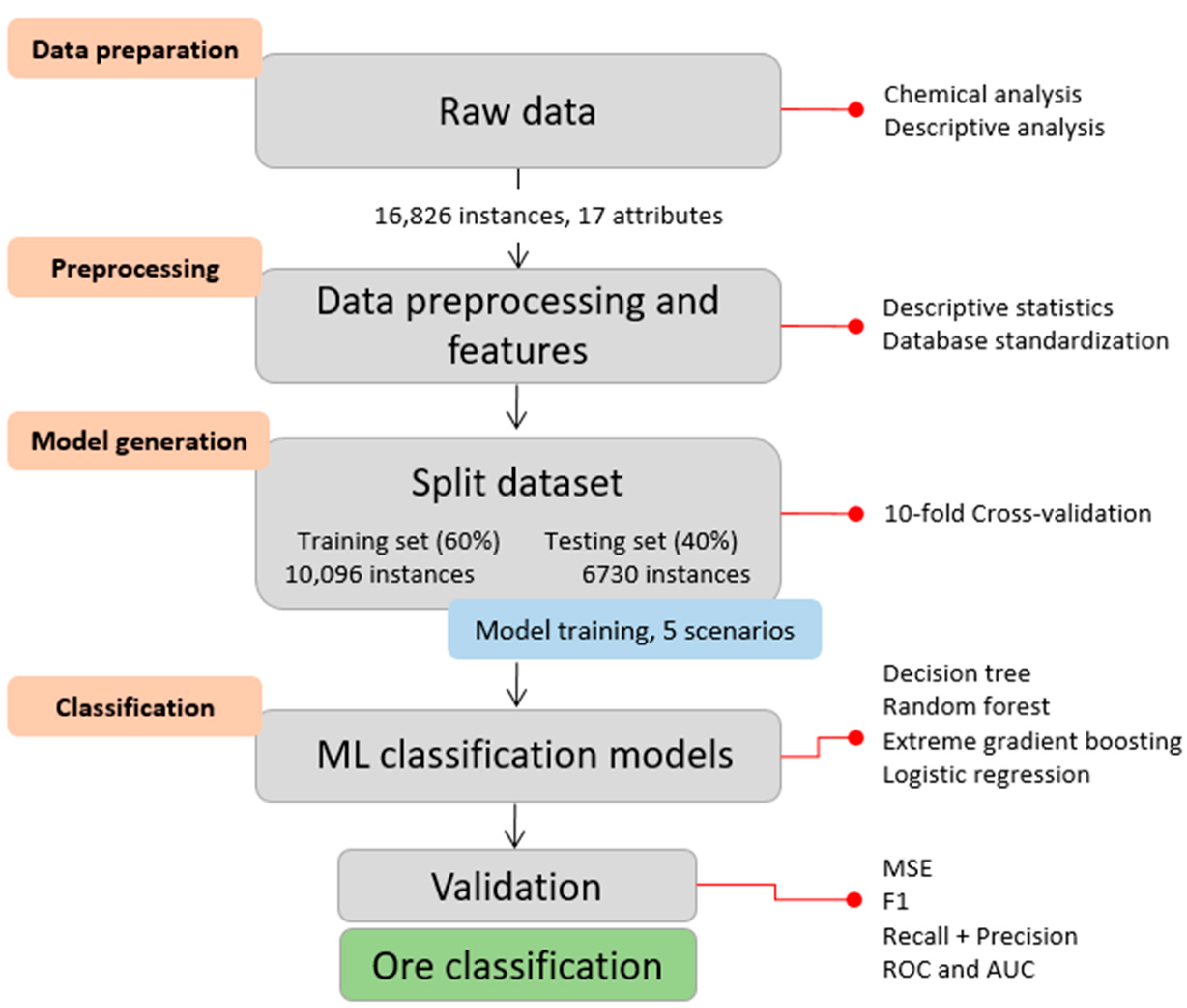
4.1. Database
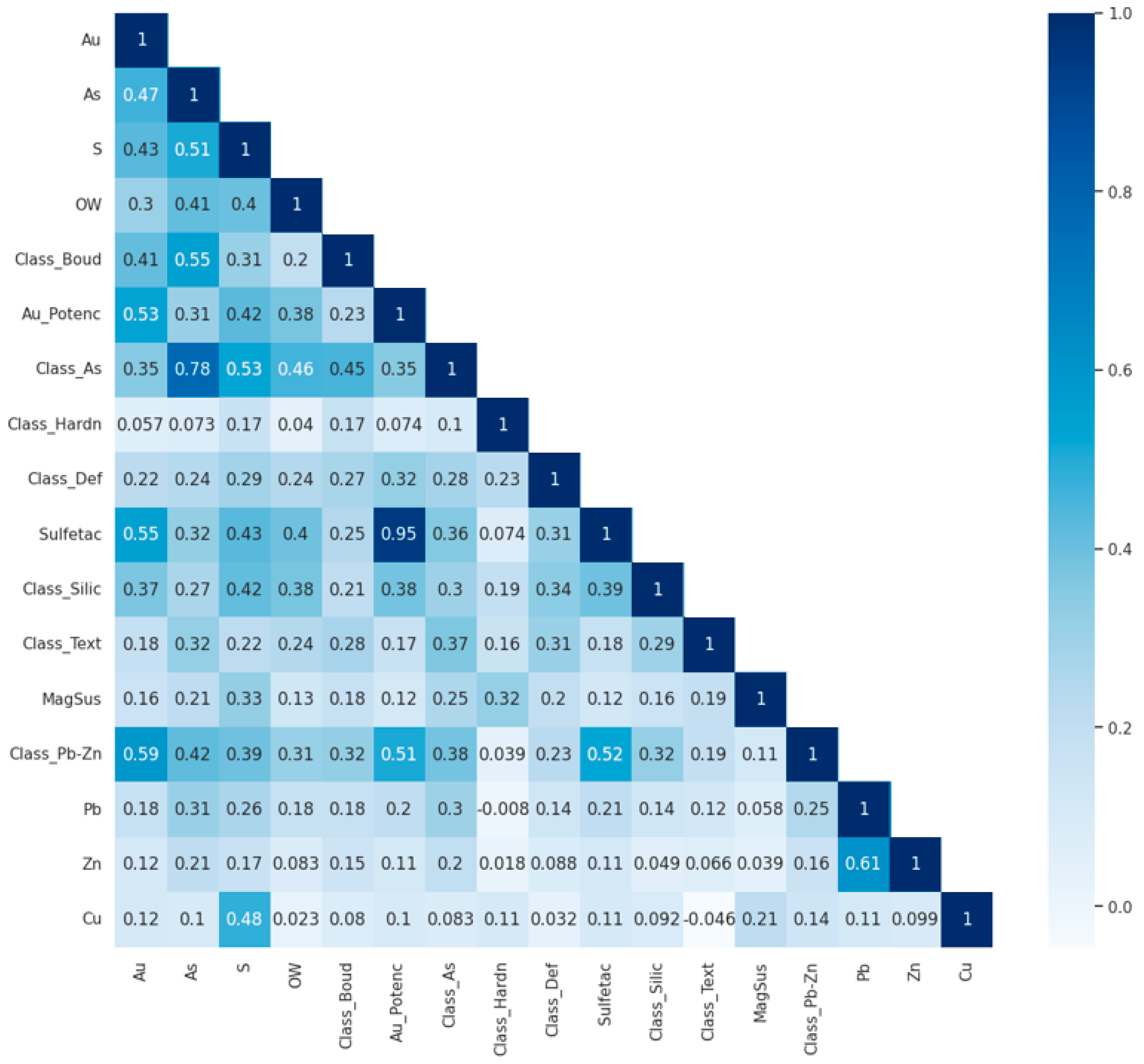
A correlation matrix was used to evaluate the relationships between the chemical and textural variables employed in the classification models (
Figure 3). Categorical variables were ordinally encoded based on geological criteria—for example, frequency-based classes such as boudinage occurrence, arsenopyrite clusters, and sulfidation were classified into Low (1), Medium (2), and High (3). Although Pearson correlation was applied to both numerical and encoded categorical variables, it is important to emphasize that the matrix serves as an exploratory tool. The results should be interpreted with caution, especially for ordinal variables, as Pearson correlation assumes linear relationships and interval-scale data.
Despite this limitation, the matrix allows the visualization of general patterns and interactions among variables. A strong correlation (r = 0.95) was observed between the occurrence of sulfide clusters (Sulfetac), mainly composed of arsenopyrite and pyrite, and the variable representing the potential for gold occurrence (Au_Potenc). This relationship is consistent with the nature of refractory gold ores, where gold is often associated with sulfides, leading to lower recovery rates and the need for more complex processing techniques. Moderate correlations, between 0.5 and 0.7, occur between Pb and Zn classes (Class_Pb-Zn), such as secondary occurrences of galena and sphalerite, sulfidation, and potential occurrence of gold grains. Grade variables such as Au, As, and S are moderately to highly directly correlated with the arsenic class (Class_As), sulfidation, and Class_Boud due to the occurrence of boudins or sulfide clusters (essentially pyrite, arsenopyrite, chalcopyrite, and pyrrhotite) as a covering of these boudins. Another important correlation is the definition between ore and gangue; as expected, they are moderately associated with the contents, but with a significant contribution from the arsenic class, silicification, and potential for the occurrence of gold grains (Au_Potenc).
The As variable is a variable that controls mineralization together with the Au grade. Ref. [
65] discussed the direct relationship between the mineral association of gold particles and arsenic content, along with an increase in the association with arsenopyrite and gold accessibility. However, very low relationships were observed between the Pb, Zn, and Cu content and hardness classes (Class_Hardn) and deformation classes (Class_Def).
The statistical analysis of the dataset is presented in
Table 4, showing the statistics before and after standardization and frequency percentage for the categorical variables boudinage class, potential occurrence of gold based on sulfide agglomerations, occurrence of arsenopyrite particles, hardness having as a parameter whether it is friable or not, deformation, sulfidation, silicification, texture, and occurrence of secondary sulfides such as galena, pyrrhotite, and sphalerite (Class_Pb-Zn).
Standardization is a feature scaling method in which data values are rescaled to fit a distribution between 0 and 1 using mean and standard deviation as a basis for finding specific values. This operation ensures that different features have a similar contribution to machine learning models, preventing variables with different scales influencing the output results.
The hyperparameters for each supervised model tested to classify ore and gangue in the four selected scenarios are summarized in
Table 5. The optimal hyperparameters for ensemble learners (AdaBoost, XGBoost, RF, and DT) are typically composed of a tree-based estimator, with a wide range of learning rates and number of estimators (trees), among the scenarios constructed.
Considering the tree estimator hyperparameter for the four models, the RF presented a higher number of estimators, mainly in scenario 2, with a reduction in the other scenarios. Similar behavior occurred with the AdaBoost, XGBoost, and DT models, with estimators of around 100. An exception can be observed in scenarios 2 and 4 for the AdaBoost model.
Another hyperparameter that presented low variation was the learning rate. The models presented around 0.1 with the exception of the AdaBoost model, which presented a rate varying to 1.
The “max depth” in ML refers to the parameter that limits the maximum depth based on DT estimators. The variation in values means that the model will not perform more divisions beyond this limit, helping to avoid overfitting and excessive model complexity. The value for the maximum depth can significantly impact the model’s performance. Different values were found between 5 and 10 throughout, with lower values for the DT model for scenarios 1, 3, and 4 and scenario 4 for the XGBoost algorithm.
To evaluate the performance of the algorithm, a 10-fold cross-validation was employed to obtain a generalized model that does not overfit on training data. In the cross-validation of the training, the original samples were randomly partitioned into ten equal-sized subsets. One subset was selected as the validation set for testing the model, while the remaining nine subsets served as the training data. This process was repeated ten times, with each of the ten subsets used exactly once as the validation data. The results show that the RF algorithm, in relation to classification accuracy, had slightly better results than XGBoost in all four scenarios analyzed.
4.2. Predictive Performance of ML Models
The evaluation performed in the training and validation stages of all supervised models is shown in
Table 6. In general, the XGBoost models achieved the highest classification scores, followed by the RF, AdaBoost, DT, and finally LR algorithms. Furthermore, among all the scenarios trained, scenario 1 typically achieved the highest metrics, and scenario 4 produced the lowest scores and the largest differences in prediction in the classification of the models. Higher precision and recall values were followed by lower mean absolute error (MSE) values. Finally, the metrics achieved in this evaluation show the best results for the XGBoost scenario 1 model, with an MSE of 0.03 in the training phase. In the evaluated training metrics, the exception occurs in scenario C4 where the RF algorithm slightly outperformed XGBoost.
The results of the ML predictions are shown in
Table 7, considering the entire set of 6730 instances tested. When comparing the five models, the results indicate proximity between the accuracy values achieved by the RF and XGBoost models in the classification. In general, the scenario used with the largest number of variables (scenario C1) also presented the highest scores among all algorithms. In addition, the results achieved also suggested reductions in these scores as the number of variables decreased and in the absence of the variable As (scenarios C2 and C4).
The classification accuracy is the ratio between the number of correct predictions and the total number of input samples. The four scenarios analyzed achieved between 0.75 and 0.96 accuracy, that is, correct predictions. Scenario 1 reached a maximum value of 96% with the intermediate scenarios 3, 4, and 2, presenting a reduction in accuracy compared to scenario C1. Finally, among the algorithms tested, LR presented low precision for the four scenarios, with accuracy ranging from 0.75 (C2) to 0.79 (C1 and C3).
Precision score is a metric that measures the frequency with which a machine learning model correctly predicts the positive class based on the total number of instances in the dataset. The simulation data obtained show that precision had little variation between the RF, AdaBoost, and XGBoost algorithms in scenario C1, going from 0.96 in XGBoost and 0.94 in AdaBoost to 0.93 in RF. The XGBoost algorithm performed best in class (C1), but, on the other hand, had low precision in LR, ranging from 0.71 in class C2 to 0.76 in class C3.
Recall score analysis is a metric that measures how often a machine learning model correctly identifies positive instances (true positives) from all real positive samples in the dataset, giving the correct number of all effective tests that are actually predicted correctly. Among the best classifications, more than 90% were predicted correctly in all four scenarios of XGBoost and RF. The exception was for class C3, where the RF algorithm performed better than XGBoost. Poor performance occurred using the AdaBoost and LR algorithms, showing between 0.76 and 0.88 and 0.75 and 0.79, respectively.
MSE is the mean squared error that is used as the loss function for least squares regression. It is the sum, over all data points, of the square of the difference between the predicted and actual target variables, divided by the number of data points. We can highlight two limitations, one being its sensitivity to outliers; MSE is sensitive to outliers due to the squared error. This can cause extreme values to have a significant impact on the model. To minimize this risk, data standardization is used, as applied in the study. The other is scale dependence, as the magnitude of MSE depends on the scale of the target variable. This can make it challenging to compare MSE values across different datasets. The results presented show a low MSE value for XGBoost in scenario C1 with an average of 0.05. The LR algorithm presented MSE values above the average variation of the other algorithms (>0.20).
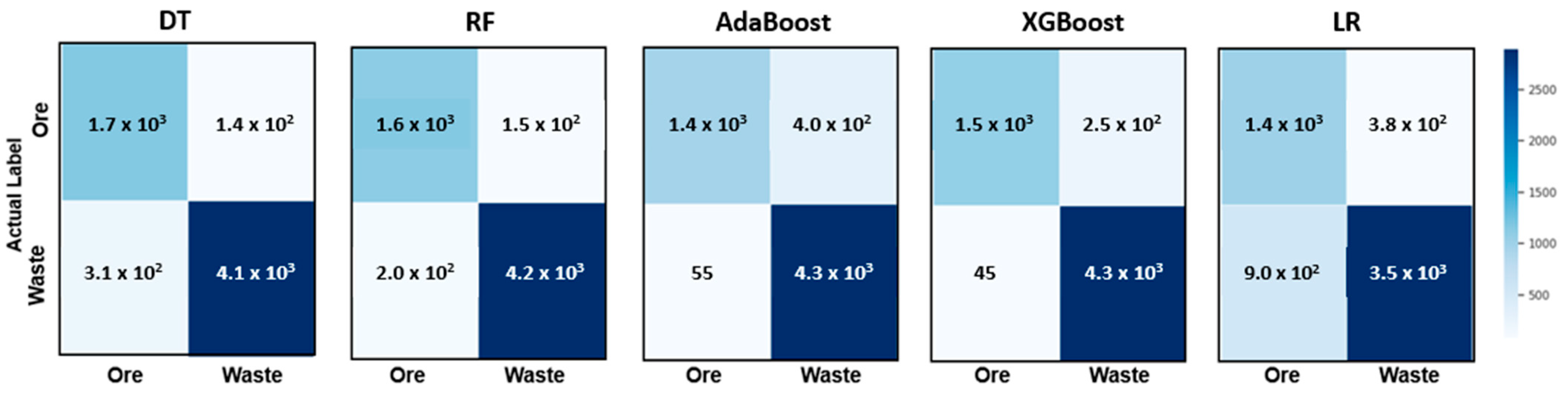
Figure 4 presents the predictions through the confusion matrix for each model for the scenario that contains all input variables (C1). The matrix shows the distribution of the inputs in terms of their original classes and their predicted classes. The matrix is a good tool for visualizing the performance of the classification algorithm in terms of accuracy. The results show that the XGBoost algorithm presented the best performance by assigning the correct predictions (true positive and true negative) for 96% of the estimated base.
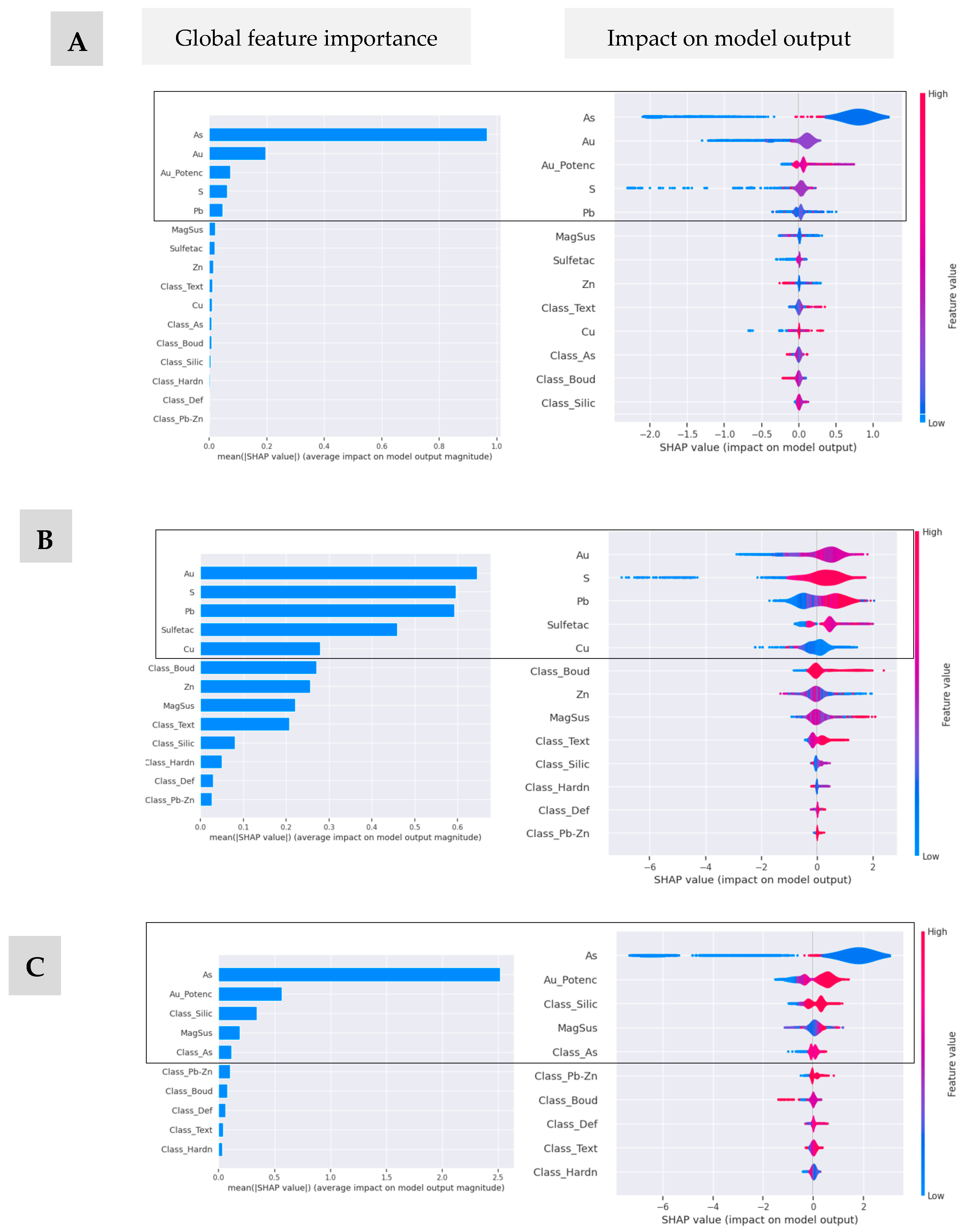
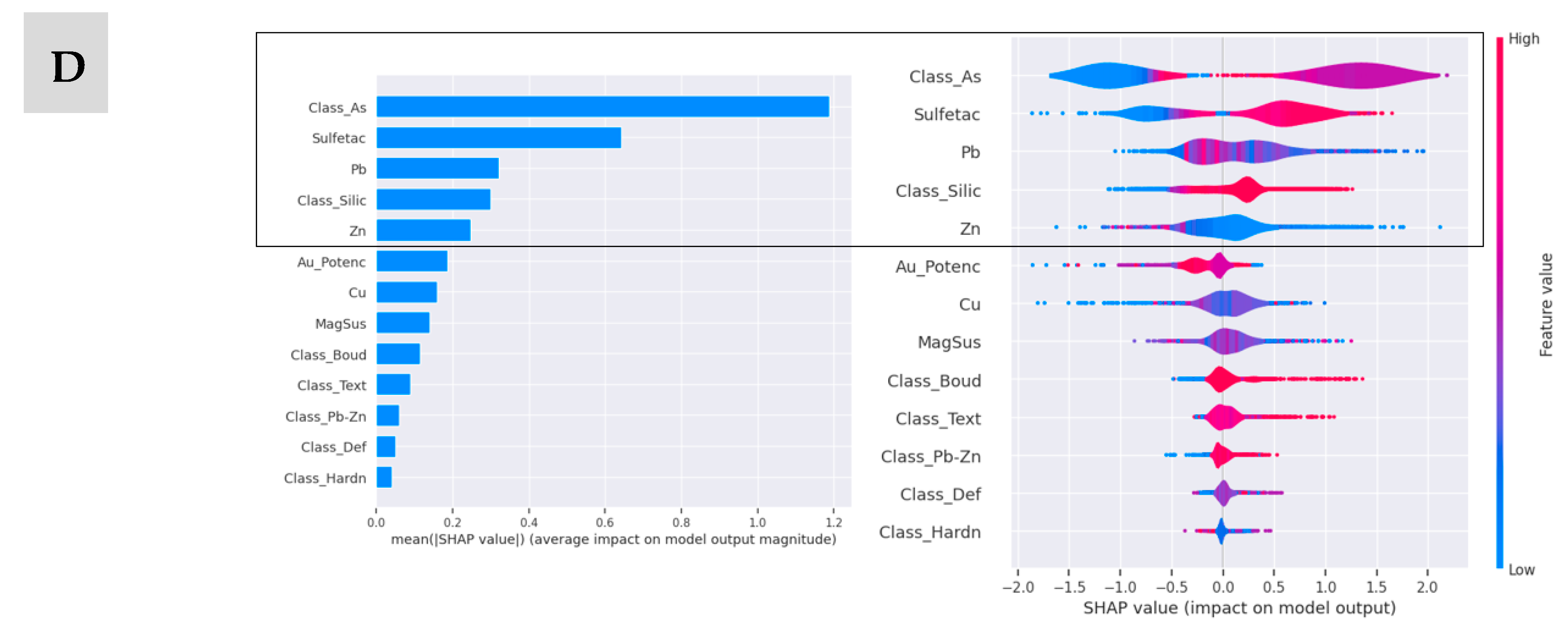
One of the SHAP aspects is the understanding of how a considerable number of numerical and categorical variables (samples) can additively provide explanations for the classified models, since the global and local analysis of the importance of resources can provide insights into the prediction of mineralized levels.
The SHAP values were used to highlight important features and their impact on the classification, which, in a way, can assist in a more detailed analysis of the variable. The results indicate that the variable As was prominent in the predictions, mainly in scenarios C1 and C3. The arsenic class (Class_As), present mainly in scenario C4, had a significant positive weight in the classification. Regarding the impact on the output model, for scenarios C1 and C3, the variable As has a moderate impact in relation to the other input variables. In scenario C2, the variable Au together with S and Pb had a moderate to high positive impact on the prediction of the output model. Finally, in scenario C4, there is a distribution in the impact weights under the classification model among the variables Class_As, Sulfetac, Pb, Class_Silic, and Zn. Important contributions are observed for sulfidation (Sulfetac), potential for gold occurrence in a favorable formation context, such as predominance of boudinage, deformation, and sulfidation.
Figure 5 shows the average impact on model output magnitude and impact on model output for the XGBoost algorithm, which presented the best performance.
In general, some relationships of importance between the variables, the weights in the contribution of the predictions between them are difficult to be perceived by decision makers but are explored and analyzed through these implementations.
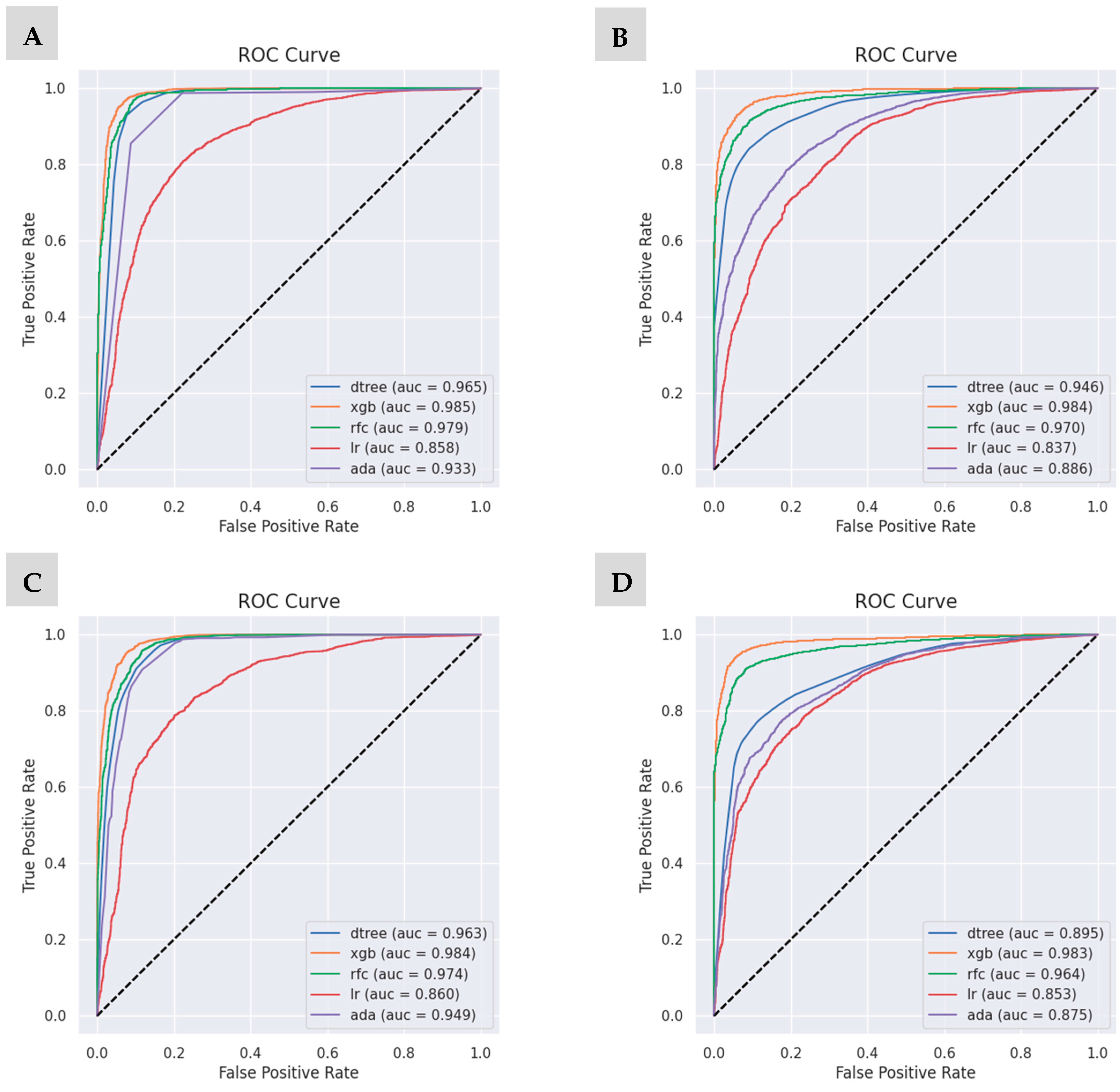
The AUC and ROC curves are used to evaluate the model classification performance of the tested algorithms and are shown in
Figure 6. AUC measures the ability of a binary classifier to distinguish classes and is used as a summary of the ROC curve. In addition, it also measures the quality of the model’s predictions, regardless of the classification threshold.
The results show that the XGBoost approach, scenario C1, obtained the highest AUC of 0.985, indicating that the algorithm performs best in the ore/gangue classification for the set of samples studied but with little variation in the other scenarios tested, as well as RF. The LR algorithm together with AdaBoost had the worst performance, also varying across the scenarios. Scenario C2 showed low performance due to the absence of the lowest weight on the arsenic variable in the prediction







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}