
Animal Pose Estimation Based on Contrastive Learning with Dynamic Conditional Prompts

Abstract
Simple Summary
Abstract
1. Introduction
2. Materials and Methods
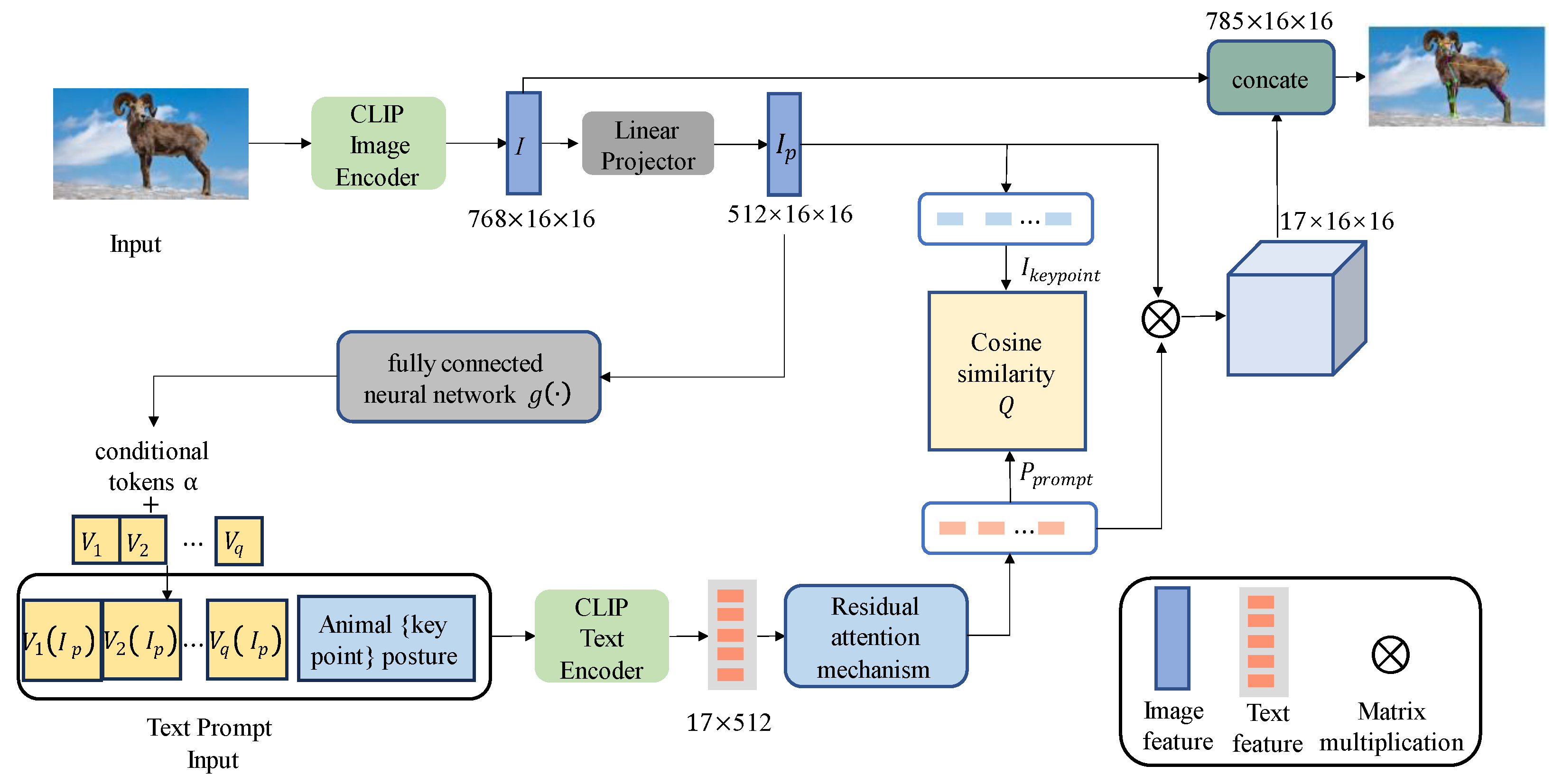
2.1. Dynamic Conditional Prompts for Prior Knowledge of Animal Poses in Language Modality
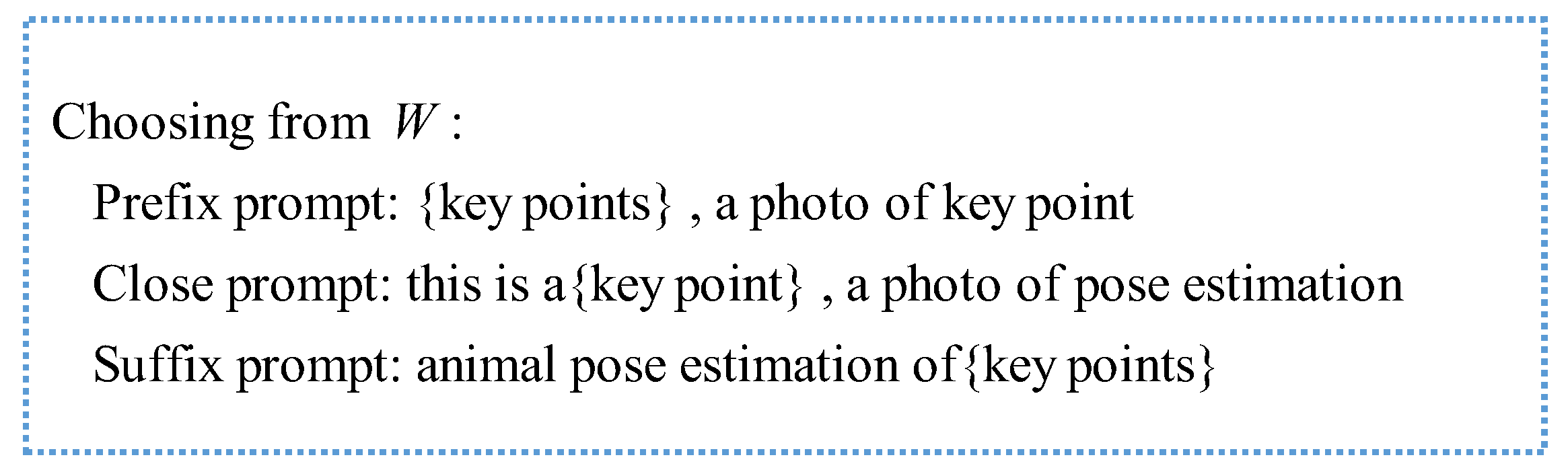
- (1)
- Text prompt templates
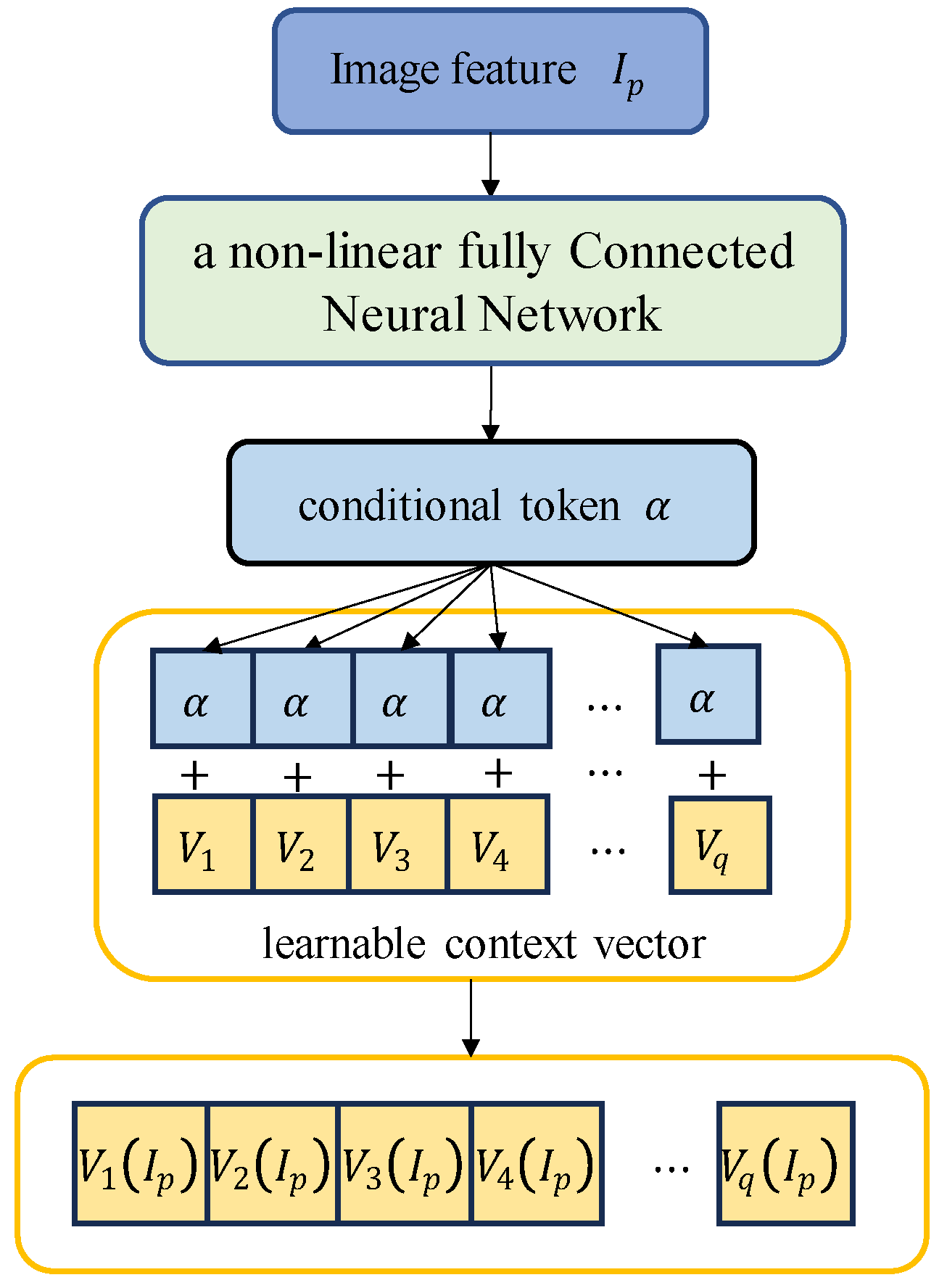
- (2)
- Conditional tokens for image features
- (3)
- Dynamic conditional prompts
2.2. Contrastive Learning for Animal Pose Estimation
2.3. Loss Function of the Animal Pose Estimation Model
3. Results and Discussion
3.1. Animal Pose Estimation Datasets
3.2. Evaluation Index
3.3. Experimental Parameter Settings
3.4. Experimental Results on the AP-10K Dataset
3.5. Experimental Results from the Animal Pose Dataset
3.6. Ablation Experiments
3.7. Visual Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vaintrub, M.O.; Levit, H.; Chincarini, M.; Fusaro, I.; Giammarco, M.; Vignola, G. Precision livestock farming, automats and new technologies: Possible applications in extensive dairy sheep farming. Animal 2021, 15, 100143. [Google Scholar] [CrossRef] [PubMed]
- Cao, J.; Tang, H.; Fang, H.S.; Shen, X.; Lu, C.; Tai, Y.W. Cross-Domain Adaptation for Animal Pose Estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9497–9506. [Google Scholar]
- Mu, J.; Qiu, W.; Hager, G.D.; Yuille, A. Learning from Synthetic Animals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 12386–12395. [Google Scholar]
- Li, C.; Lee, G.H. From Synthetic to Real: Unsupervised Domain Adaptation for Animal Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 1482–1491. [Google Scholar]
- Ye, Y.; Park, H. FusionNet: An End-to-End Hybrid Model for 6D Object Pose Estimation. Electronics 2023, 12, 4162. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models from Natural Language Supervision. In Proceedings of the International Conference on Machine Learning (ICML), Online, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Rong, X. word2vec Parameter Learning Explained. arXiv 2016, arXiv:1411.2738. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; p. 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderder, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Learning to Prompt for Vision-Language Models. Int. J. Comput. Vis. 2022, 130, 2337–2348. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Conditional Prompt Learning for Vision-Language Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 16795–16804. [Google Scholar]
- Gao, P.; Geng, S.; Zhang, R.; Ma, T.; Fang, R.; Zhang, Y.; Li, H.; Qiao, Y. CLIP-Adapter: Better Vision-Language Models with Feature Adapters. Int. J. Comput. Vis. 2024, 132, 581–595. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, W.; Chen, Z.; Xu, Y.; Zhang, J.; Tao, D. CLAMP: Prompt-based Contrastive Learning for Connecting Language and Animal Pose. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 20–22 June 2023; pp. 23272–23281. [Google Scholar]
- Yu, H.; Xu, Y.; Zhang, J.; Zhao, W.; Guan, Z.; Tao, D. AP-10K: A Benchmark for Animal Pose Estimation in the Wild. arXiv 2021, arXiv:2108.12617. [Google Scholar]
- Everingham, M.; Van, G.L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Wang, M.; Xing, J.; Liu, Y. ActionCLIP: A New Paradigm for Video Action Recognition. arXiv 2021, arXiv:2109.08472. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollar, P. Microsoft COCO: Common Objects in Context. arXiv 2015, arXiv:1405.0312. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2019, arXiv:1711.05101. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple Baselines for Human Pose Estimation and Tracking. In Proceedings of the Computer Vision–ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 472–487. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the Computer Vision–ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 122–138. [Google Scholar]
- Yu, C.; Xiao, B.; Gao, C.; Yuan, L.; Zhang, L.; Sang, N.; Wang, J. Lite-HRNet: A Lightweight High-Resolution Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 10435–10445. [Google Scholar]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional Pose Machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Xu, Y.; Zhang, J.; Zhang, Q.; Tao, D. ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation. arXiv 2022, arXiv:2204.12484. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Proceedings of the Computer Vision–ECCV 2016, Amsterdam, The Netherlands, 10–16 October 2016; pp. 483–499. [Google Scholar]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. RTMDet: An Empirical Study of Designing Real-Time Object Detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5686–5696. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label Number | Name | Label Number | Name |
|---|---|---|---|
| 0 | left eye | 9 | right elbow |
| 1 | right eye | 10 | right front paw |
| 2 | nose | 11 | left hip |
| 3 | neck | 12 | left knee |
| 4 | root of tail | 13 | left back paw |
| 5 | left shoulder | 14 | right hip |
| 6 | left elbow | 15 | right knee |
| 7 | left front paw | 16 | right back paw |
| 8 | right shoulder |
| Label Number | Name | Label Number | Name |
|---|---|---|---|
| 0 | left eye | 10 | left back elbow |
| 1 | right eye | 11 | right back elbow |
| 2 | left ear base | 12 | left front knee |
| 3 | right ear base | 13 | right front knee |
| 4 | nose | 14 | left back knee |
| 5 | throat | 15 | right back knee |
| 6 | tail base | 16 | left front paw |
| 7 | withers | 17 | right front paw |
| 8 | left front elbow | 18 | left back paw |
| 9 | right front elbow | 19 | right back paw |
| Method | Backbone | Pre-Training | /% | /% | /% | /% | /% | % |
|---|---|---|---|---|---|---|---|---|
| SimpleBaseline | ResNet-50 | ImageNet | 70.5 | 94.2 | 76.6 | 52.2 | 71.0 | 74.0 |
| SimpleBaseline | ResNet-101 | ImageNet | 70.5 | 94.3 | 77.2 | 50.9 | 71.0 | 74.0 |
| Lite-HRNet | Lite-HRNet-18 | — | 59.9 | 88.6 | 62.7 | 50.7 | 60.1 | 64.8 |
| Lite-HRNet | Lite-HRNet-30 | — | 61.2 | 89.9 | 65.4 | 48.5 | 61.5 | 65.9 |
| CPM | CPM | — | 60.2 | 89.7 | 63.1 | 45.6 | 60.5 | 64.3 |
| MobileNet | MobileNetV2 | mobilenet_v2 | 64.7 | 91.4 | 71.2 | 49.1 | 64.9 | 68.6 |
| ViTPose-S | ViT-S | MAE | 68.0 | 93.6 | 73.4 | 58.1 | 68.2 | 71.5 |
| SHN | Hourglass | — | 69.4 | 93.6 | 76.4 | 53.9 | 69.8 | 72.8 |
| Shufflenet | ShufflenetV1 | shufflenet_v1 | 58.1 | 88.1 | 61.0 | 41.3 | 58.8 | 62.5 |
| Shufflenet | ShufflenetV2 | shufflenet_v2 | 60.5 | 89.6 | 66.9 | 45.7 | 60.8 | 64.7 |
| CSPNeXt | CSPNeXt | cspnext-m | 72.9 | 94.9 | 79.9 | 58.2 | 73.2 | 76.3 |
| HRNet | HRNet-w32 | ImageNet | 72.7 | 95.5 | 78.8 | 55.6 | 73.1 | 75.9 |
| HRNet | HRNet-w48 | ImageNet | 73.2 | 95.3 | 79.6 | 57.4 | 73.5 | 76.3 |
| CLAMP | ViT-Base | CLIP | 73.6 | 94.5 | 80.4 | 49.1 | 74.1 | 76.9 |
| OUR | ViT-Base | CLIP | 74.2 | 95.3 | 80.3 | 53.8 | 74.5 | 77.4 |
| Method | Backbone | Pre-Training | /% | /% | /% | /% | /% | % |
|---|---|---|---|---|---|---|---|---|
| SimpleBaseline | ResNet-50 | ImageNet | 69.6 | 93.7 | 77.0 | 64.6 | 70.9 | 73.9 |
| SimpleBaseline | ResNet-101 | ImageNet | 68.7 | 93.7 | 76.6 | 67.1 | 69.7 | 72.7 |
| Lite-HRNet | Lite-HRNet-18 | — | 62.7 | 89.6 | 68.3 | 63.1 | 62.9 | 67.3 |
| Lite-HRNet | Lite-HRNet-30 | — | 62.7 | 89.5 | 69.5 | 65.9 | 62.3 | 67.3 |
| SHN | Hourglass | — | 68.9 | 92.7 | 77.4 | 65.9 | 69.9 | 73.0 |
| Shufflenet | ShufflenetV1 | shufflenet_v1 | 57.0 | 89.4 | 61.6 | 57.0 | 57.2 | 62.0 |
| Shufflenet | ShufflenetV2 | shufflenet_v2 | 59.5 | 89.4 | 64.5 | 57.5 | 60.3 | 64.3 |
| HRNet | HRNet-w32 | ImageNet | 72.8 | 95.7 | 81.7 | 69.6 | 73.9 | 76.8 |
| HRNet | HRNet-w48 | ImageNet | 73.2 | 95.7 | 81.9 | 71.1 | 74.2 | 77.2 |
| CLAMP | ViT-Base | CLIP | 74.0 | 95.7 | 83.0 | 69.8 | 75.1 | 78.0 |
| OUR | ViT-Base | CLIP | 74.5 | 95.8 | 84.0 | 71.2 | 75.4 | 78.7 |
| Method | /% | /% | /% | /% | /% | % |
|---|---|---|---|---|---|---|
| Baseline | 73.6 | 94.9 | 79.9 | 45.5 | 74.1 | 76.6 |
| 73.6 | 95.2 | 80.2 | 50.0 | 74.0 | 76.7 | |
| 73.7 | 95.0 | 80.1 | 52.7 | 74.2 | 77.0 | |
| OUR | 74.2 | 95.3 | 80.3 | 53.8 | 74.5 | 77.4 |
| Method | /% | /% | /% | /% | /% | % |
|---|---|---|---|---|---|---|
| CLAMP (Baseline) | 73.6 | 94.5 | 80.4 | 49.1 | 74.1 | 76.9 |
| 73.9 | 95.2 | 81.9 | 48.6 | 74.4 | 77.0 | |
| 74.1 | 94.7 | 81.0 | 52.0 | 74.5 | 77.0 | |
| OUR | 74.2 | 95.3 | 80.3 | 53.8 | 74.5 | 77.4 |
| 4 | 6 | 8 | 10 | 12 | |
|---|---|---|---|---|---|
| /% | 73.5 | 73.9 | 74.2 | 74.0 | 73.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, X.; Liu, C. Animal Pose Estimation Based on Contrastive Learning with Dynamic Conditional Prompts. Animals 2024, 14, 1712. https://doi.org/10.3390/ani14121712
Hu X, Liu C. Animal Pose Estimation Based on Contrastive Learning with Dynamic Conditional Prompts. Animals. 2024; 14(12):1712. https://doi.org/10.3390/ani14121712
Chicago/Turabian StyleHu, Xiaoling, and Chang Liu. 2024. "Animal Pose Estimation Based on Contrastive Learning with Dynamic Conditional Prompts" Animals 14, no. 12: 1712. https://doi.org/10.3390/ani14121712
APA StyleHu, X., & Liu, C. (2024). Animal Pose Estimation Based on Contrastive Learning with Dynamic Conditional Prompts. Animals, 14(12), 1712. https://doi.org/10.3390/ani14121712