
Projected Climate Change Effects on Global Vegetation Growth: A Machine Learning Approach




Abstract
:1. Introduction
2. Materials and Methods
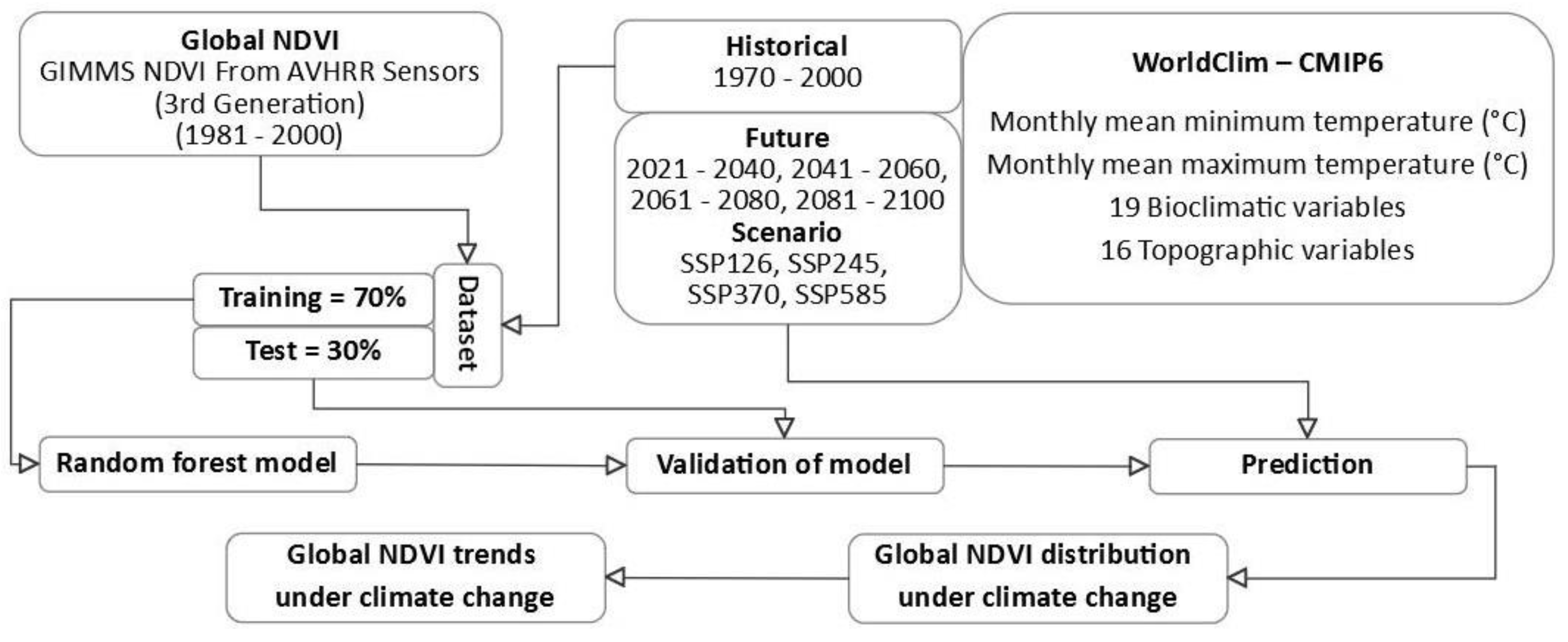
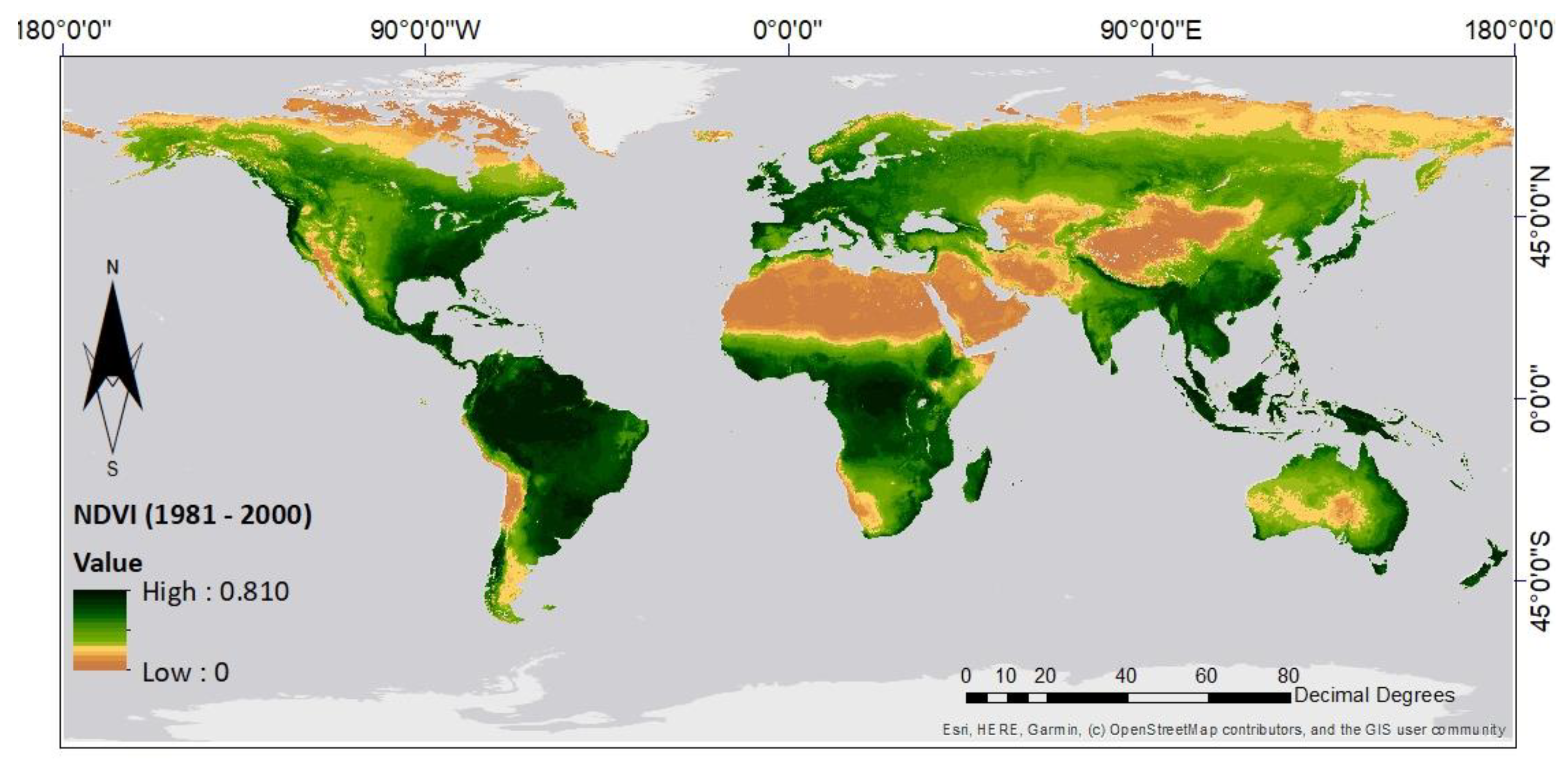
2.1. Data Collection
2.2. Methodology
3. Results and Discussion
3.1. Random Forest Model
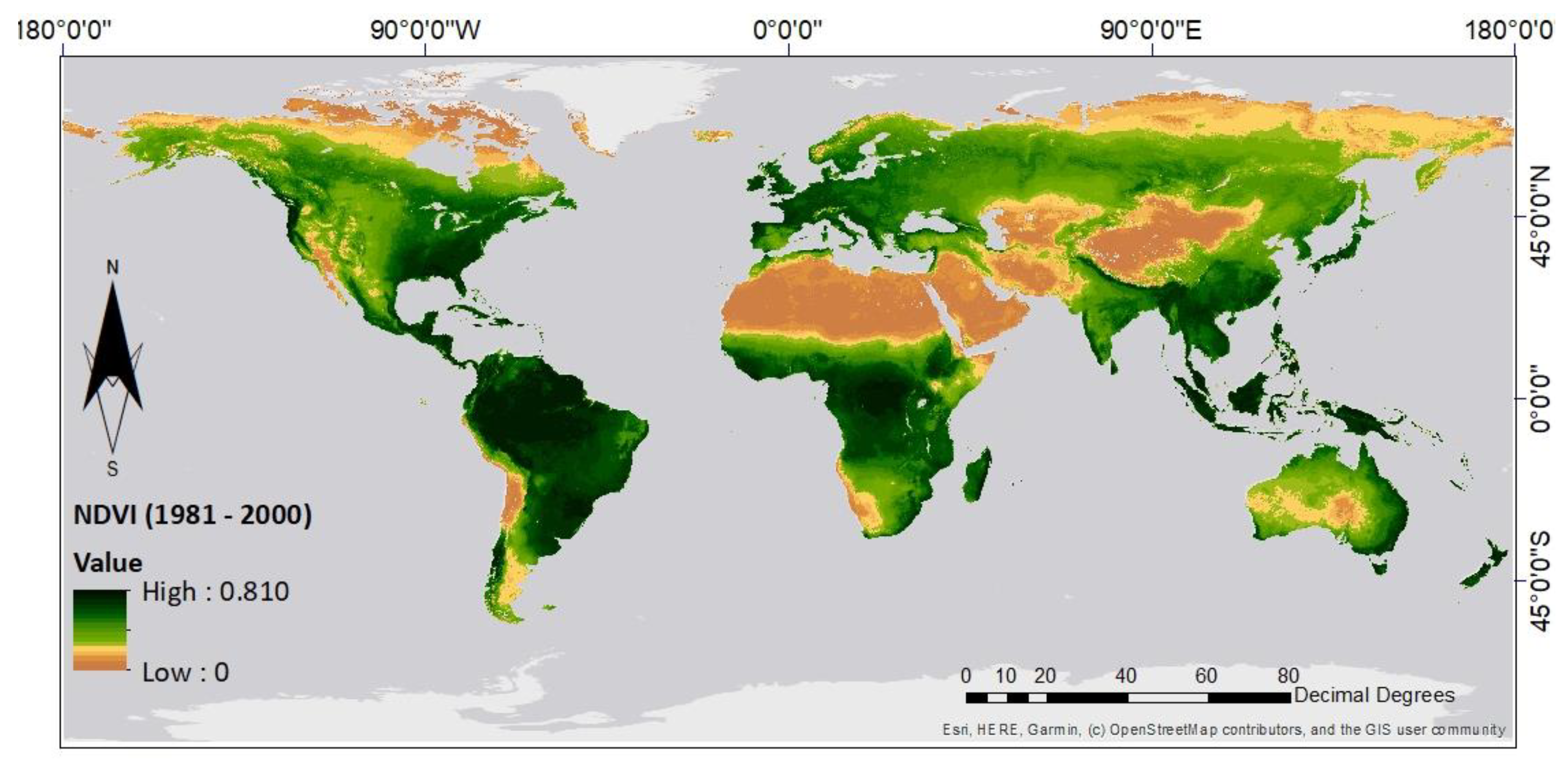
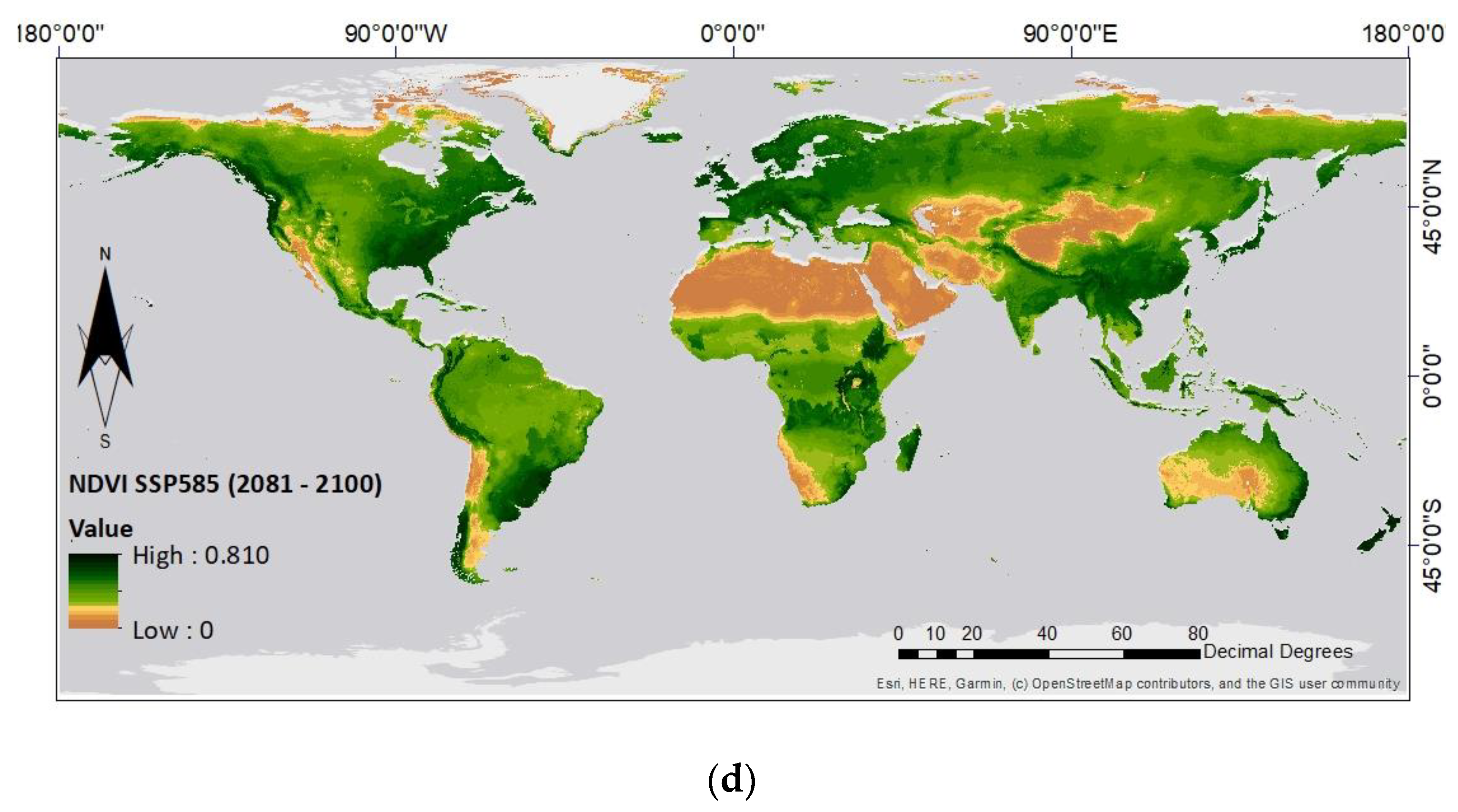
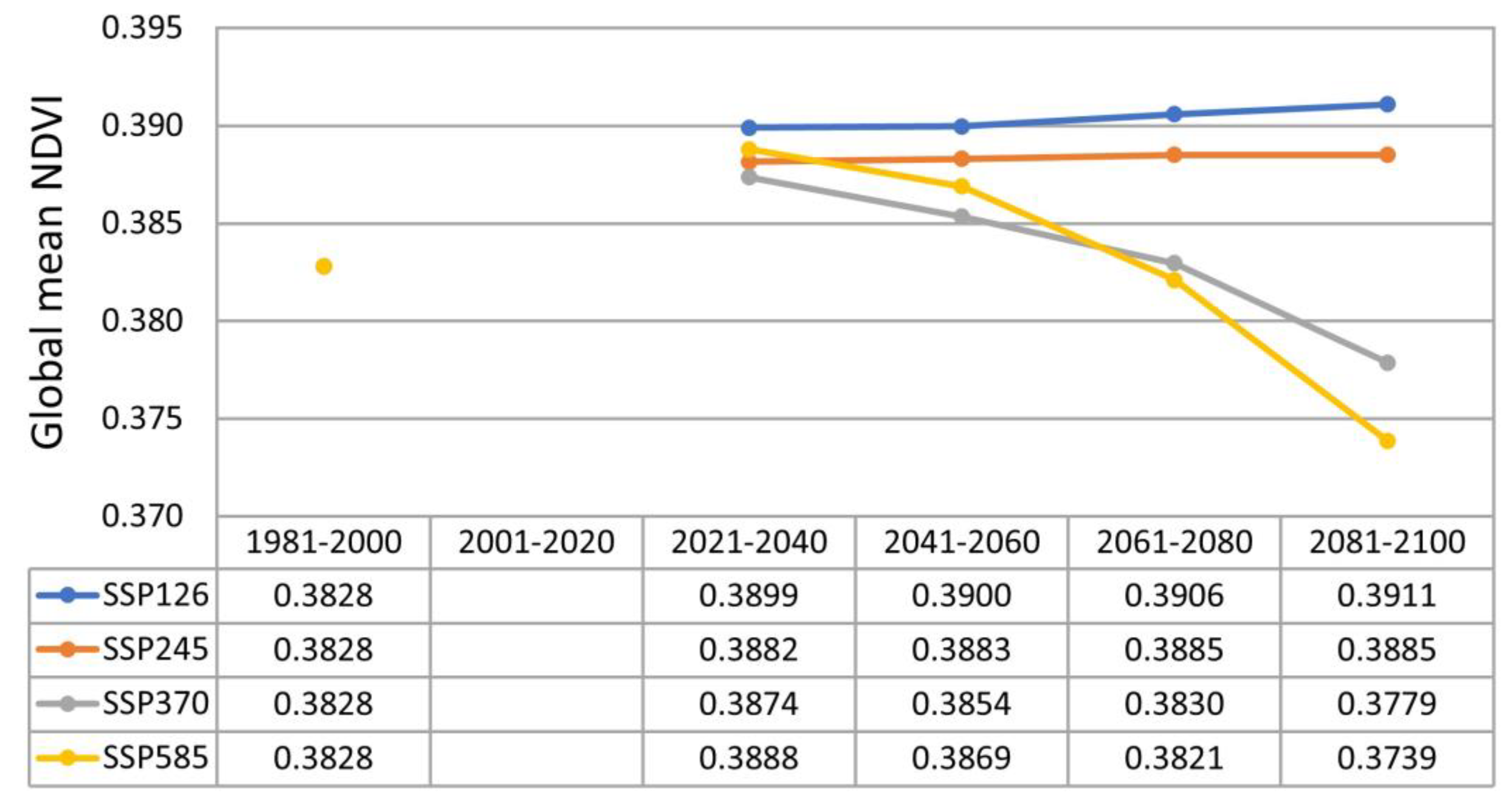
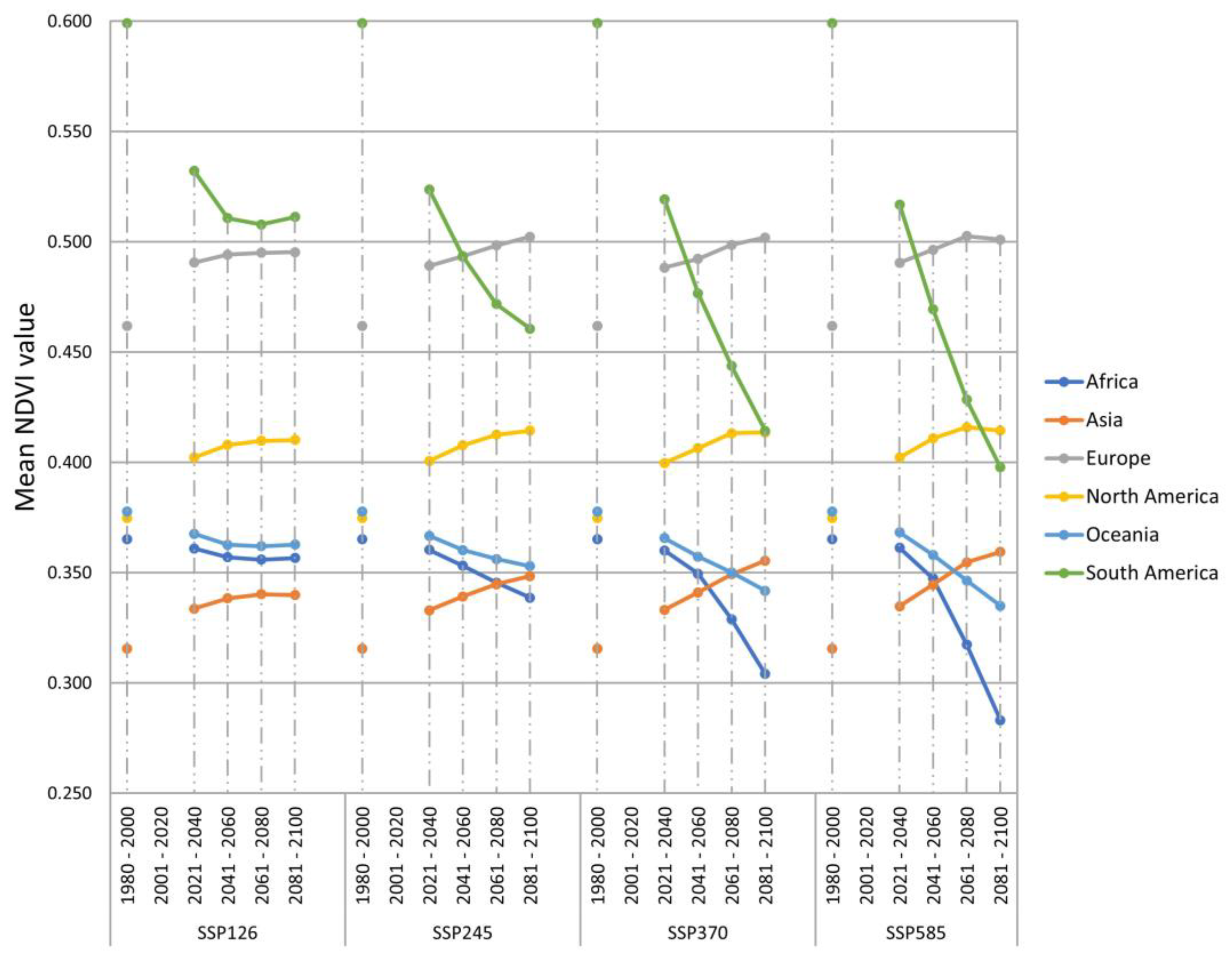
3.2. Prediction of the NDVI Value under Climate Change
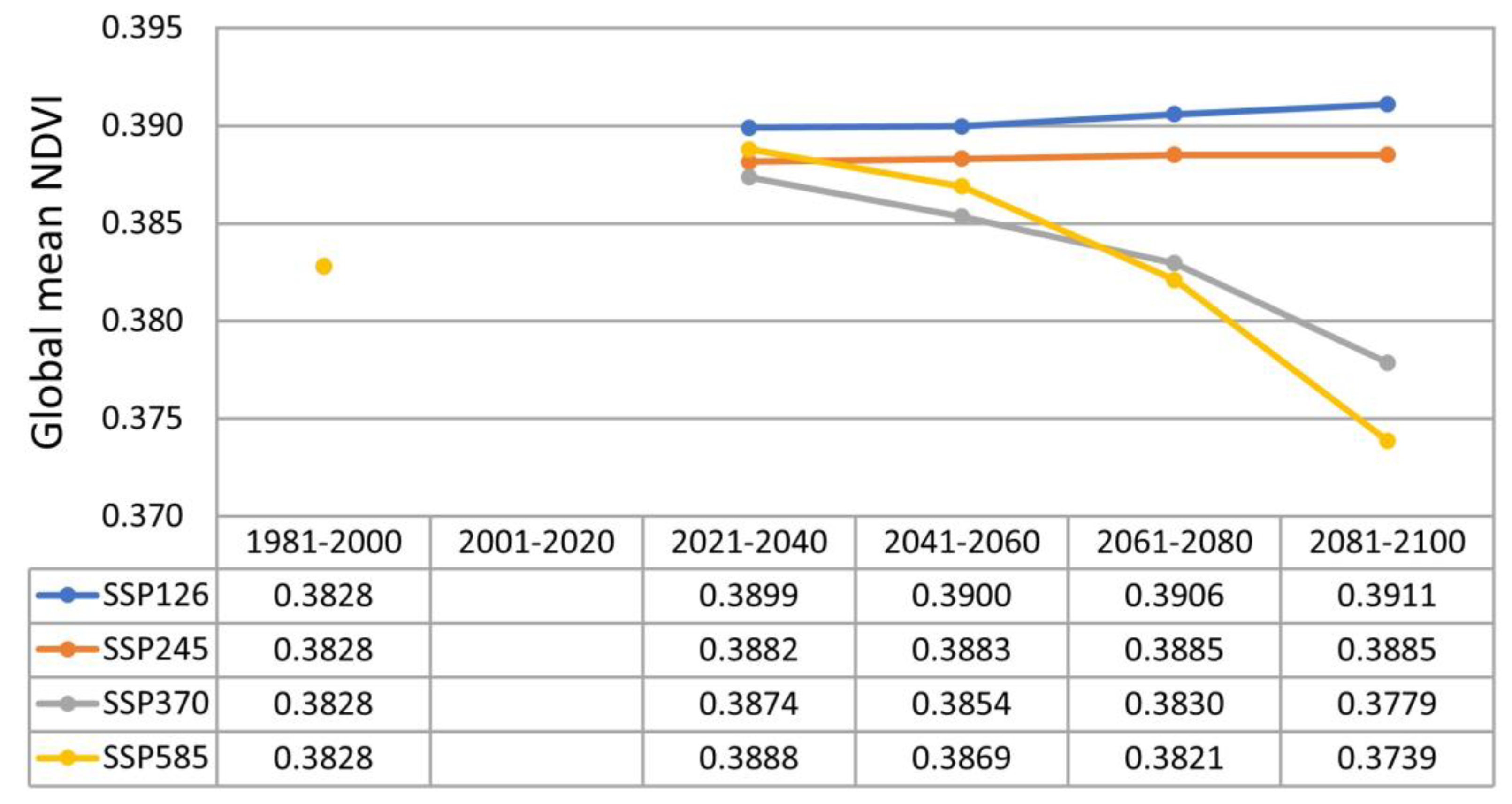
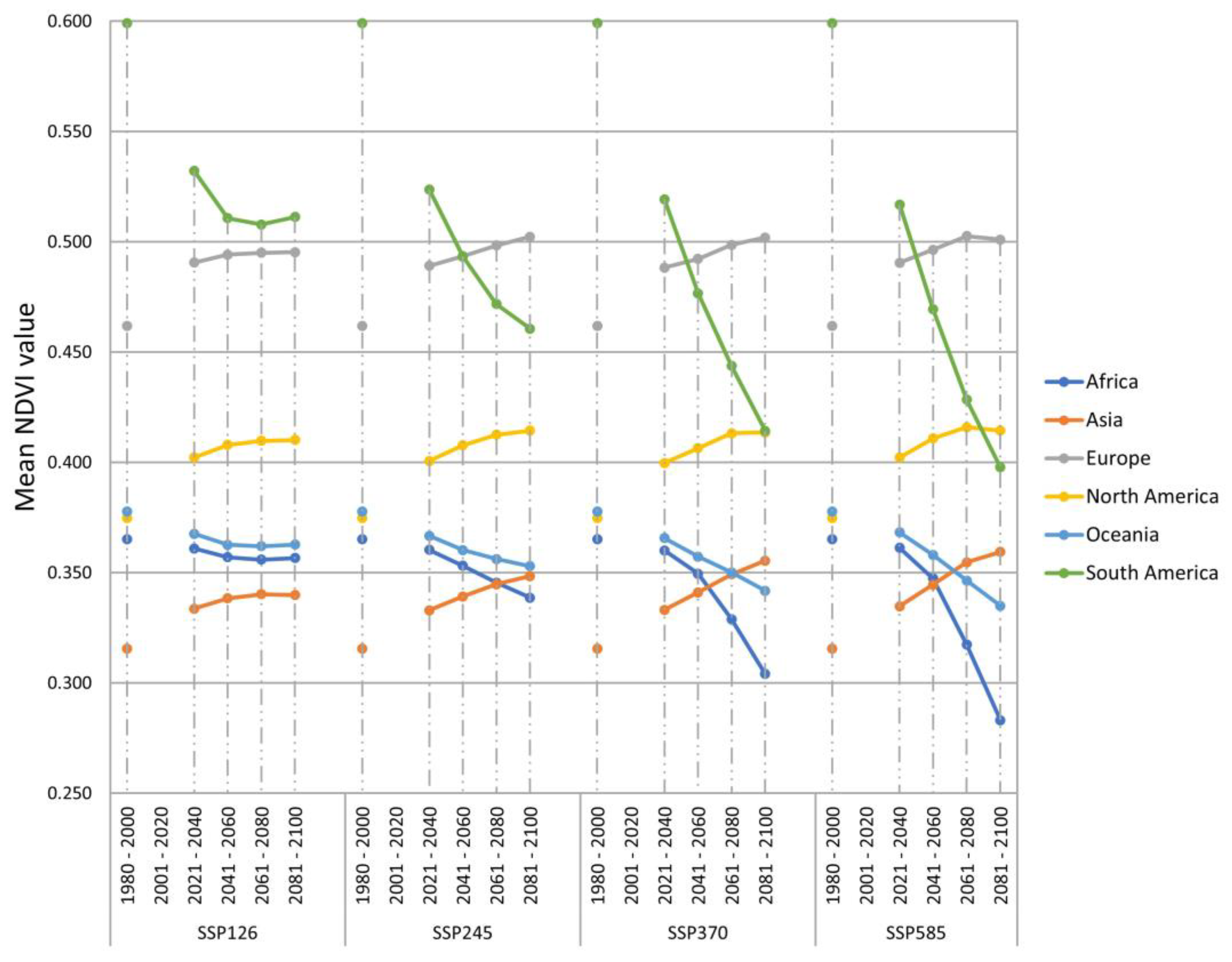
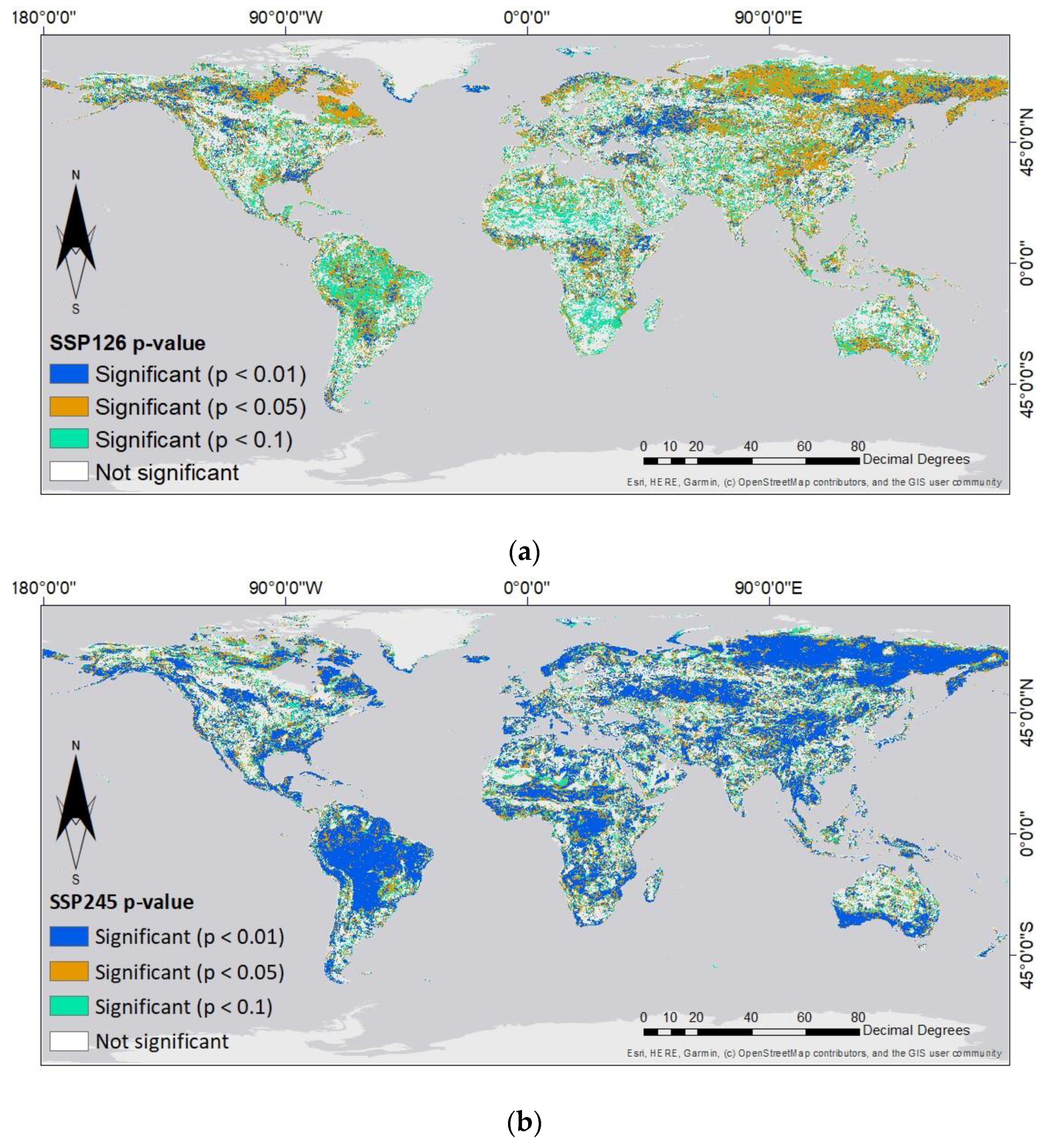
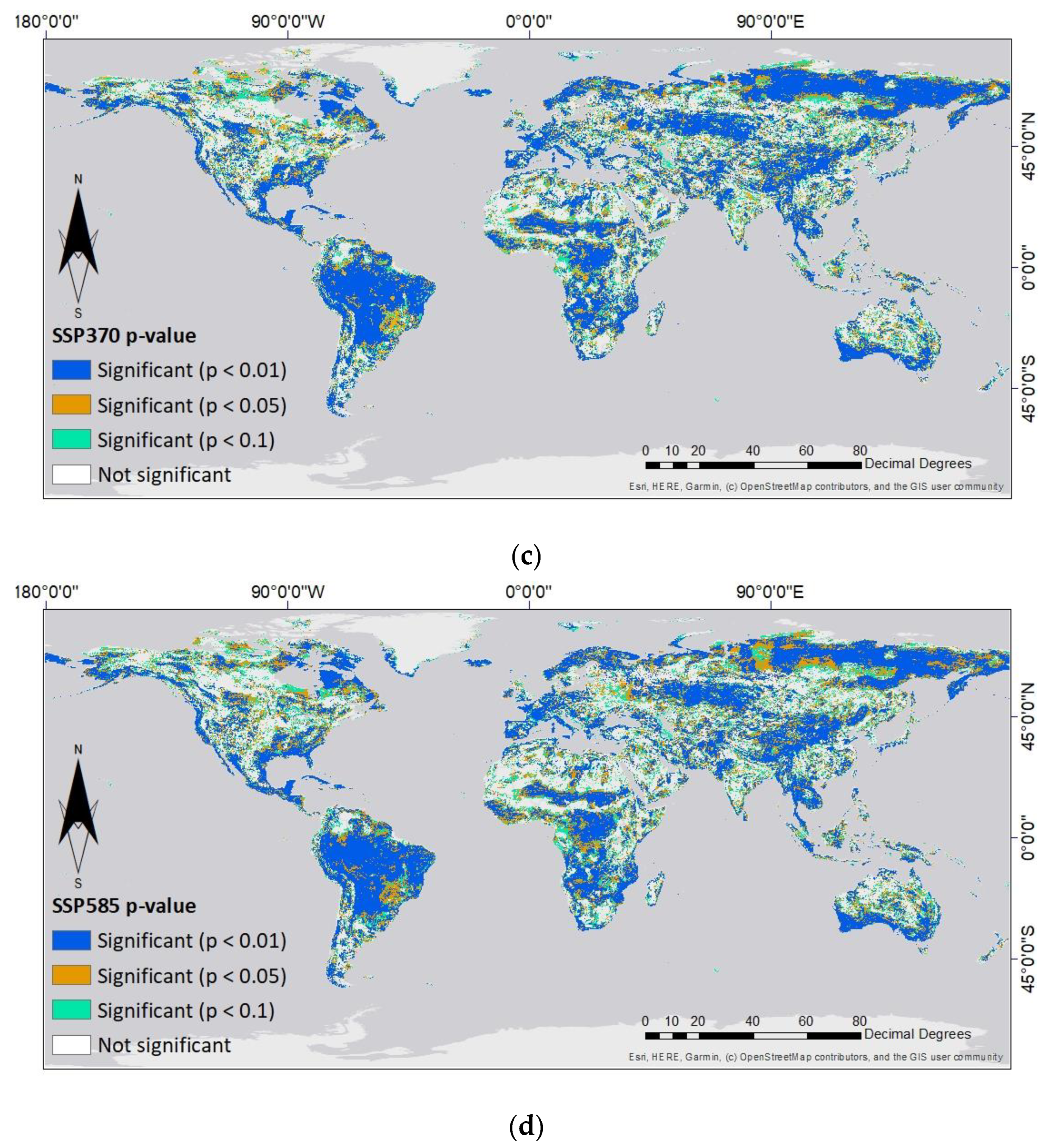
3.3. Statistical Analysis of Simulated Changes in NDVI Values
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wyser, K.; van Noije, T.; Yang, S.; von Hardenberg, J.; O’Donnell, D.; Döscher, R. On the increased climate sensitivity in the EC-Earth model from CMIP5 to CMIP6. Geosci. Model Dev. 2019, 13, 3465–3474. [Google Scholar] [CrossRef]
- Onyutha, C.; Asiimwe, A.; Ayugi, B.; Ngoma, H.; Ongoma, V.; Tabari, H. Observed and future precipitation and evapotranspiration in water management zones of Uganda: CMIP6 projections. Atmosphere 2021, 12, 887. [Google Scholar] [CrossRef]
- Raji, P.; Shiny, R.; Byju, G. Impact of climate change on the potential geographical suitability of cassava and sweet potato vs. rice and potato in India. Theor. Appl. Climatol. 2021, 146, 941–960. [Google Scholar] [CrossRef]
- Shah, S.; Adhikari, A.; Tiwari, A.; Talchabhadel, R. Seasonal Drought Index Predictability for Historical and Future periods Using Worldclim over the Southern Plain of Himalayan Tarai. In Proceedings of the AGU Fall Meeting Abstracts, New Orleans, LA, USA, 13–17 December 2021; Volume 2021, p. H45M-1328. [Google Scholar]
- Alsafadi, K.; Bi, S.; Abdo, H.G.; Almohamad, H.; Alatrach, B.; Srivastava, A.K.; Al-Mutiry, M.; Bal, S.K.; Chandran, S.M.A.; Mohammed, S. Modeling the impacts of projected climate change on wheat crop suitability in semi-arid regions using the AHP-based weighted climatic suitability index and CMIP6. Geosci. Lett. 2023, 10, 20. [Google Scholar] [CrossRef]
- Li, G.; Chen, W.; Zhang, X.; Bi, P.; Yang, Z.; Shi, X.; Wang, Z. Spatiotemporal dynamics of vegetation in China from 1981 to 2100 from the perspective of hydrothermal factor analysis. Environ. Sci. Pollut. Res. 2022, 29, 14219–14230. [Google Scholar] [CrossRef]
- Zhao, Q.; Zhu, Z.; Zeng, H.; Zhao, W.; Myneni, R.B. Future greening of the Earth may not be as large as previously predicted. Agric. For. Meteorol. 2020, 292, 108111. [Google Scholar] [CrossRef]
- Yuan, W.; Wu, S.Y.; Hou, S.; Xu, Z.; Pang, H.; Lu, H. Projecting future vegetation change for Northeast China using CMIP6 model. Remote Sens. 2021, 13, 3531. [Google Scholar] [CrossRef]
- Ma, B.; Zeng, W.; Hu, G.; Cao, R.; Cui, D.; Zhang, T. Normalized difference vegetation index prediction based on the delta downscaling method and back-propagation artificial neural network under climate change in the Sanjiangyuan region, China. Ecol. Inform. 2022, 72, 101883. [Google Scholar] [CrossRef]
- Ren, J.; Tong, S.; Ying, H.; Mei, L.; Bao, Y. Historical and Future Changes in Extreme Climate Events and Their Effects on Vegetation on the Mongolian Plateau. Remote Sens. 2022, 14, 4642. [Google Scholar] [CrossRef]
- Kawabata, A.; Ichii, K.; Yamaguchi, Y. Global monitoring of interannual changes in vegetation activities using NDVI and its relationships to temperature and precipitation. Int. J. Remote Sens. 2001, 22, 1377–1382. [Google Scholar] [CrossRef]
- Wang, J.; Rich, P.M.; Price, K.P. Temporal responses of NDVI to precipitation and temperature in the central Great Plains, USA. Int. J. Remote Sens. 2003, 24, 2345–2364. [Google Scholar] [CrossRef]
- Nguyen, K.A.; Chen, W.; Lin, B.S.; Seeboonruang, U. Comparison of ensemble machine learning methods for soil erosion pin measurements. ISPRS Int. J. Geo-Inf. 2021, 10, 42. [Google Scholar] [CrossRef]
- Willemink, M.J.; Koszek, W.A.; Hardell, C.; Wu, J.; Fleischmann, D.; Harvey, H.; Folio, L.R.; Summers, R.M.; Rubin, D.L.; Lungren, M.P. Preparing medical imaging data for machine learning. Radiology 2020, 295, 4–15. [Google Scholar] [CrossRef]
- Kratsch, W.; Manderscheid, J.; Röglinger, M.; Seyfried, J. Machine learning in business process monitoring: A comparison of deep learning and classical approaches used for outcome prediction. Bus. Inf. Syst. Eng. 2021, 63, 261–276. [Google Scholar] [CrossRef]
- Talukdar, S.; Singha, P.; Mahato, S.; Pal, S.; Liou, Y.A.; Rahman, A. Land-use land-cover classification by machine learning classifiers for satellite observations—A review. Remote Sens. 2020, 12, 1135. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, L.; Yang, H.; Wu, P.; Wang, B.; Pan, C.; Wu, Y. A Land Cover Classification Method for High-Resolution Remote Sensing Images Based on NDVI Deep Learning Fusion Network. Remote Sens. 2022, 14, 5455. [Google Scholar] [CrossRef]
- Michael, Y.; Helman, D.; Glickman, O.; Gabay, D.; Brenner, S.; Lensky, I.M. Forecasting fire risk with machine learning and dynamic information derived from satellite vegetation index time-series. Sci. Total Environ. 2021, 764, 142844. [Google Scholar] [CrossRef] [PubMed]
- Johnson, M.D.; Hsieh, W.W.; Cannon, A.J.; Davidson, A.; Bédard, F. Crop yield forecasting on the Canadian Prairies by remotely sensed vegetation indices and machine learning methods. Agric. For. Meteorol. 2016, 218, 74–84. [Google Scholar] [CrossRef]
- Ichii, K.; Kawabata, A.; Yamaguchi, Y. Global correlation analysis for NDVI and climatic variables and NDVI trends: 1982–1990. Int. J. Remote Sens. 2002, 23, 3873–3878. [Google Scholar] [CrossRef]
- De Jong, R.; de Bruin, S.; de Wit, A.; Schaepman, M.E.; Dent, D.L. Analysis of monotonic greening and browning trends from global NDVI time-series. Remote Sens. Environ. 2011, 115, 692–702. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, S.; Bai, X.; Tan, Q.; Li, Q.; Wu, L.; Tian, S.; Hu, Z.; Li, C.; Deng, Y. Factors Affecting Long-Term Trends in Global NDVI. Forests 2019, 10, 372. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Y.; Li, S.; Motesharrei, S. Spatial and temporal patterns of global NDVI trends: Correlations with climate and human factors. Remote Sens. 2015, 7, 13233–13250. [Google Scholar] [CrossRef]
- Wu, D.; Wu, H.; Zhao, X.; Zhou, T.; Tang, B.; Zhao, W.; Jia, K. Evaluation of spatiotemporal variations of global fractional vegetation cover based on GIMMS NDVI data from 1982 to 2011. Remote Sens. 2014, 6, 4217–4239. [Google Scholar] [CrossRef]
- Teng, H.; Chen, S.; Hu, B.; Shi, Z. Future changes and driving factors of global peak vegetation growth based on CMIP6 simulations. Ecol. Inform. 2023, 75, 102031. [Google Scholar] [CrossRef]
- Fick, S.E.; Hijmans, R.J. WorldClim 2: New 1km spatial resolution climate surfaces for global land areas. Int. J. Climatol. 2017, 37, 4302–4315. [Google Scholar] [CrossRef]
- Amatulli, G.; Domisch, S.; Tuanmu, M.N.; Parmentier, B.; Ranipeta, A.; Malczyk, J.; Jetz, W. A suite of global, cross-scale topographic variables for environmental and biodiversity modeling. Sci. Data 2018, 5, 180040. [Google Scholar] [CrossRef]
- Nguyen, K.A.; Chen, W.; Lin, B.S.; Seeboonruang, U.; Thomas, K. Predicting sheet and rill erosion of Shihmen reservoir watershed in Taiwan using machine learning. Sustainability 2019, 11, 3615. [Google Scholar] [CrossRef]
- Nguyen, K.A.; Chen, W. DEM-and GIS-Based Analysis of Soil Erosion Depth Using Machine Learning. ISPRS Int. J. Geo-Inf. 2021, 10, 452. [Google Scholar] [CrossRef]
- Tsai, F.; Lai, J.S.; Nguyen, K.A.; Chen, W. Determining cover management factor with remote sensing and spatial analysis for improving long-term soil loss estimation in watersheds. ISPRS Int. J. Geo-Inf. 2021, 10, 19. [Google Scholar] [CrossRef]
- Nguyen, K.A.; Chen, W.; Lin, B.S.; Seeboonruang, U. Using machine learning-based algorithms to analyze erosion rates of a watershed in Northern Taiwan. Sustainability 2020, 12, 2022. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Mann, H.B. Non-parametric tests against trend. Econom. J. Econom. Soc. 1945, 13, 245–259. [Google Scholar]
- Kendall, M.G. Rank Correlation Methods, 4th ed.; Charles Griffin: London, UK, 1975. [Google Scholar]
- Gilbert, R.O. Statistical Methods for Environmental Pollution Monitoring; John Wiley & Sons: Hoboken, NJ, USA, 1987. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Codes | Meaning |
|---|---|---|
| 1 | BIO1 | Annual Mean Temperature |
| 2 | BIO2 | Mean Diurnal Range (Mean of monthly (max temperature − min temperature)) |
| 3 | BIO3 | Isothermality (BIO2/BIO7) (×100) |
| 4 | BIO4 | Temperature Seasonality (standard deviation ×100) |
| 5 | BIO5 | Max Temperature of Warmest Month |
| 6 | BIO6 | Min Temperature of Coldest Month |
| 7 | BIO7 | Temperature Annual Range (BIO5–BIO6) |
| 8 | BIO8 | Mean Temperature of Wettest Quarter |
| 9 | BIO9 | Mean Temperature of Driest Quarter |
| 10 | BIO10 | Mean Temperature of Warmest Quarter |
| 11 | BIO11 | Mean Temperature of Coldest Quarter |
| 12 | BIO12 | Annual Precipitation |
| 13 | BIO13 | Precipitation of Wettest Month |
| 14 | BIO14 | Precipitation of Driest Month |
| 15 | BIO15 | Precipitation Seasonality (Coefficient of Variation) |
| 16 | BIO16 | Precipitation of Wettest Quarter |
| 17 | BIO17 | Precipitation of Driest Quarter |
| 18 | BIO18 | Precipitation of Warmest Quarter |
| 19 | BIO19 | Precipitation of Coldest Quarter |
| No. | Codes | Meaning |
|---|---|---|
| 1 | ELEV | Elevation |
| 2 | ROU | Roughness |
| 3 | TRI | Terrain Ruggedness Index |
| 4 | TPI | Topographic Position Index |
| 5 | VRM | Vector Ruggedness Measure |
| 6 | ACOS | Aspect Cosine |
| 7 | ASIN | Aspect Sine |
| 8 | SLOPE | Slope |
| 9 | ENESS | Eastness |
| 10 | NNESS | Northness |
| 11 | PCURV | Profile curvature |
| 12 | TCURV | Tangential curvature |
| 13 | DX | First-order partial derivative (E–W slope) |
| 14 | DY | First-order partial derivative (N–S slope) |
| 15 | DXX | Second-order partial derivative (E–W slope) |
| 16 | DYY | Second-order partial derivative (N–S slope) |
| Training | Test | |||
|---|---|---|---|---|
| Average | Standard Deviation | Average | Standard Deviation | |
| Number of samples | 4164 | 1785 | ||
| RMSE | 0.050 | 0.001 | 0.108 | 0.006 |
| NSE | 0.982 | 0.001 | 0.913 | 0.011 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, K.A.; Seeboonruang, U.; Chen, W. Projected Climate Change Effects on Global Vegetation Growth: A Machine Learning Approach. Environments 2023, 10, 204. https://doi.org/10.3390/environments10120204
Nguyen KA, Seeboonruang U, Chen W. Projected Climate Change Effects on Global Vegetation Growth: A Machine Learning Approach. Environments. 2023; 10(12):204. https://doi.org/10.3390/environments10120204
Chicago/Turabian StyleNguyen, Kieu Anh, Uma Seeboonruang, and Walter Chen. 2023. "Projected Climate Change Effects on Global Vegetation Growth: A Machine Learning Approach" Environments 10, no. 12: 204. https://doi.org/10.3390/environments10120204
APA StyleNguyen, K. A., Seeboonruang, U., & Chen, W. (2023). Projected Climate Change Effects on Global Vegetation Growth: A Machine Learning Approach. Environments, 10(12), 204. https://doi.org/10.3390/environments10120204