Application of Machine Learning for the Automation of the Quality Control of Noise Filtering Processes in Seismic Data Imaging


Abstract
1. Introduction
2. Context and Related Work
2.1. Machine Learning for Quality Control Assessment Process
2.2. Feature Transformation and Dimensionality Reduction
2.3. Classification Methods
3. Methods
3.1. Feature Transformation and Dimensionality Reduction
3.1.1. Principal Component Analysis (PCA)
3.1.2. Independent Component Analysis (ICA)
3.2. Classification Methods
3.2.1. Instance-Based K-Nearest Neighbor
3.2.2. Random Forests
3.2.3. Support Vector Machines
3.2.4. Multi-Layer Perceptronss
- STEP 1 Several multi-layer perceptrons where trained. Each one consists of a set of permanent layers ( i.e., input layer, layers validated by STEP 2 and the output layer) and one hidden layer candidate. It is composed of 32 to N perceptrons () followed by a dropout layer to avoid overfitting. The validation errors of all the neural network candidates were sent to the Minimum loss processor.
- STEP 2 All the losses received by the STEP 1 are ranked and the neural network candidate with the least validation loss is selected. The remaining mlps are rejected (i.e., they will no longer be processed by the STEP 1).
- STEP 3 Another list of hidden layer candidates is sent back to the STEP 1 and each layer of this list is appended to the final hidden layer of the selected neural network. Then the first STEP is re-operated. All the steps are repeated until the least validation error of the MLP candidates is greater than the least validation error of the previous recursion. At this point, growing the neural network structure becomes inefficient.
4. Experiments
4.1. Seismic Dataset
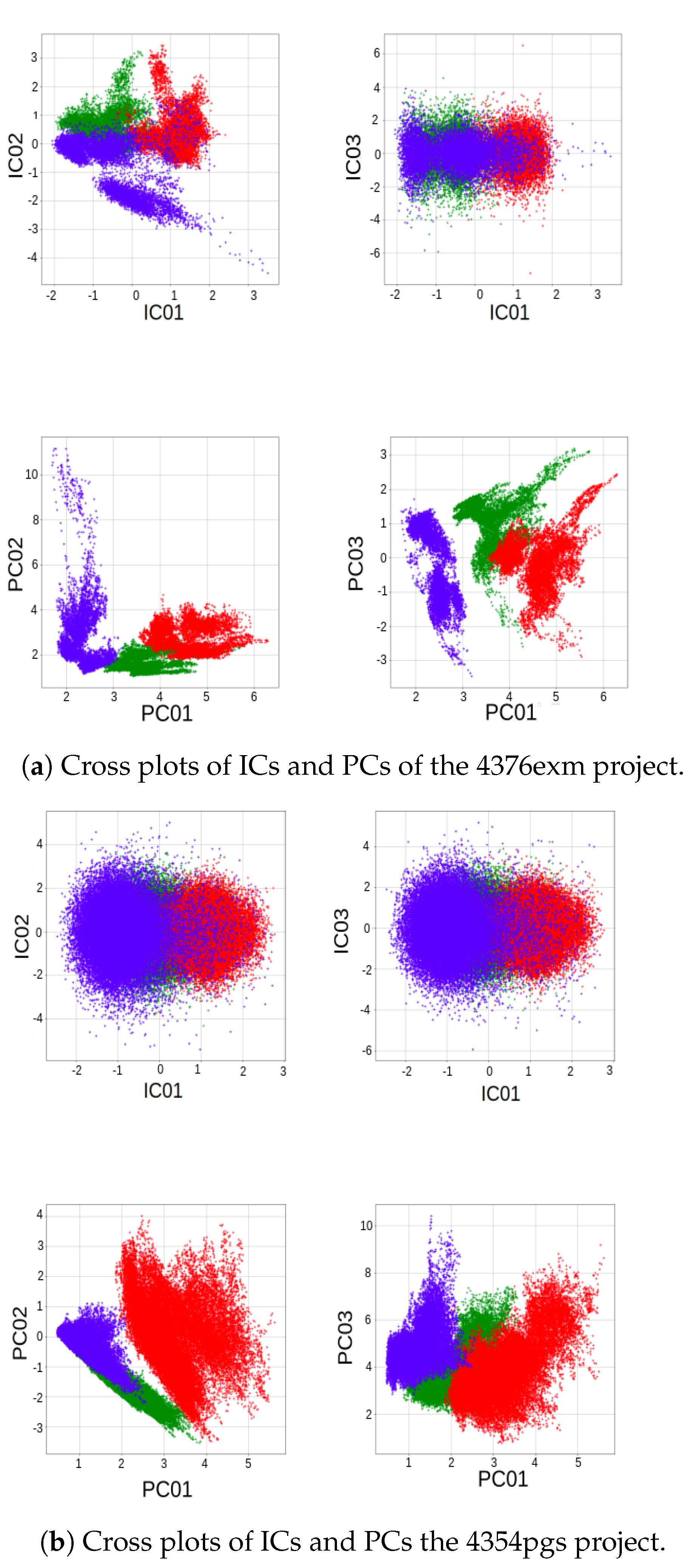
4.2. Feature Transformation and Dimensionality Reduction
4.2.1. Principal Component Analysis
4.2.2. Independent Component Analysis
4.3. Classification Methods
4.4. Assessment of the Predicted Quality Control of Seismic Data after Filtering
5. Results and Discussion
5.1. Feature Transformation and Dimensionality Reduction Methods
5.2. Classification Algorithms
5.3. Geophysical Assessment of QC Denoise Prediction Process
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mandelli, S.; Lipari, V.; Bestagini, P.; Tubaro, S. Interpolation and Denoising of Seismic Data Using Convolutional Neural Networks. arXiv 2019, arXiv:cs.NE/1901.07927. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Villalba-Diez, J.; Schmidt, D.; Gevers, R.; Ordieres-Meré, J.; Buchwitz, M.; Wellbrock, W. Deep Learning for Industrial Computer Vision Quality Control in the Printing Industry 4.0. Sensors 2019, 19, 3987. [Google Scholar] [CrossRef] [PubMed]
- Küstner, T.; Gatidis, S.; Liebgott, A.; Schwartz, M.; Mauch, L.; Martirosian, P.; Schmidt, H.; Schwenzer, N.; Nikolaou, K.; Bamberg, F.; et al. A machine-learning framework for automatic reference-free quality assessment in MRI. Magn. Reson. Imaging 2018, 53, 134–147. [Google Scholar] [CrossRef]
- Jakkampudi, S.; Shen, J.; Li, W.; Dev, A.; Zhu, T.; Martin, E.R. Footstep detection in urban seismic data with a convolutional neural network. Lead. Edge 2020, 39, 654–660. [Google Scholar] [CrossRef]
- Yu, S.; Ma, J.; Wang, W. Deep learning for denoising. Geophysics 2019, 84, V333–V350. [Google Scholar] [CrossRef]
- Bekara, M.; Day, A. Automatic QC of denoise processing using a machine learning classification. First Break 2019, 37, 51–58. [Google Scholar] [CrossRef]
- Spanos, A.; Bekara, M. Using Statistical Techniques to Improve the QC Process of Swell Noise Filtering. In Proceedings of the 75th EAGE Conference & Exhibition Incorporating SPE EUROPEC, London, UK, 10–13 June 2013; European Association of Geoscientists & Engineers: London, UK, 2013. [Google Scholar] [CrossRef]
- Bekara, M. Automatic Quality Control of Denoise Processes Using Support-Vector Machine Classifier. In Proceedings of the Conference Proceedings, 81st EAGE Conference and Exhibition, London, UK, 3–6 June 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Scholkopf, B.; Smola, A.; Müller, K.R. Kernel principal component analysis. In Advances in Kernel Methods—Support Vector Learning; MIT Press: Cambridge, MA, USA, 1999; pp. 327–352. [Google Scholar]
- Rahman, M.; Khan, M.J.; Adeel Asghar, M.; Amin, Y.; Badnava, S.; Mirjavadi, S.S. Image Local Features Description Through Polynomial Approximation. IEEE Access 2019, 7, 183692–183705. [Google Scholar] [CrossRef]
- Hyvärinen, A.; Oja, E. Independent component analysis: Algorithms and applications. Neural Netw. 2000, 13, 411–430. [Google Scholar] [CrossRef]
- Milgram, J.; Cheriet, M.; Sabourin, R. “One Against One” or “One Against All”: Which One is Better for Handwriting Recognition with SVMs; ETS-Ecole de Technologie Superieure: Montreal, QC, Canada, 2006. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Adnan, M.N.; Islam, M.Z. One-vs-all binarization technique in the context of random forest. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 22–24 April 2015; pp. 385–390. [Google Scholar]
- Inoue, H.; Narihisa, H. Efficiency of Self-Generating Neural Networks Applied to Pattern Recognition. Math. Comput. Model. 2003, 38, 1225–1232. [Google Scholar] [CrossRef]
- Pratama, M.; Za’in, C.; Ashfahani, A.; Ong, Y.S.; Ding, W. Automatic construction of multi-layer perceptron network from streaming examples. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1171–1180. [Google Scholar]
- Ashfahani, A.; Pratama, M. Autonomous Deep Learning: Continual Learning Approach for Dynamic Environments. In Proceedings of the 2019 SIAM International Conference on Data Mining, Calgary, AB, Canada, 2–4 May 2019; pp. 666–674. [Google Scholar] [CrossRef]
- Chen, C.C.; Chu, H.T. Similarity Measurement Between Images. In Proceedings of the 29th Annual International Computer Software and Applications Conference (COMPSAC’05), Edinburgh, UK, 26–28 July 2005; Volume 2, pp. 41–42. [Google Scholar] [CrossRef]
- Kolesar, P.J. A branch and bound algorithm for the knapsack problem. Manag. Sci. 1967, 13, 723–735. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Givon, L.E.; Unterthiner, T.; Erichson, N.B.; Chiang, D.W.; Larson, E.; Pfister, L.; Dieleman, S.; Lee, G.R.; van der Walt, S.; Menn, B.; et al. Scikit-Cuda 0.5.3: A Python Interface to GPU-Powered Libraries. 2019. Available online: https://www.biorxiv.org/content/10.1101/2020.07.30.229336v1.abstract (accessed on 20 October 2020).
- Martinsson, G.; Gillman, A.; Liberty, E.; Halko, N.; Rokhlin, V.; Hao, S.; Shkolnisky, Y.; Young, P.; Tropp, J.; Tygert, M.; et al. Randomized methods for computing the Singular Value Decomposition (SVD) of very large matrices. In Works. on Alg. for Modern Mass; Data Sets: Palo Alto, CA, USA, 2010. [Google Scholar]
- Nadal, J.P.; PARGA, N. Sensory coding: Information maximization and redundancy reduction. In Neuronal Information Processing; World Scientific: Singapore, 1999; pp. 164–171. [Google Scholar]
- Rutledge, D.N.; Bouveresse, D.J.R. Independent components analysis with the JADE algorithm. TrAC Trends Anal. Chem. 2013, 50, 22–32. [Google Scholar] [CrossRef]
- Dagum, C. Decomposition and interpretation of Gini and the generalized entropy inequality measures. Statistica 1997, 57, 295–308. [Google Scholar]
- Oshiro, T.; Perez, P.; Baranauskas, J. How Many Trees in a Random Forest? In Proceedings of the International Workshop on Machine Learning and Data Mining in Pattern Recognition, New York, NY, USA, 19–25 July 2012; Volume 7376. [CrossRef]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. Coursera Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Zeiler, M.D. Adadelta: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Baeza-Yates, R.; Ribeiro-Neto, B. Modern Information Retrieval; ACM Press: New York, NY, USA, 2011; pp. 327–328. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Project | and Methods | Score [31] | Processing Time (s) | ||
|---|---|---|---|---|---|
| Optimal | Harsh | Mild | |||
| 4376exm | whitening | 93.1 | 99.3 | 98.4 | 130 |
| PCA | 93.8 | 100 | 98.2 | 100 | |
| Kernel PCA | 91.5 | 98.3 | 97.3 | 5300 | |
| ICA | 87.1 | 99.0 | 97.3 | 540 | |
| 4354pgs | whitening | 95.7 | 91.2 | 90.3 | 1432 |
| PCA | 96.8 | 93.6 | 90.5 | 1054 | |
| Kernel PCA | 91.5 | 91.7 | 88.9 | 10321 | |
| ICA | 95.0 | 90.9 | 84.3 | 2630 | |
| Project | Classifier | Score [31] (%) | ||
|---|---|---|---|---|
| Optimal | Harsh | Mild | ||
| 4376exm | Support Vector Machine | 95.1 | 93.7 | 93.3 |
| Random Forest | 93.4 | 94.7 | 99.3 | |
| multi-layer perceptrons | 95.5 | 95.6 | 98.0 | |
| Instance-based Nearest Neighbors | 71.6 | 89.7 | 82.4 | |
| 4354pgs | Support Vector Machine | 93.6 | 99.7 | 90.9 |
| Random Forest | 91.7 | 97.8 | 83.7 | |
| multi-layer perceptrons | 93.5 | 99.2 | 90.9 | |
| Instance-based Nearest Neighbors | 87.6 | 92.1 | 91.4 | |
| Project | Classifier | Processing Time | Memory Usage (kB) | |
|---|---|---|---|---|
| Training Phase | Prediction Phase | |||
| 4376exm | Support Vector Machines | 15.19 | 2.98 | 355.5 |
| Instance-based Nearest Neighbor | 96.8 | 57.06 | 6900.5 | |
| Random Forest | 15.57 | 1.68 | 5223.6 | |
| multi-layer perceptrons | 930.4 | 3.6 | 31,291.8 | |
| 4354pgs | Support Vector Machines | 633.10 | 27.88 | 983.41 |
| Instance-based Nearest Neighbor | 3880.5 | 27.88 | 29,606 | |
| Random Forest | 128.79 | 7.69 | 21,197 | |
| multi-layer perceptrons | 9304 | 6.5 | 69,350.6 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mejri, M.; Bekara, M. Application of Machine Learning for the Automation of the Quality Control of Noise Filtering Processes in Seismic Data Imaging. Geosciences 2020, 10, 475. https://doi.org/10.3390/geosciences10120475
Mejri M, Bekara M. Application of Machine Learning for the Automation of the Quality Control of Noise Filtering Processes in Seismic Data Imaging. Geosciences. 2020; 10(12):475. https://doi.org/10.3390/geosciences10120475
Chicago/Turabian StyleMejri, Mohamed, and Maiza Bekara. 2020. "Application of Machine Learning for the Automation of the Quality Control of Noise Filtering Processes in Seismic Data Imaging" Geosciences 10, no. 12: 475. https://doi.org/10.3390/geosciences10120475
APA StyleMejri, M., & Bekara, M. (2020). Application of Machine Learning for the Automation of the Quality Control of Noise Filtering Processes in Seismic Data Imaging. Geosciences, 10(12), 475. https://doi.org/10.3390/geosciences10120475