Geoscience Methods in Real Estate Market Analyses Subjectivity Decrease




Abstract
:1. Introduction
2. Literature Review and Research Issues
3. Materials and Methods
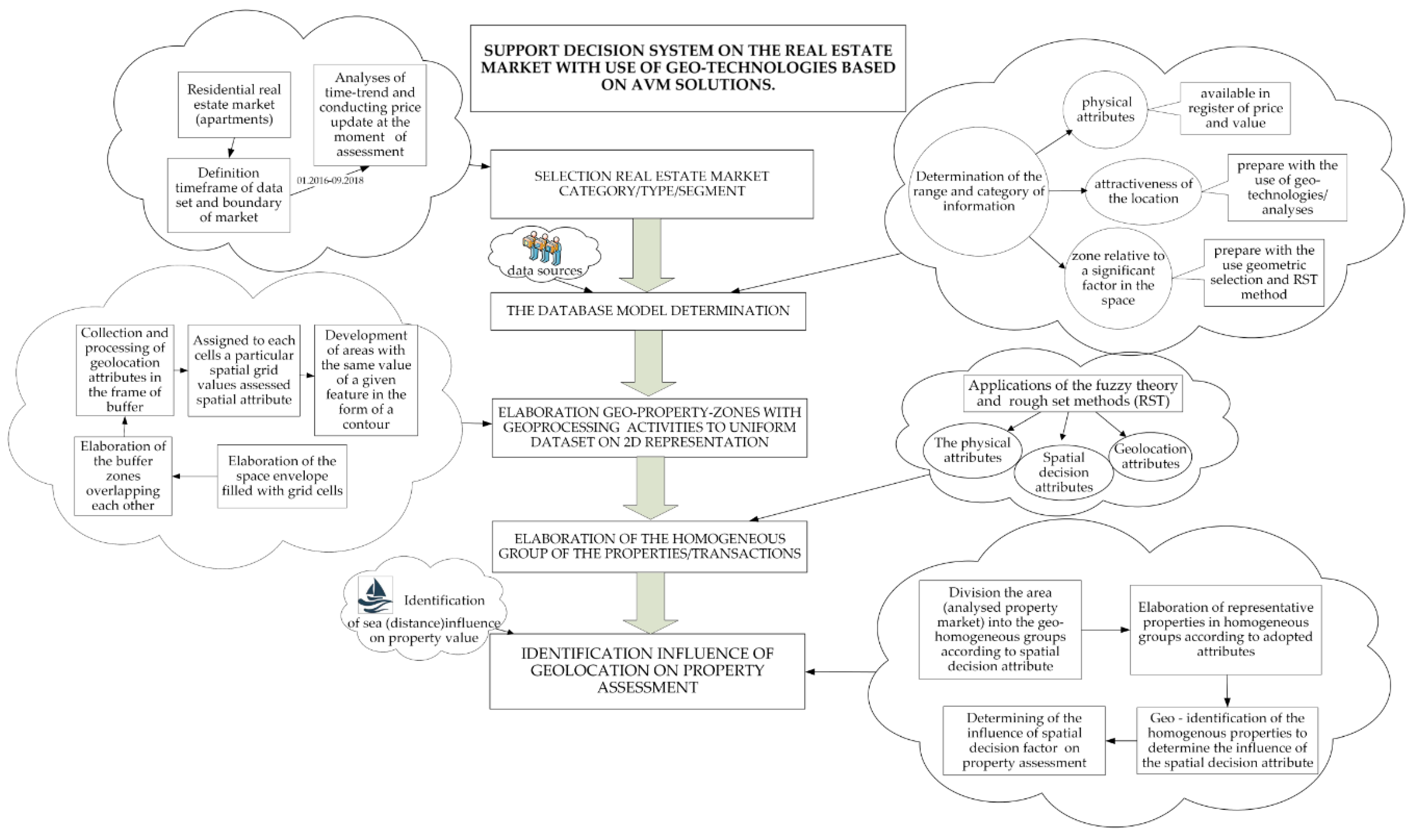
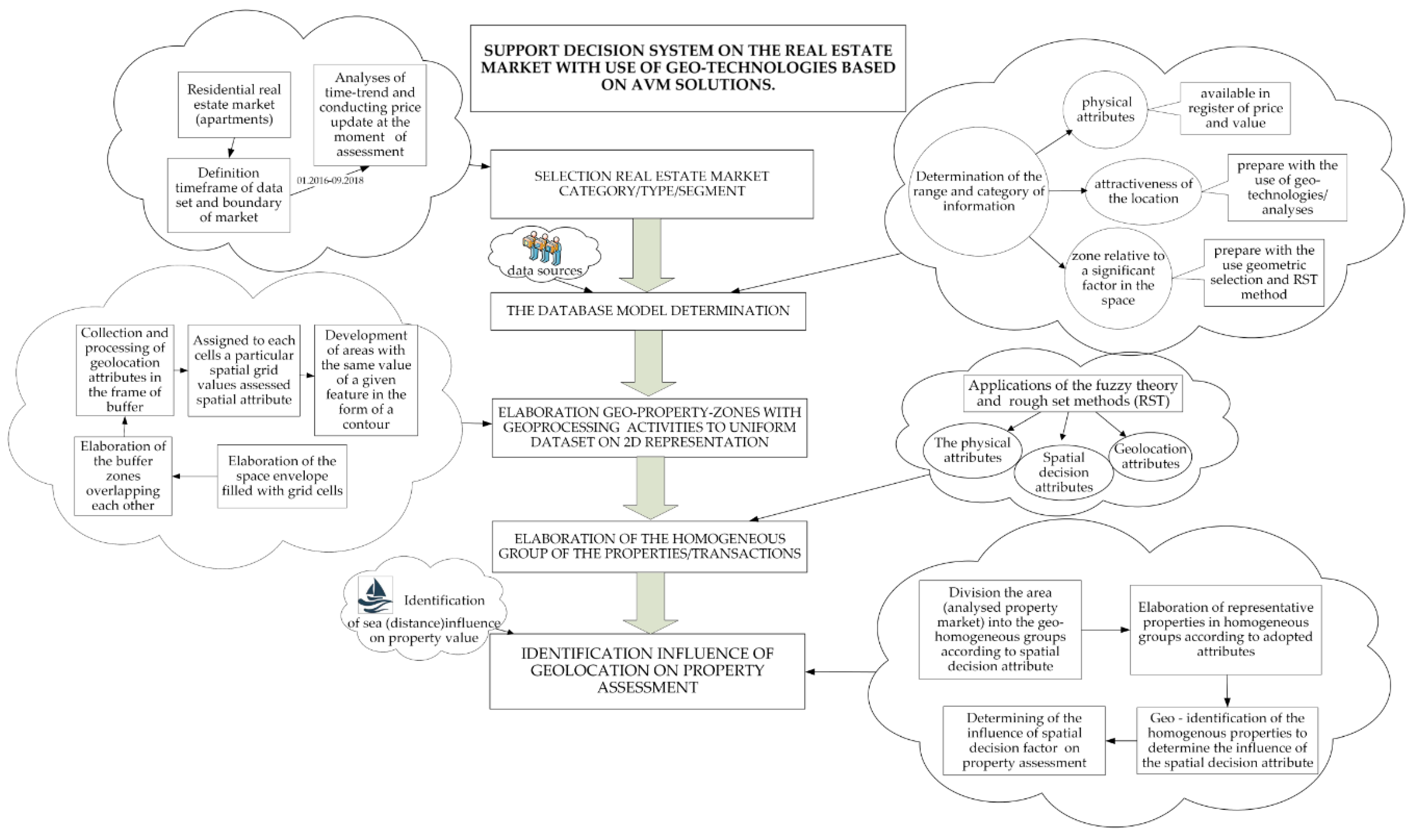
3.1. Methodology of the Analyses and Scope of Data Analysis
- ➢
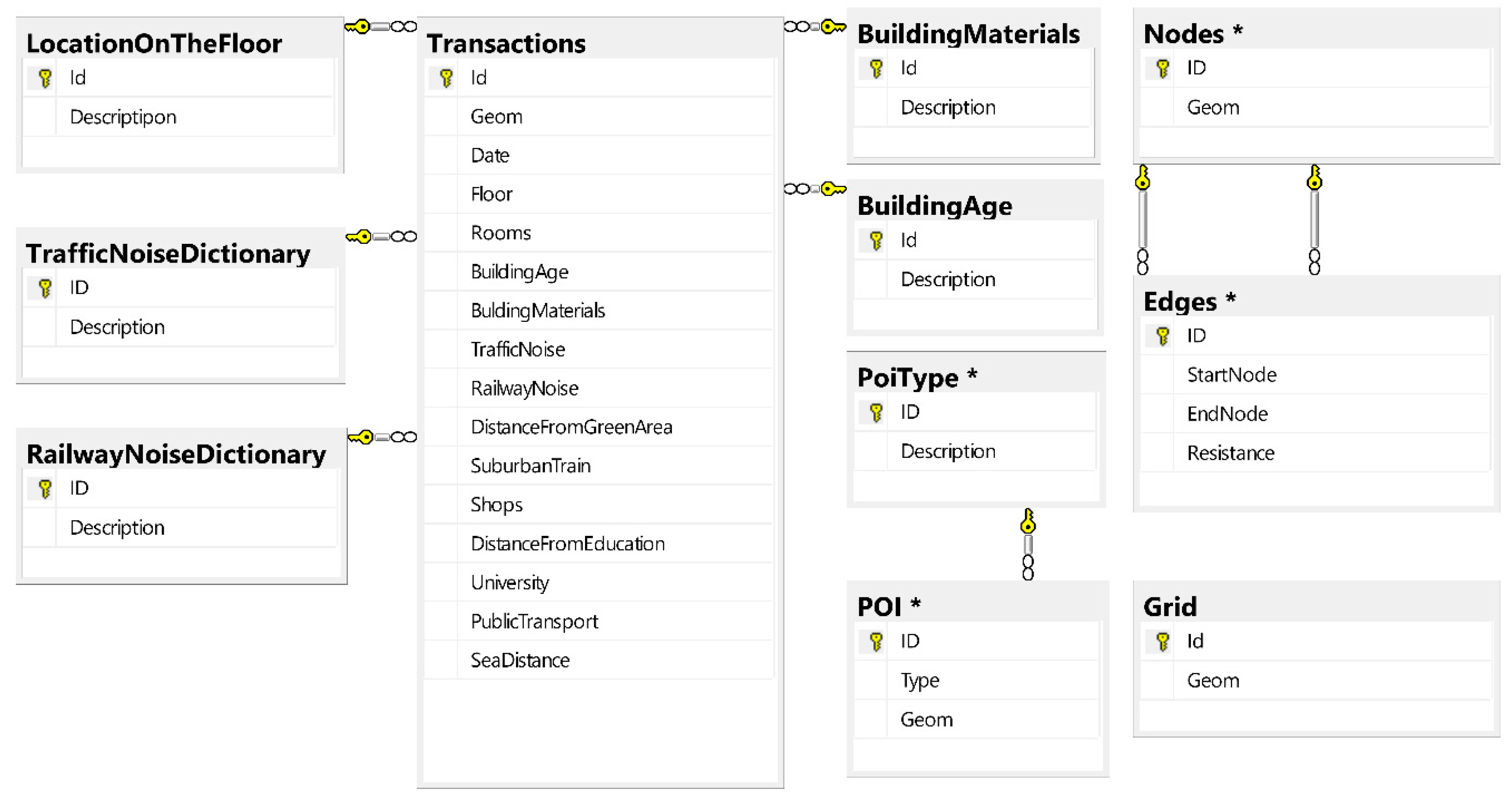
- determination of the database model—designation of attributes—gathering, developing and processing the descriptions/attributes of property transactions; the main elements of the database are as follow:
- -
- defining and coding technical attributes from public register of property transactions,
- -
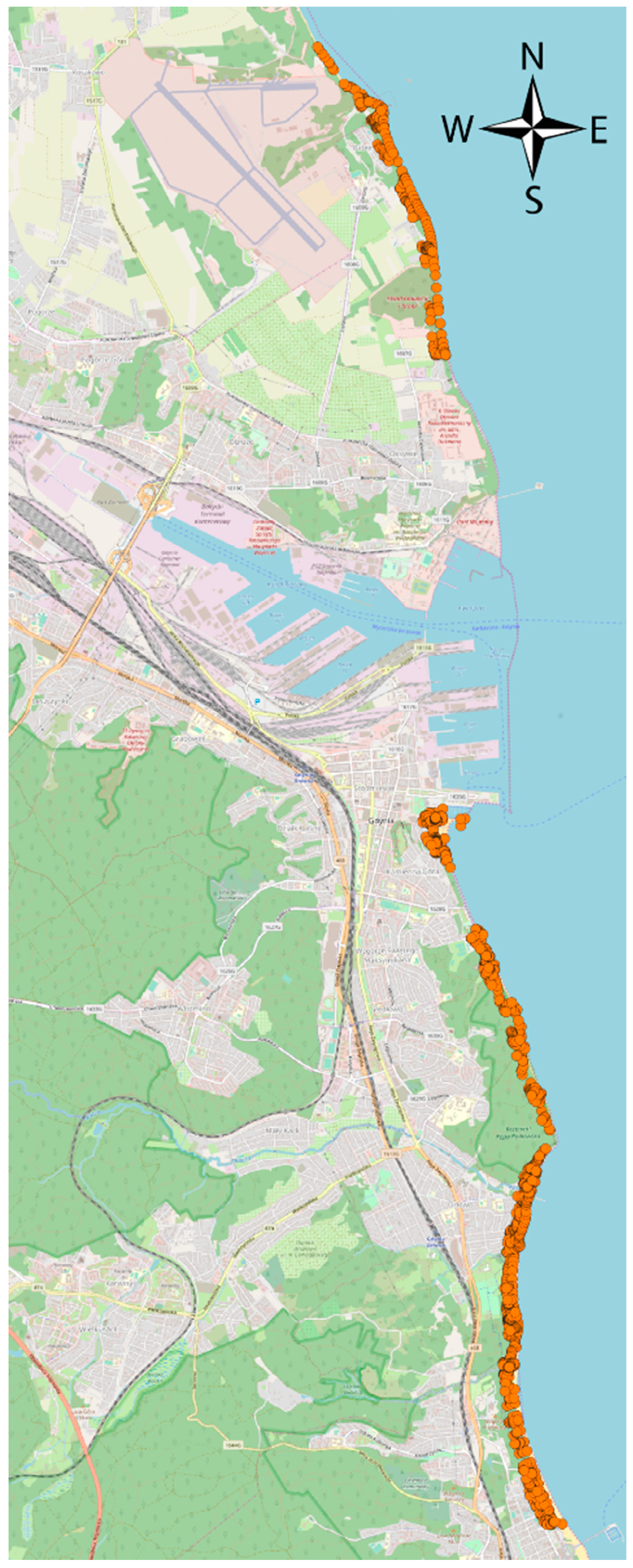
- defining and coding geolocation attributes with the use of geocoding tools (for transforming a physical address description to a location on the Earth’s surface) Nominatim (see Section 4.3) for particular coordinate system, calculation Euclidean distance or routing distance along the public roads obtained as a vector data from Open Street Map (OSM) system, getting number of POI (specific point location interesting or useful for someone) in buffer zones,
- -
- defining and coding spatial decision factor—seashore of Baltic sea in this case—with the use of geotechnologies based on grid distance, fuzzy logic, rough set method.
- ➢
- geo–property–zones elaboration with geoprocessing activities:
- -
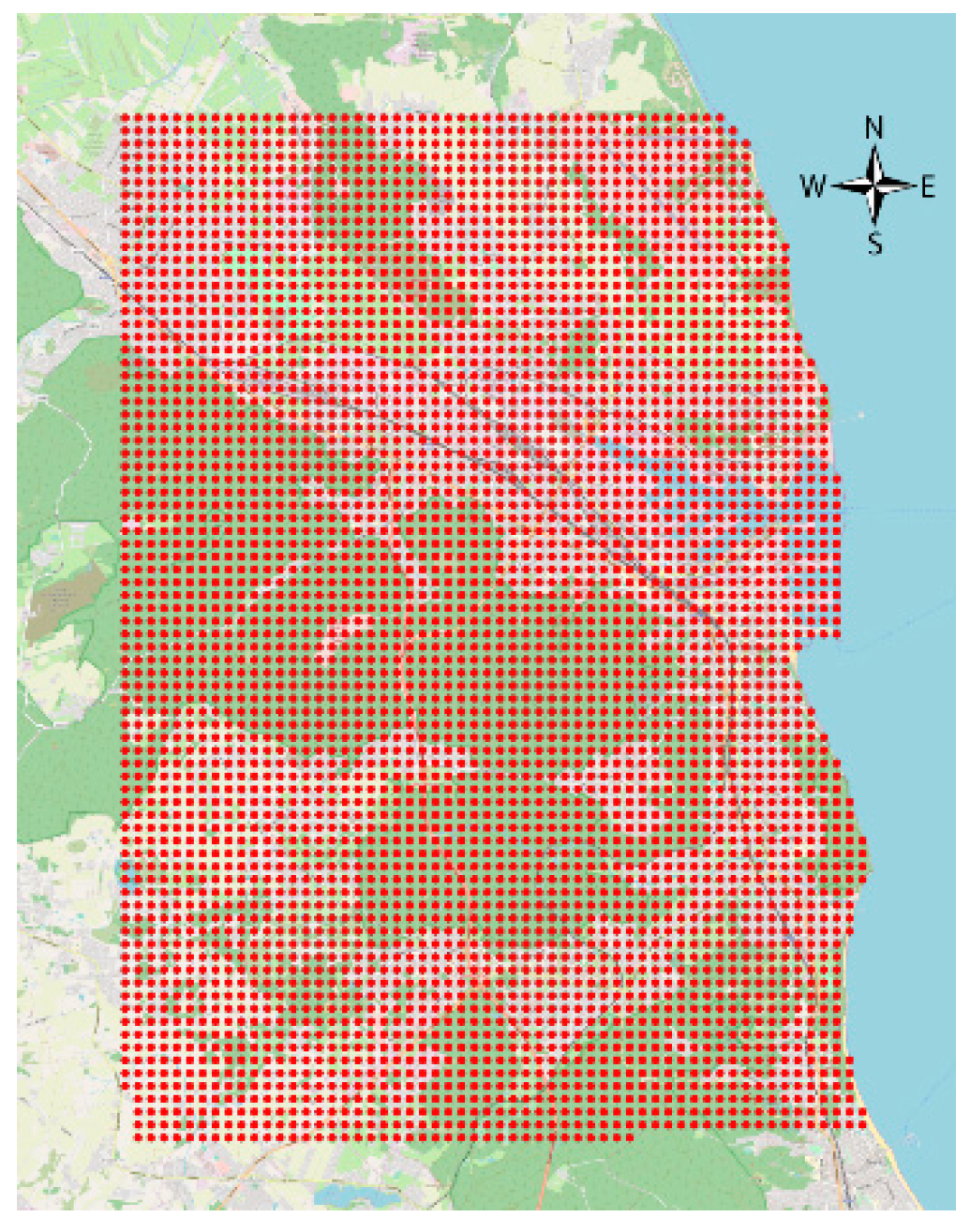
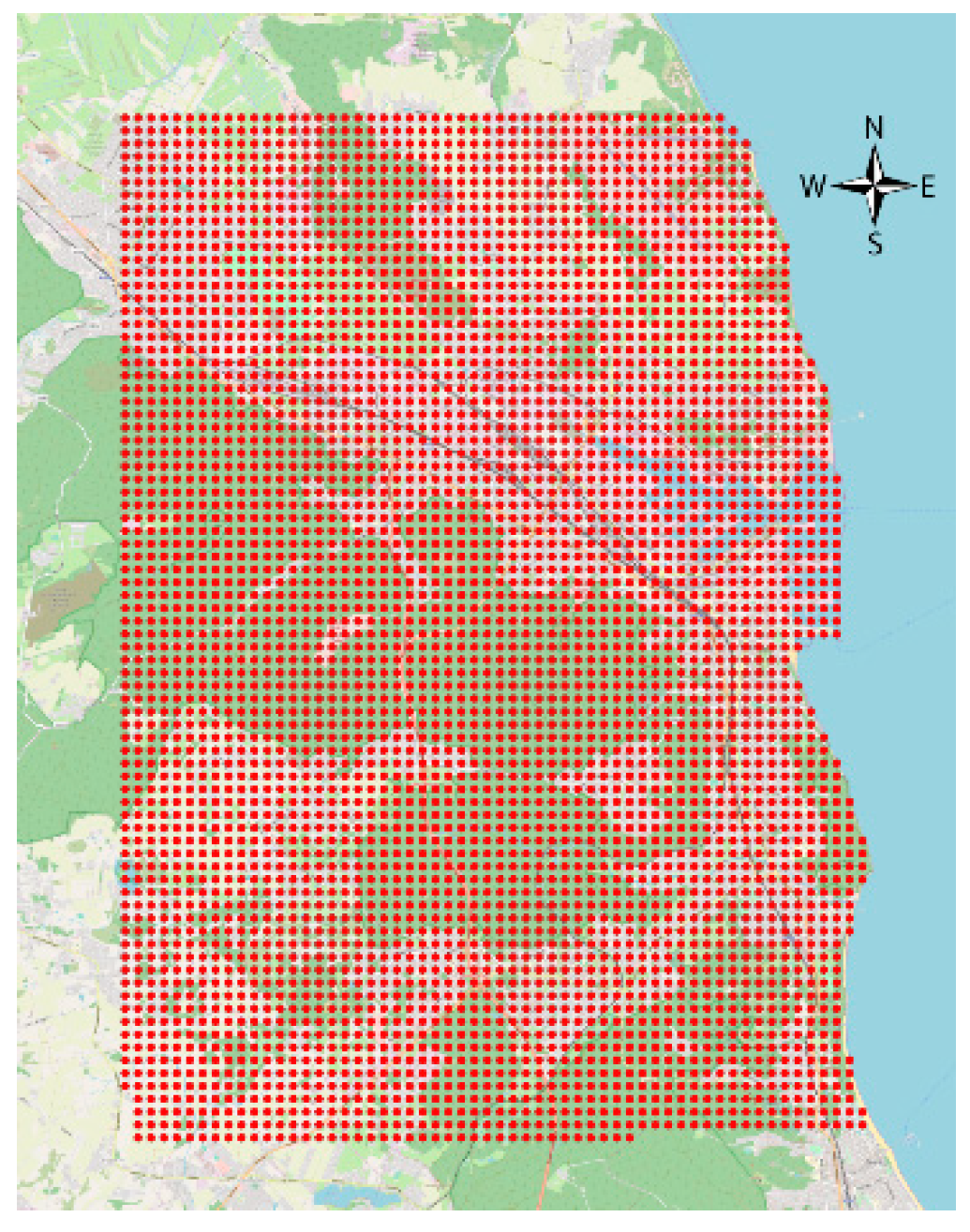
- designation of square grid,
- -
- elaboration of the buffer zones,
- -
- collection of geolocation attributes,
- -
- development of areas with the same characteristics (for all attributes separately).
- ➢
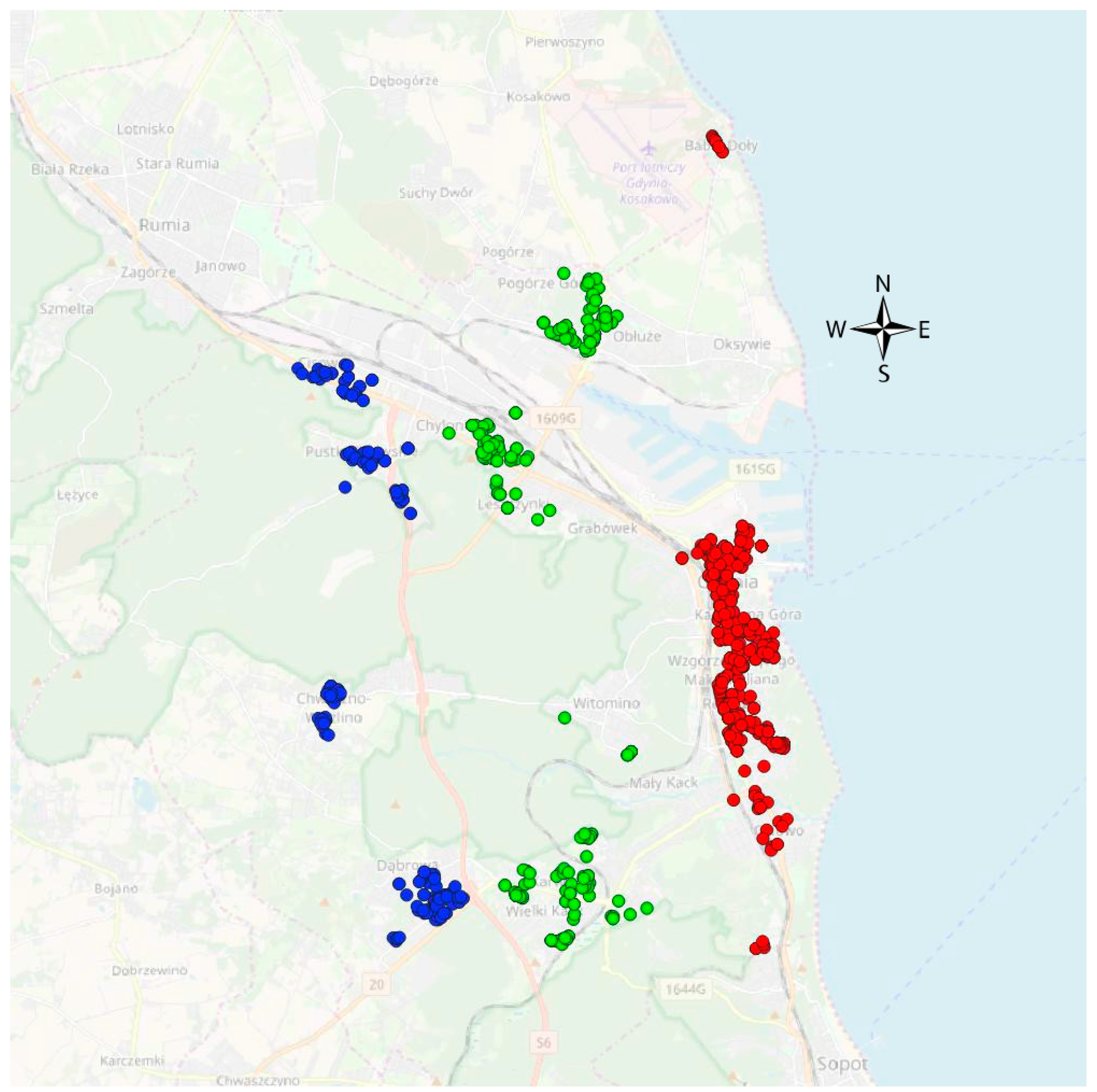
- identification of homogeneous group of property transactions—polarization of properties:
- -
- grouping/classifying the properties that are located in the zone relative to a significant decision factor in the space—that may define real estate market from geolocation point of view (e.g., costal property market),
- -
- grouping/classifying the properties regarding physical characteristics,
- -
- grouping/classifying the properties regarding attractiveness of the geolocation.
3.2. Data Description
4. Empirical Results Based on Algorithm of Decision Support System for Property Analyses with the Use of Geo-Technology
4.1. Selection of Real Estate Market Category/Type/Segment
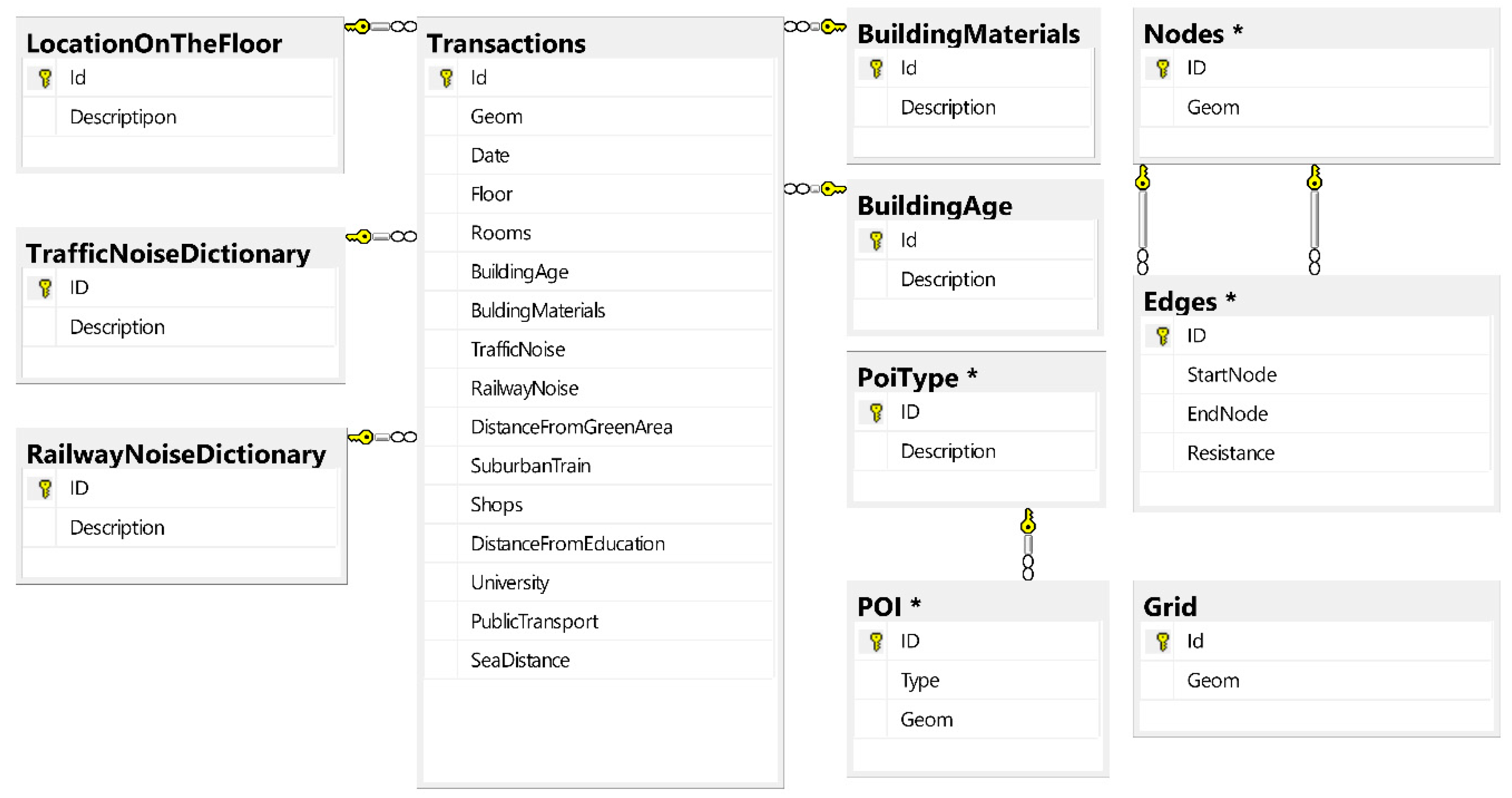
4.2. Determination of the Pattern of the Database Structure
- -
- physical attributes—derived from public transactions register of price and value: usable area, location on the floor, number of rooms, building age, building materials,
- -
- attractiveness of location—prepared with the use of geo–analyses products: traffic noise, railway noise, distance from green areas, occurrence suburban train, occurrence shops, distance from points of early childhood education, occurrence of universities, occurrence public transport stops,
- -
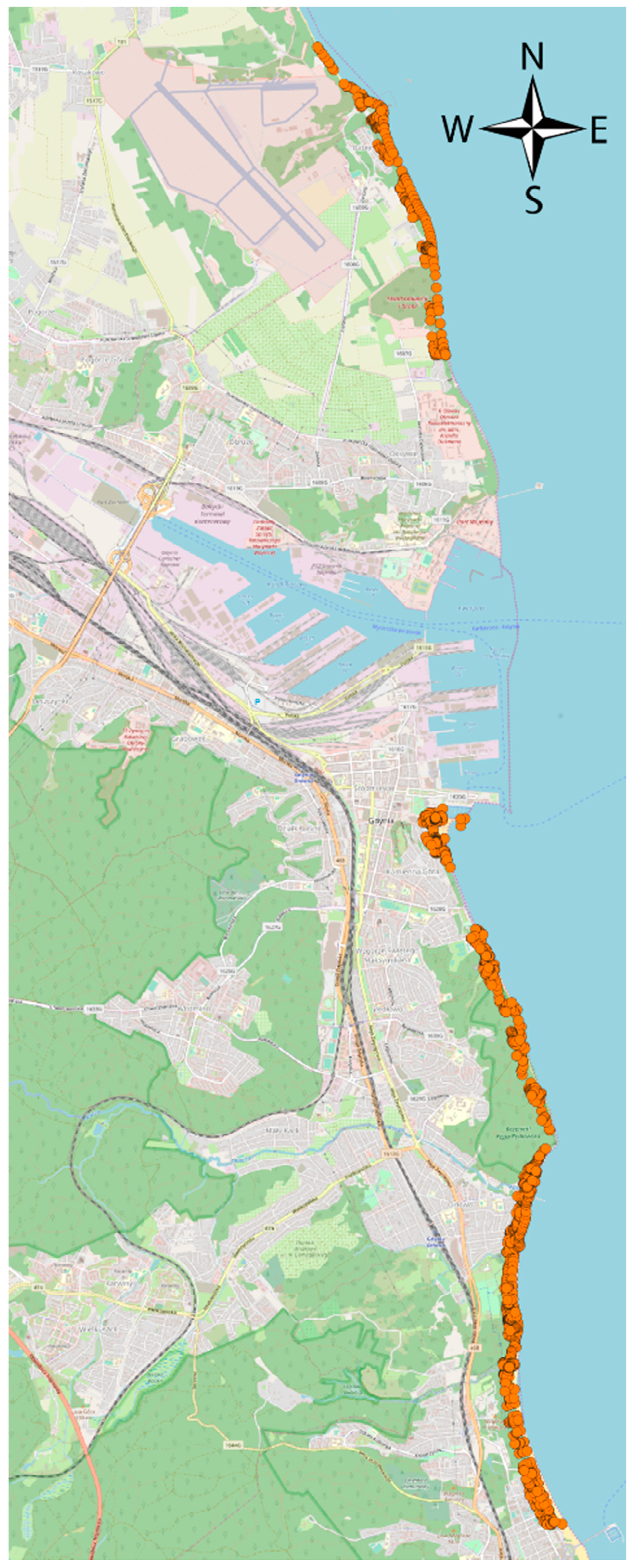
- spatial decision factor—remoteness from the sea.
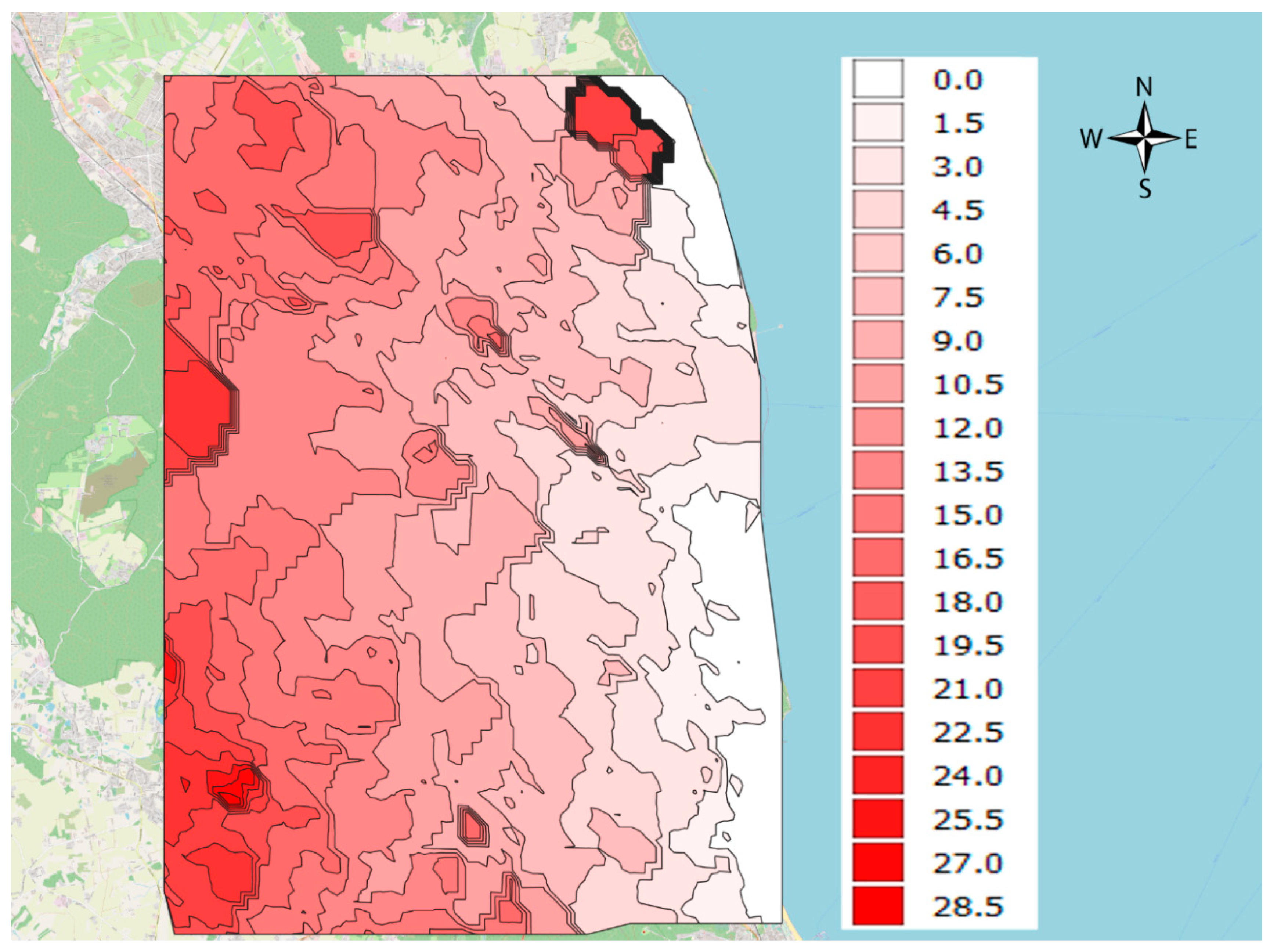
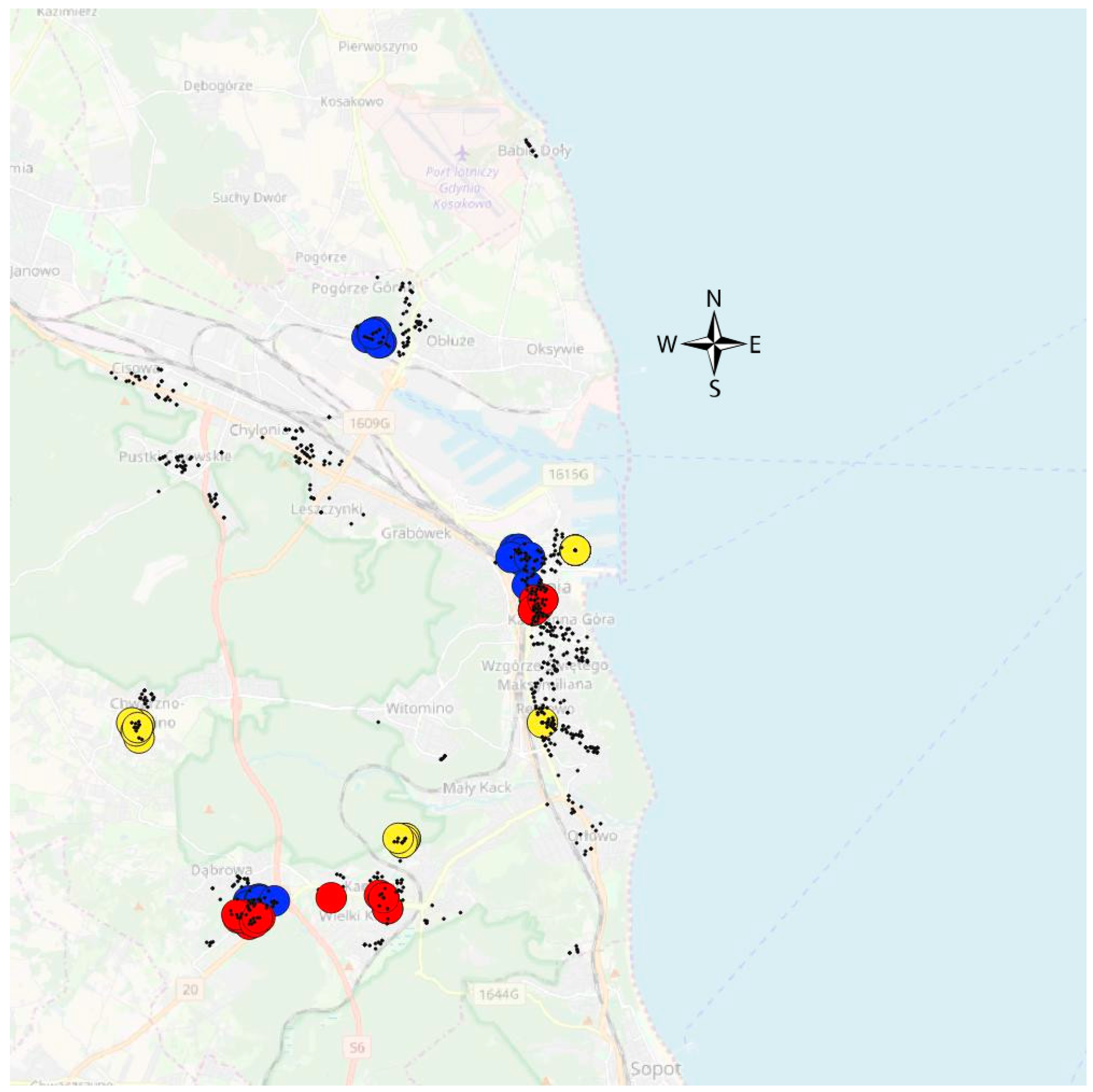
4.3. Geo-Property-Zones Elaboration with Geoprocessing Activities
- -
- incompatibility of identification of objects in various numerical resources (sometimes analogue),
- -
- the degree of generality of the description [48]—e.g., assigning specific attribute values to particular location information with different spatial resolution.
- -
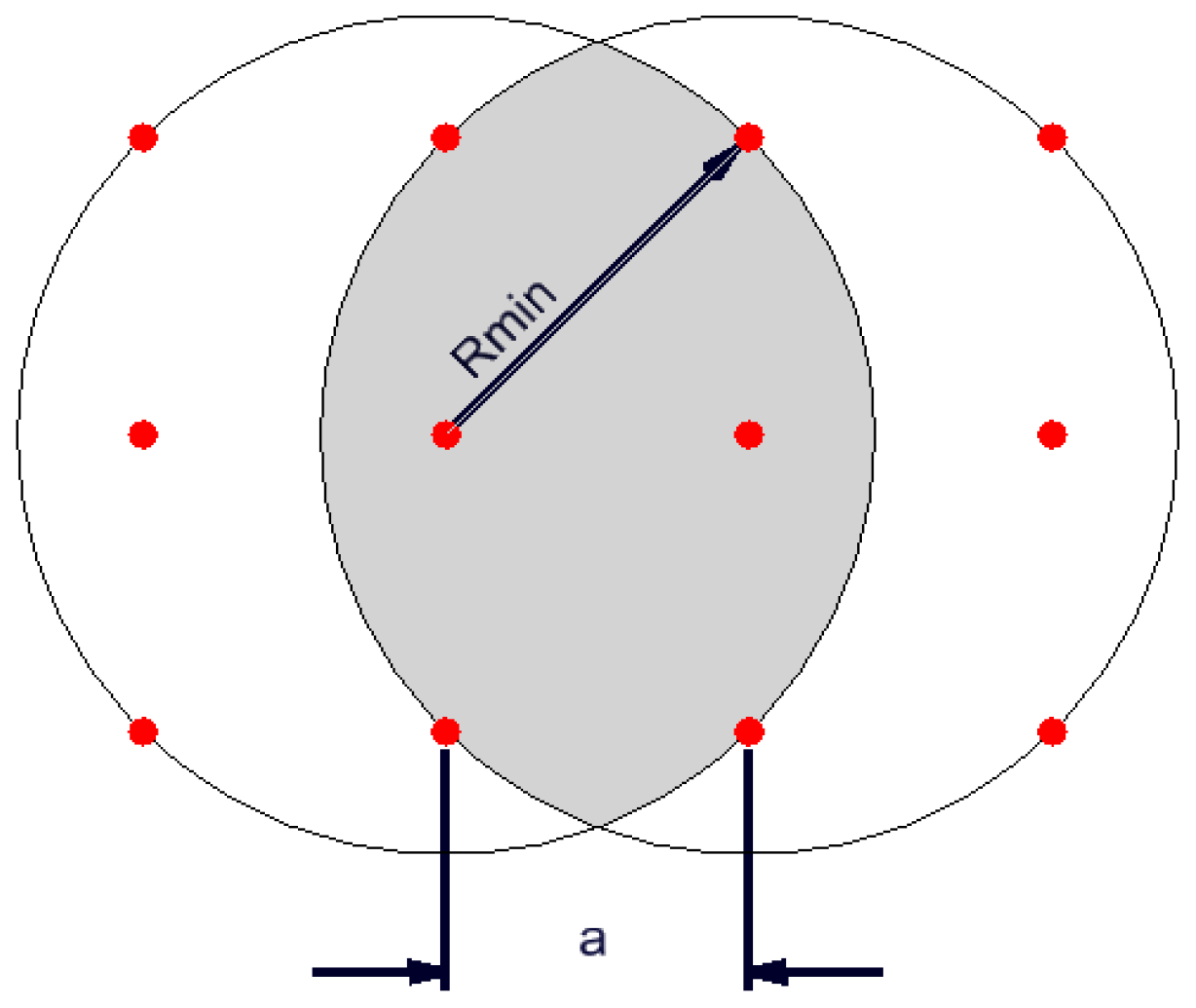
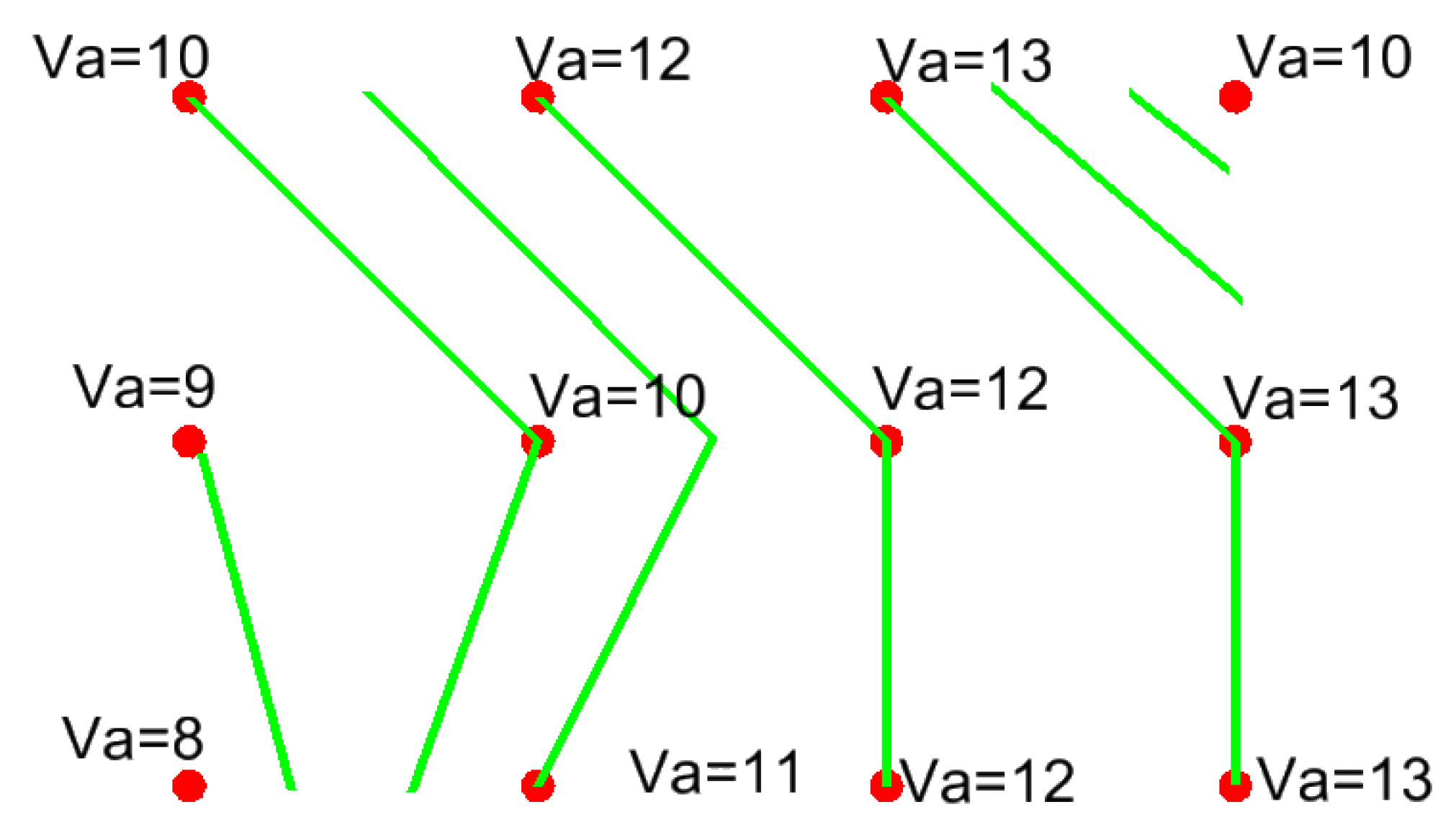
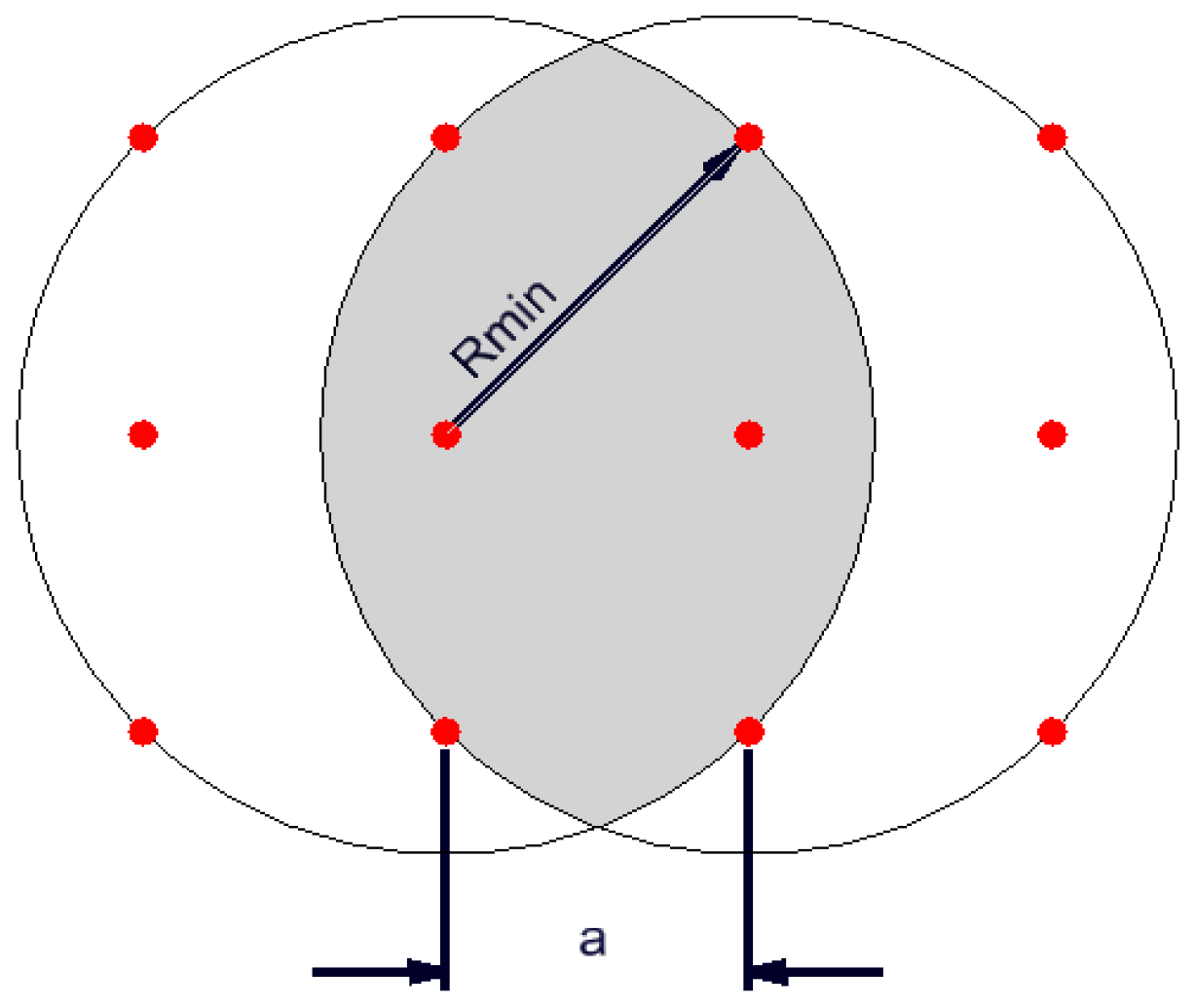
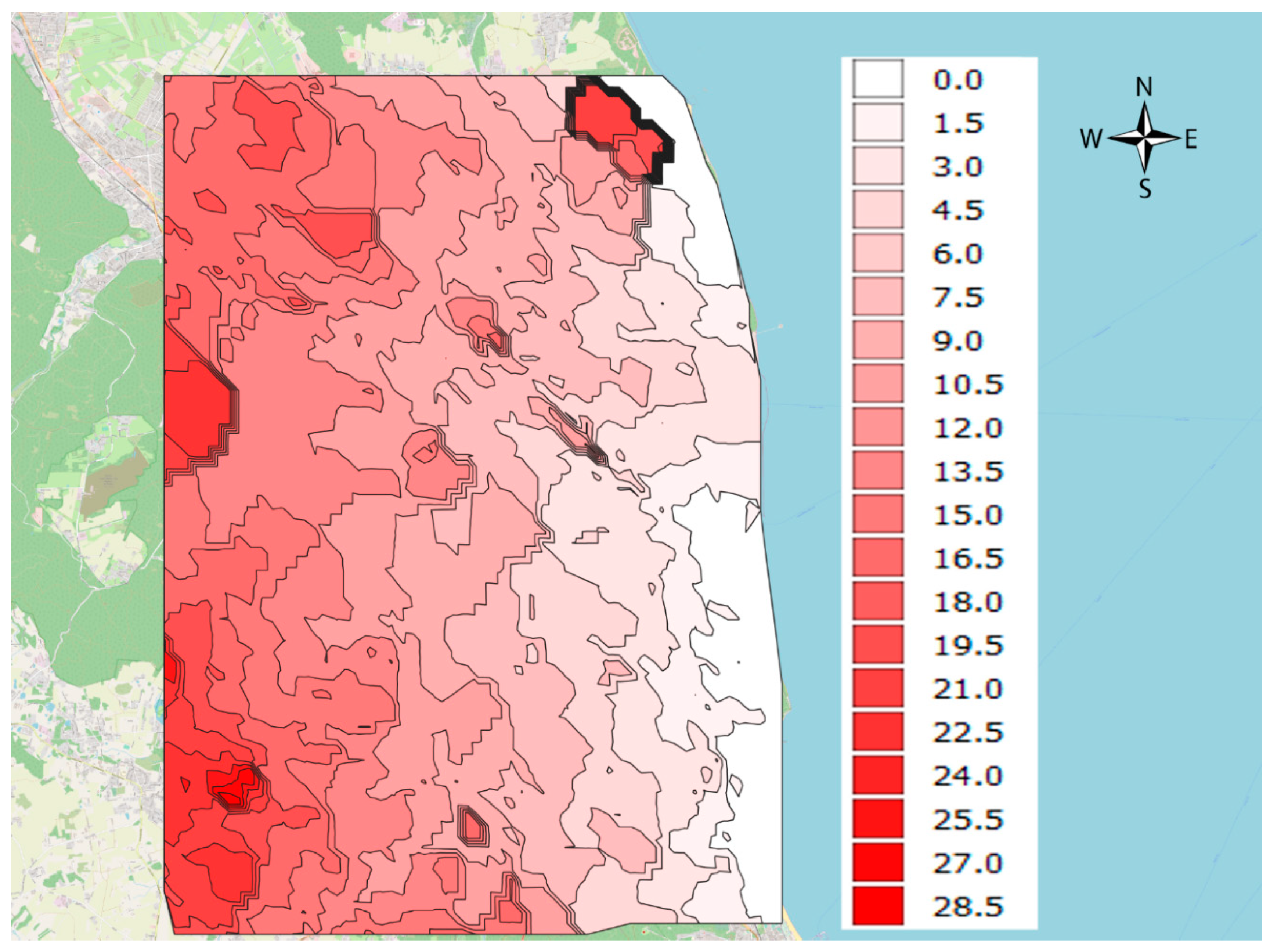
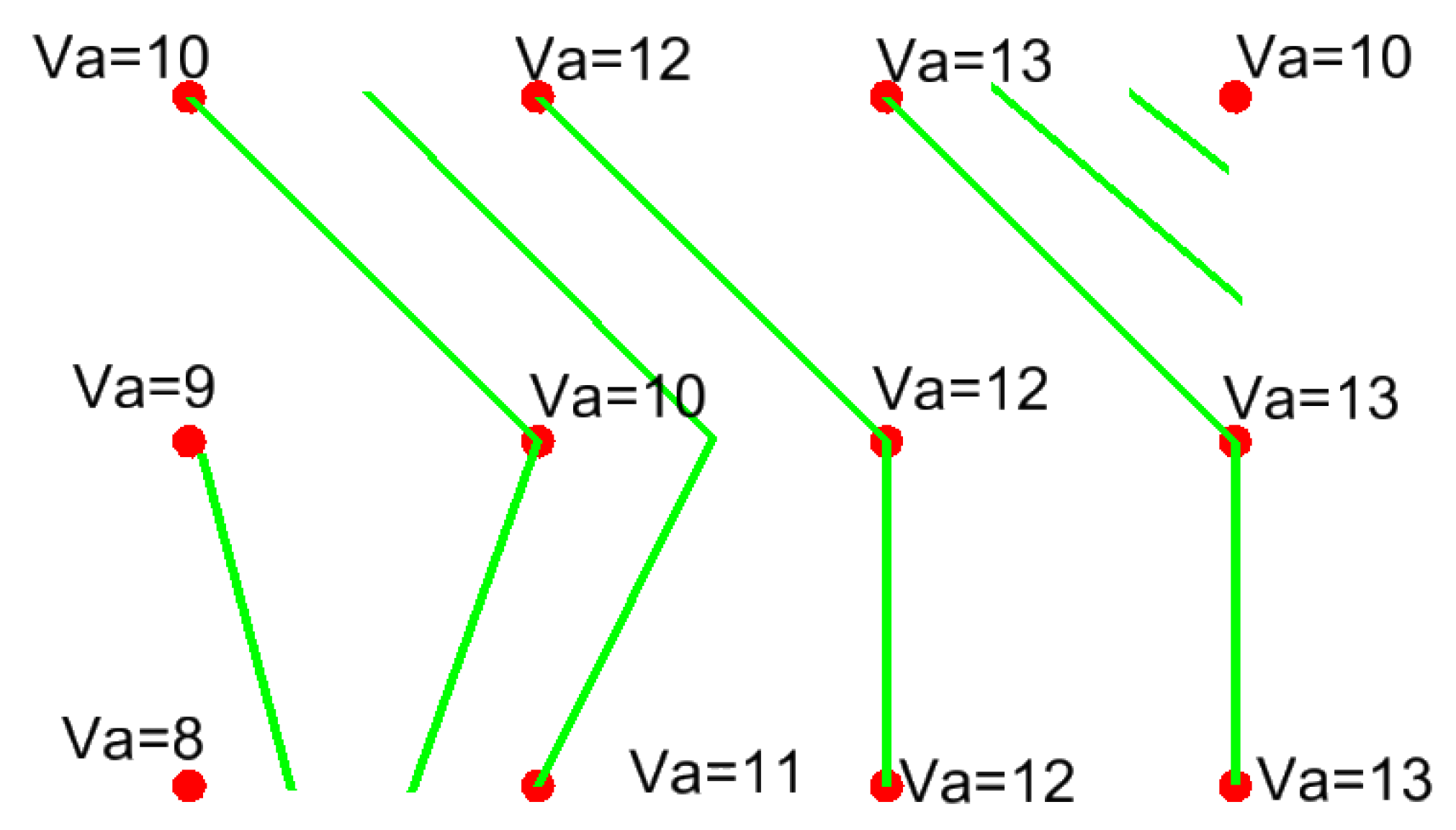
- assessment of the occurrence of a given phenomenon in a spatial buffer zone in the form of a circle with a suitably chosen radius. The assumption of the interpenetration of the impact of individual environmental features on neighbouring grid nodes resulted in the adoption of Rmin = a√2 (Figure 4).
- -
- Euclidean distance—most often recognized as a parameter of the deterministic model. This approach is correct when assessing the proximity of unfavourable factors: noise, pollution sources and so forth. or visual: direct visibility of the sea, where the propagation or nuisance of their impact is a linear dependence on the distance or its derivative,
- -
- other than the numerical and linear nature of the influence of external factors (e.g., location-dependent) on the magnitude of the attribute being examined. From the point of view of functioning in a city, it may often be more important to reach the object of interest than its immediate neighbourhood. The proximity of attractive green areas based on their direct visibility but requiring a by-pass to reach it, loses its significance. In this case, the assessment of the attractiveness of space, comfort of life based on access to “services” of the modern city is based on calculations related to the travel time to such places.
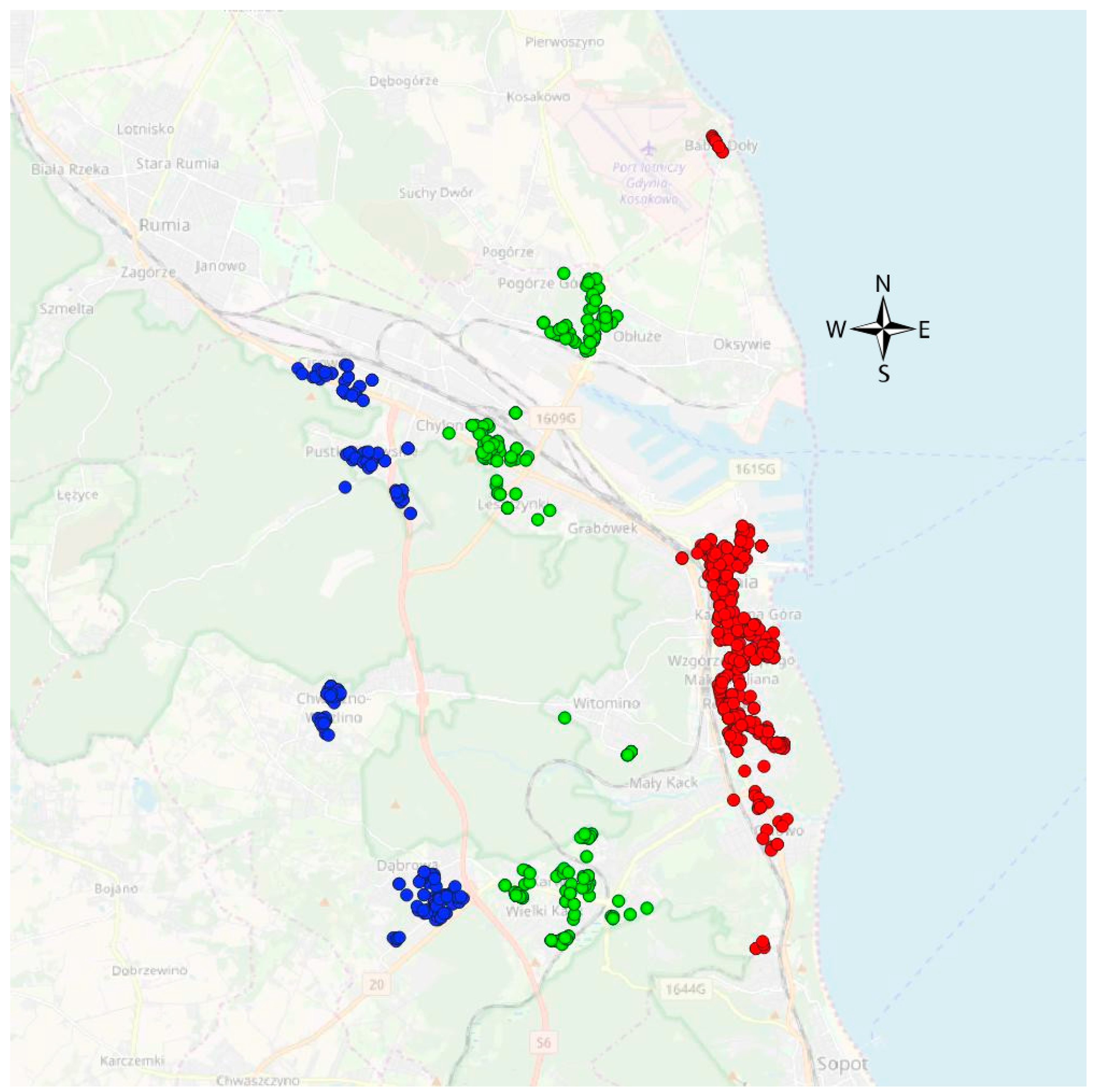
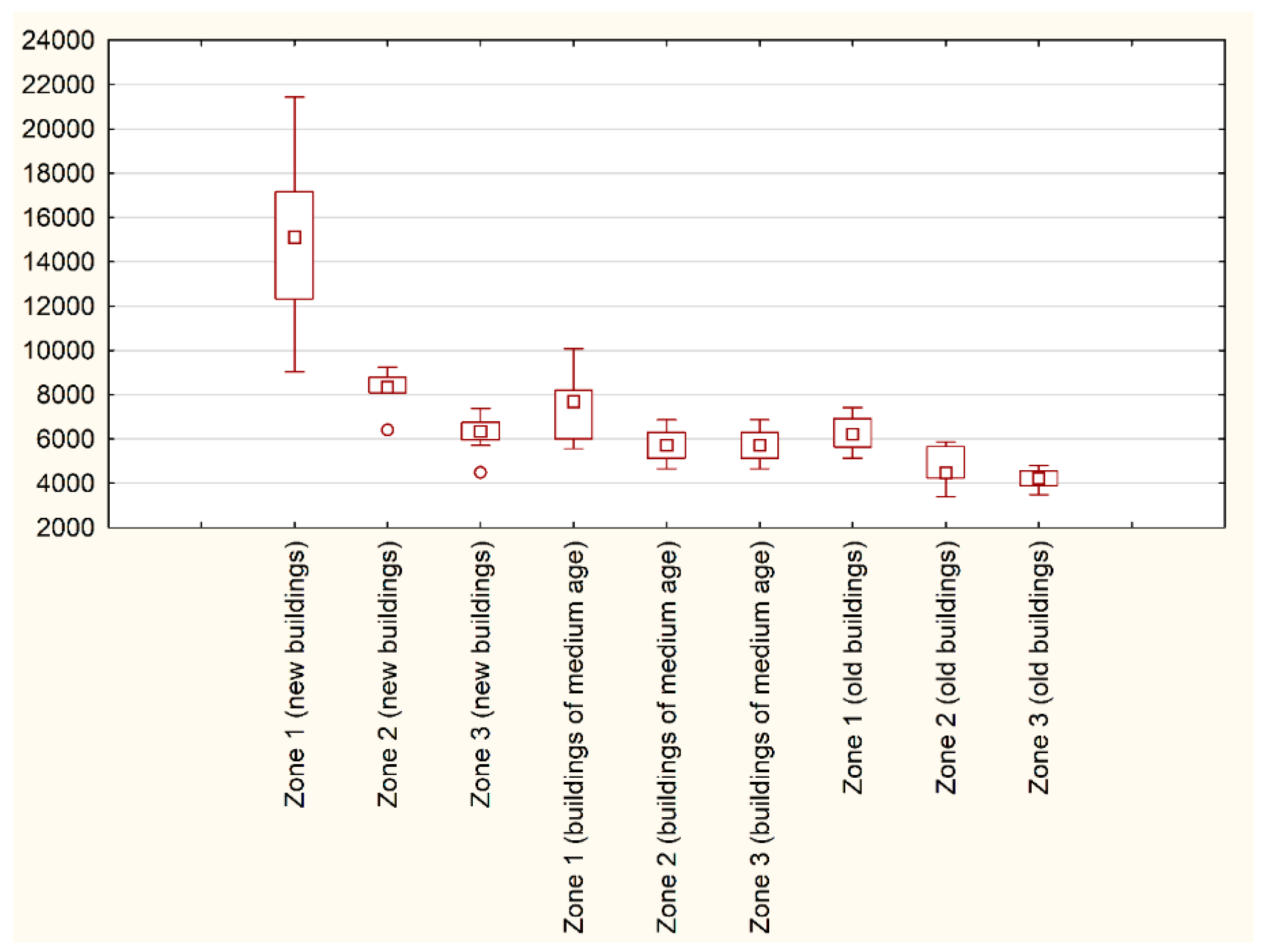
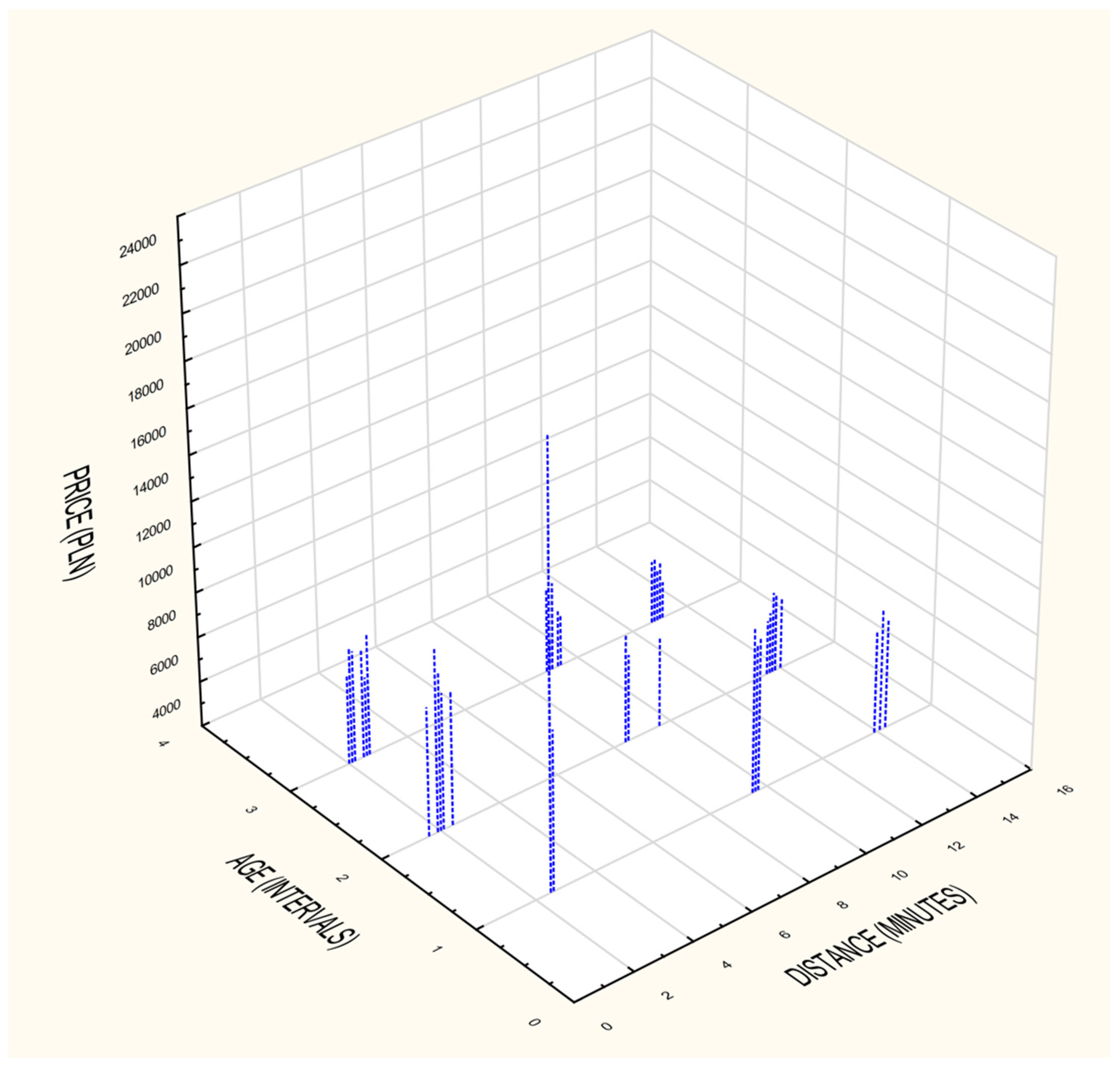
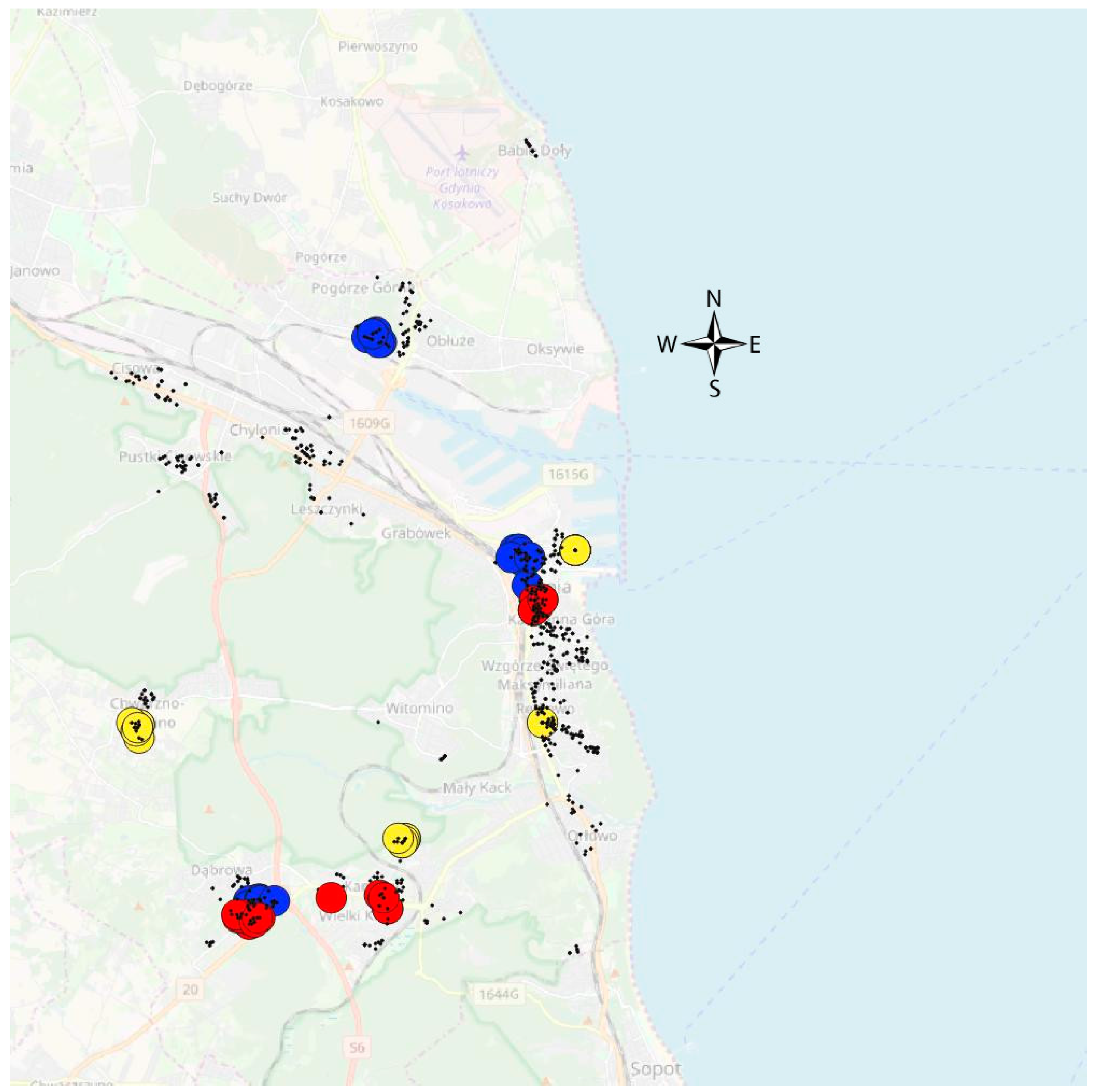
4.4. Elaboration of the Homogeneous Group of the Property/Transactions
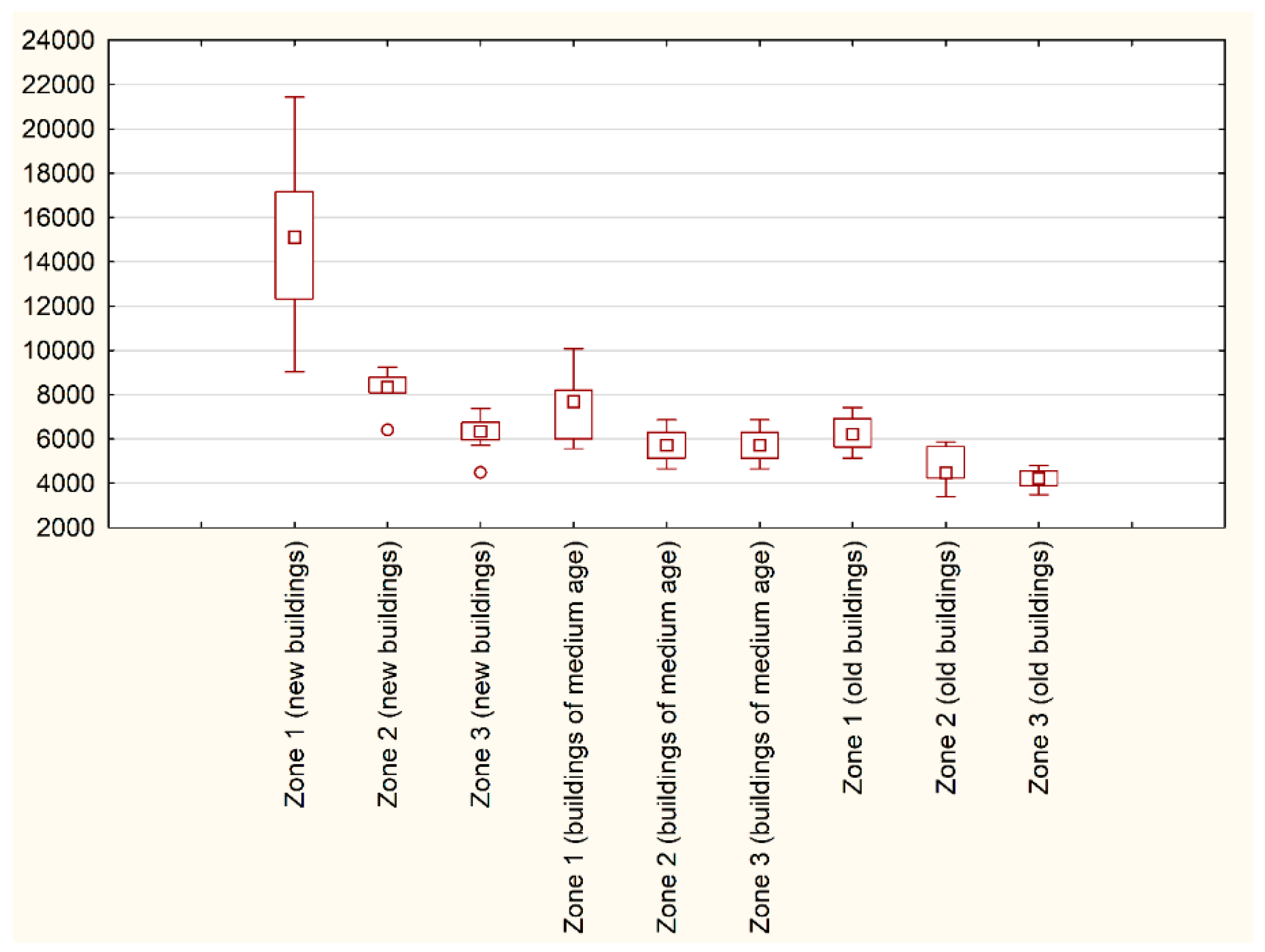
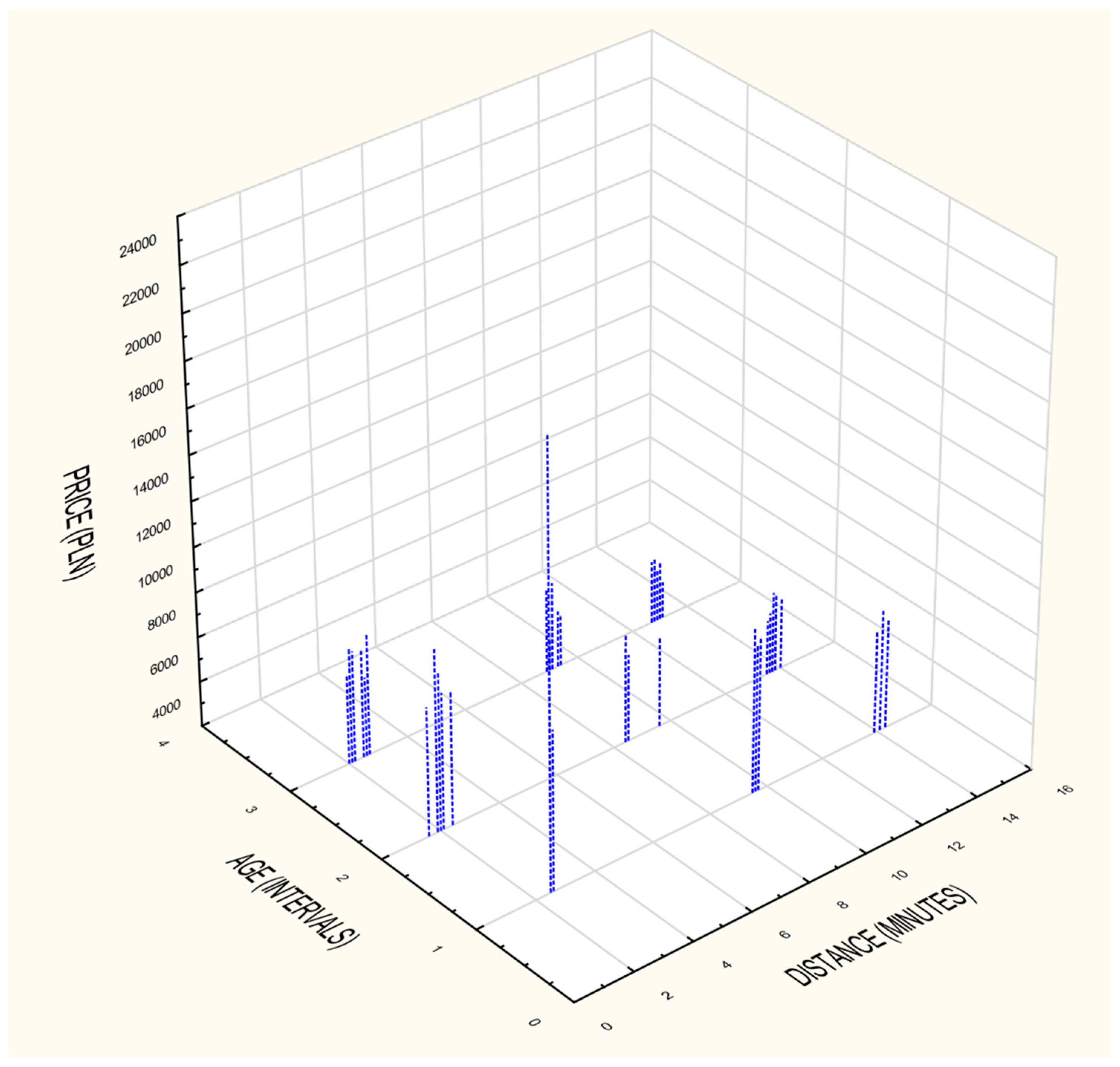
4.5. Identification Influence of Geolocation on Property Assessment
- -
- old buildings (1950–1980),
- -
- building of medium age (1970–1997),
- -
- new buildings (2005–2015).
- CW—unit price brought to the valuation date of the highest condition of the feature,
- CM—unit price with the lowest condition.
- CMAX—the highest recorded unit price in the set
- CMIN—the lowest unit price recorded in the set.
5. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Von Bertalanffy, L. General System Theory; George Braziller, Inc.: New York, NY, USA, 1968. [Google Scholar]
- Demetriou, D. Automating the land valuation process carried out in land consolidation schemes. Land Use Policy 2018, 75, 21–32. [Google Scholar] [CrossRef]
- Źróbek, S.; Grzesik, C. Modern Challenges Facing the Valuation Profession and Allied University Education in Poland. Real Estate Manag. Valuat. 2013, 21, 14–18. [Google Scholar] [CrossRef]
- Kriegel, H.P.; Schneider, R.; Brinkhoff, T. Potentials for improving query processing in spatial databse systems. Proc. 9iemes Journees Bases Donnees Avoncee 1993, 11, 11–31. [Google Scholar]
- Prigogine, I.; Stengers, I. Order out of Chaos: Man’s New Dialogue with Nature; Bantam Books: New York, NY, USA, 1984; ISBN 9780553340822. [Google Scholar]
- Popper, K. The Logic of Scientific Discovery; Routledge: London, UK, 2002. [Google Scholar]
- Longley, P.; Higgs, G.; Martin, D. The predictive use of GIS to model property valuations. Int. J. Geogr. Inf. Syst. 1994, 8, 217–235. [Google Scholar] [CrossRef]
- Wyatt, P. The development of a property information system for valuation using geographical information system (GIS). J. Prop. Res. 1996, 13, 317–336. [Google Scholar] [CrossRef]
- Hamilton, S.; Morgan, A. Integrating lidar, GIS and hedonic price modeling to measure amenity values in urban beach residential property markets. Comput. Environ. Urban Syst. 2010, 34, 133–141. [Google Scholar] [CrossRef]
- Gedal, M.; Ellen, I.G. Valuing urban land: Comparing the use of teardown and vacant land sales. Reg. Sci. Urban Econ. 2018, 70, 190–203. [Google Scholar] [CrossRef]
- Cupal, M. Flood Risk as a Price–setting Factor in the Market Value of Real Property. Procedia Econ. Financ. 2015, 23, 658–664. [Google Scholar] [CrossRef]
- Renigier–Biłozor, M.; Biłozor, A.; Wiśniewski, R. Real estate markets rating engineering as the condition of urban areas assessment. Land Use Policy 2017, 61, 511–525. [Google Scholar] [CrossRef]
- Robinson, G.; Dawnie, M. Integrating valuation models with valuation services to meet the need of borrowers lenders and valuers. Find. Built Rural. Environ. 2009, 3, 3–10. [Google Scholar]
- RICS. Comparable Evidence in Property Valuation; RICS: London, UK, 2012; ISBN 978-1-84219-684. [Google Scholar]
- Renigier–Biłozor, M.; Wiśniewski, R.; Biłozor, A.; Kaklauskas, A. Rating methodology for real estate markets–Poland case study. Int. J. Strateg. Prop. Manag. 2014, 18, 198–212. [Google Scholar] [CrossRef]
- Mark, J.; Goldberg, M. Multiple regression analysis and mass assessment: A review of the issue. Apprais. J. 1988, 56, 89–109. [Google Scholar]
- Fletcher, M.; Gallimore, P.; Mangan, J. Heteroscedasticity in hedonic house price models. J. Prop. Res. 2000, 17, 93–108. [Google Scholar] [CrossRef]
- Dubin, R.A.; Goodman, A.C. Valuation of neighborhood characteristics through hedonic prices. Popul. Environ. 1982, 5, 166–181. [Google Scholar] [CrossRef]
- Des Rosiers, F.; Theriault, M. House Prices and Spatial Dependence: Towards an Integrated Procedure to Model Neighbourhood Dynamics; Working Papiers; Laval–Faculte des Sciences de Administration: Rue de la Terrasse, QC, Canada, 1999. [Google Scholar]
- Helbich, M.; Brunauer, W.; Vaz, E.; Nijkamp, P. Spatial heterogeneity in hedonic house price models: The case of Austria. Urban Stud. 2014, 51, 390–411. [Google Scholar] [CrossRef]
- Radhakrishna, R.C. Statistics and Truth: Putting Chance to Work; World Scientific: Singapore, 1997. [Google Scholar]
- Ferretti, V.; Montibeller, G. Key challenges and meta–choices in designing and applying multi–criteria spatial decision support systems. Decis. Support Syst. 2016, 84, 41–52. [Google Scholar] [CrossRef]
- Malczewski, J. GIS–based land–use suitability analysis: A critical overview. Prog. Plan. 2004, 62, 3–65. [Google Scholar] [CrossRef]
- Borst, R.; McCluskey, W. The Modified Comparable Sales Method as the Basis for a Property Tax Valuations System and Its Relationship and Comparison to Spatially Autoregressive Valuation Models; Kauko, T., d’Amato, M., Eds.; Mass Appraisal Methods: An International Perspective for Property Valuers; Wiley Blackwell: Chicester, UK, 2008; pp. 49–69. [Google Scholar] [CrossRef]
- Wilhelmsson, M. Spatial models in real estate economics. Hous. Theory Soc. 2002, 19, 92–101. [Google Scholar] [CrossRef]
- Borst, R.A.; McCluskey, W.J. Comparative evaluation of the comparable sales method with geostatistical valuation models. Pac. Rim Prop. Res. J. 2007, 13, 106–129. [Google Scholar] [CrossRef]
- Quintos, C. Spatial weight matrices and their use as baseline values and location–adjustment factors in property assessment models. Cityscape 2013, 15, 295–306. [Google Scholar]
- d’Amato, M.; Kauko, T. Advances in Automated Valuation Modeling: AVM after the Non–Agency Mortgage Crisis; Springer: Heidelberg, Germany, 2017. [Google Scholar]
- Lentz, G.H.; Wang, K. Residential appraisal and the lending process: A survey of issues. J. Real Estate Res. 1998, 15, 11–39. [Google Scholar]
- Renigier–Biłozor, M. Analysis of real estate markets with the use of the rough set theory. J. Pol. Real Estate Sci. Soc. 2011, 19, 107–118. [Google Scholar]
- Borst, R.A. Artificial Neural Networks: The Next Modelling/Calibration Technology for the Assessment Community. Prop. Tax J. 1992, 10, 69–94. [Google Scholar]
- McCluskey, W.; Deddis, W.; Mannis, A.; McBurney, D.; Borst, R. Interactive application of computer assisted mass appraisal and geographic information systems. J. Prop. Valuat. Invest. 1997, 15, 448–465. [Google Scholar] [CrossRef]
- Worzala, E.; Lenk, M.; Silva, A. An Exploration of Neural Networks and its Application to Real Estate Valuation. J. Real Estate Res. 1995, 10, 185–201. [Google Scholar]
- O’Connor, P. Automated valuation models by model–building practitioners: Testing hybrid model structure and GIS location adjustments. J. Prop. Tax Assess. Adm. 2008, 5, 5–24. [Google Scholar]
- Jozaghi, A.; Alizadeh, B.; Hatami, M.; Flood, I.; Khorrami, M.; Khodaei, N.; Tousi, E. A Comparative Study of the AHP and TOPSIS Techniques for Dam Site Selection Using GIS: A Case Study of Sistan and Baluchestan Province, Iran. Geosciences 2018, 8, 494. [Google Scholar] [CrossRef]
- d’Amato, M. A comparison between MRA and rough set theory for mass appraisal. A case in bari. Int. J. Strateg. Prop. Manag. 2004, 8, 205–217. [Google Scholar] [CrossRef]
- Aurelio, M.; Gonzalez, S. Automated Valuation Methods in Real Estate Market–a Two–Level Fuzzy System; d’Amato, M., Kauko, T., Eds.; Advances in Automated Valuation Modeling; AVM after the Non–Agency Morgage Crisis; Springer: Berlin, Germany, 2017; ISBN 978-3-319-49746-4. [Google Scholar]
- Kauko, T.; d’Amato, M. Neighbourhood Effect, International Encyclopedia of Housing and Home; Elsevier Publisher: Cambridge, UK, 2011. [Google Scholar]
- PricewaterhouseCoopers. Available online: https://www.pwc.pl/en/wielkie-miasta-polski/raport_tricity_eng.pdf (accessed on 14 March 2019).
- Kaklauskas, A.; Kelpsiene, L.; Zavadskas, E.K.; Bardauskiene, D.; Kaklauskas, G.; Urbonas, M.; Sorakas, V. Crisis management in construction and real estate: Conceptual modeling at the micro–, meso– and macro–levels. Land Use Policy 2011, 28, 280–293. [Google Scholar] [CrossRef]
- Ball, M.; Wood, A. Housing investment: Long run international trends and volatility. Hous. Stud. 1999, 14, 185–209. [Google Scholar] [CrossRef]
- Case, K.E.; Shiller, R.J. Forecasting Prices and Excess Returns in the Housing Market. Real Estate Econ. 1990, 18, 253–273. [Google Scholar] [CrossRef]
- Cellmer, R.; Bełej, M.; Zrobek, S.; Subic-Kovac, M. Urban Land Value Maps—A Methodological Approach. Geod. Vestn. 2014, 58, 535–551. [Google Scholar] [CrossRef]
- McCue, D.; Belsky, E.S. Why do House Prices Fall? Perspective on the Historical Drivers of Large Nominal House Price Declines; Joint Center for Housing Studies of Harvard University: Cambridge, MA, USA, 2007. [Google Scholar]
- Kaklauskas, A.; Zavadskas, E.K.; Trinkunas, V. A multiple criteria decision support on–line system for construction. Eng. Appl. Artif. Intell. 2007, 20, 163–175. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, X.; Zhou, M.; Song, Y.; Luo, X.; Kuang, B. Complex spatial morphology of urban housing price based on digital elevation model: A case study of wuhan city, china. Sustainability 2019, 11, 348. [Google Scholar] [CrossRef]
- Noichan, R.; Dewancker, B. Analysis of accessibility in an urban mass transit node: A case study in a bangkok transit station. Sustainability 2018, 10, 819. [Google Scholar] [CrossRef]
- Goodchild, M.F. A Geographer Looks at Spatial Information Theory; Montello, D.R., Ed.; Spatial Information Theory; COSIT 2001; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2001; Volume 2205. [Google Scholar]
- Clemens, K. Geocoding with OpenStreetMap Data. In Proceedings of the Seventh International Conference on Advanced Geographic Information Systems, Applications, and Services, Lisbon, Portugal, 22–27 February 2015. [Google Scholar]
- Dijkstra, E.W. A Note on Two Problems in Connexion with Graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef]
- Reddy, H. Path Finding–Dijkstra’s and A* Algorithm’s”, December 13, 2013. Available online: http://cs.indstate.edu/hgopireddy/algor.pdf (accessed on 14 March 2019).
- Yang, S.W.; Choi, Y.; Jung, C.K. A divide–and–conquer Delaunay triangulation algorithm with a vertex array and flip operations in two–dimensional space. Int. J. Precis. Eng. Manuf. 2011, 12, 435–442. [Google Scholar] [CrossRef]
- Renigier-Biłozor, M.; Biłozor, A. The Significance of Real Estate Attributes in the Process of Determining Land Function with the Use of the Rough Set Theory; Scientific Monograph: Value in the Process of Real Estate Management and Land Administration; Studia i Materiały Towarzystwa Naukowego Nieruchomości: Olsztyn, Poland, 2009; pp. 103–117. ISBN 978-83-61564-00-3. [Google Scholar]
- Pawlak, Z. Rough sets. Int. J. Inf. Comput. Sci. 1982, 11, 341–356. [Google Scholar] [CrossRef]
- Komorowski, J.; Pawlak, Z.; Polkowski, L.; Skowron, A. Rough Sets: A Tutorial; Pal, S.K., Skowron, A., Eds.; Rough Fuzzy Hybrydatin; A New Trend in Decision Making; Springer: Berlin, Germany, 1999; pp. 3–98. [Google Scholar]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–352. [Google Scholar] [CrossRef]
- Stefanowski, J.; Tsoukias, A. Valued Tolerance and Decision Rules. In International Conference on Rough Sets and Current Trends in Computing; Ziarko, W., Yao, Y., Eds.; Springer: Berlin, Germany, 2000. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. of Transaction | Date of Transaction | Location on the Floor | Number of Rooms | Usable Area of Real Estate | Building Age | Building Materials | |
|---|---|---|---|---|---|---|---|
| 2364 | from 1 (1 January 2016) to 987days (4 September 2018) | 1—ground floor (the year of building to 2000) 2—(above 3rd floor (the year of building to 2000) 3—1st and 2nd floor (the year of building to 2000) and all of floors in the modern buildings (the year of building to 2000) | the number of rooms in the apartment | Square meters | 1—<1965 2—1965–1995 3—1995–2010 4—>2010 | 0—concrete slab 1—no concrete slab | |
| Geolocation Attributes—Referenced to the Particular Location Zones | |||||||
| Location in the Traffic Noise Zone | Location in the Railway Noise Zone | Distance from Green Areas | Occurrence of Suburban Train | Occurrence of Shops | Distance from Points of Early Childhood Education | Occurrence of Universities | Occurrence of Public Transport Stops |
| 55–60 dB | 55–60 dB | percentage of occurrence the green areas such as: forest, park, nature reserve, green recreation ground | occurrence of train station in the defined neighbourhood area (500 m) | number of shops such as: bakery, bar, beauty shop, bookshop, cafe, clothes shop, computer shop, greengrocer, hairdresser, pharmacy, restaurant, supermarket | occurrence of points of early childhood education such as: schools and kindergarten (500 m) | occurrence of university in the defined neighbourhood area (3000 m) | number of public transport stops such as: bus, tram stops and stations in defined neighbourhood area (500 m) |
| 60–65 dB | 60–65 dB | ||||||
| 65–70 dB | 65–70 dB | ||||||
| 70–75 dB | 70–75 dB | ||||||
| >75 dB | >75 dB | ||||||
| Zone Relative To A Significant Spatial Decision Factor | |||||||
| Remoteness from the sea | zone elaborated on the basis of identification similar/indifference/homogeneous group of properties designated taking into account minimal time to reach sea zone measured along the street | ||||||
| New Buildings | Buildings of Medium Age | Old Buildings | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zone 1 | Zone 2 | Zone 3 | Zone 1 | Zone 2 | Zone 3 | Zone 1 | Zone 2 | Zone 3 | |||||||||
| No | Unit price | No | Unit price | No | Unit price | No | Unit price | No | Unit price | No | Unit Price | No | Unit price | No | Unit price | No | Unit price |
| 1 | 12,326 | 7 | 6414 | 13 | 5714 | 1 | 6000 | 7 | 6296 | 13 | 5081 | 1 | 5485 | 7 | 4245 | 13 | 3583 |
| 2 | 11,207 | 8 | 8433 | 14 | 4490 | 2 | 8000 | 8 | 5833 | 14 | 5079 | 2 | 5139 | 8 | 4481 | 14 | 4577 |
| 3 | 17,164 | 9 | 9236 | 15 | 6612 | 3 | 7692 | 9 | 5139 | 15 | 4683 | 3 | 6897 | 9 | 4348 | 15 | 3898 |
| 4 | 12,048 | 10 | 8098 | 16 | 6348 | 4 | 5577 | 10 | 5606 | 16 | 5413 | 4 | 7038 | 10 | 5870 | 16 | 4167 |
| 5 | 10,119 | 11 | 8259 | 17 | 6348 | 5 | 8194 | 11 | 4660 | 17 | 5556 | 5 | 7415 | 11 | 5870 | 17 | 3984 |
| 6 | 9048 | 12 | 8776 | 18 | 7391 | 6 | 6486 | 12 | 6863 | 18 | 4476 | 6 | 6000 | 12 | 3396 | 18 | 4750 |
| New Buildings | Buildings of Medium Age | Old Buildings | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Zone 1–2 | Zone 2–3 | Zone 1–2 | Zone 2–3 | Zone 1–2 | Zone 2–3 | ||||||
| Pairs | Difference | Pairs | Difference | Pairs | Difference | Pairs | Difference | Pairs | Difference | Pairs | Difference |
| 1–7 | 0.55 | 7–13 | 0.15 | 1–7 | –0.08 | 7–13 | 0.51 | 1–7 | 0.31 | 7–13 | 0.27 |
| 2–8 | 0.26 | 8–14 | 0.83 | 2–8 | 0.61 | 8–14 | 0.32 | 2–8 | 0.16 | 8–14 | –0.04 |
| 3–9 | 0.74 | 9–15 | 0.55 | 3–9 | 0.72 | 9–15 | 0.19 | 3–9 | 0.63 | 9–15 | 0.18 |
| 4–10 | 0.37 | 10–16 | 0.37 | 4–10 | –0.01 | 10–16 | 0.08 | 4–10 | 0.29 | 10–16 | 0.69 |
| 5–11 | 0.17 | 11–17 | 0.40 | 5–11 | 1.00 | 11–17 | –0.38 | 5–11 | 0.38 | 11–17 | 0.76 |
| 6–12 | 0.03 | 12–18 | 0.29 | 6–12 | –0.11 | 12–18 | 1.00 | 6–12 | 0.65 | 12–18 | –0.55 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Renigier-Bilozor, M.; Janowski, A.; Walacik, M. Geoscience Methods in Real Estate Market Analyses Subjectivity Decrease. Geosciences 2019, 9, 130. https://doi.org/10.3390/geosciences9030130
Renigier-Bilozor M, Janowski A, Walacik M. Geoscience Methods in Real Estate Market Analyses Subjectivity Decrease. Geosciences. 2019; 9(3):130. https://doi.org/10.3390/geosciences9030130
Chicago/Turabian StyleRenigier-Bilozor, Malgorzata, Artur Janowski, and Marek Walacik. 2019. "Geoscience Methods in Real Estate Market Analyses Subjectivity Decrease" Geosciences 9, no. 3: 130. https://doi.org/10.3390/geosciences9030130
APA StyleRenigier-Bilozor, M., Janowski, A., & Walacik, M. (2019). Geoscience Methods in Real Estate Market Analyses Subjectivity Decrease. Geosciences, 9(3), 130. https://doi.org/10.3390/geosciences9030130