2.1. Literature Review
Generative Artificial Intelligence (GAI) is built upon deep learning and large-scale data training techniques. It enables the creation of multimodal content—including text, images, audio, and video—with a high degree of autonomy and adaptability across diverse scenarios (
Cao et al., 2023). From a technological evolution perspective, GAI represents a paradigm shift from “analytical intelligence” to “creative intelligence,” transforming technical architectures and redefining human–AI collaboration. Unlike traditional AI that emphasizes classification and prediction, GAI is oriented toward content creation and innovation. For instance, ChatGPT generates high-quality natural language text, while DALL·E produces diverse images based on user prompts, offering unprecedented creative support (
Cao et al., 2023). Notably, the role of GAI in the workplace has evolved from that of a simple auxiliary tool to a catalyst for innovation, reshaping workflows, decision-making models, and modes of creative expression. However, widespread GAI adoption has raised issues including privacy concerns, algorithmic bias, and ethical misuse, imposing higher standards for responsible use (
Tang et al., 2023).
Contemporary organizational research emphasizes the pressing need for systematic AI literacy development in workplace contexts. Studies indicate that inadequate employee AI competencies represent a significant barrier to digital transformation initiatives, with skill gaps identified across sectors (
Abou Karroum & Elshaiekh, 2023). Cross-industry research demonstrates that AI literacy gaps affect organizational innovation capacity and competitive advantage, highlighting the need for comprehensive workplace-oriented AI literacy frameworks (
Borines et al., 2024).
In response to these challenges, researchers have increasingly recognized that a lack of user competence in handling GAI technologies is a major bottleneck limiting its effective implementation. Inadequate prompt engineering skills may result in low-quality or irrelevant outputs, while insufficient critical evaluation capabilities hinder users’ ability to assess the logical coherence and reliability of generated content (
Dang et al., 2022;
Lin, 2023). Additionally, limited awareness of ethical and compliance issues can further exacerbate the risks of misuse (
Tang et al., 2023). These issues collectively underscore the importance of cultivating Generative AI Literacy (GAIL). GAIL is proposed as a theoretical construct aimed at assessing users’ multifaceted capabilities in employing GAI, thereby supporting both technological effectiveness and social responsibility.
GAIL is theoretically rooted in established scholarly traditions that provide a foundation for scale development. First, it draws from the traditions of information literacy and digital literacy, emphasizing the ability to identify, evaluate, and utilize information effectively within digital environments (
Machin-Mastromatteo, 2021). Second, it incorporates insights from the technology acceptance model (TAM) and the diffusion of innovation theory, which explore users’ psychological mechanisms and behavioral tendencies regarding technology adoption (
Y. Zhou, 2008). Third, GAIL integrates key perspectives from critical thinking theory, which emphasizes rational evaluation and reflective judgment of AI-generated content (
Gonsalves, 2024). Finally, it incorporates elements from ethical decision-making theory, foregrounding the importance of ethical considerations and value-based judgment in technology use (
Mertz et al., 2023). This multi-theoretical integration provides a solid foundation for the GAIL framework and reflects its multidimensional nature.
To understand current GAIL measurement landscapes and identify theoretical gaps, this study conducted a comprehensive comparative analysis of existing frameworks. This comparative analysis not only reveals the diversity of existing approaches but, more importantly, exposes some key limitations that partially demonstrate the necessity of developing workplace-specific frameworks. Existing studies have made preliminary efforts to conceptualize and measure GAIL, but several important distinctions indicate the necessity and value of developing alternative approaches.
Specifically,
Ng et al. (
2024) proposed the ABCE framework—Affective, Behavioral, Cognitive, and Ethical—outlining four core dimensions of GAIL through a 32-item validated questionnaire targeting secondary school students. Their approach, grounded in educational psychology frameworks, emphasizes the balance between emotional engagement and technical competence in educational settings. However, this framework’s focus on student learning outcomes rather than workplace performance competencies somewhat limits its applicability to organizational contexts where collaborative innovation and professional standards are important.
Meanwhile,
Lee and Park (
2024), focusing specifically on ChatGPT users, developed a multidimensional 25-item scale that includes technical proficiency, critical evaluation, communication proficiency, creative application, and ethical competence. Their methodology employed the Delphi method for expert consensus and focus group validation, offering valuable insights into user experience with specific AI platforms. However, the platform-specific nature of their framework may limit generalizability across diverse GAI technologies, and their emphasis on individual user experience may not adequately address the collaborative and organizational performance requirements that characterize workplace AI implementation.
Among existing AI literacy frameworks,
Nong et al. (
2024) merit particular attention due to their broad dimensional scope and focus on the general public. The authors proposed a comprehensive seven-dimensional model that includes application ability, cognitive ability, morality, critical thinking, Self-Efficacy, perceived ease of use, and perceived usefulness. Their framework is designed for the general population and emphasizes perceptual measures grounded in technology acceptance theory, validated through large-scale surveys and structural equation modeling. However, compared with the workplace-oriented framework proposed in this study, several limitations emerge. First, in terms of conceptual validity, potential conceptual overlap between dimensions such as “application ability” and “Self-Efficacy” may undermine discriminant validity. Second, regarding the measurement focus, the emphasis on perceptual constructs (e.g., perceived ease of use and usefulness) reflects users’ attitudes rather than actual behavioral competencies required in professional settings, thereby limiting the framework’s predictive validity for workplace performance. Third, in terms of contextual applicability, a general population focus may not sufficiently account for the collaborative dynamics, regulatory compliance, and performance standards that are critical in workplace AI adoption. Finally, from the perspective of theoretical integration, while the framework draws from multiple theoretical traditions, it lacks a tightly integrated structure, which may constrain its overall explanatory power.
Additionally,
Zhao et al. (
2022) developed a four-dimensional framework encompassing “Knowing and Understanding AI,” “Applying AI,” “Evaluating AI Application,” and “AI Ethics,” specifically targeting primary and secondary school teachers. Their research, based on educational technology frameworks and validated through structural equation modeling analysis with 1013 survey participants, found that “Applying AI” had significant positive effects on the other three dimensions. While their teacher-specific needs assessment and expert content validation provide valuable insights, the occupation-specific design and educational context constraints somewhat limit cross-sector applicability and may not adequately address the broader organizational requirements that characterize contemporary workplace AI implementation.
To provide a systematic comparison of approaches in this field and highlight the unique contributions of this study’s framework,
Table 1 presents a comprehensive analysis of major GAIL scale development studies, detailing comparisons of their theoretical foundations, methodological approaches, target populations, and related limitations.
As shown in
Table 1, the GAIL framework proposed in this study differs significantly from existing models of AI literacy in its multidimensional structure, demonstrating notable strengths in both theoretical construction and practical relevance. First, in terms of competency architecture, this study adopts a process-oriented design that conceptualizes GAIL as a dynamic and progressively developing competency spectrum. The framework moves from foundational technical understanding to advanced creative application, reflecting the iterative and evolving nature of human–AI collaboration in workplace environments. This developmental perspective stands in contrast to traditional models that often treat AI literacy as a static collection of discrete skills, offering a more theoretically grounded and future-oriented approach. Second, regarding the integration of technical and ethical dimensions, this framework departs from prior instruments that typically emphasize either technical proficiency or educational application. Instead, it seeks to achieve a balanced synthesis of technical capability and ethical responsibility across all dimensions. This dual emphasis aligns with the real-world demands of professional environments, where the ability to competently and responsibly engage with AI technologies is increasingly essential. Finally, in terms of contextual adaptability, this study is explicitly tailored to the workplace, incorporating key organizational considerations such as collaborative innovation, regulatory compliance, and performance accountability. These elements, often overlooked in general-purpose or education-focused frameworks, enhance the contextual relevance of GAIL for contemporary organizational settings.
A deeper analysis of current research on the theory and measurement of Generative AI Literacy (GAIL) reveals three primary conceptual gaps that this study attempts to address, which to some extent demonstrates the necessity and value of the proposed framework. First, regarding conceptual boundaries, further clarification may be needed. Some existing studies may not adequately distinguish GAIL from general AI literacy, to some extent overlooking the unique interactive mechanisms and creative attributes of generative AI. This may result in some degree of conceptual overlap and ambiguity. Second, the theoretical connotations of GAIL require systematic development. Most existing frameworks may be constructed more based on practical needs rather than theoretical guidance, potentially leading to relatively unclear logical relationships and developmental pathways among dimensions. Third, measurement frameworks exhibit some imbalance. Current scales often may overemphasize either technical operation or ethical awareness, failing to adequately achieve balanced representation of technical capability and social responsibility, which may to some extent affect the comprehensiveness and validity of measurement efforts. These gaps collectively underscore the importance of constructing a rigorous conceptual and measurement framework for GAIL grounded in relatively solid theory.
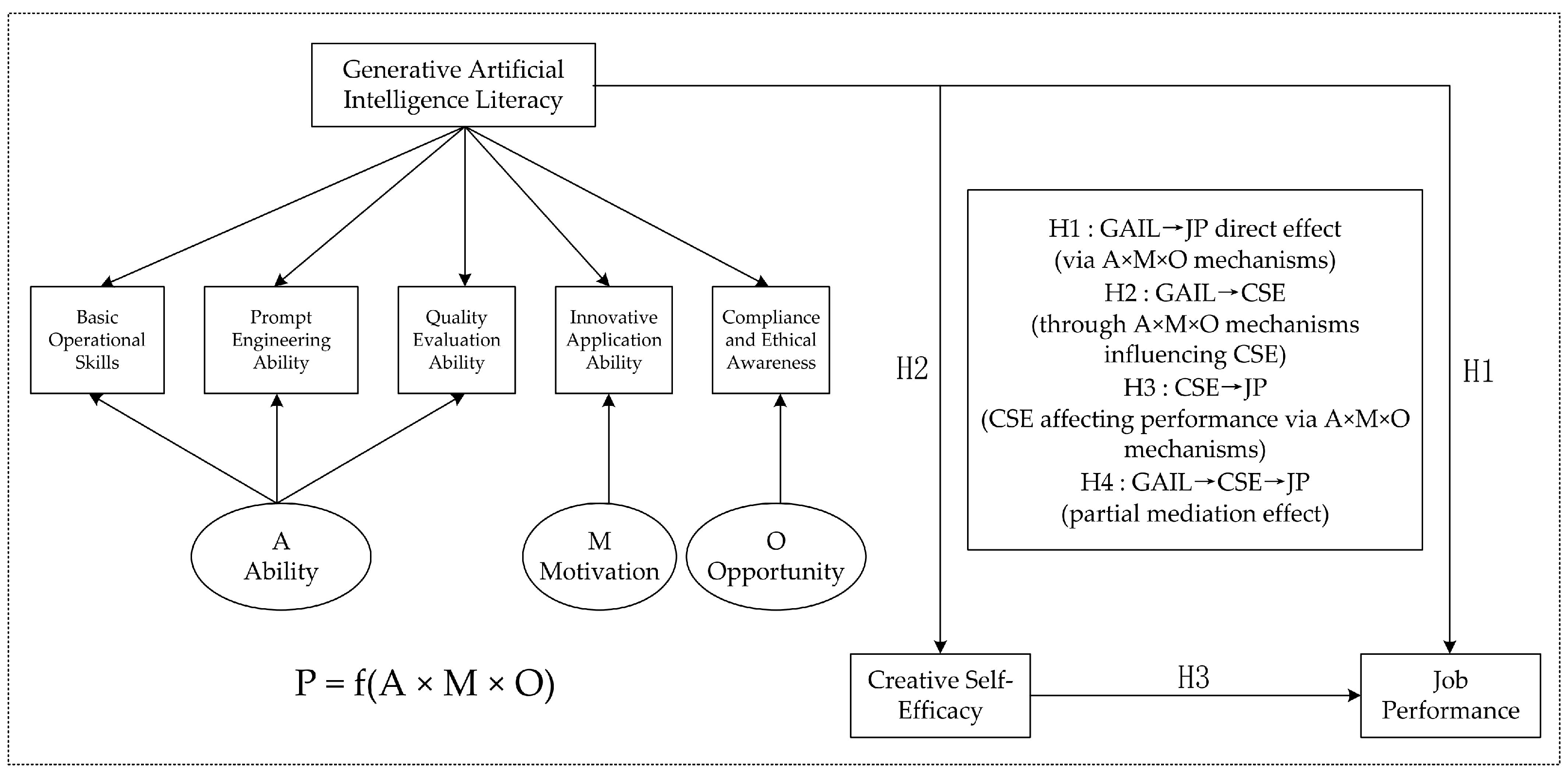
Based on the above analysis, this study redefines Generative AI Literacy (GAIL) as a multidimensional conceptual framework for evaluating users’ capabilities throughout the entire process of using generative AI technologies. The choice of five core dimensions—basic technical proficiency, prompt optimization, quality evaluation, innovative practice, and ethical and compliance awareness—rather than alternative configurations is grounded in both theoretical considerations and practical demands of the workplace. This dimensional design aims to address several shortcomings found in existing frameworks. Compared with the seven-dimensional model by
Nong et al. (
2024), which may suffer from conceptual overlap, the five-dimensional structure in this study seeks to enhance discriminant validity. In contrast to
Lee and Park’s (
2024) platform-specific framework, the present model strives for cross-platform and cross-technology applicability. Furthermore, while many existing models are oriented toward educational contexts, this framework is explicitly designed to align with workplace performance requirements. This redefinition offers three key theoretical advantages. First, it conceptualizes GAIL as a multidimensional capability structure rather than a singular skill set, highlighting its holistic and systematic nature. Second, it frames GAIL as a process-oriented competence, emphasizing performance across the entire life cycle of technology use rather than static knowledge acquisition. Third, it integrates technical application with ethical responsibility, uniting the ability to use AI with the capacity to use it responsibly—thereby providing a more comprehensive and practice-oriented interpretation of digital literacy.
To systematically capture the multidimensional nature of users’ competencies in using generative AI, this study identifies five core dimensions of GAIL based on extensive literature review and established theoretical traditions. The construction of the conceptual model follows established competency development theoretical frameworks, particularly Bloom’s cognitive taxonomy’s hierarchical structure, which provides a relatively clear pathway for skill development from basic cognition to advanced creation (
Voinohovska & Doncheva, 2024). Meanwhile, mature research in the digital literacy field provides important reference for constructing multidimensional competency frameworks, particularly in the integration of technical capabilities and critical thinking skills (
Jordan et al., 2024). These dimensions form a unified theoretical model as a relatively integrated, hierarchical competency spectrum—ranging from foundational to advanced levels, and from technical operation to ethical judgment.
The five-dimensional structural design of the conceptual model also draws from theoretical insights about competency progression in information literacy research. Research in the information literacy field indicates that relatively effective digital competency frameworks typically include core elements such as technical foundations, information processing, critical evaluation, and innovative application (
Adeleye et al., 2024). This study’s dimensional selection largely aligns with this established pattern while making adjustments and extensions for the unique characteristics of generative AI. Additionally, research in technology acceptance and usage provides important theoretical support for understanding how users progress from basic use to innovative application (
Johnson et al., 2014). Human–computer interaction research also provides valuable theoretical foundations for understanding GAI’s unique interaction patterns and competency requirements, particularly in prompt design and content evaluation (
Shen et al., 2025).
From the perspective of cognitive development theory, this model reflects a progression from basic skill acquisition to critical thinking and ultimately to creative application. From the lens of technology acceptance and usage, it represents a deepening trajectory from understanding and use to innovation. Ethically, it embodies awareness of responsible technology use throughout the application process. This theoretical architecture facilitates systematic understanding of the internal structure of GAIL and provides a relatively clear foundation for developing corresponding measurement tools.
Basic technical proficiency is the foundational dimension of GAIL, rooted in digital literacy theory (
Ng et al., 2024) and information processing frameworks (
Ebert & Louridas, 2023). It refers to users’ understanding of the basic principles and operational techniques of generative AI, providing prerequisites for the development of other capabilities. Related empirical research suggests that technical foundational capabilities may directly affect the development of subsequent advanced capabilities and the effective use of AI tools (
Campbell et al., 2023). In Bloom’s taxonomy, this corresponds to the “remember” and “understand” levels, serving as the basis for constructing effective mental models.
Prompt optimization ability represents a relatively unique and important skill in GAI applications, derived from human–computer interaction theory (
Oppenlaender et al., 2023) and communication studies (
Liu et al., 2023). It measures users’ capacity to design and refine prompts that improve the quality and relevance of generated content. This ability may directly affect the efficiency of human–AI interaction and represents an important characteristic distinguishing generative AI from traditional AI. Prompt engineering represents a shift from “using technology” to “guiding technology” and reflects metacognitive capabilities in human–machine collaboration.
Content evaluation ability emphasizes users’ critical thinking in assessing AI-generated outputs, based on critical thinking theory (
Tang et al., 2023) and information literacy frameworks (
Fu et al., 2023). This skill is of significant importance for ensuring the reliability and practical utility of generated content. Related empirical research indicates that content evaluation ability may serve as an important safeguard against automation bias and cognitive delegation, potentially directly affecting the quality of AI-assisted decision making.
Innovative application ability captures users’ capacity to transform creative ideas into practical outcomes using GAI, rooted in creativity theory (
Bilgram & Laarmann, 2023) and innovation diffusion frameworks (
Harwood, 2023). This dimension represents the higher-order component of GAIL, corresponding to the “synthesize” and “create” levels in Bloom’s taxonomy. Organizational research suggests that innovative application ability may serve as an important mediating factor in translating technological literacy into job performance, potentially to some extent determining the organizational return on AI investment.
Ethical and compliance awareness represents an important dimension within this study’s GAIL framework. This dimension addresses users’ capabilities to identify potential risks in GAI applications and adhere to relevant legal, regulatory, and social norms that characterize professional environments, drawing from ethical decision-making theory (
Tang et al., 2023) and technology ethics frameworks (
Banh & Strobel, 2023). In workplace contexts, this dimension becomes particularly relevant as organizations must navigate complex regulatory requirements, data privacy concerns, intellectual property considerations, and professional standards that govern AI implementation. This dimension recognizes that responsible AI use requires dedicated competencies that are essential for comprehensive Generative AI Literacy in workplace contexts.
To further explore how GAIL influences job performance and its underlying mechanisms, this study establishes a focused dual-core theoretical architecture that attempts to avoid the theoretical fragmentation observed in previous research. This study integrates the Ability–Motivation–Opportunity (AMO) framework as the primary explanatory lens for understanding how GAIL influences workplace performance, while social cognitive theory (
Bandura, 2001) provides the psychological foundation for understanding Self-Efficacy mechanisms and learning processes. This integrated approach builds upon established scholarly traditions while maintaining theoretical coherence and analytical clarity, potentially offering certain advantages over existing frameworks that often lack coherent theoretical grounding. From the perspective of the dual-core theoretical architecture, the GAIL model provides a relatively solid theoretical foundation for subsequent empirical research, systematically elucidating how individual AI competencies translate into organizational performance outcomes through psychological mechanisms.
2.2. Item Generation Based on Artificial Intelligence Algorithms
This study employs an AI-based approach for generating and screening measurement items, utilizing modern natural language processing (NLP) models to assist in scale development. Drawing from the pioneering work of
Hernandez and Nie (
2023), who demonstrated the effectiveness of transformer-based models in personality scale development, we adapted their established methodology to address the specific requirements of workplace Generative AI Literacy measurement. Compared to traditional methods that rely heavily on expert intuition and subjective experience, AI-driven approaches allow for objective and highly efficient generation of candidate items—for instance, producing item pools at the scale of millions within a short time frame. AI-generated items can be evaluated across multiple dimensions simultaneously, including linguistic structure, semantic relevance, content validity, and construct coverage, thereby offering a more systematic and reproducible validation mechanism compared to conventional expert-based approaches.
The item generation pipeline consists of four sequential stages, each leveraging distinct AI capabilities to ensure both quantity and quality of generated items. The process began by clearly defining the target construct and its primary dimensions. Based on these definitions and a set of carefully selected seed items representing each GAIL dimension, item generation was directed accordingly. Following
Hernandez and Nie’s (
2023) validated framework, we utilized their pre-trained generative transformer model accessed through Claude 3.5 Sonnet API. This model was selected for its demonstrated superior performance in generating contextually appropriate and linguistically sophisticated items compared to earlier models like GPT-2, which, despite being freely available, tend to exhibit relatively lower accuracy in domain-specific generation tasks.
In the semantic similarity assessment stage, we implemented the BERT-based approach established by
Hernandez and Nie (
2023) to estimate semantic relatedness between generated items and original seed items. BERT (Bidirectional Encoder Representations from Transformers) was selected over alternative semantic similarity methods due to its bidirectional context processing capability, which enables more nuanced understanding of item semantics compared to unidirectional models. The semantic similarity was calculated using cosine similarity between BERT embeddings, with items achieving similarity scores above 0.7 with seed items being retained for further evaluation. This threshold was established based on Hernandez and Nie’s validation studies to balance semantic relevance with item diversity.
For content validation, we employed zero-shot classification models rather than traditional manual content validity indexing. This methodological choice was motivated by several considerations demonstrated in the original framework: (1) zero-shot classifiers can process large item pools efficiently without requiring extensive labeled training data; (2) they provide consistent and reproducible content categorization across different validation sessions; (3) they can assess content coverage across multiple theoretical dimensions simultaneously; and (4) they reduce potential human bias in content evaluation while maintaining high accuracy rates. The zero-shot classifier was configured to evaluate each generated item against the five GAIL dimensions, providing probability scores for dimension membership and enabling systematic content balance assessment. It is important to note that, after the AI-based item generation and screening process, the candidate items were reviewed and refined by three domain experts. They evaluated each item for conceptual clarity, construct relevance, and linguistic appropriateness, making necessary minor adjustments to improve item quality while preserving the original semantic structure generated by the AI.
Finally, the reliability and validity of the scale were evaluated through exploratory factor analysis (EFA) and Confirmatory Factor Analysis (CFA), followed by further validation of scale performance using additional samples. This multi-stage validation approach ensures that AI-generated items not only demonstrate semantic coherence but also exhibit appropriate psychometric properties for measurement applications.
2.3. Exploratory Factor Analysis
To validate the construct of the Generative AI Literacy Scale, this study distributed electronic questionnaires using a snowball sampling method through social networks and resources from classmates, friends, and family. The snowball sampling was initiated through the researchers’ personal networks, beginning with initial contacts in private sector organizations and asking them to refer colleagues with similar organizational backgrounds. To ensure sample homogeneity and relevance to the workplace context, we specifically targeted employees from private enterprises based on the following organizational classification criteria: respondents were asked to identify their current workplace as (1) state-owned enterprise/state-holding enterprise, (2) private enterprise, (3) foreign-invested enterprise, (4) joint venture, (5) public institution, (6) government agency, (7) social organization/non-profit institution, or (8) other. Only responses from individuals employed in private enterprises (Option 2) were included in the analysis.
A total of 311 questionnaires were distributed with a response rate of 89.4%, yielding 278 valid responses after data screening for completeness and attention checks. No formal quotas were established for demographic characteristics, but we monitored sample composition during collection to ensure adequate representation across age and experience groups. Inclusion criteria required respondents to be current employees in private enterprises with at least basic familiarity with AI technologies, while exclusion criteria eliminated responses with incomplete data or failed attention checks. In terms of gender distribution, 48.56% were male and 51.44% were female. Regarding age, 20.14% were aged 25 or younger, 38.85% were aged 26–35, 25.54% were aged 36–45, 10.79% were aged 46–55, and 4.68% were aged 56 or older. In terms of marital status, 23.74% were unmarried and single, 20.14% were unmarried but not single, 12.23% were married without children, and 43.88% were married with children. Regarding education, 4.32% had a college degree or lower, 50.72% held a bachelor’s degree, 38.49% held a master’s degree, and 6.47% had a doctoral degree. In terms of work experience, 22.30% had 5 years or fewer, 23.74% had 6–10 years, 26.26% had 11–15 years, 14.75% had 16–20 years, and 12.95% had more than 21 years. Regarding monthly income, 10.79% earned below 5000 CNY, 39.21% earned between 5000 and 8000 CNY, 30.22% earned between 8000 and 12,000 CNY, and 19.78% earned more than 12,000 CNY.
This study conducted exploratory factor analysis (EFA) on the 311 data points using SPSS 27.0. The results indicated a Kaiser–Meyer–Olkin (KMO) value of 0.915, which exceeds the recommended threshold of 0.7. Bartlett’s Test of Sphericity yielded a chi-square value of 5244.240 (
df = 136), which was significant at the 0.1% level, indicating that the data are suitable for factor analysis. Principal component analysis was used to extract factors, with oblique rotation, and factors with eigenvalues greater than 1 were retained. The results of the EFA showed that the five extracted factors accounted for a cumulative variance of 89.746%, surpassing the 60% threshold. These five dimensions were: basic operational skills, prompt engineering ability, innovative application ability, quality evaluation ability, and compliance and ethical awareness. As shown in
Table 2, the standardized factor loadings for all measurement items ranged from 0.82 to 0.92, all exceeding the 0.5 threshold, indicating good construct validity for the items.
2.4. Confirmatory Factor Analysis of the Scale
To assess the fit of the factors in the Generative Artificial Intelligence Literacy Scale, this study conducted a second independent data collection using the same snowball sampling methodology and organizational targeting criteria as the EFA phase. Following the same approach, we leveraged social networks of classmates and friends to identify and recruit private enterprise employees, maintaining consistency in sample characteristics with the exploratory phase.
A total of 337 questionnaires were distributed with a response rate of 90.8%, and after screening using identical inclusion and exclusion criteria as the EFA phase, 306 valid samples were obtained for confirmatory factor analysis. The same organizational classification question was used to ensure all respondents were private enterprise employees, and attention checks were implemented to maintain data quality. In terms of gender distribution, 50.33% of the respondents were male, and 49.67% were female. Regarding age distribution, 20.26% were aged 25 or younger, 38.56% were aged 26–35, 25.49% were aged 36–45, 10.78% were aged 46–55, and 4.90% were aged 56 or older. In terms of marital status, 19.28% were unmarried and single, 21.90% were unmarried but not single, 13.40% were married without children, and 45.42% were married with children. Regarding educational level, 3.59% had a college degree or lower, 52.29% held a bachelor’s degree, 35.29% held a master’s degree, and 8.82% held a doctoral degree. In terms of work experience, 21.57% had 5 years or fewer, 24.18% had 6–10 years, 27.45% had 11–15 years, 14.38% had 16–20 years, and 12.42% had 21 years or more. Regarding monthly income, 9.15% earned less than 5000 CNY, 36.60% earned between 5000 and 8000 CNY, 32.68% earned between 8000 and 12,000 CNY, and 21.57% earned more than 12,000 CNY.
The results indicated that the five-factor model provided the best fit (
χ2 = 136.937,
df = 109, SRMR = 0.020, CFI = 0.995, TLI = 0.994, and RMSEA = 0.029). Furthermore, as shown in
Table 3, the composite reliability (CR) for each dimension of Generative AI Literacy exceeded 0.7, and the average variance extracted (AVE) values for all dimensions were greater than 0.5, indicating strong convergent validity for the Generative AI Literacy Scale.
To enhance the practical applicability of the scale and improve response efficiency in subsequent research and organizational applications, we recommend constructing a streamlined 10-item short-form scale based on the results of both exploratory factor analysis (EFA) and confirmatory factor analysis (CFA). This abbreviated scale would be developed by selecting the two highest factor-loading items from each of the five dimensions, creating a concise measurement instrument that significantly reduces respondent burden and improves questionnaire completion rates while preserving the theoretical integrity of the five-dimensional GAIL framework.



{kind=link}