
Bridging Perceived and Actual Data Quality: Automating the Framework for Governance Reliability


Abstract

1. Introduction
1.1. Overview of Advanced Spatial Data Quality Evaluation Techniques
1.2. Data Quality Evaluation and Stakeholder Engagement
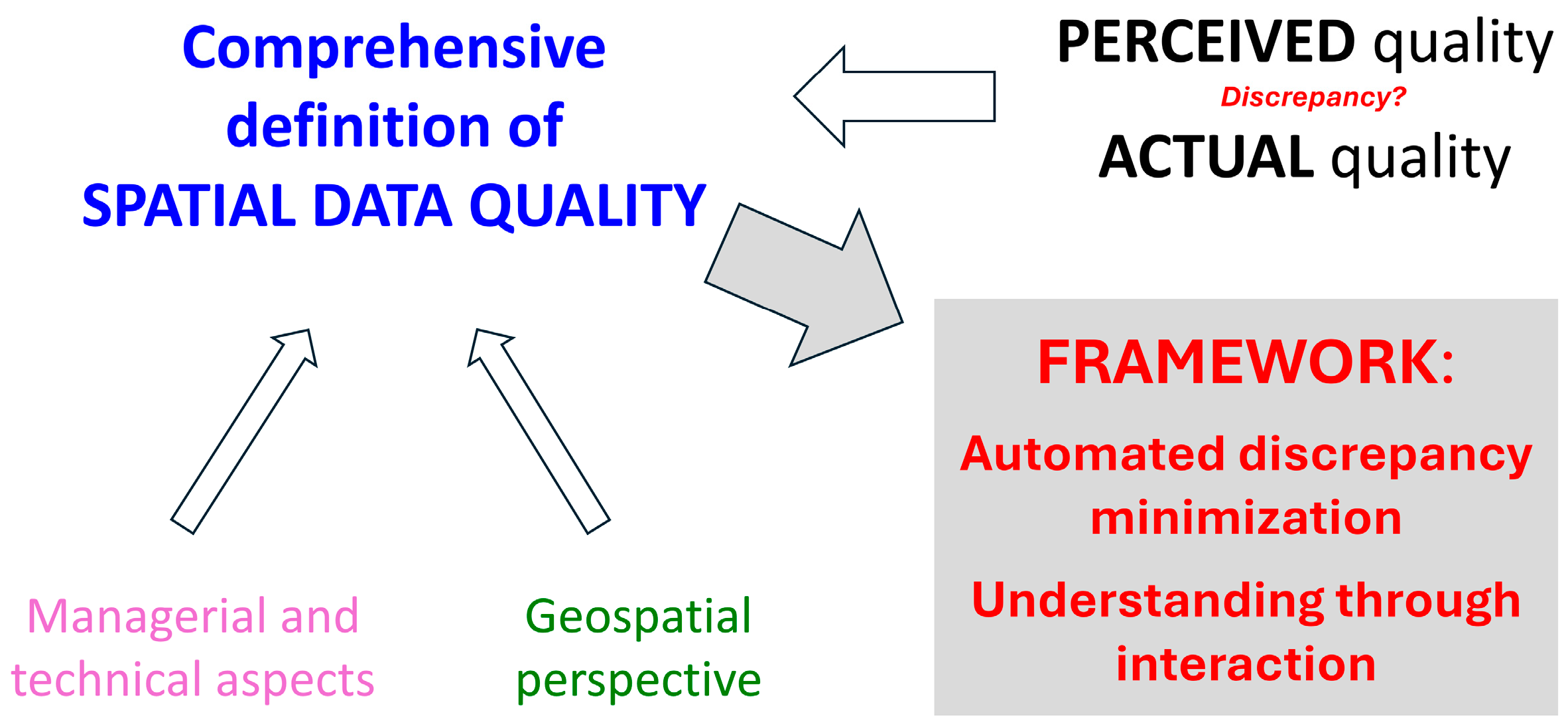
1.3. Problem Statement
2. Materials and Methods
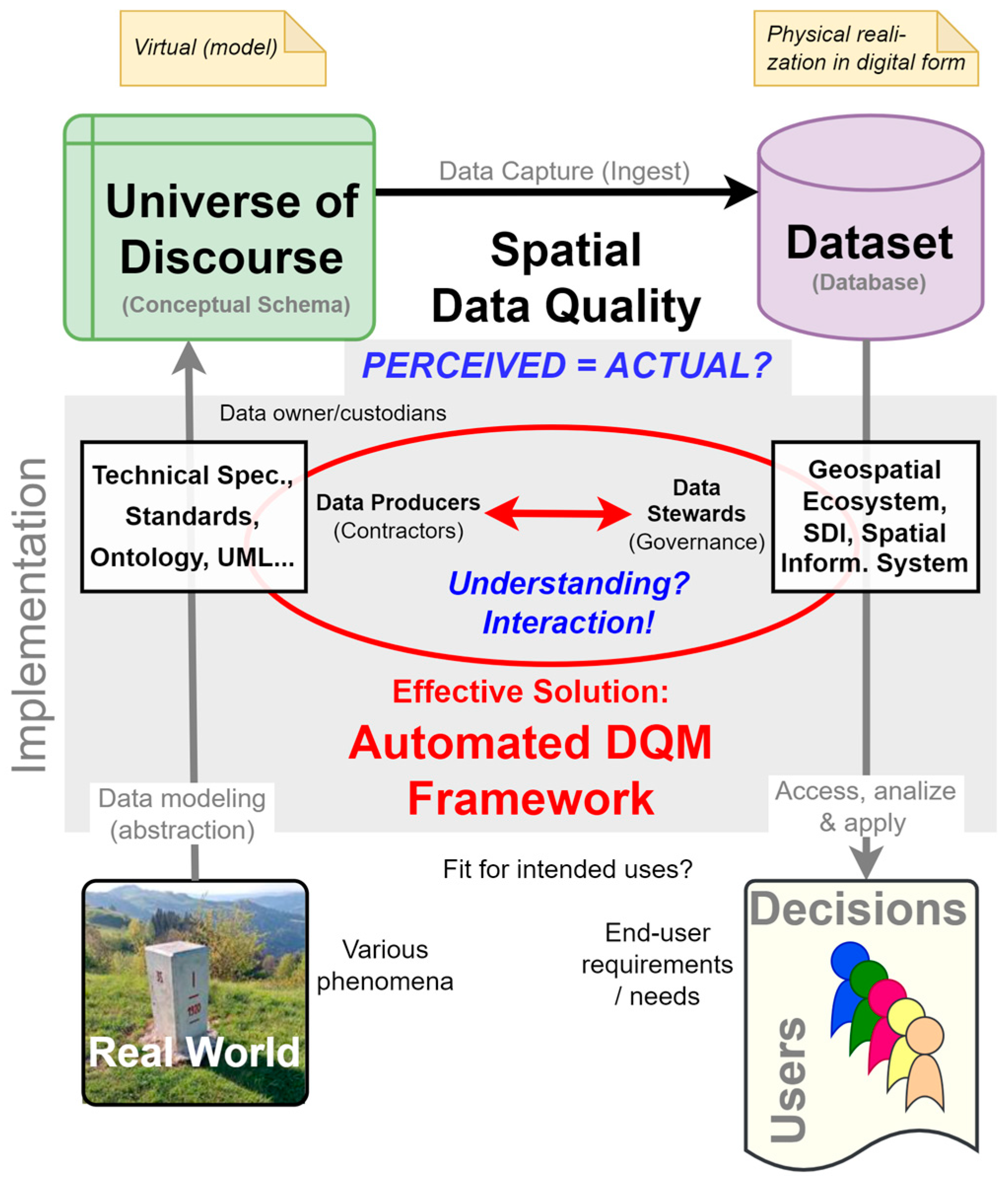
2.1. Technical Definition of Spatial Data Quality
2.2. Integrating Technical and Managerial Aspects of Data Quality
2.3. Geospatial Perspective of Data Quality
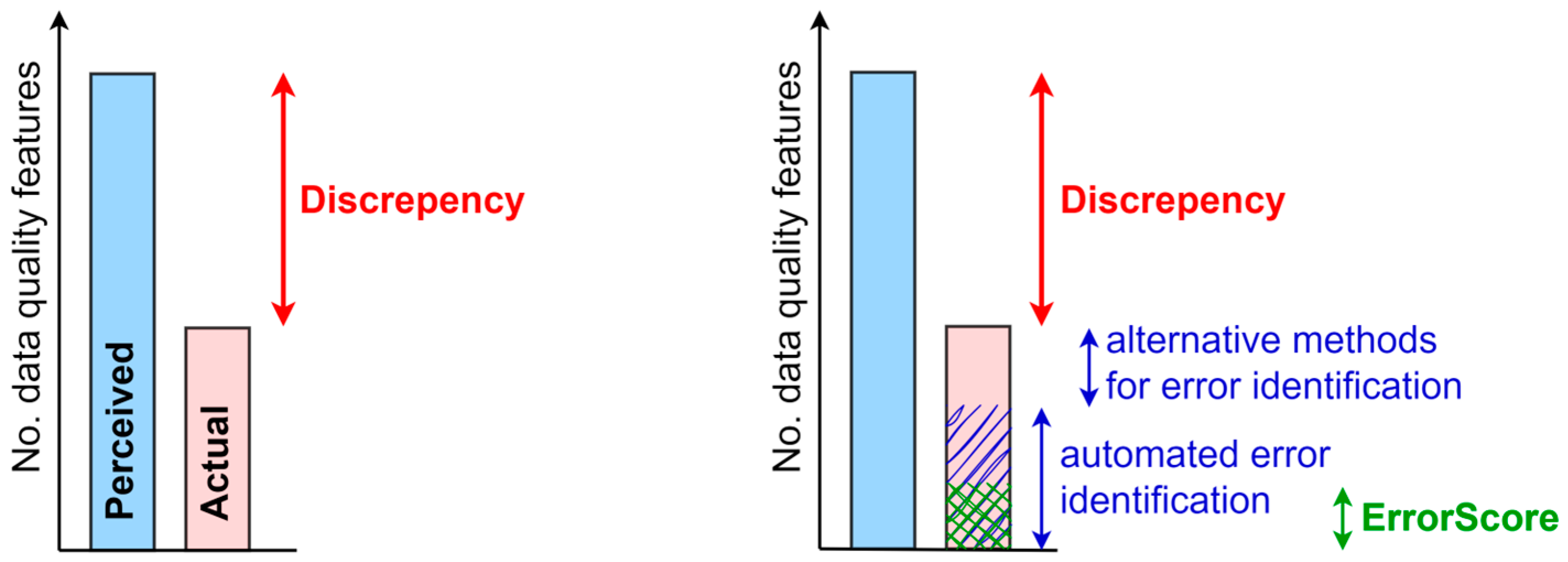
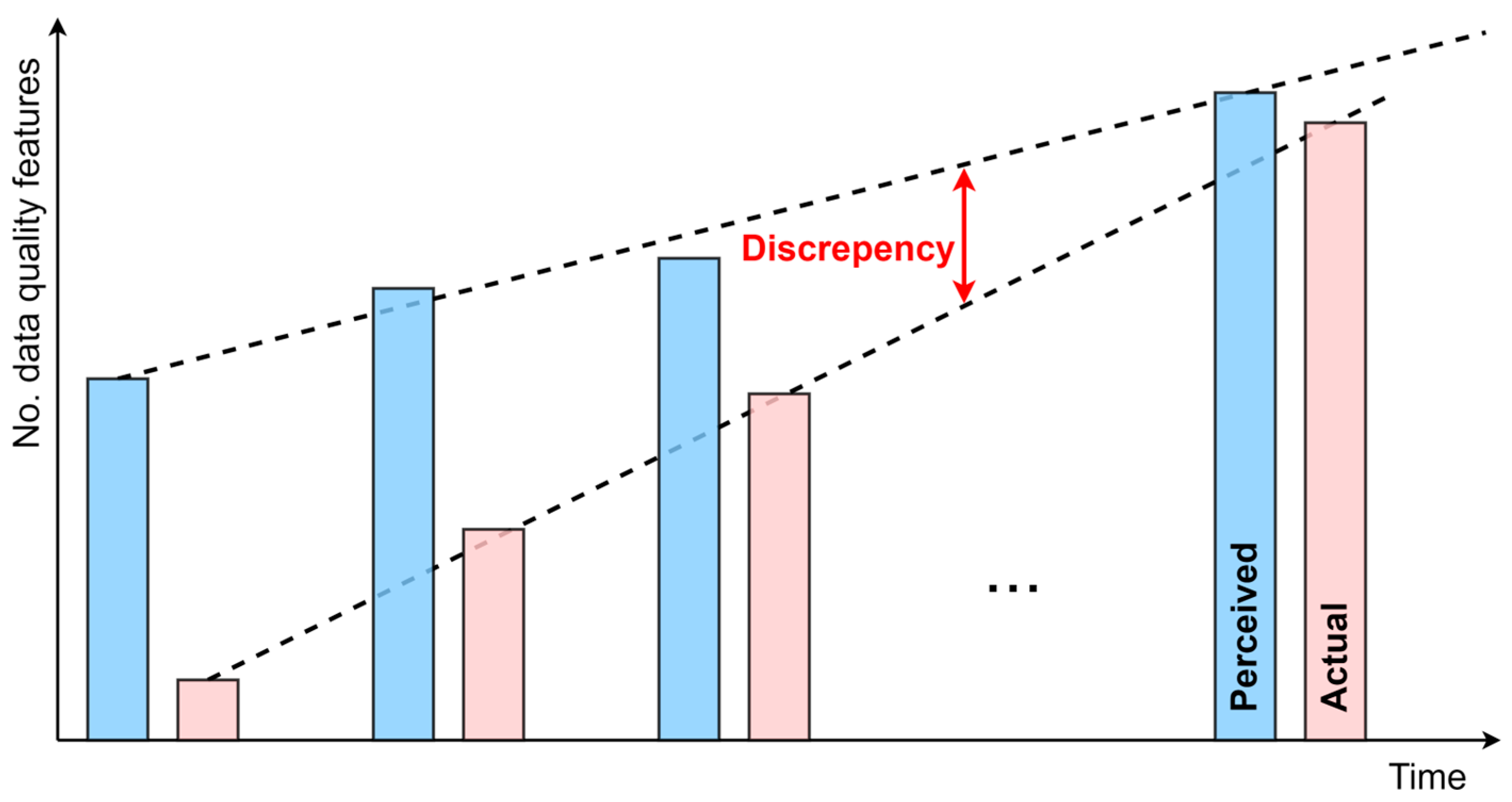
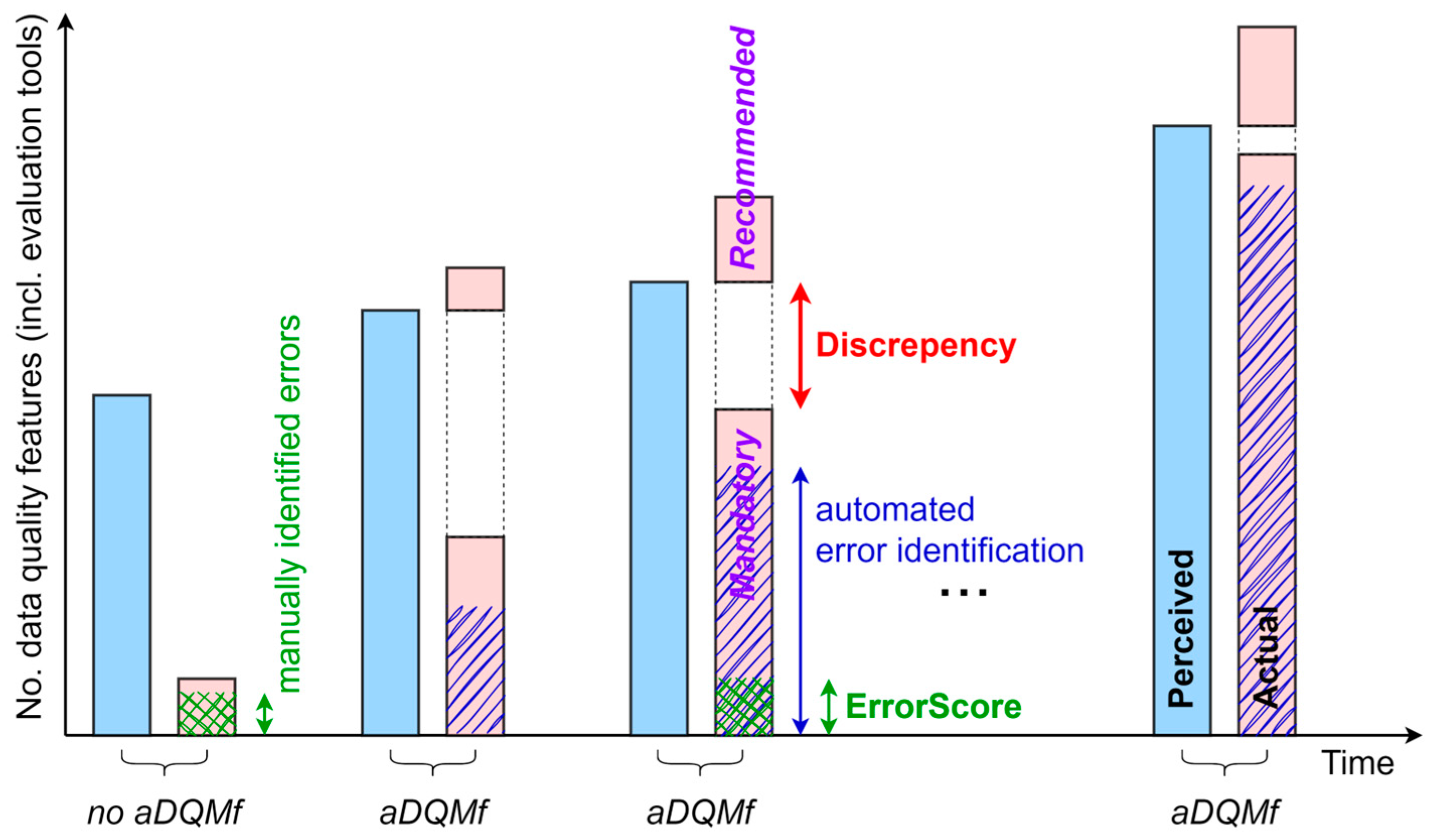
2.4. Understanding Perceived and Actual Data Quality
2.5. Automated DQM Framework Principles
- Reducing the data quality gap minimizes the discrepancy between perceived and actual data quality based on a comprehensive definition of spatial data quality.
- Reliable governance and stakeholder interaction improve stakeholder communication through automated support to enhance governance, ensure shared understanding, improve collaboration, reduce human error, and support continuous education.
- Comprehensive data quality evaluation ensures compliance with policies and standards by integrating management, technical, and geospatial perspectives into a holistic evaluation approach, guaranteeing that data quality is high and aligned with technical specifications.
- Error identification and cleaning utilizes statistical methods and visualization to effectively detect, present, and interpret errors, facilitating efficient data cleaning and quality improvement.
- Enhanced efficiency and integration optimize workflows for spatial data management, ensuring seamless integration into enterprise geospatial systems.
- Advancing DQM maturity strengthens data quality management through continuous automation, governance reliability, and iterative improvements in data quality.
- Scalability and adaptability ensure that technical specifications are continuously refined and that the framework remains flexible and scalable to accommodate evolving data requirements, new datasets, and technological advancements, ensuring long-term sustainability.
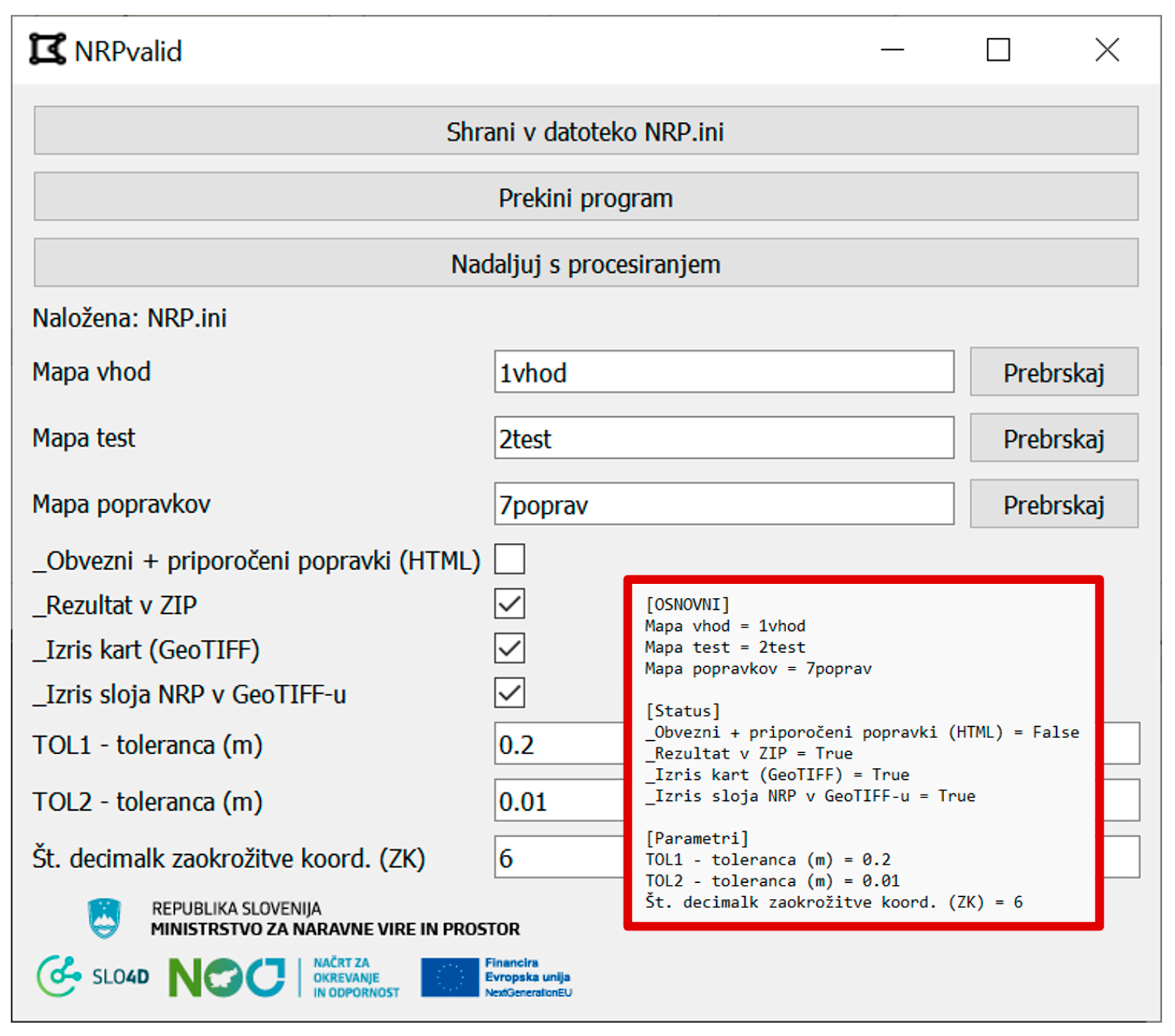
2.6. Toolkit for Automated DQM Framework Implementation
- Design for consistent use by both the data producers and the data stewards who oversee its governance;
- A fully automated data evaluation toolkit built on the QA/QC process and extended with additional capabilities;
- A standalone desktop toolkit, independent of the internet and designed as a cross-platform interaction interface that works independently and is not a plugin or API;
- The use of the toolkit and results does not require the use of GIS or other geospatial tools;
- The design of the toolkit operates seamlessly on all major operating systems and is optimized for execution on any modern computer;
- No toolkit installation and intuitive interfaces to minimize operating instructions;
- Ensures scalability of the toolkit by enabling it to handle increasing amounts of data, computational tasks, and the integration of new databases without significant performance degradation;
- Ongoing adaptation of the toolkit based on collective feedback from diverse stakeholders, particularly domain experts and end users, to optimize performance, address potential conflicts, and align with national and international strategies and plans;
- Minimum number of required configuration parameters for processing;
- Highly efficient algorithms designed to process data and deliver results within expected timeframes;
- Compliance of the implemented methods with the requirements of the technical specifications for data production and international standards;
- Prioritizes end user’s needs, preferences, and workflows to improve usability;
- The robust toolkit design anticipates and warns of unexpected errors without crashing;
- Comprehensive understanding of potential inaccuracies through a combination of descriptive statistics, georeferenced data files, and error visualization.
3. Results
3.1. Data Used
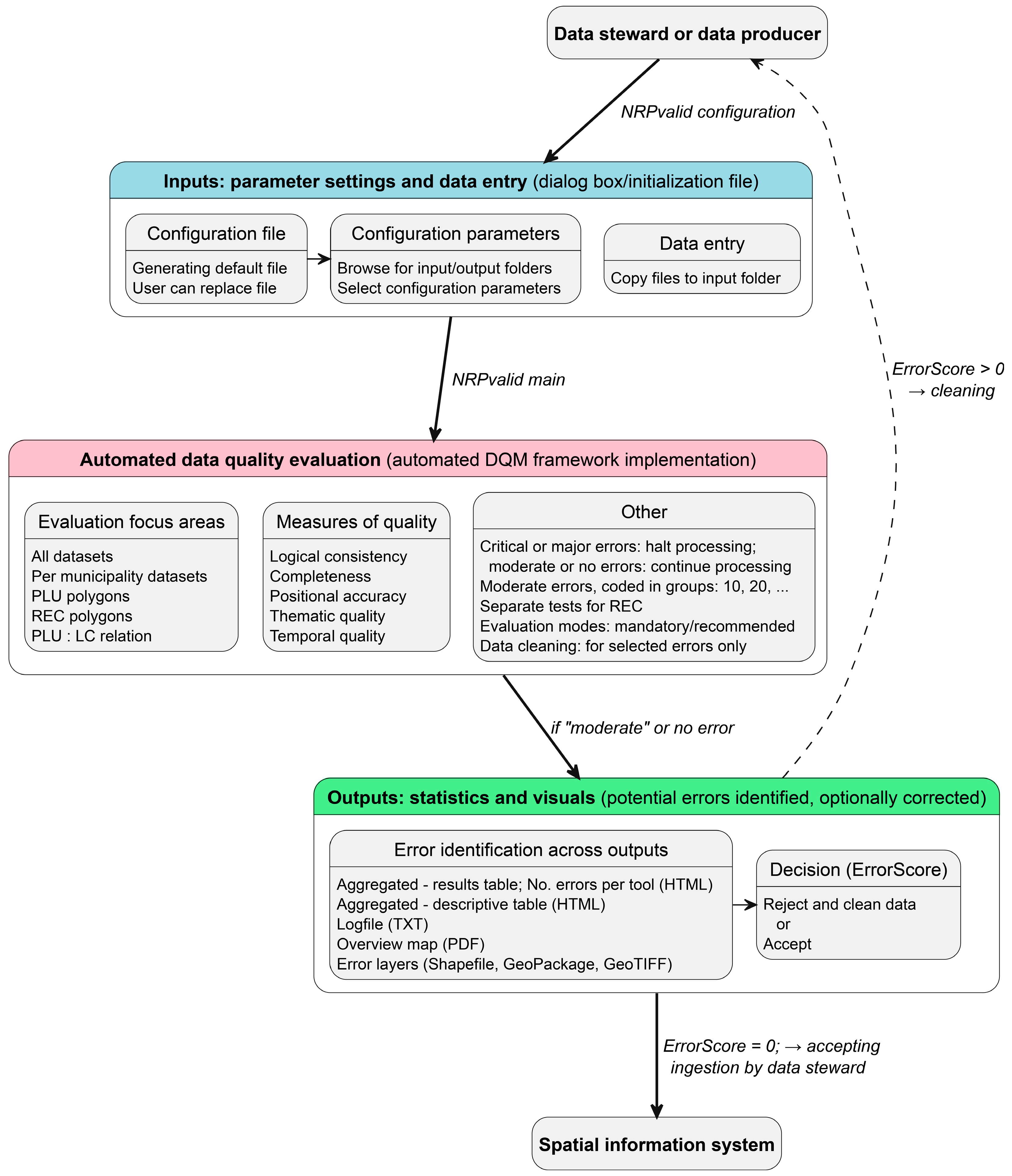
3.2. Functional Design of the Automated DQM Framework
3.3. Deployment of the Automated DQM Framework Within the NRPvalid Toolkit
4. Discussion
4.1. Technical Implications
4.2. Societal and Governance Implications
5. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| API | Application programming interface |
| BIM | Building information modeling |
| CRS | Coordinate reference system |
| DEM | Digital elevation model |
| DQM | Data quality management |
| EPSG | Geodetic parameter registry with codes |
| GIS | Geographic information system |
| ISO | International Organization for Standardization |
| LC | Land Cadaster |
| ML | Machine learning |
| OGC | Open Geospatial Consortium |
| PCA | Principal component analysis |
| PLU | Planned land use |
| QA/QC | Quality assurance/quality control |
| REC | Real Estate Cadaster |
| SDGs | Sustainable Development Goals |
| SDI | Spatial data infrastructure |
| TDQM | Total data quality management |
| t-SNE | t-distributed stochastic neighbor embedding |
| UML | Unified modeling language |
| UN-GGIM | United Nations Committee of Experts on Global Geospatial Information Management |
| UN-IGIF | United Nations Integrated Geospatial Information Framework |
| UTF-8 | Unicode transformation format (8-bit) |
| UX | User experience |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Simplified Expression | Description |
|---|---|
| Planned land use (PLU) polygons | eup_nrp_pos data |
| Land Cadaster (LC) points | tgd data with attributes TGD_VRSTA = 1 |
| Real Estate Cadaster (REC) points | tgd data with attribute NRP_ID = 3000 to 3999 |
| Planned land use (PLU) attribute | eup_nrp_pos data with attributes NRP_ID (land use types of group codes: 1000, 2000, 3000, 4000, 5000) |
| Land Cadaster (LC) attribute | tgd data with attributes TGD_VRSTA = 1 |
| configuration file | *.INI file (NRP.ini, NRP_sablona.ini and others) |
| NRPvalid configuration | NRPvalid_start.exe file |
| NRPvalid core | NRPvalid.exe file |
References
- Nagle, T.; Redman, T.C.; Sammon, D. Only 3% of Companies’ Data Meets Basic Quality Standards. Harv. Bus. Rev. 2017, 98, 2–5. Available online: https://hbr.org/2017/09/only-3-of-companies-data-meets-basic-quality-standards (accessed on 8 December 2024).
- Deming, W.E. Elementary Principles of the Statistical Control of Quality: A Series of Lectures; Nippon Kagaku Gijutsu Remmei: Tokyo, Japan, 1950; p. 103. [Google Scholar]
- Fujimaki, R. Most Data Science Projects Fail, But Yours Doesn’t Have To. BigDATAwire. 2020. Available online: https://www.bigdatawire.com/2020/10/01/most-data-science-projects-fail-but-yours-doesnt-have-to/ (accessed on 7 December 2024).
- Goodchild, M.F.; Li, L. Assuring the Quality of Volunteered Geographic Information. Spat. Stat. 2012, 1, 110–120. [Google Scholar] [CrossRef]
- MXavier, E.M.A.; Ariza-López, F.J.; Ureña-Cámara, M.A. Automatic Evaluation of Geospatial Data Quality Using Web Services. Rev. Cartográfica 2019, 98, 59–73. [Google Scholar] [CrossRef]
- ISO 19157-1:2023(En); Geographic Information—Data Quality—Part 1: General Requirements. ISO: Geneva, Switzerland, 2023.
- Parslow, P.; Jamieson, A. 30 Years of Geospatial Standards. GIM Int. 2024, 3, 28–30. [Google Scholar]
- OGC (Open Geospatial Consortium). Available online: https://www.ogc.org/ (accessed on 7 December 2024).
- GIS Data Quality Management & Validation|ArcGIS Data Reviewer. Available online: https://www.esri.com/en-us/arcgis/products/arcgis-data-reviewer/overview (accessed on 15 December 2024).
- Follin, J.-M.; Girres, J.-F.; Olteanu Raimond, A.-M.; Sheeren, D. The Origins of Imperfection in Geographic Data; Wiley: Hoboken, NJ, USA, 2019; pp. 25–44. ISBN 978-1-78630-297-7. [Google Scholar]
- Nassif, A.B.; Talib, M.A.; Nasir, Q.; Dakalbab, F.M. Machine Learning for Anomaly Detection: A Systematic Review. IEEE Access 2021, 9, 78658–78700. [Google Scholar] [CrossRef]
- Chen, D. Reviewing Methods for Controlling Spatial Data Quality from Multiple Perspectives. Geosci. Remote Sens. 2022, 5, 22–27. [Google Scholar] [CrossRef]
- Heuvelink, G.B.M. Error Propagation in Environmental Modelling With GIS, 1st ed.; CRC Press: Boca Raton, FL, USA, 1998; p. 146. [Google Scholar]
- Podobnikar, T. Simulation and Representation of the Positional Errors of Boundary and Interior Regions in Maps. In Geospatial Vision: New Dimensions in Cartography; Moore, A., Drecki, I., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 141–169. ISBN 978-3-540-70970-1. [Google Scholar]
- Devillers, R.; Bédard, Y.; Jeansoulin, R. Multidimensional Management of Geospatial Data Quality Information for Its Dynamic Use Within GIS. Photogramm. Eng. Remote Sens. 2005, 71, 205–215. [Google Scholar] [CrossRef]
- Kersting, K.; De Raedt, L. Basic Principles of Learning Bayesian Logic Programs. In Probabilistic Inductive Logic Programming: Theory and Applications; De Raedt, L., Frasconi, P., Kersting, K., Muggleton, S., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2008; pp. 189–221. ISBN 978-3-540-78652-8. [Google Scholar]
- Fotheringham, S.A.; Rogerson, P.A. The SAGE Handbook of Spatial Analysis, 1st ed.; SAGE Publications, Ltd.: London, UK, 2009; ISBN 978-0-85702-013-0. [Google Scholar]
- Yılmaz, C.; Cömert, Ç.; Yıldırım, D. Ontology-Based Spatial Data Quality Assessment Framework. Appl. Sci. 2024, 14, 10045. [Google Scholar] [CrossRef]
- Podobnikar, T. Methods for Visual Quality Assessment of a Digital Terrain Model. SAPIENS Surv. Perspect. Integrating Environ. Soc. 2009, 2, 10. [Google Scholar]
- Grieves, M.; Vickers, J. Digital Twin: Mitigating Unpredictable, Undesirable Emergent Behavior in Complex Systems. In Transdisciplinary Perspectives on Complex Systems: New Findings and Approaches; Kahlen, F.-J., Flumerfelt, S., Alves, A., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 85–113. ISBN 978-3-319-38756-7. [Google Scholar]
- Yanenko, O.; Schlieder, C. Game Principles for Enhancing the Quality of User-Generated Data Collections. In Proceedings of the 17th AGILE Conference on Geographic Information Science, Castellón, Spain, 3–6 June 2014. [Google Scholar]
- Sui, D.; Elwood, S.; Goodchild, M. (Eds.) Crowdsourcing Geographic Knowledge: Volunteered Geographic Information (VGI) in Theory and Practice; Springer: Dordrecht, The Netherlands, 2013; ISBN 978-94-007-4586-5. [Google Scholar]
- Mooney, P.; Corcoran, P. The Annotation Process in OpenStreetMap. Trans. GIS 2012, 16, 561–579. [Google Scholar] [CrossRef]
- Ataman, A. Data Quality in AI: Challenges, Importance & Best Practices. Available online: https://research.aimultiple.com/data-quality-ai/ (accessed on 8 December 2024).
- Chafiq, T.; Azmi, R.; Fadil, A.; Mohammed, O. Investigating the Potential of Blockchain Technology for Geospatial Data Sharing: Opportunities, Challenges, and Solutions. Geomatica 2024, 76, 100026. [Google Scholar] [CrossRef]
- Podobnikar, T. Production of Integrated Digital Terrain Model from Multiple Datasets of Different Quality. Int. J. Geogr. Inf. Sci. 2005, 19, 69–89. [Google Scholar] [CrossRef]
- Vaddi, R.; Phaneendra Kumar, B.L.N.; Manoharan, P.; Agilandeeswari, L.; Sangeetha, V. Strategies for Dimensionality Reduction in Hyperspectral Remote Sensing: A Comprehensive Overview. Egypt. J. Remote Sens. Space Sci. 2024, 27, 82–92. [Google Scholar] [CrossRef]
- Shivaprasad, N. Enhancing Data Quality through Automated Data Profiling. Int. J. Res. Publ. Semin. 2024, 15, 108–117. [Google Scholar] [CrossRef]
- Thumburu, S.K.R. Real-Time Data Quality Monitoring and Remediation in EDI. Adv. Comput. Sci. 2021, 4, 21. [Google Scholar]
- Ariza López, F.J.; Barreira González, P.; Masó Pau, J.; Zabala Torres, A.; Rodríguez Pascual, A.F.; Moreno Vergara, G.; García Balboa, J.L. Geospatial Data Quality (ISO 19157-1): Evolve or Perish. Rev. Cartográfica 2020, 100, 129–154. [Google Scholar] [CrossRef]
- Kruger, J.; Dunning, D. Unskilled and Unaware of It: How Difficulties in Recognizing One’s Own Incompetence Lead to Inflated Self-Assessments. J. Pers. Soc. Psychol. 1999, 77, 1121–1134. [Google Scholar] [CrossRef] [PubMed]
- Devillers, R.; Stein, A.; Bédard, Y.; Chrisman, N.; Fisher, P.; Shi, W. Thirty Years of Research on Spatial Data Quality: Achievements, Failures, and Opportunities. Trans. GIS 2010, 14, 387–400. [Google Scholar] [CrossRef]
- Hayes, G.E.; Romig, H.G. Modern Quality Control; Macmillan Pub Co.: Sydney, Australia, 1977; p. 874. ISBN 978-0-02-802910-8. [Google Scholar]
- ISO 9000; Family—Quality Management. ISO: Geneva, Switzerland, 2021.
- Egenhofer, M.J.; Mark, D.M. Naive Geography. In Spatial Information Theory: A Theoretical Basis for GIS; Frank, A.U., Kuhn, W., Eds.; Springer: Berlin/Heidelberg, Germany, 1995; pp. 1–15. [Google Scholar]
- Ehrlinger, L.; Wöß, W. A Survey of Data Quality Measurement and Monitoring Tools. Front. Big Data 2022, 5, 850611. [Google Scholar] [CrossRef] [PubMed]
- Sakpal, M. 12 Actions to Improve Your Data Quality. Available online: https://www.gartner.com/smarterwithgartner/how-to-improve-your-data-quality (accessed on 16 December 2024).
- Nolasco, H.R.; Vargo, A.; Komatsu, Y.; Iwata, M.; Kise, K. Perception Versus Reality: How User Self-Reflections Compare to Actual Data. In Proceedings of the Human-Computer Interaction—INTERACT 2023, York, UK, 28 August–1 September 2023; pp. 665–674. [Google Scholar]
- Spatial Information System. Available online: https://pis.eprostor.gov.si/en/pis/predstavitev-sistema.html?changeLang=true (accessed on 20 September 2024).
- INSPIRE Maintenance and Implementation Group (MIG). INSPIRE Data Specification on Land Use—Technical Guidelines; INSPIRE: Brussels, Belgium, 2024. [Google Scholar]
- Ministry of Natural Resources and Spatial Planning. Technical Rules for the Preparation of Municipal Spatial Acts in Digital Form (Tehnična Pravila za Pripravo Občinskih Prostorskih Izvedbenih Aktov v Digitalni Obliki); Ministry of Natural Resources and Spatial Planning: Ljubljana, Slovenia, 2024.
- Selmy, S.A.H.; Kucher, D.E.; Yang, Y.; García-Navarro, F.J.; Selmy, S.A.H.; Kucher, D.E.; Yang, Y.; García-Navarro, F.J. Geospatial Data: Acquisition, Applications, and Challenges; IntechOpen: London, UK, 2024; ISBN 978-1-83769-828-8. [Google Scholar]
- Haining, R. (Ed.) Data Quality: Implications for Spatial Data Analysis. In Spatial Data Analysis: Theory and Practice; Cambridge University Press: Cambridge, UK, 2003; pp. 116–178. ISBN 978-0-521-77437-6. [Google Scholar]
- Romano, A. Synthetic Geospatial Data and Fake Geography: A Case Study on the Implications of AI-Derived Data in a Data-Intensive Society. Digit. Geogr. Soc. 2025, 8, 100108. [Google Scholar] [CrossRef]
- Southekal, P. Data for Business Performance: The Goal-Question-Metric (GQM) Model to Transform Business Data into an Enterprise Asset, 1st ed.; Technics Publications: Basking Ridge, NJ, USA, 2017; p. 316. ISBN 978-1-63462-184-7. [Google Scholar]
- ISO 19157-3; Geographic Information—Data Quality—Part 3: Data Quality Measures Register. ISO: Geneva, Switzerland, 2025.
- Parry-Jones, C. Data Quality Doesn’t Need to Be Complicated: Three Zero-Cost Solutions That Take Hours, Not Months. Data Sci. 2024. Available online: https://towardsdatascience.com/stop-overcomplicating-data-quality-4569fc6d35a4 (accessed on 16 December 2024).
- Taylor, F.W. The Principles of Scientific Management; Harper: New York, NY, USA, 1913; p. 156. [Google Scholar]


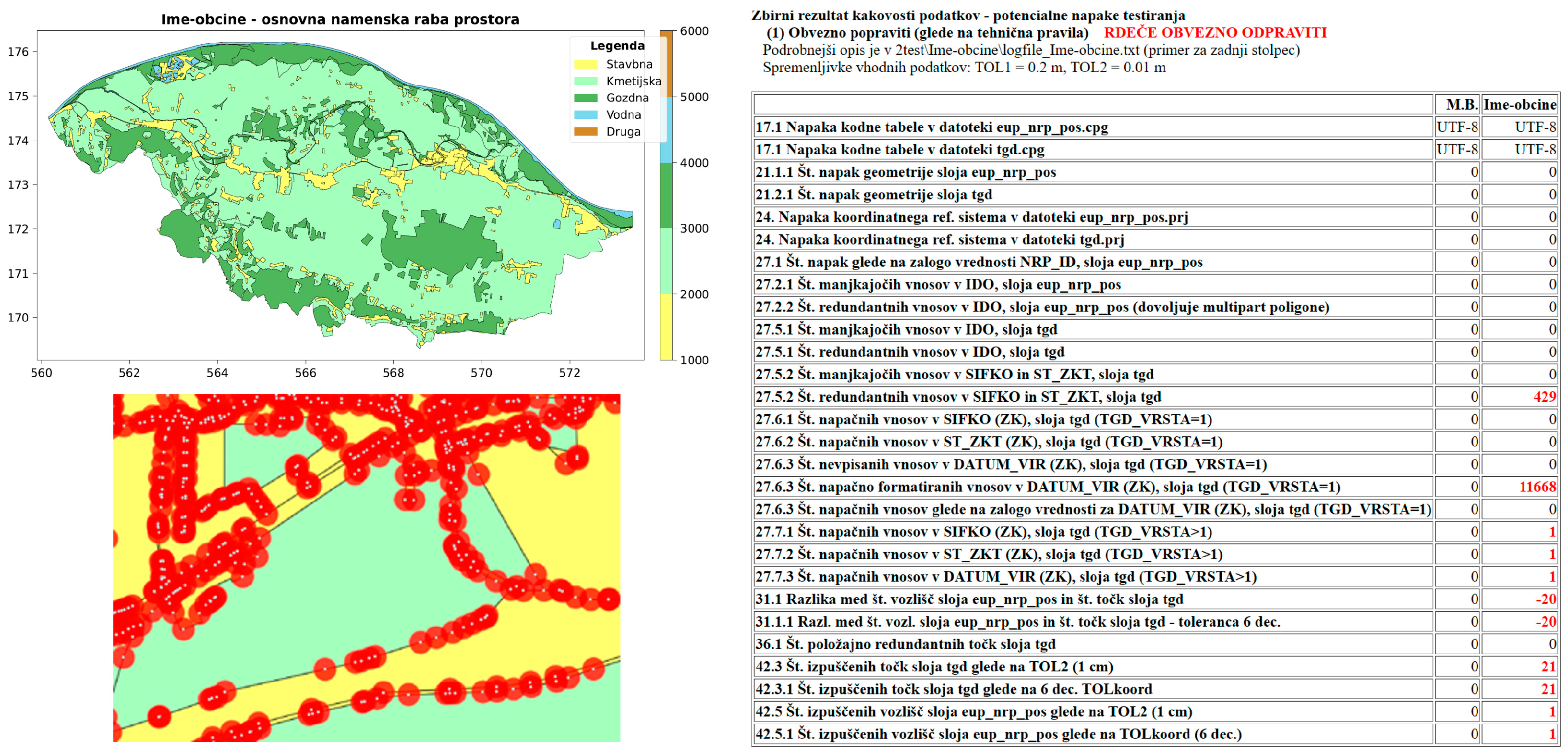
| Coded Group | Measure/Element | Tool | Focus Area |
|---|---|---|---|
| 10 | completeness | file presence | all datasets |
| . | logical consistency | format, readability | configuration file, all datasets |
| . | logical consistency | UTF-8, Windows-1250 | per municipality datasets |
| 20 | logical consistency | geometry, topology | per municipality datasets |
| . | logical consistency | data schema/attribute type | per municipality datasets |
| . | logical/thematic | attribute domain | per municipality (attributes) |
| . | completn./temporal | missing/duplicate/invalid val. | per municipality datasets |
| . | logical consistency | CRS parameters | per municipality datasets |
| 30 | completeness | counting | PLU and LC datasets |
| . | positional accuracy | counting | PLU and LC datasets |
| . | completeness | duplicates, matching | PLU and LC datasets |
| 40 | completeness | different No. points | relation PLU: LC |
| . | positional accuracy | matching with diff. tolerances | relation PLU: LC |
| 100 | logical consistency | verification coord. rounding | per PLU attribute |
| . | completeness | descriptive statistics | per PLU attribute |
| . | completeness | descriptive statistics | all/LC attribute |
| 900 | (data cleaning) | UTF-8, CRS, data schema | per municipality datasets |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Podobnikar, T. Bridging Perceived and Actual Data Quality: Automating the Framework for Governance Reliability. Geosciences 2025, 15, 117. https://doi.org/10.3390/geosciences15040117
Podobnikar T. Bridging Perceived and Actual Data Quality: Automating the Framework for Governance Reliability. Geosciences. 2025; 15(4):117. https://doi.org/10.3390/geosciences15040117
Chicago/Turabian StylePodobnikar, Tomaž. 2025. "Bridging Perceived and Actual Data Quality: Automating the Framework for Governance Reliability" Geosciences 15, no. 4: 117. https://doi.org/10.3390/geosciences15040117
APA StylePodobnikar, T. (2025). Bridging Perceived and Actual Data Quality: Automating the Framework for Governance Reliability. Geosciences, 15(4), 117. https://doi.org/10.3390/geosciences15040117