
Enhancing Landmark Point Detection in Eriocheir Sinensis Carapace with Differentiable End-to-End Networks

 ,
,
Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Data
2.2. Method
2.2.1. Data Processing Method
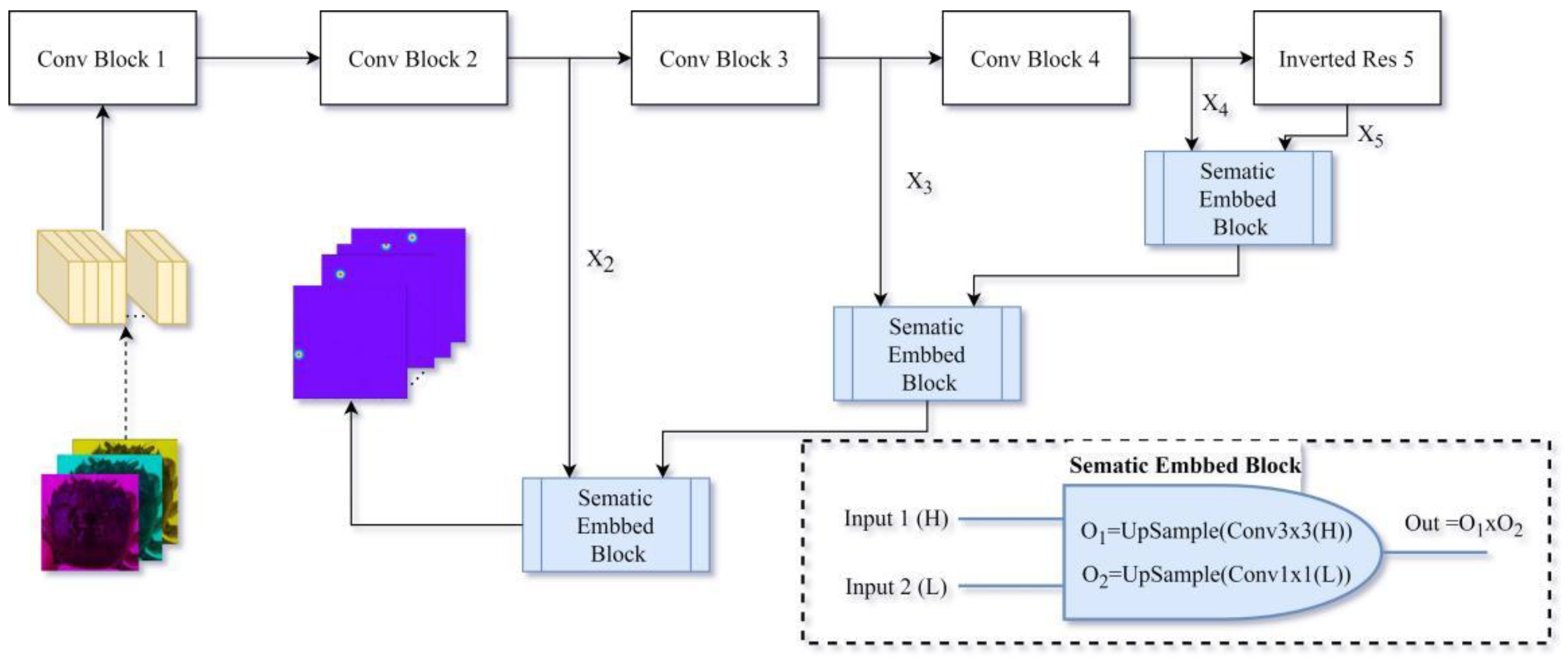
2.2.2. Network Design Methods
The Fully Connected Method
The Gaussian Heatmap Method
The Method of Differentiable Space-Numerical Transformation
| Algorithm 1. Differentiable space-numerical transformation |
| While loss > 0.001: |
| Through the fully convolutional neural network |
| Through the DSNT module For each channel k: |
| Normalize using Softmax to get , ; (with ) |
| Define , i = 1,2, ……, m; j = 1, 2, ……, n |
| Define , i = 1, 2, ……, m; j = 1, 2, ……, n Compute Compute |
| Calculate loss as mean of Euclidean Loss (MSE) and regularization loss |
| Update model parameters |
2.2.3. Design of Parallel Experiments
3. Results
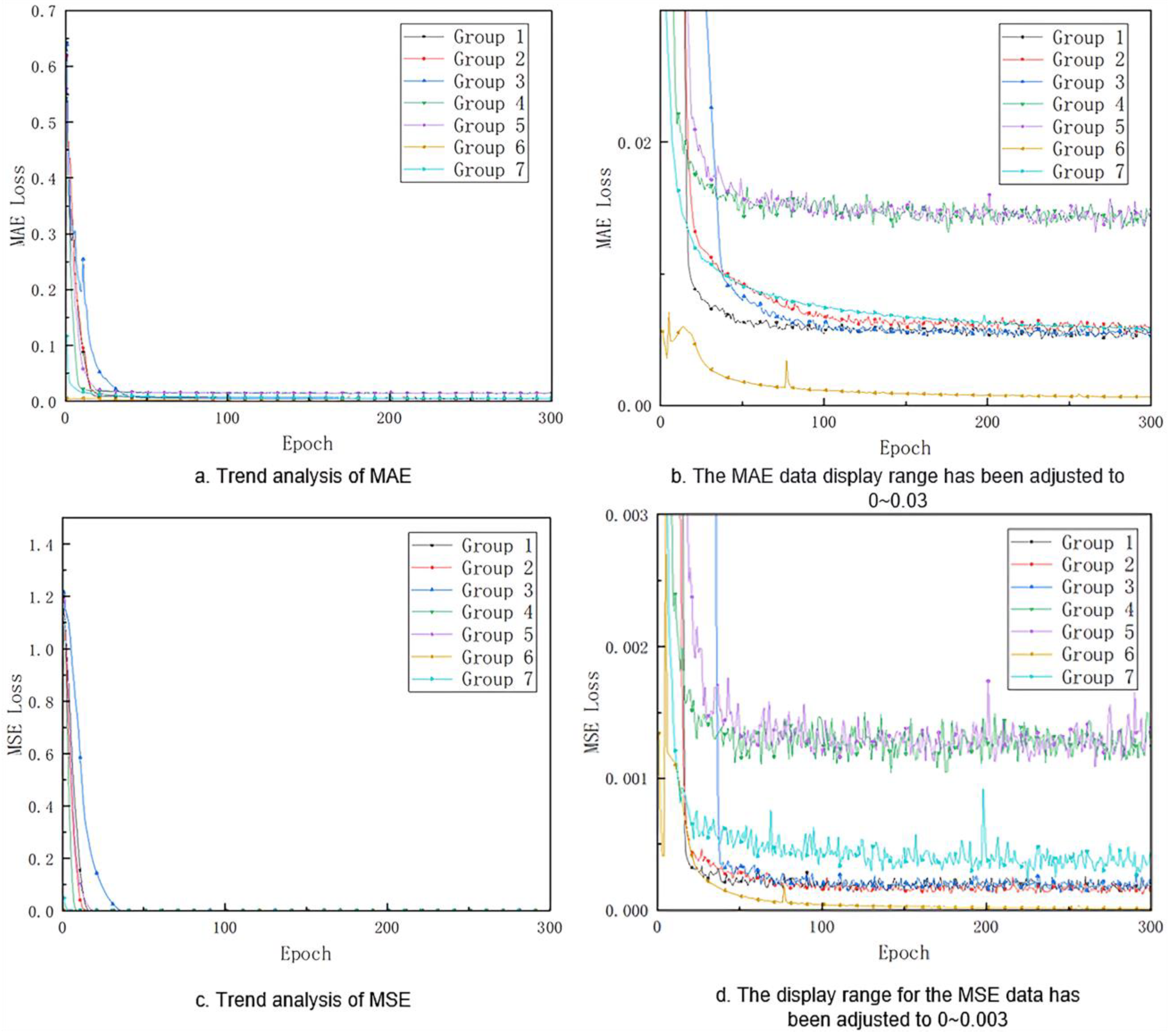
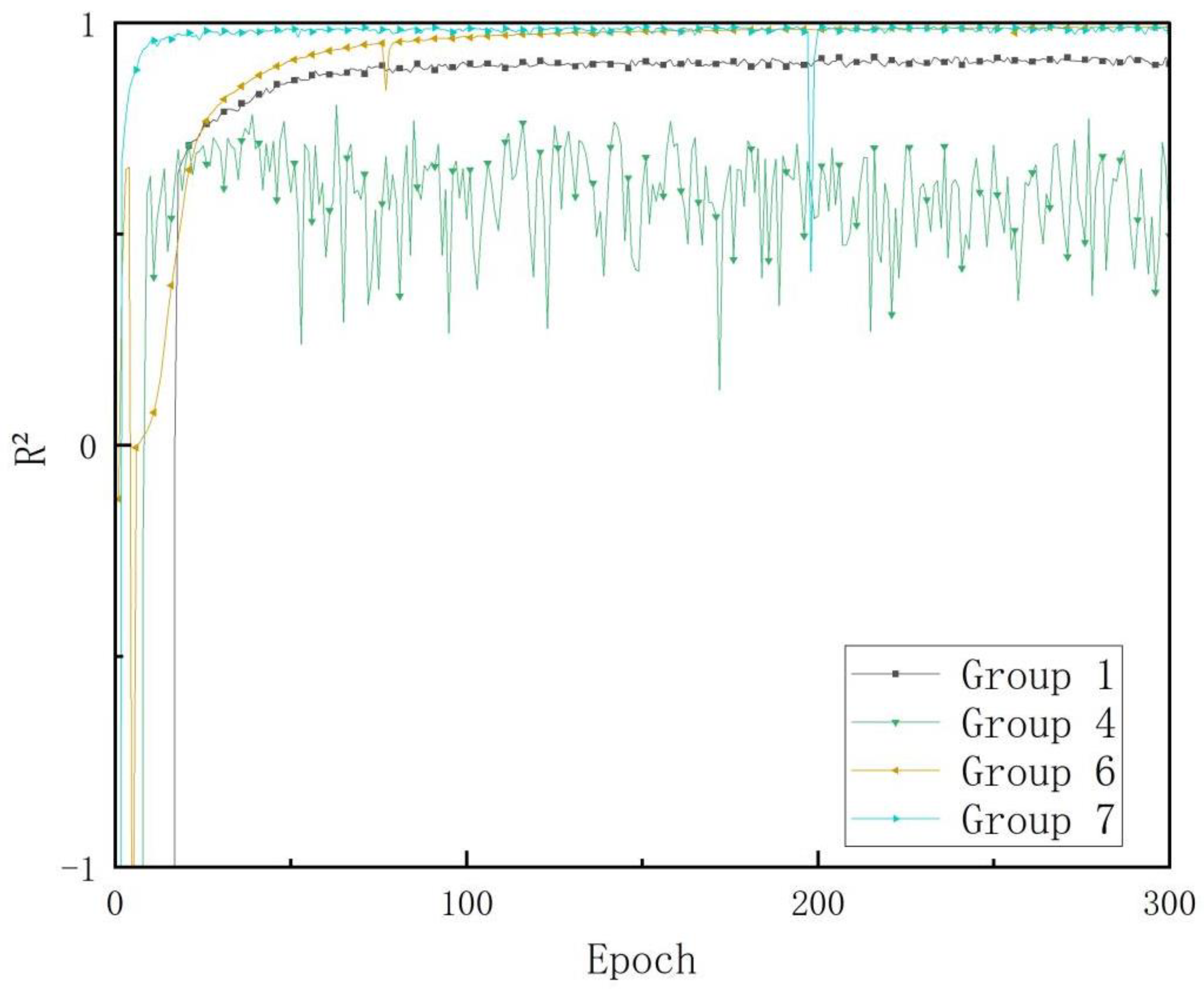
3.1. Training Results
3.2. Results in the Test Set
3.3. Model Power Consumption Related Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rudnick, D.A.; Hieb, K.; Grimmer, K.F.; Resh, V.H. Patterns and processes of biological invasion: The Chinese mitten crab in San Francisco Bay. Basic Appl. Ecol. 2003, 4, 249–262. [Google Scholar] [CrossRef]
- Rice, A.L. Crab zoeal morphology and its bearing on the classification of the Brachyura. Trans. Zool. Soc. Lond. 1980, 35, 271–372. [Google Scholar] [CrossRef]
- Hidayani, A.A.; Trijuno, D.D.; Fujaya, Y.; Alimuddin; Umar, M.T. The morphology and morphometric characteristics of the male swimming crab (Portunus pelagicus) from the East Sahul Shelf, Indonesia. Aquac. Aquar. Conserv. Legis. 2018, 11, 1724–1736. [Google Scholar]
- Cui, Y.; Pan, T.; Chen, S.; Zou, X. A gender classification method for Chinese mitten crab using deep convolutional neural network. Multimed. Tools Appl. 2020, 79, 7669–7684. [Google Scholar] [CrossRef]
- Cao, S.; Zhao, D.; Sun, Y.; Ruan, C. Learning-based low-illumination image enhancer for underwater live crab detection. ICES J. Mar. Sci. 2021, 78, 979–993. [Google Scholar] [CrossRef]
- Wang, D.; Vinson, R.; Holmes, M.; Seibel, G.; Tao, Y. Convolutional neural network guided blue crab knuckle detection for autonomous crab meat picking machine. Opt. Eng. 2018, 57, 043103. [Google Scholar] [CrossRef]
- Frueh, M.; Schilling, A.; Gatidis, S.; Kuestner, T. Real Time Landmark Detection for Within-and Cross Subject Tracking with Minimal Human Supervision. IEEE Access 2022, 10, 81192–81202. [Google Scholar] [CrossRef]
- Tie, Y.; Guan, L. Automatic landmark point detection and tracking for human facial expressions. EURASIP J. Image Video Process. 2013, 2013, 8. [Google Scholar] [CrossRef]
- Probst, T.; Maninis, K.-K.; Chhatkuli, A.; Ourak, M.; Poorten, E.V.; Van Gool, L. Automatic tool landmark detection for stereo vision in robot-assisted retinal surgery. IEEE Robot. Autom. Lett. 2017, 3, 612–619. [Google Scholar] [CrossRef]
- Chen, J.; Zou, L.-H.; Zhang, J.; Dou, L.-H. The Comparison and Application of Corner Detection Algorithms. J. Multimed. 2009, 4, 435–441. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Hou, Q.; Wang, J.; Cheng, L.; Gong, Y. Facial landmark detection via cascade multi-channel convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 1800–1804. [Google Scholar]
- Sagonas, C.; Tzimiropoulos, G.; Zafeiriou, S.; Pantic, M. 300 faces in-the-wild challenge: The first facial landmark localization challenge. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 2–8 December 2013; pp. 397–403. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Liu, H.; Chen, Y.; Zhao, W.; Zhang, S.; Zhang, Z. Human pose recognition via adaptive distribution encoding for action perception in the self-regulated learning process. Infrared Phys. Technol. 2021, 114, 103660. [Google Scholar] [CrossRef]
- Moon, G.; Chang, J.Y.; Lee, K.M. Posefix: Model-agnostic general human pose refinement network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 7773–7781. [Google Scholar]
- Nibali, A.; He, Z.; Morgan, S.; Prendergast, L. Numerical coordinate regression with convolutional neural networks. arXiv 2018, arXiv:1801.07372. [Google Scholar]
- Qin, R.; Hua, Z.; Sun, Z.; He, R. Recognition method of knob gear in substation based on YOLOv4 and Darknet53-DUC-DSNT. Sensors 2022, 22, 4722. [Google Scholar] [CrossRef]
- Yang, S.; Zang, Q.; Zhang, C.; Huang, L.; Xie, Y. RT-DEMT: A hybrid real-time acupoint detection model combining mamba and transformer. arXiv 2025, arXiv:250211179. [Google Scholar]
- Amitguptagwl. Imglab. Available online: https://github.com/NaturalIntelligence/imglab (accessed on 1 March 2025).
- Chen, S.; Liu, Y.; Gao, X.; Han, Z. Mobilefacenets: Efficient cnns for accurate real-time face verification on mobile devices. In Proceedings of the Chinese Conference on Biometric Recognition, Urumqi, China, 11–12 August 2018; pp. 428–438. [Google Scholar]
- Kemelmacher-Shlizerman, I.; Seitz, S.M.; Miller, D.; Brossard, E. The megaface benchmark: 1 million faces for recognition at scale. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4873–4882. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Feng, Z.-H.; Kittler, J.; Awais, M.; Huber, P.; Wu, X.-J. Wing loss for robust facial landmark localisation with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2235–2245. [Google Scholar]
- Wu, Y.; Ji, Q. Facial landmark detection: A literature survey. Int. J. Comput. Vis. 2019, 127, 115–142. [Google Scholar] [CrossRef]
- Li, H.; Guo, Z.; Rhee, S.-M.; Han, S.; Han, J.-J. Towards Accurate Facial Landmark Detection via Cascaded Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4176–4185. [Google Scholar]
- Liu, Y.-B.; Zeng, M.; Meng, Q.-H. Heatmap-based vanishing point boosts lane detection. arXiv 2020, arXiv:200715602. [Google Scholar]
- Islam, M.A.; Jia, S.; Bruce, N.D. How much position information do convolutional neural networks encode? arXiv 2020, arXiv:2001.08248. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Parkes, L.; Quinitio, E.T.; Le Vay, L. Phenotypic differences between hatchery-reared and wild mud crabs, Scylla serrata, and the effects of conditioning. Aquac. Int. 2011, 19, 361–380. [Google Scholar] [CrossRef]
- Zheng, C.; Jiang, T.; Luo, R.; Chesn, X.; Liu, H.; Yang, J. Geometric morphometric analysis of the Chinese mitten crab Eriocheir sinensis: A potential approach for geographical origin authentication. N. Am. J. Fish. Manag. 2021, 41, 891–903. [Google Scholar] [CrossRef]
- Contreras-Reyes, J.E.; López Quintero, F.O.; Yáñez, A.A. Towards age determination of Southern King crab (Lithodes santolla) off Southern Chile using flexible mixture modeling. J. Mar. Sci. Eng. 2018, 6, 157. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Groups | Loss Functions | Data Sets | Networks | ||||||
|---|---|---|---|---|---|---|---|---|---|
| L1 | Smooth | Wing | Others | Source | Augmented | FC | HM | DSNT | |
| Group 1 | √ | √ | √ | ||||||
| Group 2 | √ | √ | √ | ||||||
| Group 3 | √ | √ | √ | ||||||
| Group 4 | √ | √ | √ | ||||||
| Group 5 | √ | √ | √ | ||||||
| Group 6 | √ | √ | √ | ||||||
| Group 7 | √ | √ | √ | ||||||
| Groups | R2 Value on the Test Set |
|---|---|
| Group 1 | 0.8755 |
| Group 2 | 0.8451 |
| Group 3 | 0.8690 |
| Group 4 | 0.9830 |
| Group 5 | 0.9833 |
| Group 6 | 0.9846 |
| Group 7 | 0.9906 |
| Groups | Training Time (h) | Parameters (M) | FLOPs (G) | Model Size (MB) |
|---|---|---|---|---|
| Group 1 | 5.53 | 27.93 | 159.58 | 106.37 |
| Group 2 | 7.06 | 27.93 | 159.58 | 106.37 |
| Group 3 | 5.54 | 27.93 | 159.58 | 106.37 |
| Group 4 | 8.57 | 27.93 | 159.58 | 106.37 |
| Group 5 | 8.59 | 27.93 | 159.58 | 106.37 |
| Group 6 | 224.01 | 0.97 | 156.05 | 4.23 |
| Group 7 | 8.33 | 0.84 | 88.34 | 3.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, C.; Wang, S.; Zhang, S.; Zheng, H.; Wang, W.; Yang, S. Enhancing Landmark Point Detection in Eriocheir Sinensis Carapace with Differentiable End-to-End Networks. Animals 2025, 15, 836. https://doi.org/10.3390/ani15060836
Wu C, Wang S, Zhang S, Zheng H, Wang W, Yang S. Enhancing Landmark Point Detection in Eriocheir Sinensis Carapace with Differentiable End-to-End Networks. Animals. 2025; 15(6):836. https://doi.org/10.3390/ani15060836
Chicago/Turabian StyleWu, Chong, Shuxian Wang, Shengmao Zhang, Hanfeng Zheng, Wei Wang, and Shenglong Yang. 2025. "Enhancing Landmark Point Detection in Eriocheir Sinensis Carapace with Differentiable End-to-End Networks" Animals 15, no. 6: 836. https://doi.org/10.3390/ani15060836
APA StyleWu, C., Wang, S., Zhang, S., Zheng, H., Wang, W., & Yang, S. (2025). Enhancing Landmark Point Detection in Eriocheir Sinensis Carapace with Differentiable End-to-End Networks. Animals, 15(6), 836. https://doi.org/10.3390/ani15060836