
The Acquisition of /ɪ/–/iː/ Is Challenging: Perceptual and Production Evidence from Cypriot Greek Speakers of English


Abstract
:1. Introduction
2. Formulation of Predictions
3. The Perceptual Study
3.1. Methodology
3.1.1. Participants
3.1.2. Stimuli
3.1.3. Procedure
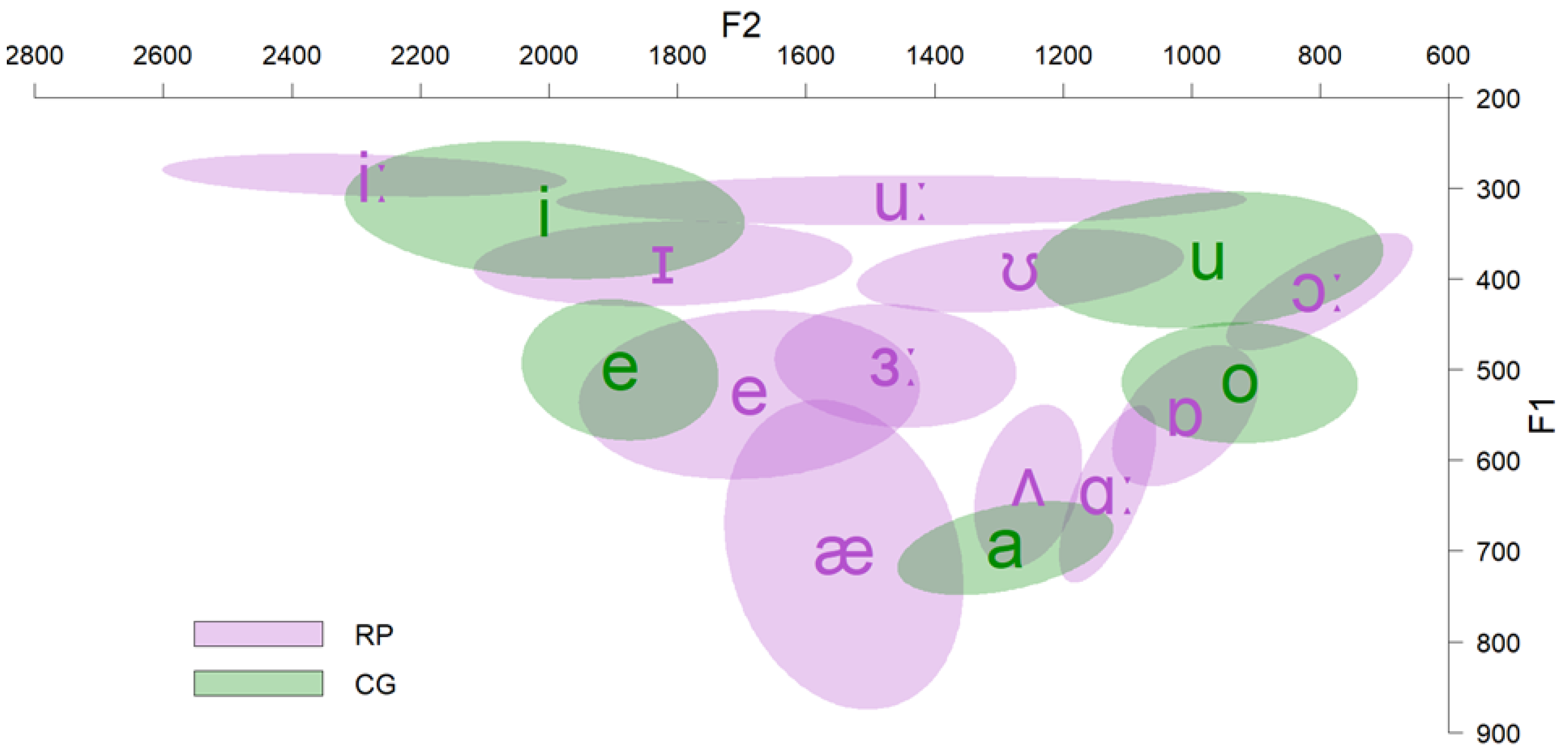
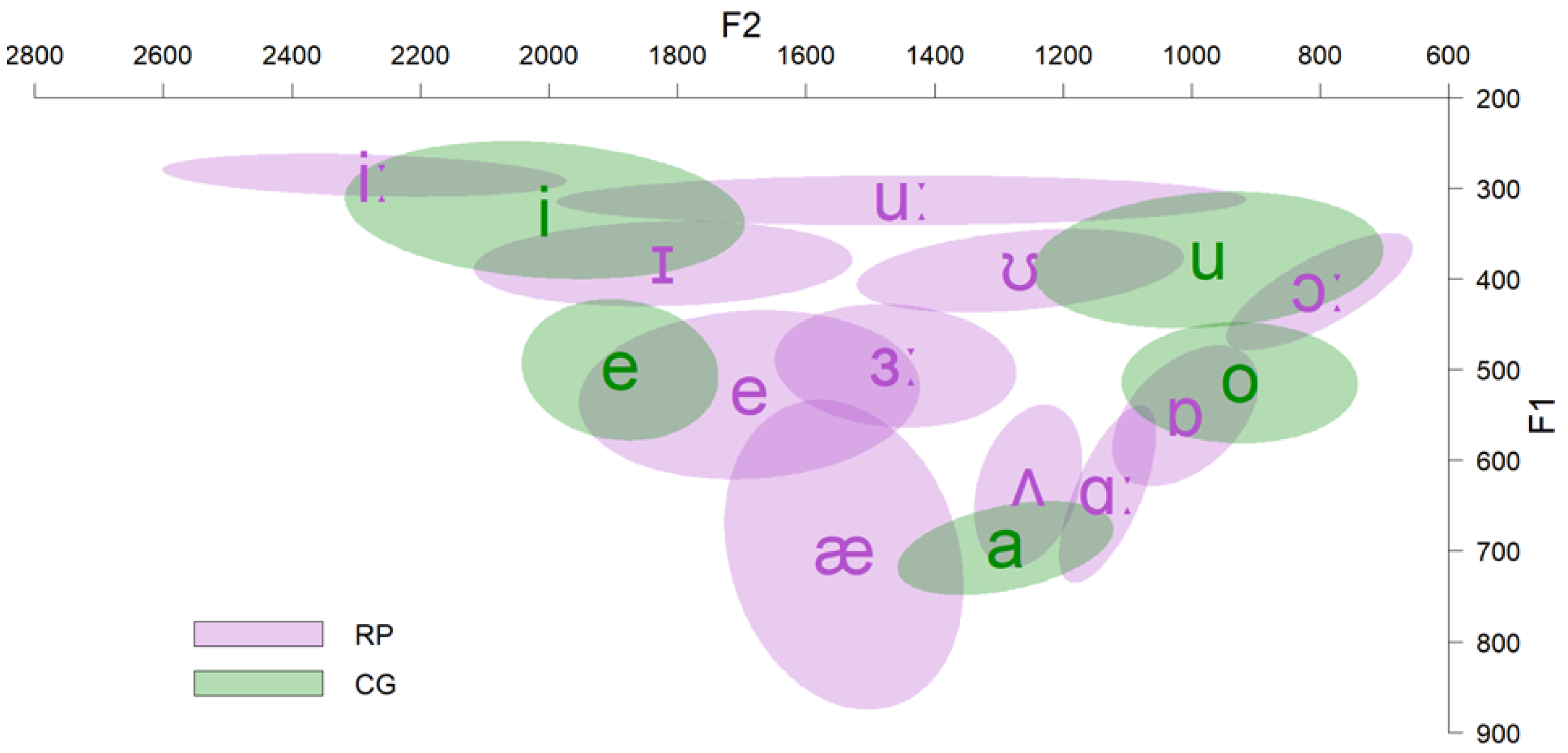
3.2. Results
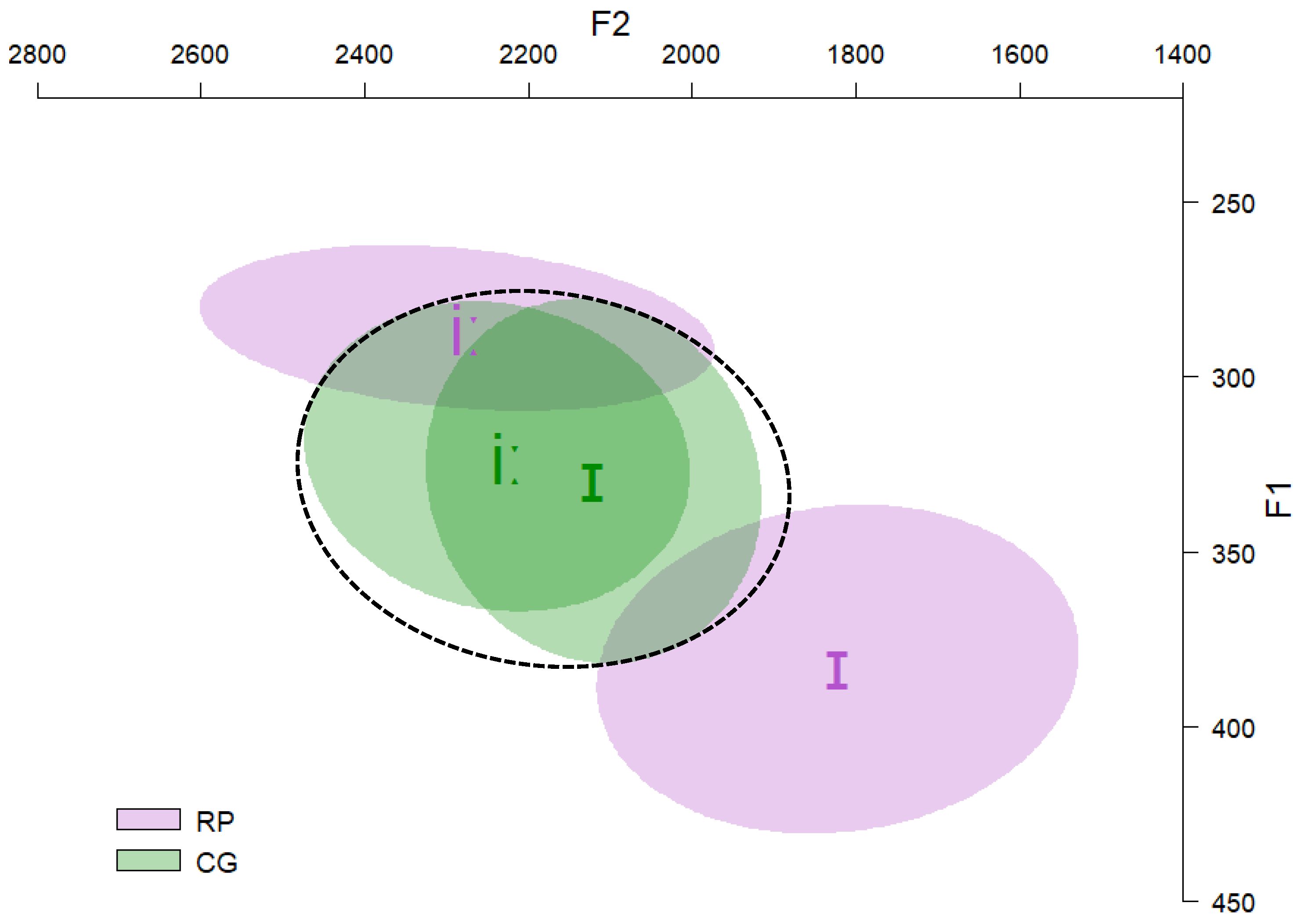
3.2.1. Classification Test
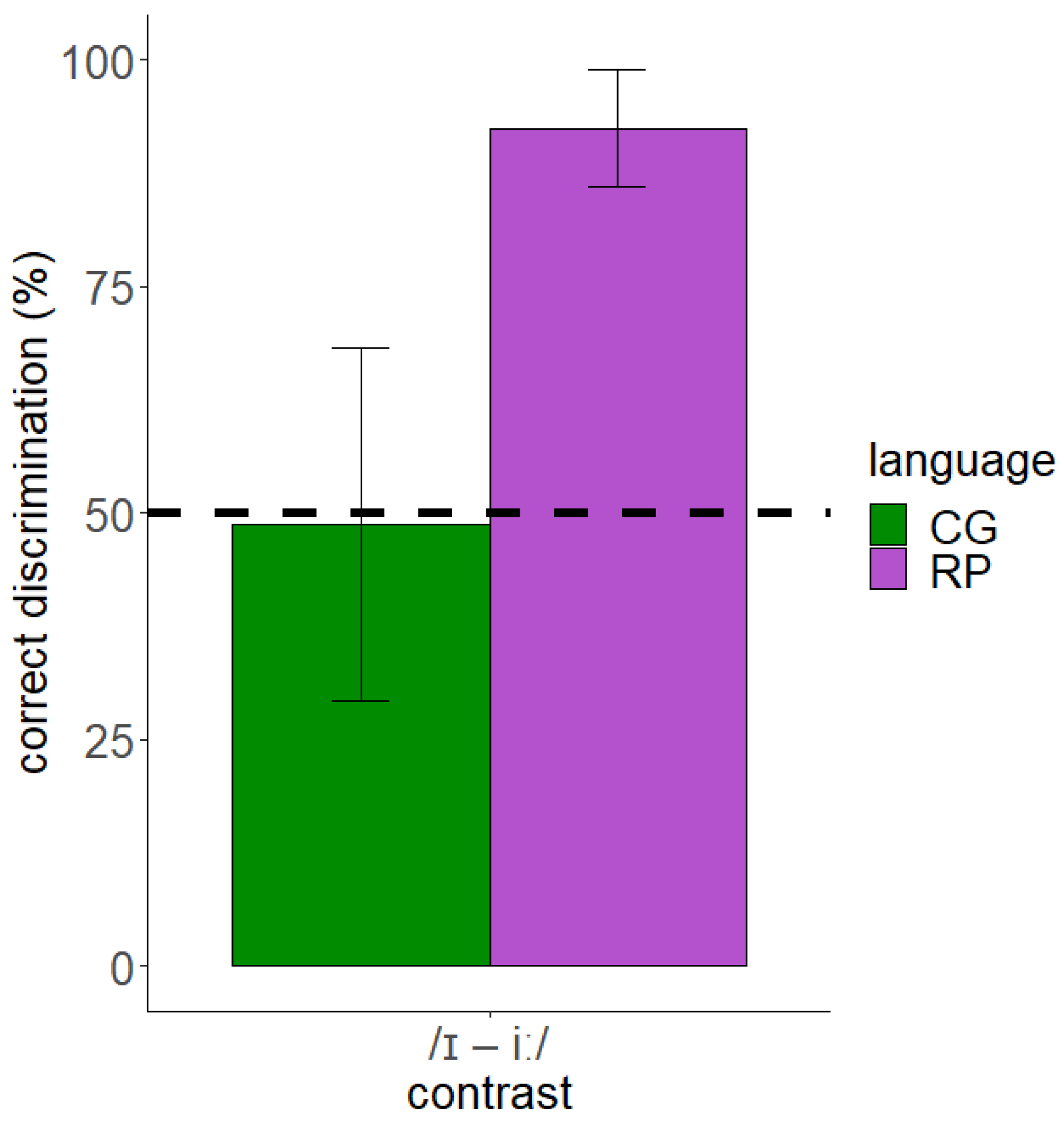
3.2.2. Discrimination Test
4. The Production Study
4.1. Methodology
4.1.1. Participants
4.1.2. Stimuli
4.1.3. Procedure
4.1.4. Acoustic Analysis
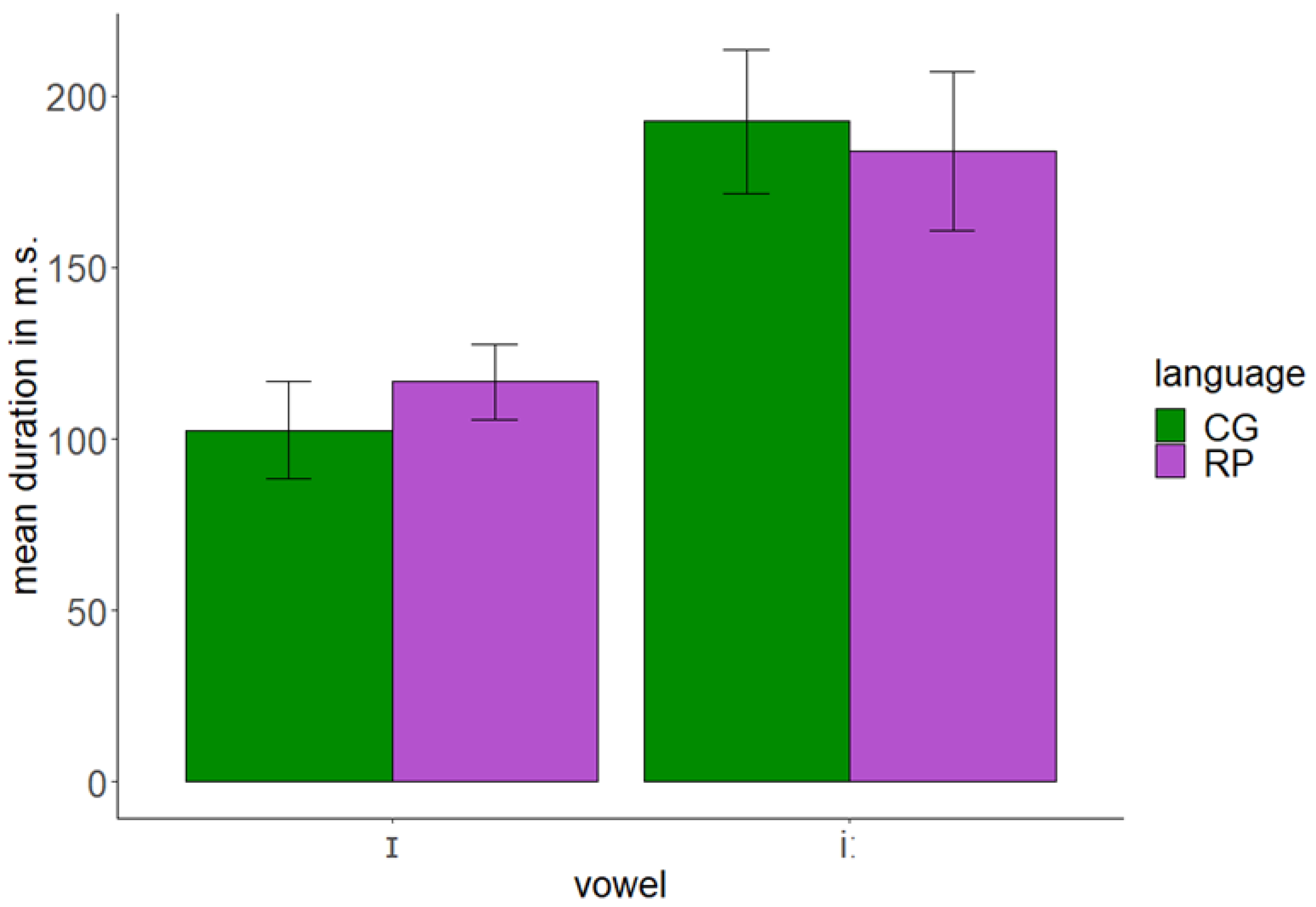
4.2. Results
5. Discussion
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Baigorri, M.; Campanelli, L.; Levy, E.S. Perception of American–English Vowels by Early and Late Spanish–English Bilinguals. Lang. Speech 2019, 62, 681–700. [Google Scholar] [CrossRef]
- Desmeules-Trudel, F.; Joanisse, M.F. Discrimination of four Canadian-French vowels by native Canadian-English listeners. J. Acoust. Soc. Am. 2020, 147, EL391–EL395. [Google Scholar] [CrossRef]
- Georgiou, G.P. Discrimination of Uncategorized-Categorized and Uncategorized-Uncategorized Greek consonantal contrasts by Russian speakers. Top. Linguist. 2020, 21, 74–82. [Google Scholar] [CrossRef]
- Georgiou, G.P.; Perfilieva, N.; Tenizi, M. Vocabulary size leads to a better attunement to L2 phonetic differences: Clues from Russian learners of English. Lang. Learn. Dev. 2020, 16, 382–398. [Google Scholar] [CrossRef]
- Georgiou, G.P.; Perfilieva, N.; Denisenko, V.; Novospasskaya, N. Perceptual realization of Greek consonants by Russian monolingual speakers. Speech Commun. 2020, 125, 7–14. [Google Scholar] [CrossRef]
- Inceoglu, S. Language Experience and Subjective Word Familiarity on the Multimodal Perception of Non-native Vowels. Lang. Speech 2022, 65, 173–192. [Google Scholar] [CrossRef]
- Lee, S.; Cho, M. The impact of L2-learning experience and target dialect on predicting English vowel identification using Korean vowel categories. J. Phon. 2020, 82, 100983. [Google Scholar] [CrossRef]
- Rato, A.; Carlet, A. Second language perception of English vowels by Portuguese learners: The effect of stimulus type. Ilha Do Desterro J. Engl. Lang. Lit. Engl. Cult. Stud. 2020, 73, 205–226. [Google Scholar] [CrossRef]
- Shafer, V.L.; Kresh, S.; Ito, K.; Hisagi, M.; Vidal, N.; Higby, E.; Castillo, D.; Strange, W. The neural timecourse of American English vowel discrimination by Japanese, Russian and Spanish second-language learners of English. Biling. Lang. Cogn. 2021, 24, 642–655. [Google Scholar] [CrossRef]
- Iverson, P.; Kuhl, P.K.; Akahane-Yamada, R.; Diesch, E.; Tohkura, Y.; Kettermann, A.; Siebert, C. A perceptual interference account of acquisition difficulties for non-native phonemes. Cognition 2003, 87, B47–B57. [Google Scholar] [CrossRef]
- Flege, J.E.; Bohn, O.S.; Jang, S. The production and perception of English vowels by native speakers of German, Korean, Mandarin, and Spanish. J. Phon. 1997, 25, 437–470. [Google Scholar] [CrossRef] [Green Version]
- Flege, J.E.; MacKay, I.R.A.; Meador, D. Native Italian speakers’ perception and production of English vowels. J. Acoust. Soc. Am. 1999, 106, 2973–2987. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rochet, B.L. Perception and production of second-language speech sounds by adults. In Speech Perception and Linguistic Experience: Issues in Cross-Language Research; Strange, W., Ed.; York Press: Baltimore, MD, USA, 1995; pp. 379–410. [Google Scholar]
- Bongaerts, T. Ultimate attainment in L2 pronunciation: The case of very advanced late learners. In Second Language Acquisition and the Critical Period Hypothesis; Birdsong, D., Ed.; LEA: Mahwah, NJ, USA; pp. 133–160.
- Flege, J.E.; Munro, M.; Mackay, I.R.A. Effects of age of second-language learning on the production of English consonants. Speech Commun. 1995, 16, 1–26. [Google Scholar] [CrossRef]
- Flege, J.E.; Birdsong, D.; Bialystok, E.; Mack, M.; Sung, H.; Tsukada, K. Degree of foreign accent in English sentences produced by Korean children and adults. J. Phon. 2006, 34, 153–175. [Google Scholar] [CrossRef]
- Georgiou, G. Effects of Phonetic Training on the Discrimination of Second Language Sounds by Learners with Naturalistic Access to the Second Language. J. Psycholinguist. Res. 2021, 50, 707–721. [Google Scholar] [CrossRef] [PubMed]
- Georgiou, G.P.; Themistocleous, C. Vowel learning in diglossic settings: Evidence from Arabic-Greek learners. Int. J. Biling. 2020, 25, 135–150. [Google Scholar] [CrossRef]
- Bohn, O.S.; Munro, M.J. (Eds.) Language Experience in second Language Speech Learning: In honor of James Emil Flege; John Benjamins Publishing: Amsterdam, The Netherlands, 2007; Volume 17. [Google Scholar]
- Strange, W. (Ed.) Speech Perception and Linguistic Experience: Issues in Cross-Language Research; York Press: Baltimore, MD, USA, 1995. [Google Scholar]
- Hacquard, V.; Walter, M.A.; Marantz, A. The effects of inventory on vowel perception in French and Spanish: An MEG study. Brain Lang. 2007, 100, 295–300. [Google Scholar] [CrossRef]
- Iverson, P.; Evans, B.G. Learning English vowels with different first-language vowel systems: Perception of formant targets, formant movement, and duration. J. Acoust. Soc. Am. 2007, 122, 2842–2854. [Google Scholar] [CrossRef]
- Souza, H.K.D.; Carlet, A.; Jułkowska, I.A.; Rato, A. Vowel inventory size matters: Assessing cue-weighting in L2 vowel perception. Ilha Do Desterro J. Engl. Lang. Lit. Engl. Cult. Stud. 2017, 70, 33–46. [Google Scholar] [CrossRef]
- Alispahic, S.; Mulak, K.E.; Escudero, P. Acoustic Properties Predict Perception of Unfamiliar Dutch Vowels by Adult Australian English and Peruvian Spanish Listeners. Front. Psychol. 2017, 8, 52. [Google Scholar] [CrossRef] [PubMed]
- Elvin, J.; Escudero, P.; Vasiliev, P. Spanish is better than English for discriminating Portuguese vowels: Acoustic similarity versus vowel inventory size. Front. Psychol. 2014, 5, 1188. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Flege, J.E. Second language speech learning: Theory, findings and problems. In Speech Perception and Linguistic Experience: Theoretical and Methodological Issues; Strange, W., Ed.; York Press: Baltimore, MD, USA, 1995; pp. 233–277. [Google Scholar]
- Flege, J.E.; Bohn, O.S. The revised speech learning model (SLM-r). In Second Language Speech Learning: Theoretical and Empirical Progress; Cambridge University Press: Cambridge, UK, 2021; pp. 3–83. [Google Scholar]
- Best, C.T. A direct realist view of cross-language speech perception: New Directions in Research and Theory. In Speech Perception and Linguistic Experience: Theoretical and Methodological Issues; Strange, W., Ed.; York Press: Baltimore, MD, USA, 1995; pp. 171–204. [Google Scholar]
- Best, C.T.; Tyler, M. Non-native and second-language speech perception: Commonalities and complementarities. In Second Language Speech Learning: In honor of James Emil Flege; Bohn, O.-S., Munro, M.J., Eds.; John Benjamins: Amsterdam, The Netherlands; Philadelphia, PA, USA, 2007; pp. 13–34. [Google Scholar]
- Escudero, P. Linguistic perception of “similar” L2 sounds. In Phonology in Perception; Boersma, P., Hamann, S., Eds.; Mouton de Gruyter: Berlin, Germany, 2009; pp. 151–190. [Google Scholar]
- Georgiou, G.P. Toward a new model for speech perception: The Universal Perceptual Model (UPM) of second language. Cogn. Proc. 2021, 22, 277–289. [Google Scholar] [CrossRef] [PubMed]
- Georgiou, G.P.; Giannakou, A.; Alexander, K. Perception of L2 phonetic contrasts by monolinguals and bidialectals: A comparison of competencies. Int. J. Biling. 2022, 20. [Google Scholar]
- Georgiou, G.P. ‘Bit’ and ‘beat’ are heard as the same: Mapping the vowel perceptual patterns of Greek-English bilingual children. Lang. Sci. 2019, 72, 1–12. [Google Scholar] [CrossRef]
- Morrison, G.S. L1-Spanish Speakers’ Acquisition of the English/i/—/I/Contrast: Duration-based perception is not the initial developmental stage. Lang. Speech 2009, 51, 285–315. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Shi, F.; Liu, X.; Zhao, Y. Learning styles and perceptual patterns for English /i/ and /ɪ/ among Chinese college students. Appl. Psycholinguist. 2015, 37, 673–701. [Google Scholar] [CrossRef]
- Cebrian, J. Experience and the use of non-native duration in L2 vowel categorization. J. Phon. 2006, 34, 372–387. [Google Scholar] [CrossRef]
- Fullana Rivera, N.; MacKay, I.R. Production of English sounds by EFL learners: The case of /i/and/i. In Proceedings of the 15th International Congress of Phonetic Sciences, Barcelona, Spain, 3–9 August 2003; pp. 1525–1528. [Google Scholar]
- Strange, W.; Bohn, O.-S.; Nishi, K.; Trent, S.A. Contextual variation in the acoustic and perceptual similarity of North German and American English vowels. J. Acoust. Soc. Am. 2005, 118, 1751–1762. [Google Scholar] [CrossRef]
- Llompart, M.; Reinisch, E. Imitation in a Second Language Relies on Phonological Categories but Does Not Reflect the Productive Usage of Difficult Sound Contrasts. Lang. Speech 2018, 62, 594–622. [Google Scholar] [CrossRef]
- Liberman, A.M.; Mattingly, I.G. The motor theory of speech perception revised. Cognition 1985, 21, 1–36. [Google Scholar] [CrossRef]
- Liberman, A.M.; Mattingly, I.G. A specialization for speech perception. Science 1989, 245, 489–494. [Google Scholar] [CrossRef]
- Fowler, C.A. An event approach to the study of speech perception from a direct-realist perspective. J. Phon. 1986, 14, 3–28. [Google Scholar] [CrossRef]
- Bradlow, A.R.; Pisoni, D.B.; Yamada, R.A.; Tohkura, Y. Training Japanese listeners to identify English /r/and/l/: IV. Some effects of perceptual learning on speech production. J. Acoust. Soc. Am. 1997, 101, 2299–2310. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Georgiou, G.P. Interplay between perceived cross-linguistic similarity and L2 production: Analyzing the L2 vowel patterns of bilinguals. J. Second. Lang. Stud. 2021, 4, 48–65. [Google Scholar] [CrossRef]
- Georgiou, G.P. The impact of auditory perceptual training on the perception and production of English vowels by Cypriot Greek children and adults. Lang. Learn. Dev. 2022, 18, 379–392. [Google Scholar] [CrossRef]
- Iverson, P.; Pinet, M.; Evans, B.G. Auditory training for experienced and inexperienced second-language learners: Native French speakers learning English vowels. Appl. Psycholinguist. 2011, 33, 145–160. [Google Scholar] [CrossRef]
- Lopez-Soto, T.; Kewley-Port, D. Relation of perception training to production of codas in English as a second language. Proc. Meet. Acoust. 2009, 6, 062003. [Google Scholar]
- Klecka, W.R. Discriminant Analysis, Quantitative Applications in the Social Sciences; Sage: Newbury Park, CA, USA, 1980; Volume 19. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022; Available online: https://www.R-project.org/ (accessed on 14 September 2022).
- Ripley, B.; Venables, B.; Bates, D.M.; Hornik, K.; Gebhardt, A.; Firth, D.; Ripley, M.B. Package ‘Mass’; Cran R, 2022. [Google Scholar]
- Gilichinskaya, Y.D.; Strange, W. Perceptual assimilation of American English vowels by naïve Russian listeners. J. Acoust. Soc. Am. 2010, 128, EL80–EL85. [Google Scholar] [CrossRef] [Green Version]
- Elvin, J.; Williams, D.; Shaw, J.A.; Best, C.T.; Escudero, P. The Role of Acoustic Similarity and Non-Native Categorisation in Predicting Non-Native Discrimination: Brazilian Portuguese Vowels by English vs. Spanish Listeners. Languages 2021, 6, 44. [Google Scholar] [CrossRef]
- Boersma, P.; Weenink, D. Praat: Doing Phonetics by Computer [Computer Program]. 2022. Available online: http://www.fon.hum.uva.nl/praat/ (accessed on 14 September 2022).
- Georgiou, G.P. How Do Speakers of a Language with a Transparent Orthographic System Perceive the L2 Vowels of a Language with an Opaque Orthographic System? An Analysis through a Battery of Behavioral Tests. Languages 2021, 6, 118. [Google Scholar] [CrossRef]
- Bürkner, P.C. brms: An R package for Bayesian multilevel models using Stan. J. Stat. Softw. 2017, 80, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Gelman, A.; Hwang, J.; Vehtari, A. Understanding predictive information criteria for Bayesian models. Stat. Comp. 2014, 24, 997–1016. [Google Scholar] [CrossRef]
- Gelman, A.; Lee, D.; Guo, J. Stan: A probabilistic programming language for Bayesian inference and optimization. J. Educ. Behav. Stat. 2015, 40, 530–543. [Google Scholar] [CrossRef] [Green Version]
- Jeffreys, H. Theory of Probability, 3rd ed.; Oxford University Press: Oxford, UK, 1961. [Google Scholar]
- Georgiou, G.P. Acoustic markers of vowels produced with different types of face masks. Appl. Acoust. 2022, 191, 108691. [Google Scholar] [CrossRef] [PubMed]
- Kendall, T.; Thomas, E.R.; Kendall, M.T. Package ‘Vowels’ [R Package]; Cran R, 2018. [Google Scholar]
- Oller, C.E.C. Características acústicas de las vocales altas anteriores del inglés. Estud. Fonética Exp. 1997, 8, 127–152. [Google Scholar]
- Flege, J.E. The Interlingual Identification of Spanish and English Vowels: Orthographic Evidence. Q. J. Exp. Psychol. Sect. A 1991, 43, 701–731. [Google Scholar] [CrossRef]
- Faris, M.M.; Best, C.T.; Tyler, M.D. An examination of the different ways that non-native phones may be perceptually assimilated as uncategorized. J. Acoust. Soc. Am. 2016, 139, EL1–EL5. [Google Scholar] [CrossRef] [Green Version]
- Faris, M.M.; Best, C.T.; Tyler, M.D. Discrimination of uncategorised non-native vowel contrasts is modulated by perceived overlap with native phonological categories. J. Phon. 2018, 70, 1–19. [Google Scholar] [CrossRef]
- Levy, E.S. Language experience and consonantal context effects on perceptual assimilation of French vowels by American-English learners of French. J. Acoust. Soc. Am. 2009, 125, 1138–1152. [Google Scholar] [CrossRef] [Green Version]
- Escudero, P.; Boersma, P. Bridging the gap between L2 speech perception research and phonological theory. Stud. Second Lang. Acquis. 2004, 26, 551–585. [Google Scholar] [CrossRef]
- Morrison, G.S. Effects of L1 Duration Experience on Japanese and Spanish Listeners’ Perception of English High Front Vowels; Simon Fraser University: Burnaby, BC, Canada, 2002. [Google Scholar]
- Escudero, P. Developmental Patterns in the Adult L2 Acquisition of New Contrasts: The Acoustic Cue Weighting in the Perception of Scottish Tense/Lax Vowels by Spanish Speakers. Ph.D. Thesis, University of Edinburgh, Edinburgh, UK, 2000. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vowel | Duration (m.s.) | SD |
|---|---|---|
| /i/ | 111 | 10.2 |
| /e/ | 129 | 11.1 |
| /a/ | 146 | 15.6 |
| /o/ | 143 | 12 |
| /u/ | 124 | 15.8 |
| Vowel | Duration (m.s.) | SD |
|---|---|---|
| /ɪ/ | 117 | 11.1 |
| /iː/ | 184 | 23.2 |
| /e/ | 135 | 11.5 |
| /ɜː/ | 201 | 10.1 |
| /æ/ | 163 | 15.8 |
| /ɑː/ | 215 | 6.5 |
| /ʌ/ | 127 | 10.7 |
| /ɒ/ | 129 | 9.7 |
| /ɔː/ | 206 | 13.3 |
| /ʊ/ | 191 | 26.1 |
| /uː/ | 117 | 14.8 |
| Vowels | CG | |||||
|---|---|---|---|---|---|---|
| i | e | a | o | u | ||
| RP | ɪ | 0.80 | 0.20 | |||
| iː | 1.00 | |||||
| Vowels | CG | |||||
|---|---|---|---|---|---|---|
| i | e | a | o | u | ||
| RP | ɪ | 0.86 | 0.14 | |||
| iː | 0.98 | 0.02 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Georgiou, G.P. The Acquisition of /ɪ/–/iː/ Is Challenging: Perceptual and Production Evidence from Cypriot Greek Speakers of English. Behav. Sci. 2022, 12, 469. https://doi.org/10.3390/bs12120469
Georgiou GP. The Acquisition of /ɪ/–/iː/ Is Challenging: Perceptual and Production Evidence from Cypriot Greek Speakers of English. Behavioral Sciences. 2022; 12(12):469. https://doi.org/10.3390/bs12120469
Chicago/Turabian StyleGeorgiou, Georgios P. 2022. "The Acquisition of /ɪ/–/iː/ Is Challenging: Perceptual and Production Evidence from Cypriot Greek Speakers of English" Behavioral Sciences 12, no. 12: 469. https://doi.org/10.3390/bs12120469
APA StyleGeorgiou, G. P. (2022). The Acquisition of /ɪ/–/iː/ Is Challenging: Perceptual and Production Evidence from Cypriot Greek Speakers of English. Behavioral Sciences, 12(12), 469. https://doi.org/10.3390/bs12120469