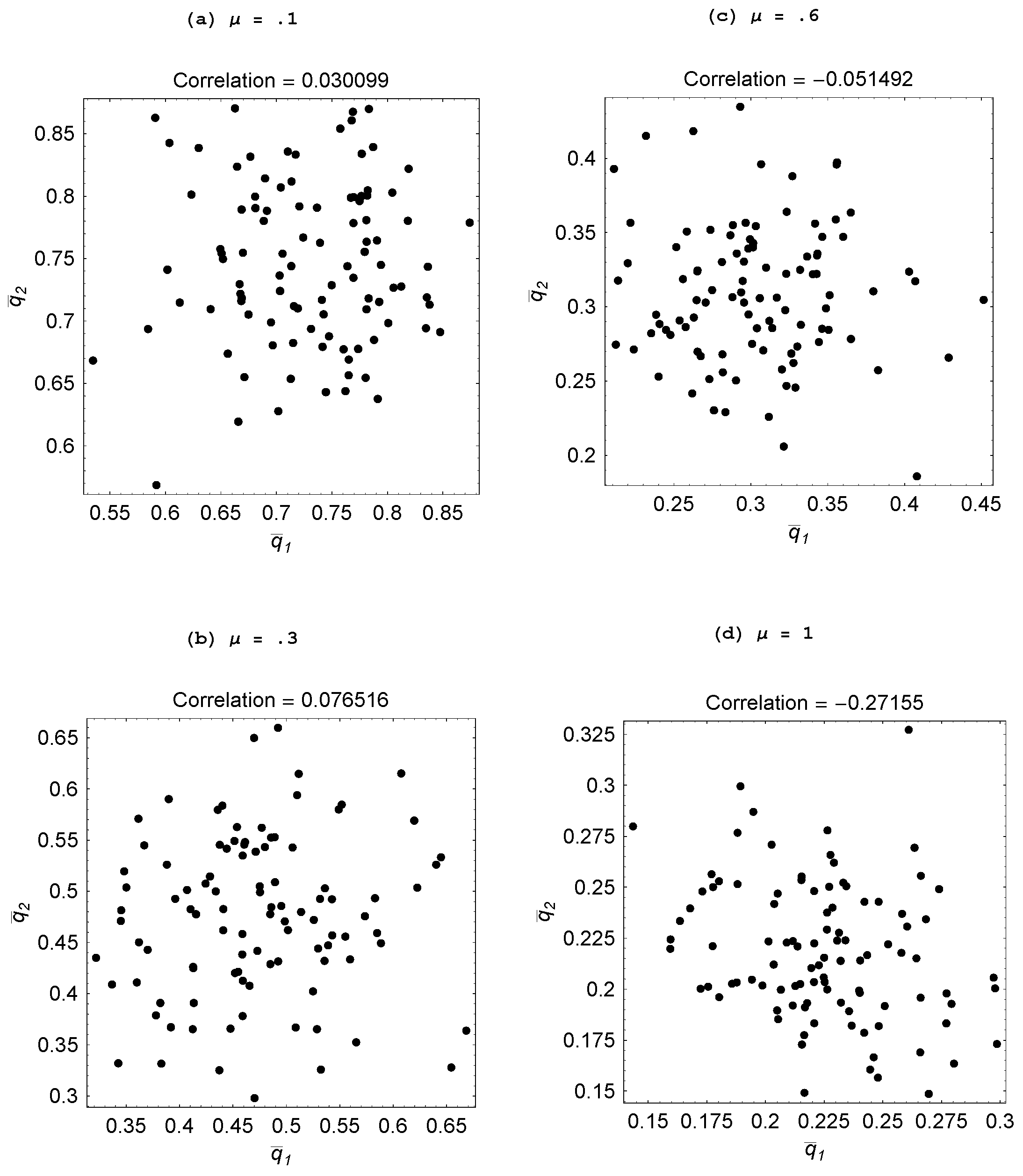
Figure 6.
Impact of μ ( ).
Figure 6.
Impact of μ ( ).
Figure 4(b) and
Figure 6 explore what happens when agents are equally skilled at these two tasks,
and we make them more skilled by raising
As
μ is progressively raised from 0.1 to 1, agents engage in less individual learning and more specialization emerges. When agents are relatively unskilled, ideas are scarce and furthermore when social learning finally succeeds in finding an idea, it is apt to be “old” and thus was adopted for an environment distinct from the current one. In contrast, ideas discovered through individual learning will not suffer from being “old.” As a result, agents largely engage in individual learning when unskilled. As they become more skilled, social learning proves more productive—both because other agents are producing more ideas and social learning discovers them faster—so we observe agents engaging in less individual learning. But what also happens is there is more specialization as, if one agent is heavily engaged in individual learning, then the other agents free-ride by focusing on social learning.
Property 3 For populations with two or three agents, specialization is greater when agents are more skilled in both individual and social learning.
From
Figure 4,
Figure 5 and
Figure 6, one can conclude that the key parameter is the productivity of agents with respect to social learning,
When it is low - regardless of whether
is low or high—agents largely engage in individual learning and little structure emerges. When
is at least moderately high, specialization can emerge whether or not agents are relatively effective in individual learning. If agents are effective at communicating with each other then the environment is ripe for heterogeneous roles to arise in spite of the homogeneity of agents’ skills.
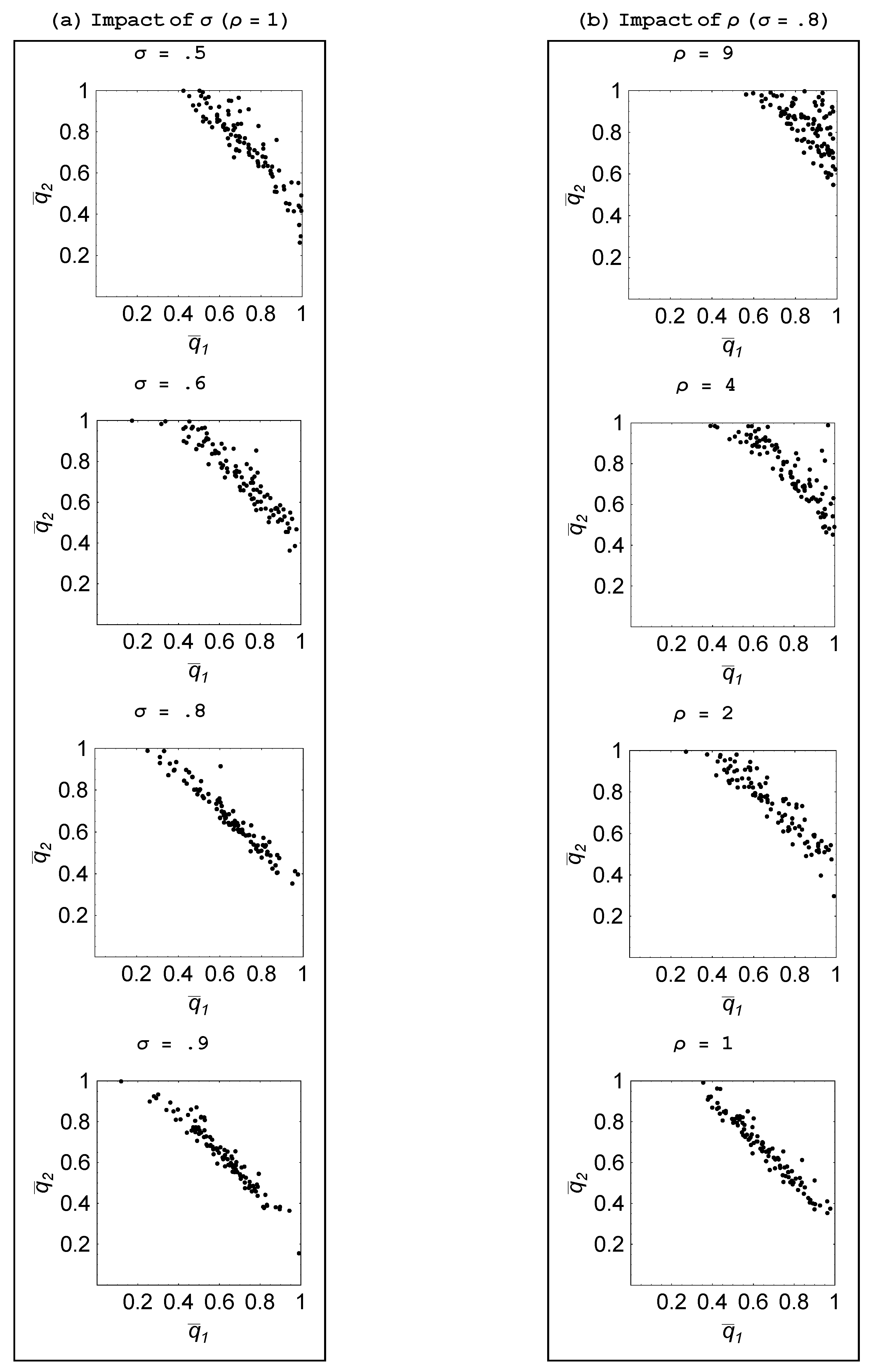
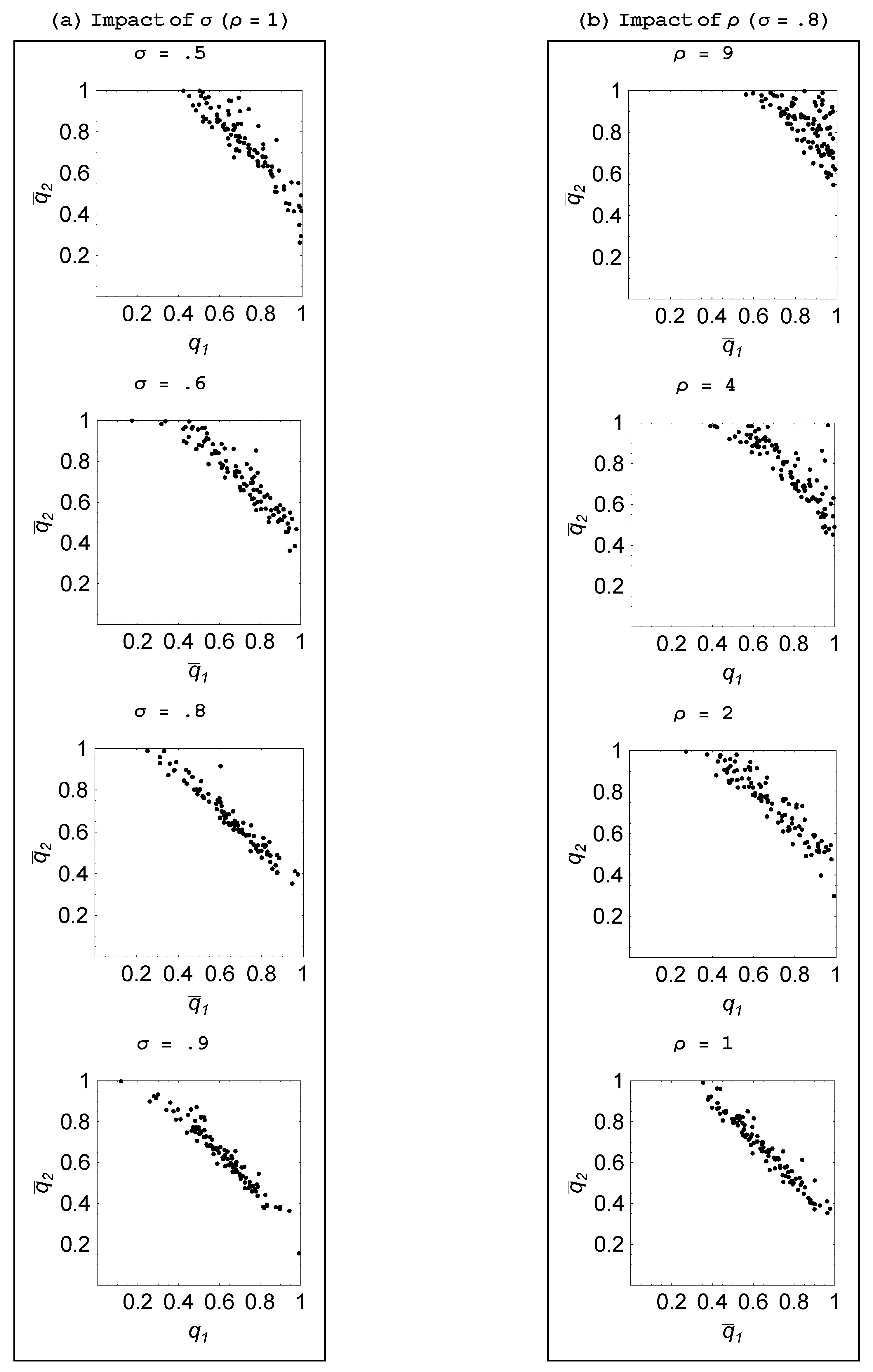
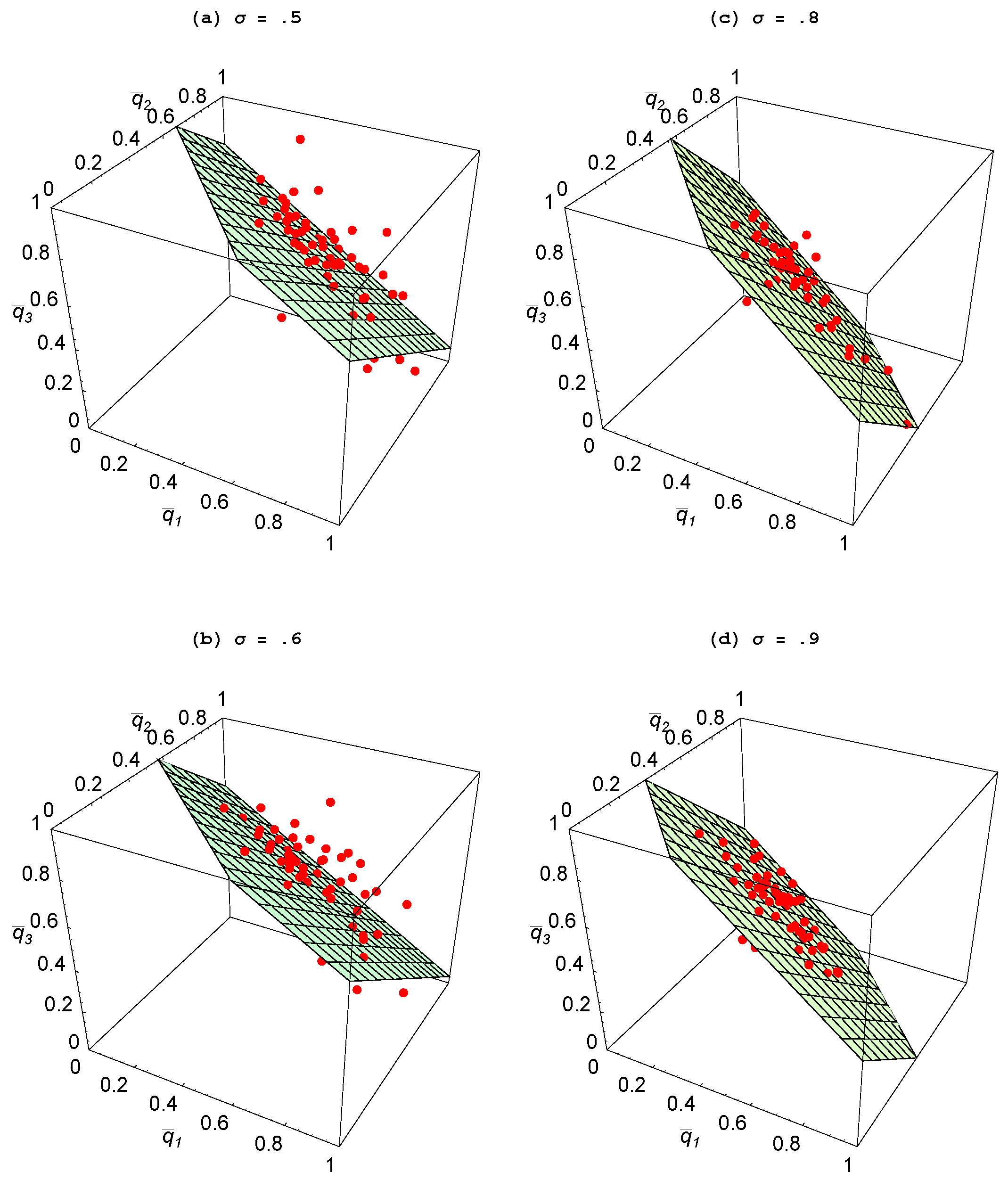
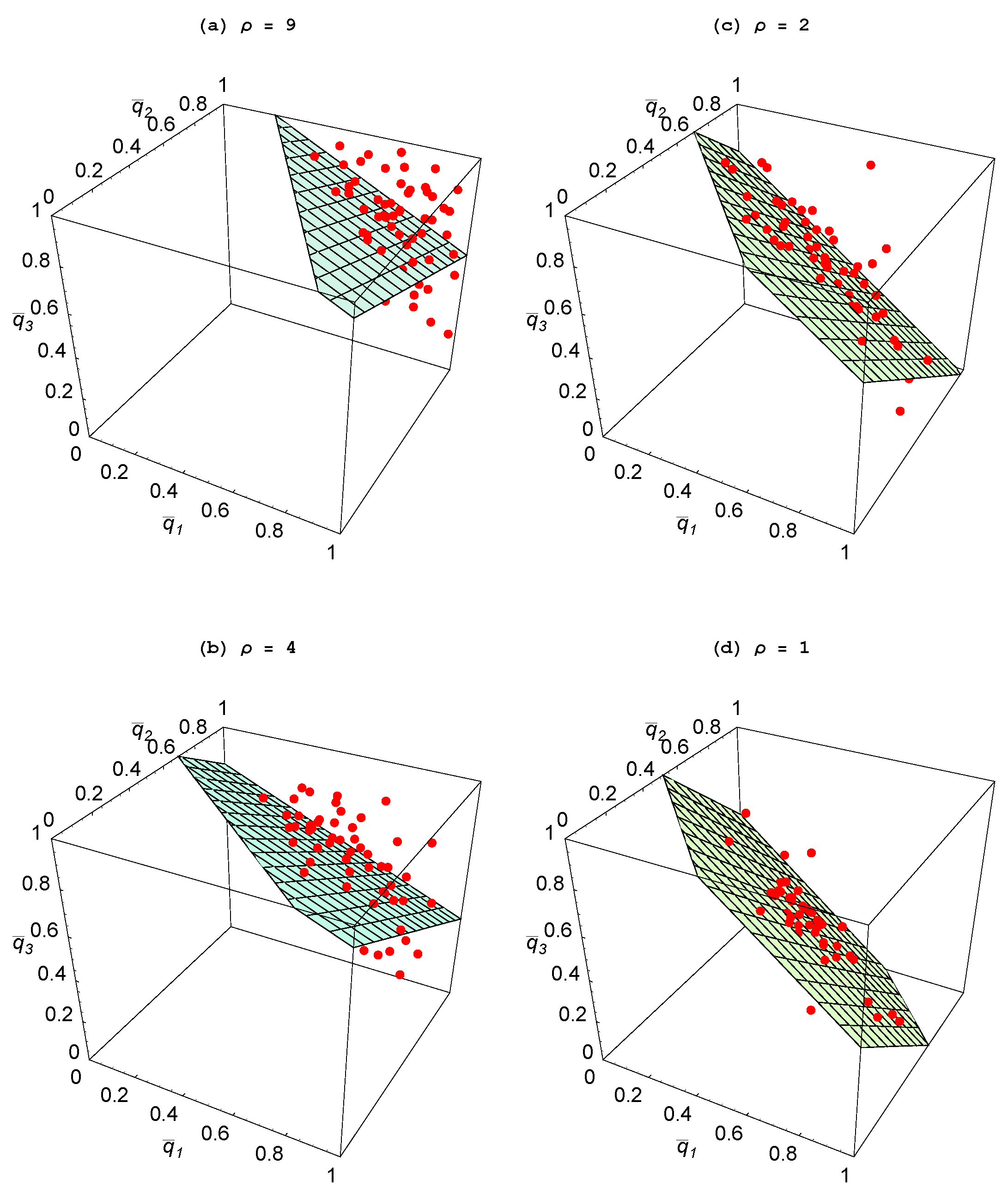
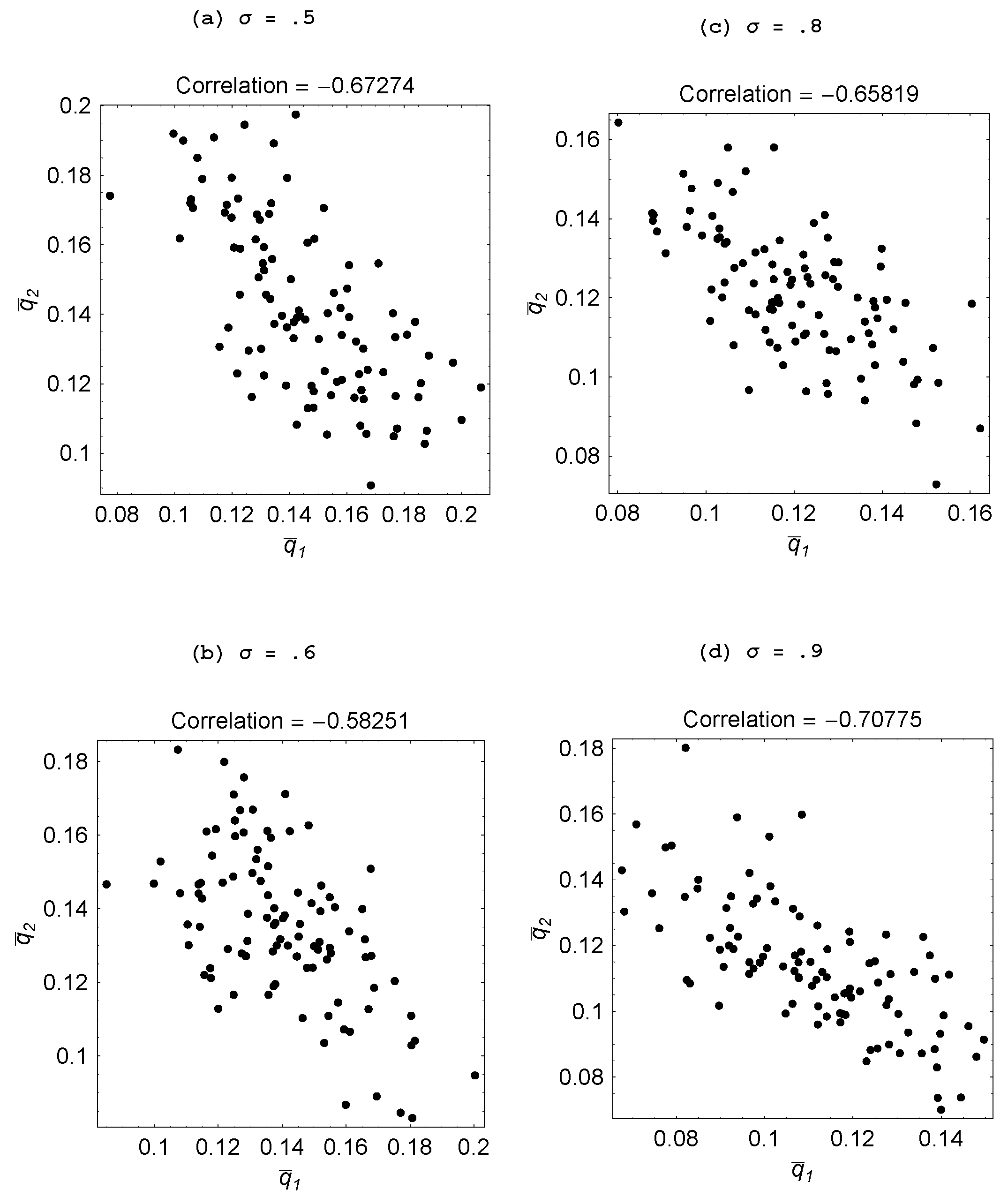
An interesting comparative static is to assess how the volatility of the environment affects the emergence of specialization. Recall that
σ is the probability with which the goal vector shifts in a given period, while
ρ represents the number of tasks in which change occurs.
Figure 7 shows how making the environment more stable—as reflected in a rise in
σ and a fall in
ρ—impacts outcomes for a two-agent population, while analogous results are reported in
Figure 8 and
Figure 9 for when there are three agents. These results lead us to the following statement:
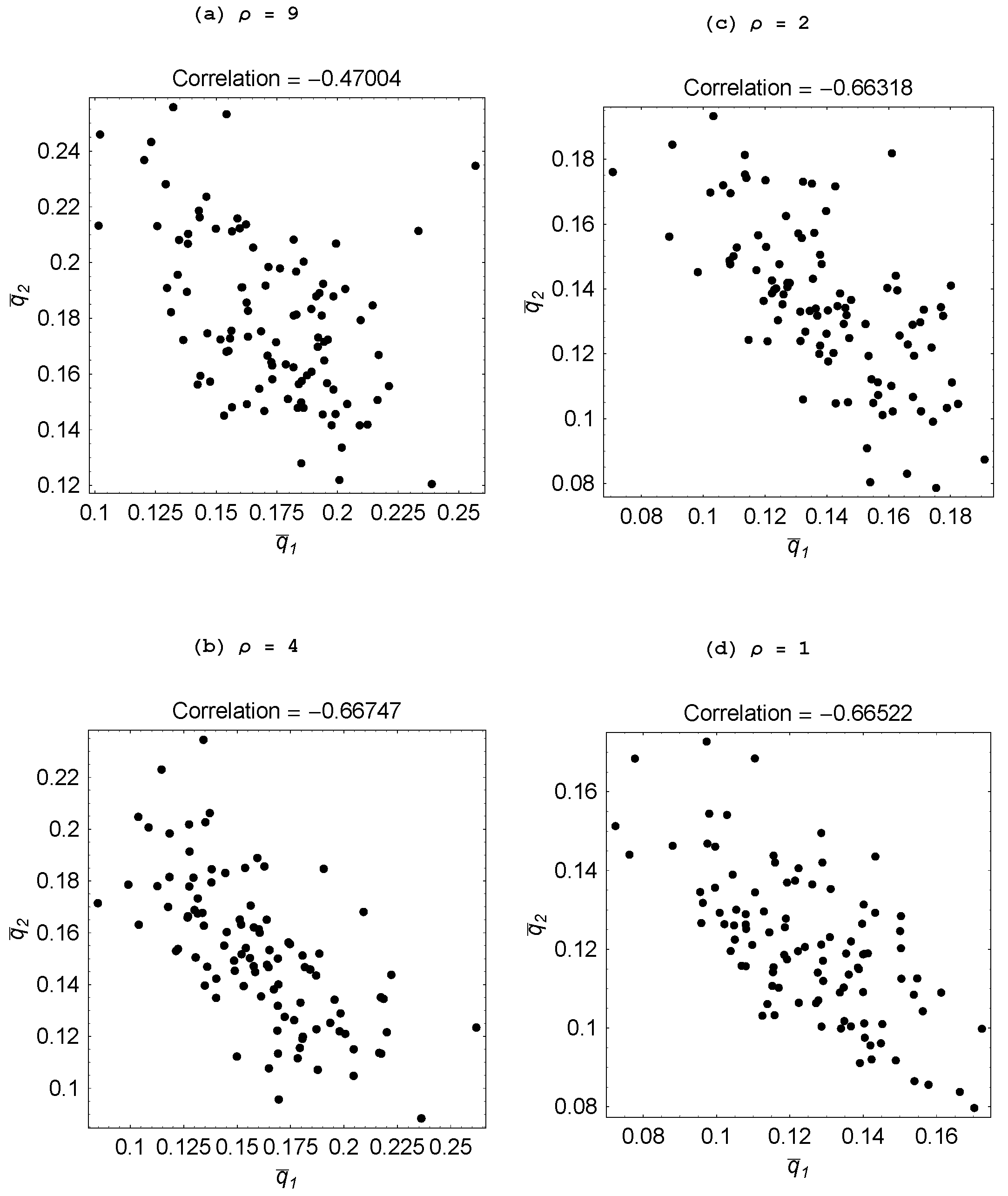
Property 4 For populations with two or three agents, specialization is greater when the environment is more stable.
A more volatile environment calls for a higher rate of adaptation by the agents. Recall that there is delay associated with the social learning process in that the process entails one agent discovering an idea that is useful for the current environment and then another agent learning that idea. By the time this social learning takes place, the environment could have changed which then makes this idea unattractive. Hence, social learning is relatively less productive when the environment is changing at a faster rate—as with a lower value for σ—or involves bigger changes—as with a higher value for ρ. It is then only when there is sufficient persistence in the environment, that social learning becomes effective enough that some agents choose to specialize in it and learn from an agent who focuses on individual learning.
To provide additional support for the above four properties, note that
represents the probability with which agent
i chooses individual learning along the steady-state. The likelihood of specialization being observed in a two-agent population is then represented by
, where
. This measures the likelihood that exactly one agent engages in individual learning, while the other engages in social learning along the steady-state. As there are 100 independent trials, we have 100 realizations of
for each parameter configuration.
Table 1 reports the mean and standard deviation of
s obtained in these replications. As expected, the likelihood of specialization monotonically increases in
and
σ, while it decreases in
ρ.
Figure 7.
Impact of environmental volatility ().
Figure 7.
Impact of environmental volatility ().
Figure 8.
Impact of σ ( ).
Figure 8.
Impact of σ ( ).
Figure 9.
Impact of ρ (; ).
Figure 9.
Impact of ρ (; ).
Table 1.
Mean and Standard Deviation of over 100 Replications.
Table 1.
Mean and Standard Deviation of over 100 Replications.
| | Parameters | |
|---|
| | σ | ρ | Mean | Std. Dev. |
|---|
| Impact of (
, ) | 0.8 | 0.2 | 0.8 | 1 | 0.0330197 | 0.0204064 |
| 0.6 | 0.6 | 0.8 | 1 | 0.465696 | 0.0630542 |
| 0.3 | 0.7 | 0.8 | 1 | 0.568567 | 0.103349 |
| 0.1 | 0.9 | 0.8 | 1 | 0.622361 | 0.137291 |
| Impact of
| 0.1 | 0.1 | 0.8 | 1 | 0.279422 | 0.107147 |
| 0.3 | 0.3 | 0.8 | 1 | 0.395829 | 0.0891995 |
| 0.6 | 0.6 | 0.8 | 1 | 0.470937 | 0.0568553 |
| 1 | 1 | 0.8 | 1 | 0.492638 | 0.0794427 |
| Impact of σ | 1 | 1 | 0.5 | 1 | 0.441256 | 0.0749621 |
| 1 | 1 | 0.6 | 1 | 0.462514 | 0.0723325 |
| 1 | 1 | 0.8 | 1 | 0.496672 | 0.0605297 |
| 1 | 1 | 0.9 | 1 | 0.517676 | 0.0722354 |
| Impact of ρ | 1 | 1 | 0.8 | 1 | 0.497152 | 0.0528074 |
| 1 | 1 | 0.8 | 1 | 0.458065 | 0.0636729 |
| 1 | 1 | 0.8 | 1 | 0.393731 | 0.0770097 |
| 1 | 1 | 0.8 | 1 | 0.283333 | 0.0781933 |
4.2. Social Sub-Optimality of Endogenous Specialization
The previous results characterize agent behavior when they are acting independently and responding to their own individual performance. How does the resulting allocation between individual learning and social learning compare with what would maximize aggregate steady-state performance of the population? Due to computational constraints, this question we addressed only for the case of a two agent population. 100 trials were performed and, for each trial, we carried out the learning process with two agents for each of the 121 probability pairs,
, where
,
. [To perform an analogous exercise for when there are three agents would require doing this for 1,331 triples of
.] The pair,
, was constrained to remain fixed for the entire horizon of
periods. For each
pair, the mean steady-state performance for the population,
, was computed as specified in Equation (
14). Comparing among those
s, the
socially optimal probability pair,
, was identified for a given trial: Since the population size is fixed at
L, the aggregate steady-state performance of the population is simply
and the derivation of
can be based on the comparisons among
s. Given that there are 100 trials in total, we then have 100 realizations of the socially optimal probability pair.
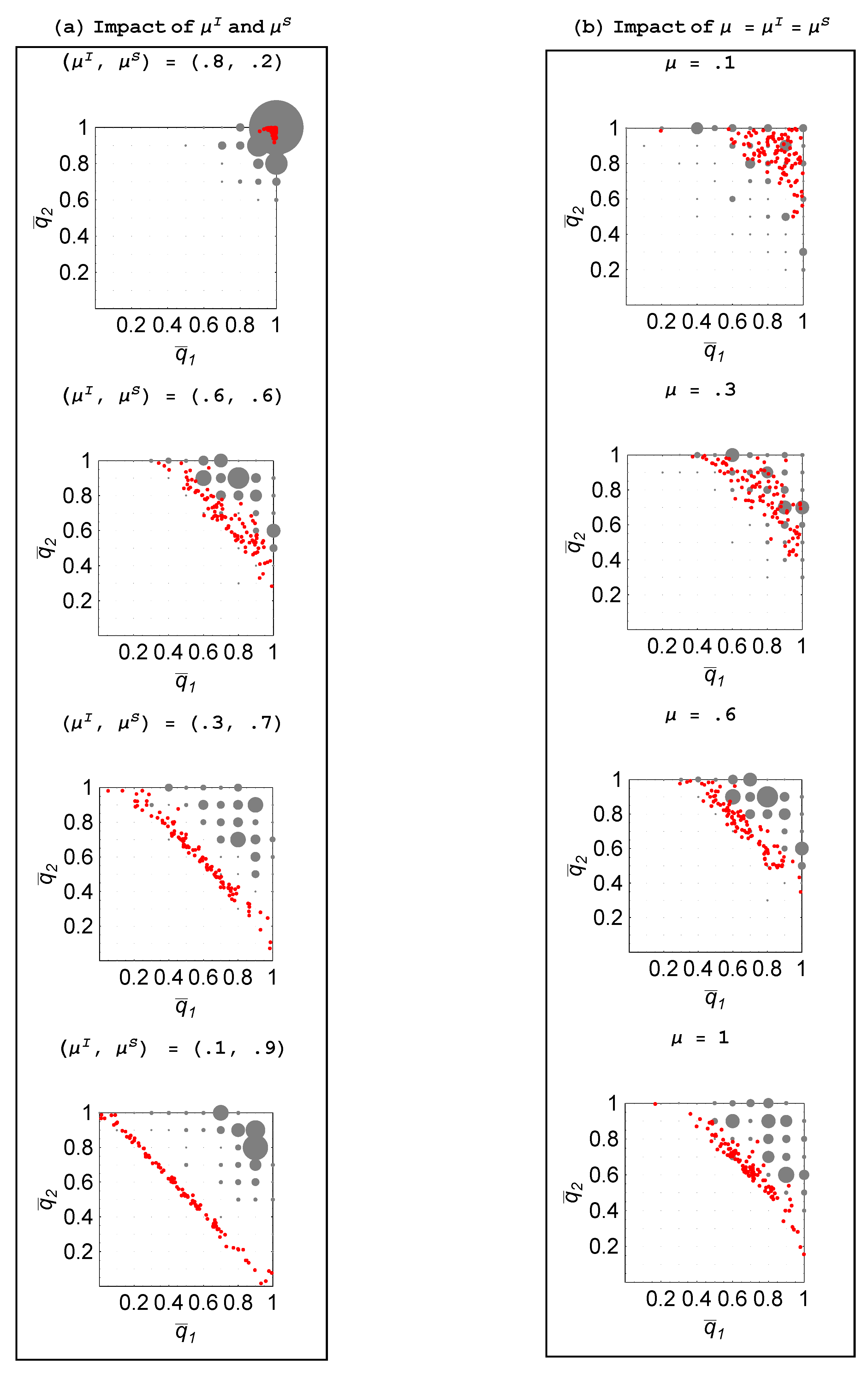
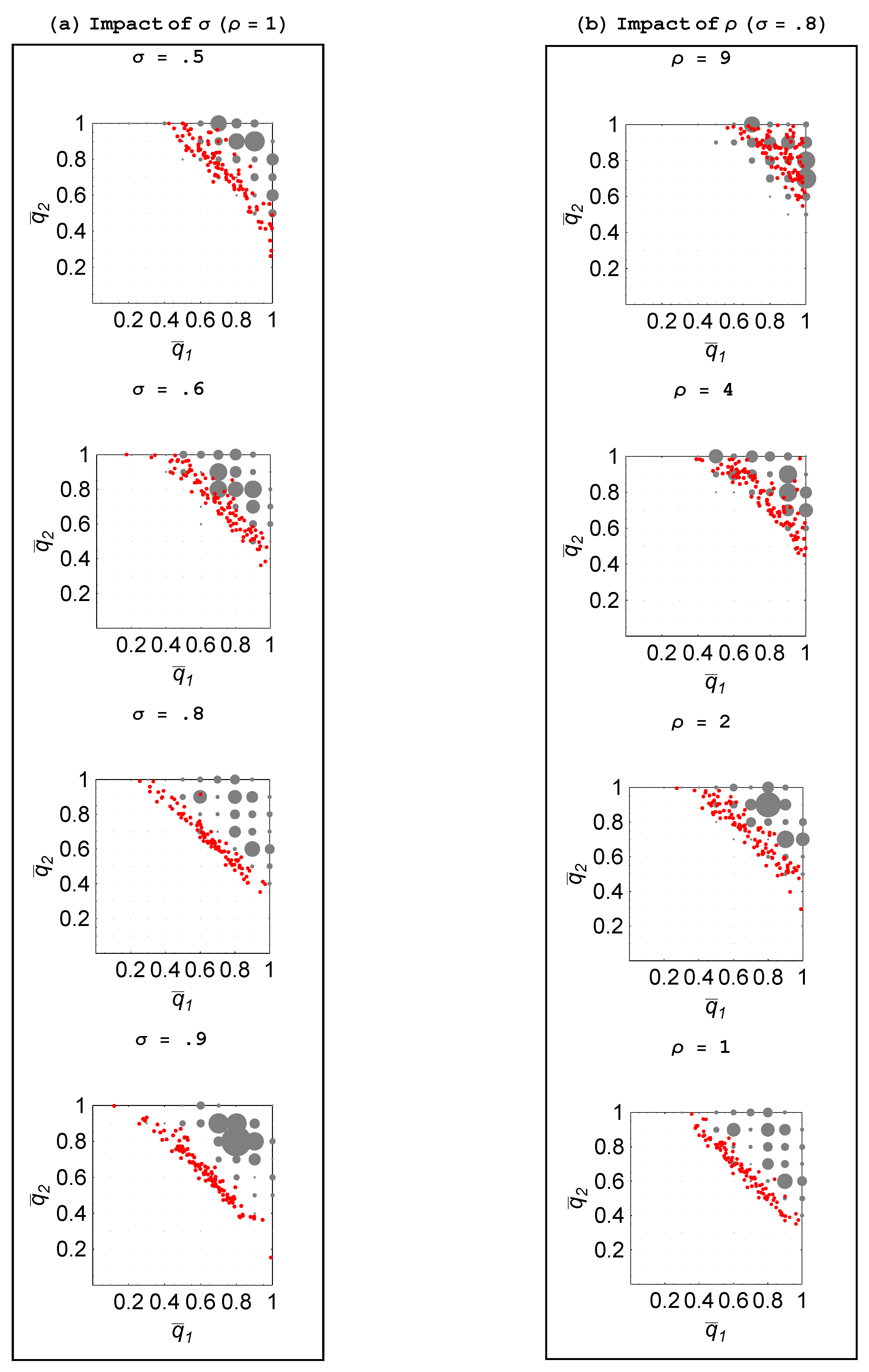
Figure 10 and
Figure 11 plot these social optima for different parameter configurations (in exactly the same format as the previous figures). The coordinates of the center of a grey disc represents the occurrence of that probability pair as the social optimum, while the frequency (among the 100 trials) with which it was a social optimum is represented by the size of the disc: The larger the disc, the greater is the frequency. The endogenous probability pairs from
Figure 4 and
Figure 7 have been superimposed to allow for an easier comparison. As before,
Figure 10 considers the impacts of
and
μ, while
Figure 11 examines the impacts of
σ and
ρ.
Figure 10.
vs. given and .
Figure 10.
vs. given and .
Figure 11.
vs. given .
Figure 11.
vs. given .
The central property we observe is that the social optimum, generally, entails more individual learning by both agents than that which emerges under autonomous choice rules. Left to engaging in reinforcement learning on their own, agents tend to imitate too much and innovate too little.
Property 5 For a two-agent population, agents engage in excessive social learning. The deviation from the socially optimal level of social learning tends to: (1) increase in relative to ; (2) increase in μ; (3) increase in σ; and (4) decrease in ρ.
Note that the deviation from the social optimum tends to be more severe in those cases where there exists a greater divergence in the steady-state probabilities. This implies that the circumstances more favorable to social learning and, hence, free-riding are also the ones which cause deviations from the social optimum to a greater extent.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}