

A Feature-Informed Data-Driven Approach for Predicting Maximum Flood Inundation Extends



Abstract
:1. Introduction
2. Materials and Methods
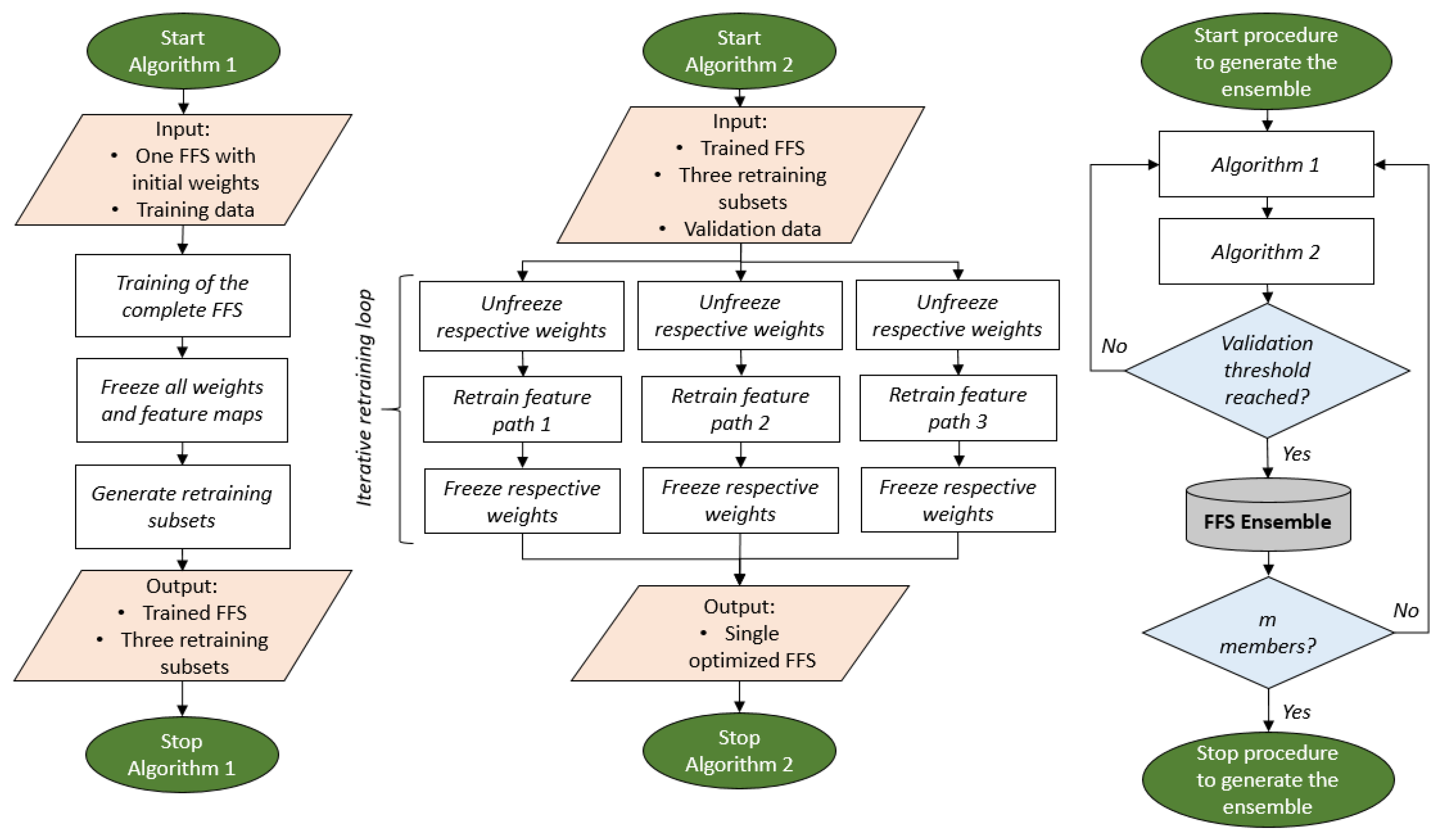
2.1. Framework of the Feature-Informed Forecast System (FFS)
- The hybrid database of this study was generated by Crotti et al. [6] (see Section 2.6). The hydrological model LARSIM (Large Area Runoff Simulation Model) [20] was used by the authors to generate synthetic, real-based, and historical discharge scenarios for three rivers, which were flowing into and through the study area. These scenarios were simulated with the hydrodynamic model HEC-RAS 2D (Hydrologic Engineering Center—River Analysis System, Davis, CA, USA) [21] to obtain the corresponding maximum water levels in the catchment area as an inundation map.
- As we follow an image-to-image strategy as a forecasting process, the time series of the hydrographs have to be converted so they can be presented to the feature-based data-driven model as images, which are later then translated into the corresponding inundation map. Therefore, the time series, are converted into a tensor with the size 14 × 14 × R, where R describes the numbers of hydrographs. In our study, R is equal to three. Nevertheless, other study areas may require different values of R. The 14 × 14 size, is the minimum size, necessary to make effective use of the convolutional operations. Smaller sizes lead to a 1 × 1 image size during the convolutional downsampling operations. Larger image sizes can be used without loss of accuracy or relevance of the modeling. For filling the image cells, the first timestep of the series is then placed into position 1 × 1 × 1, where the second timestep is placed into 1 × 2 × 1, and so on until the entire hydrograph is used up. A similar approach is used in the study of Kimura et al., 2019 [10];
- The images from stage 2 are then fed into the feature-informed data-driven model, described in Section 2.2. This model translates these images into the upcoming inundation map. The architecture allows the integration of spatial and physical prior knowledge into the network. The model is trained, validated, and tested with the hybrid database from step 1, whereby the resolution of the prediction within the study area is given by the resolution of the respective hydrodynamic model used for generating the database. After training and validation, the data-driven model is able to replace the 2-dimensional flood model and can be used for real-time forecasting.
2.2. Feature-Informed Data-Driven Approach
- residual Convolutional Neural Network with 50 layers (ResNets50),
- the feature-informed Dense Layers.
- feature 1: cells that are in a range of 150 m to a river;
- feature 2: cells that are in a range of 150 to 400 m to a river;
- feature 3: cells that are farther than 400 m away from a river.
2.3. Optimization and Ensemble Approach
2.4. Model Evaluation Criteria
2.5. Study Site
2.6. Dataset for Training, Validation, and Testing the Forecast System
3. Results
3.1. Training Durations and Validation Accuracy
3.2. Performance of the Feature-Informed Forecast System
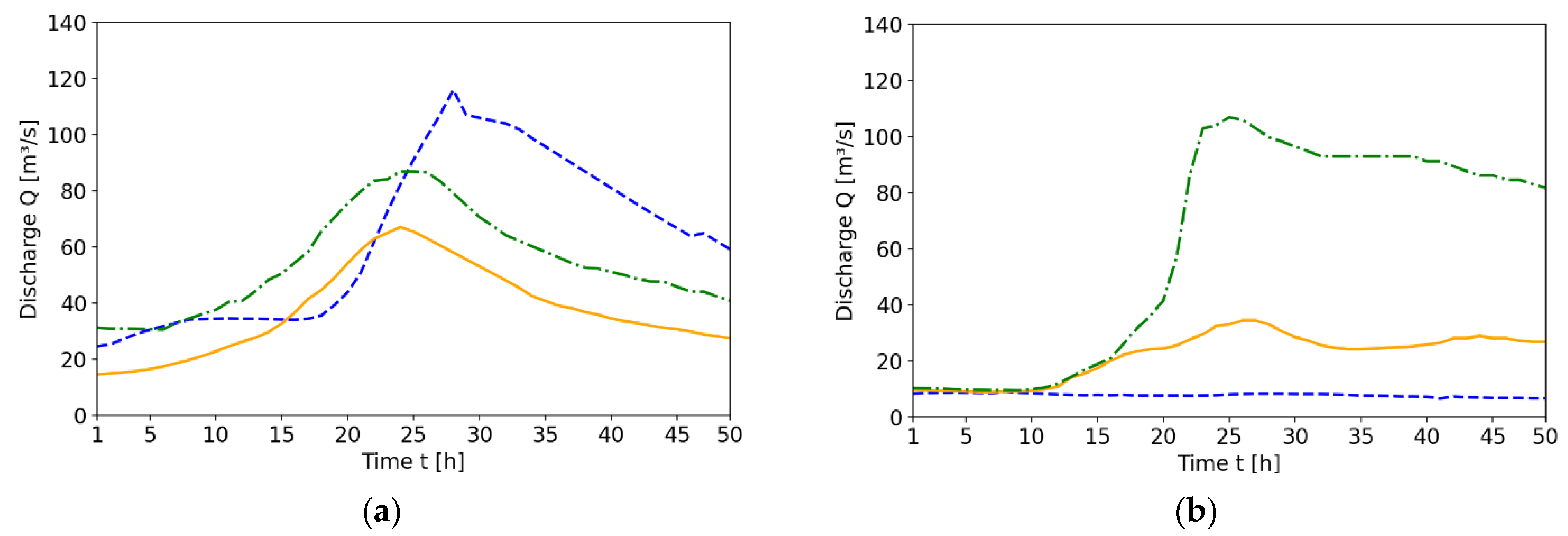
3.2.1. Overall Performance
3.2.2. Comparison of the Individual Feature Performance on the Observed Events
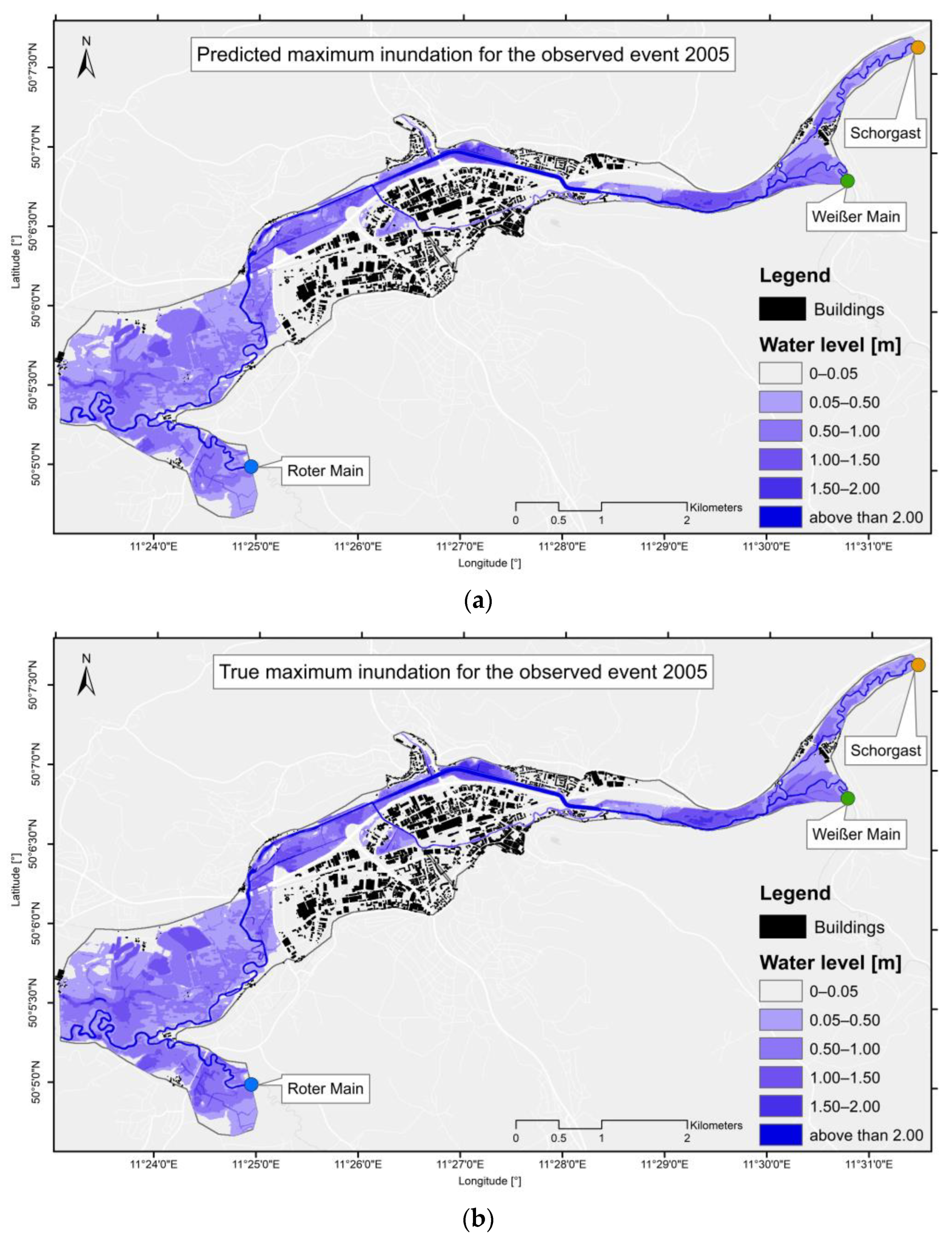
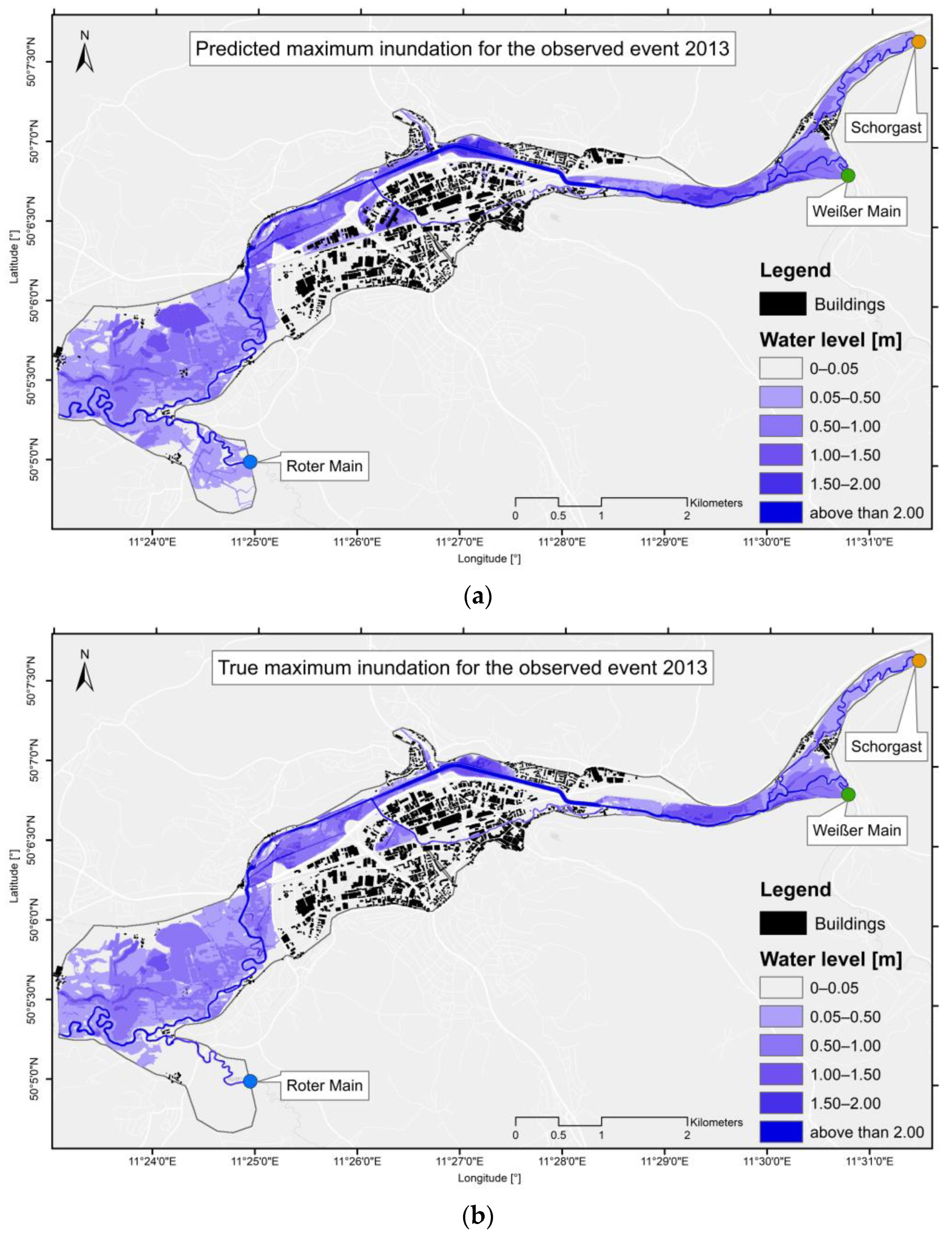
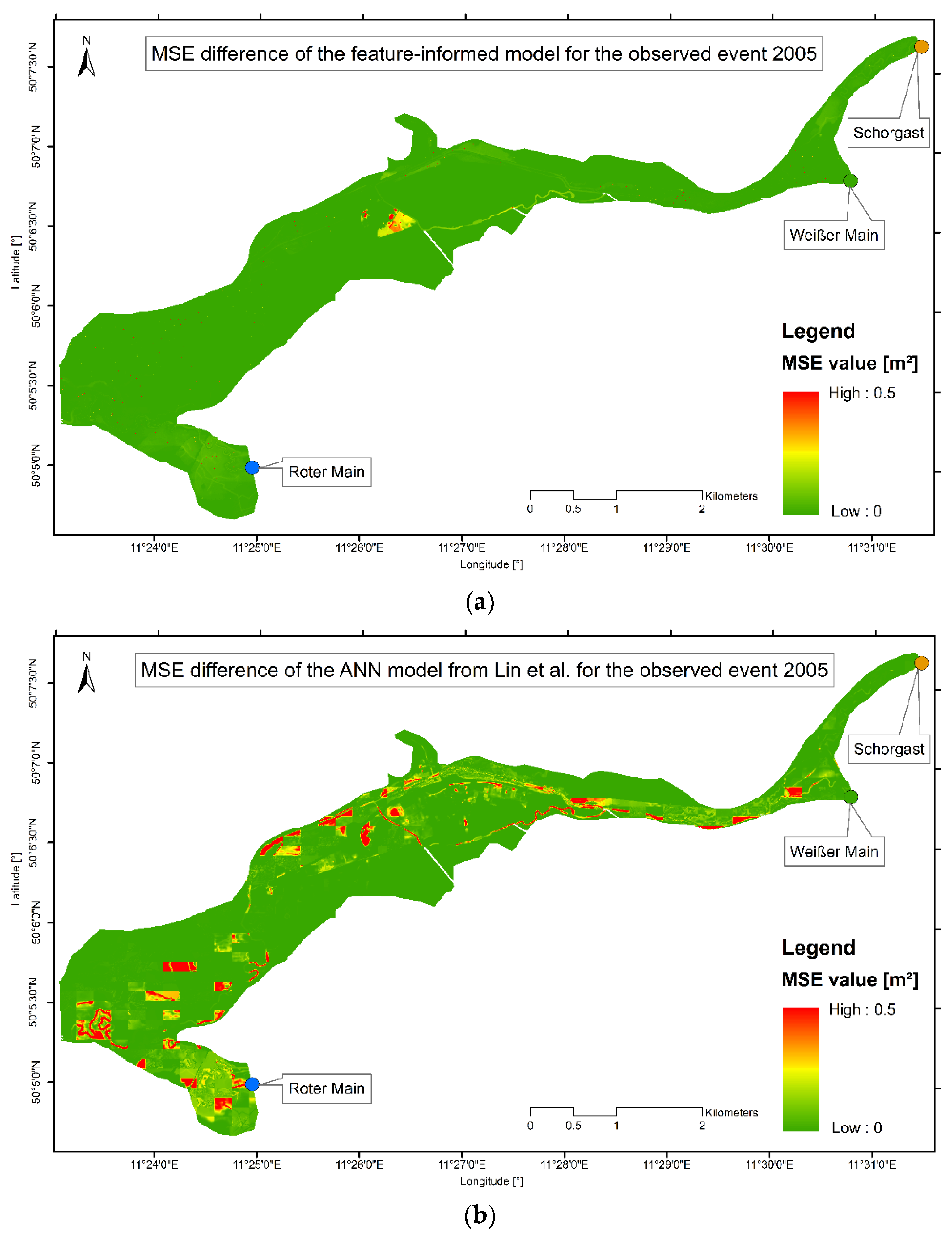
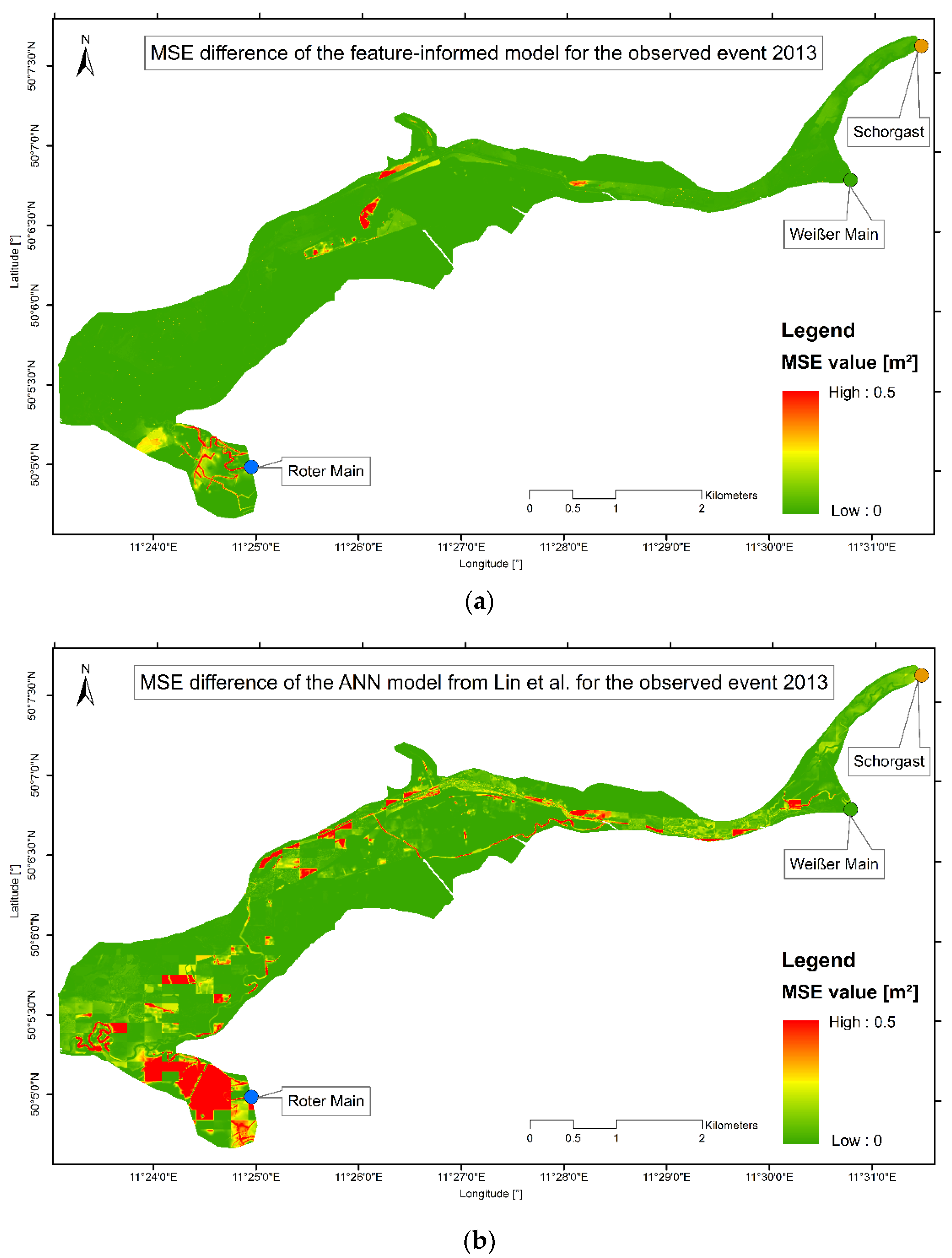
3.2.3. Inundation Maps and Spatially Distributed Prediction Error of the Observed Events
4. Discussion
4.1. Training Durations and Validation Accuracy
4.2. Performance of the Feature-Informed Forecast System
4.2.1. Overall Performance
4.2.2. Comparison of the Individual Feature Performance on the Observed Events
4.2.3. Inundation Maps and Spatially Distributed Prediction Error of the Observed Events
4.3. Limitations and Future Research
5. Conclusions
- The FFS delivers the prediction within 19 s, thus making the system usable for real-time applications.
- The innovative training workflow with pre-simulated inundation scenarios from a hybrid database ensures a high prediction quality. The accuracy of the FFS compared with the physically based model HEC-RAS shows average RMSE values of 0.052 for 35 test events. A test on two observed flood events showed RMSE values of 0.074 and 0.141.
- The feature-informed architecture makes it possible to integrate additional knowledge about flooding into the model without providing an additional dataset. This not only enhances the prediction performance, since it also allows training on a standard computer, making such an application accessible to a wider range of users. The prediction performance on two observed test events showed only 0.11% and 2.14% of the cells forecasted have an MSE value larger than 0.2 m2, an improvement as compared to the work of Lin et al., 2020 [11] which reached values of 8.97% and 13.62%.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Swiss RE Institue Sigma—Natural Catastrophes in 2021: The Floodgates Are Open. Available online: https://www.swissre.com/institute/research/sigma-research/sigma-2022-01.html (accessed on 11 December 2023).
- Arnell, N.W.; Lloyd-Hughes, B. The Global-Scale Impacts of Climate Change on Water Resources and Flooding under New Climate and Socio-Economic Scenarios. Clim. Chang. 2014, 122, 127–140. [Google Scholar] [CrossRef]
- Bevacqua, E.; Maraun, D.; Vousdoukas, M.I.; Voukouvalas, E.; Vrac, M.; Mentaschi, L.; Widmann, M. Higher Probability of Compound Flooding from Precipitation and Storm Surge in Europe under Anthropogenic Climate Change. Sci. Adv. 2019, 5, eaaw5531. [Google Scholar] [CrossRef] [PubMed]
- Calvin, K.; Dasgupta, D.; Krinner, G.; Mukherji, A.; Thorne, P.W.; Trisos, C.; Romero, J.; Aldunce, P.; Barrett, K.; Blanco, G.; et al. IPCC, 2023: Climate Change 2023: Synthesis Report. Contribution of Working Groups I, II and III to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change; Core Writing Team, Lee, H., Romero, J., Eds.; IPCC: Geneva, Switzerland, 2023. [Google Scholar]
- Rözer, V.; Peche, A.; Berkhahn, S.; Feng, Y.; Fuchs, L.; Graf, T.; Haberlandt, U.; Kreibich, H.; Sämann, R.; Sester, M.; et al. Impact-Based Forecasting for Pluvial Floods. Earth’s Future 2021, 9, 2020EF001851. [Google Scholar] [CrossRef]
- Crotti, G.; Leandro, J.; Bhola, P.K. A 2D Real-Time Flood Forecast Framework Based on a Hybrid Historical and Synthetic Runoff Database. Water 2019, 12, 114. [Google Scholar] [CrossRef]
- Henonin, J.; Russo, B.; Mark, O.; Gourbesville, P. Real-Time Urban Flood Forecasting and Modelling—A State of the Art. J. Hydroinform. 2013, 15, 717–736. [Google Scholar] [CrossRef]
- Sun, W.; Bocchini, P.; Davison, B.D. Applications of Artificial Intelligence for Disaster Management. Nat. Hazards 2020, 103, 2631–2689. [Google Scholar] [CrossRef]
- Berkhahn, S. An Ensemble Neural Network Model for Real-Time Prediction of Urban Floods. J. Hydrol. 2019, 12, 743–754. [Google Scholar] [CrossRef]
- Kimura, N.; Yoshinaga, I.; Sekijima, K.; Azechi, I.; Baba, D. Convolutional Neural Network Coupled with a Transfer-Learning Approach for Time-Series Flood Predictions. Water 2019, 12, 96. [Google Scholar] [CrossRef]
- Lin, Q.; Leandro, J.; Wu, W.; Bhola, P.; Disse, M. Prediction of Maximum Flood Inundation Extents With Resilient Backpropagation Neural Network: Case Study of Kulmbach. Front. Earth Sci. 2020, 8, 332. [Google Scholar] [CrossRef]
- Kabir, S.; Patidar, S.; Xia, X.; Liang, Q.; Neal, J.; Pender, G. A Deep Convolutional Neural Network Model for Rapid Prediction of Fluvial Flood Inundation. J. Hydrol. 2020, 590, 125481. [Google Scholar] [CrossRef]
- Guo, Z.; Leitão, J.P.; Simões, N.E.; Moosavi, V. Data-driven Flood Emulation: Speeding up Urban Flood Predictions by Deep Convolutional Neural Networks. J. Flood Risk Manag. 2021, 14, e12684. [Google Scholar] [CrossRef]
- Hofmann, J.; Schüttrumpf, H. floodGAN: Using Deep Adversarial Learning to Predict Pluvial Flooding in Real Time. Water 2021, 13, 2255. [Google Scholar] [CrossRef]
- Burrichter, B.; Hofmann, J.; Koltermann da Silva, J.; Niemann, A.; Quirmbach, M. A Spatiotemporal Deep Learning Approach for Urban Pluvial Flood Forecasting with Multi-Source Data. Water 2023, 15, 1760. [Google Scholar] [CrossRef]
- Russell, S.J.; Norvig, P.; Chang, M.; Devlin, J.; Dragan, A.; Forsyth, D.; Goodfellow, I.; Malik, J.; Mansinghka, V.; Pearl, J.; et al. Artificial Intelligence: A Modern Approach, 4th ed.; Pearson Series in Artificial Intelligence; Pearson: Harlow, UK, 2022; ISBN 978-1-292-40113-3. [Google Scholar]
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef]
- Löwe, R.; Böhm, J.; Getreuer Jensen, D.; Leandro, J.; Højmark Rasmussen, S. U-FLOOD—Topographic Deep Learning for Predicting Urban Pluvial Flood Water Depth. J. Hydrol. 2021, 603, 126898. [Google Scholar] [CrossRef]
- Ludwig, K.; Bremicker, M. The Water Balance Model LARSIM—Design, Content and Applications; Freiburger Schriften zur Hydrologie: Freiburg, Germany, 2006; Volume 22. [Google Scholar]
- US Army Corps of Engineers, Hydrologic Engineering Center. HEC-RAS River Analysis System—2D Modeling Users Manual 2016. Available online: https://www.hec.usace.army.mil/software/hec-ras/documentation/HEC-RAS%205.0%202D%20Modeling%20Users%20Manual.pdf (accessed on 11 December 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Chiang, Y.-M.; Chang, L.-C.; Tsai, M.-J.; Wang, Y.-F.; Chang, F.-J. Dynamic Neural Networks for Real-Time Water Level Predictions of Sewerage Systems-Covering Gauged and Ungauged Sites. Hydrol. Earth Syst. Sci. 2010, 11, 1309–1319. [Google Scholar] [CrossRef]
- Schmid, F.; Leandro, J. An Ensemble Data-Driven Approach for Incorporating Uncertainty in the Forecasting of Stormwater Sewer Surcharge. Urban Water J. 2023, 20, 1140–1156. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Blundell, C.; Cornebise, J.; Kavukcuoglu, K.; Wierstra, D. Weight Uncertainty in Neural Networks. arXiv 2015, arXiv:1505.05424. [Google Scholar]
- Bhola, P.; Leandro, J.; Disse, M. Framework for Offline Flood Inundation Forecasts for Two-Dimensional Hydrodynamic Models. Geosciences 2018, 8, 346. [Google Scholar] [CrossRef]
- Tayfur, G.; Singh, V.; Moramarco, T.; Barbetta, S. Flood Hydrograph Prediction Using Machine Learning Methods. Water 2018, 10, 968. [Google Scholar] [CrossRef]
- Tayfur, G. Real-Time Flood Hydrograph Predictions Using Rating Curve and Soft Computing Methods (GA, ANN). In Handbook of Hydroinformatics; Elsevier: Amsterdam, The Netherlands, 2023; pp. 325–338. ISBN 978-0-12-821962-1. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Validation Accuracy [RMSE] | Training Time [min] | |
|---|---|---|
| Output of algorithm 2: 1 | 0.039 m | 126 |
| Output of algorithm 2: 2 | 0.042 m | 131 |
| Output of algorithm 2: 3 | 0.048 m | 116 |
| Output of algorithm 2: 4 | 0.051 m | 125 |
| Accuracy [RMSE] | |
|---|---|
| Test dataset (35 events) | 0.052 m |
| Observed event 2005 | 0.074 m |
| Observed event 2013 | 0.141 m |
| RMSE of Feat. 1 | RMSE of Feat. 2 | RMSE of Feat. 3 | |
|---|---|---|---|
| (Cells Up to 150 m Away) | (Cells Up to 400 m Away) | (Cells > 400 m Away) | |
| Observed event 2005 | 0.063 m | 0.070 m | 0.078 m |
| Observed event 2013 | 0.101 m | 0.141 m | 0.152 m |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schmid, F.; Leandro, J. A Feature-Informed Data-Driven Approach for Predicting Maximum Flood Inundation Extends. Geosciences 2023, 13, 384. https://doi.org/10.3390/geosciences13120384
Schmid F, Leandro J. A Feature-Informed Data-Driven Approach for Predicting Maximum Flood Inundation Extends. Geosciences. 2023; 13(12):384. https://doi.org/10.3390/geosciences13120384
Chicago/Turabian StyleSchmid, Felix, and Jorge Leandro. 2023. "A Feature-Informed Data-Driven Approach for Predicting Maximum Flood Inundation Extends" Geosciences 13, no. 12: 384. https://doi.org/10.3390/geosciences13120384
APA StyleSchmid, F., & Leandro, J. (2023). A Feature-Informed Data-Driven Approach for Predicting Maximum Flood Inundation Extends. Geosciences, 13(12), 384. https://doi.org/10.3390/geosciences13120384