
A Two-Stage Method to Detect the Sex Ratio of Hemp Ducks Based on Object Detection and Classification Networks

 ,
,
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Access to Materials
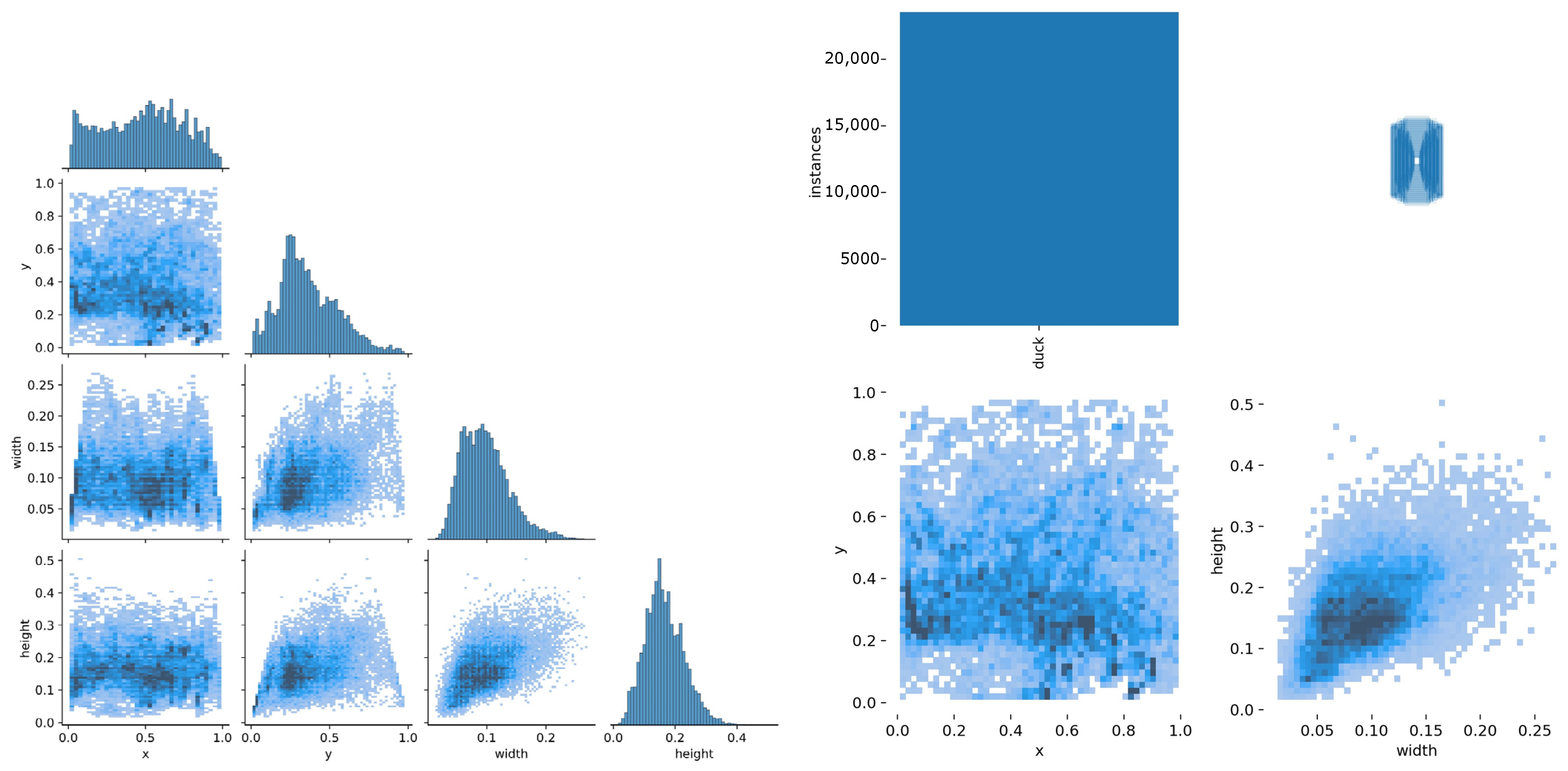
2.2. Data Pre-Processing
2.2.1. Mosaic Data Enhancement
2.2.2. Mixup
2.2.3. Other Tricks
2.3. Related Networks
2.3.1. YOLOv5
2.3.2. VovNet_27slim
2.4. Detection and Evaluation Methods
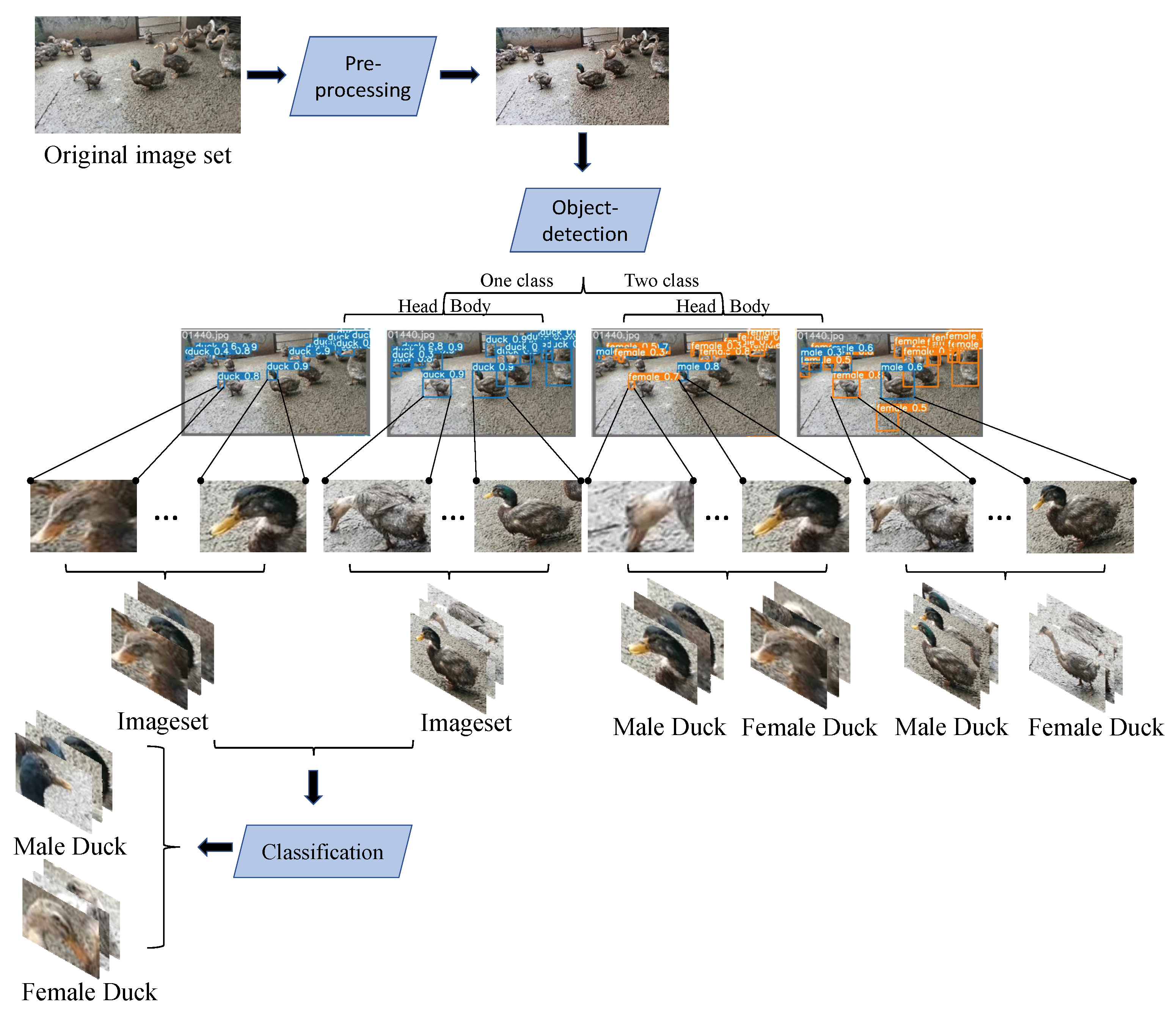
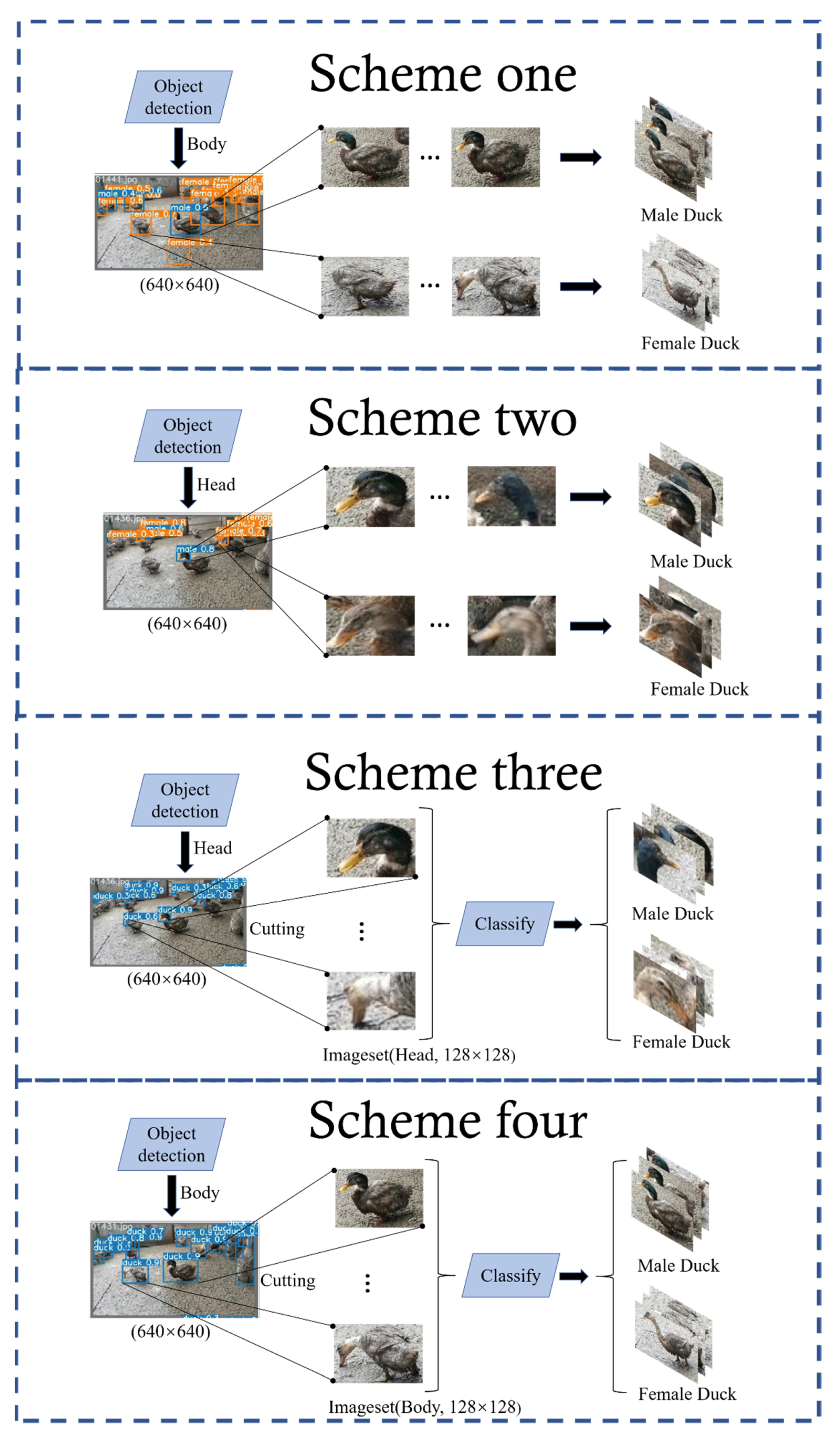
2.4.1. Detection Methods
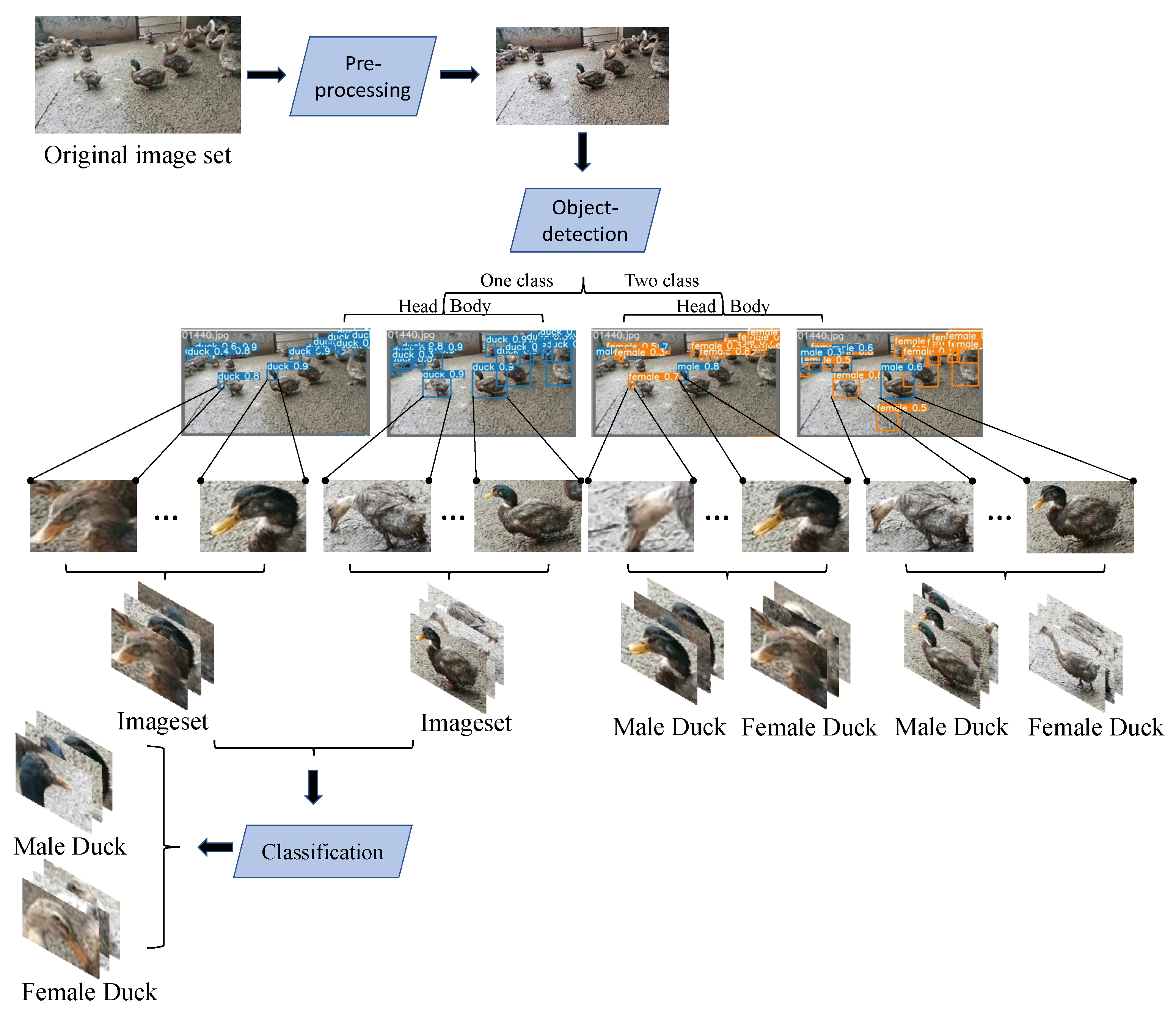
- Scheme one: Target detection for the whole ducks using Yolov5 in the target-detection phase, where the classifier is set to two categories, female and male, to directly obtain the sex ratio of the ducks;
- Scheme two: Target detection for duck heads uses Yolov5 in the target-detection phase, where the classifier is set to two categories, female and male, to directly obtain the sex ratio of the ducks;
- Scheme three: In the target-detection stage, target detection is carried out using Yolov5 for duck heads, where the classifier sets only one category of the duck, and then the detected head pictures of a single duck are fed into the classification network model. Finally the classification network carries out sex classification to obtain the sex ratio of the ducks;
- Scheme four: In the target-detection stage, target detection is carried out using Yolov5 for the whole ducks, where the classifier sets only one category of the duck, and then the detected body pictures of a single duck are fed into the classification network model. Finally the classification network carries out sex classification to obtain the sex ratio of the ducks.
2.4.2. Focal Loss
2.4.3. IoU, Accuracy, Precision, Recall, and F1 Score
2.4.4. Average Precision
2.5. Experimental Environment
2.6. Training Strategies
3. Results
3.1. General Description
- Through comparative experiments, the optimal scheme of the Yolov5 and VovNet_27slim combination is obtained;
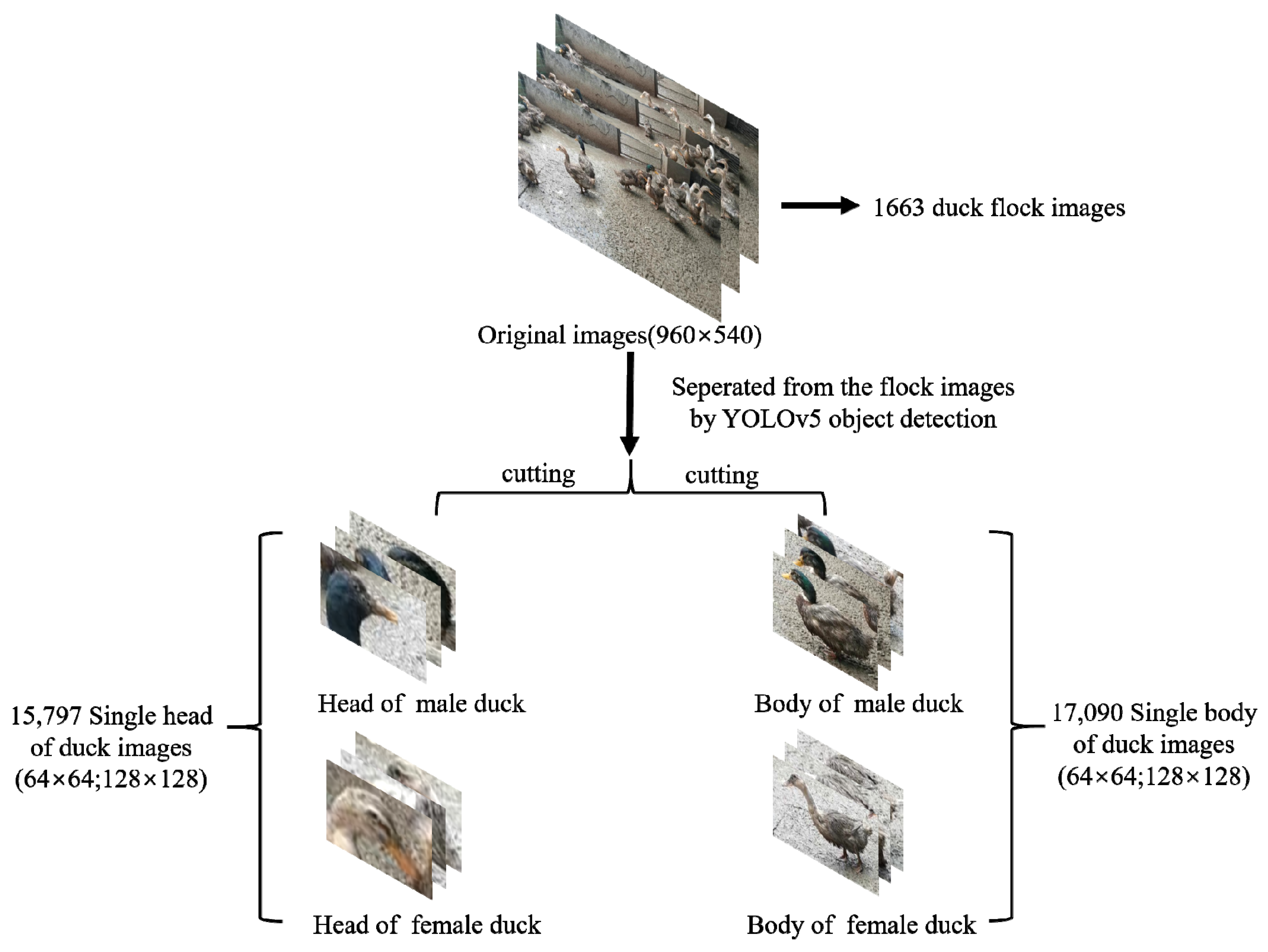
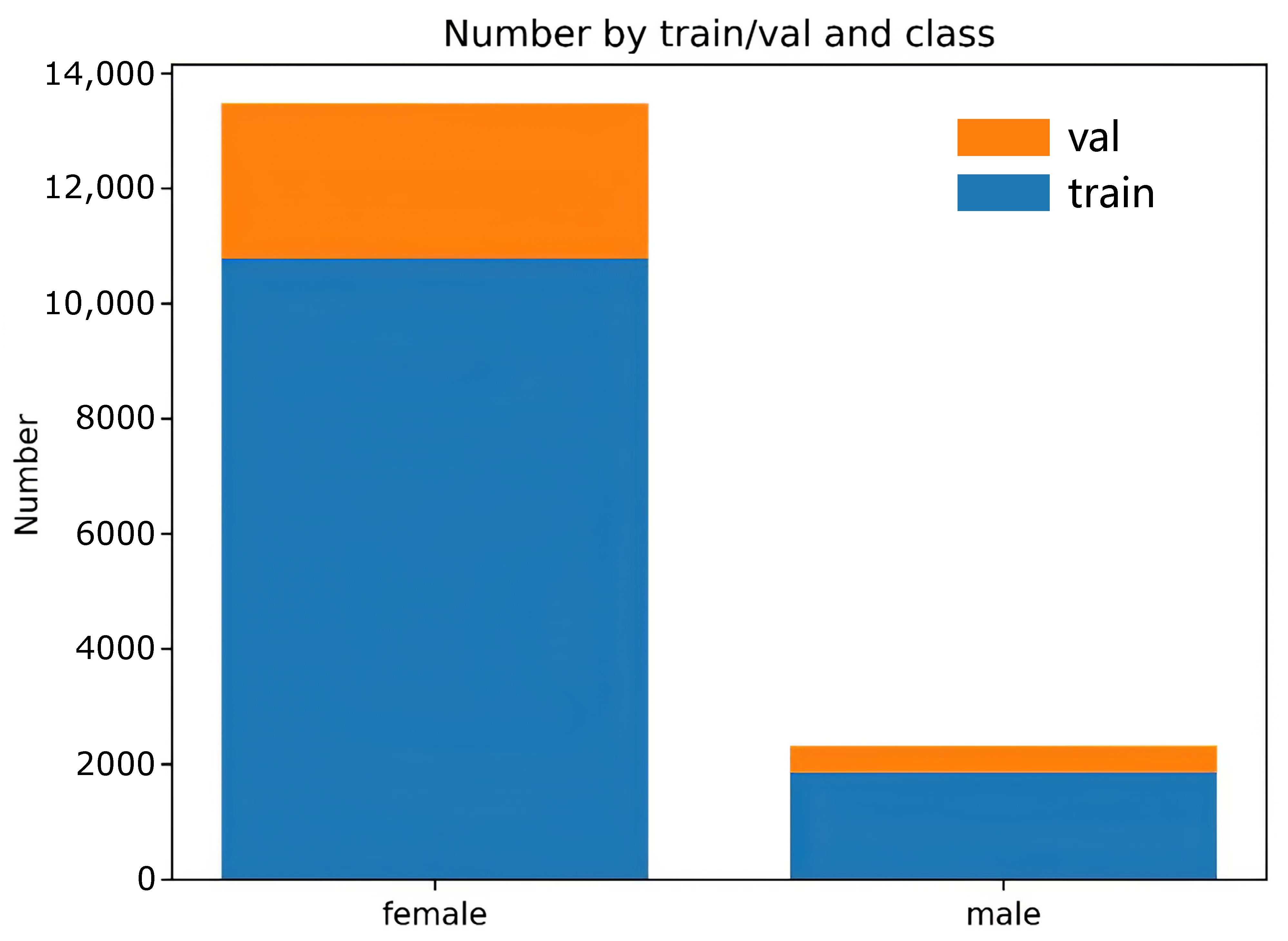
- The duck-head detection experiment of the duck group was completed by the Yolov5 detector, and by applying the results from the above experiments, a large number of images of ducks’ single heads were cropped, then a single-head dataset containing 15,797 images was generated by manual screening;
- The whole-duck detection process was completed by the Yolov5 detector, and the above experiments were used to obtain a large number of completely framed duck images; then, the whole-duck dataset containing 17,090 images was generated by manually labeling the sex of the ducks;
- The performance of the major classification networks in the sex dichotomies of ducks was compared, and the use of the VovNet_27slim network was determined;
- In the ablation experiment of the Yolov5 detection, HSV_Aug, Mosaic, and MixUp were added to improve the evaluation index, thus enhancing the effect of the model;
- The combined model of the Yolov5 and VovNet_27slim was used to estimate the sex of the duck;
- The superiority of single classification object detection and dichotomous classification network in the sex estimation of ducks was proven by comparison; also, it provides a novel solution for other classification problems based on local characteristics.
3.2. Object Detector
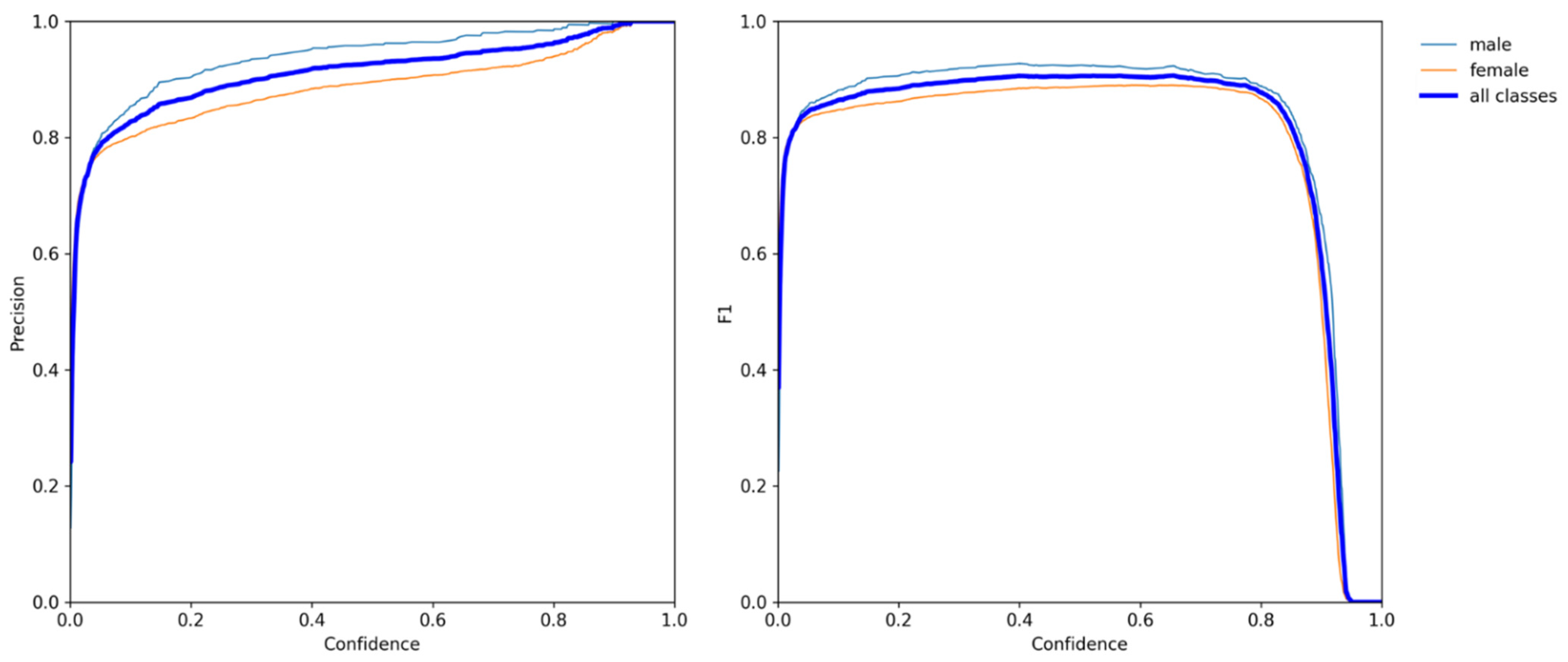
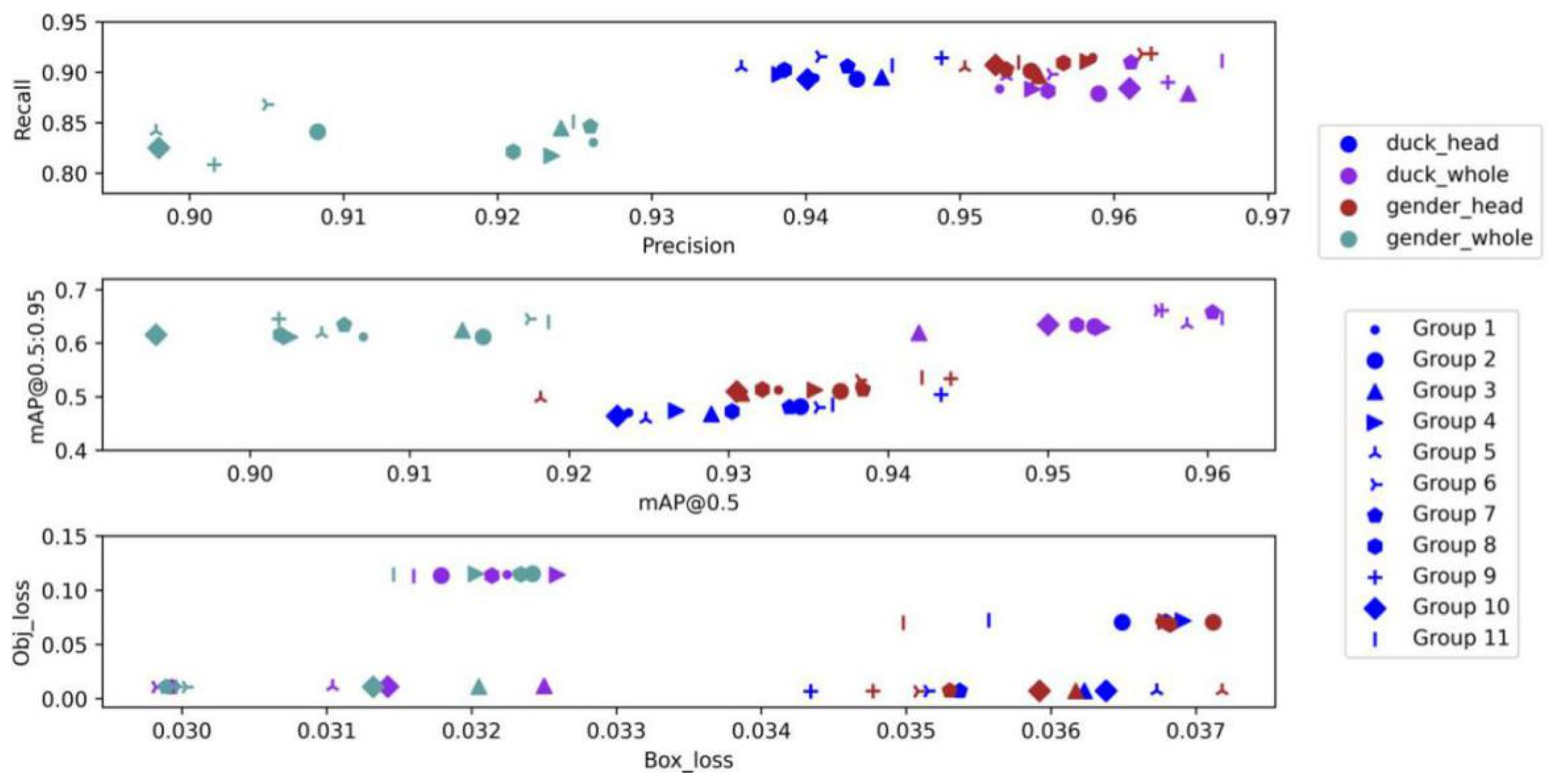
- According to the comparison between Yolov5 and other detectors in Table 1, Yolov5 is the detector with the best comprehensive ability in this experiment, with a high accuracy of 0.93 mAP and the fastest speed of verifying a picture in 8 ms;
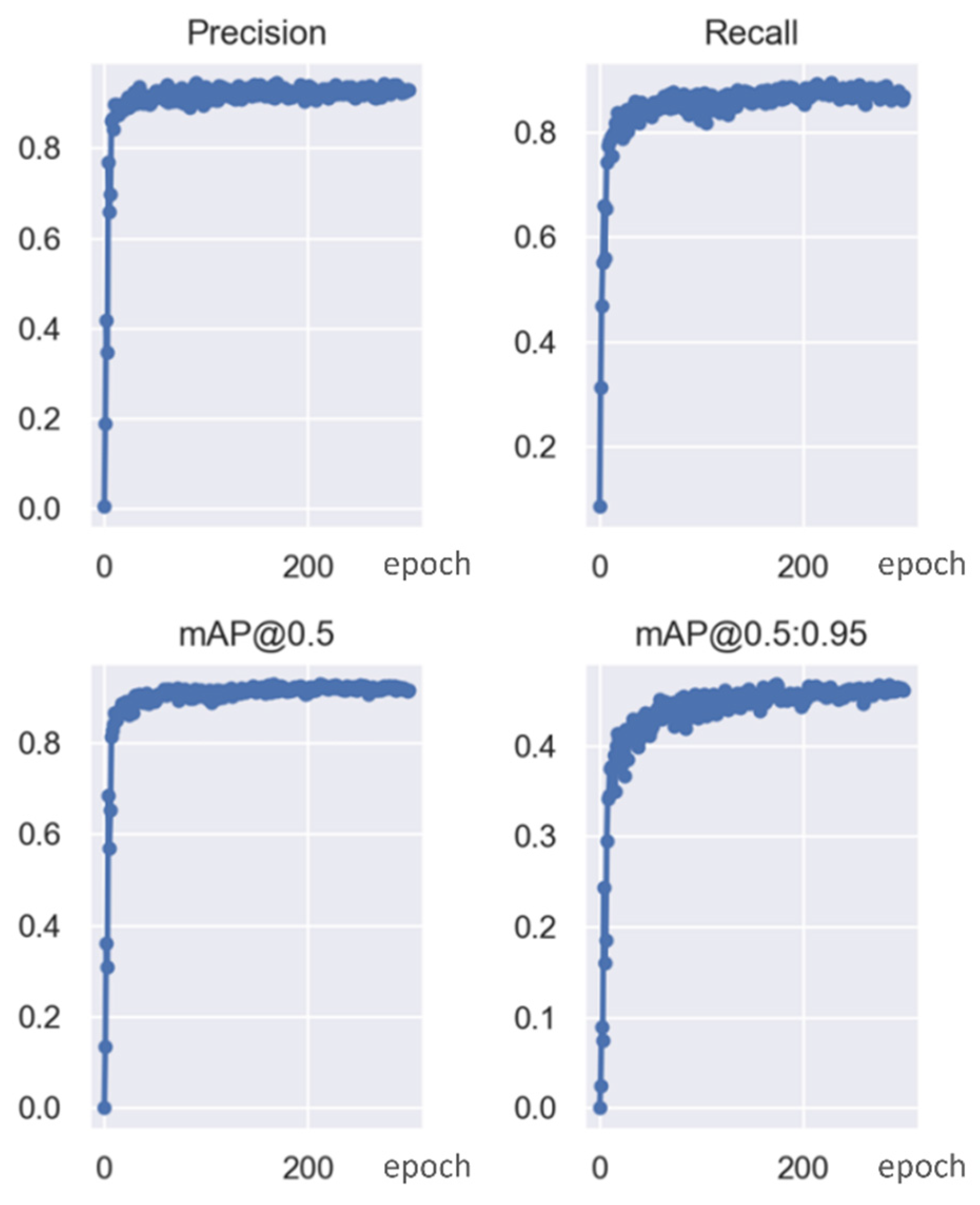
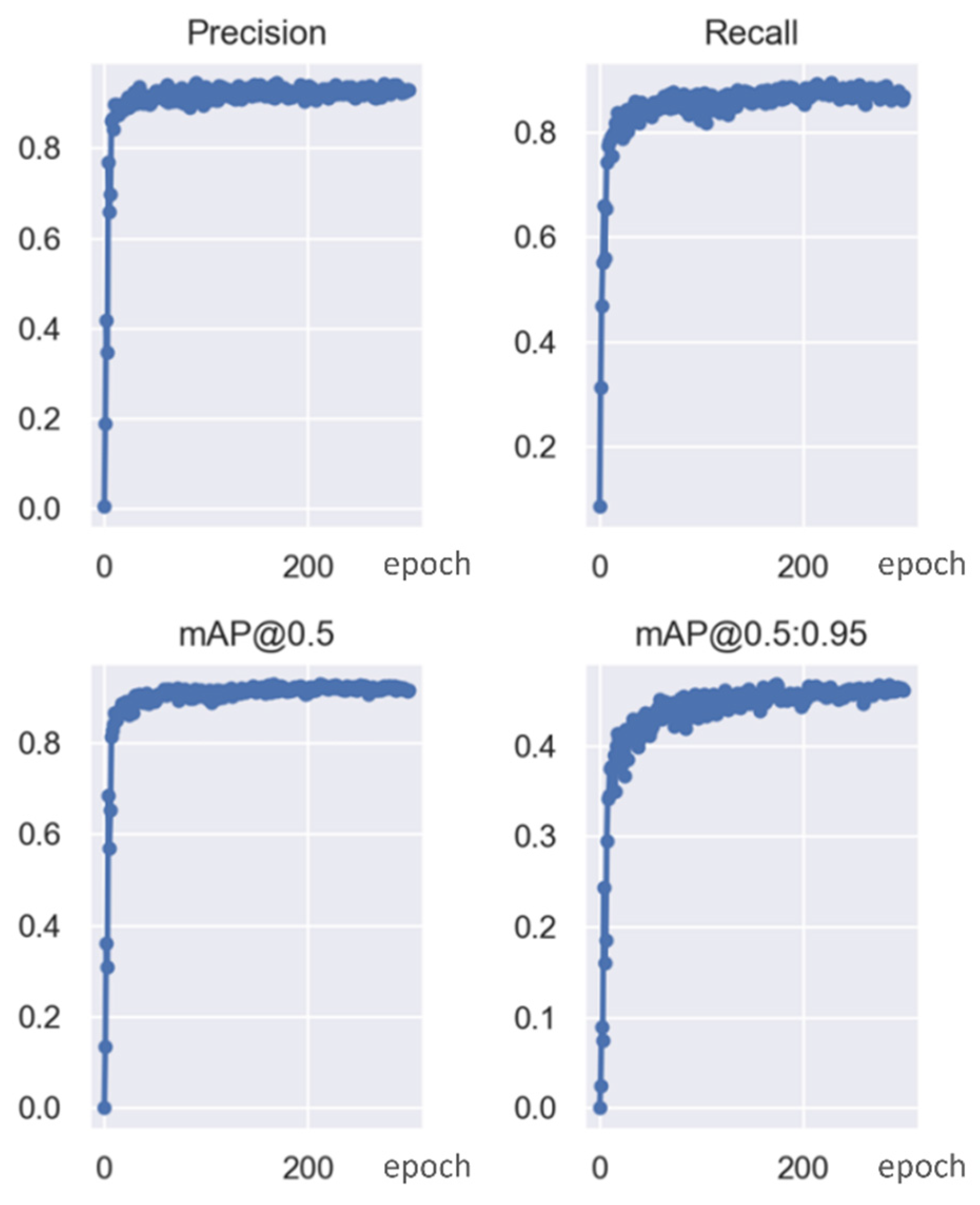
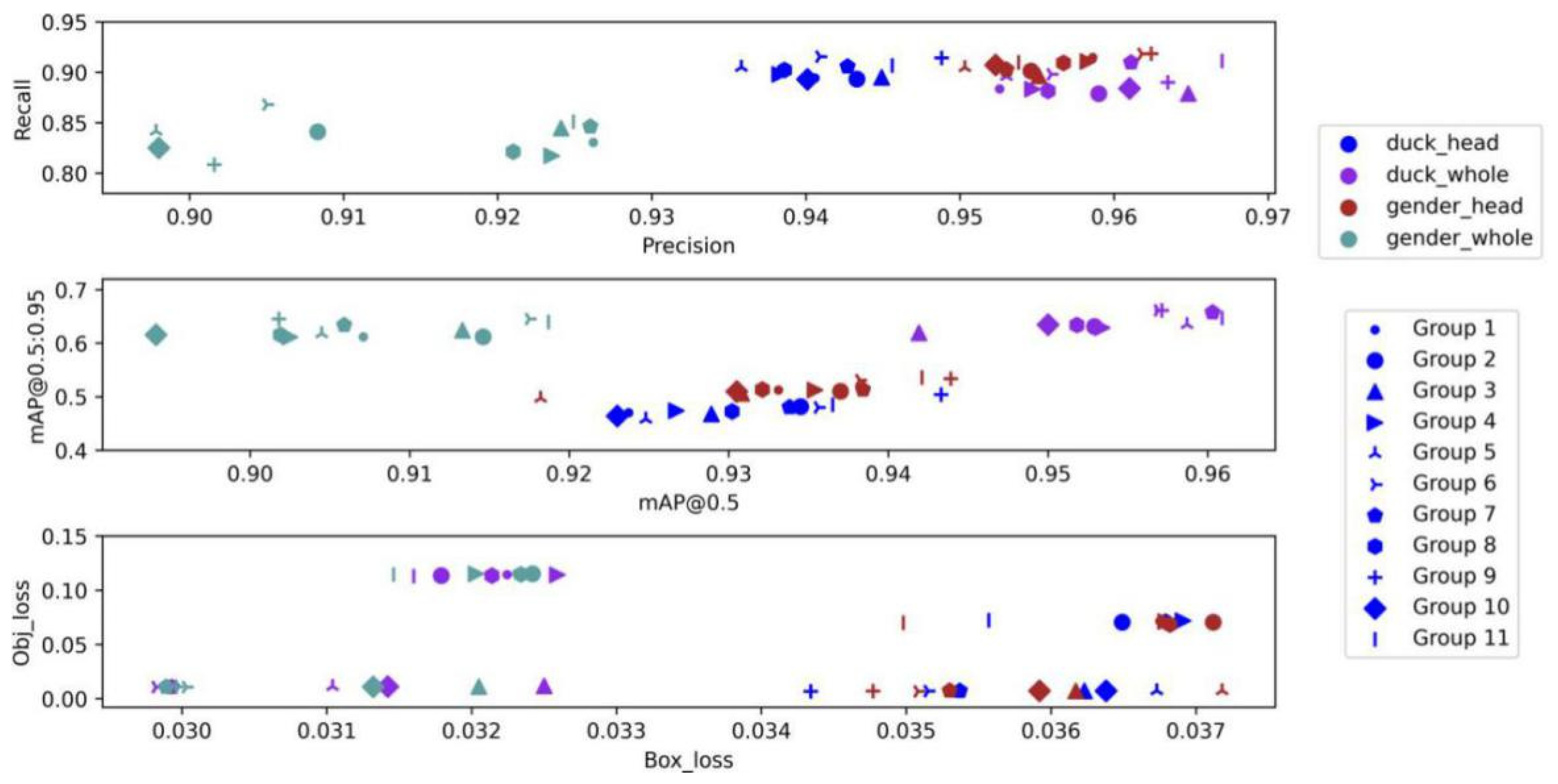
- According to the comparison of Group 1, 2, and 4 in Table 3 and Figure 12, HSV_Aug, Mosaic, and other tricks can make the precision and recall of the detector rise slightly but have no obvious influence on mAP. As can be seen from the comparison of groups 7 and 9, it is the introduction of focal loss that shows an obvious upward trend in the model effect. By reducing the weight of samples that are easy to classify, this function makes the model focus more on samples that are difficult to classify during training, thus improving the overall effect.
3.3. Scheme One
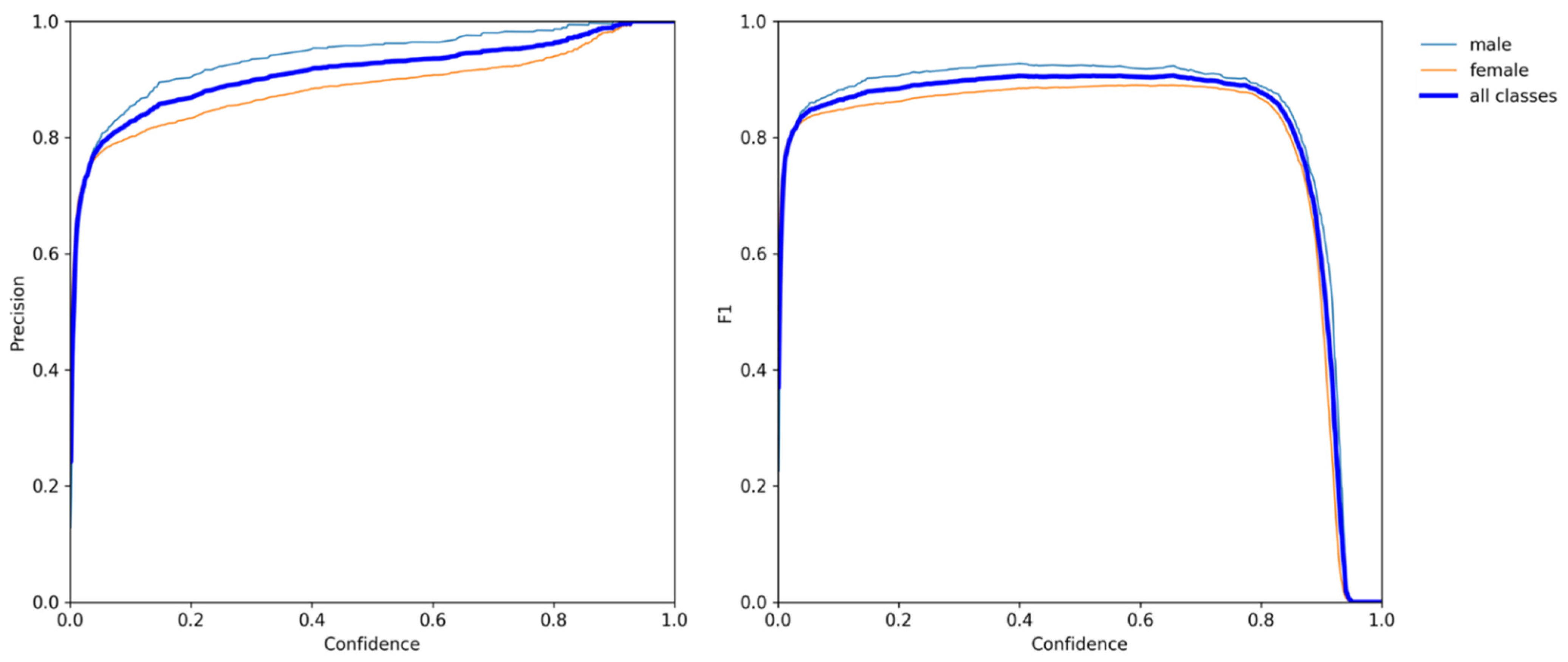
3.4. Scheme Two
3.5. Scheme Three
- With the deepening of the classification network structure of the ResNet series, the overall speed and fps tend to slow down; also, the accuracy and F1 score decrease, and the overall effect gradually declines;
- The MobileNet series, which is famous for being lightweight, has basically similar effects but has no obvious advantages compared with other models. The advantages of speed and fps are not reflected in the experiment, and the overall effect is not ideal, which also indicates that it cannot fully exploit its advantages in the small dataset;
- VovNet_27slim relies on its OSA module and optimizes its network structure to be very lightweight by performing a downsampling operation at the end of each stage. In comparison experiments, the advantages of its speed and fps were fully demonstrated. At the same time, due to its inheritance of DenseNet advantages, the reasoning ability of the model was also improved.
3.6. Scheme Four
- The density in the activity area of ducks is low, and there is no overlap of ducks;
- In the sampling area of the duck farm, there should only be ducks and not other animals, especially birds. The dataset used for training in this experiment is only for ducks. If there are other birds, the results will be interfered with, and subsequent management will not be conducive.
4. Discussion
4.1. Contribution to Sex Estimation in Poultry
4.2. The Effectiveness of the Proposed Method
4.3. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Statistical Bulletin of the People’s Republic of China on National Economic and Social Development in 2020. Available online: http://www.stats.gov.cn/xxgk/sjfb/zxfb2020/202102/t20210228_1814159.html (accessed on 1 August 2021).
- Outline of the 13th Five-Year Plan for National Economic and Social Development of the People’s Republic of China. Available online: http://www.12371.cn/special/sswgh/wen/#si (accessed on 1 August 2021).
- NICKOLOVA, M. Effect of the sex ratio on the egg fertility of Muscovy duck (Cairina moshcata). J. Cent. Eur. Agric. 2004, 5, 367–372. [Google Scholar]
- Li, Z.G. Factors affecting duck breeding performance. Rural Sci. Technol. 2014, 19, 34. [Google Scholar]
- Pöysä, H.; Linkola, P.; Paasivaara, A. Breeding sex ratios in two declining diving duck species: Between-year variation and changes over six decades. J. Ornithol. 2019, 160, 1015–1023. [Google Scholar] [CrossRef] [Green Version]
- Lu, H.; Liu, Y.; Liu, X.; Hou, R.; Huang, Y. Design and application of WSN-based poultry body temperature monitoring system. China Poult. 2018, 40, 76–79. [Google Scholar] [CrossRef]
- Vroegindeweij, B.A.; van Hell, S.; IJsselmuiden, J.M.; van Henten, E.J. Object discrimination in poultry housing using spectral reflectivity. Biosyst. Eng. 2018, 167, 99–113. [Google Scholar] [CrossRef]
- Geronimo, B.C.; Mastelini, S.M.; Carvalho, R.H.; Júnior, S.B.; Barbin, D.F.; Shimokomaki, M.; Ida, E.I. Computer vision system and near-infrared spectroscopy for identification and classification of chicken with wooden breast, and physicochemical and technological characterization. Infrared Phys. Technol. 2019, 96, 303–310. [Google Scholar] [CrossRef]
- Geffen, O.; Yitzhaky, Y.; Barchilon, N.; Druyan, S.; Halachmi, I. A machine vision system to detect and count laying hens in battery cages. Animal 2020, 14, 2628–2634. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Del Valle, J.E.; Pereira, D.F.; Neto, M.M.; Gabriel Filho, L.R.A.; Salgado, D.D.A. Unrest index for estimating thermal comfort of poultry birds (Gallus gallus domesticus) using computer vision techniques. Biosyst. Eng. 2021, 206, 123–134. [Google Scholar] [CrossRef]
- Leroy, T.; Vranken, E.; Van Brecht, A.; Struelens, E.; Sonck, B.; Berckmans, D. A computer vision method for on-line behavioral quantification of individually caged poultry. Trans. ASABE 2006, 49, 795–802. [Google Scholar] [CrossRef]
- Lubich, J.; Thomas, K.; Engels, D.W. Identification and classification of poultry eggs: A case study utilizing computer vision and machine learning. SMU Data Sci. Rev. 2019, 2, 20. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhuang, X.; Zhang, T. Detection of sick broilers by digital image processing and deep learning. Biosyst. Eng. 2019, 179, 106–116. [Google Scholar] [CrossRef]
- Fang, C.; Zhang, T.; Zheng, H.; Huang, J.; Cuan, K. Pose estimation and behavior classification of broiler chickens based on deep neural networks. Comput. Electron. Agric. 2021, 180, 105863. [Google Scholar] [CrossRef]
- Pu, H.; Lian, J.; Fan, M. Automatic recognition of flock behavior of chickens with convolutional neural network and kinect sensor. Int. J. Pattern Recognit. Artif. Intell. 2018, 32, 1850023. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Jurio, A.; Pagola, M.; Galar, M.; Lopez-Molina, C.; Paternain, D. A comparison study of different color spaces in clustering based image segmentation. In Proceedings of the 13th International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems, Dortmund, Germany, 28 June–2 July 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 532–541. [Google Scholar]
- Lee, Y.; Hwang, J.-W.; Lee, S.; Bae, Y.; Park, J. An energy and GPU-computation efficient backbone network for real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Thuan, D. Evolution of Yolo Algorithm and Yolov5: The State-of-the-Art Object Detection Algorithm. 2021. Available online: https://urn.fi/URN:NBN:fi:amk-202103042892 (accessed on 1 August 2021).
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [Green Version]
- Leevy, J.L.; Khoshgoftaar, T.M.; Bauder, R.A.; Seliya, N. A survey on addressing high-class imbalance in big data. J. Big Data 2018, 5, 42. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Everingham, M.; Winn, J. The PASCAL visual object classes challenge 2007 (VOC2007) development kit. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Lin, B.; Su, H.; Li, D.; Feng, A.; Li, H.; Li, J.; Jiang, K.; Jiang, H.; Gong, X.; Liu, T. PlaneNet: An efficient local feature extraction network. PeerJ Comput. Sci. 2021, 7, e783. [Google Scholar] [CrossRef]
- Zhi, X. Research on Bird Image Recognition Based on Deep Learning; Dalian University of Technology: Dalian, China, 2019. [Google Scholar] [CrossRef]
- Ian, J.; Jean Pouget-Abadie, G.; Mirza, M.; Xu, B.; Warde-Farley, D.; Aaron Courville, S.O.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Improving Object Detection with One Line of Code. arXiv 2017, arXiv:1704.04503. [Google Scholar]
- Neubeck, A.; Gool, L. Efficient Non-Maximum Suppression. In Proceedings of the 18th International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006; pp. 850–855. [Google Scholar]
- Song, W.; Tang, R.; Yang, K.; Liu, H. A tilted rectangular range frame labeling method and analysis of remote sensing target detection application. J. China Inst. Water Resour. Hydropower Sci. 2021, 19, 165–172. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Class | Precision | Recall | F1 Score | mAP@0.5 | Inference Time @batch_size 1 (ms) |
|---|---|---|---|---|---|---|
| CenterNet | All | 0.95 | 0.83 | 0.89 | 0.91 | 32 |
| Male | 0.96 | 0.90 | 0.93 | 0.94 | ||
| Female | 0.94 | 0.76 | 0.84 | 0.88 | ||
| Yolov4s | All | 0.80 | 0.91 | 0.85 | 0.91 | 10 |
| Male | 0.81 | 0.93 | 0.86 | 0.93 | ||
| Female | 0.90 | 0.90 | 0.90 | 0.88 | ||
| Yolov5s | All | 0.95 | 0.90 | 0.92 | 0.93 | 8 |
| Male | 0.98 | 0.90 | 0.94 | 0.95 | ||
| Female | 0.92 | 0.89 | 0.90 | 0.90 | ||
| YoloR | All | 0.82 | 0.91 | 0.88 | 0.93 | 11 |
| Male | 0.89 | 0.92 | 0.90 | 0.94 | ||
| Female | 0.76 | 0.91 | 0.85 | 0.91 |
| Model | Class | Precision | Recall | F1 Score | mAP@0.5 | Inference Time @batch_size 1 (ms) |
|---|---|---|---|---|---|---|
| CenterNet | All | 0.99 | 0.58 | 0.73 | 0.91 | 32 |
| Male | 0.98 | 0.60 | 0.75 | 0.91 | ||
| Female | 0.99 | 0.55 | 0.71 | 0.91 | ||
| Yolov4s | All | 0.70 | 0.85 | 0.77 | 0.86 | 10 |
| Male | 0.69 | 0.85 | 0.76 | 0.87 | ||
| Female | 0.72 | 0.85 | 0.78 | 0.86 | ||
| Yolov5s | All | 0.89 | 0.83 | 0.86 | 0.91 | 8 |
| Male | 0.93 | 0.80 | 0.86 | 0.92 | ||
| Female | 0.85 | 0.86 | 0.85 | 0.91 | ||
| YoloR | All | 0.76 | 0.83 | 0.80 | 0.90 | 11 |
| Male | 0.75 | 0.78 | 0.76 | 0.87 | ||
| Female | 0.78 | 0.89 | 0.83 | 0.93 |
| Group | HSV_Aug | FocalLoss | Mosaic | MixUp | Other Tricks | Precision | Recall | F1 Score | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | × | × | × | × | × | 0.93 | 0.87 | 0.90 | 0.91 | 0.45 |
| 2 | √ | × | × | × | × | 0.91 | 0.88 | 0.90 | 0.90 | 0.46 |
| 3 | √ | √ | × | × | × | 0.92 | 0.89 | 0.91 | 0.91 | 0.44 |
| 4 | √ | √ | √ | × | × | 0.93 | 0.90 | 0.91 | 0.92 | 0.45 |
| 5 | √ | √ | √ | √ | × | 0.92 | 0.89 | 0.90 | 0.91 | 0.46 |
| 6 | √ | × | × | √ | × | 0.92 | 0.89 | 0.91 | 0.92 | 0.46 |
| 7 | √ | √ | √ | × | Fliplrud | 0.92 | 0.91 | 0.91 | 0.93 | 0.47 |
| 8 | √ | √ | × | × | Fliplrud | 0.92 | 0.88 | 0.90 | 0.91 | 0.45 |
| 9 | √ | × | √ | √ | Fliplrud | 0.92 | 0.89 | 0.91 | 0.91 | 0.47 |
| 10 | √ | × | × | × | Fliplrud RandomScale (0.5~1.5) | 0.93 | 0.88 | 0.91 | 0.92 | 0.47 |
| 11 | √ | √ | √ | √ | Fliplrud RandomScale (0.5~1.5) | 0.93 | 0.87 | 0.90 | 0.92 | 0.46 |
| Model | Accuracy | Precision | Recall | F1 Score | Time (ms) | fps |
|---|---|---|---|---|---|---|
| ResNet_18 | 98.75 | 96.92 | 98.20 | 97.55 | 9 | 297.23 |
| ResNet_34 | 98.98 | 97.89 | 98.05 | 97.97 | 9 | 167.63 |
| ResNet_50 | 98.21 | 95.53 | 97.54 | 96.50 | 10 | 127.01 |
| ResNext_50-32×4d | 98.65 | 96.65 | 98.06 | 97.34 | 12 | 96.10 |
| RegNetx_200mf | 98.15 | 96.07 | 96.60 | 96.33 | 9 | 127.51 |
| RegNety_200mf | 98.42 | 97.01 | 96.69 | 96.84 | 10 | 96.12 |
| MobileNetv2_1.0 | 98.83 | 97.51 | 97.83 | 97.67 | 9 | 153.09 |
| MobileNetv3_small | 98.83 | 97.23 | 98.15 | 97.69 | 8 | 173.50 |
| MobileNetv3_large | 98.88 | 97.39 | 98.18 | 97.78 | 9 | 142.21 |
| GhostNet_1.0 | 98.51 | 96.51 | 97.63 | 97.06 | 9 | 79.50 |
| ShuffleNetv2_1.0 | 98.24 | 95.39 | 97.88 | 96.58 | 9 | 130.96 |
| DenseNet_121 | 99.00 | 97.32 | 98.79 | 98.04 | 11 | 55.88 |
| VovNet_27slim | 98.89 | 97.05 | 98.62 | 97.81 | 9 | 273.27 |
| se-ResNet_18 | 99.02 | 97.92 | 98.18 | 98.05 | 9 | 232.09 |
| se-ResNet_34 | 99.06 | 97.70 | 98.612 | 98.15 | 9 | 125.24 |
| se-ResNet_50 | 98.43 | 96.51 | 97.30 | 96.90 | 11 | 95.80 |
| Input Size | Accuracy | Precision | Recall | F1 Score | Time (ms) | fps |
|---|---|---|---|---|---|---|
| 64 × 64 | 98.89 | 97.05 | 98.62 | 97.81 | 9 | 273.27 |
| 128 × 128 | 99.29 | 98.16 | 99.05 | 98.60 | 19 | 269.68 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, X.; Li, F.; Lin, B.; Xie, D.; Liu, Y.; Jiang, K.; Gong, X.; Jiang, H.; Peng, R.; Duan, X. A Two-Stage Method to Detect the Sex Ratio of Hemp Ducks Based on Object Detection and Classification Networks. Animals 2022, 12, 1177. https://doi.org/10.3390/ani12091177
Zheng X, Li F, Lin B, Xie D, Liu Y, Jiang K, Gong X, Jiang H, Peng R, Duan X. A Two-Stage Method to Detect the Sex Ratio of Hemp Ducks Based on Object Detection and Classification Networks. Animals. 2022; 12(9):1177. https://doi.org/10.3390/ani12091177
Chicago/Turabian StyleZheng, Xingze, Feiyi Li, Bin Lin, Donghang Xie, Yang Liu, Kailin Jiang, Xinyao Gong, Hongbo Jiang, Ran Peng, and Xuliang Duan. 2022. "A Two-Stage Method to Detect the Sex Ratio of Hemp Ducks Based on Object Detection and Classification Networks" Animals 12, no. 9: 1177. https://doi.org/10.3390/ani12091177
APA StyleZheng, X., Li, F., Lin, B., Xie, D., Liu, Y., Jiang, K., Gong, X., Jiang, H., Peng, R., & Duan, X. (2022). A Two-Stage Method to Detect the Sex Ratio of Hemp Ducks Based on Object Detection and Classification Networks. Animals, 12(9), 1177. https://doi.org/10.3390/ani12091177