Better to Be Alone than in Bad Company: Cognate Synonyms Impair Word Learning



Abstract
1. Introduction
2. Materials and Methods
2.1. Participants
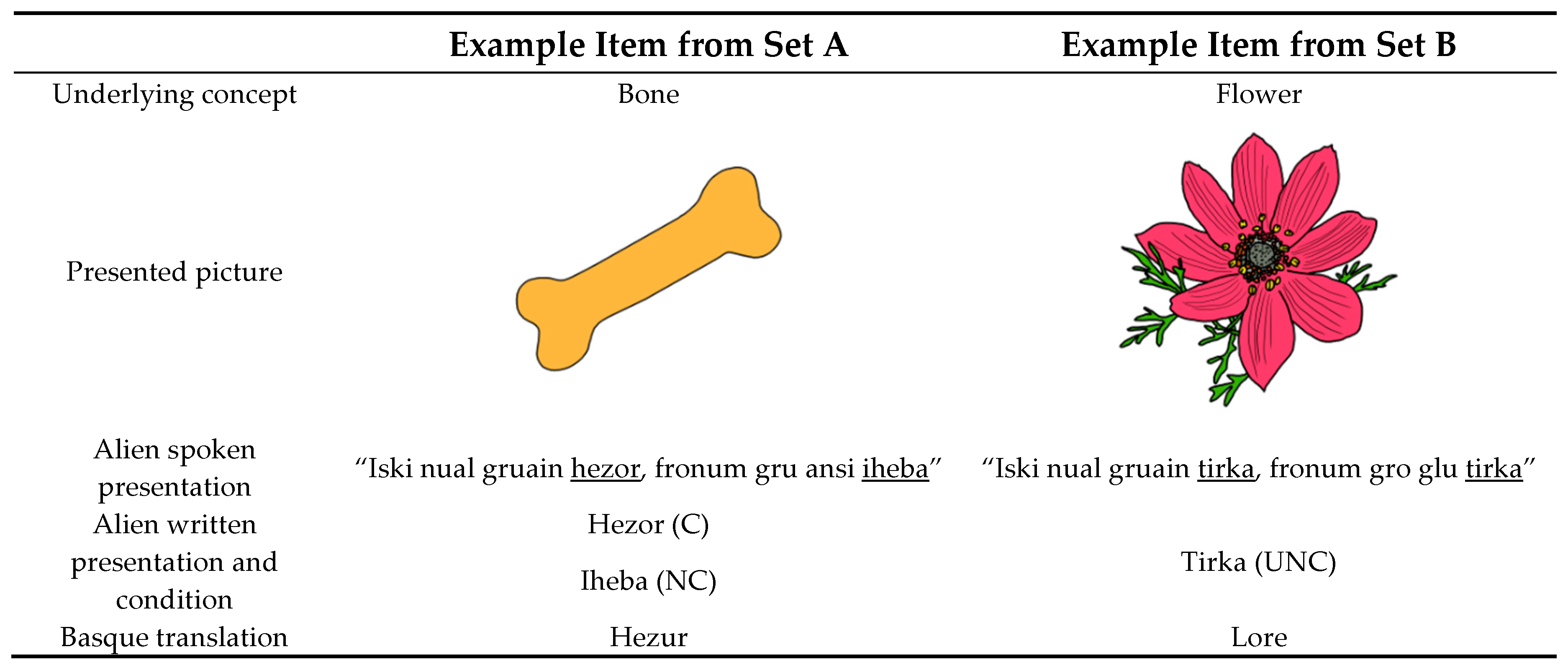
2.2. Materials
2.3. Procedure
- “Iski nual gruain tirka, fronum gro glu tirka”.(“What you see here is called tirka, we call it tirka”).
- “Iski nual gruain hezor, fronum gru ansi iheba”.(“What you see here is called hezor, and we also call it iheba”).
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
| SET A | SET B | |||||||
|---|---|---|---|---|---|---|---|---|
| Concept | Basque Word | Associated Picture | C | NC | Concept | Basque Word | Associated Picture | UNC |
| bird | txori | PICTURE_430 | txor | redal | hair | ile | PICTURE_102 | artune |
| dog | txakur | PICTURE_707 | txakuroz | krogo | table | mahai | PICTURE_110 | flobor |
| root | sustrai | PICTURE_245 | sustraioz | muno | beard | bizar | PICTURE_159 | tipu |
| pencil | arkatz | PICTURE_654 | arkatzoz | glapa | head | buru | PICTURE_182 | edupe |
| river | ibai | PICTURE_86 | ibaiu | fluti | wheel | gurpil | PICTURE_2 | lula |
| blackboard | arbel | PICTURE_402 | arbelu | bleti | stone | harri | PICTURE_279 | plaglo |
| bone | hezur | PICTURE_24 | hezor | iheba | flower | lore | PICTURE_312 | tirka |
| apple | sagar | PICTURE_552 | sigar | tadru | fish | arrain | PICTURE_324 | gribe |
| lip | ezpain | PICTURE_513 | ezpainoz | furron | coin | txanpon | PICTURE_383 | bluna |
| key | giltza | PICTURE_78 | giltzu | astes | snow | elur | PICTURE_390 | baru |
| branch | adar | PICTURE_536 | adaru | udigo | teacher | maisu | PICTURE_434 | debrati |
| walnut | intxaur | PICTURE_119 | intxauroz | burtiko | box | kutxa | PICTURE_508 | truplo |
| finger | behatz | PICTURE_408 | behat | kamut | cloud | hodei | PICTURE_599 | plobo |
| bed | ohe | PICTURE_268 | oheu | troka | honey | ezti | PICTURE_610 | tupuk |
| cheese | gazta | PICTURE_72 | gazt | oilop | barrel | kupel | PICTURE_630 | gasi |
| bridge | zubi | PICTURE_178 | zubiu | serta | thief | lapur | PICTURE_631 | ripeda |
| hammer | mailu | PICTURE_216 | meilu | betome | bee | erle | PICTURE_672 | ibima |
| house | etxe | PICTURE_522 | etxa | gufal | trousers | galtza | PICTURE_718 | aban |
| chair | aulki | PICTURE_122 | aulk | freba | heart | bihotz | PICTURE_83 | gafo |
| leaf | hosto | PICTURE_318 | host | tlobo | milk | esne | PICTURE_96 | utepa |
References
- Beekes, R.S.P. Comparative Indo-European Linguistics: An Introduction, 2nd ed.; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2011; ISBN 9789027285003. [Google Scholar]
- Hock, H.H.; Joseph, B.D. Language History, Language Change, and Language Relationship; Trends in Linguistics. Studies and Monographs [TiLSM]; Mouton de Gruyter: Berlin, Germany; New York, NY, USA, 2009; ISBN 9783110214307. [Google Scholar]
- Jarvis, S. Lexical transfer. In The Bilingual Mental Lexicon: Interdisciplinary Approaches; Multilingual Matters: Bristol, UK, 2009; pp. 99–124. [Google Scholar]
- Friel, B.M.; Kennison, S.M. Identifying German–English cognates, false cognates, and non-cognates: Methodological issues and descriptive norms. Biling. Lang. Cogn. 2001, 4, 249–274. [Google Scholar] [CrossRef]
- Casaponsa, A.; Antón, E.; Pérez, A.; Duñabeitia, J.A. Foreign language comprehension achievement: Insights from the cognate facilitation effect. Front. Psychol. 2015, 6, 588. [Google Scholar] [CrossRef]
- Lijewska, A. Cognate Processing Effects in Bilingual Lexical Access. In Bilingual Lexical Ambiguity Resolution; Cambridge University Press: Cambridge, UK, 2020; pp. 71–95. [Google Scholar]
- De Groot, A.M.B. Word-Type Effects in Bilingual Processing Tasks. In The Bilingual Lexicon; John Benjamins Publishing Company: Amsterdam, The Netherlands, 1993; pp. 27–51. [Google Scholar]
- Duñabeitia, J.A.; Perea, M.; Carreiras, M. Masked Translation Priming Effects With Highly Proficient Simultaneous Bilinguals. Exp. Psychol. 2010, 57, 98–107. [Google Scholar] [CrossRef] [PubMed]
- Duñabeitia, J.A.; Ivaz, L.; Casaponsa, A. Developmental changes associated with cross-language similarity in bilingual children. J. Cogn. Psychol. 2016, 28, 16–31. [Google Scholar] [CrossRef]
- Schwartz, A.I.; Kroll, J.F. Bilingual lexical activation in sentence context. J. Mem. Lang. 2006, 55, 197–212. [Google Scholar] [CrossRef]
- Jacobs, A.; Fricke, M.; Kroll, J.F. Cross-Language Activation Begins during Speech Planning and Extends into Second Language Speech. Lang. Learn. 2016, 66, 324–353. [Google Scholar] [CrossRef]
- Dijkstra, T.; Grainger, J.; Van Heuven, W.J.B. Recognition of Cognates and Interlingual Homographs: The Neglected Role of Phonology. J. Mem. Lang. 1999, 41, 496–518. [Google Scholar] [CrossRef]
- Lemhöfer, K.; Dijkstra, T.; Schriefers, H.; Baayen, R.H.; Grainger, J.; Zwitserlood, P. Native Language Influences on Word Recognition in a Second Language: A Megastudy. J. Exp. Psychol. Learn. Mem. Cogn. 2008, 34, 12–31. [Google Scholar] [CrossRef]
- Mulder, K.; Dijkstra, T.; Schreuder, R.; Baayen, H.R. Effects of primary and secondary morphological family size in monolingual and bilingual word processing. J. Mem. Lang. 2014, 72, 59–84. [Google Scholar] [CrossRef]
- Comesaña, M.; Bertin, P.; Oliveira, H.; Soares, A.P.; Hernández-Cabrera, J.A.; Casalis, S. The impact of cognateness of word bases and suffixes on morpho-orthographic processing: A masked priming study with intermediate and high-proficiency Portuguese-English bilinguals. PLoS ONE 2018, 13, e0193480. [Google Scholar] [CrossRef]
- Lemhöfer, K.; Dijkstra, T.; Michel, M.C. Three languages, one ECHO: Cognate effects in trilingual word recognition. Lang. Cogn. Process. 2004, 19, 585–611. [Google Scholar] [CrossRef]
- Dijkstra, T.; Van Heuven, W.J.B. The BIA model and bilingual word recognition. In Localist Connectionist Approaches to Human Cognition; Scientific Psychology Series; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 1998; pp. 189–225. [Google Scholar]
- Dijkstra, T.; Miwa, K.; Brummelhuis, B.; Sappelli, M.; Baayen, H. How cross-language similarity and task demands affect cognate recognition. J. Mem. Lang. 2010, 62, 284–301. [Google Scholar] [CrossRef]
- Dijkstra, T.; van Heuven, W.J.B. The architecture of the bilingual word recognition system: From identification to decision. Biling. Lang. Cogn. 2002, 5, 175–197. [Google Scholar] [CrossRef]
- Casaponsa, A.; Thierry, G.; Duñabeitia, J.A. The Role of Orthotactics in Language Switching: An ERP Investigation Using Masked Language Priming. Brain Sci. 2019, 10, 22. [Google Scholar] [CrossRef]
- Casaponsa, A.; Duñabeitia, J.A. Lexical organization of language-ambiguous and language-specific words in bilinguals. Q. J. Exp. Psychol. 2016, 69, 589–604. [Google Scholar] [CrossRef]
- De Bot, K. A bilingual production model: Levelt’s’ speaking’model adapted. Appl. Linguist. 1992, 13, 1–24. [Google Scholar]
- Costa, A.; Miozzo, M.; Caramazza, A. Lexical Selection in Bilinguals: Do Words in the Bilingual’s Two Lexicons Compete for Selection? J. Mem. Lang. 1999, 41, 365–397. [Google Scholar] [CrossRef]
- Kroll, J.F.; Stewart, E. Category Interference in Translation and Picture Naming: Evidence for Asymmetric Connections Between Bilingual Memory Representations. J. Mem. Lang. 1994, 33, 149–174. [Google Scholar] [CrossRef]
- Poulisse, N.; Bongaerts, T. First language use in second language production. Appl. Linguist. 1994, 15, 36–57. [Google Scholar] [CrossRef]
- French, R.M.; Jacquet, M. Understanding bilingual memory: Models and data. Trends Cogn. Sci. 2004, 8, 87–93. [Google Scholar] [CrossRef]
- Perea, M.; Duñabeitia, J.A.; Carreiras, M. Masked associative/semantic priming effects across languages with highly proficient bilinguals. J. Mem. Lang. 2008, 58, 916–930. [Google Scholar] [CrossRef]
- Costa, A.; Caramazza, A.; Sebastian-Galles, N. The Cognate Facilitation Effect: Implications for Models of Lexical Access. J. Exp. Psychol. Learn. Mem. Cogn. 2000, 26, 1283–1296. [Google Scholar] [CrossRef] [PubMed]
- Hoshino, N.; Kroll, J.F. Cognate effects in picture naming: Does cross-language activation survive a change of script? Cognition 2008, 106, 501–511. [Google Scholar] [CrossRef] [PubMed]
- Ellis, N.; Beaton, A. Factors Affecting the Learning of Foreign Language Vocabulary: Imagery Keyword Mediators and Phonological Short-term Memory. Q. J. Exp. Psychol. Sect. A 1993, 46, 533–558. [Google Scholar] [CrossRef]
- Lotto, L.; de Groot, A.M.B. Effects of Learning Method and Word Type on Acquiring Vocabulary in an Unfamiliar Language. Lang. Learn. 1998, 48, 31–69. [Google Scholar] [CrossRef]
- De Groot, A.M.B.; Van Hell, J.G. The learning of foreign language vocabulary. In Handbook of Bilingualism: Psycholinguistic Approaches; Oxford University Press: Oxford, UK, 2005; pp. 9–29. [Google Scholar]
- De Groot, A.M.B.; Keijzer, R. What is hard to learn is easy to forget: The roles of word concreteness, cognate status, and word frequency in foreign-language vocabulary learning and forgetting. Lang. Learn. 2000, 50, 1–56. [Google Scholar] [CrossRef]
- Dressler, C.; Carlo, M.S.; Snow, C.E.; August, D.; White, C.E. Spanish-speaking students’ use of cognate knowledge to infer the meaning of English words. Bilingualism 2011, 14, 243–255. [Google Scholar] [CrossRef]
- August, D.; Carlo, M.; Dressler, C.; Snow, C. The Critical Role of Vocabulary Development for English Language Learners. Learn. Disabil. Res. Prac. 2005, 20, 50–57. [Google Scholar] [CrossRef]
- van Hell, J.G.; Mahn, A.C. Keyword Mnemonics Versus Rote Rehearsal: Learning Concrete and Abstract Foreign Words by Experienced and Inexperienced Learners. Lang. Learn. 1997, 47, 507–546. [Google Scholar] [CrossRef]
- Ellis, N.C.; Beaton, A. Psycholinguistic Determinants of Foreign Language Vocabulary Learning. Lang. Learn. 1993, 43, 559–617. [Google Scholar] [CrossRef]
- Emirmustafaoğlu, A.; Gökmen, D.U. The Effects of Picture vs. Translation Mediated Instruction on L2 Vocabulary Learning. Procedia Soc. Behav. Sci. 2015, 199, 357–362. [Google Scholar] [CrossRef]
- Comesaña, M.; Soares, A.P.; Sánchez-Casas, R.; Lima, C. Lexical and semantic representations in the acquisition of L2 cognate and non-cognate words: Evidence from two learning methods in children. Br. J. Psychol. 2012, 103, 378–392. [Google Scholar] [CrossRef] [PubMed]
- Otwinowska, A.; Foryś-Nogala, M.; Kobosko, W.; Szewczyk, J. Learning Orthographic Cognates and Non-Cognates in the Classroom: Does Awareness of Cross-Linguistic Similarity Matter? Lang. Learn. 2020. [Google Scholar] [CrossRef]
- Duyck, W.; Van Assche, E.; Drieghe, D.; Hartsuiker, R.J. Visual word recognition by bilinguals in a sentence context: Evidence for nonselective lexical access. J. Exp. Psychol. Learn. Mem. Cogn. 2007, 33, 663. [Google Scholar] [CrossRef] [PubMed]
- Webb, S. The effects of synonymy on second-language vocabulary learning. Read. A Foreign Lang. 2007, 19, 120–136. [Google Scholar]
- Brown, R.W. Linguistic determinism and the part of speech. J. Abnorm. Soc. Psychol. 1957, 55, 1. [Google Scholar] [CrossRef]
- Schwanenflugel, P.J. Why are abstract concepts hard to understand. Psychol. Word Mean. 1991, 11, 223–250. [Google Scholar]
- Comesaña, M.; Perea, M.; Piñeiro, A.; Fraga, I. Vocabulary teaching strategies and conceptual representations of words in L2 in children: Evidence with novice learners. J. Exp. Child. Psychol. 2009, 104, 22–33. [Google Scholar] [CrossRef]
- Timmer, K.; Ganushchak, L.Y.; Ceusters, I.; Schiller, N.O. Second language phonology influences first language word naming. Brain Lang. 2014, 133, 14–25. [Google Scholar] [CrossRef]
- Duñabeitia, J.A.; Crepaldi, D.; Meyer, A.S.; New, B.; Pliatsikas, C.; Smolka, E.; Brysbaert, M. MultiPic: A standardized set of 750 drawings with norms for six European languages. Q. J. Exp. Psychol. 2018, 71, 808–816. [Google Scholar] [CrossRef]
- Nation, I.S.P. Learning Vocabulary in Another Language; Cambridge University Press: Cambridge, UK, 2001. [Google Scholar]
- Higa, M. Interference effects of intralist word relationships in verbal learning. J. Verbal Learn. Verbal Behav. 1963, 2, 170–175. [Google Scholar] [CrossRef]
- Tinkham, T. The effect of semantic clustering on the learning of second language vocabulary. System 1993, 21, 371–380. [Google Scholar] [CrossRef]
- Waring, R. The negative effects of learning words in semantic sets: A replication. System 1997, 25, 261–274. [Google Scholar] [CrossRef]
- Laufer, B. Why are some words more difficult than others? IRAL Int. Rev. Appl. Linguist. Lang. Teach. 1990, 28, 293–308. [Google Scholar]
- Grainger, J.; Midgley, K.; Holcomb, P.J. Re-thinking the bilingual interactive-activation model from a developmental perspective (BIA-d). In Language Acquisition Across Linguistic and Cognitive Systems; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2010; Volume 52, pp. 267–283. [Google Scholar]
- Kroll, J.F.; Van Hell, J.G.; Tokowicz, N.; Green, D.W. The Revised Hierarchical Model: A critical review and assessment. Bilingualism 2010, 13, 373–381. [Google Scholar] [CrossRef]

| Picture-Word Matching | Translation Recognition | ||||||
|---|---|---|---|---|---|---|---|
| SET A | SET B | SET A | SET B | ||||
| C only | NC only | C and NC | Total | Total | NC | UNC | |
| Mean | 53% | 6% | 16% | 76% | 37% | 20% | 28% |
| Standard deviation | 25% | 10% | 25% | 24% | 29% | 24% | 28% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Antón, E.; Duñabeitia, J.A. Better to Be Alone than in Bad Company: Cognate Synonyms Impair Word Learning. Behav. Sci. 2020, 10, 123. https://doi.org/10.3390/bs10080123
Antón E, Duñabeitia JA. Better to Be Alone than in Bad Company: Cognate Synonyms Impair Word Learning. Behavioral Sciences. 2020; 10(8):123. https://doi.org/10.3390/bs10080123
Chicago/Turabian StyleAntón, Eneko, and Jon Andoni Duñabeitia. 2020. "Better to Be Alone than in Bad Company: Cognate Synonyms Impair Word Learning" Behavioral Sciences 10, no. 8: 123. https://doi.org/10.3390/bs10080123
APA StyleAntón, E., & Duñabeitia, J. A. (2020). Better to Be Alone than in Bad Company: Cognate Synonyms Impair Word Learning. Behavioral Sciences, 10(8), 123. https://doi.org/10.3390/bs10080123