
Capturing the Heterogeneity of Word Learners by Analyzing Persons

Abstract
1. Introduction
Applications of Person-Centered Analyses to the Study of Language Development
2. Methods
2.1. Participants
2.2. Procedures
2.3. Analytical Plan
3. Results
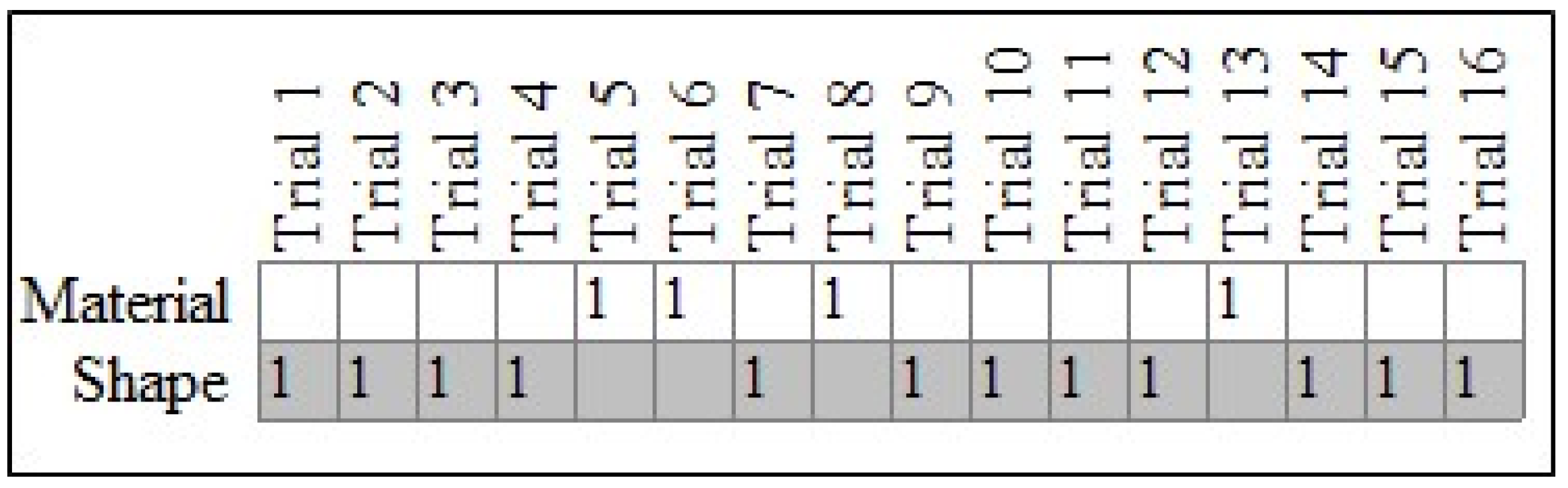
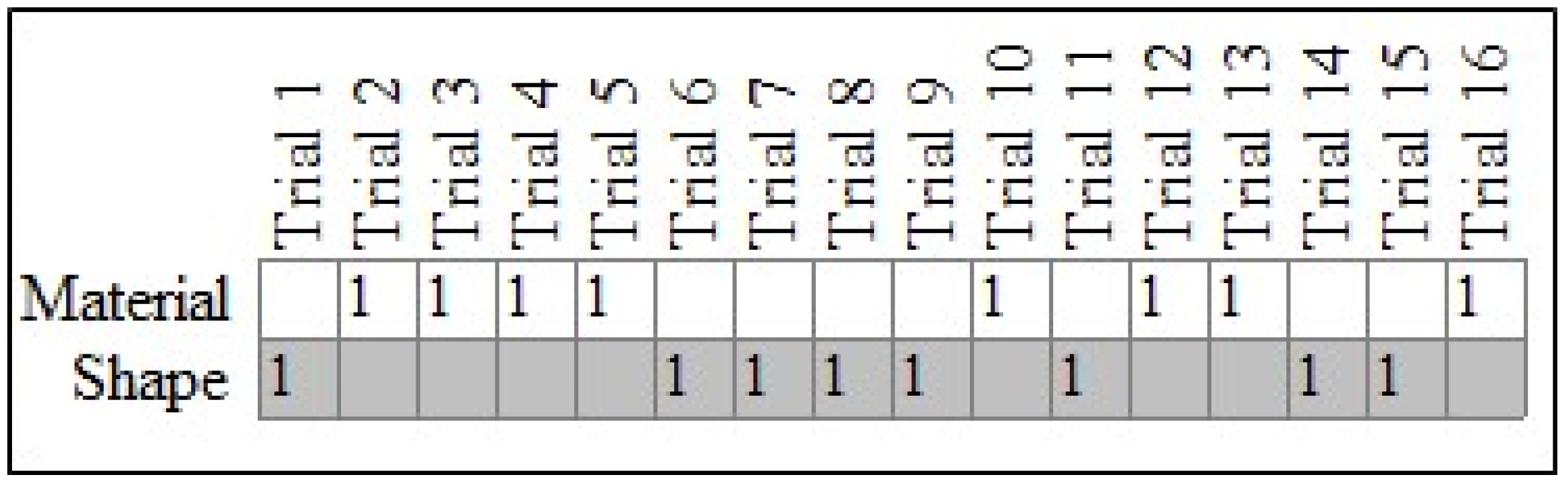
3.1. Person-Centered Tests against Chance versus Aggregate Tests of Chance
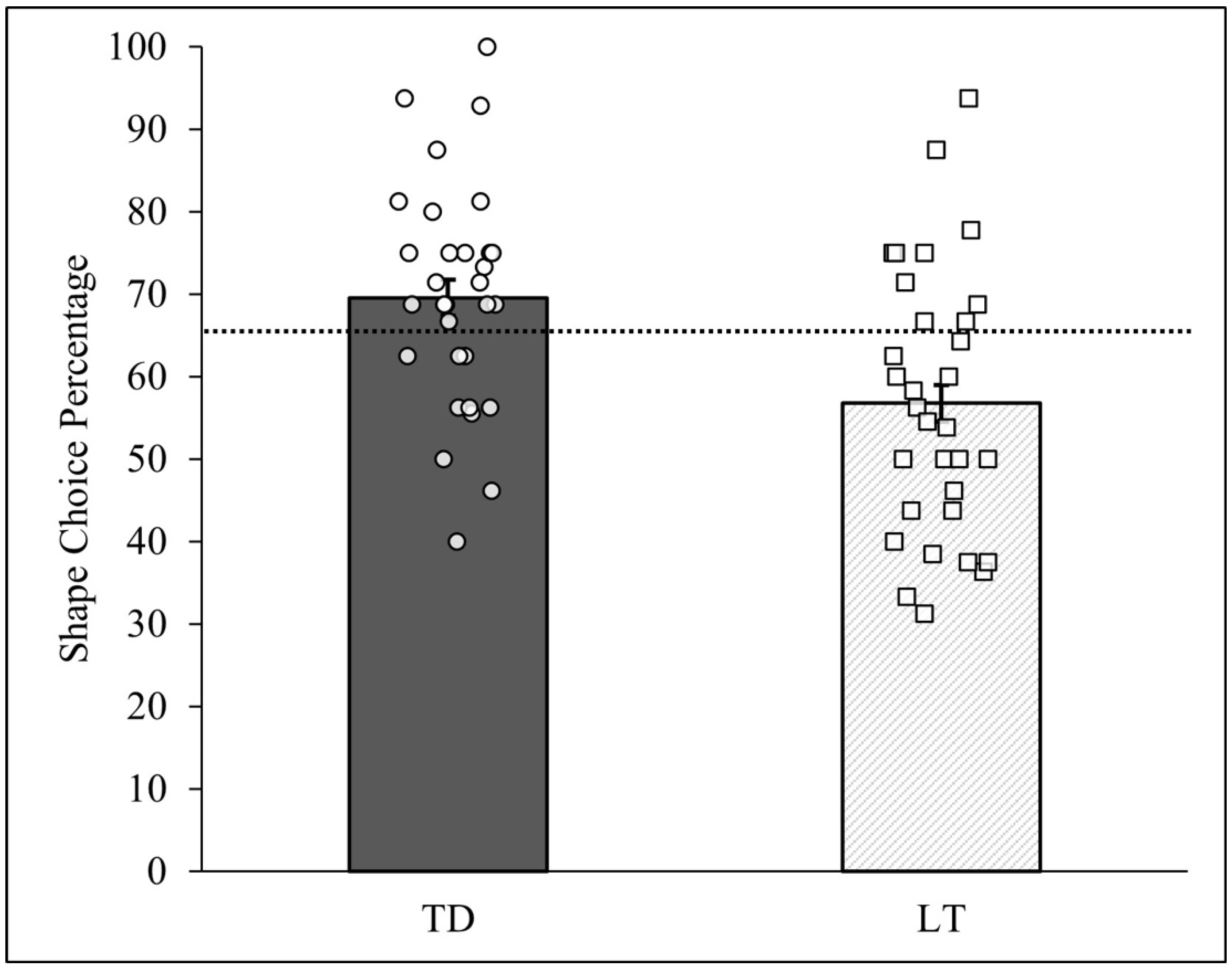
3.2. Group Comparisons with Persons
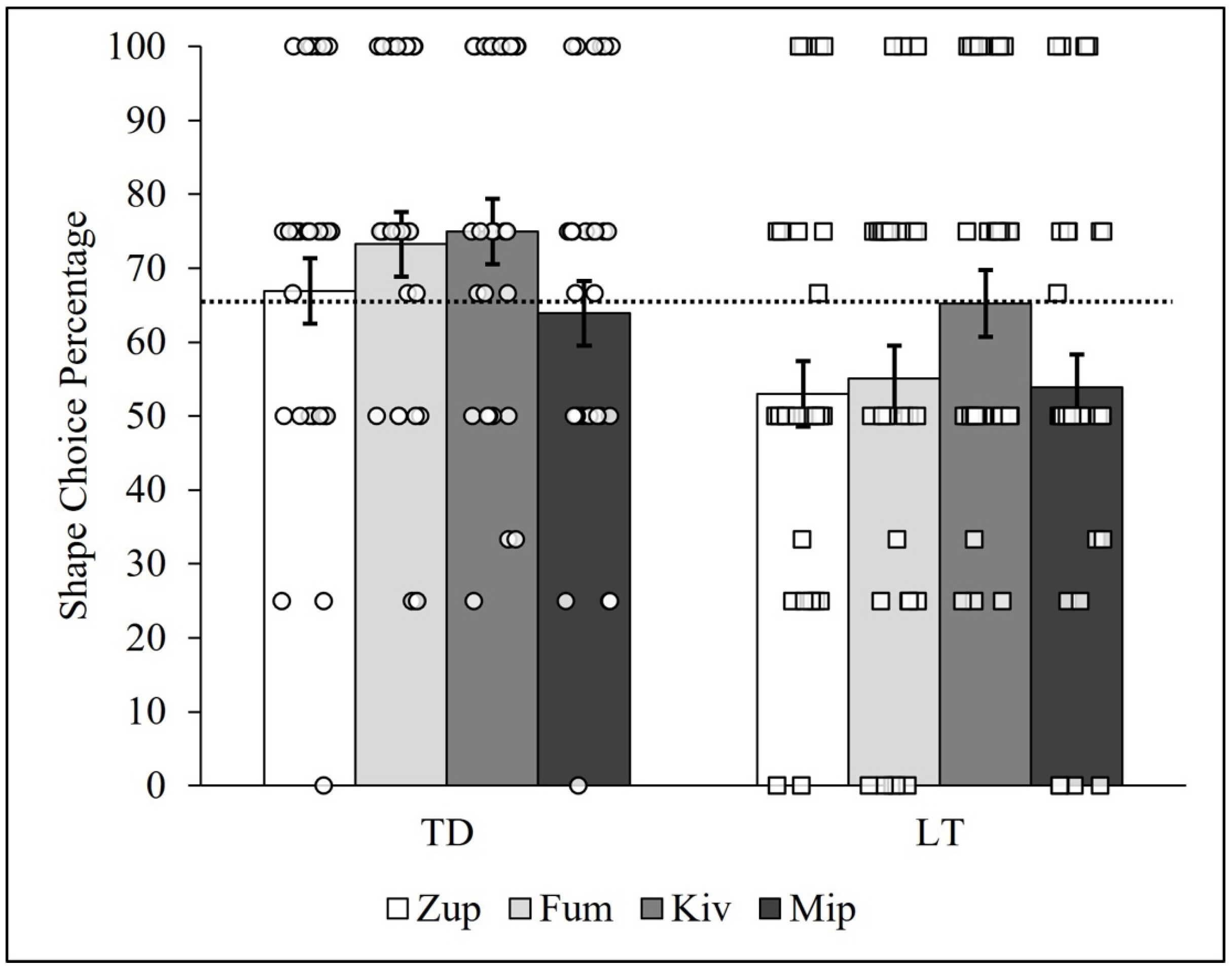
3.3. Mixed-Effects and Person-Centered Approaches
3.4. Random Effects and Person-Centered Approaches
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bates, E.; Dale, P.S.; Thal, D. Individual differences and their implications for theories of language development. Handb. Child Lang. 1995, 30, 96–151. [Google Scholar] [CrossRef]
- Gershkoff-Stowe, L.; Smith, L.B. Shape and the first hundred nouns. Child Dev. 2004, 75, 1098–1114. [Google Scholar] [CrossRef] [PubMed]
- McCullough, K.C.; Bayles, K.A.; Bouldin, E.D. Language performance of individuals at risk for mild cognitive impairment. J. Speech Lang. Hear. Res. 2019, 62, 706–722. [Google Scholar] [CrossRef] [PubMed]
- Perry, L.K.; Kucker, S.C. The heterogeneity of word learning biases in late-talking children. J. Speech Lang. Hear. Res. 2019, 62, 554–563. [Google Scholar] [CrossRef] [PubMed]
- Perry, L.K.; Kucker, S.C.; Horst, J.S.; Samuelson, L.K. Late bloomer or language disorder? Differences in toddler vocabulary composition associated with long-term language outcomes. Dev. Sci. 2022, 26, e13342. [Google Scholar] [CrossRef] [PubMed]
- Dollaghan, C. Late talker or SLI?: The story of Jay X. Semin. Speech Lang. 1998, 19, 7–14. [Google Scholar] [CrossRef] [PubMed]
- McManus, R.M.; Young, L.; Sweetman, J. Psychology is a property of persons, not averages or distributions: Confronting the group-to-person generalizability problem in experimental psychology. Adv. Methods Pract. Psychol. Sci. 2023, 6, 1–23. [Google Scholar] [CrossRef]
- van der Gaag, M.A. A person-centered approach in developmental science: Why this is the future and how to get there. Infant Child Dev. 2023, 32, e2478. [Google Scholar] [CrossRef]
- Gordon, K.R. How mixed-effects modeling can advance our understanding of learning and memory and improve clinical and educational practice. J. Speech Lang. Hear. Res. 2019, 62, 507–524. [Google Scholar] [CrossRef]
- McMillan, G.P.; Cannon, J.B. Bayesian applications in auditory research. J. Speech Lang. Hear. Res. 2019, 62, 577–586. [Google Scholar] [CrossRef]
- Oleson, J.J.; Brown, G.D.; McCreery, R. The evolution of statistical methods in speech, language, and hearing sciences. J. Speech Lang. Hear. Res. 2019, 62, 498–506. [Google Scholar] [CrossRef] [PubMed]
- Paulon, G.; Reetzke, R.; Chandrasekaran, B.; Sarkar, A. Functional Logistic Mixed-Effects Models for Learning Curves From Longitudinal Binary Data. J. Speech Lang. Hear. Res. 2019, 62, 543–553. [Google Scholar] [CrossRef] [PubMed]
- Walker, E.A.; Redfern, A.; Oleson, J.J. Linear mixed-model analysis to examine longitudinal trajectories in vocabulary depth and breadth in children who are hard of hearing. J. Speech Lang. Hear. Res. 2019, 62, 525–542. [Google Scholar] [CrossRef] [PubMed]
- Byers-Heinlein, K.; Bergmann, C.; Savalei, V. Six solutions for more reliable infant research. Infant Child Dev. 2021, 31, 1–19. [Google Scholar] [CrossRef]
- Syed, M. Special issue on reliability of infant research. Infant Child Dev. 2022, 31, e2382. [Google Scholar] [CrossRef]
- Davis-Kean, P.E.; Ellis, A. An overview of issues in infant and developmental research for the creation of robust and replicable science. Infant Behav. Dev. 2019, 57, 101339. [Google Scholar] [CrossRef] [PubMed]
- Frank, M.C. Towards a more robust and replicable science of infant development. Infant Behav. Dev. 2019, 57, 101349. [Google Scholar] [CrossRef] [PubMed]
- Grice, J.W.; Medellin, E.; Jones, I.; Horvath, S.; McDaniel, H.; O’lansen, C.; Baker, M. Persons as effect sizes. Adv. Methods Pract. Psychol. Sci. 2020, 3, 443–455. [Google Scholar] [CrossRef]
- Speelman, C.P.; McGann, M. Statements about the pervasiveness of behavior require data about the pervasiveness of behavior. Front. Psychol. 2020, 11, 594675. [Google Scholar] [CrossRef]
- Arocha, J.F. Scientific realism and the issue of variability in behavior. Theory Psychol. 2020, 31, 375–398. [Google Scholar] [CrossRef]
- Beechey, T. Ordinal Pattern Analysis: A Tutorial on Assessing the Fit of Hypotheses to Individual Repeated Measures Data. J. Speech Lang. Hear. Res. 2023, 66, 347–364. [Google Scholar] [CrossRef] [PubMed]
- Erisman, M.C.; Blom, E. Reading outcomes in children with developmental language disorder: A person-centered approach. Autism Dev. Lang. Impair. 2020, 5, 2396941520979857. [Google Scholar] [CrossRef] [PubMed]
- de Klerk, M.; Veen, D.; Wijnen, F.; de Bree, E. A step forward: Bayesian hierarchical modelling as a tool in assessment of individual discrimination performance. Infant Behav. Dev. 2019, 57, 101345. [Google Scholar] [CrossRef]
- Sayette, M.A.; Goodwin, M.E.; Creswell, K.G.; Esmacher, H.J.; Dimoff, J.D. A Person-Centered Analysis of Craving in Smoking-Cue-Exposure Research. Clin. Psychol. Sci. 2022, 10, 570–583. [Google Scholar] [CrossRef]
- Valentine, K.D.; Buchanan, E.M. JAM-boree: An application of observation oriented modelling to judgements of associative memory. J. Cogn. Psychol. 2013, 25, 400–422. [Google Scholar] [CrossRef]
- Valentine, K.D.; Buchanan, E.M.; Scofield, J.E.; Beauchamp, M.T. Beyond p values: Utilizing multiple methods to evaluate evidence. Behaviormetrika 2019, 46, 121–144. [Google Scholar] [CrossRef]
- Nketia, J.; Amso, D.; Brito, N.H. Towards a more inclusive and equitable developmental cognitive neuroscience. Dev. Cogn. Neurosci. 2021, 52, 101014. [Google Scholar] [CrossRef]
- Zuo, X.N.; Xu, T.; Milham, M.P. Harnessing reliability for neuroscience research. Nat. Hum. Behav. 2019, 3, 768–771. [Google Scholar] [CrossRef] [PubMed]
- Ferguson, C.J. Is psychological research really as good as medical research? Effect size comparisons between psychology and medicine. Rev. Gen. Psychol. 2009, 13, 130–136. [Google Scholar] [CrossRef]
- Funder, D.C.; Ozer, D.J. Evaluating effect size in psychological research: Sense and nonsense. Adv. Methods Pract. Psychol. Sci. 2019, 2, 156–168. [Google Scholar] [CrossRef]
- Rutledge, T.; Loh, C. Effect sizes and statistical testing in the determination of clinical significance in behavioral medicine research. Ann. Behav. Med. 2004, 27, 138–145. [Google Scholar] [CrossRef] [PubMed]
- Berk, R.A.; Freedman, D.A. Statistical assumptions as empirical commitments. In Punishment and Social Control, 2nd ed.; Bloomberg, T.G., Cohen, S., Eds.; Aldine De Gruyter: Berlin, Germany, 2003; pp. 235–254. Available online: https://escholarship.org/uc/item/0zj8s368 (accessed on 7 August 2024).
- Hoff, P.D. A First Course in Bayesian Statistical Methods; Springer: New York, NY, USA, 2009; Volume 580. [Google Scholar]
- Meeden, G. A Bayesian justification for random sampling in sample survey. Pak. J. Stat. Oper. Res. 2012, 8, 353–357. [Google Scholar] [CrossRef]
- Meier, L. (Ed.) Random and Mixed Effects Models. In ANOVA and Mixed Models: A Short Introduction Using R; CRC Press: Boca Raton, FL, USA, 2022; pp. 119–152. [Google Scholar] [CrossRef]
- Bornstein, M.H.; Jager, J.; Putnick, D.L. Sampling in developmental science: Situations, shortcomings, solutions, and standards. Dev. Rev. 2013, 33, 357–370. [Google Scholar] [CrossRef] [PubMed]
- Oakes, L.M. Sample size, statistical power, and false conclusions in infant looking-time research. Infancy 2017, 22, 436–469. [Google Scholar] [CrossRef] [PubMed]
- Rescorla, L. Late talkers: Do good predictors of outcome exist? Dev. Disabil. Res. Rev. 2011, 17, 141–150. [Google Scholar] [CrossRef] [PubMed]
- Bishop, D.V.; Holt, G.; Line, E.; McDonald, D.; McDonald, S.; Watt, H. Parental phonological memory contributes to prediction of outcome of late talkers from 20 months to 4 years: A longitudinal study of precursors of specific language impairment. J. Neurodev. Disord. 2012, 4, 3. [Google Scholar] [CrossRef] [PubMed]
- Catts, H.W.; Fey, M.E.; Tomblin, J.B.; Zhang, X. A longitudinal investigation of reading outcomes in children with language impairments. J. Speech Lang. Hear. Res. 2002, 45, 1142–1157. [Google Scholar] [CrossRef] [PubMed]
- Conti-Ramsden, G.; Botting, N. Social difficulties and victimization in children with SLI at 11 years of age. J. Speech Lang. Hear. Res. 2004, 47, 145–161. [Google Scholar] [CrossRef] [PubMed]
- Hadley, P.A.; Rice, M.L. Conversational responsiveness of speech-and language-impaired preschoolers. J. Speech Lang. Hear. Res. 1991, 34, 1308–1317. [Google Scholar] [CrossRef]
- Weismer, S.E. Typical talkers, late talkers, and children with specific language impairment: A language endowment spectrum? In Language Disorders from a Developmental Perspective; Psychology Press: London, UK, 2017; pp. 83–101. [Google Scholar]
- Ellis, E.M.; Thal, D.J. Early language delay and risk for language impairment. Perspect. Lang. Learn. Educ. 2008, 15, 93–100. [Google Scholar] [CrossRef]
- Fischel, J.E.; Whitehurst, G.J.; Caulfield, M.B.; DeBaryshe, B. Language growth in children with expressive language delay. Pediatrics 1989, 83, 218–227. [Google Scholar] [CrossRef]
- Girolametto, L.; Wiigs, M.; Smyth, R.; Weitzman, E.; Pearce, P.S. Children with a history of expressive vocabulary delay. Am. J. Speech-Lang. Pathol. 2001, 10, 358–369. [Google Scholar] [CrossRef]
- Paul, R.; Murray, C.; Clancy, K.; Andrews, D. Reading and metaphonological outcomes in late talkers. J. Speech Lang. Hear. Res. 1997, 40, 1037–1047. [Google Scholar] [CrossRef]
- Rescorla, L. Language and reading outcomes to age 9 in late-talking toddlers. J. Speech Lang. Hear. Res. 2002, 45, 360–371. [Google Scholar] [CrossRef] [PubMed]
- Rescorla, L. Age 13 language and reading outcomes in late-talking toddlers. J. Speech Lang. Hear. Res. 2005, 48, 459–472. [Google Scholar] [CrossRef] [PubMed]
- Rescorla, L. Age 17 language and reading outcomes in late-talking toddlers: Support for a dimensional perspective on language delay. J. Speech Lang. Hear. Res. 2009, 52, 16–30. [Google Scholar] [CrossRef] [PubMed]
- Rice, M.L.; Taylor, C.L.; Zubrick, S.R. Language outcomes of 7-year-old children with or without a history of late language emergence at 24 months. J. Speech Lang. Hear. Res. 2008, 51, 394–407. [Google Scholar] [CrossRef]
- Fernald, A.; Marchman, V.A. Individual differences in lexical processing at 18 months predict vocabulary growth in typically developing and late-talking toddlers. Child Dev. 2012, 83, 203–222. [Google Scholar] [CrossRef]
- Fisher, E.L. A systematic review and meta-analysis of predictors of expressive-language outcomes among late talkers. J. Speech Lang. Hear. Res. 2017, 60, 2935–2948. [Google Scholar] [CrossRef]
- Collisson, B.A.; Grela, B.; Spaulding, T.; Rueckl, J.G.; Magnuson, J.S. Individual differences in the shape bias in preschool children with specific language impairment and typical language development: Theoretical and clinical implications. Dev. Sci. 2015, 18, 373–388. [Google Scholar] [CrossRef]
- Colunga, E.; Sims, C.E. Not only size matters: Early-talker and late-talker vocabularies support different word-learning biases in babies and networks. Cogn. Sci. 2017, 41, 73–95. [Google Scholar] [CrossRef] [PubMed]
- Jones, S.S. Late talkers show no shape bias in a novel name extension task. Dev. Sci. 2003, 6, 477–483. [Google Scholar] [CrossRef]
- Jones, S.S.; Smith, L.B. Object name learning and object perception: A deficit in late talkers. J. Child Lang. 2005, 32, 223–240. [Google Scholar] [CrossRef] [PubMed]
- Kucker, S.C.; Samuelson, L.K.; Perry, L.K.; Yoshida, H.; Colunga, E.; Lorenz, M.G.; Smith, L.B. Reproducibility and a unifying explanation: Lessons from the shape bias. Infant Behav. Dev. 2019, 54, 156–165. [Google Scholar] [CrossRef] [PubMed]
- Landau, B.; Smith, L.B.; Jones, S.S. The importance of shape in early lexical learning. Cogn. Dev. 1988, 3, 299–321. [Google Scholar] [CrossRef]
- Perry, L.K.; Samuelson, L.K.; Malloy, L.M.; Schiffer, R.N. Learn locally, think globally: Exemplar variability supports higher-order generalization and word learning. Psychol. Sci. 2010, 21, 1894–1902. [Google Scholar] [CrossRef] [PubMed]
- Samuelson, L.K. Statistical regularities in vocabulary guide language acquisition in connectionist models and 15–20-month-olds. Dev. Psychol. 2002, 38, 1016. [Google Scholar] [CrossRef] [PubMed]
- Smith, L.B.; Jones, S.S.; Landau, B.; Gershkoff-Stowe, L.; Samuelson, L. Object name learning provides on-the-job training for attention. Psychol. Sci. 2002, 13, 13–19. [Google Scholar] [CrossRef] [PubMed]
- Perry, L.K.; Samuelson, L.K. The shape of the vocabulary predicts the shape of the bias. Front. Psychol. 2011, 2, 345. [Google Scholar] [CrossRef]
- Grice, J.W. OOM: Observation Oriented Modeling [Computer Software]. 2024. Available online: https://idiogrid.com/OOM/ (accessed on 7 August 2024).
- Grice, J.W. Observation Oriented Modeling: Analysis of Cause in the Behavioral Sciences; Academic Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Grice, J.W. Drawing inferences from randomization tests. Personal. Individ. Differ. 2021, 179, 110931. [Google Scholar] [CrossRef]
- Harris, R.J. ANOVA: An Analysis of Variance Primer; Peacock Publishers: Itasca, IL, USA, 1994. [Google Scholar]
- Pomper, R.; Saffran, J.R. Familiar object salience affects novel word learning. Child Dev. 2019, 90, e246–e262. [Google Scholar] [CrossRef] [PubMed]
- Samuelson, L.K.; Horst, J.S. Dynamic noun generalization: Moment-to-moment interactions shape children’s naming biases. Infancy 2007, 11, 97–110. [Google Scholar] [CrossRef]
- Horner, R.H.; Carr, E.G.; Halle, J.; McGee, G.; Odom, S.; Wolery, M. The use of single subject research to identify evidence-based practice in special education. Except. Child. 2005, 71, 165–179. [Google Scholar] [CrossRef]
- Kazdin, A.E. Single-Case Research Designs: Methods for Clinical and Applied Settings; Oxford University Press: Oxford, UK, 2011. [Google Scholar]
- McReynolds, L.V.; Kearns, K. Single-Subject Experimental Designs in Communicative Disorders; University Park Press: Baltimore, MD, USA, 1983. [Google Scholar]
- Botting, N.; Faragher, B.; Simkin, Z.; Knox, E.; Conti-Ramsden, G. Predicting Pathways of Specific Language Impairment: What Differentiates Good and Poor Outcome? J. Child Psychol. Psychiatry Allied Discip. 2001, 42, 1013–1020. [Google Scholar] [CrossRef] [PubMed]
- Peterson, N.R.; Pisoni, D.B.; Miyamoto, R.T. Cochlear implants and spoken language processing abilities: Review and assessment of the literature. Restor. Neurol. Neurosci. 2010, 28, 237–250. [Google Scholar] [CrossRef] [PubMed]
- Pisoni, D.B.; Kronenberger, W.G.; Harris, M.S.; Moberly, A.C. Three challenges for future research on cochlear implants. World J. Otorhinolaryngol.-Head Neck Surg. 2017, 3, 240–254. [Google Scholar] [CrossRef] [PubMed]
- Grice, J.W.; Barrett, P.T.; Cota, L.; Taylor, Z.; Felix, C.; Garner, S.; Medellin, E.; Vest, A. Four bad habits of modern psychologists. Behav. Sci. 2017, 7, 53. [Google Scholar] [CrossRef] [PubMed]
- Pérez-Edgar, K.; Vallorani, A.; Buss, K.A.; LoBue, V. Individual differences in infancy research: Letting the baby stand out from the crowd. Infancy 2020, 25, 438–457. [Google Scholar] [CrossRef] [PubMed]
- Grice, J.W.; Craig, D.P.A.; Abramson, C.I. A simple and transparent alternative to repeated measures ANOVA. Sage Open 2015, 5, 1–13. [Google Scholar] [CrossRef]
- Jaeger, T.F. Categorical data analysis: Away from ANOVAs (transformation or not) and towards logit mixed models. J. Mem. Lang. 2008, 59, 434–446. [Google Scholar] [CrossRef]
- Kucker, S.C.; Seidler, E. The timescales of word learning in children with language delays: In-the-moment mapping, retention, and generalization. J. Child Lang. 2023, 50, 245–273. [Google Scholar] [CrossRef] [PubMed]
- Thal, D.J.; Bates, E.; Goodman, J.; Jahn-Samilo, J. Continuity of language abilities: An exploratory study of late-and early-talking toddlers. Dev. Neuropsychol. 1997, 13, 239–273. [Google Scholar] [CrossRef]
- Fidler, F.; Loftus, G.R. Why figures with error bars should replace p values: Some conceptual arguments and empirical demonstrations. Z. Psychol./J. Psychol. 2009, 217, 27–37. [Google Scholar] [CrossRef]
- Tukey, J.W. Exploratory Data Analysis; Addison-Wesley: Reading, MA, USA, 1977; Volume 2, pp. 131–160. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Typically Developing | Late Talking | ||||||
|---|---|---|---|---|---|---|---|
| Case # | Trials | PCC | c-Value | Case # | Trials | PCC | c-Value |
| 1 | 16 | 56.25 | 0.40 | 33 | 16 | 75.00 | 0.04 |
| 2 | 16 | 68.75 | 0.10 | 34 | 16 | 62.50 | 0.23 |
| 3 | 12 | 66.67 | 0.19 | 35 | 16 | 43.75 * | 0.78 |
| 4 | 15 | 40.00 * | 0.85 | 36 | 11 | 36.36 * | 0.89 |
| 5 | 12 | 75.00 | 0.07 | 37 | 16 | 56.25 | 0.40 |
| 6 | 14 | 71.43 | 0.09 | 38 | 16 | 50.00 * | 0.60 |
| 7 | 15 | 73.33 | 0.06 | 39 | 13 | 46.15 * | 0.71 |
| 8 | 16 | 68.75 | 0.10 | 40 | 15 | 60.00 | 0.30 |
| 9 | 14 | 92.86 | 0.001 | 41 | 15 | 33.33 * | 0.94 |
| 10 | 16 | 68.75 | 0.10 | 42 | 12 | 58.33 | 0.38 |
| 11 | 16 | 75.00 | 0.04 | 43 | 15 | 60.00 | 0.30 |
| 12 | 16 | 68.75 | 0.11 | 44 | 16 | 50.00 * | 0.59 |
| 13 | 16 | 75.00 | 0.04 | 45 | 10 | 40.00 * | 0.83 |
| 14 | 16 | 62.50 | 0.22 | 46 | 16 | 93.75 | <0.0001 |
| 15 | 8 | 62.50 | 0.37 | 47 | 13 | 53.85 | 0.49 |
| 16 | 6 | 100.00 | 0.02 | 48 | 14 | 64.29 | 0.21 |
| 17 | 16 | 75.00 | 0.04 | 49 | 16 | 75.00 | 0.04 |
| 18 | 16 | 75.00 | 0.04 | 50 | 16 | 43.75 * | 0.77 |
| 19 | 16 | 62.50 | 0.22 | 51 | 14 | 71.43 | 0.09 |
| 20 | 16 | 68.75 | 0.10 | 52 | 16 | 50.00 * | 0.60 |
| 21 | 13 | 46.15 * | 0.71 | 53 | 6 | 66.67 | 0.34 |
| 22 | 9 | 55.56 | 0.50 | 54 | 11 | 54.55 | 0.50 |
| 23 | 15 | 80.00 | 0.02 | 55 | 13 | 38.46 * | 0.86 |
| 24 | 16 | 56.25 | 0.40 | 56 | 16 | 31.25 * | 0.96 |
| 25 | 16 | 50.00 * | 0.60 | 57 | 16 | 37.50 * | 0.89 |
| 26 | 16 | 93.75 | <0.0001 | 58 | 9 | 77.78 | 0.09 |
| 27 | 16 | 68.75 | 0.10 | 59 | 16 | 75.00 | 0.04 |
| 28 | 14 | 71.43 | 0.09 | 60 | 16 | 68.75 | 0.11 |
| 29 | 16 | 56.25 | 0.41 | 61 | 16 | 50.00 * | 0.60 |
| 30 | 16 | 87.50 | 0.002 | 62 | 16 | 87.50 | 0.002 |
| 31 | 16 | 81.25 | 0.01 | 63 | 16 | 37.50 * | 0.90 |
| 32 | 16 | 81.25 | 0.01 | 64 | 15 | 66.67 | 0.16 |
| Totals | 467 | 69.59 | <0.0001 | Totals | 458 | 56.77 | 0.002 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jones, I.T.; Kucker, S.C.; Perry, L.K.; Grice, J.W. Capturing the Heterogeneity of Word Learners by Analyzing Persons. Behav. Sci. 2024, 14, 708. https://doi.org/10.3390/bs14080708
Jones IT, Kucker SC, Perry LK, Grice JW. Capturing the Heterogeneity of Word Learners by Analyzing Persons. Behavioral Sciences. 2024; 14(8):708. https://doi.org/10.3390/bs14080708
Chicago/Turabian StyleJones, Ian T., Sarah C. Kucker, Lynn K. Perry, and James W. Grice. 2024. "Capturing the Heterogeneity of Word Learners by Analyzing Persons" Behavioral Sciences 14, no. 8: 708. https://doi.org/10.3390/bs14080708
APA StyleJones, I. T., Kucker, S. C., Perry, L. K., & Grice, J. W. (2024). Capturing the Heterogeneity of Word Learners by Analyzing Persons. Behavioral Sciences, 14(8), 708. https://doi.org/10.3390/bs14080708