

Machine-Learning Applications in Geosciences: Comparison of Different Algorithms and Vegetation Classes’ Importance Ranking in Wildfire Susceptibility


Abstract
1. Introduction
2. Material and Methods
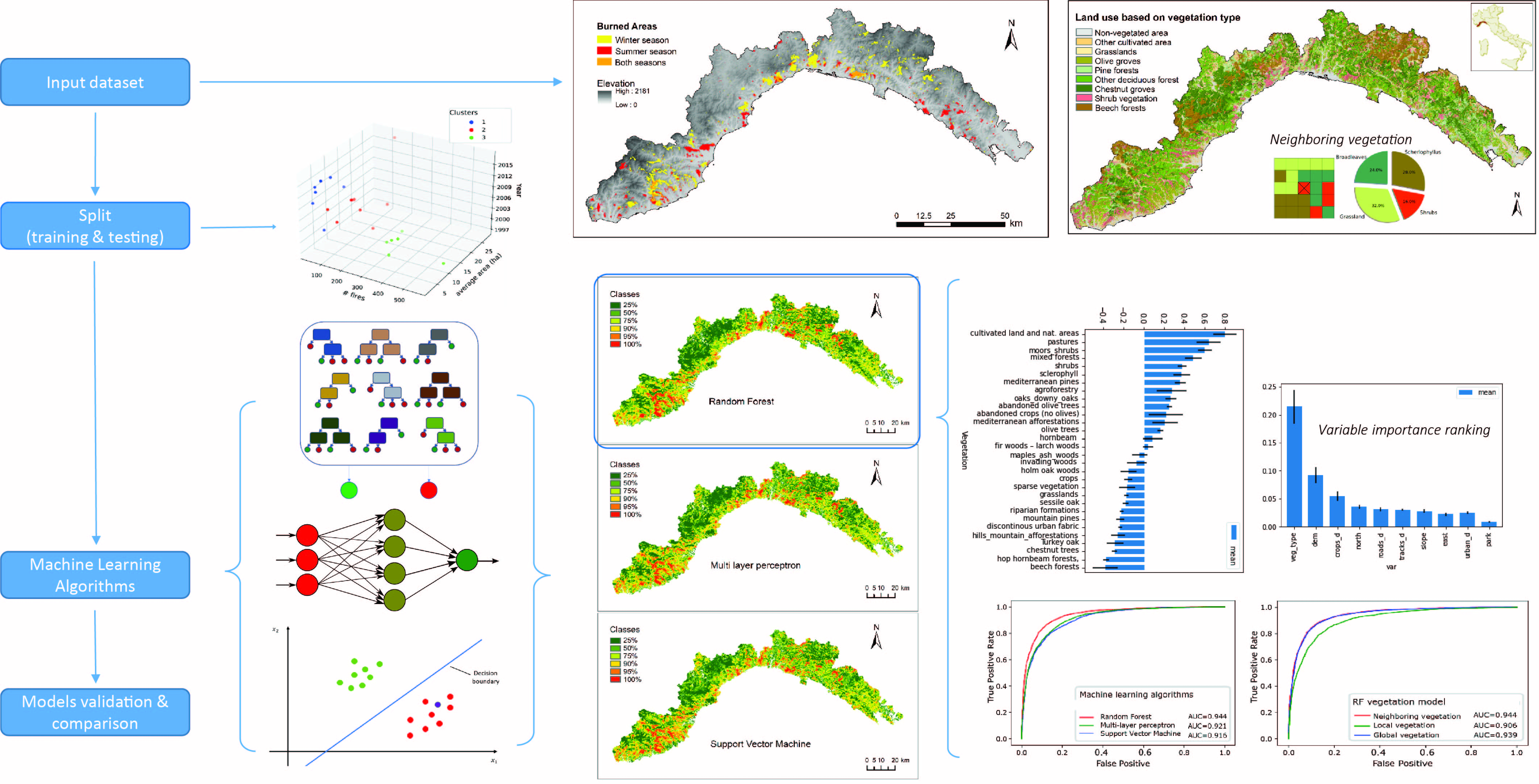
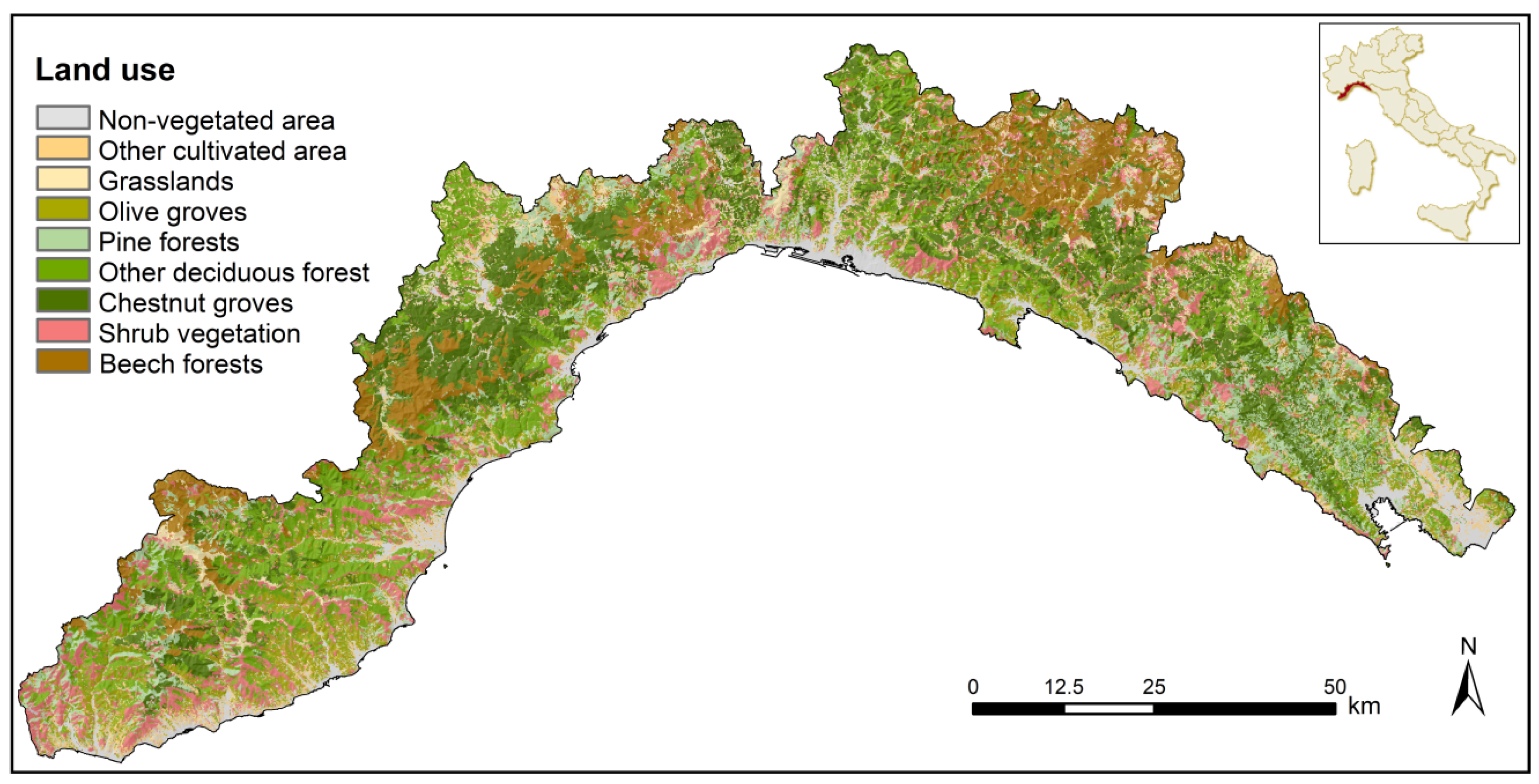
2.1. Study Area
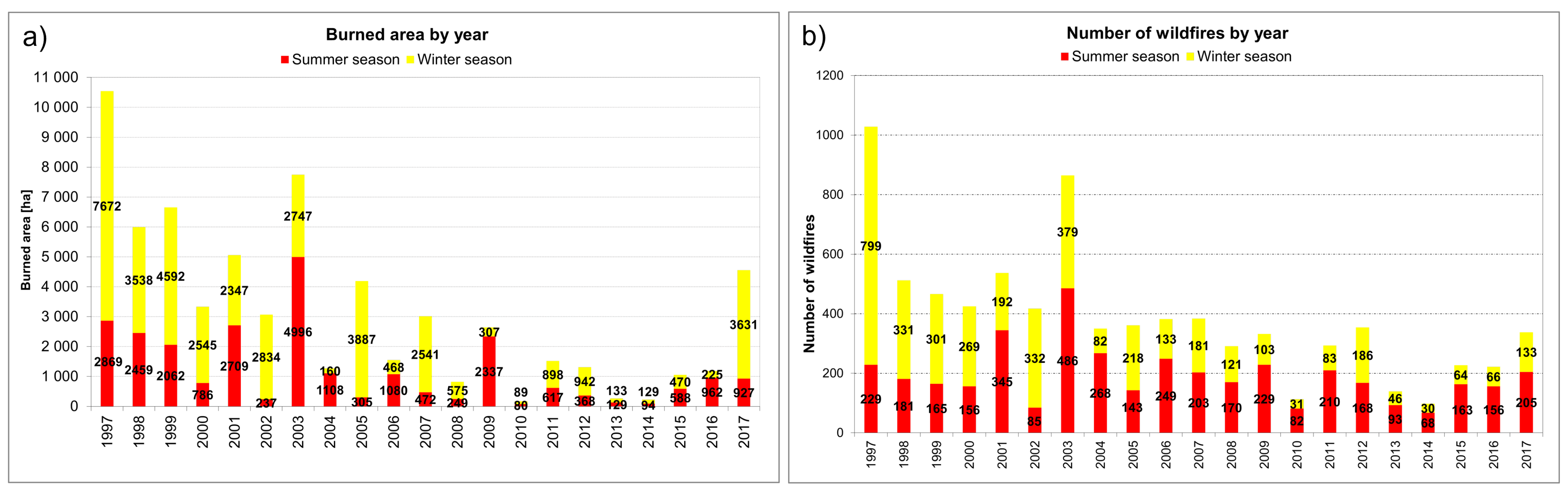
2.2. Wildfires Dataset
2.3. Predictor Variables
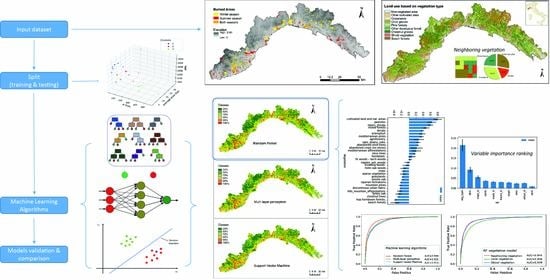
2.4. The Methodological Workflow
- Elaboration of the input dataset: pre-processing of the raster describing the predictor variables (i.e., topographic, anthropogenic, and vegetation features) and the independent variable (i.e., the wildfire dataset).
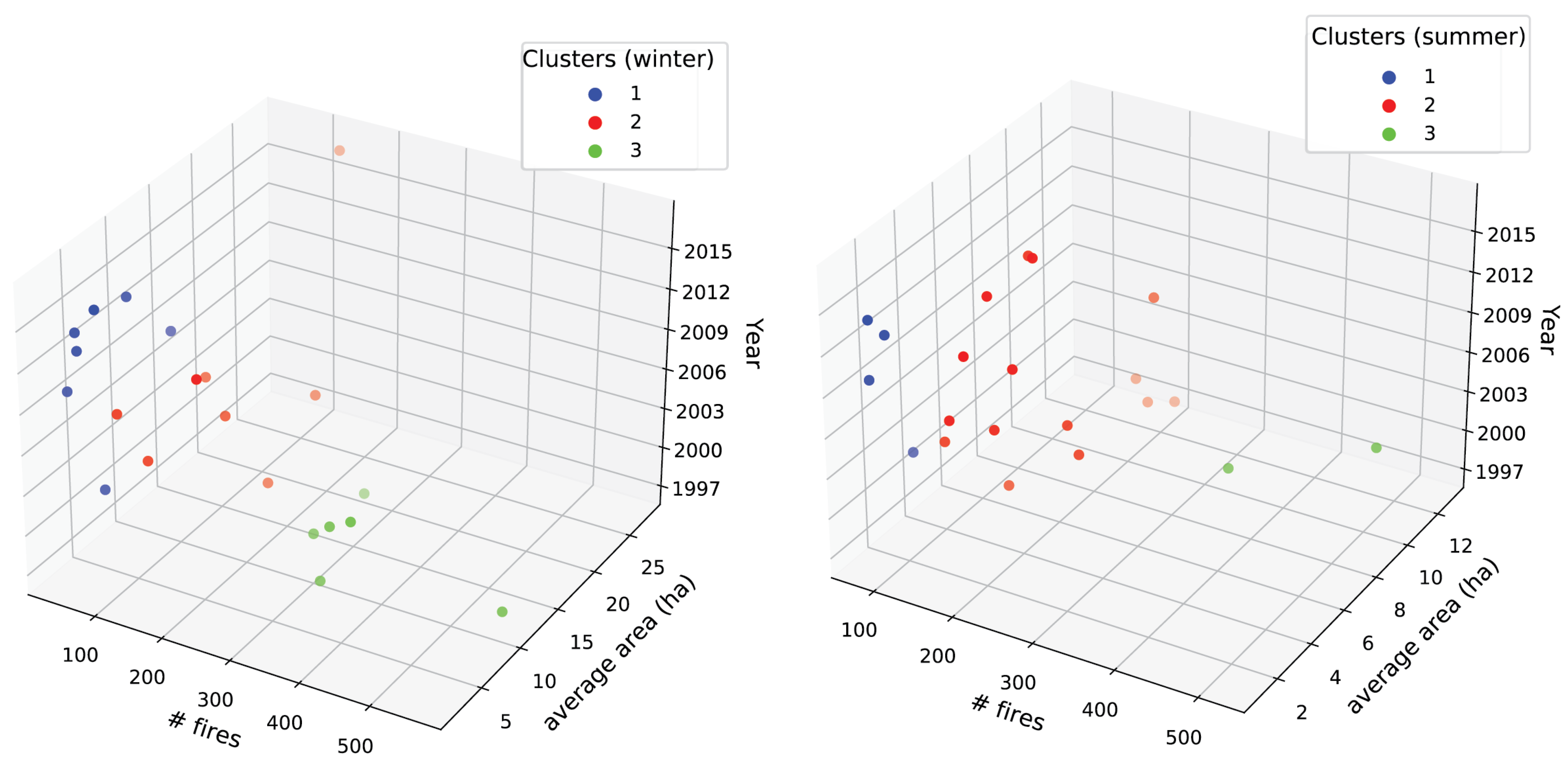
- Selection of the testing and training subsets: 3 out of 17 years were randomly selected for the testing subset based on a clustering procedure, to ensure a fair representation of the possible wildfire trends.
- Selection of the validation subset (via spatial-cross validation): the training subset was then split into 5 parts, and the model was trained on the remaining four parts—the one left out was alternated.
- Implementation of the machine learning (ML) algorithms, namely, random forest (RF), multi-layer perceptron (MLP), and support vector machine (SVM), for the spatial prediction of wildfire susceptibility.
- Evaluation of the performance indicators for each ML algorithm and for the two seasons.
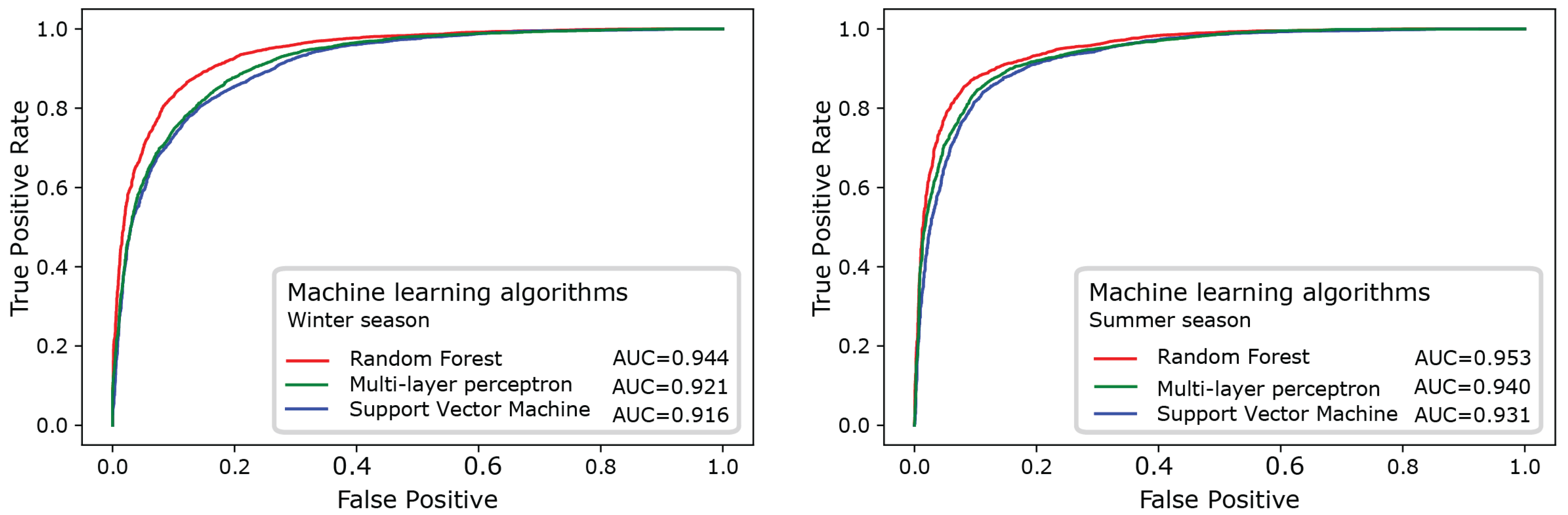
- The AUC (area under the curve) ROC (receiver operating characteristic) were evaluated over the testing dataset.
- The root mean-square error (RMSE) between the values resulting from the three ML-models and the testing subset was also evaluated.
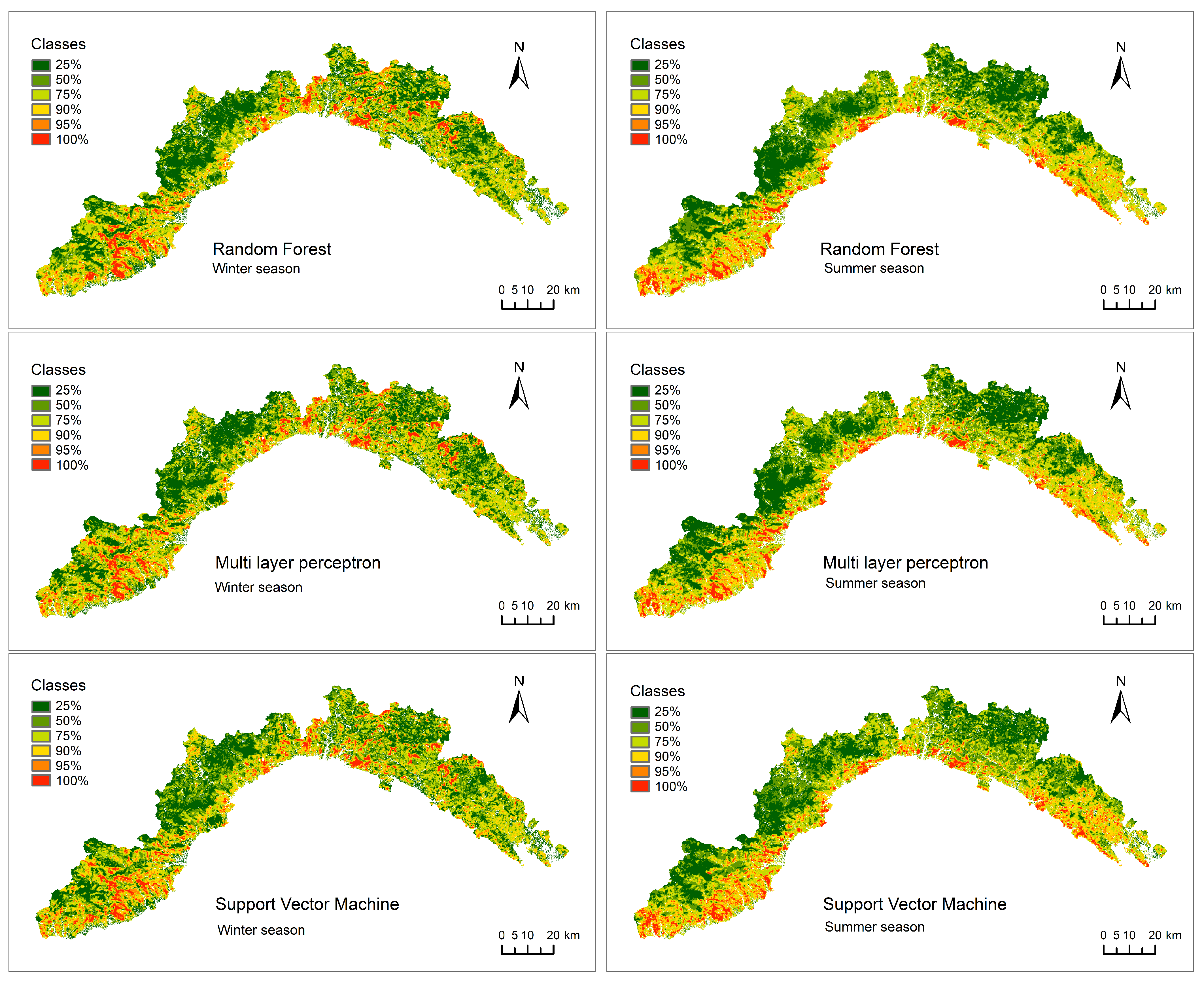
- Elaboration of the wildfire susceptibility maps, based of the probabilistic outputs resulting from the three ML implemented models.
- Assessment of the importance of the predictor variables, obtained by evaluating their rankings and the marginal effect on the predicted outcome.
- This was achieved with RF, which can handle both numerical variables (e.g., the percentage of neighboring vegetation) and native categorical variables (e.g., the classes of vegetation at the pixel level).
2.5. Machine-Learning Algorithms
2.5.1. Random Forest
2.5.2. Multi-Layer Perceptron
2.5.3. Support Vector Machine
2.6. Model Evaluation
2.6.1. Spatial Cross-Validation
2.6.2. Selection of the Testing Subset
2.6.3. Performance Metrics
3. Results and Discussion
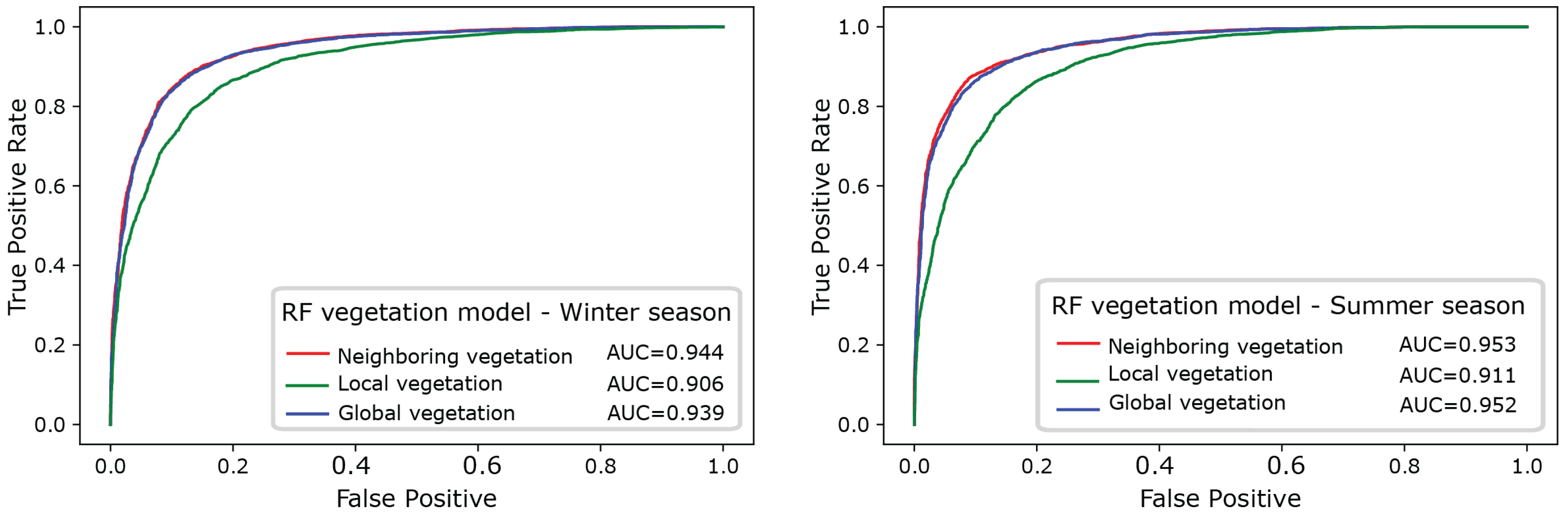
3.1. Comparison of the Three ML Algorithms
3.2. Susceptibility Maps
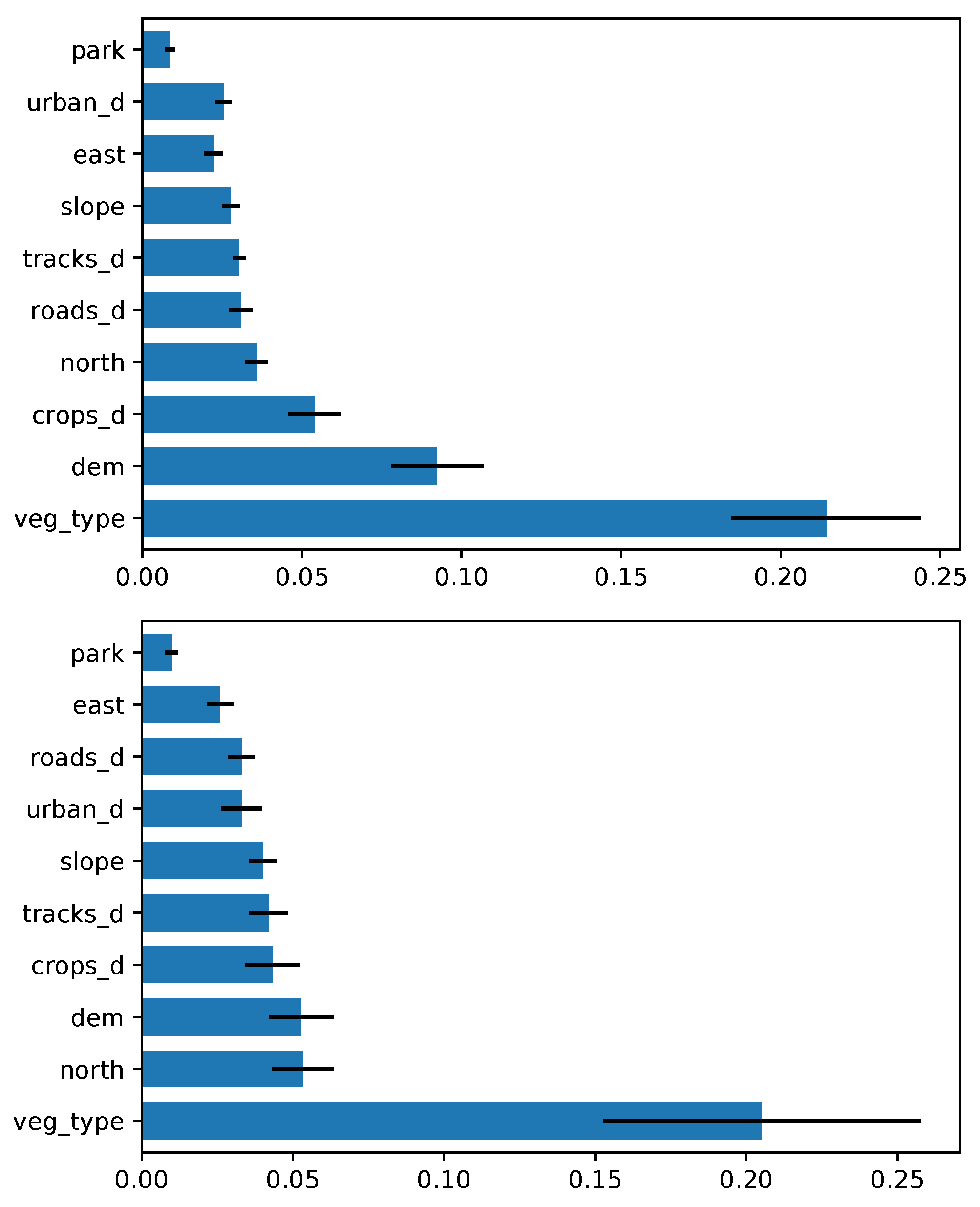
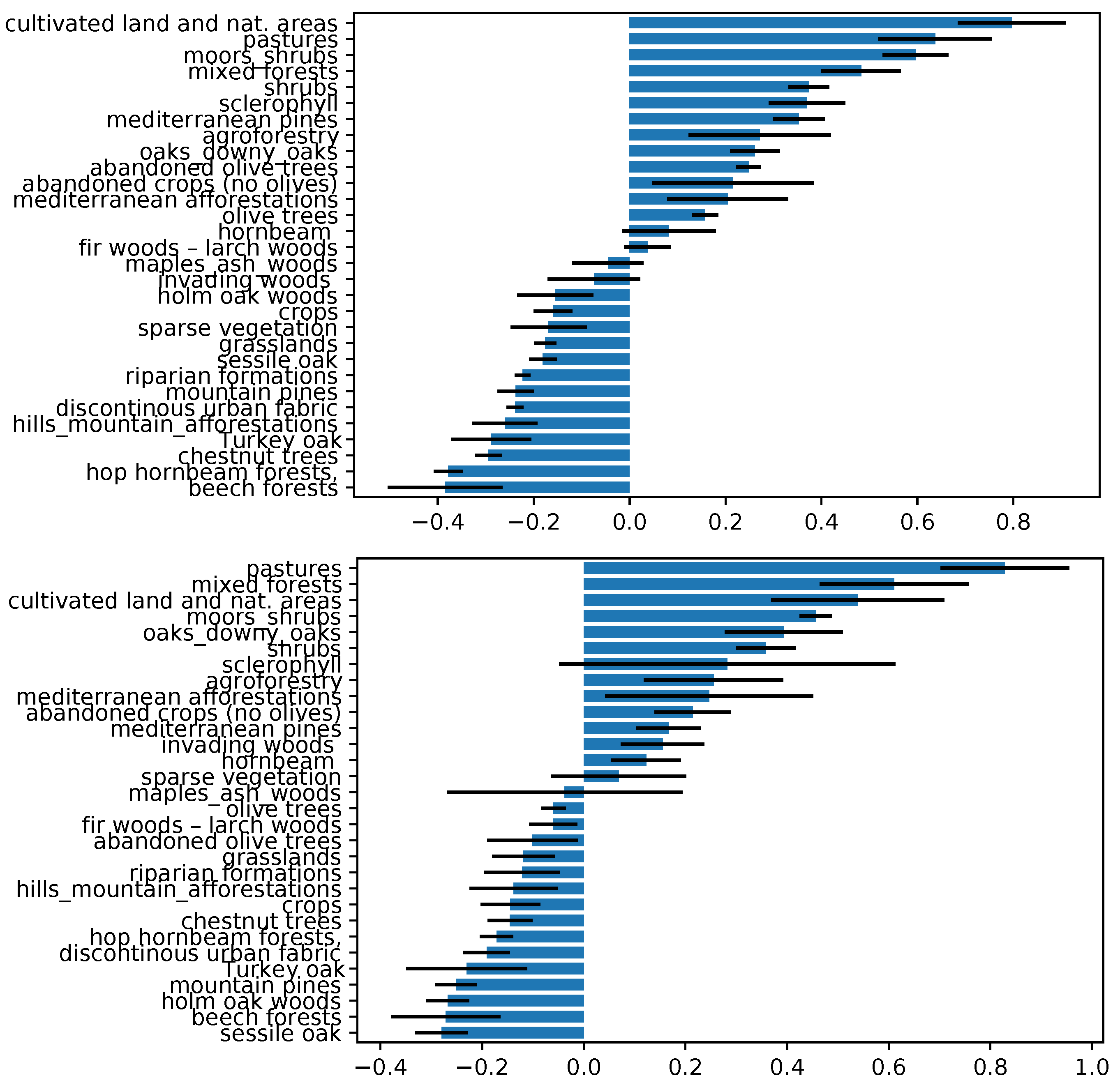
3.3. Assessment of the Predictor Variables
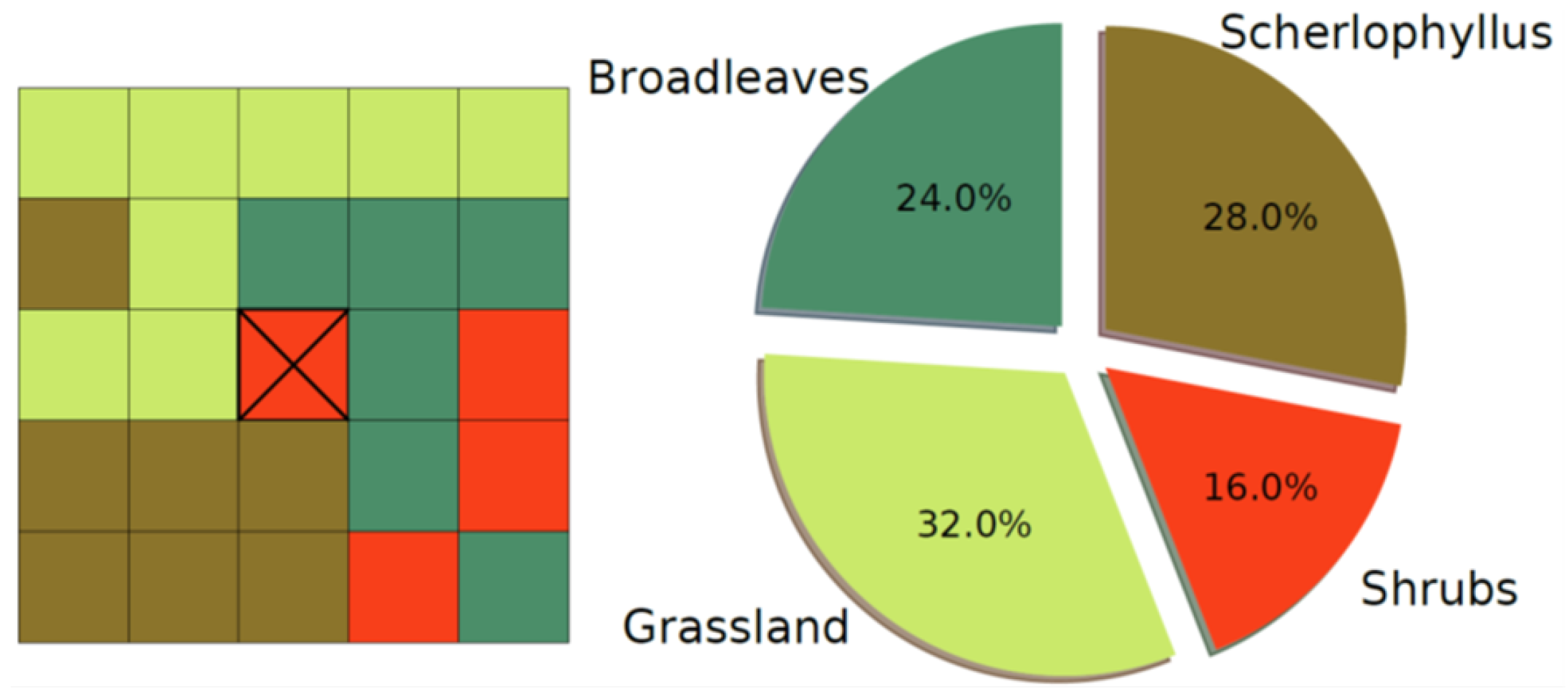
3.3.1. Effect of the Neighboring Vegetation
3.3.2. Predictor Variables Importance Ranking
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mavsar, R.; Cabán, A.G.; Varela, E. The state of development of fire management decision support systems in America and Europe. For. Policy Econ. 2013, 29, 45–55. [Google Scholar] [CrossRef]
- Vasilakos, C.; Kalabokidis, K.; Hatzopoulos, J.; Matsinos, I. Identifying wildland fire ignition factors through sensitivity analysis of a neural network. Nat. Hazards 2009, 50, 125–143. [Google Scholar] [CrossRef]
- WHO. Wildfires. World Health Organization Website. Available online: https://www.who.int/health-topics/wildfires (accessed on 25 October 2022).
- Hernandez-Leal, P.; Arbelo, M.; Gonzalez-Calvo, A. Fire risk assessment using satellite data. Adv. Space Res. 2006, 37, 741–746. [Google Scholar] [CrossRef]
- Liu, Y.; Stanturf, J.; Goodrick, S. Trends in global wildfire potential in a changing climate. For. Ecol. Manag. 2010, 259, 685–697. [Google Scholar] [CrossRef]
- Santi, P.M.; Rengers, F.K. 9.32-Wildfire and Landscape Change. In Treatise on Geomorphology, 2nd ed.; Shroder, J.J.F., Ed.; Academic Press: Oxford, UK, 2022; pp. 765–797. [Google Scholar] [CrossRef]
- Amraoui, M.; Pereira, M.G.; DaCamara, C.C.; Calado, T.J. Atmospheric conditions associated with extreme fire activity in the Western Mediterranean region. Sci. Total Environ. 2015, 524–525, 32–39. [Google Scholar] [CrossRef]
- San-Miguel-Ayanz, J.; Durrant, T.; Boca, R.; Maianti, P.; Liberta, G.; Artes, V.T.; Nuitjen, D. Advance EFFIS Report on Forest Fires in Europe, Middle East and North Africa 2020; Publications Office of the European Union: Luxembourg, 2021. [Google Scholar] [CrossRef]
- Turco, M.; Jerez, S.; Augusto, S.; Tarín-Carrasco, P.; Ratola, N.; Jiménez-Guerrero, P.; Trigo, R.M. Climate drivers of the 2017 devastating fires in Portugal. Sci. Rep. 2019, 9, 13886. [Google Scholar] [CrossRef]
- Turco, M.; Bedia, J.; Di Liberto, F.; Fiorucci, P.; von Hardenberg, J.; Koutsias, N.; Llasat, M.C.; Xystrakis, F.; Provenzale, A. Decreasing Fires in Mediterranean Europe. PLoS ONE 2016, 11, e0150663. [Google Scholar] [CrossRef]
- Duguy, B.; Alloza, J.A.; Baeza, M.J.; De la Riva, J.; Echeverría, M.; Ibarra, P.; Llovet, J.; Cabello, F.P.; Rovira, P.; Vallejo, R.V. Modelling the ecological vulnerability to forest fires in Mediterranean ecosystems using geographic information technologies. Environ. Manag. 2012, 50, 1012–1026. [Google Scholar] [CrossRef]
- Duguy, B.; Paula, S.; Pausas, J.; Alloza, J.; Gimeno, T.; Vallejo, V. Effects of Climate and Extreme Events on Wildfire Regime and Their Ecological Impacts. In Regional Assessment of Climate Change in the Mediterranean; Springer: Dordrecht, The Netherlands, 2013; pp. 101–134. [Google Scholar] [CrossRef]
- Collins, R.D.; de Neufville, R.; Claro, J.; Oliveira, T.; Pacheco, A.P. Forest fire management to avoid unintended consequences: A case study of Portugal using system dynamics. J. Environ. Manag. 2013, 130, 1–9. [Google Scholar] [CrossRef]
- Fernandes, P.M.; Davies, G.M.; Ascoli, D.; Fernández, C.; Moreira, F.; Rigolot, E.; Stoof, C.R.; Vega, J.A.; Molina, D. Prescribed burning in southern Europe: Developing fire management in a dynamic landscape. Front. Ecol. Environ. 2013, 11, e4–e14. [Google Scholar] [CrossRef]
- Tonini, M.; D’Andrea, M.; Biondi, G.; Degli Esposti, S.; Trucchia, A.; Fiorucci, P. A Machine Learning-Based Approach for Wildfire Susceptibility Mapping. The Case Study of the Liguria Region in Italy. Geosciences 2020, 10, 105. [Google Scholar] [CrossRef]
- Trucchia, A.; Meschi, G.; Fiorucci, P.; Gollini, A.; Negro, D. Defining Wildfire Susceptibility Maps in Italy for Understanding Seasonal Wildfire Regimes at the National Level. Fire 2022, 5, 30. [Google Scholar] [CrossRef]
- Finney, M.A. The challenge of quantitative risk analysis for wildland fire. For. Ecol. Manag. 2005, 211, 97–108. [Google Scholar] [CrossRef]
- Hardy, C.C. Wildland fire hazard and risk: Problems, definitions, and context. For. Ecol. Manag. 2005, 211, 73–82. [Google Scholar] [CrossRef]
- Watts, J.M.; Hall, J.R. Introduction to fire risk analysis. In SFPE Handbook of Fire Protection Engineering; Springer: Berlin/Heidelberg, Germany, 2016; pp. 2817–2826. [Google Scholar]
- Meacham, B.J.; Charters, D.; Johnson, P.; Salisbury, M. Building fire risk analysis. In SFPE Handbook of Fire Protection Engineering; Springer: Berlin/Heidelberg, Germany, 2016; pp. 2941–2991. [Google Scholar]
- Catani, F.; Lagomarsino, D.; Segoni, S.; Tofani, V. Landslide susceptibility estimation by random forests technique: Sensitivity and scaling issues. Nat. Hazards Earth Syst. Sci. 2013, 13, 2815–2831. [Google Scholar] [CrossRef]
- Bustillo Sánchez, M.; Tonini, M.; Mapelli, A.; Fiorucci, P. Spatial Assessment of Wildfires Susceptibility in Santa Cruz (Bolivia) Using Random Forest. Geosciences 2021, 11, 224. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Aryal, J. Forest Fire Susceptibility and Risk Mapping Using Social/Infrastructural Vulnerability and Environmental Variables. Fire 2019, 2, 50. [Google Scholar] [CrossRef]
- Eugenio, F.C.; dos Santos, A.R.; Fiedler, N.C.; Ribeiro, G.A.; da Silva, A.G.; dos Santos, Á.B.; Paneto, G.G.; Schettino, V.R. Applying GIS to develop a model for forest fire risk: A case study in Espírito Santo, Brazil. J. Environ. Manag. 2016, 173, 65–71. [Google Scholar] [CrossRef]
- Teodoro, A.; Duarte, L. Forest fire risk maps: A GIS open source application—A case study in Norwest of Portugal. Int. J. Geogr. Inf. Sci. 2013, 27, 699–720. [Google Scholar] [CrossRef]
- Pourghasemi, H.; Goli Jirandeh, A.; Pradhan, B.; Xu, C.; Gokceoglu, C. Landslide susceptibility mapping using support vector machine and GIS at the Golestan Province, Iran 2. J. Earth Syst. Sci. 2013, 122, 349–369. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Kariminejad, N.; Amiri, M.; Edalat, M.; Zarafshar, M.; Blaschke, T.; Cerda, A. Assessing and mapping multi-hazard risk susceptibility using a machine learning technique. Sci. Rep. 2020, 10, 3203. [Google Scholar] [CrossRef] [PubMed]
- Chhetri, S.K.; Kayastha, P. Manifestation of an Analytic Hierarchy Process (AHP) Model on Fire Potential Zonation Mapping in Kathmandu Metropolitan City, Nepal. ISPRS Int. J. Geo Inf. 2015, 4, 400–417. [Google Scholar] [CrossRef]
- Hong, H.; Naghibi, S.; Moradi Dashtpagerdi, M.; Pourghasemi, H.; Chen, W. A comparative assessment between linear and quadratic discriminant analyses (LDA-QDA) with frequency ratio and weights-of-evidence models for forest fire susceptibility mapping in China. Arab. J. Geosci. 2017, 10, 1–14. [Google Scholar] [CrossRef]
- Jaafari, A.; Mafi-Gholami, D.; Zenner, E. A Bayesian modeling of wildfire probability in the Zagros Mountains, Iran. Ecol. Inform. 2017, 39, 32–44. [Google Scholar] [CrossRef]
- Jaafari, A.; Mafi-Gholami, D.; Pham, B.; Bui, D. Wildfire Probability Mapping: Bivariate vs. Multivariate Statistics. Remote Sens. 2019, 11, 618. [Google Scholar] [CrossRef]
- Ljubomir, G.; Pamučar, D.; Drobnjak, S.; Pourghasemi, H.R. 15—Modeling the Spatial Variability of Forest Fire Susceptibility Using Geographical Information Systems and the Analytical Hierarchy Process. In Spatial Modeling in GIS and R for Earth and Environmental Sciences; Pourghasemi, H.R., Gokceoglu, C., Eds.; Elsevier: Amsterdam, The Netherlands, 2019; pp. 337–369. [Google Scholar] [CrossRef]
- Salavati, G.; Saniei, E.; Ghaderpour, E.; Hassan, Q.K. Wildfire Risk Forecasting Using Weights of Evidence and Statistical Index Models. Sustainability 2022, 14, 3881. [Google Scholar] [CrossRef]
- Novo, A.; Fariñas-Álvarez, N.; Martínez-Sánchez, J.; González-Jorge, H.; Fernández-Alonso, J.M.; Lorenzo, H. Mapping Forest Fire Risk—A Case Study in Galicia (Spain). Remote Sens. 2020, 12, 3705. [Google Scholar] [CrossRef]
- Pourtaghi, Z.S.; Pourghasemi, H.R.; Aretano, R.; Semeraro, T. Investigation of general indicators influencing on forest fire and its susceptibility modeling using different data mining techniques. Ecol. Indic. 2016, 64, 72–84. [Google Scholar] [CrossRef]
- Leuenberger, M.; Parente, J.; Tonini, M.; Pereira, M.G.; Kanevski, M. Wildfire susceptibility mapping: Deterministic vs. stochastic approaches. Environ. Model. Softw. 2018, 101, 194–203. [Google Scholar] [CrossRef]
- Oliveira, S.; Oehler, F.; San-Miguel-Ayanz, J.; Camia, A.; Pereira, J.M. Modeling spatial patterns of fire occurrence in Mediterranean Europe using Multiple Regression and Random Forest. For. Ecol. Manag. 2012, 275, 117–129. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shirzadi, A.; Shahabi, H.; Geertsema, M.; Omidvar, E.; Clague, J.J.; Thai Pham, B.; Dou, J.; Talebpour Asl, D.; Bin Ahmad, B.; et al. New Ensemble Models for Shallow Landslide Susceptibility Modeling in a Semi-Arid Watershed. Forests 2019, 10, 743. [Google Scholar] [CrossRef]
- Satir, O.; Berberoglu, S.; Donmez, C. Mapping regional forest fire probability using artificial neural network model in a Mediterranean forest ecosystem. Geomat. Nat. Hazards Risk 2016, 7, 1645–1658. [Google Scholar] [CrossRef]
- Kanevski, M. Machine Learning for Spatial Environmental Data: Theory, Applications, and Software; EPFL Press: Lausanne, Switzerland, 2009. [Google Scholar]
- Jung, H.S.; Lee, S. Machine Learning Techniques Applied to Geoscience Information System and Remote Sensing; MDPI: Basel, Switzerland, 2019. [Google Scholar]
- Sacchini, A.; Ferraris, F.; Faccini, F.; Firpo, M. Environmental climatic maps of Liguria (Italy). J. Maps 2012, 8, 199–207. [Google Scholar] [CrossRef]
- Camerano, P.; Grieco, C.; Mensio, F.; Varese, P. I Tipi Forestali Della Liguria; Regione Liguria, Erga Edizioni: Genoa, Italy, 2008. [Google Scholar]
- Mantero, G.; Morresi, D.; Marzano, R.; Motta, R.; Mladenoff, D.J.; Garbarino, M. The influence of land abandonment on forest disturbance regimes: A global review. Landsc. Ecol. 2020, 35, 2723–2744. [Google Scholar] [CrossRef]
- Galiana-Martín, L. Spatial Planning Experiences for Vulnerability Reduction in the Wildland-Urban Interface in Mediterranean European Countries. Eur. Countrys. 2017, 9, 577–593. [Google Scholar] [CrossRef]
- Liguria, R. Geoportale Regione Liguria. 2021. Available online: https://geoportal.regione.liguria.it/ (accessed on 17 November 2022).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Safi, Y.; Bouroumi, A. Prediction of forest fires using Artificial neural networks. Appl. Math. Sci. 2013, 7, 271–286. [Google Scholar] [CrossRef]
- Bergmeir, C.; Benítez, J.M. Neural Networks in R Using the Stuttgart Neural Network Simulator: RSNNS. J. Stat. Softw. 2012, 46, 1–26. [Google Scholar] [CrossRef]
- Zanaty, E. Support Vector Machines (SVMs) versus Multilayer Perception (MLP) in data classification. Egypt. Inform. J. 2012, 13, 177–183. [Google Scholar] [CrossRef]
- Rodrigues, M.; de la Riva, J. An insight into machine-learning algorithms to model human-caused wildfire occurrence. Environ. Model. Softw. 2014, 57, 192–201. [Google Scholar] [CrossRef]
- Hong, H.; Shahabi, H.; Shirzadi, A.; Chen, W.; Chapi, K.; Ahmad, B.B.; Roodposhti, M.S.; Yari Hesar, A.; Tian, Y.; Tien Bui, D. Landslide susceptibility assessment at the Wuning area, China: A comparison between multi-criteria decision making, bivariate statistical and machine learning methods. Nat. Hazards 2019, 96, 173–212. [Google Scholar] [CrossRef]
- Evgeniou, T.; Pontil, M. Support Vector Machines: Theory and Applications. In Machine Learning and Its Applications: Advanced Lectures; Paliouras, G., Karkaletsis, V., Spyropoulos, C.D., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 249–257. [Google Scholar] [CrossRef]
- Karatzoglou, A.; Smola, A.; Hornik, K. kernlab: Kernel-Based Machine Learning Lab, R Package Version 0.9-31. 2022. Available online: https://rdrr.io/cran/kernlab/ (accessed on 26 September 2022).
- Cortez, P. Data Mining with Neural Networks and Support Vector Machines using the R/rminer Tool. In Proceedings of the Advances in Data Mining–Applications and Theoretical Aspects, 10th Industrial Conference on Data Mining; Perner, P., Ed.; LNAI 6171; Springer: Berlin, Germany, 2010; pp. 572–583. [Google Scholar]
- Fiorucci, P.; Gaetani, F.; Minciardi, R. Development and application of a system for dynamic wildfire risk assessment in Italy. Environ. Model. Softw. 2008, 23, 690–702. [Google Scholar] [CrossRef]
- Fiorucci, P.; D’Andrea, M.; Negro, D.; Severino, M. Manuale d’uso del Sistema Previsionale Della Pericolosità Potenziale Degli Incendi Boschivi RIS.I.CO; Technical Report; Italian Department of Civil Protection–Presidency of the Council of Ministers, and CIMA Research Foundation: Rome, Italy, 2011.
- Fiorucci, P.; D’Andrea, M.; Negro, D.; Gollini, A.; Severino, M. I° Aggiornamento del Manuale d’uso del Sistema Previsionale Della Pericolosità Potenziale Degli Incendi Boschivi RIS.I.CO. –RISICO2015; Technical Report; Italian Department of Civil Protection– Presidency of the Council of Ministers, and CIMA Research Foundation: Rome, Italy, 2015.
- Dramsch, J.S. Chapter One—70 years of machine learning in geoscience in review. In Advances in Geophysics; Moseley, B., Krischer, L., Eds.; Elsevier: Amsterdam, The Netherlands, 2020; Volume 61, pp. 1–55. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Group | Variable Name | Type | Unit of Measure | Model |
|---|---|---|---|---|
| Topographic | Elevation | Continuous | [m] | All |
| Slope | Continuous | [°] | All | |
| Northing | Continuous | - | All | |
| Easting | Continuous | - | All | |
| Anthropic | Distance from urban areas | Continuous | [m] | All |
| Distance from Crops | Continuous | [m] | All | |
| Distance from Roads | Continuous | [m] | All | |
| Distance from Tracks | Continuous | [m] | All | |
| Vegetational | Vegetation (local) | Categorical (30 cat.) | - | RF Global Vegetation, RF local vegetation |
| Neighboring vegetation (30 variables) | Continuous | [%] | RF Global Vegetation, RF neighbouring vegetation, SVM, MLP |
| Winter | RMSE | AUC | |
| Random Forest | Neighboring Vegetation | 0.335 | 0.944 |
| Local vegetation | 0.367 | 0.906 | |
| Global vegetation | 0.342 | 0.939 | |
| SVM | Neighboring Vegetation | 0.36 | 0.916 |
| MLP | Neighboring Vegetation | 0.353 | 0.921 |
| Summer | RMSE | AUC | |
| Random Forest | Neighboring Vegetation | 0.329 | 0.953 |
| Local Vegetation | 0.37 | 0.911 | |
| Global vegetation | 0.328 | 0.952 | |
| SVM | Neighboring Vegetation | 0.358 | 0.931 |
| MLP | Neighboring Vegetation | 0.344 | 0.94 |
| Winter Season | SVM | MLP | RF | ||||
| Classes | Total Area (%) | Testing BA | Prob. Value | Testing BA | Prob. Value | Testing BA | Prob. Value |
| 25% | 25 | 0.42 | 0.13 | 0.48 | 0.13 | 0.27 | 0.10 |
| 50% | 25 | 2.14 | 0.22 | 1.55 | 0.25 | 1.43 | 0.21 |
| 75% | 25 | 10.14 | 0.46 | 8.43 | 0.46 | 4.65 | 0.41 |
| 90% | 15 | 19.97 | 0.74 | 21.67 | 0.68 | 17.67 | 0.67 |
| 95% | 5 | 19.05 | 0.85 | 18.57 | 0.81 | 17.40 | 0.81 |
| 100% | 5 | 48.27 | 0.99 | 49.30 | 0.99 | 58.58 | 1.00 |
| >75% | 25 | 87.30 | 89.54 | 93.65 | |||
| Summer Season | SVM | MLP | RF | ||||
| Classes | Total Area (%) | Testing BA | Prob. Value | Testing BA | Prob. Value | Testing BA | Prob. Value |
| 25% | 25 | 0.34 | 0.09 | 0.10 | 0.08 | 0.18 | 0.05 |
| 50% | 25 | 1.11 | 0.17 | 1.35 | 0.21 | 0.83 | 0.18 |
| 75% | 25 | 6.62 | 0.50 | 5.87 | 0.47 | 4.14 | 0.45 |
| 90% | 15 | 15.99 | 0.77 | 13.82 | 0.69 | 10.22 | 0.69 |
| 95% | 5 | 19.79 | 0.83 | 16.82 | 0.82 | 14.64 | 0.81 |
| 100% | 5 | 56.14 | 0.99 | 62.04 | 1.00 | 69.94 | 1.00 |
| >75% | 25 | 91.93 | 92.68 | 94.80 | |||
| Winter Season | Global Vegetation | Neighboring Vegetation | Without Neighboring Vegetation | ||||
| Classes | Total Area (%) | Testing BA (%) | Prob. Value | Testing BA (%) | Prob. Value | Testing BA (%) | Prob. Value |
| 25% | 25 | 0.34 | 0.09 | 0.27 | 0.10 | 0.94 | 0.12 |
| 50% | 25 | 1.47 | 0.21 | 1.43 | 0.21 | 2.75 | 0.26 |
| 75% | 25 | 4.70 | 0.43 | 4.65 | 0.41 | 8.72 | 0.46 |
| 90% | 15 | 18.09 | 0.68 | 17.67 | 0.67 | 23.79 | 0.70 |
| 95% | 5 | 19.83 | 0.82 | 17.40 | 0.81 | 17.94 | 0.84 |
| 100% | 5 | 55.59 | 1.00 | 58.58 | 1.00 | 45.84 | 1.00 |
| >75% | 93.50 | 93.65 | 87.57 | ||||
| Summer Season | Global Vegetation | Neighboring Vegetation | Without Neighboring Vegetation | ||||
| Classes | Total Area (%) | Testing BA (%) | Prob. Value | Testing BA (%) | Prob. Value | Testing BA (%) | Prob. Value |
| 25% | 25 | 0.13 | 0.05 | 0.18 | 0.05 | 0.26 | 0.06 |
| 50% | 25 | 1.14 | 0.18 | 0.83 | 0.18 | 2.02 | 0.19 |
| 75% | 25 | 4.04 | 0.46 | 4.14 | 0.45 | 9.50 | 0.53 |
| 90% | 15 | 10.84 | 0.70 | 10.22 | 0.69 | 21.76 | 0.75 |
| 95% | 5 | 14.98 | 0.82 | 14.64 | 0.81 | 17.10 | 0.83 |
| 100% | 5 | 68.85 | 1.00 | 69.94 | 1.00 | 49.34 | 1.00 |
| >75% | 94.67 | 94.80 | 88.20 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trucchia, A.; Izadgoshasb, H.; Isnardi, S.; Fiorucci, P.; Tonini, M. Machine-Learning Applications in Geosciences: Comparison of Different Algorithms and Vegetation Classes’ Importance Ranking in Wildfire Susceptibility. Geosciences 2022, 12, 424. https://doi.org/10.3390/geosciences12110424
Trucchia A, Izadgoshasb H, Isnardi S, Fiorucci P, Tonini M. Machine-Learning Applications in Geosciences: Comparison of Different Algorithms and Vegetation Classes’ Importance Ranking in Wildfire Susceptibility. Geosciences. 2022; 12(11):424. https://doi.org/10.3390/geosciences12110424
Chicago/Turabian StyleTrucchia, Andrea, Hamed Izadgoshasb, Sara Isnardi, Paolo Fiorucci, and Marj Tonini. 2022. "Machine-Learning Applications in Geosciences: Comparison of Different Algorithms and Vegetation Classes’ Importance Ranking in Wildfire Susceptibility" Geosciences 12, no. 11: 424. https://doi.org/10.3390/geosciences12110424
APA StyleTrucchia, A., Izadgoshasb, H., Isnardi, S., Fiorucci, P., & Tonini, M. (2022). Machine-Learning Applications in Geosciences: Comparison of Different Algorithms and Vegetation Classes’ Importance Ranking in Wildfire Susceptibility. Geosciences, 12(11), 424. https://doi.org/10.3390/geosciences12110424