


Attention-Guided Instance Segmentation for Group-Raised Pigs
Abstract
:Simple Summary
Abstract
1. Introduction
- Taking ResNet50 as the backbone network and Mask R-CNN, and Cascade Mask R-CNN as the task networks, we compared the data augmentation operations during training and attention modules (1111 and 0010) to the backbone to explore the impact of two strategies on pig instance segmentation.
- Compared with the existing attention modules CBAM, DANet, and SCSE, it is proven that our proposed GAM attention module is more effective.
- We explore the influence of the number of groups on the performance of group attention to select the optimal number of groups.
- Model tests were performed on the datasets with different adhesion degrees, different ages, and third-party datasets that were not participating in training to verify the robustness and transferability of our model.
2. Materials and Methods
2.1. Data Source
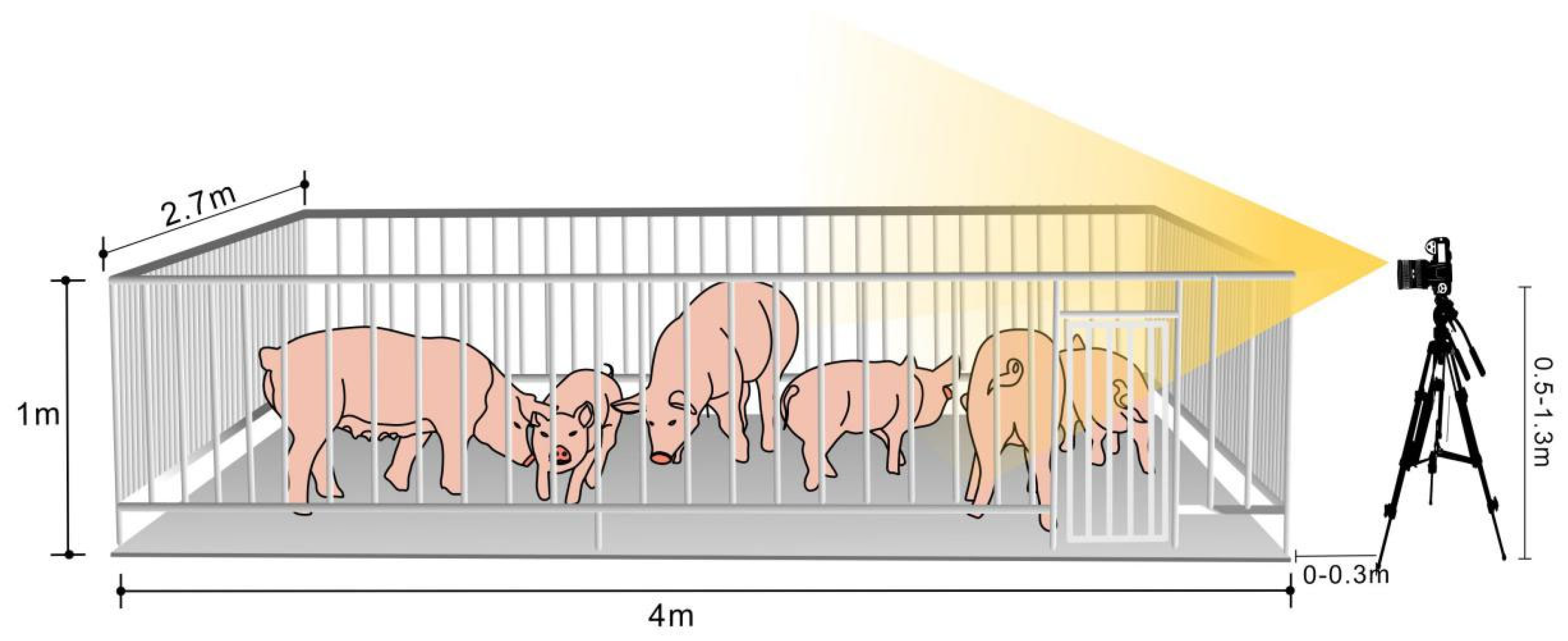
2.2. Data Collection
- The camera lens used for collection can be conveniently rotated and retracted, which is conducive to capturing data under changing conditions;
- This method can capture the face, hoof, and other areas with rich biological information to a greater extent, which is conducive to the identification of live pigs;
- Behavioral data such as climbing and aggression can be collected from a human perspective, which is helpful for pig behavior identification.
2.3. Data Preprocessing
- The collected videos were cut every 25 frames, and the resolution size of the obtained picture was 1920 × 1080, which was adjusted to 2048 × 1024 according to the aspect ratio of 2:1. The edge area was filled with white pixels, and LabelMe (http://labelme.csail.mit.edu/Release3.0/) (accessed on 5 April 2023) was used for data labeling. In order to reduce the memory usage of the model, the overall annotation data was scaled to 512 × 256, and finally, 1917 images were obtained as the initial annotation dataset, which was divided into 959 training sets, 192 validation sets, and 766 test sets.
- Then, the data augmentation operation performed during training was performed on the initially labeled dataset. Different from traditional related studies that preprocess the augmented data [1,3,11,25], the advantages of using data augmentation during training are as follows: (a) the generated data is more random; (b) each image has a probabilistic enhancement operation in each iteration process, avoiding the pre-enhancement strategy to limit the diversity of image data. The methods and their corresponding parameters used for data augmentation during training are shown in Table 3.
3. Pig Instance Segmentation Model
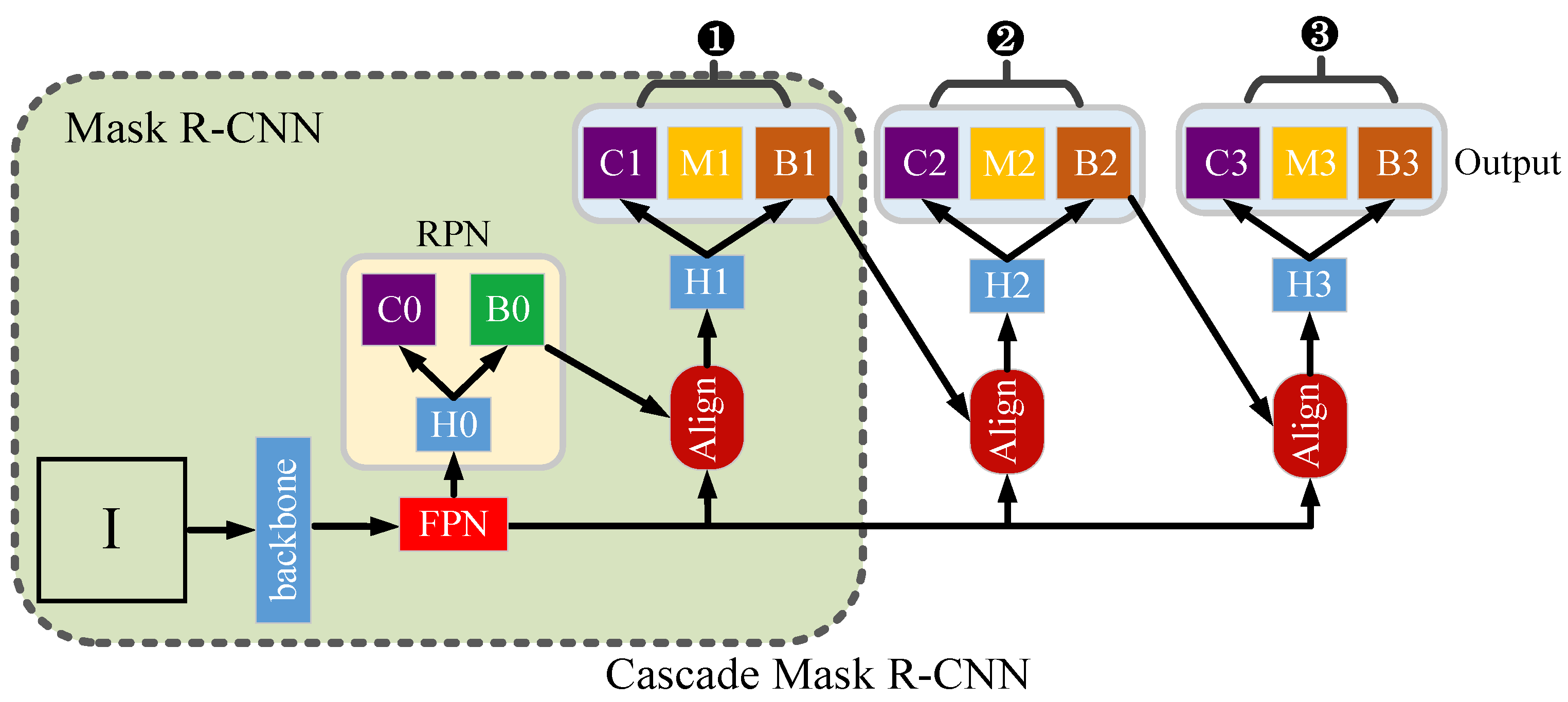
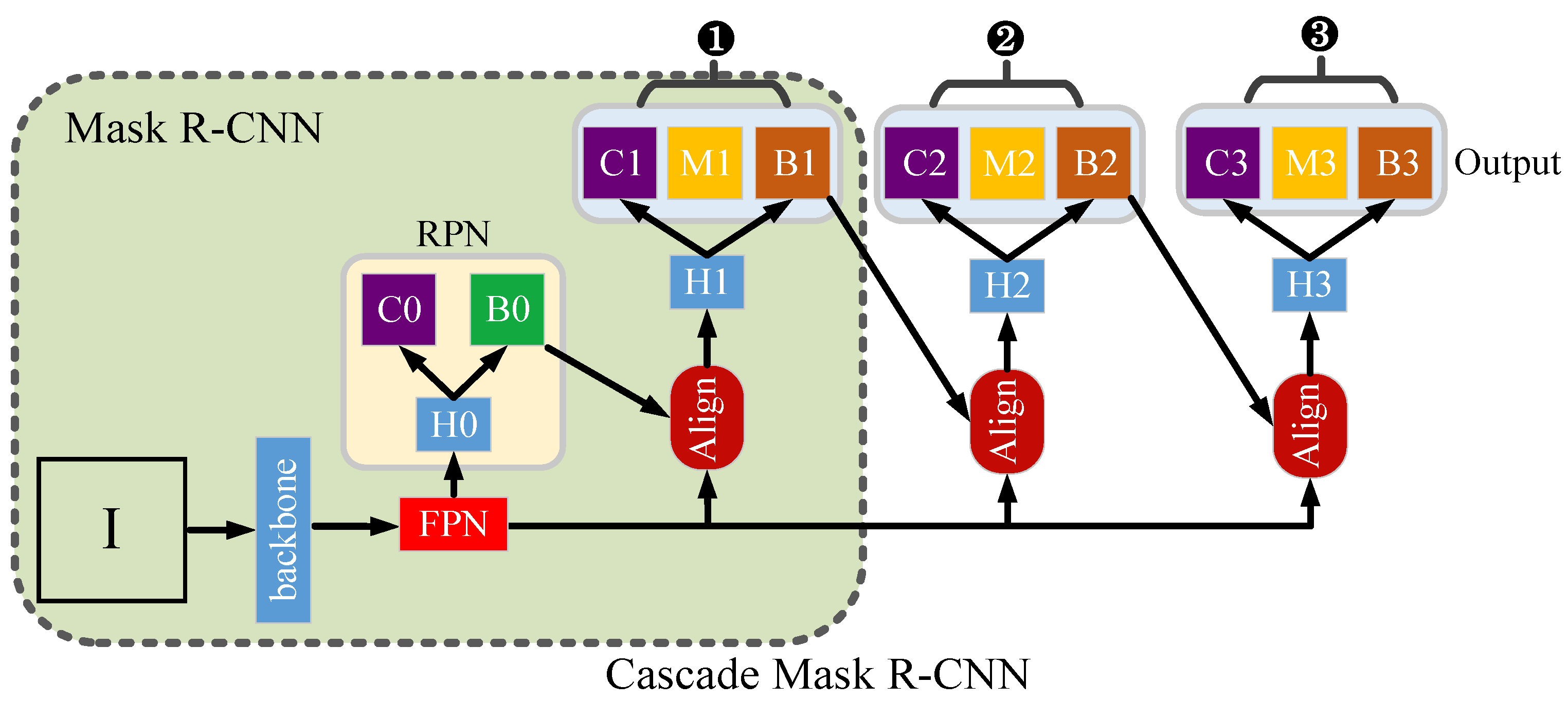
3.1. Mask R-CNN and Cascade Mask R-CNN Task Model
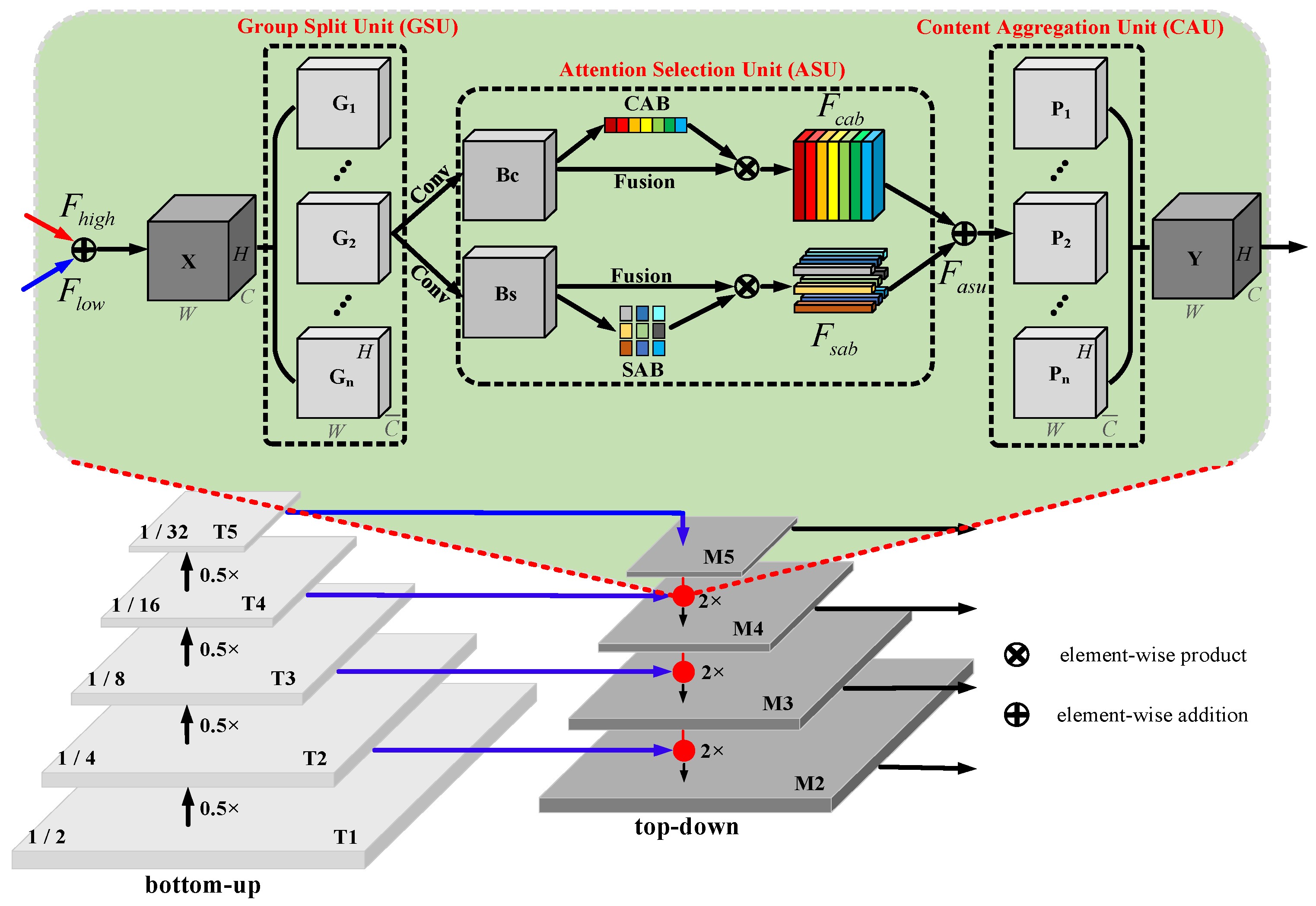
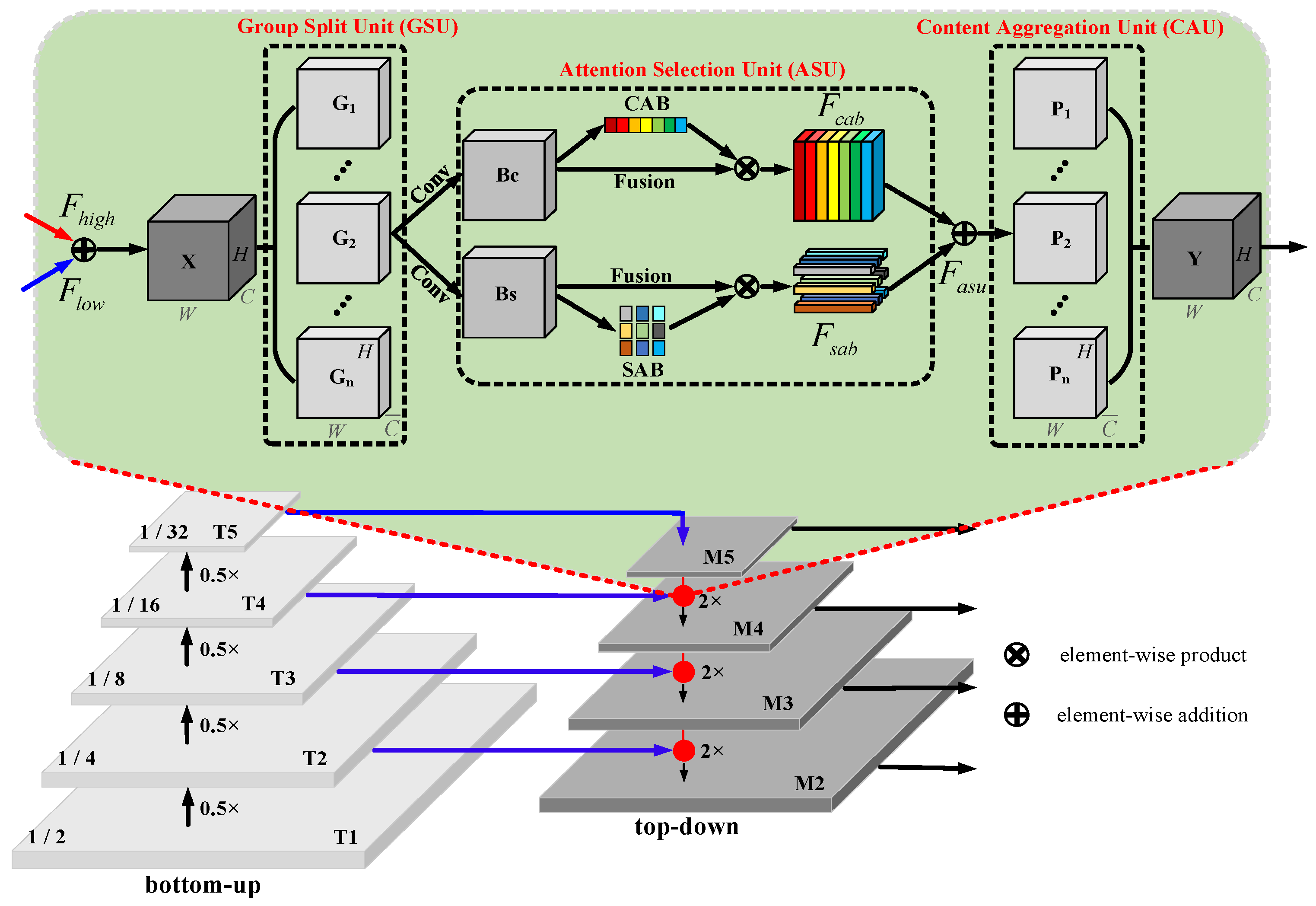
3.2. Feature Pyramid Network after Adding Group Attention
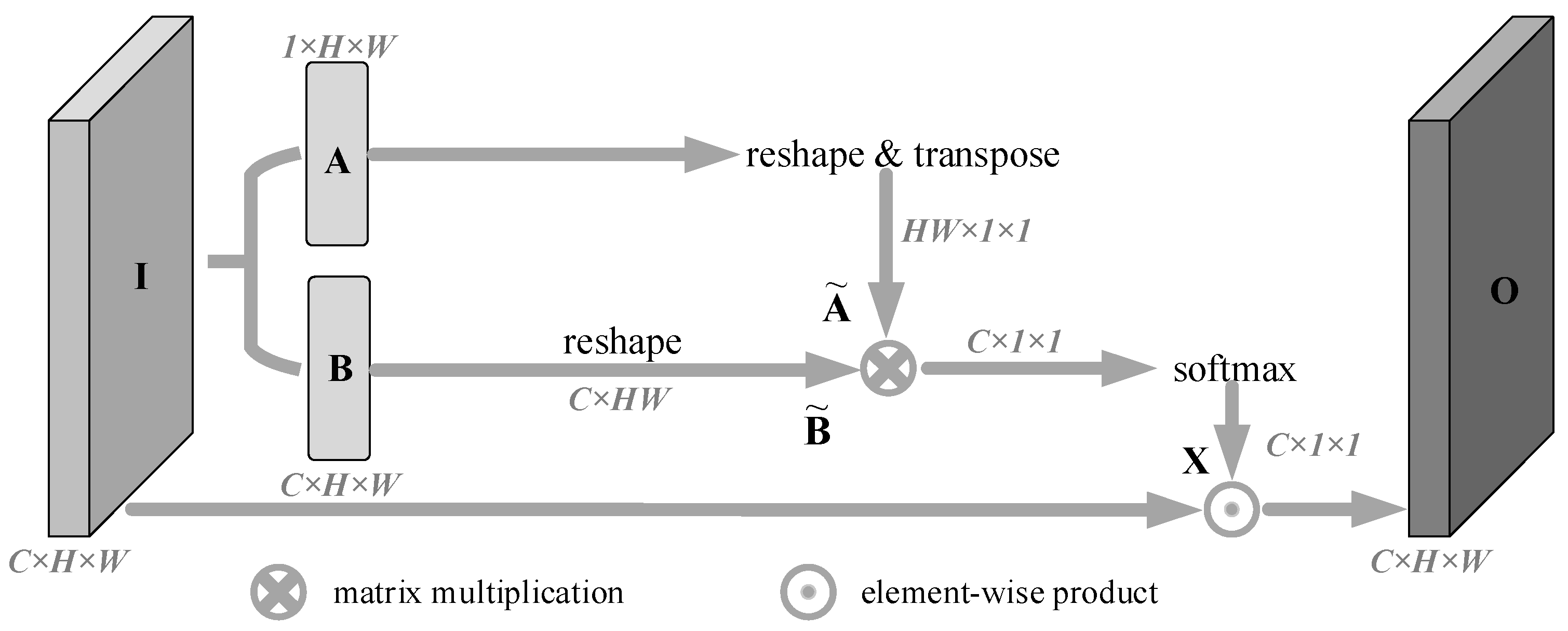
3.3. Channel Attention Branch
- (1)
- We performed a convolution operation on the input feature map I with a convolution kernel size of 3 × 3, and the number of channels set to C and 1, to obtain feature map B and channel-compressed feature map A, respectively. Where , , and .
- (2)
- Firstly, we performed dimension transformation and transposition operations on feature map A to obtain feature map , and also performed dimension transformation on feature map B to obtain feature map , where , . Then, we performed matrix multiplication of and , at the same time, the softmax activation function was used to process the multiplication result to obtain the channel attention map X, where . The value of each element in X represents the attention value of the i-th channel after the action of the remaining channels, and its value can be calculated by Formula (1), where represents the value of the i-th row of and exp(*) represents the exponential function with base e.
- (3)
- We bit-wise multiplied the channel attention map X with the input I to get the channel attention-enhanced representation output O, where .
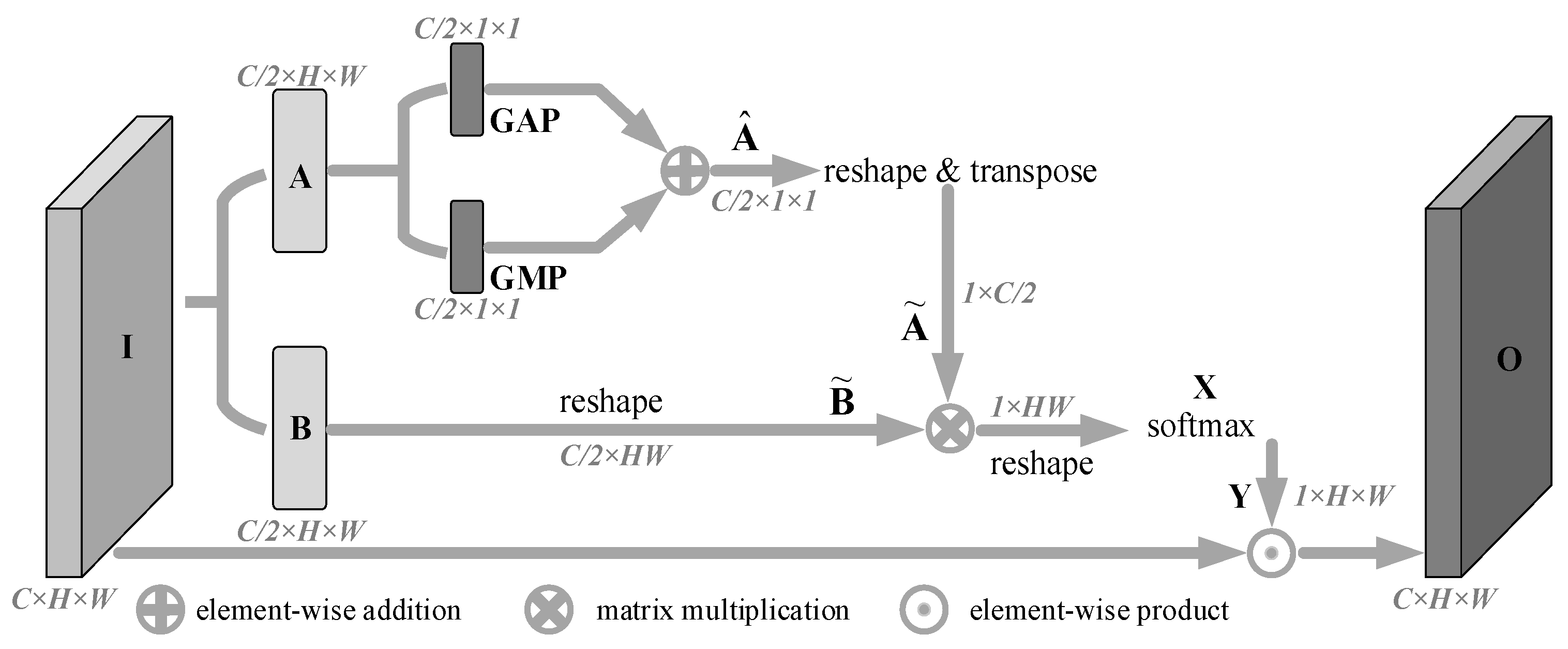
3.4. Spatial Attention Branch
- (1)
- We performed a two-way convolution operation on the input feature map I with a kernel size 3 × 3 and the number of channels , and obtain two feature maps A and B with the same size, where , and . The feature map A was compressed in the spatial dimension by two methods, Global Average Pooling (GAP) and Global Max Pooling (GMP), and the two compression results are superimposed bitwise to obtain the feature map . At the same time, the feature map B was dimensionally transformed to obtain the feature map .
- (2)
- We first performed dimension transformation and transposition operation on feature map to obtain feature map , and then performed matrix multiplication operation on and feature map . Then, the operation result was dimensionally transformed to obtain , and the softmax activation function was spliced to obtain the spatial attention weight map . Each element in X and in Y represents the activation value at the position of the i-th row and the j-th column in the corresponding feature map, which can be represented by Formula (2), where the two terms in the formula get the superimposed activation values from the column and row angles respectively.
- (3)
- We multiplied the spatial attention map Y by the input I to obtain the output filtered by spatial attention.
4. Experiment
4.1. Implementation Details
4.2. Evaluation Metrics
4.3. Main Results
4.3.1. The Effects of Backbone Attention, Data Augmentation, and Deformable Convolution
4.3.2. Add Different Attention Modules
4.3.3. Set Different Number Groups
4.3.4. Changes in the Amount of Parameters and the Amount of Calculation
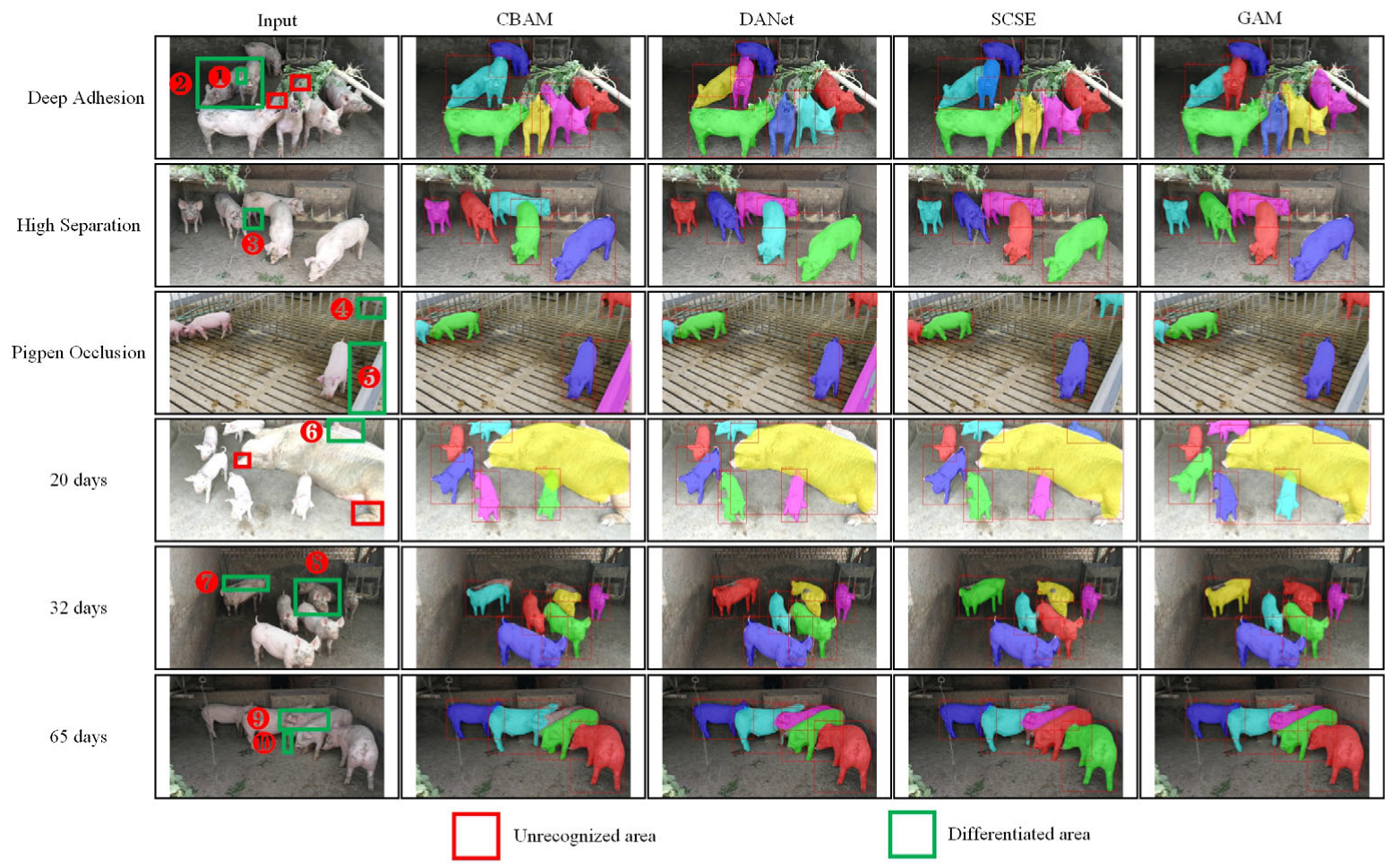
4.4. Visualization
4.4.1. Spatial Attention Visualization
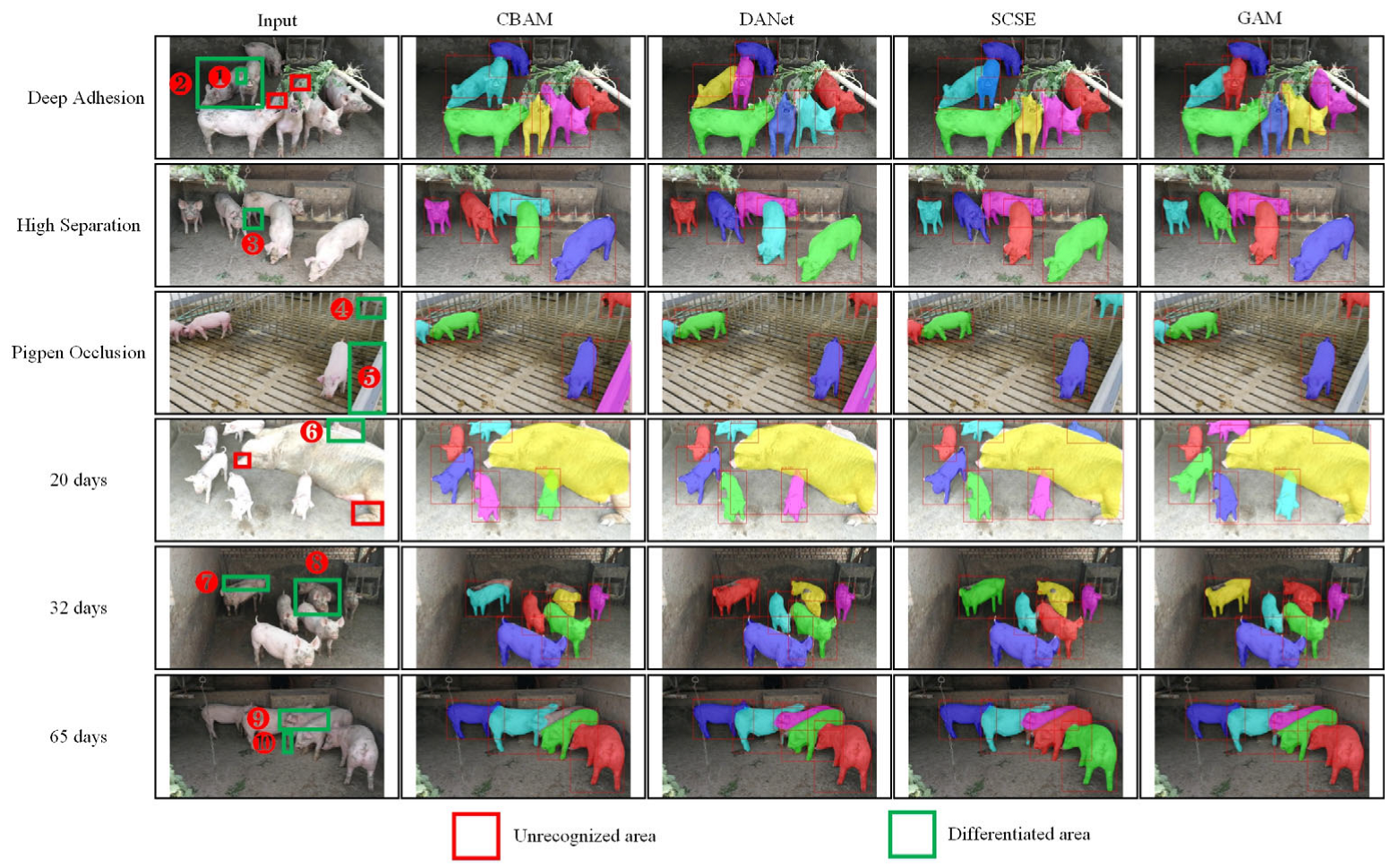
4.4.2. Visualization of Prediction Results for Different Scenarios and Age Stages
4.4.3. Visualization of Prediction Results for Other Datasets
5. Discussion
6. Conclusions
- (1)
- Introducing 0010 and 1111 attention, deformable convolution, and training-time data augmentation strategies in the backbone network can improve the prediction performance of the model to a certain extent. Additionally, the 1111 attention can get a better AP metric value than 0010 attention.
- (2)
- Under the premise of 1111-Albu-DCN, compared with adding CBAM, DANet, and SCSE attention modules, Mask R-CNN-GAM is 0.3~1.2% higher than Mask R-CNN-CBAM, 0.6~1.1% higher than Mask R-CNN-DANet, and 0.6~0.7% higher than Mask R-CNN-SCSE, indicating that GAM is more conducive to the extraction of attention information.
- (3)
- Under the same test conditions, with an increase in the number of groups, the corresponding AP metric value oscillates, and when the group size is set to 16, the two task networks have the best performance.
- (4)
- The visualization of the feature map of the spatial attention branch shows that spatial attention in GAM can aggregate denser and richer contextual dependencies and extract regional information with similar semantic categories.
- (5)
- Compared with the addition of CBAM, DANet, and SCSE attention modules, we perform the prediction on different scenes, different ages, and the third-party daytime and nighttime sub-datasets. After adding GAM attention, the segmentation is more complete and finer, indicating that GAM is more robust and has better migration ability.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, C.; Zhu, W.X.; Steibel, J.; Siegford, J.; Han, J.J.; Norton, T. Recognition of feeding behaviour of pigs and determination of feeding time of each pig by a video-based deep learning method. Comput. Electron. Agric. 2020, 176, 105642. [Google Scholar] [CrossRef]
- Hu, Z.W.; Yang, H.; Lou, T.T. Dual attention-guided feature pyramid network for instance segmentation of group pigs. Comput. Electron. Agr. 2021, 186, 106140. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, W.X.; Oczak, M.; Maschat, K.; Baumgartner, J.; Larsen, M.L.V.; Norton, T. A computer vision approach for recognition of the engagement of pigs with different enrichment objects. Comput. Electron. Agric. 2020, 175, 105580. [Google Scholar] [CrossRef]
- Marsot, M.; Mei, J.Q.; Shan, X.C.; Ye, L.Y.; Feng, P.; Yan, X.J.; Li, C.F.; Zhao, Y.F. An adaptive pig face recognition approach using convolutional neural networks. Comput. Electron. Agric. 2020, 173, 105386. [Google Scholar] [CrossRef]
- Hu, Z.W.; Yan, H.W.; Lou, T.T. Parallel channel and position attention-guided feature pyramid for pig face posture detection. Int. J. Agric. Biol. Eng. 2022, 15, 222–234. [Google Scholar] [CrossRef]
- Yan, H.W.; Hu, Z.W.; Cui, Q.L. Study on feature extraction of pig face based on principal component analysis. INMATEH-Agric. Eng. 2022, 68, 333–340. [Google Scholar] [CrossRef]
- Yan, H.W.; Cai, S.R.; Li, E.H.; Liu, J.Y.; Hu, Z.W.; Li, Q.S.; Wang, H.T. Study on the Influence of PCA Pre-Treatment on Pig Face Identification with Random Forest. Animals 2023, 13, 1555. [Google Scholar] [CrossRef]
- Yan, H.W.; Liu, Z.Y.; Cui, Q.L.; Hu, Z.W.; Li, Y.W. Detection of facial gestures of group pigs based on improved Tiny-YOLO. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2019, 35, 169–179. [Google Scholar]
- Chen, F.; Liang, X.M.; Chen, L.H.; Liu, B.Y.; Lan, Y.B. Novel method for real-time detection and tracking of pig body and its different parts. Agric. Biol. Eng. 2020, 13, 144–149. [Google Scholar] [CrossRef]
- Gan, H.T.; Ou, M.Q.; Zhao, F.Y.; Xu, C.G.; Li, S.M.; Chen, C.X.; Xue, Y.J. Automated piglet tracking using a single convolutional neural network. Biosyst. Eng. 2021, 205, 48–63. [Google Scholar] [CrossRef]
- Jensen, D.B.; Pedersen, L.J. Automatic counting and positioning of slaughter pigs within the pen using a convolutional neural network and video images. Comput. Electron. Agric. 2021, 188, 106296. [Google Scholar] [CrossRef]
- Hu, Z.W.; Yang, H.; Lou, T.T. Instance detection of group breeding pigs using a pyramid network with dual attention feature. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE). 2021, 37, 166–174. [Google Scholar]
- Xiao, D.Q.; Lin, S.C.; Liu, Y.F.; Yang, Q.M.; Wu, H.L. Group-housed pigs and their body parts detection with Cascade Faster R-CNN. Int. J. Agric. Biol. Eng. 2022, 15, 203–209. [Google Scholar] [CrossRef]
- Yan, H.W.; Liu, Z.Y.; Cui, Q.L.; Hu, Z.W. Multi-target detection based on feature pyramid attention and deep convolution network for pigs. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2020, 36, 193–202. [Google Scholar]
- Hu, Z.W.; Yang, H.; Lou, T.T.; Yan, H.W. Concurrent channel and spatial attention in Fully Convolutional Network for individual pig image segmentation. Int. J. Agric. Biol. Eng. 2023, 16, 232–242. [Google Scholar] [CrossRef]
- Hu, Z.W.; Yang, H.; Lou, T.T.; Hu, G.; Xie, Q.Q.; Huang, J.J. Extraction of pig contour based on fully convolutional networks. J. South China Agric. Univ. 2018, 39, 111–119. [Google Scholar]
- Yang, A.Q.; Huang, H.S.; Zheng, C.; Zhu, X.M.; Yang, X.F.; Chen, P.F.; Xue, Y.J. High-accuracy image segmentation for lactating sows using a fully convolutional network. Biol. Eng. 2018, 176, 36–47. [Google Scholar] [CrossRef]
- Yang, A.Q.; Huang, H.S.; Zhu, X.M.; Yang, X.F.; Chen, P.F.; Li, S.M.; Xue, Y.J. Automatic recognition of sow nursing behaviour using deep learning-based segmentation and spatial and temporal features. Biol. Eng. 2018, 175, 133–145. [Google Scholar] [CrossRef]
- Yang, A.Q.; Huang, H.S.; Yang, X.F.; Li, S.M.; Chen, C.X.; Gan, H.M.; Xue, Y.J. Automated video analysis of sow nursing behavior based on fully convolutional network and oriented optical flow. Comput. Electron. Agric. 2019, 167, 105048. [Google Scholar] [CrossRef]
- Xu, B.B.; Wang, W.S.; Falzon, G.; Kwan, P.; Guo, L.F.; Chen, G.P.; Tait, A.; Schneider, D. Automated cattle counting using Mask R-CNN in quadcopter vision system. Comput. Electron. Agric. 2020, 171, 105300. [Google Scholar] [CrossRef]
- Vayssade, J.A.; Jones, G.; Gée, C.; Paoli, J.N. Pixelwise instance segmentation of leaves in dense foliage. Comput. Electron. Agric. 2022, 195, 106797. [Google Scholar] [CrossRef]
- Liu, X.; Hu, C.H.; Li, P.P. Automatic segmentation of overlapped poplar seedling leaves combining mask R-CNN and DBSCAN. Comput. Electron. Agric. 2020, 178, 105753. [Google Scholar] [CrossRef]
- Tian, Y.N.; Yang, G.D.; Wang, Z.; Li, E.; Liang, Z.Z. Instance segmentation of apple flowers using the improved mask R-CNN model. Biol. Eng. 2020, 193, 264–278. [Google Scholar] [CrossRef]
- Tu, S.Q.; Yuan, W.J.; Liang, Y.; Wang, F.; Wan, H. Automatic detection and segmentation for group-housed pigs based on PigMS R-CNN. Sensors 2021, 21, 3251. [Google Scholar] [CrossRef]
- Gan, H.M.; Ou, M.Q.; Li, C.P.; Wang, X.R.; Guo, J.F.; Mao, A.X.; Ceballos, M.C.; Parsons, T.D.; Liu, K.; Xue, Y.J. Automated detection and analysis of piglet suckling behaviour using high-accuracy amodal instance segmentation. Comput. Electron. Agric. 2022, 199, 107162. [Google Scholar] [CrossRef]
- Brünger, J.; Gentz, M.; Traulsen, I.; Koch, R. Panoptic instance segmentation on pigs. arXiv 2020, arXiv:2005.10499. [Google Scholar]
- Liu, K.; Yang, H.; Yang, H.Q.; Meng, K.; Hu, Z.W. Instance segmentation of group-housed pigs based on recurrent residual attention. J. South China Agric. Univ. 2020, 41, 169–178. [Google Scholar]
- Zhang, X.Y.; Zhou, X.Y.; Lin, M.X.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Zhang, H.; Zu, K.; Lu, J.; Zou, Y.; Meng, D. Epsanet: An efficient pyramid split attention block on convolutional neural network. arXiv 2021, arXiv:2105.14447. [Google Scholar]
- He, K.M.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.W.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. NeurIPS 2015, 28, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.J.; Liu, F.Q.; Fan, X.Y.; Huang, D. Polarized self-attention: Towards high-quality pixel-wise regression. arXiv 2021, arXiv:2107.00782. [Google Scholar]
- Woo, S.Y.; Park, J.C.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhu, X.Z.; Cheng, D.Z.; Zhang, Z.; Lin, S.; Dai, J.F. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 6688–6697. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.J.; Li, Y.; Bao, Y.J.; Fang, Z.W.; Lu, H.Q. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Roy, A.G.; Navab, N.; Wachinger, C. Concurrent spatial and channel squeeze & excitation in fully convolutional networks. In Proceedings of the MICCAI, Granada, Spain, 16–20 September 2018; pp. 421–429. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Meaning |
|---|---|
| CNN | Convolutional Neural Network |
| FCN | Fully Convolutional Network |
| CBAM | Convolutional Block Attention Module |
| DANet | Dual Attention Network |
| SCSE | Concurrent Spatial and Channel Squeeze and Channel Excitation |
| Mask R-CNN | Mask Region-based Convolutional Neural Network |
| Cascade Mask R-CNN | Cascade Mask Region-based Convolutional Neural Network |
| ResNet | Residual Network |
| RPN | Region Proposal Network |
| FPN | Feature Pyramid Network |
| IOU | Intersection over Union |
| GAM | Group Attention Module |
| GSU | Group Split Unit |
| ASU | Attention Selection Unit |
| CAU | Content Aggregation Unit |
| CAB | Channel Attention Branch |
| SAB | Spatial Attention Branch |
| AP | Average Precision |
| Farm Name | Collection Time | Collection Temperature | Collection Environment | Pigpen Size |
|---|---|---|---|---|
| Farm One | 1 June 2019 9:00~14:00 | Sunny, 23~29 °C | Outdoor, bright light | 3.5 m × 2.5 m × 1 m |
| Farm Two | 13 October 2019 10:30~12:00 | Cloudy, 10~19 °C | Indoors, low light | 4 m × 2.7 m × 1 m |
| Augmentation Method | Parameter Settings | Probability |
|---|---|---|
| Translation zoom and rotate | The translation factor is 0.0625, the image scaling and rotation factors are set to 0.1~0.3, and linear interpolation is used to fill the area where the translation occurs. | 0.5 |
| Randomly change brightness and contrast | The brightness and contrast variation range factors are both set to 0.1~0.3. | 0.2 |
| RGB value transformation | The R/G/B three-channel random transformation range is set to 0~10. | 0.1 |
| HSV value transformation | The range of H/S/V random transformation is set to 0~20, 0~30, and 0~20, respectively. | 0.1 |
| Image compression | The upper and lower limits of the compression percentage are set to 95 and 85, respectively. | 0.2 |
| Randomly rearrange channels | —— | 0.1 |
| Median blur | The filter radius is set to 3. | 0.1 |
| Task Network | Backbone Attention Type | Extra | AP50 | AP75 | APL | AP |
|---|---|---|---|---|---|---|
| Mask R-CNN | 0010 | NONE | 89.9 | 80.2 | 68.4 | 66.0 |
| Albu | 91.4 | 80.9 | 68.8 | 66.5 | ||
| Albu-DCN | 91.8 | 82.3 | 69.7 | 67.3 | ||
| 1111 | NONE | 91.6 | 82.0 | 69.6 | 67.2 | |
| Albu | 91.9 | 83.1 | 70.1 | 67.7 | ||
| Albu-DCN | 92.2 | 83.6 | 70.6 | 68.1 | ||
| Cascade Mask R-CNN | 0010 | NONE | 91.1 | 82.5 | 70.4 | 68.0 |
| Albu | 91.7 | 82.9 | 70.6 | 68.3 | ||
| Albu-DCN | 91.9 | 83.0 | 70.7 | 68.5 | ||
| 1111 | NONE | 91.9 | 83.3 | 71.0 | 68.7 | |
| Albu | 92.3 | 83.1 | 71.2 | 68.8 | ||
| Albu-DCN | 92.1 | 83.6 | 71.4 | 69.0 |
| Task Network | Extra | Attention Module | AP50 | AP75 | APL | AP |
|---|---|---|---|---|---|---|
| Mask R-CNN | 0010-Albu-DCN | CBAM | 92.1 | 82.5 | 69.9 | 67.5 |
| DANet | 91.8 | 83.1 | 69.8 | 67.4 | ||
| SCSE | 92.3 | 82.3 | 70.1 | 67.7 | ||
| GAM | 92.3 | 83.3 | 70.8 | 68.3 | ||
| 1111-Albu-DCN | CBAM | 92.3 | 84.4 | 71.6 | 69.1 | |
| DANet | 92.7 | 84.0 | 71.7 | 69.2 | ||
| SCSE | 92.6 | 84.0 | 72.1 | 69.6 | ||
| GAM | 93.3 | 84.7 | 72.7 | 70.3 | ||
| Cascade Mask R-CNN | 0010-Albu-DCN | CBAM | 93.0 | 83.9 | 72.1 | 69.6 |
| DANet | 92.9 | 84.5 | 72.1 | 69.7 | ||
| SCSE | 92.4 | 84.2 | 72.2 | 69.9 | ||
| GAM | 93.4 | 84.9 | 72.8 | 70.5 | ||
| 1111-Albu-DCN | CBAM | 93.9 | 85.8 | 73.7 | 71.3 | |
| DANet | 94.2 | 86.2 | 73.9 | 71.5 | ||
| SCSE | 94.4 | 86.4 | 74.2 | 71.9 | ||
| GAM | 94.4 | 86.5 | 74.6 | 72.2 |
| Task Network | Group Size | AP50 | AP75 | APL | AP |
|---|---|---|---|---|---|
| Mask R-CNN | 8 | 92.1 | 83.6 | 71.4 | 68.9 |
| 16 | 93.3 | 84.7 | 72.7 | 70.3 | |
| 32 | 92.5 | 84.1 | 72.0 | 69.5 | |
| 64 | 93.1 | 84.4 | 72.4 | 69.8 | |
| Cascade Mask R-CNN | 8 | 93.9 | 86.3 | 74.1 | 71.7 |
| 16 | 94.4 | 86.5 | 74.6 | 72.2 | |
| 32 | 93.7 | 85.9 | 73.9 | 71.6 | |
| 64 | 94.0 | 86.2 | 74.1 | 71.7 |
| Model | Parameters | GFLOPs |
|---|---|---|
| CBAM | +0.020 M | +0.030 |
| DANet | +0.041 M | +0.034 |
| SCSE | +0.033 M | +0.031 |
| GAM | +0.038 M | +0.032 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Z.; Yang, H.; Yan, H. Attention-Guided Instance Segmentation for Group-Raised Pigs. Animals 2023, 13, 2181. https://doi.org/10.3390/ani13132181
Hu Z, Yang H, Yan H. Attention-Guided Instance Segmentation for Group-Raised Pigs. Animals. 2023; 13(13):2181. https://doi.org/10.3390/ani13132181
Chicago/Turabian StyleHu, Zhiwei, Hua Yang, and Hongwen Yan. 2023. "Attention-Guided Instance Segmentation for Group-Raised Pigs" Animals 13, no. 13: 2181. https://doi.org/10.3390/ani13132181
APA StyleHu, Z., Yang, H., & Yan, H. (2023). Attention-Guided Instance Segmentation for Group-Raised Pigs. Animals, 13(13), 2181. https://doi.org/10.3390/ani13132181