
Detection and Localization of Albas Velvet Goats Based on YOLOv4

 , , ,
, , ,
Abstract
:Simple Summary
Abstract
1. Introduction
- (1)
- We construct a goat image dataset. The dataset has a total of 8387 goats and consists of 11 goats in their natural grazing state.
- (2)
- We propose a goat target detection algorithm consisting of ShallowSE and an improved Custom_YOLO based on YOLOv4. We first added the attention mechanism to enhance the feature extraction capability of the module. We then changed the activation function to enhance the generalization of the model. Finally, we lightened the model to improve detection speed while ensuring accuracy.
- (3)
- We propose a 3D coordinate regression algorithm based on fully connected networks. We constructed a fully connected network to fit the transformation relationship between the 2D and 3D coordinates of goats. The network can calculate the spatial coordinates of a goat after detecting the goat.
2. Materials and Methods
2.1. Dataset Creation
2.2. Experimental Platform
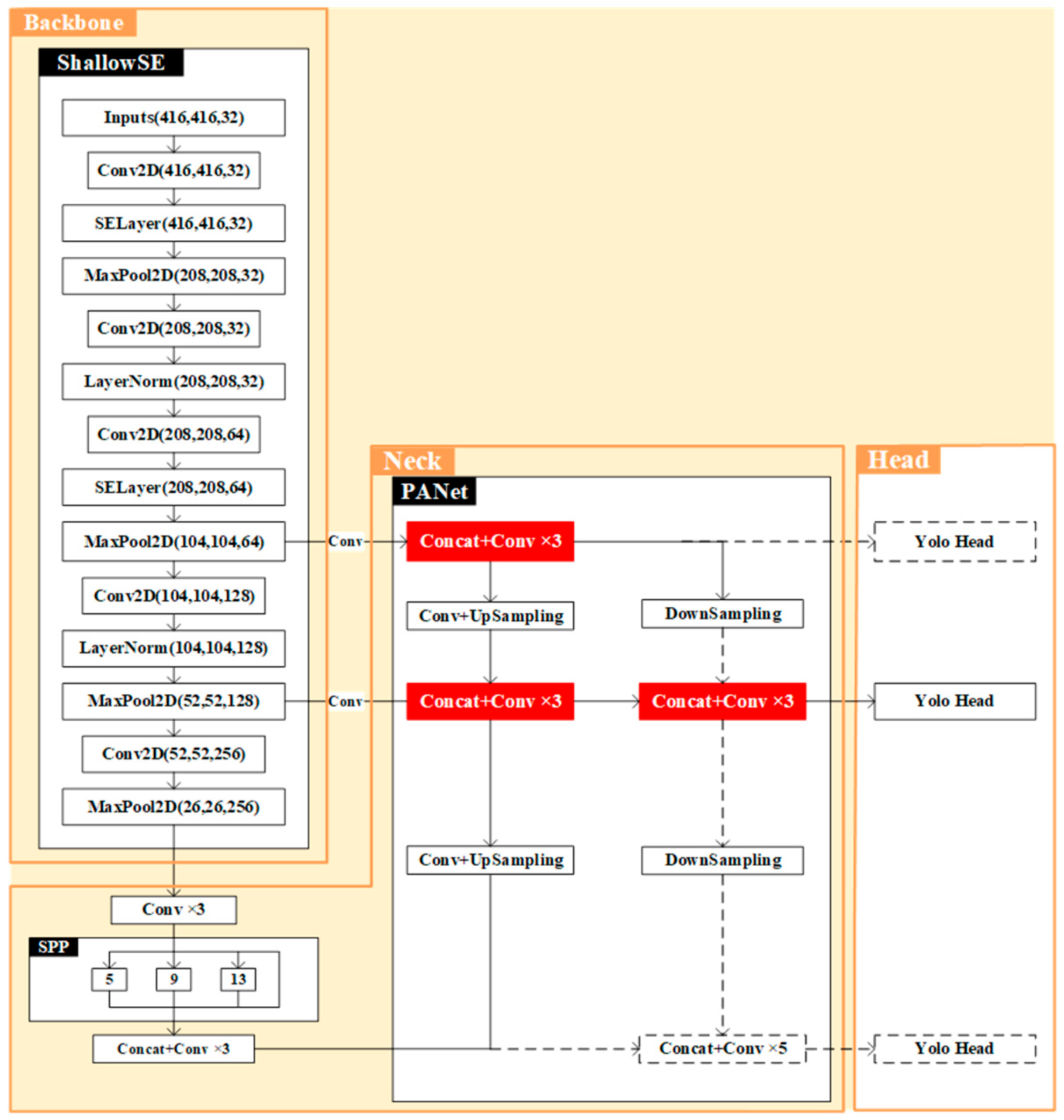
2.3. Construction of the Goat Target Detection Algorithm
2.3.1. SE Module
2.3.2. GeLU Activation Function
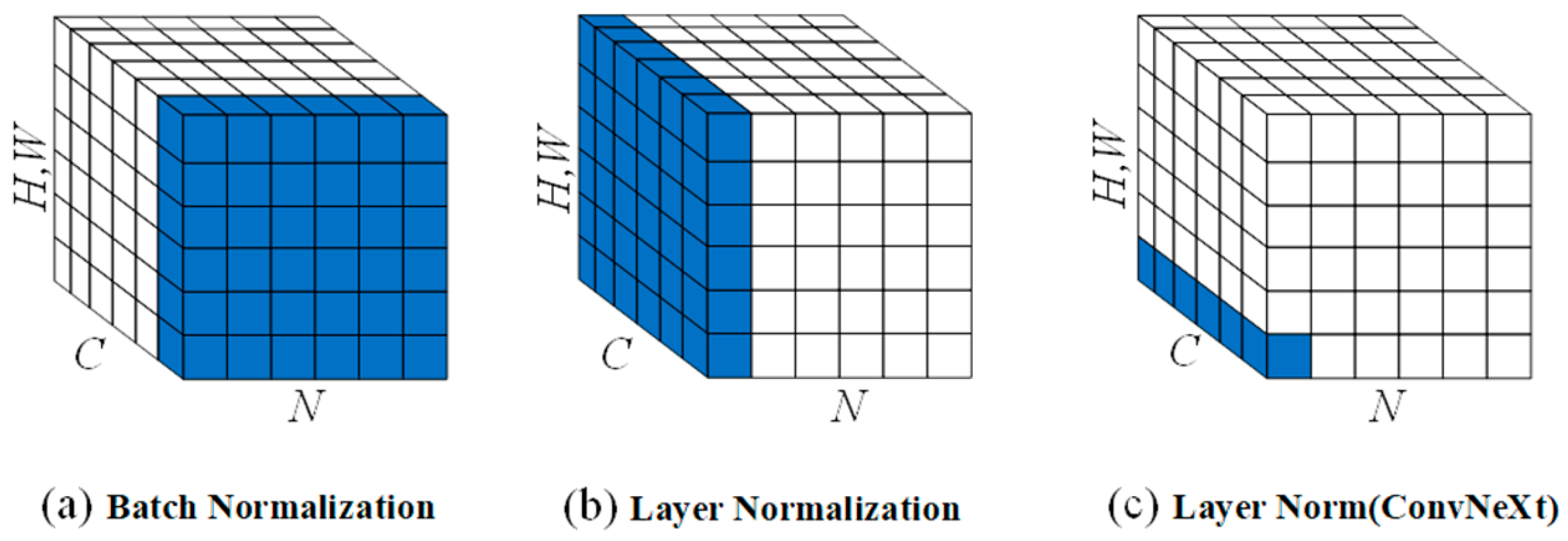
2.3.3. Layer Normalization
2.3.4. Model Streamlining
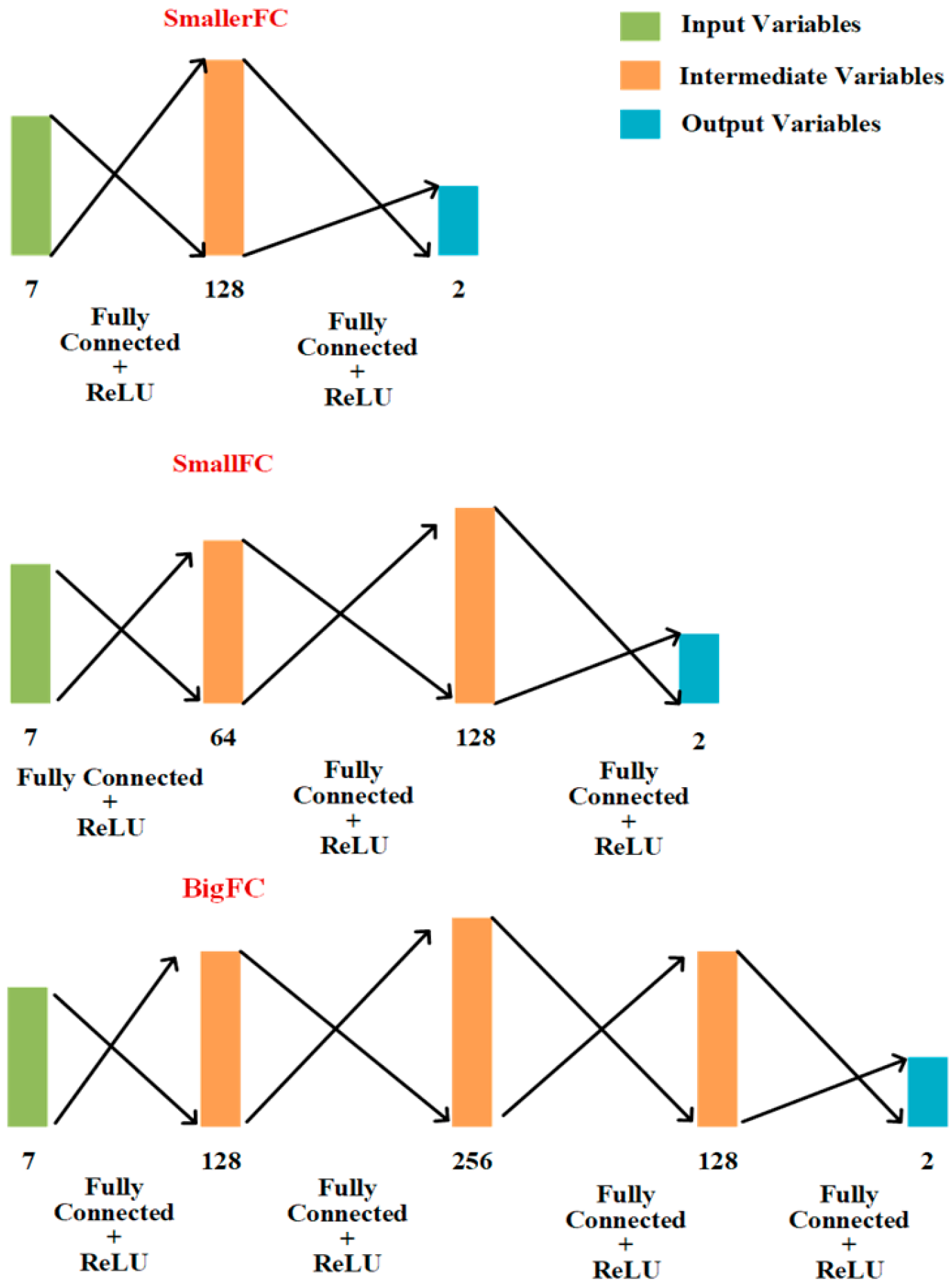
2.4. Coordinate Regression Algorithm
2.5. Model Training and Test Precision Evaluation
3. Results
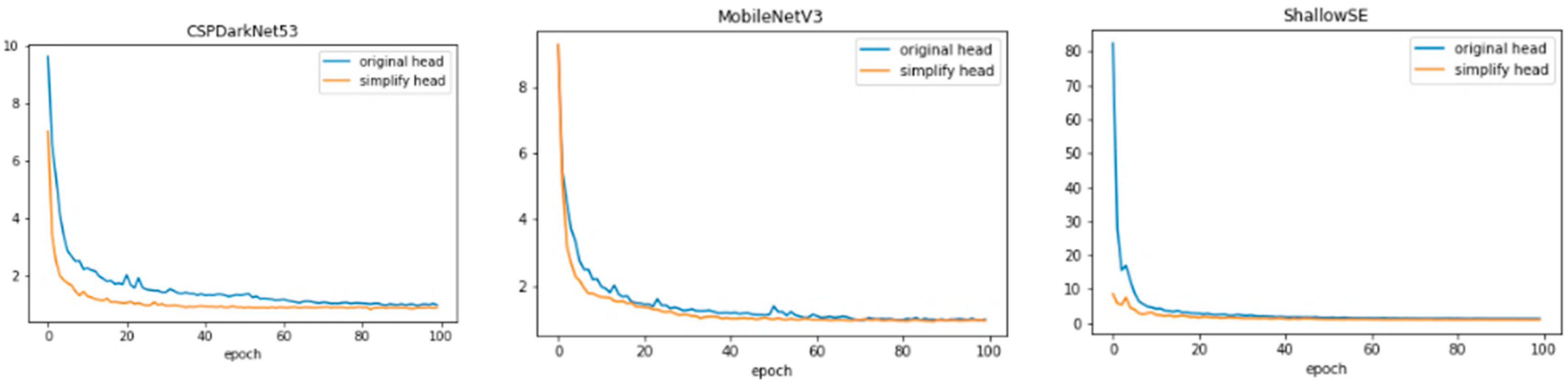
3.1. Model Streamlining before and after Comparison
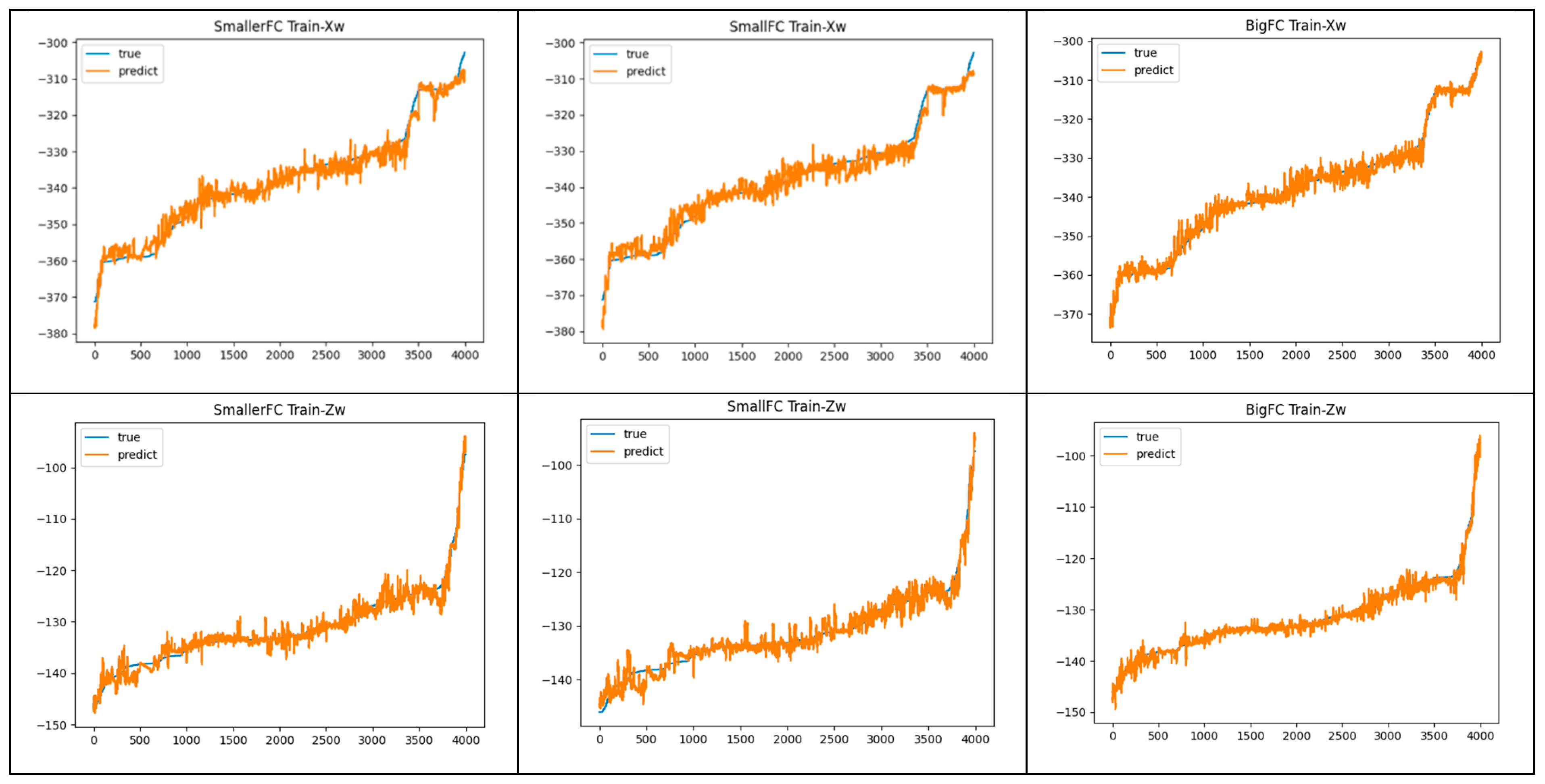
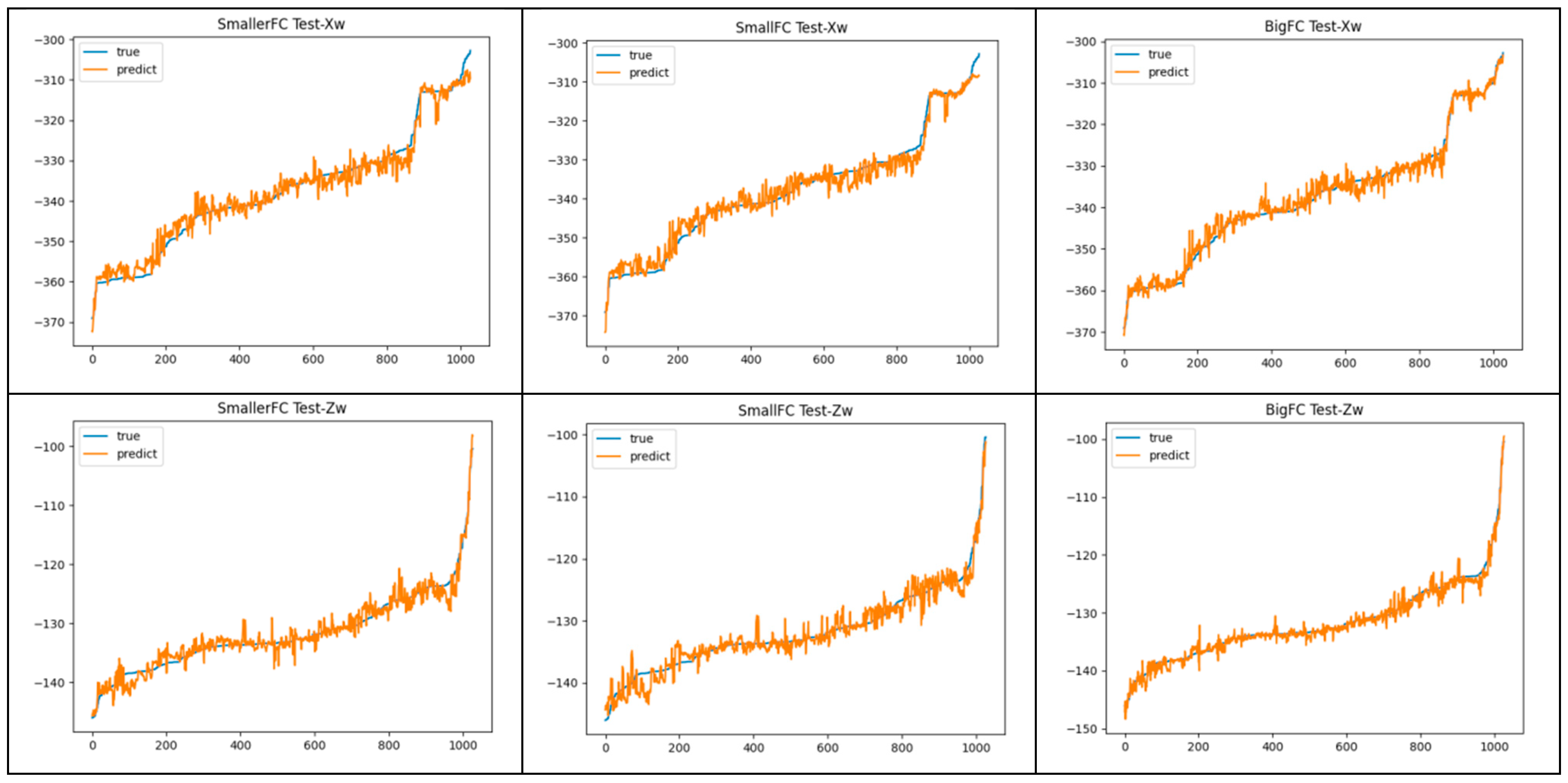
3.2. Analysis of 3D Coordinate Regression Algorithm Results
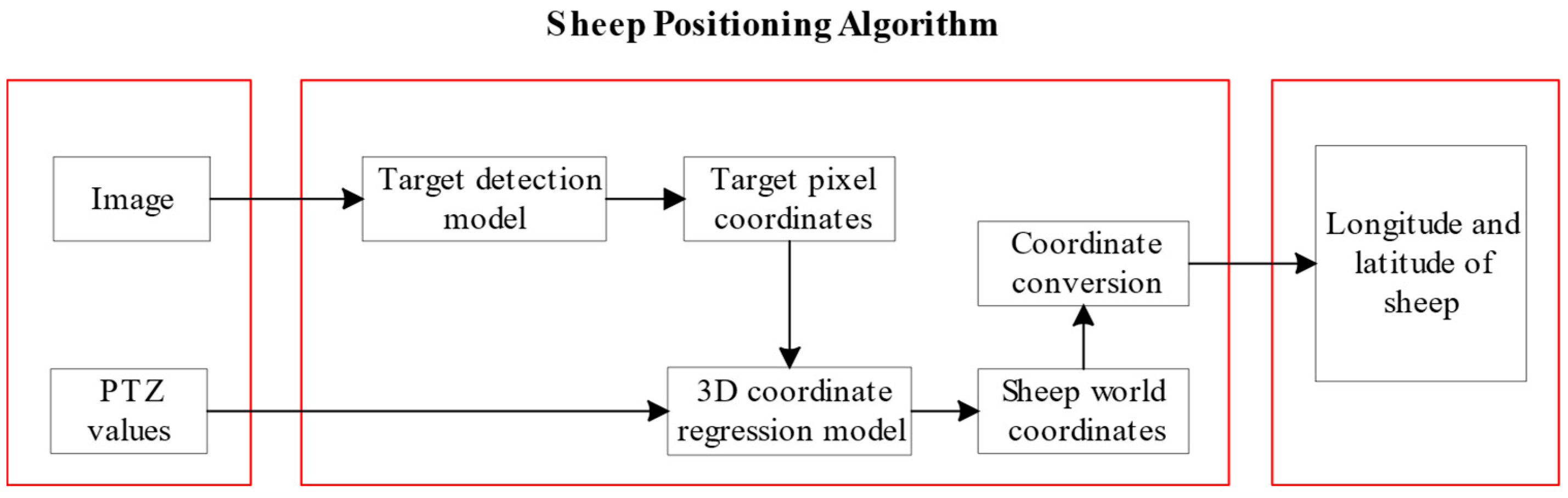
3.3. Goat Positioning Algorithm Results
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xiao, D.Q.; Feng, A.J.; Yang, Q.M. Rapid detection method of pig movement based on video tracking. J. Agric. Mach. 2016, 47, 351–357+331. [Google Scholar]
- Asikainen, M.; Haataja, K.; Toivanen, P. Wireless Indoor Tracking of Livestock for Behavioral Analysis. In Proceedings of the 2013 9th International Wireless Communications and Mobile Computing Conference (IWCMC), Sardinia, Italy, 1–5 July 2013; pp. 1833–1838. [Google Scholar]
- Hierold, M.; Hartmann, M.; Ripperger, S.; Mayer, F.; Heuberger, A.; Weigel, R.; Koelpin, A. Low-weight wireless sensor node for animal encounter detection and dual-band localization. In Proceedings of the 2016 IEEE Topical Conference on Wireless Sensors and Sensor Networks (WiSNet), Austin, TX, USA, 24–27 January 2016; pp. 21–23. [Google Scholar] [CrossRef]
- Duda, N.; Weigel, R.; Koelpin, A. Enhanced mobile node design for small size animal borne wireless sensor nodes with encounter detection and localization. In Proceedings of the 2018 11th German Microwave Conference (GeMiC), Freiburg, Germany, 12–14 March 2018; pp. 123–126. [Google Scholar] [CrossRef]
- Catarinucci, L.; Colella, R.; Mainetti, L.; Patrono, L.; Pieretti, S.; Sergi, I.; Tarricone, L. Smart RFID Antenna System for Indoor Tracking and Behavior Analysis of Small Animals in Colony Cages. IEEE Sens. J. 2014, 14, 1198–1206. [Google Scholar] [CrossRef]
- Millner, H.; Ebelt, R.; Hoffmann, G.; Vossiek, M. Wireless 3D localization of animals for trait and behavior analysis in indoor and outdoor areas. In Proceedings of the 2009 IEEE MTT-S International Microwave Workshop on Wireless Sensing, Local Positioning, and RFID, Cavtat, Croatia, 24–25 September 2009; pp. 1–4. [Google Scholar] [CrossRef]
- Xiong, B.H.; Qian, P.; Luo, Q.Y. Design and implementation of a fine feeding program based on individual body condition of dairy cows. J. Agric. Eng. 2005, 21, 118–120. [Google Scholar]
- Gor, M.; Vora, J.; Tanwar, S. GATA: GPS-Arduino Based Tracking and Alarm System for Protection of Wildlife Animals. In Proceedings of the 2017 International Conference on Computer, Information and Telecommunication Systems (CITS), Dalian, China, 21–23 July 2017; pp. 166–170. [Google Scholar]
- Nico, P.; David, P.; Jens, T. TDoA-Based Outdoor Positioning with Tracking Algorithm in a Public LoRa Network. WireLess Commun. Mob. Comput. 2018, 2018, 1864209. [Google Scholar]
- Singh, P.; Lindshield, S.M.; Zhu, F.; Reibman, A.R. Animal Localization in Camera-Trap Images with Complex Backgrounds. In Proceedings of the 2020 IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI), Albuquerque, NM, USA, 29–31 March 2020; pp. 66–69. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A. Modeling the Shape of the Scene: A Holistic Representation of the Spatial Envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Desicion-theoretic Generalization of On-line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Osuna, E.; Freund, R.; Girosi, F. Training Support Vector Machines: An Application to Face Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; pp. 130–136. [Google Scholar]
- Viola, P.; Jones, M. Rapid Object Detection Using a Boosted Cascade of Simple Features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; pp. 511–518. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision & Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- He, K.; Zhang, X.; Ren, S. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zhang, X.; Xuan, C.; Xue, J.; Chen, B.; Ma, Y. LSR-YOLO: A High-Precision, Lightweight Model for Sheep Face Recognition on the Mobile End. Animals 2023, 13, 1824. [Google Scholar] [CrossRef]
- Wei, L.; Dragomir, A.; Dumitru, E. SSD: Single Shot MultiBox Detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2020, 128, 642–656. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27–29 October 2019; pp. 6569–6578. [Google Scholar]
- Dong, W.; Tang, J.L.; Zhu, W. Dairy Goat Detection Based on Faster R-CNN from Surveillance Video. Comput. Electron. Agric. 2018, 154, 443–449. [Google Scholar]
- Ran, Y.; Deng, M.H. Pig Target Recognition in Piggery Environment Based on Deep Convolutional Neural Network. Test Eng. Manag. 2020, 83, 21087–21099. [Google Scholar]
- Lei, J.; Gao, S.; Rasool, M.A.; Fan, R.; Jia, Y.; Lei, G. Optimized Small Waterbird Detection Method Using Surveillance Videos Based on YOLOv7. Animals 2023, 13, 1929. [Google Scholar] [CrossRef]
- Song, S.; Liu, T.; Wang, H.; Hasi, B.; Yuan, C.; Gao, F.; Shi, H. Using Pruning-Based YOLOv3 Deep Learning Algorithm for Accurate Detection of Sheep Face. Animals 2022, 12, 1465. [Google Scholar] [CrossRef]
- Lee, T.; Na, Y.; Kim, B.G.; Lee, S.; Choi, Y. Identification of Individual Hanwoo Cattle by Muzzle Pattern Images through Deep Learning. Animals 2023, 13, 2856. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Yu, C.; Liu, H.; Chen, X.; Lei, Y.; Pang, T.; Zhang, J. An Integrated Goat Head Detection and Automatic Counting Method Based on Deep Learning. Animals 2022, 12, 1810. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Geffen, O.; Yitzhaky, Y.; Barchilon, N. A machine vision system to detect and count laying hens in battery cages-ScienceDirect. Animal 2020, 14, 2628–2634. [Google Scholar] [CrossRef] [PubMed]
- Felzenszwalb, P.F.; Mcallester, D.A.; Ramanan, D. A Discriminatively Trained, Multiscale, Deformable Part Model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Wang, Y.; Han, D.; Wang, L.; Guo, Y.; Du, H. Contextualized Small Target Detection Network for Small Target Goat Face Detection. Animals 2023, 13, 2365. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Num | xmin | ymin | xmax | ymax | Pan | Tilt | Zoom | Xw | Zw |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 370.81399 | 322.28571 | 411.34543 | 400.20779 | 145.6 | 2.7 | 18.4 | −302.75021 | −136.18202 |
| 2 | 371.12577 | 321.66233 | 414.15146 | 403.32467 | 145.6 | 2.7 | 18.4 | -- | −136.18202 |
| 3 | 370.50221 | 325.40259 | 416.64570 | 403.94805 | 145.6 | 2.7 | 18.4 | −302.75021 | −136.18202 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 5028 | 341.64705 | 256.94117 | 365.17647 | 303.0588235 | 144.7 | 7.5 | 3.8 | −371.25324 | −97.453996 |
| Network | Body | Params (M) | MACs (G) | mAP | FPS |
|---|---|---|---|---|---|
| VGG-16 | YOLOv4 | 14.714688 | 52.97694106 | 93.73% | 19.19 |
| ResNet-50 | YOLOv4 | 23.508032 | 14.12160512 | 93.34% | 18.30 |
| CSPDarkNet-53 | YOLOv4 | 26.617184 | 17.33899981 | 96.34% | 13.75 |
| MobileNetv3 | YOLOv4 | 5.483032 | 0.76975596 | 95.53% | 17.42 |
| EfficientNet-B0 | YOLOv4 | 3.595388 | 0.279041152 | 91.07% | 16.64 |
| ShallowSE | YOLOv4 | 0.400344 | 2.960644704 | 93.98% | 21.94 |
| Model | Params | mAP | FPS | Time (ms) |
|---|---|---|---|---|
| CSPDarkNet-53-YOLOv4 | 63,937,686 | 96.34% | 13.75 | 29.1 |
| CSPDarkNet-53-Custom_YOLO | 30,943,462 | 96.18% | 17.02 | 25.8 |
| MobileNetv3-YOLOv4 | 42,231,118 | 95.53% | 17.42 | 22.9 |
| MobileNetv3-Custom_YOLO | 9,623,966 | 96.09% | 17.81 | 21.3 |
| ShallowSE-YOLOv4 | 37,205,070 | 93.98% | 21.94 | 11.5 |
| ShallowSE-Custom_YOLO | 4,556,458 | 95.89% | 25.32 | 8.5 |
| Model | Training Set | Test Set | ||
|---|---|---|---|---|
| Average Error (m) | Maximum Error (m) | Average Error (m) | Maximum Error (m) | |
| SmallerFC | 1.3951541 | 8.1814829 | 1.37147070 | 8.7922006 |
| SmallFC | 1.0992516 | 8.3155968 | 1.05533216 | 8.3128948 |
| BigFC | 0.9719390 | 6.7282131 | 0.88486233 | 6.5844086 |
| Model | Longitude | Latitude | ||
|---|---|---|---|---|
| Maximum Error Distance (m) | Average Error Distance (m) | Maximum Error Distance (m) | Average Error Distance (m) | |
| ShallowSE-Custom_YOLO-SmallerFC | 4.3448 | 1.4355 | 5.5023 | 1.3414 |
| ShallowSE-Custom_YOLO-SmallFC | 2.0996 | 1.0433 | 3.3299 | 0.8292 |
| ShallowSE-Custom_YOLO-BigFC | 4.3176 | 1.9062 | 2.0578 | 0.8796 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Y.; Wang, X.; Han, M.; Xin, J.; Hou, Y.; Gong, Z.; Wang, L.; Fan, D.; Feng, L.; Han, D. Detection and Localization of Albas Velvet Goats Based on YOLOv4. Animals 2023, 13, 3242. https://doi.org/10.3390/ani13203242
Guo Y, Wang X, Han M, Xin J, Hou Y, Gong Z, Wang L, Fan D, Feng L, Han D. Detection and Localization of Albas Velvet Goats Based on YOLOv4. Animals. 2023; 13(20):3242. https://doi.org/10.3390/ani13203242
Chicago/Turabian StyleGuo, Ying, Xihao Wang, Mingjuan Han, Jile Xin, Yun Hou, Zhuo Gong, Liang Wang, Daoerji Fan, Lianjie Feng, and Ding Han. 2023. "Detection and Localization of Albas Velvet Goats Based on YOLOv4" Animals 13, no. 20: 3242. https://doi.org/10.3390/ani13203242
APA StyleGuo, Y., Wang, X., Han, M., Xin, J., Hou, Y., Gong, Z., Wang, L., Fan, D., Feng, L., & Han, D. (2023). Detection and Localization of Albas Velvet Goats Based on YOLOv4. Animals, 13(20), 3242. https://doi.org/10.3390/ani13203242