




Predicting the Risk of Loneliness in Children and Adolescents: A Machine Learning Study


Abstract
1. Introduction
1.1. Risk Factors for Loneliness in Children and Adolescents
1.2. Machine Learning (ML) in Predicting Loneliness
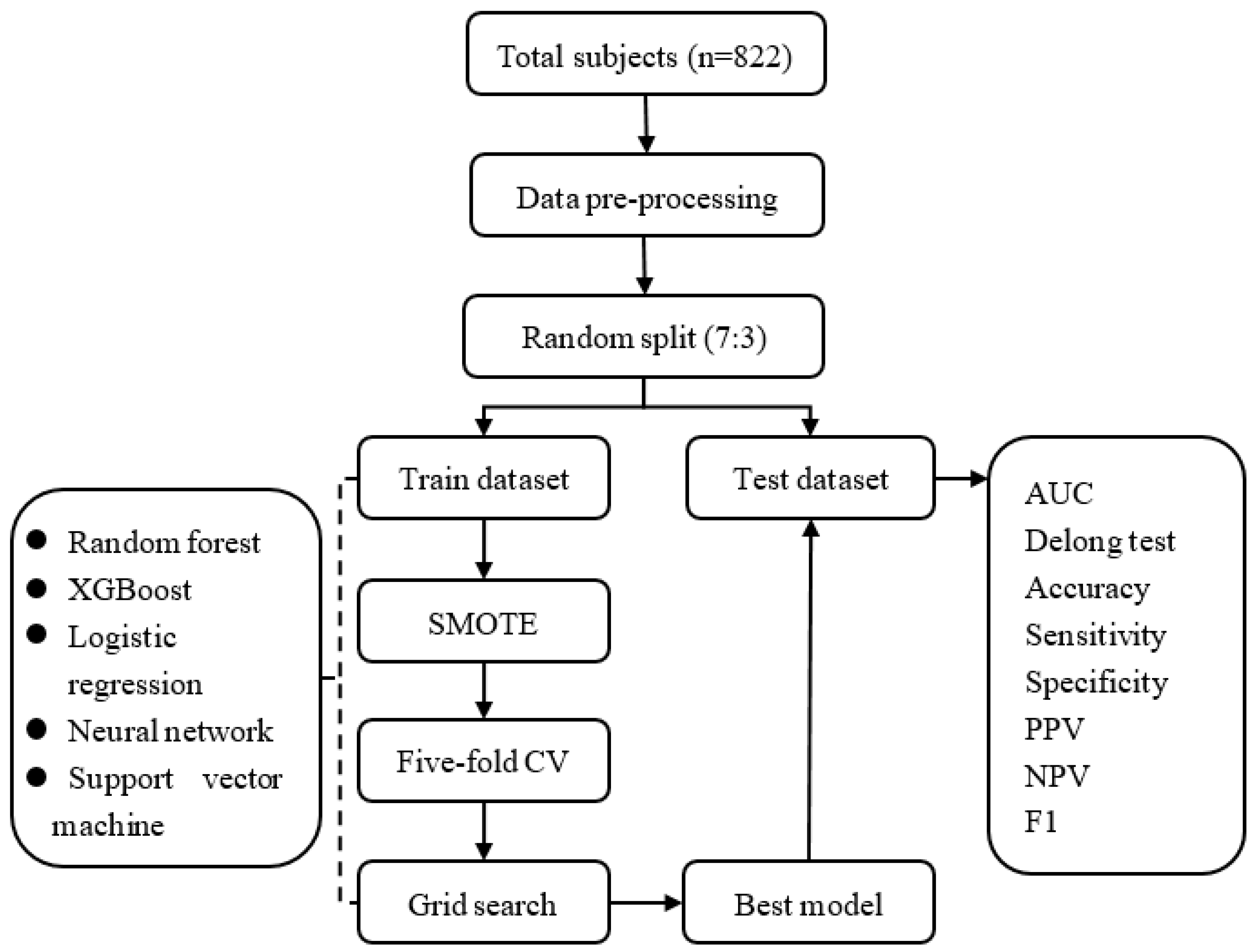
2. Material and Methods
2.1. Data Set and Measures
2.2. Statistical Analysis
2.2.1. Data Pre-Processing
2.2.2. Model Development
2.2.3. Model Evaluation
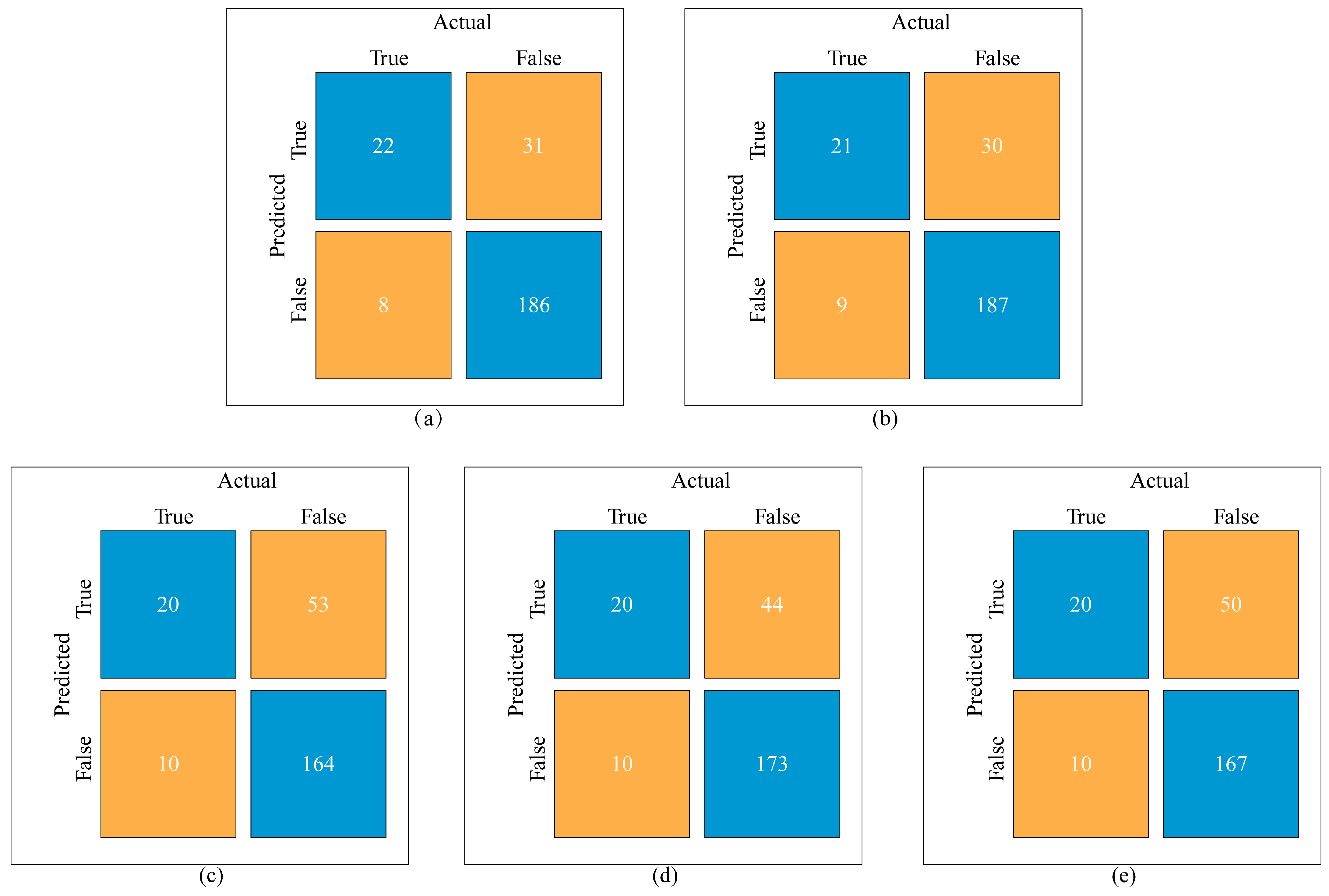
3. Results
3.1. Prediction of Loneliness
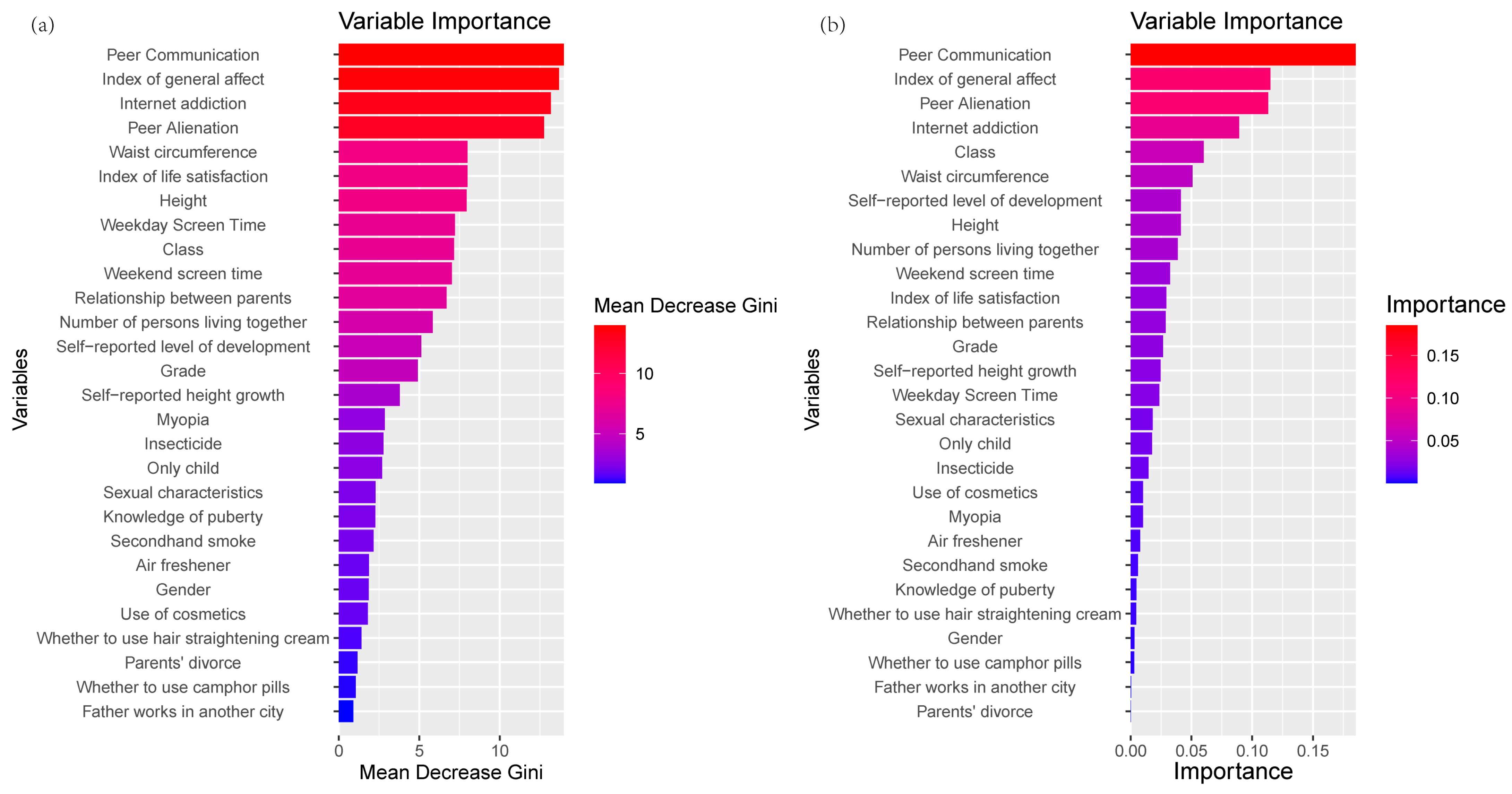
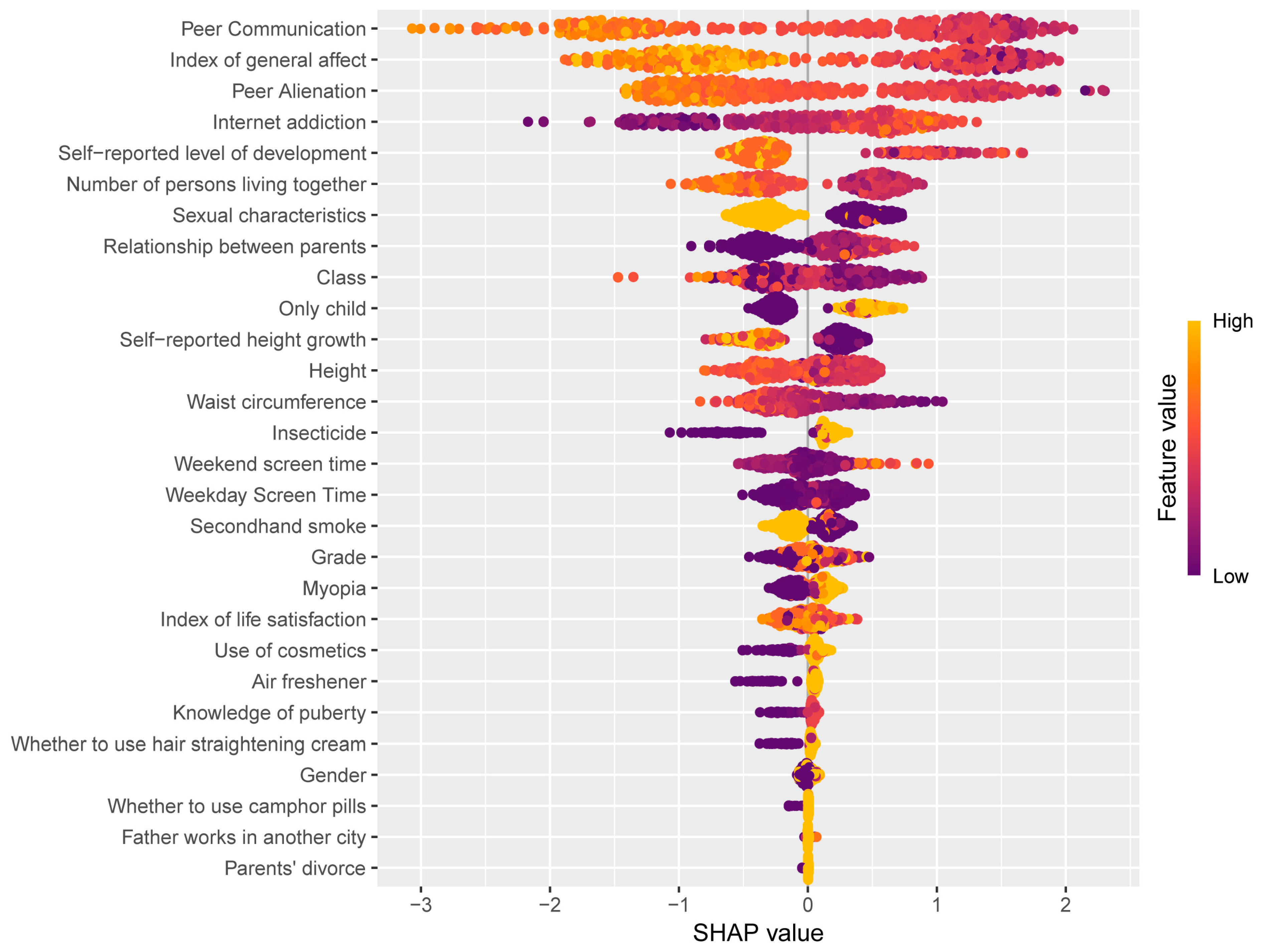
3.2. Important Features
4. Discussion
4.1. Model Performance
4.2. Variable Importance
4.3. Strengths and Limitations
4.4. Future Directions
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ML | machine learning |
| XGBoost | machine learning algorithm extreme gradient boosting |
| RF | random forest |
| CV | cross-validation |
| AUC | area under the receiver operating characteristic curve |
| PPV | positive predictive value |
| NPV | negative predictive value |
References
- Peplau, L.A.; Perlman, D.J.L. Asoct, research, therapy. In Perspectives on Loneliness; John Wiley & Sons: New York, NY, USA, 1982; pp. 1–18. [Google Scholar]
- The, L. Loneliness as a health issue. Lancet 2023, 402, 79. [Google Scholar] [CrossRef]
- Goldman, N.; Khanna, D.; El Asmar, M.L.; Qualter, P.; El-Osta, A. Addressing loneliness and social isolation in 52 countries: A scoping review of National policies. BMC Public Health 2024, 24, 1207. [Google Scholar] [CrossRef] [PubMed]
- Mund, M.; Freuding, M.M.; Möbius, K.; Horn, N.; Neyer, F.J. The Stability and Change of Loneliness Across the Life Span: A Meta-Analysis of Longitudinal Studies. Pers. Soc. Psychol. Rev. 2020, 24, 24–52. [Google Scholar] [CrossRef] [PubMed]
- Surkalim, D.L.; Luo, M.; Eres, R.; Gebel, K.; van Buskirk, J.; Bauman, A.; Ding, D. The prevalence of loneliness across 113 countries: Systematic review and meta-analysis. BMJ Clin. Res. Ed. 2022, 376, e067068. [Google Scholar] [CrossRef] [PubMed]
- Maes, M.; Nelemans, S.A.; Danneel, S.; Fernández-Castilla, B.; Van den Noortgate, W.; Goossens, L.; Vanhalst, J. Loneliness and social anxiety across childhood and adolescence: Multilevel meta-analyses of cross-sectional and longitudinal associations. Dev. Psychol. 2019, 55, 1548–1565. [Google Scholar] [CrossRef] [PubMed]
- Sbarra, D.A.; Ramadan, F.A.; Choi, K.W.; Treur, J.L.; Levey, D.F.; Wootton, R.E.; Stein, M.B.; Gelernter, J.; Klimentidis, Y.C. Loneliness and depression: Bidirectional mendelian randomization analyses using data from three large genome-wide association studies. Mol. Psychiatry 2023, 28, 4594–4601. [Google Scholar] [CrossRef] [PubMed]
- Griffin, S.C.; Williams, A.B.; Ravyts, S.G.; Mladen, S.N.; Rybarczyk, B.D. Loneliness and sleep: A systematic review and meta-analysis. Health Psychol. Open 2020, 7, 2055102920913235. [Google Scholar] [CrossRef]
- Kim, H. The Mediating Effect of Depression on the Relationship between Loneliness and Substance Use in Korean Adolescents. Behav. Sci. 2024, 14, 241. [Google Scholar] [CrossRef]
- Ernst, M.; Brähler, E.; Wild, P.S.; Faber, J.; Merzenich, H.; Beutel, M.E. Loneliness predicts suicidal ideation and anxiety symptoms in long-term childhood cancer survivors. Int. J. Clin. Health Psychol. IJCHP 2021, 21, 100201. [Google Scholar] [CrossRef]
- Vasan, S.; Lim, M.H.; Eikelis, N.; Lambert, E. Investigating the relationship between early cardiovascular disease markers and loneliness in young adults. Sci. Rep. 2024, 14, 14221. [Google Scholar] [CrossRef]
- Bryan, B.T.; Thompson, K.N.; Goldman-Mellor, S.; Moffitt, T.E.; Odgers, C.L.; So, S.L.S.; Uddin Rahman, M.; Wertz, J.; Matthews, T.; Arseneault, L. The socioeconomic consequences of loneliness: Evidence from a nationally representative longitudinal study of young adults. Soc. Sci. Med. 2024, 345, 116697. [Google Scholar] [CrossRef] [PubMed]
- Lyyra, N.; Junttila, N.; Tynjälä, J.; Villberg, J.; Välimaa, R. Loneliness, subjective health complaints, and medicine use among Finnish adolescents 2006–2018. Scand. J. Public Health 2022, 50, 1097–1104. [Google Scholar] [CrossRef] [PubMed]
- O’Sullivan, R.; Leavey, G.; Lawlor, B. We need a public health approach to loneliness. BMJ Clin. Res. Ed. 2022, 376, o280. [Google Scholar] [CrossRef] [PubMed]
- Barjaková, M.; Garnero, A.; d’Hombres, B. Risk factors for loneliness: A literature review. Soc. Sci. Med. 2023, 334, 116163. [Google Scholar] [CrossRef]
- Bowirrat, A.; Elman, I.; Dennen, C.A.; Gondré-Lewis, M.C.; Cadet, J.L.; Khalsa, J.; Baron, D.; Soni, D.; Gold, M.S.; McLaughlin, T.J.; et al. Neurogenetics and Epigenetics of Loneliness. Psychol. Res. Behav. Manag. 2023, 16, 4839–4857. [Google Scholar] [CrossRef]
- Lodder, G.M.A.; Scholte, R.H.J.; Goossens, L.; Verhagen, M. Loneliness in Early Adolescence: Friendship Quantity, Friendship Quality, and Dyadic Processes. J. Clin. Child Adolesc. Psychol. 2017, 46, 709–720. [Google Scholar] [CrossRef]
- Chen, J.; Wang, Q.; Liang, Y.; Chen, B.; Ren, P. Comorbidity of loneliness and social anxiety in adolescents: Bridge symptoms and peer relationships. Soc. Sci. Med. 2023, 334, 116195. [Google Scholar] [CrossRef]
- Allen, J.P.; Porter, M.; McFarland, C.; McElhaney, K.B.; Marsh, P. The relation of attachment security to adolescents’ paternal and peer relationships, depression, and externalizing behavior. Child Dev. 2007, 78, 1222–1239. [Google Scholar] [CrossRef]
- Liu, S.; Zeng, Z.; Qi, Q.; Yang, Q.; Hu, Y. The Effect of Peer Relationships on Adolescent Loneliness: The Role of Psychological Resilience and the OXTR Gene. Psychol. Res. Behav. Manag. 2024, 17, 2477–2489. [Google Scholar] [CrossRef]
- Mozafar Saadati, H.; Mirzaei, H.; Okhovat, B.; Khodamoradi, F. Association between internet addiction and loneliness across the world: A meta-analysis and systematic review. SSM-Popul. Health 2021, 16, 100948. [Google Scholar] [CrossRef]
- Goodfellow, C.; Hardoon, D.; Inchley, J.; Leyland, A.H.; Qualter, P.; Simpson, S.A.; Long, E. Loneliness and personal well-being in young people: Moderating effects of individual, interpersonal, and community factors. J. Adolesc. 2022, 94, 554–568. [Google Scholar] [CrossRef] [PubMed]
- Qualter, P.; Hurley, R.; Eccles, A.; Abbott, J.; Boivin, M.; Tremblay, R. Reciprocal Prospective Relationships Between Loneliness and Weight Status in Late Childhood and Early Adolescence. J. Youth Adolesc. 2018, 47, 1385–1397. [Google Scholar] [CrossRef] [PubMed]
- Dwyer, D.B.; Falkai, P.; Koutsouleris, N. Machine Learning Approaches for Clinical Psychology and Psychiatry. Annu. Rev. Clin. Psychol. 2018, 14, 91–118. [Google Scholar] [CrossRef] [PubMed]
- Shatte, A.B.R.; Hutchinson, D.M.; Teague, S.J. Machine learning in mental health: A scoping review of methods and applications. Psychol. Med. 2019, 49, 1426–1448. [Google Scholar] [CrossRef]
- Hawes, M.T.; Schwartz, H.A.; Son, Y.; Klein, D.N. Predicting adolescent depression and anxiety from multi-wave longitudinal data using machine learning. Psychol. Med. 2023, 53, 6205–6211. [Google Scholar] [CrossRef]
- Su, R.; John, J.R.; Lin, P.I. Machine learning-based prediction for self-harm and suicide attempts in adolescents. Psychiatry Res. 2023, 328, 115446. [Google Scholar] [CrossRef]
- Dwyer, D.; Koutsouleris, N. Annual Research Review: Translational machine learning for child and adolescent psychiatry. J. Child Psychol. Psychiatry 2022, 63, 421–443. [Google Scholar] [CrossRef]
- Guntuku, S.C.; Schneider, R.; Pelullo, A.; Young, J.; Wong, V.; Ungar, L.; Polsky, D.; Volpp, K.G.; Merchant, R. Studying expressions of loneliness in individuals using twitter: An observational study. BMJ Open 2019, 9, e030355. [Google Scholar] [CrossRef]
- Doryab, A.; Villalba, D.K.; Chikersal, P.; Dutcher, J.M.; Tumminia, M.; Liu, X.; Cohen, S.; Creswell, K.; Mankoff, J.; Creswell, J.D.; et al. Identifying Behavioral Phenotypes of Loneliness and Social Isolation with Passive Sensing: Statistical Analysis, Data Mining and Machine Learning of Smartphone and Fitbit Data. JMIR mHealth uHealth 2019, 7, e13209. [Google Scholar] [CrossRef]
- Liu, S.; Liu, Q.; Ostbye, T.; Story, M.; Deng, X.; Chen, Y.; Li, W.; Wang, H.; Qiu, J.; Zhang, J. Levels and risk factors for urinary metabolites of polycyclic aromatic hydrocarbons in children living in Chongqing, China. Sci. Total Environ. 2017, 598, 553–561. [Google Scholar] [CrossRef]
- Asher, S.R.; Hymel, S.; Renshaw, P.D. Loneliness in children. Child Dev. 1984, 55, 1456–1464. [Google Scholar] [CrossRef]
- Cole, A.; Bond, C.; Qualter, P.; Maes, M. A Systematic Review of the Development and Psychometric Properties of Loneliness Measures for Children and Adolescents. Int. J. Environ. Res. Public Health 2021, 18, 3285. [Google Scholar] [CrossRef] [PubMed]
- Cronbach, L.J. Coefficient alpha and the internal structure of tests. Psychometrika 1951, 16, 297–334. [Google Scholar] [CrossRef]
- Armsden, G.C.; Greenberg, M.T. The inventory of parent and peer attachment: Individual differences and their relationship to psychological well-being in adolescence. J. Youth Adolesc. 1987, 16, 427–454. [Google Scholar] [CrossRef] [PubMed]
- Campbell, A. Subjective measures of well-being. Am. Psychol. 1976, 31, 117. [Google Scholar] [CrossRef]
- Young, K.S. Caught in the Net: How to Recognize the Signs of Internet Addiction—And a Winning Strategy for Recovery; John Wiley & Sons, Inc.: New York, NY, USA, 1998. [Google Scholar]
- Efthimiou, O.; Seo, M.; Chalkou, K.; Debray, T.; Egger, M.; Salanti, G. Developing clinical prediction models: A step-by-step guide. BMJ Clin. Res. Ed. 2024, 386, e078276. [Google Scholar] [CrossRef]
- Chawla, N.V.; Lazarevic, A.; Hall, L.O.; Bowyer, K.W. SMOTEBoost: Improving Prediction of the Minority Class in Boosting. In Proceedings of the European Conference on Knowledge Discovery in Databases: Pkdd. 7th European Conference on Principles and Practice of Knowledge Discovery in Databases, Cavtat-Dubrovnik, Croatia, 22–26 September 2003. [Google Scholar]
- Zhong, M.; Zhang, H.; Yu, C.; Jiang, J.; Duan, X. Application of machine learning in predicting the risk of postpartum depression: A systematic review. J. Affect. Disord. 2022, 318, 364–379. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2013; Volume 112. [Google Scholar]
- Probst, P.; Wright, M.N.; Boulesteix, A.-L. Hyperparameters and tuning strategies for random forest. WIREs Data Min. Knowl. Discov. 2019, 9, e1301. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Martinez-Taboada, F.; Redondo, J.I. Variable importance plot (mean decrease accuracy and mean decrease Gini). PLoS ONE 2020, 15, e0230799. [Google Scholar]
- Lundberg, S.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Lam, J.A.; Murray, E.R.; Yu, K.E.; Ramsey, M.; Nguyen, T.T.; Mishra, J.; Martis, B.; Thomas, M.L.; Lee, E.E. Neurobiology of loneliness: A systematic review. Neuropsychopharmacology 2021, 46, 1873–1887. [Google Scholar] [CrossRef] [PubMed]
- Igami, K.; Hosozawa, M.; Ikeda, A.; Bann, D.; Shimizu, T.; Iso, H. Adolescent Loneliness in 70 Countries Across Africa, America, and Asia: A Comparison of Prevalence and Correlates. J. Adolesc. Health 2023, 72, 906–913. [Google Scholar] [CrossRef] [PubMed]
- Zavlis, O.; Matheou, A.; Bentall, R. Identifying the bridge between depression and mania: A machine learning and network approach to bipolar disorder. Bipolar Disord. 2023, 25, 571–582. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Zhang, Y.; Lu, T.; Liang, R.; Wu, Z.; Liu, M.; Qin, L.; Chen, H.; Yan, X.; Deng, S.; et al. Identification of diagnostic genes for both Alzheimer’s disease and Metabolic syndrome by the machine learning algorithm. Front. Immunol. 2022, 13, 1037318. [Google Scholar] [CrossRef]
- Haque, U.M.; Kabir, E.; Khanam, R. Early detection of paediatric and adolescent obsessive-compulsive, separation anxiety and attention deficit hyperactivity disorder using machine learning algorithms. Health Inf. Sci. Syst. 2023, 11, 31. [Google Scholar] [CrossRef]
- Ghavidel, A.; Pazos, P. Machine learning (ML) techniques to predict breast cancer in imbalanced datasets: A systematic review. J. Cancer Surviv. 2023, 1–25. [Google Scholar] [CrossRef]
- Han, Y.; Wei, Z.; Huang, G. An imbalance data quality monitoring based on SMOTE-XGBOOST supported by edge computing. Sci. Rep. 2024, 14, 10151. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.; Cho, J.K.; Park, J.; Lee, H.; Fond, G.; Boyer, L.; Kim, H.J.; Park, S.; Cho, W.; Lee, H.; et al. Machine Learning-Based Prediction of Suicidality in Adolescents With Allergic Rhinitis: Derivation and Validation in 2 Independent Nationwide Cohorts. J. Med. Internet Res. 2024, 26, e51473. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.C.; Zhou, Z.; Tang, Q.; Yu, P.; Zou, H.; Liu, Q.; Wang, X.Q.; Jiang, J.; Zhou, Y.; Liu, L.; et al. Prediction of non-suicidal self-injury in adolescents at the family level using regression methods and machine learning. J. Affect. Disord. 2024, 352, 67–75. [Google Scholar] [CrossRef] [PubMed]
- van Mens, K.; de Schepper, C.; Wijnen, B.; Koldijk, S.J.; Schnack, H.; de Looff, P.; Lokkerbol, J.; Wetherall, K.; Cleare, S.; O’Connor, R.C.; et al. Predicting future suicidal behaviour in young adults, with different machine learning techniques: A population-based longitudinal study. J. Affect. Disord. 2020, 271, 169–177. [Google Scholar] [CrossRef]
- Walsh, C.G.; Ribeiro, J.D.; Franklin, J.C. Predicting suicide attempts in adolescents with longitudinal clinical data and machine learning. J. Child Psychol. Psychiatry 2018, 59, 1261–1270. [Google Scholar] [CrossRef]
- Corke, M.; Mullin, K.; Angel-Scott, H.; Xia, S.; Large, M. Meta-analysis of the strength of exploratory suicide prediction models; from clinicians to computers. BJPsych Open 2021, 7, e26. [Google Scholar] [CrossRef]
- Wang, J.; Ouyang, H.; Jiao, R.; Cheng, S.; Zhang, H.; Shang, Z.; Jia, Y.; Yan, W.; Wu, L.; Liu, W. The application of machine learning techniques in posttraumatic stress disorder: A systematic review and meta-analysis. NPJ Digit. Med. 2024, 7, 121. [Google Scholar] [CrossRef]
- Zimmerman, M. Positive Predictive Value: A Clinician’s Guide to Avoid Misinterpreting the Results of Screening Tests. J. Clin. Psychiatry 2022, 83, 22com14513. [Google Scholar] [CrossRef]
- Monaghan, T.F.; Rahman, S.N.; Agudelo, C.W.; Wein, A.J.; Lazar, J.M.; Everaert, K.; Dmochowski, R.R. Foundational Statistical Principles in Medical Research: Sensitivity, Specificity, Positive Predictive Value, and Negative Predictive Value. Medicina 2021, 57, 503. [Google Scholar] [CrossRef]
- Cassidy, J.; Asher, S.R. Loneliness and peer relations in young children. Child Dev. 1992, 63, 350–365. [Google Scholar] [CrossRef]
- Schwartz-Mette, R.A.; Shankman, J.; Dueweke, A.R.; Borowski, S.; Rose, A.J. Relations of friendship experiences with depressive symptoms and loneliness in childhood and adolescence: A meta-analytic review. Psychol. Bull. 2020, 146, 664–700. [Google Scholar] [CrossRef] [PubMed]
- Chiao, C.; Lin, K.C.; Chyu, L. Perceived Peer Relationships in Adolescence and Loneliness in Emerging Adulthood and Workplace Contexts. Front. Psychol. 2022, 13, 794826. [Google Scholar] [CrossRef] [PubMed]
- Hong, J.H.; Yeh, C.S.; Sandy, L.G.; Fellows, A.; Martin, D.C.; Shaeffer, J.A.; Tkatch, R.; Parker, K.; Kim, E.S. Friendship and Loneliness: A Prototype Roadmap for Health System Action. Am. J. Prev. Med. 2022, 63, 141–145. [Google Scholar] [CrossRef] [PubMed]
- Cotten, S.R.; Anderson, W.A.; McCullough, B.M. Impact of internet use on loneliness and contact with others among older adults: Cross-sectional analysis. J. Med. Internet Res. 2013, 15, e39. [Google Scholar] [CrossRef] [PubMed]
- Nogueira-López, A.; Rial-Boubeta, A.; Guadix-García, I.; Villanueva-Blasco, V.J.; Billieux, J. Prevalence of problematic Internet use and problematic gaming in Spanish adolescents. Psychiatry Res. 2023, 326, 115317. [Google Scholar] [CrossRef]
- Zhang, S.; Tian, Y.; Sui, Y.; Zhang, D.; Shi, J.; Wang, P.; Meng, W.; Si, Y. Relationships Between Social Support, Loneliness, and Internet Addiction in Chinese Postsecondary Students: A Longitudinal Cross-Lagged Analysis. Front. Psychol. 2018, 9, 1707. [Google Scholar] [CrossRef]
- VanderWeele, T.J.; Hawkley, L.C.; Cacioppo, J.T. On the reciprocal association between loneliness and subjective well-being. Am. J. Epidemiol. 2012, 176, 777–784. [Google Scholar] [CrossRef] [PubMed]
- Barreto, M.; Victor, C.; Hammond, C.; Eccles, A.; Richins, M.T.; Qualter, P. Loneliness around the world: Age, gender, and cultural differences in loneliness. Personal. Individ. Differ. 2021, 169, 110066. [Google Scholar] [CrossRef]
- Rodriguez, M.; Osborn, T.L.; Gan, J.Y.; Weisz, J.R.; Bellet, B.W. Loneliness in Kenyan adolescents: Socio-cultural factors and network association with depression and anxiety symptoms. Transcult. Psychiatry 2022, 59, 797–809. [Google Scholar] [CrossRef]
- van Staden, W.C.; Coetzee, K. Conceptual relations between loneliness and culture. Curr. Opin. Psychiatry 2010, 23, 524–529. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | Total, n (%) (N = 822) | Loneliness, n (%) (N = 109) | No loneliness, n (%) (N = 713) |
|---|---|---|---|
| Age (mean (SD)) | 13.52 (1.14) | 13.78 (1.23) | 13.48 (1.13) |
| Gender | |||
| Male | 385 (46.84) | 57 (52.29) | 328 (46.00) |
| Female | 437 (53.16) | 52 (47.71) | 385 (54.00) |
| Grade | |||
| 7 | 234 (28.47) | 30 (27.52) | 204 (28.61) |
| 8 | 244 (29.68) | 25 (22.94) | 219 (30.72) |
| 9 | 220 (26.76) | 23 (21.10) | 197 (27.63) |
| 10 | 124 (15.09) | 31 (28.44) | 93 (13.04) |
| Relationship between parents | |||
| Excellent | 457 (55.60) | 38 (34.86) | 419 (58.77) |
| Good | 223 (27.13) | 29 (26.61) | 194 (27.21) |
| Average | 115 (13.99) | 32 (29.36) | 83 (11.64) |
| Not very good | 21 (2.55) | 8 (7.34) | 13 (1.82) |
| Poor | 6 (0.73) | 2 (1.83) | 4 (0.56) |
| Only child (n = 821) | |||
| Yes | 284 (34.59) | 45 (41.28) | 239 (33.57) |
| No | 537 (65.41) | 64.(58.72) | 473. (66.43) |
| Weekday screen time (minutes, Mean (SD), n = 821) | 100.38 (257.13) | 127.95 (224.65) | 96.16 (261.63) |
| Weekend screen time (minutes, Mean (SD), n = 820) | 180.29 (195.88) | 223.96 (233.42) | 173.67 (188.85) |
| Father death (n = 821) | |||
| Yes | 10 (1.22) | 2 (1.85) | 8 (1.12) |
| No | 811 (98.78) | 106 (98.15) | 705 (98.88) |
| Mother death (n = 821) | |||
| Yes | 3 (0.37) | 0 (0.00) | 3 (0.42) |
| No | 818 (99.63) | 108 (100) | 710 (99.58) |
| Parents’ divorce (n = 821) | |||
| Yes | 74 (9.01) | 13 (12.04) | 61 (8.56) |
| No | 747 (90.99) | 95 (87.96) | 652 (91.44) |
| Father works in another city (n = 820) | |||
| Yes | 67 (8.17) | 9 (8.33) | 58 (8.15) |
| No | 753 (91.83) | 99 (91.67) | 654 (91.85) |
| Mother works in another city (n = 820) | |||
| Yes | 20 (2.44) | 4 (3.70) | 16 (2.25) |
| No | 800 (97.56) | 104 (96.30) | 696 (97.75) |
| Number of persons living together | |||
| 0 | 1 (0.12) | 0 (0.00) | 1 (0.14) |
| 1 | 47 (5.72) | 9 (8.26) | 38 (5.33) |
| 2 | 291 (35.40) | 41 (37.61) | 250 (35.06) |
| 3 | 292 (35.52) | 38 (34.86) | 254 (35.62) |
| 4 | 133 (16.18) | 11 (10.09) | 122 (17.11) |
| 5 | 50 (6.08) | 9 (8.26) | 41 (5.75) |
| 6 | 7 (0.85) | 1 (0.92) | 6 (0.84) |
| 7 | 1 (0.12) | 0 (0.00) | 1 (0.14) |
| Secondhand smoke | |||
| Yes | 433 (52.68) | 59 (54.13) | 374 (52.45) |
| No | 389 (73.32) | 50 (45.87) | 339 (47.55) |
| Myopia (n = 821) | |||
| No myopia | 339 (41.29) | 50 (45.87) | 289 (40.59) |
| Myopia in the left eye | 29 (3.53) | 3 (2.75) | 26 (3.65) |
| Myopia in the right eye | 43 (5.24) | 6 (5.50) | 37 (5.20) |
| Myopia in both eyes | 410 (49.94) | 50 (45.87) | 360 (50.56) |
| Height (mean (SD)) | 160.16 (7.86) | 159.89 (7.09) | 160.19 (7.96) |
| Weight (mean (SD)) | 53.59 (12.47) | 53.79 (13.38) | 53.56 (12.36) |
| Waist circumference (mean (SD)) | 72.59 (9.85) | 72.05 (10.34) | 72.66 (9.79) |
| Hip circumference (mean (SD)) | 87.62 (8.82) | 87.20 (9.52) | 87.67 (8.73) |
| Sexual characteristics | |||
| Yes | 524 (63.75) | 55 (50.46) | 469 (65.78) |
| No | 298 (36.25) | 54 (49.54) | 244 (34.22) |
| Peer trust (mean (SD), n = 816) | 36.84 (7.09) | 30.97 (7.52) | 37.73 (6.58) |
| Peer communication (mean (SD), n = 820) | 27.55 (6.24) | 22.35 (5.88) | 28.35 (5.91) |
| Peer alienation (mean (SD), n = 810) | 24.55 (4.37) | 21.48 (4.28) | 25.03 (4.19) |
| Internet addiction (mean (SD), n = 804) | 42.73 (13.23) | 51.48 (14.38) | 41.37 (12.51) |
| Index of general affect (mean (SD), n = 820) | 42.01 (12.05) | 31.99 (12.70) | 43.55 (11.18) |
| Index of life satisfaction (mean (SD), n = 821) | 5.44 (1.51) | 4.46 (1.75) | 5.58 (1.42) |
| Classifier | Description |
|---|---|
| Random forest [43] | Random forest generates a diversified set of decision trees by randomly picking features and bootstrap aggregating (bagging). The ultimate forecast is generated by averaging or voting on each tree projections. |
| XGBoost [44] | XGBoost is a gradient boosting method that creates a powerful prediction model by combining weak learners (decision trees). It optimizes the objective function by adding new weak learners repeatedly that focus on the residual mistakes of prior models. |
| Logistic regression [45] | Logistic regression evaluates the likelihood of an event occurring depending on input factors. Maximum likelihood estimation is used by the model to learn the appropriate weights for the input characteristics. |
| Neural network [46] | Neural networks are a collection of artificial neurons that are interconnected to replicate the structure and function of the human brain. They are made up of three layers, input, hidden, and output, with each neuron executing a weighted sum of inputs followed by an activation function. |
| Support vector machine [47] | Support vector machine creates a hyperplane or a series of hyperplanes to optimize the margin between various classes, aiming for the greatest separation possible. |
| Classifier | Caret Label | R Package | Tuned Hyperparameters |
|---|---|---|---|
| Random forest | rf | randomForest | mtry |
| XGBoost | xgbTree | xgboost | nrounds, max_depth, eta, gamma, colsample_bytree, min_child_weight, subsample |
| Logistic regression | glm | glmnet | |
| Neural network | nnet | nnet | size, decay |
| Support vector machine | svmRadial | Kernlab | σ, C |
| Classifier | AUC (95%CI) | p Value a | Accuracy (95%CI) | Sensitivity | Specificity | PPV | NPV | F1 |
|---|---|---|---|---|---|---|---|---|
| Random forest | 0.85 (0.77, 0.92) | 0.14 | 0.84 (0.79, 0.89) | 0.73 | 0.86 | 0.42 | 0.96 | 0.53 |
| XGBoost | 0.87 (0.80, 0.93) | 0.05 | 0.84 (0.79, 0.89) | 0.70 | 0.86 | 0.41 | 0.95 | 0.52 |
| Logistic regression | 0.80 (0.70, 0.89) | Ref | 0.74 (0.69, 0.80) | 0.67 | 0.76 | 0.27 | 0.94 | 0.39 |
| Neural network | 0.80 (0.71, 0.89) | 0.93 | 0.78 (0.72, 0.83) | 0.67 | 0.80 | 0.31 | 0.95 | 0.43 |
| Support vector machine | 0.79 (0.79, 0.89) | 0.83 | 0.76 (0.70, 0.81) | 0.67 | 0.77 | 0.29 | 0.94 | 0.40 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Feng, X.; Wang, W.; Liu, S.; Zhang, Q.; Wu, D.; Liu, Q. Predicting the Risk of Loneliness in Children and Adolescents: A Machine Learning Study. Behav. Sci. 2024, 14, 947. https://doi.org/10.3390/bs14100947
Zhang J, Feng X, Wang W, Liu S, Zhang Q, Wu D, Liu Q. Predicting the Risk of Loneliness in Children and Adolescents: A Machine Learning Study. Behavioral Sciences. 2024; 14(10):947. https://doi.org/10.3390/bs14100947
Chicago/Turabian StyleZhang, Jie, Xinyi Feng, Wenhe Wang, Shudan Liu, Qin Zhang, Di Wu, and Qin Liu. 2024. "Predicting the Risk of Loneliness in Children and Adolescents: A Machine Learning Study" Behavioral Sciences 14, no. 10: 947. https://doi.org/10.3390/bs14100947
APA StyleZhang, J., Feng, X., Wang, W., Liu, S., Zhang, Q., Wu, D., & Liu, Q. (2024). Predicting the Risk of Loneliness in Children and Adolescents: A Machine Learning Study. Behavioral Sciences, 14(10), 947. https://doi.org/10.3390/bs14100947