


LSR-YOLO: A High-Precision, Lightweight Model for Sheep Face Recognition on the Mobile End



Abstract
Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Self-Built Dataset
2.1.1. Data Collection
2.1.2. Dataset Pre-Processing and Creation
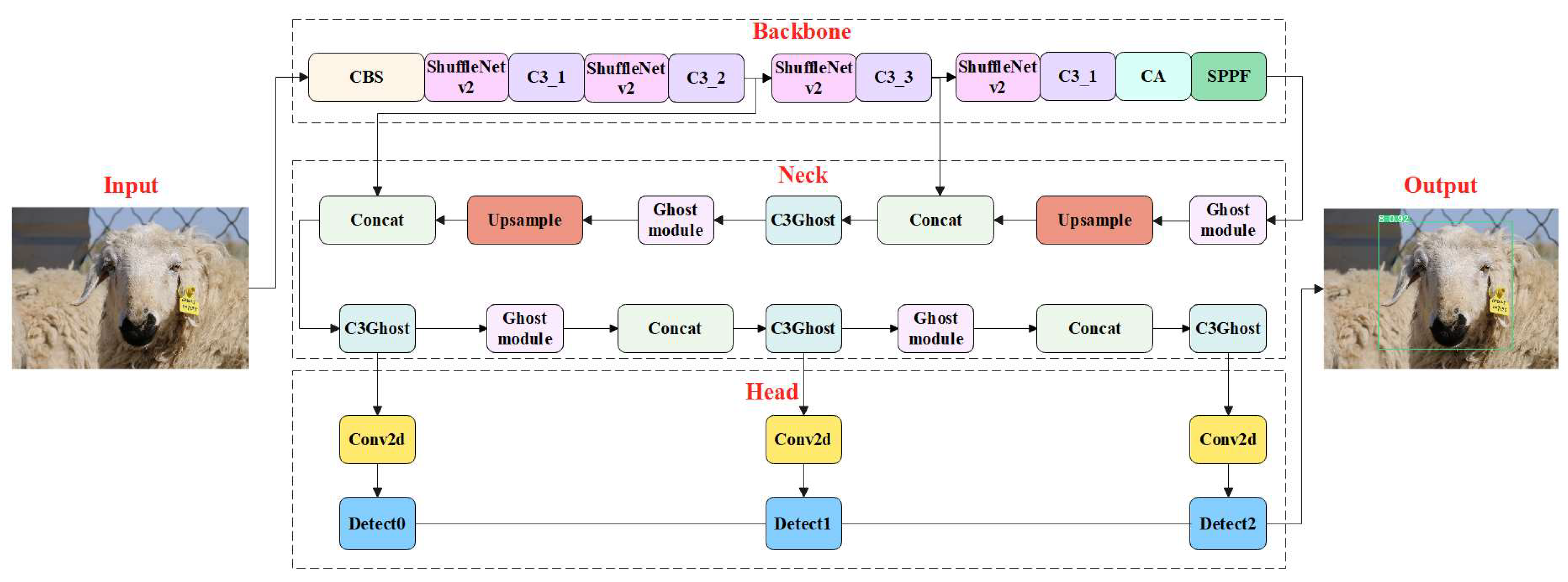
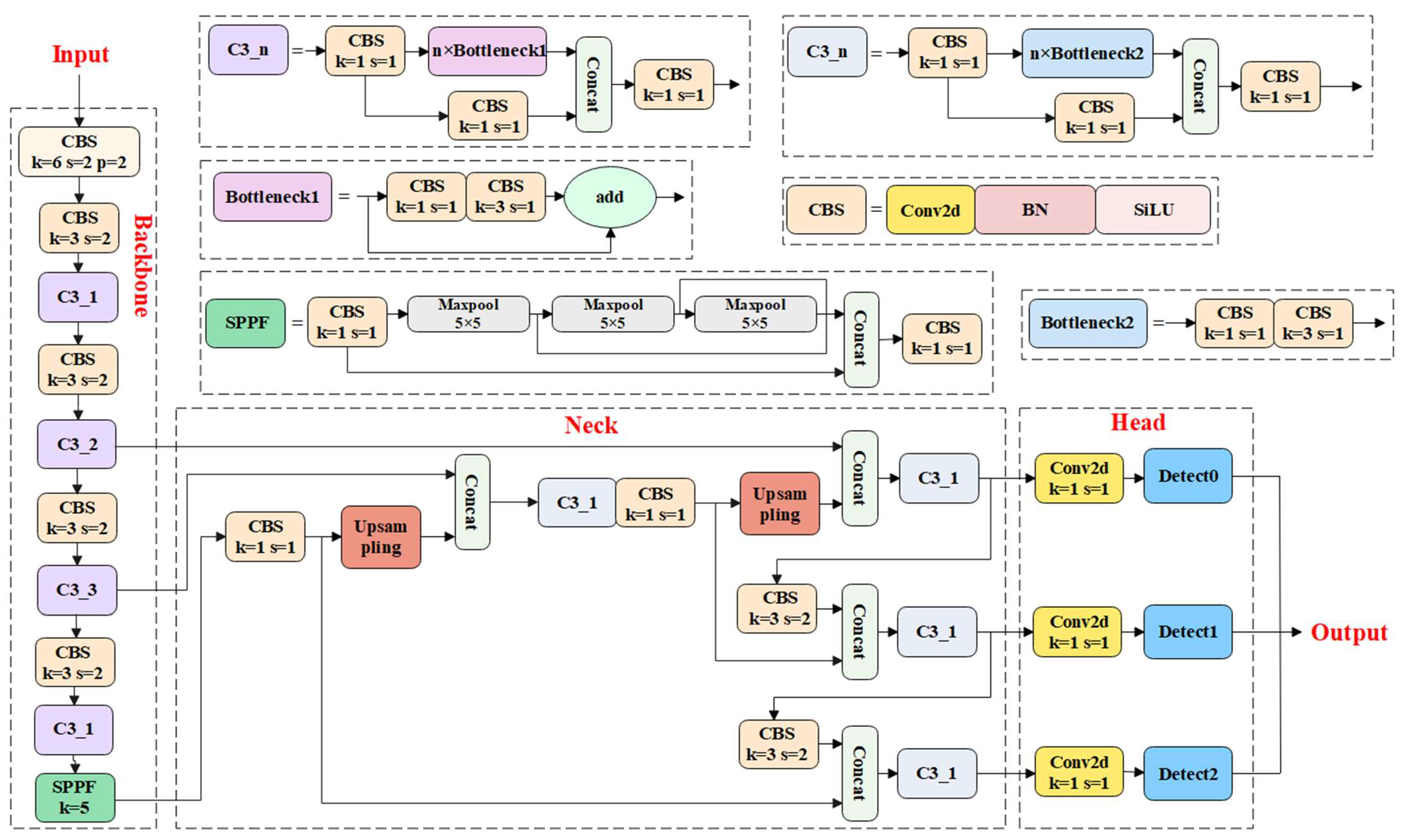
2.2. LSR-YOLO Network Architecture Design
2.2.1. Sheep Face Detection Module
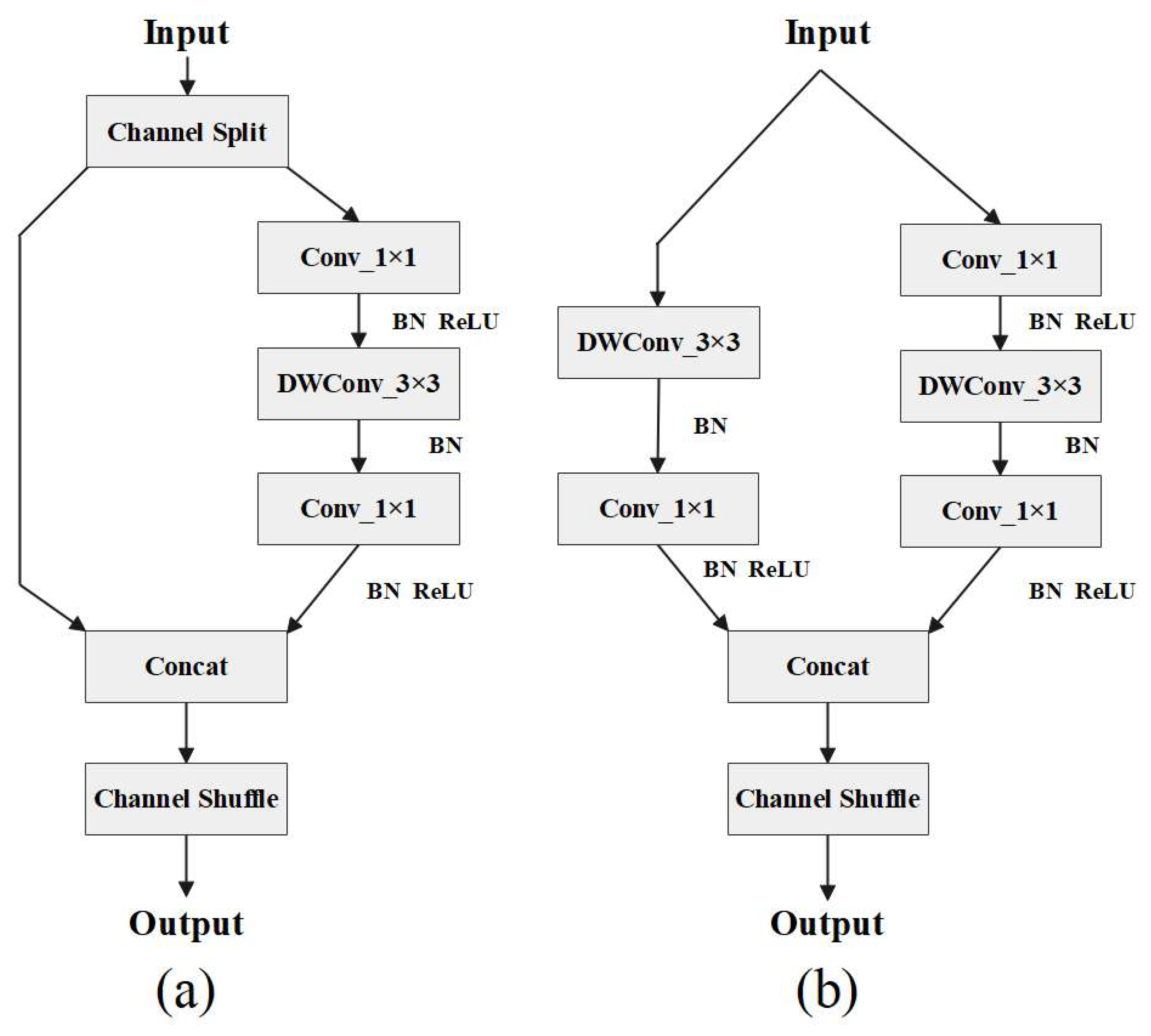
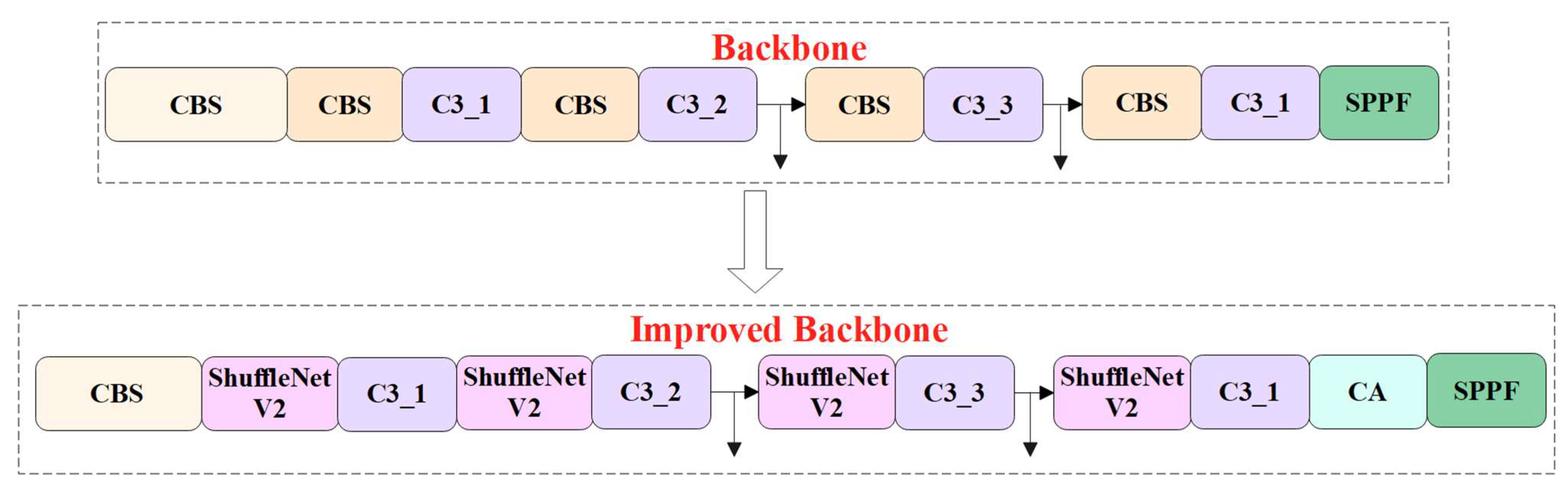
2.2.2. Optimization of the Backbone Network
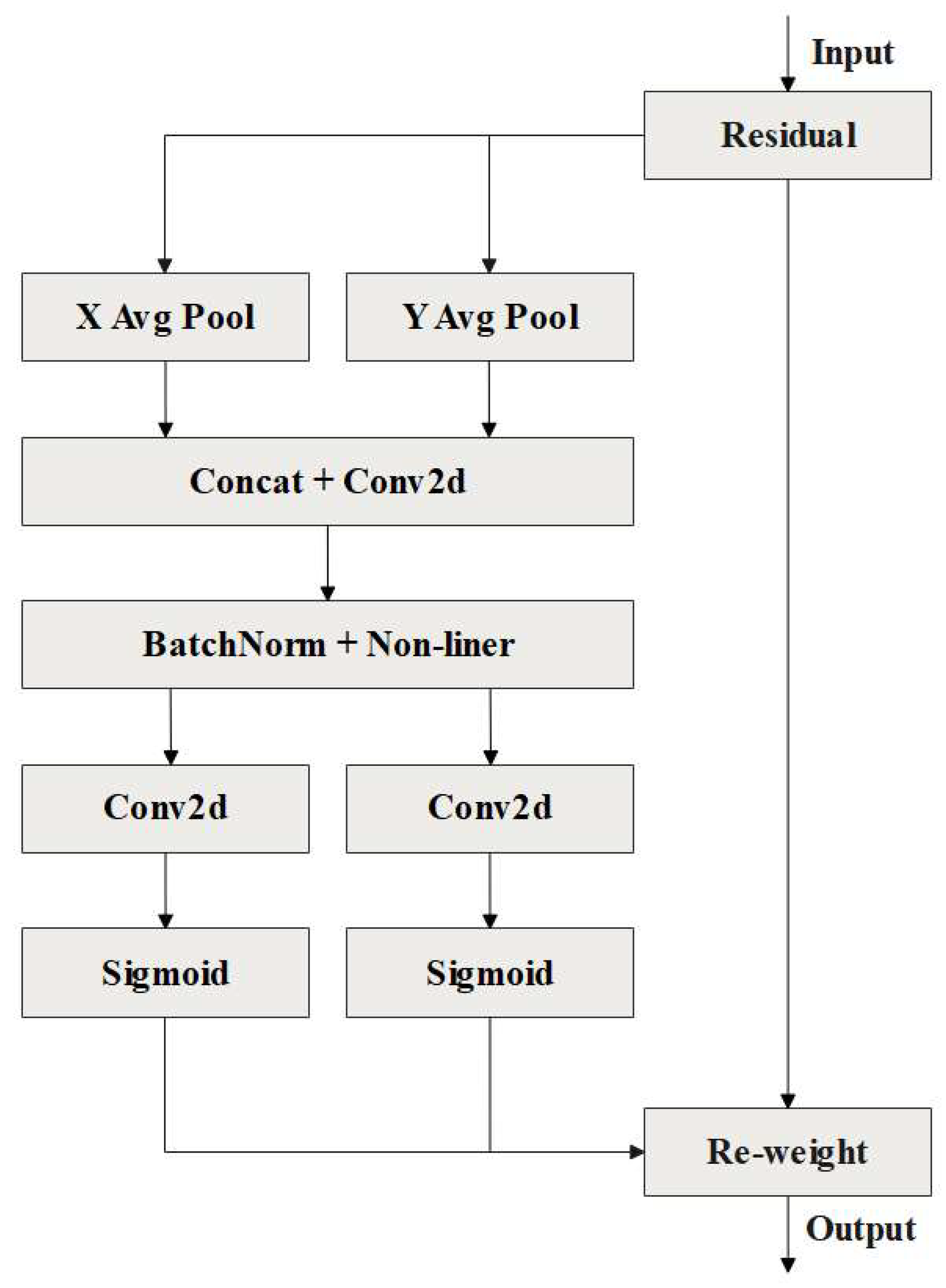
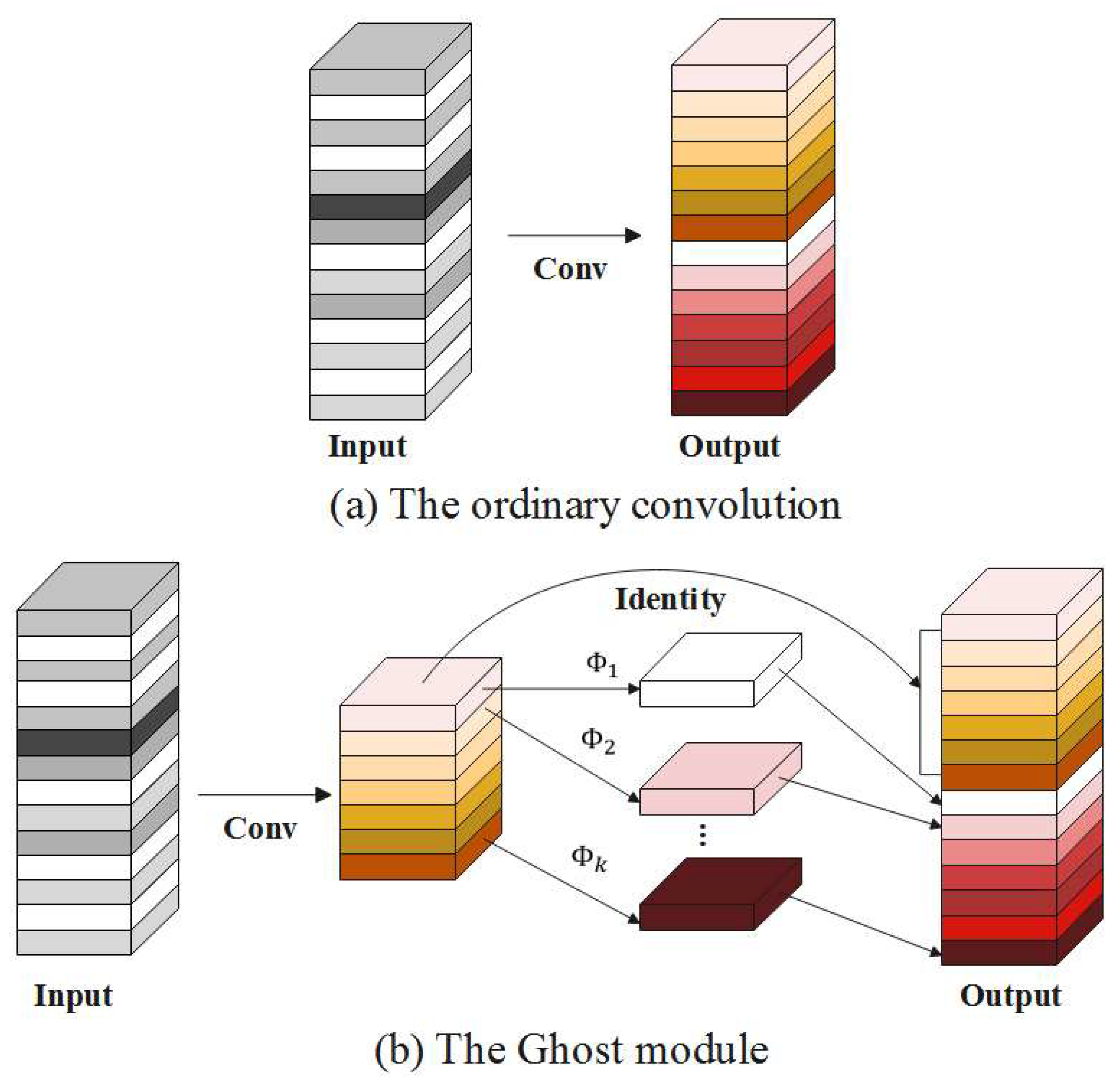
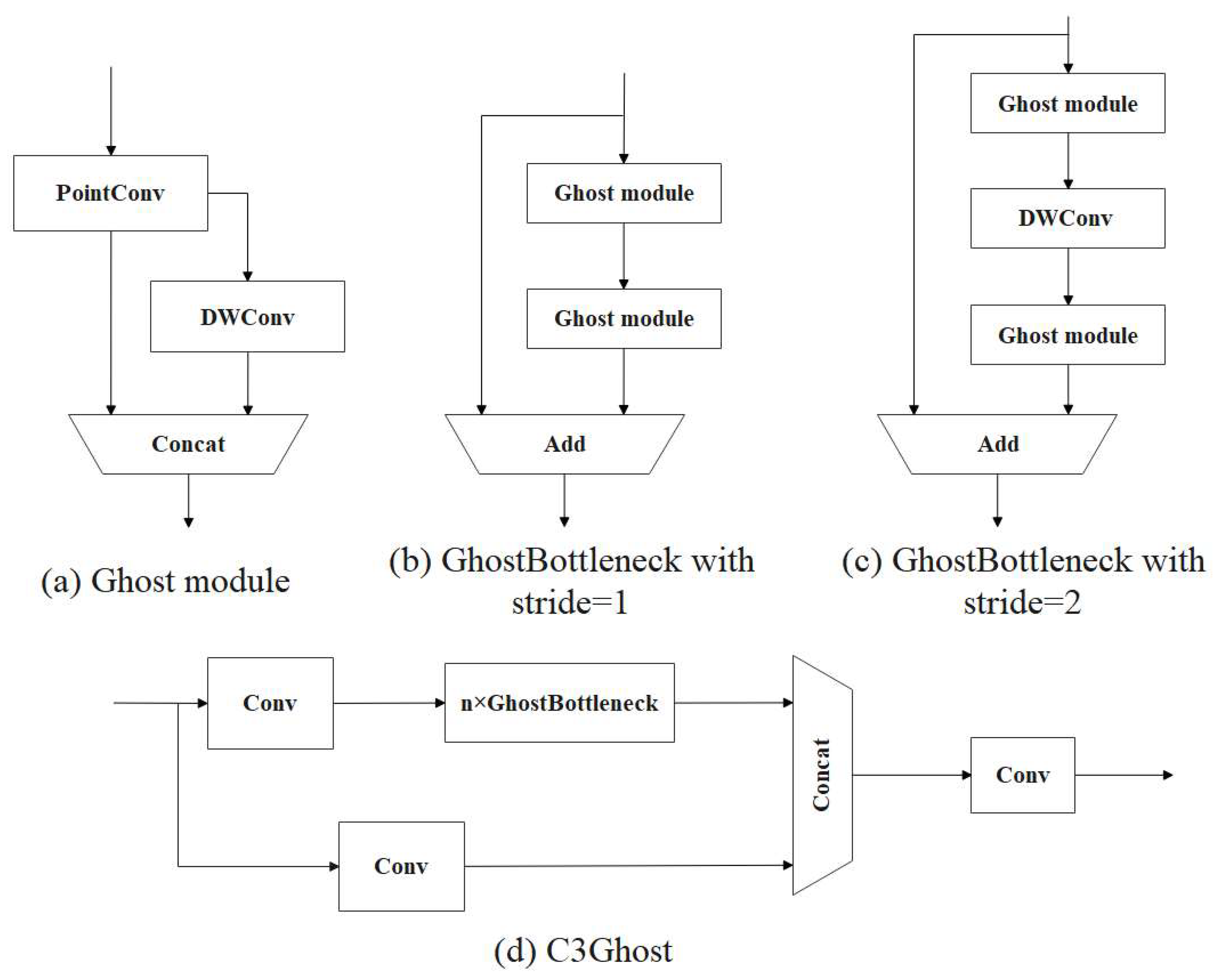
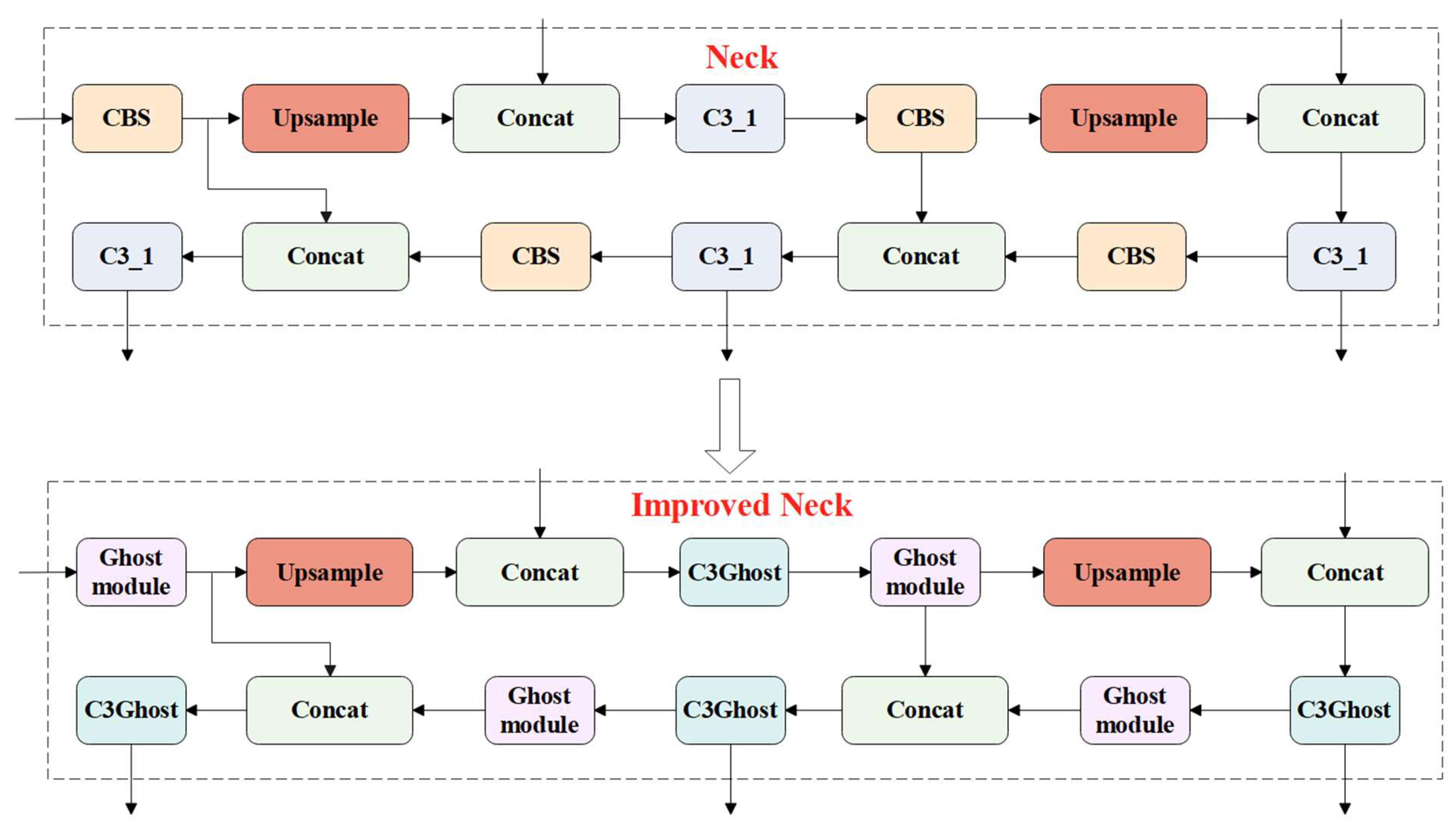
2.2.3. Optimization of the Neck Network
3. Results
3.1. Hyperparameters of Training
3.2. Performance Evaluation
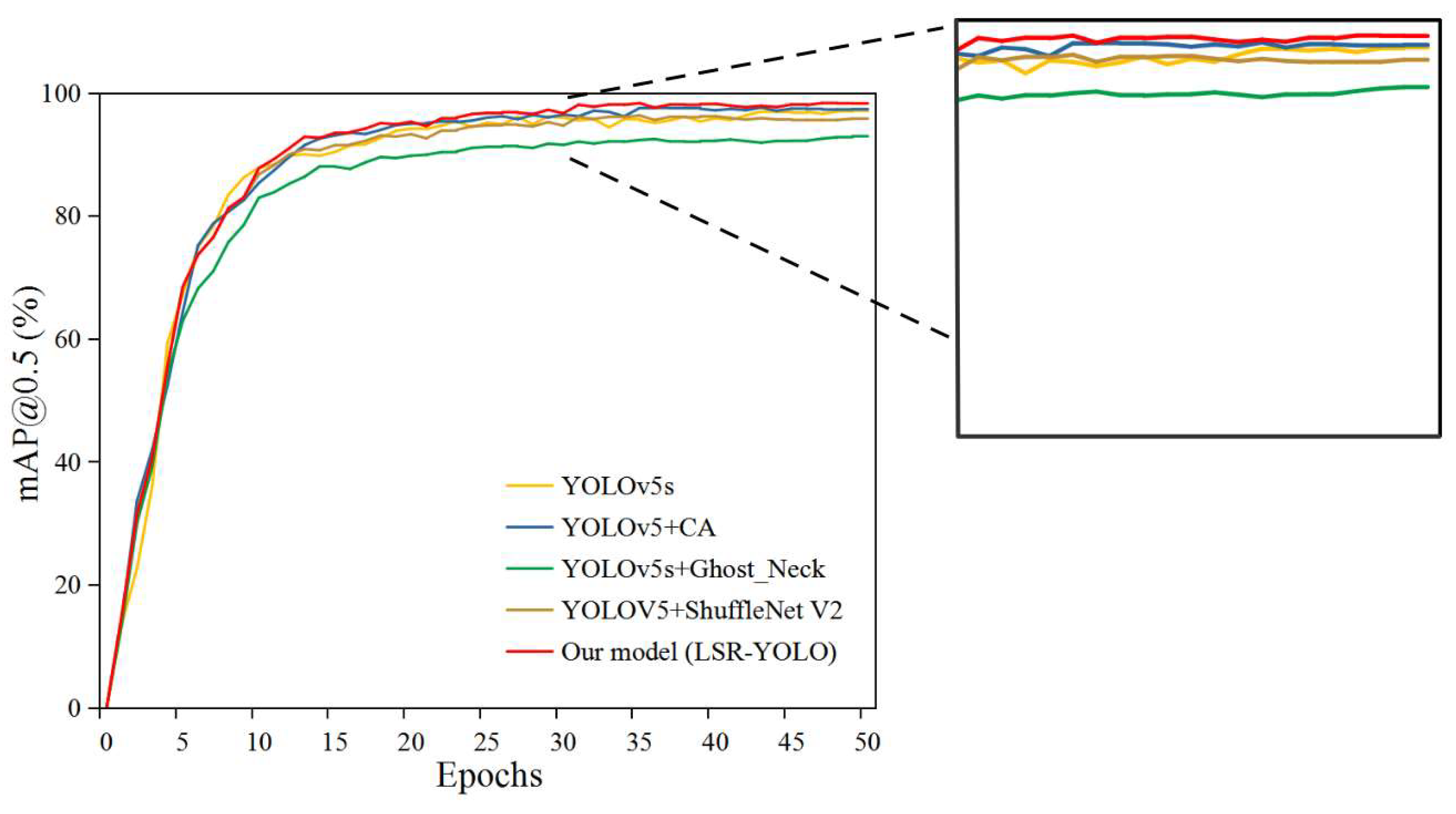
3.3. Training Evaluation
3.4. Comparison with Different Detection Models
3.5. Improved Module Performance Comparison
3.6. Improved Backbone Performance Comparison
3.7. Ghost Module Performance Comparison
3.8. Comparison of Different Attention Modules
3.9. Comparison with State-of-the-Art Models
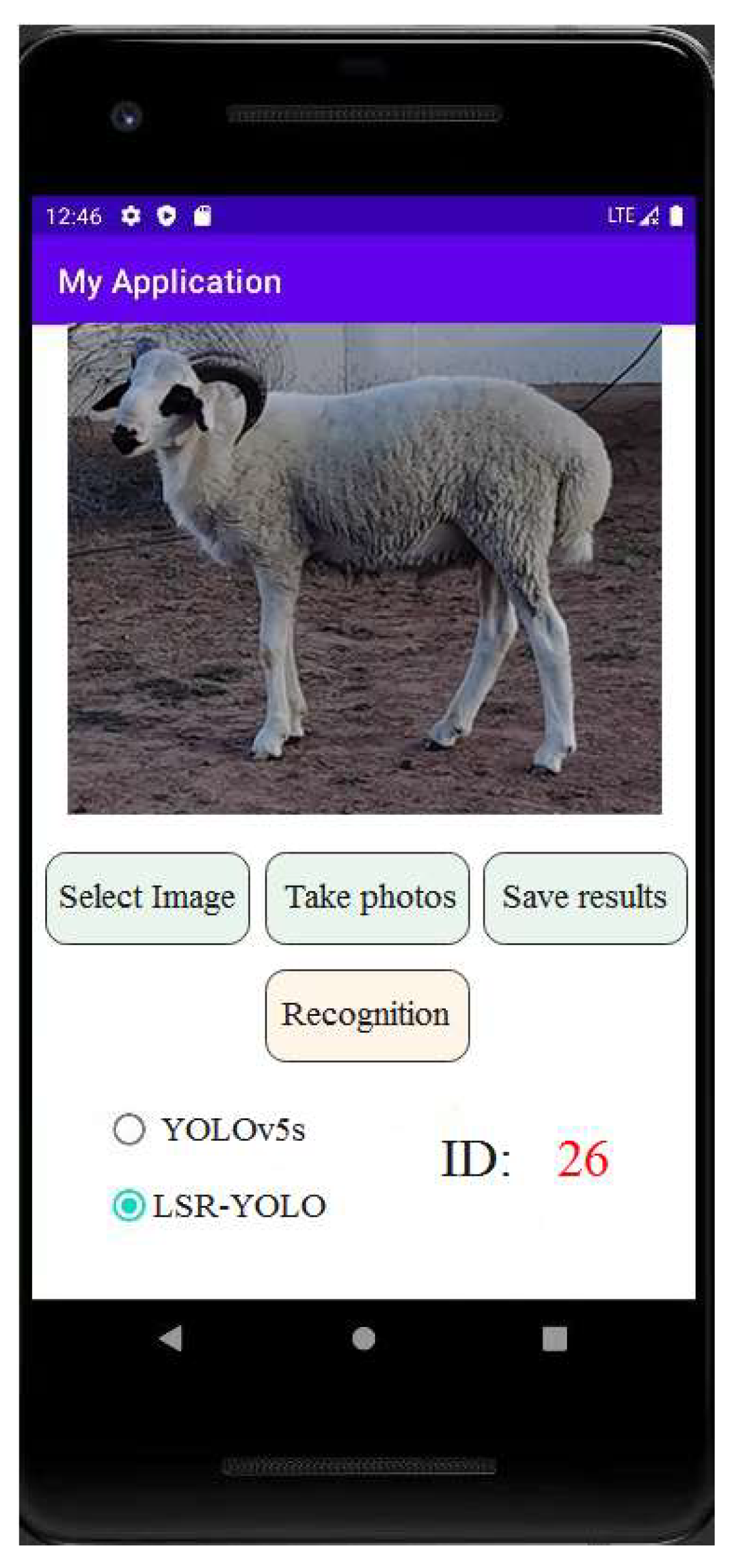
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Corkery, G.; Gonzales-Barron, U.; Butler, F.; Mcdonnell, K.; Ward, S. A preliminary investigation on face recognition as a biometric identifier of sheep. Trans. ASABE 2007, 50, 313–320. [Google Scholar] [CrossRef]
- Andrew, W.; Gao, J.; Mullan, S.; Campbell, N.; Dowsey, A.W.; Burghardt, T. Visual identification of individual Holstein-Friesian cattle via deep metric learning. Comput. Electron. Agric. 2021, 185, 106133. [Google Scholar] [CrossRef]
- Voulodimos, A.S.; Patrikakis, C.X.; Sideridis, A.B.; Ntafis, V.A.; Xylouri, E.M. A complete farm management system based on animal identification using RFID technology. Comput. Electron. Agric. 2010, 70, 380–388. [Google Scholar] [CrossRef]
- Zhang, X.; Xuan, C.; Ma, Y.; Su, H.; Zhang, M. Biometric facial identification using attention module optimized YOLOv4 for sheep. Comput. Electron. Agric. 2022, 203, 107452. [Google Scholar] [CrossRef]
- Li, X.; Xiang, L.; Li, S. Combining convolutional and vision transformer structures for sheep face recognition. Comput. Electron. Agric. 2023, 205, 107651. [Google Scholar] [CrossRef]
- Xu, B.; Wang, W.; Guo, L.; Chen, G.; Li, Y.; Cao, Z.; Wu, S. CattleFaceNet: A cattle face identification approach based on RetinaFace and ArcFace loss. Comput. Electron. Agric. 2022, 193, 106675. [Google Scholar] [CrossRef]
- Li, X.; Du, J.; Yang, J.; Li, S. When Mobilenetv2 Meets Transformer: A Balanced Sheep Face Recognition Model. Agriculture 2022, 12, 1126. [Google Scholar] [CrossRef]
- Alam, N.; Zhao, Y.; Koubâa, A.; Wu, L.; Khan, R.; Abdalla, F. Automated sheep facial expression classification using deep transfer learning. Comput. Electron. Agric. 2020, 175, 105528. [Google Scholar]
- Chen, R.; Little, R.; Mihaylova, L.; Delahay, R.; Cox, R. Wildlife surveillance using deep learning methods. Ecol. Evol. 2019, 9, 9453–9466. [Google Scholar] [CrossRef]
- Gonzales Barron, U.; Corkery, G.; Barry, B.; Butler, F.; McDonnell, K.; Ward, S. Assessment of retinal recognition technology as a biometric method for sheep identification. Comput. Electron. Agric. 2008, 60, 156–166. [Google Scholar] [CrossRef]
- Hansena, M.F.; Smitha, M.L.; Smitha, L.N.; Salterb, M.G.; Baxterc, E.M.; Farishc, M.; Grieve, B. Towards on-farm pig face recognition using convolutional neural networks. Comput. Ind. 2018, 98, 145–152. [Google Scholar] [CrossRef]
- Zhang, X.; Kang, X.; Feng, N.; Liu, G. Automatic recognition of dairy cow mastitis from thermal images by a deep learning detector. Comput. Electron. Agric. 2020, 178, 105754. [Google Scholar] [CrossRef]
- Wang, K.; Wu, P.; Cui, H.; Xuan, C.; Su, H. Identification and classification for sheep foraging behavior based on acoustic signal and deep learning. Comput. Electron. Agric. 2021, 187, 106275. [Google Scholar] [CrossRef]
- Yağ, İ.; Altan, A. Artificial Intelligence-Based Robust Hybrid Algorithm Design and Implementation for Real-Time Detection of Plant Diseases in Agricultural Environments. Biology 2022, 11, 1732. [Google Scholar] [CrossRef]
- Song, S.; Liu, T.; Wang, H.; Hasi, B.; Yuan, C.; Gao, F.; Shi, H. Using Pruning-Based YOLOv3 Deep Learning Algorithm for Accurate Detection of Sheep Face. Animals 2022, 12, 1465. [Google Scholar] [CrossRef]
- Billah, M.; Wang, X.; Yu, J.; Jiang, Y. Real-time goat face recognition using convolutional neural network. Comput. Electron. Agric. 2022, 194, 106730. [Google Scholar] [CrossRef]
- Hitelman, A.; Edan, Y.; Godo, A.; Berenstein, R.; Lepar, J.; Halachmi, I. Biometric identification of sheep via a machine-vision system. Comput. Electron. Agric. 2022, 194, 106713. [Google Scholar] [CrossRef]
- Wang, D.; He, D. Channel pruned YOLO V5s-based deep learning approach for rapid and accurate apple fruitlet detection before fruit thinning. Biosyst. Eng. 2021, 210, 271–281. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, X.; Yan, J.; Qiu, X.; Yao, X.; Tian, Y.; Zhu, Y.; Cao, W. A Wheat Spike Detection Method in UAV Images Based on Improved YOLOv5. Remote Sens. 2021, 13, 3095. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, Q.; Jiang, P.; Zheng, Y.; Yuan, L.; Yuan, P. LDS-YOLO: A lightweight small object detection method for dead trees from shelter forest. Comput. Electron. Agric. 2022, 198, 107035. [Google Scholar] [CrossRef]
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using channel pruning-based YOLOv4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Zhang, P.; Liu, X.; Yuan, J.; Liu, C. YOLO5-spear: A robust and real-time spear tips locator by improving image augmentation and lightweight network for selective harvesting robot of white asparagus. Biosyst. Eng. 2022, 218, 43–61. [Google Scholar] [CrossRef]
- Wang, K.; Wu, P.; Xuan, C.; Zhang, Y.; Bu, K.; Ma, Y. Identification of grass growth conditions based on sheep grazing acoustic signals. Comput. Electron. Agric. 2021, 190, 106463. [Google Scholar] [CrossRef]
- Jubayer, F.; Soeb, J.A.; Mojumder, A.N.; Paul, M.K.; Barua, P.; Kayshar, S.; Akter, S.S.; Rahman, M.; Islam, A. Detection of mold on the food surface using YOLOv5. Curr. Res. Food Sci. 2021, 4, 724–728. [Google Scholar] [CrossRef] [PubMed]
- Guo, Z.; Wang, C.; Yang, G.; Huang, Z.; Li, G. Msf-yolo: Improved yolov5 based on transformer for detecting defects of steel surface. Sensors 2022, 22, 3467. [Google Scholar] [CrossRef]
- Yu, G.; Zhou, X. An Improved YOLOv5 Crack Detection Method Combined with a Bottleneck Transformer. Mathematics 2023, 11, 2377. [Google Scholar] [CrossRef]
- Ma, X.; Liu, M.; Hou, Z.; Gao, X.; Bai, Y.; Guo, M. Numerical simulation and experimental study on the pelletized coating of small grain forage seeds. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2023, 39, 43–52. [Google Scholar] [CrossRef]
- Mao, Q.; Wang, M.; Hu, X.; Xue, X.; Zhai, J. Intelligent Identification Method of Shearer Drums Based on Improved YOLOv5s with Dark Channel-Guided Filtering Defogging. Energies 2023, 16, 4190. [Google Scholar] [CrossRef]
- Liu, P.; Wang, Q.; Zhang, H.; Mi, J.; Liu, Y. A Lightweight Object Detection Algorithm for Remote Sensing Images Based on Attention Mechanism and YOLOv5s. Remote Sens. 2023, 15, 2429. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, Y.; Zhao, Y.; Pan, Q.; Jin, K.; Xu, G.; Hu, Y. TS-YOLO: An All-Day and Lightweight Tea Canopy Shoots Detection Model. Agronomy 2023, 13, 1411. [Google Scholar] [CrossRef]
- Yu, J.; Li, S.; Zhou, S.; Wang, H. MSIA-Net: A Lightweight Infrared Target Detection Network with Efficient Information Fusion. Entropy 2023, 25, 808. [Google Scholar] [CrossRef] [PubMed]
- Ma, N.; Zhang, X.; Zheng, H.; Sun, J. ShuffleNetv2: Practical Guidelines for Efficient CNN Architecture Design. arXiv 2018, arXiv:1807.11164v1. [Google Scholar]
- Wang, W.; Guo, S.; Zhao, S.; Lu, Z.; Xing, Z.; Jing, Z.; Wei, Z.; Wang, Y. Intelligent Fault Diagnosis Method Based on VMD-Hilbert Spectrum and ShuffleNet-V2: Application to the Gears in a Mine Scraper Conveyor Gearbox. Sensors 2023, 23, 4951. [Google Scholar] [CrossRef]
- Wei, C.; Tan, Z.; Qing, Q.; Zeng, R.; Wen, G. Fast Helmet and License Plate Detection Based on Lightweight YOLOv5. Sensors 2023, 23, 4335. [Google Scholar] [CrossRef] [PubMed]
- Chang, B.R.; Tsai, H.-F.; Hsieh, C.-W. Accelerating the Response of Self-Driving Control by Using Rapid Object Detection and Steering Angle Prediction. Electronics 2023, 12, 2161. [Google Scholar] [CrossRef]
- Dong, X.; Yan, S.; Duan, C. A lightweight vehicles detection network model based on YOLOv5. Eng. Appl. Artif. Intell. 2022, 113, 104914. [Google Scholar] [CrossRef]
- Li, L.; Wang, Z.; Zhang, T. GBH-YOLOv5: Ghost Convolution with BottleneckCSP and Tiny Target Prediction Head Incorporating YOLOv5 for PV Panel Defect Detection. Electronics 2023, 12, 561. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, L.; Liu, Y. Hemerocallis citrina Baroni Maturity Detection Method Integrating Lightweight Neural Network and Dual Attention Mechanism. Electronics 2022, 11, 2743. [Google Scholar] [CrossRef]
- Alameer, A.; Kyriazakis, I.; Dalton, H.A.; Miller, A.L.; Bacardit, J. Automatic recognition of feeding and foraging behaviour in pigs using deep learning. Biosyst. Eng. 2020, 197, 91–104. [Google Scholar]
- Kamilaris, A.; Kartakoullis, A.; Prenafeta-Boldú, F.X. A review on the practice of big data analysis in agriculture. Comput. Electron. Agric. 2017, 143, 23–37. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Images | Size | Proportion |
|---|---|---|---|
| Training | 9928 | 2736 × 1824 | 80% |
| Verification | 1241 | 2736 × 1824 | 10% |
| Testing | 1241 | 2736 × 1824 | 10% |
| Total | 12,410 | 2736 × 1824 | 100% |
| Model | Precision (%) | Recall (%) | F1-Score (%) | Model Size (MB) |
|---|---|---|---|---|
| YOLOv3-tiny | 82.0 | 83.2 | 82.6 | 33.7 |
| YOLOv4-tiny | 86.0 | 87.5 | 86.7 | 22.6 |
| VGG16 | 86.2 | 82.8 | 84.5 | 527.8 |
| SSD | 91.3 | 93.0 | 92.1 | 99.5 |
| YOLOv5s | 93.4 | 95.4 | 94.4 | 14.0 |
| YOLOv5s | Ghost_Neck | ShuffleNev2 | CA | Parameters | Average Detection Time (ms per Image) | FLOPs (G) | Model Size (MB) | mAP@0.5 (%) |
|---|---|---|---|---|---|---|---|---|
| √ | 7,189,540 | 12.5 | 16.5 | 14.0 | 97.0 | |||
| √ | √ | 5,786,004 | 11.1 | 14.0 | 11.3 | 93.0 | ||
| √ | √ | 5,895,460 | 11.0 | 14.1 | 11.6 | 96.1 | ||
| √ | √ | 7,483,476 | 12.6 | 17.2 | 14.5 | 97.7 | ||
| √ | √ | √ | 4,491,924 | 9.0 | 11.6 | 9.0 | 93.9 | |
| √ | √ | √ | 6,079,940 | 11.6 | 14.7 | 11.9 | 94.8 | |
| √ | √ | √ | 6,189,396 | 10.2 | 14.8 | 12.1 | 96.8 | |
| √ | √ | √ | √ | 4,785,860 | 9.3 | 12.3 | 9.5 | 97.8 |
| Model | Parameters | FLOPs (G) | Average Detection Time (ms per Image) | Model Size (MB) | mAP@0.5 (%) |
|---|---|---|---|---|---|
| YOLOv5s | 7,189,540 | 16.5 | 12.5 | 14.0 | 97.0 |
| YOLOv5s + RepVGG | 7,365,540 | 16.9 | 12.6 | 14.3 | 96.9 |
| YOLOv5s + ShuffleNetv2 | 5,895,460 | 14.1 | 11.0 | 11.6 | 96.1 |
| Model | Parameters | FLOPs (G) | Average Detection Time (ms per Image) | Model Size (MB) | mAP@0.5 (%) |
|---|---|---|---|---|---|
| YOLOv5s | 7,189,540 | 16.5 | 12.5 | 14.0 | 97.0 |
| YOLOv5s + Ghost_all | 3,851,756 | 8.7 | 8.2 | 7.7 | 82.4 |
| YOLOv5s + Ghost_Backbone | 5,255,292 | 11.3 | 10.8 | 10.3 | 90.9 |
| YOLOv5s + Ghost_Neck | 5,786,004 | 14.0 | 11.1 | 11.3 | 93.0 |
| Group | Model | mAP@0.5 (%) | Model Size (MB) |
|---|---|---|---|
| 1 | +ECA | 97.3 | 9.4 |
| 2 | +SE | 97.2 | 9.5 |
| 3 | +CBAM | 97.6 | 9.5 |
| 4 | +CA (ours) | 97.8 | 9.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Xuan, C.; Xue, J.; Chen, B.; Ma, Y. LSR-YOLO: A High-Precision, Lightweight Model for Sheep Face Recognition on the Mobile End. Animals 2023, 13, 1824. https://doi.org/10.3390/ani13111824
Zhang X, Xuan C, Xue J, Chen B, Ma Y. LSR-YOLO: A High-Precision, Lightweight Model for Sheep Face Recognition on the Mobile End. Animals. 2023; 13(11):1824. https://doi.org/10.3390/ani13111824
Chicago/Turabian StyleZhang, Xiwen, Chuanzhong Xuan, Jing Xue, Boyuan Chen, and Yanhua Ma. 2023. "LSR-YOLO: A High-Precision, Lightweight Model for Sheep Face Recognition on the Mobile End" Animals 13, no. 11: 1824. https://doi.org/10.3390/ani13111824
APA StyleZhang, X., Xuan, C., Xue, J., Chen, B., & Ma, Y. (2023). LSR-YOLO: A High-Precision, Lightweight Model for Sheep Face Recognition on the Mobile End. Animals, 13(11), 1824. https://doi.org/10.3390/ani13111824