
Validation of the Prediction Accuracy for 13 Traits in Chinese Simmental Beef Cattle Using a Preselected Low-Density SNP Panel

 ,
,
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Ethics Statement
2.2. Animals and Phenotypic Data
2.3. Genotyping and Population Structure
2.4. Genetic Parameter Estimation
2.5. Preselection of Low-Density SNP Panel
2.6. Genomic Prediction
2.7. Assessment of the Low-Density SNP Panel
3. Results
3.1. Statistics and Population Structure
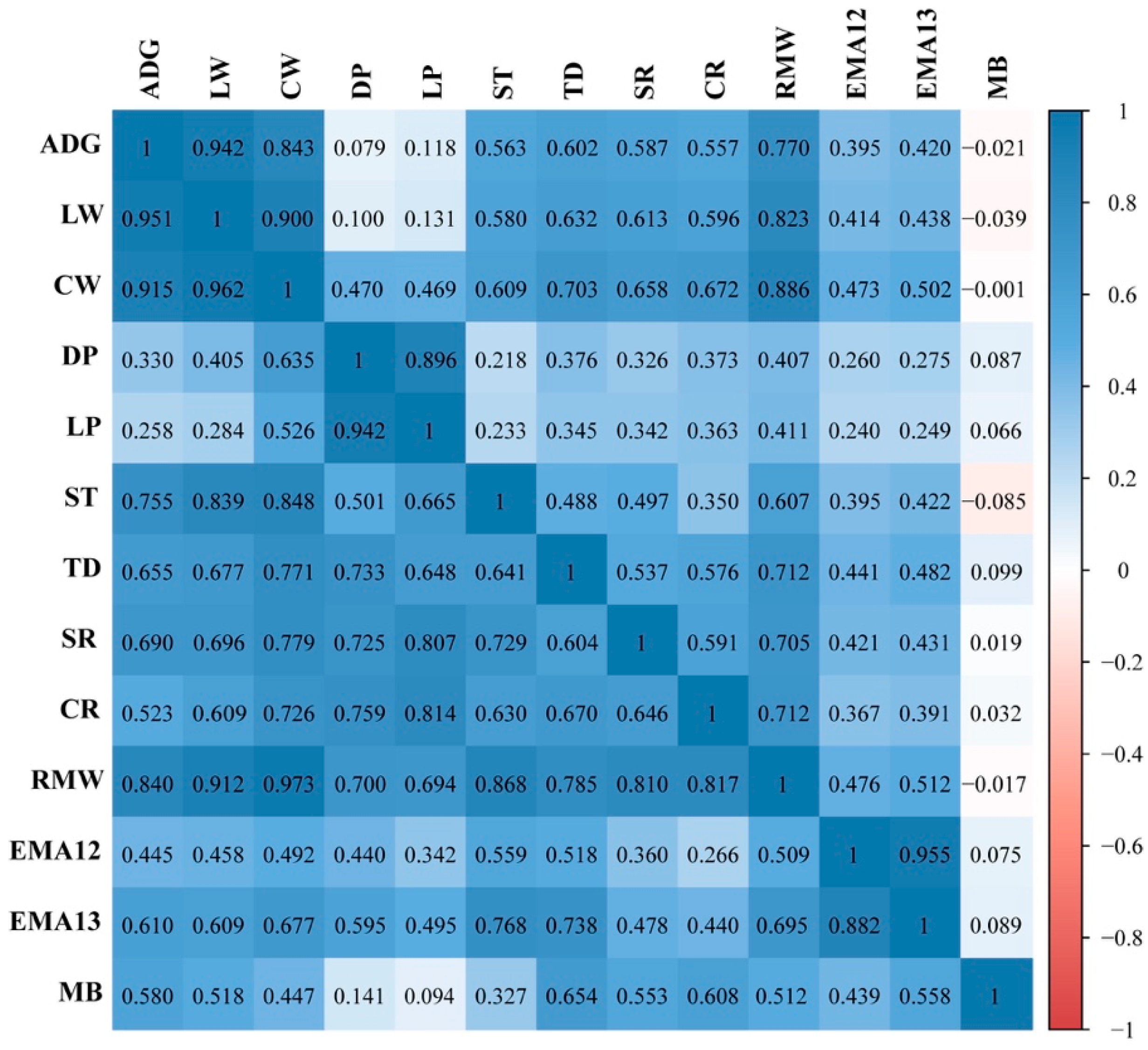
3.2. Estimation of Genetic Parameters
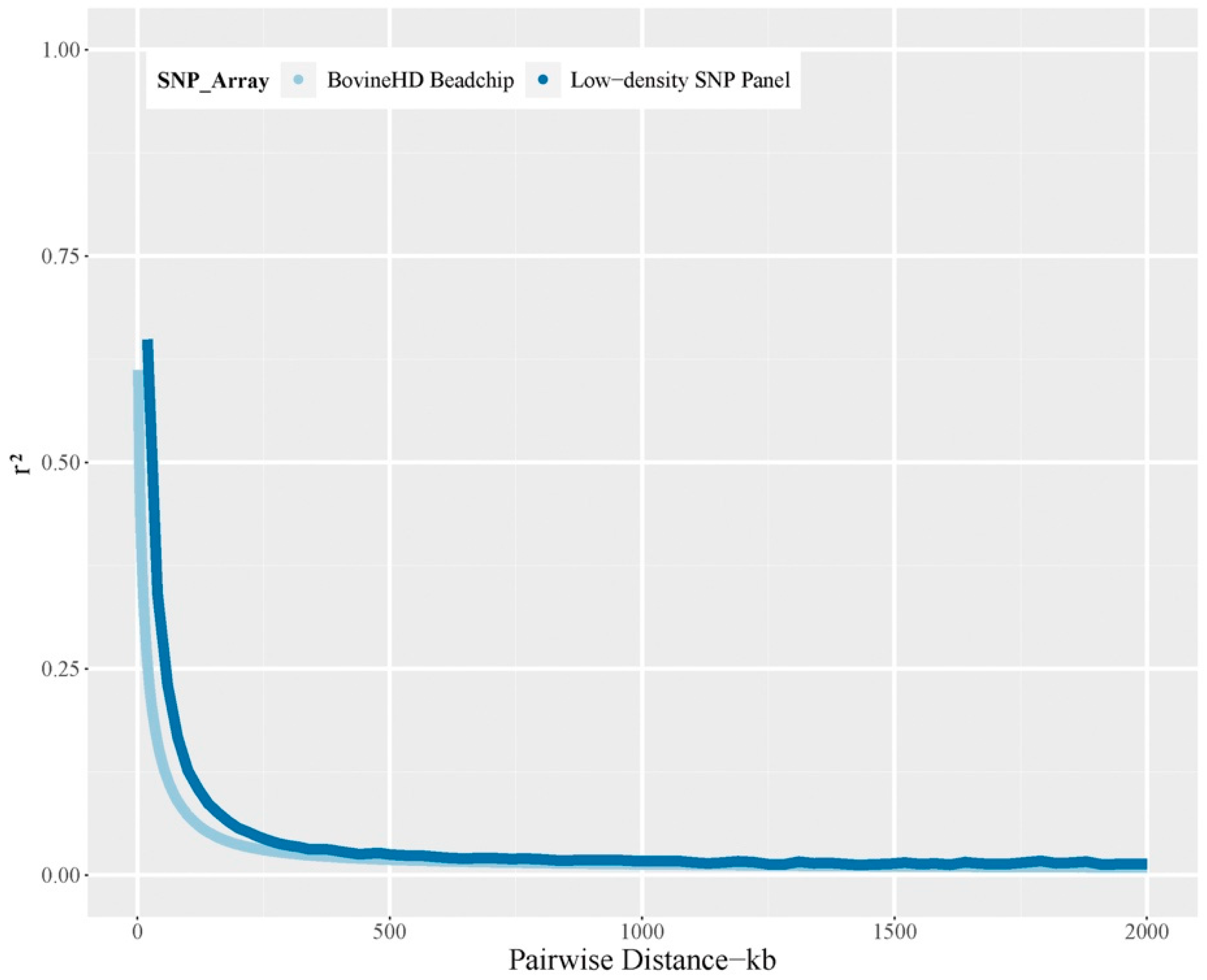
3.3. Features of the Low-Density SNP Panel
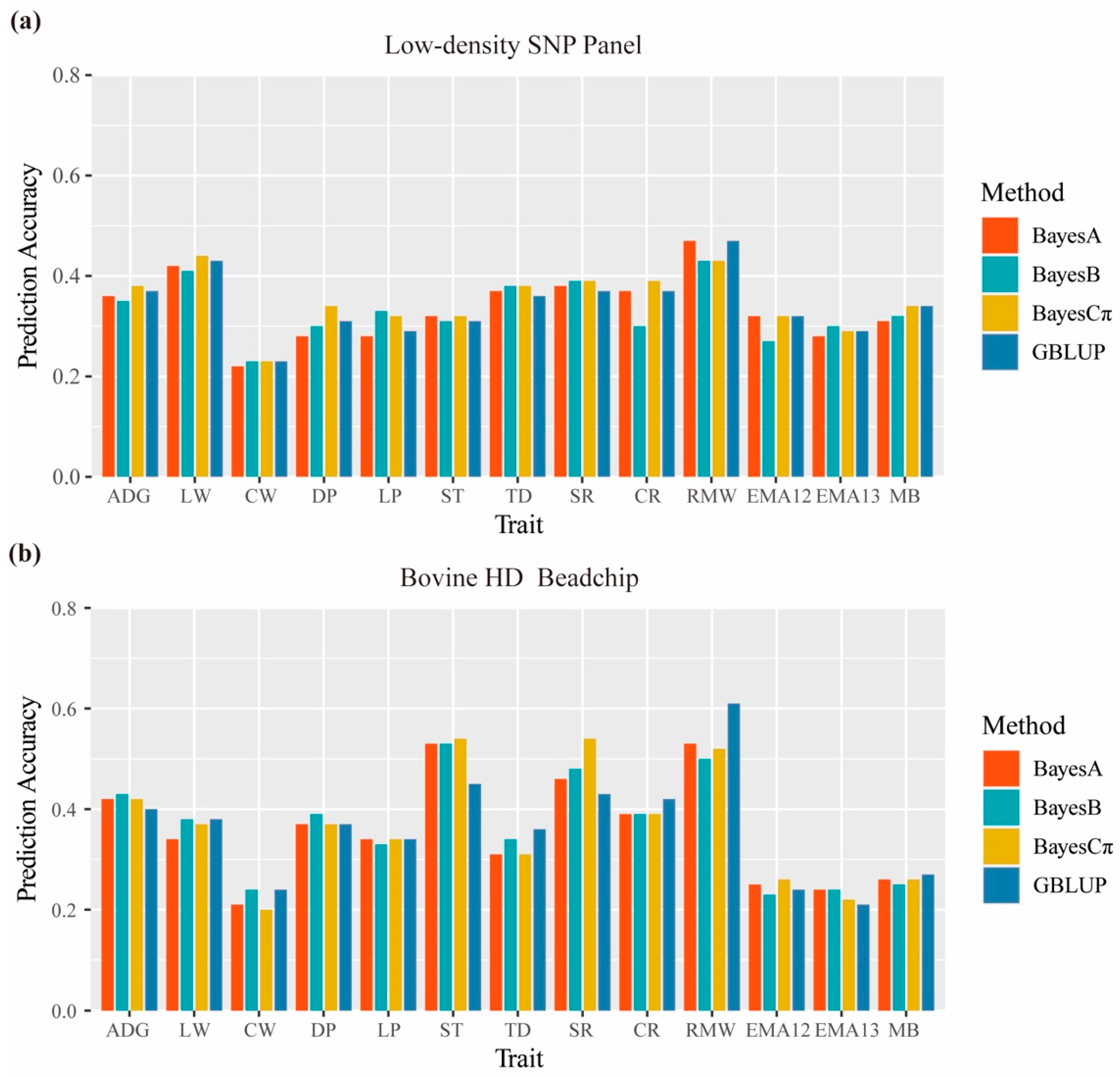
3.4. Prediction Accuracy of Low-Density SNP Panel
3.5. Regression Coefficients of the Low-Density SNP Panel Using Different Methods
3.6. Prediction Performance of Different Methods
4. Discussion
4.1. The Selection Strategies of the Low-Density SNP Panel
4.2. Estimation of Genetic Parameters
4.3. The Prediction Accuracy of the Low-Density SNP Panel
4.4. The Prediction Accuracy of Four Prediction Methods
4.5. Application of the Low-Density SNP Panel
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Campos, G.D.L.; Hickey, J.M.; Pong-Wong, R.; Daetwyler, H.D.; Calus, M.P.L. Whole-Genome Regression and Prediction Methods Applied to Plant and Animal Breeding. Genetics 2013, 193, 327–345. [Google Scholar] [CrossRef] [Green Version]
- Hayes, B.J.; Cogan, N.O.I.; Pembleton, L.W.; Goddard, M.E.; Wang, J.; Spangenberg, G.C.; Forster, J.W. Prospects for genomic selection in forage plant species. Plant Breed. 2013, 132, 133–143. [Google Scholar] [CrossRef]
- Riedelsheimer, C.; Czedik-Eysenberg, A.; Grieder, C.; Lisec, J.; Technow, F.; Sulpice, R.; Altmann, T.; Stitt, M.; Willmitzer, L.; E Melchinger, A. Genomic and metabolic prediction of complex heterotic traits in hybrid maize. Nat. Genet. 2012, 44, 217–220. [Google Scholar] [CrossRef] [PubMed]
- Hayes, B.J.; Pryce, J.; Chamberlain, A.J.; Bowman, P.J.; Goddard, M.E. Genetic Architecture of Complex Traits and Accuracy of Genomic Prediction: Coat Colour, Milk-Fat Percentage, and Type in Holstein Cattle as Contrasting Model Traits. PLoS Genet. 2010, 6, e1001139. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Erbe, M.; Hayes, B.; Matukumalli, L.; Goswami, S.; Bowman, P.; Reich, C.; Mason, B.; Goddard, M. Improving accuracy of genomic predictions within and between dairy cattle breeds with imputed high-density single nucleotide polymorphism panels. J. Dairy Sci. 2012, 95, 4114–4129. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bolormaa, S.; Pryce, J.E.; Kemper, K.; Savin, K.; Hayes, B.J.; Barendse, W.; Zhang, Y.; Reich, C.M.; Mason, B.A.; Bunch, R.J.; et al. Accuracy of prediction of genomic breeding values for residual feed intake and carcass and meat quality traits in Bos taurus, Bos indicus, and composite beef cattle1. J. Anim. Sci. 2013, 91, 3088–3104. [Google Scholar] [CrossRef] [Green Version]
- A Clark, S.; Hickey, J.M.; Van Der Werf, J.H. Different models of genetic variation and their effect on genomic evaluation. Genet. Sel. Evol. 2011, 43, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Meuwissen, T.H.; Hayes, B.J.; Goddard, M.E. Prediction of total genetic value using genome-wide dense marker maps. Genetics 2001, 157, 1819–1829. [Google Scholar] [CrossRef]
- VanRaden, P.M.; Tooker, M.E.; O’Connell, J.R.; Cole, J.B.; Bickhart, D.M. Selecting sequence variants to improve genomic predictions for dairy cattle. Genet. Sel. Evol. 2017, 49, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Calus, M.P.L.; Bouwman, A.C.; Schrooten, C.; Veerkamp, R.F. Efficient genomic prediction based on whole-genome sequence data using split-and-merge Bayesian variable selection. Genet. Sel. Evol. 2016, 48, 1–19. [Google Scholar] [CrossRef]
- Van Binsbergen, R.; Calus, M.P.; Bink, M.C.; van Eeuwijk, F.A.; Schrooten, C.; Veerkamp, R.F. Genomic prediction using imputed whole-genome sequence data in Holstein Friesian cattle. Genet. Sel. Evol. 2015, 47, 71. [Google Scholar] [CrossRef] [Green Version]
- Frischknecht, M.; Meuwissen, T.H.; Bapst, B.; Seefried, F.R.; Flury, C.; Garrick, D.; Signer-Hasler, H.; Stricker, C.; Bieber, A.; Fries, R.; et al. Short communication: Genomic prediction using imputed whole-genome sequence variants in Brown Swiss Cattle. J. Dairy Sci. 2018, 101, 1292–1296. [Google Scholar] [CrossRef] [PubMed]
- Ertl, J.; Edel, C.; Emmerling, R.; Pausch, H.; Fries, R.; Götz, K.-U. On the limited increase in validation reliability using high-density genotypes in genomic best linear unbiased prediction: Observations from Fleckvieh cattle. J. Dairy Sci. 2014, 97, 487–496. [Google Scholar] [CrossRef] [Green Version]
- Su, G.; Brøndum, R.; Ma, P.; Guldbrandtsen, B.; Aamand, G.P.; Lund, M. Comparison of genomic predictions using medium-density (∼54,000) and high-density (∼777,000) single nucleotide polymorphism marker panels in Nordic Holstein and Red Dairy Cattle populations. J. Dairy Sci. 2012, 95, 4657–4665. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Calus, M.P.L.; E Meuwissen, T.H.; de Roos, A.P.W.; Veerkamp, R.F. Accuracy of Genomic Selection Using Different Methods to Define Haplotypes. Genetics 2008, 178, 553–561. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Meuwissen, T.H. Accuracy of breeding values of ’unrelated’ individuals predicted by dense SNP genotyping. Genet. Sel. Evol. 2009, 41, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Akanno, E.C.; Chen, L.; Abo-Ismail, M.K.; Crowley, J.J.; Wang, Z.; Li, C.; Basarab, J.A.; MacNeil, M.D.; Plastow, G. Genomic prediction of breed composition and heterosis effects in Angus, Charolais, and Hereford crosses using 50K genotypes. Can. J. Anim. Sci. 2017, 97, 431–438. [Google Scholar] [CrossRef] [Green Version]
- Berg, I.V.D.; MacLeod, I.; Reich, C.; Breen, E.; Pryce, J. Optimizing genomic prediction for Australian Red dairy cattle. J. Dairy Sci. 2020, 103, 6276–6298. [Google Scholar] [CrossRef]
- Vazquez, A.I.; Rosa, G.J.M.; Weigel, K.A.; Campos, G.D.L.; Gianola, D.; Allison, D.B. Predictive ability of subsets of single nucleotide polymorphisms with and without parent average in US Holsteins. J. Dairy Sci. 2010, 93, 5942–5949. [Google Scholar] [CrossRef] [Green Version]
- Boichard, D.; Chung, H.; Dassonneville, R.; David, X.; Eggen, A.; Fritz, S.; Gietzen, K.J.; Hayes, B.J.; Lawley, C.T.; Sonstegard, T.S.; et al. Design of a bovine low-density SNP array optimized for imputation. PLoS ONE 2012, 7, e34130. [Google Scholar] [CrossRef] [Green Version]
- Abo-Ismail, M.K.; Lansink, N.; Akanno, E.; Karisa, B.K.; Crowley, J.J.; Moore, S.S.; Bork, E.; Stothard, P.; A Basarab, J.; Plastow, G.S. Development and validation of a small SNP panel for feed efficiency in beef cattle1. J. Anim. Sci. 2018, 96, 375–397. [Google Scholar] [CrossRef] [Green Version]
- Sollero, B.P.; Junqueira, V.S.; Gomes, C.C.G.; Caetano, A.R.; Cardoso, F.F. Tag SNP selection for prediction of tick resistance in Brazilian Braford and Hereford cattle breeds using Bayesian methods. Genet. Sel. Evol. 2017, 49, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Kemp, R.A.; Stothard, P.; Wang, Z.; Boddicker, N.; Krivushin, K.; Dekkers, J.; Plastow, G. Genomic evaluation of feed efficiency component traits in Duroc pigs using 80K, 650K and whole-genome sequence variants. Genet. Sel. Evol. 2018, 50, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Bolormaa, S.; Gore, K.; Van Der Werf, J.H.J.; Hayes, B.J.; Daetwyler, H.D. Design of a low-density SNP chip for the main Australian sheep breeds and its effect on imputation and genomic prediction accuracy. Anim. Genet. 2015, 46, 544–556. [Google Scholar] [CrossRef]
- Herry, F.; Hérault, F.; Druet, D.P.; Varenne, A.; Burlot, T.; Le Roy, P.; Allais, S. Design of low density SNP chips for genotype imputation in layer chicken. BMC Genet. 2018, 19, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, B.; Guo, P.; Wang, Z.; Zhang, W.; Chen, Y.; Zhang, L.; Gao, H.; Gao, X.; Xu, L.; Li, J. Accuracies of genomic prediction for twenty economically important traits in Chinese Simmental beef cattle. Anim. Genet. 2019, 50, 634–643. [Google Scholar] [CrossRef] [Green Version]
- Zhu, B.; Zhu, M.; Jiang, J.; Niu, H.; Wang, Y.; Wu, Y.; Xu, L.; Chen, Y.; Zhang, L.; Gao, X.; et al. The Impact of Variable Degrees of Freedom and Scale Parameters in Bayesian Methods for Genomic Prediction in Chinese Simmental Beef Cattle. PLoS ONE 2016, 11, e0154118. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, B.; Niu, H.; Zhang, W.; Wang, Z.; Liang, Y.; Guan, L.; Guo, P.; Chen, Y.; Zhang, L.; Guo, Y.; et al. Genome wide association study and genomic prediction for fatty acid composition in Chinese Simmental beef cattle using high density SNP array. BMC Genom. 2017, 18, 1–15. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Purcell, S.; Neale, B.; Todd-Brown, K.; Thomas, L.; Ferreira, M.A.; Bender, D.; Maller, J.; Sklar, P.; De Bakker, P.I.; Daly, M.J.; et al. PLINK: A Tool Set for Whole-Genome Association and Population-Based Linkage Analyses. Am. J. Hum. Genet. 2007, 81, 559–575. [Google Scholar] [CrossRef] [Green Version]
- Chang, C.C.; Chow, C.C.; Tellier, L.C.A.M.; Vattikuti, S.; Purcell, S.M.; Lee, J.J. Second-generation PLINK: Rising to the challenge of larger and richer datasets. GigaScience 2015, 4, 1–16. [Google Scholar] [CrossRef]
- Browning, B.L.; Browning, S.R. Genotype Imputation with Millions of Reference Samples. Am. J. Hum. Genet. 2016, 98, 116–126. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gilmour, A.R.; Gogel, B.J.; Cullis, B.R.; Welham, S.; Thompson, R. ASReml User Guide Release 4.1 Structural Specification; VSN International Ltd.: Hemel Hempstead, UK, 2015. [Google Scholar]
- Aulchenko, Y.S.; Ripke, S.; Isaacs, A.; Van Duijn, C.M. GenABEL: An R library for genome-wide association analysis. Bioinformatics 2007, 23, 1294–1296. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Edwards, S.M.; Sørensen, I.F.; Sarup, P.; Mackay, T.F.; Sørensen, P. Genomic Prediction for Quantitative Traits Is Improved by Mapping Variants to Gene Ontology Categories in Drosophila melanogaster. Genetics 2016, 203, 1871–1883. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Do, D.N.; Janss, L.L.G.; Jensen, J.; Kadarmideen, H.N. SNP annotation-based whole genomic prediction and selection: An application to feed efficiency and its component traits in pigs1. J. Anim. Sci. 2015, 93, 2056–2063. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Quinlan, A.R.; Hall, I.M. BEDTools: A flexible suite of utilities for comparing genomic features. Bioinformatics 2010, 26, 841–842. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- VanRaden, P.M. Efficient Methods to Compute Genomic Predictions. J. Dairy Sci. 2008, 91, 4414–4423. [Google Scholar] [CrossRef] [Green Version]
- Habier, D.; Fernando, R.L.; Kizilkaya, K.; Garrick, D.J. Extension of the bayesian alphabet for genomic selection. BMC Bioinform. 2011, 12, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Morgante, F.; Huang, W.; Maltecca, C.; Mackay, T.F.C. Effect of genetic architecture on the prediction accuracy of quantitative traits in samples of unrelated individuals. Heredity 2018, 120, 500–514. [Google Scholar] [CrossRef]
- Gao, N.; Martini, J.W.R.; Zhang, Z.; Yuan, X.; Zhang, H.; Simianer, H.; Li, J. Incorporating Gene Annotation into Genomic Prediction of Complex Phenotypes. Genetics 2017, 207, 489–501. [Google Scholar] [CrossRef]
- Nani, J.P.; Rezende, F.; Peñagaricano, F. Predicting male fertility in dairy cattle using markers with large effect and functional annotation data. BMC Genom. 2019, 20, 258. [Google Scholar] [CrossRef] [Green Version]
- Xu, L.; Gao, N.; Wang, Z.; Xu, L.; Liu, Y.; Chen, Y.; Xu, L.; Gao, X.; Zhang, L.; Gao, H.; et al. Incorporating Genome Annotation Into Genomic Prediction for Carcass Traits in Chinese Simmental Beef Cattle. Front. Genet. 2020, 11. [Google Scholar] [CrossRef] [PubMed]
- Saatchi, M.; McClure, M.C.; McKay, S.D.; Rolf, M.M.; Kim, J.; E Decker, J.; Taxis, T.M.; Chapple, R.H.; Ramey, H.R.; Northcutt, S.L.; et al. Accuracies of genomic breeding values in American Angus beef cattle using K-means clustering for cross-validation. Genet. Sel. Evol. 2011, 43, 1–16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Freetly, H.C.; A Kuehn, L.; Thallman, R.M.; Snelling, W.M. Heritability and genetic correlations of feed intake, body weight gain, residual gain, and residual feed intake of beef cattle as heifers and cows. J. Anim. Sci. 2020, 98. [Google Scholar] [CrossRef] [PubMed]
- Crews, D.H., Jr.; Pollak, E.J.; Weaber, R.L.; Quaas, R.L.; Lipsey, R.J. Genetic parameters for carcass traits and their live animal indicators in Simmental cattle. J. Anim. Sci. 2003, 81, 1427–1433. [Google Scholar] [CrossRef] [PubMed]
- Onogi, A.A.; Ogino, T.; Komatsu, N.; Shoji, K.; Simizu, K.; Kurogi, T.; Yasumori, K.; Togashi, K.; Iwata, H. Genomic prediction in Japanese Black cattle: Application of a single-step approach to beef cattle. J. Anim. Sci. 2015, 92, 1931–1938. [Google Scholar] [CrossRef]
- Mehrban, H.; Lee, D.H.; Moradi, M.H.; IlCho, C.; Naserkheil, M.; Ibáñez-Escriche, N. Predictive performance of genomic selection methods for carcass traits in Hanwoo beef cattle: Impacts of the genetic architecture. Genet. Sel. Evol. 2017, 49, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Júnior, G.A.F.; Rosa, G.J.M.; Valente, B.D.; Carvalheiro, R.; Baldi, F.; Garcia, D.A.; Gordo, D.G.M.; Espigolan, R.; Takada, L.; Tonussi, R.L.; et al. Genomic prediction of breeding values for carcass traits in Nellore cattle. Genet. Sel. Evol. 2016, 48, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Somavilla, A.L.; Regitano, L.C.A.; Rosa, G.J.M.; Mokry, F.B.; Mudadu, M.A.; Tizioto, P.C.; Oliveira, P.S.N.; Souza, M.M.; Coutinho, L.L.; Munari, D.P. Genome-Enabled Prediction of Breeding Values for Feedlot Average Daily Weight Gain in Nelore Cattle. G3 (Bethesda) 2017, 7, 1855–1859. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Miao, J.; Chang, T.; Xia, J.; An, B.; Li, Y.; Xu, L.; Zhang, L.; Gao, X.; Li, J.; et al. Evaluation of GBLUP, BayesB and elastic net for genomic prediction in Chinese Simmental beef cattle. PLoS ONE 2019, 14, e0210442. [Google Scholar] [CrossRef] [PubMed]
- Pérez-Enciso, M.; Rincón, J.C.; Legarra, A. Sequence- vs. chip-assisted genomic selection: Accurate biological information is advised. Genet. Sel. Evol. 2015, 47, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Meuwissen, T.; Goddard, M. Accurate prediction of genetic values for complex traits by whole genome resequencing. Genetics 2010, 185, 623–631. [Google Scholar] [CrossRef] [PubMed]
- Niu, H.; Zhu, B.; Guo, P.; Zhang, W.; Xue, J.; Chen, Y.; Zhang, L.; Gao, H.; Gao, X.; Xu, L.; et al. Estimation of linkage disequilibrium levels and haplotype block structure in Chinese Simmental and Wagyu beef cattle using high-density genotypes. Livest. Sci. 2016, 190, 1–9. [Google Scholar] [CrossRef]
- Daetwyler, H.D.; Pong-Wong, R.; Villanueva, B.; A Woolliams, J. The Impact of Genetic Architecture on Genome-Wide Evaluation Methods. Genetics 2010, 185, 1021–1031. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lehermeier, C.; Wimmer, V.; Albrecht, T.; Auinger, H.-J.; Gianola, D.; Schmid, V.J.; Schön, C.-C. Sensitivity to prior specification in Bayesian genome-based prediction models. Stat. Appl. Genet. Mol. Biol. 2013, 12, 375–391. [Google Scholar] [CrossRef] [PubMed]
- Zhu, B.; Zhang, J.; Niu, H.; Guan, L.; Guo, P.; Xu, L.; Chen, Y.; Zhang, L.; Gao, H.; Gao, X.; et al. Effects of marker density and minor allele frequency on genomic prediction for growth traits in Chinese Simmental beef cattle. J. Integr. Agric. 2017, 16, 911–920. [Google Scholar] [CrossRef]
- Zhang, Z.; Ding, X.; Liu, J.-F.; Zhang, Q.; De Koning, D.J. Accuracy of genomic prediction using low-density marker panels. J. Dairy Sci. 2011, 94, 3642–3650. [Google Scholar] [CrossRef] [Green Version]

{kind=link}
{kind=link}
{kind=link}
| Traits 1 | The Number of Phenotypes | Mean (SD) | h2 (SE) | |||
|---|---|---|---|---|---|---|
| Growth traits | ADG | 1330 | 0.96 ± 0.22 | 0.37 ± 0.06 | 0.12 | 0.17 |
| LW | 1342 | 504.95 ± 70.22 | 0.38 ± 0.07 | 4586.61 | 7483.41 | |
| Carcass traits | CW | 1346 | 270.67 ± 45.20 | 0.42 ± 0.05 | 314.05 | 433.69 |
| DP | 1341 | 53.56 ± 2.91 | 0.28 ± 0.06 | 2.04 | 5.23 | |
| LP | 1338 | 45.47 ± 3.00 | 0.35 ± 0.07 | 3.00 | 5.57 | |
| ST | 1342 | 8.55 ± 1.99 | 0.40 ± 0.05 | 0.75 | 1.13 | |
| TD | 1341 | 3.97 ± 0.70 | 0.28 ± 0.07 | 2.04 | 5.24 | |
| SR | 1341 | 10.57 ± 2.23 | 0.39 ± 0.07 | 0.12 | 0.19 | |
| CR | 1334 | 11.47 ± 3.25 | 0.56 ± 0.06 | 1.98 | 1.56 | |
| RMW | 1344 | 167.79 ± 30.15 | 0.39 ± 0.07 | 112.42 | 175.83 | |
| Meat quality traits | EMA12 | 1343 | 85.53 ± 13.58 | 0.18 ± 0.06 | 21.20 | 96.59 |
| EMA13 | 1203 | 85.21 ± 14.13 | 0.28 ± 0.06 | 26.19 | 67.35 | |
| MB | 1343 | 5.14 ± 1.00 | 0.11 ± 0.05 | 0.27 | 2.18 | |
| Traits 1 | GBLUP | BayesA | BayesB | BayesCπ | |||||
|---|---|---|---|---|---|---|---|---|---|
| LD 2 | HD 3 (SD) | LD | HD (SD) | LD | HD (SD) | LD | HD (SD) | ||
| Growth traits | ADG (−0.05) | 0.37 | 0.40 (0.06) | 0.36 | 0.42 (0.06) | 0.35 | 0.43 (0.06) | 0.38 | 0.42 (0.06) |
| LW (+0.06) | 0.43 | 0.38 (0.05) | 0.42 | 0.34 (0.06) | 0.41 | 0.38 (0.06) | 0.44 | 0.37 (0.06) | |
| Carcass traits | CW (0) | 0.23 | 0.24 (0.06) | 0.22 | 0.21 (0.06) | 0.23 | 0.24 (0.06) | 0.23 | 0.20 (0.06) |
| DP (−0.07) | 0.31 | 0.37 (0.05) | 0.28 | 0.37 (0.06) | 0.30 | 0.39 (0.06) | 0.34 | 0.37 (0.06) | |
| LP (−0.03) | 0.29 | 0.34 (0.06) | 0.28 | 0.34 (0.05) | 0.33 | 0.33 (0.06) | 0.32 | 0.34 (0.06) | |
| ST (−0.20) | 0.31 | 0.45 (0.06) | 0.32 | 0.53 (0.06) | 0.31 | 0.53 (0.06) | 0.32 | 0.54 (0.06) | |
| TD (+0.04) | 0.36 | 0.36 (0.05) | 0.37 | 0.31 (0.06) | 0.38 | 0.34 (0.06) | 0.38 | 0.31 (0.06) | |
| SR (−0.09) | 0.37 | 0.43 (0.06) | 0.38 | 0.46 (0.06) | 0.39 | 0.48 (0.05) | 0.39 | 0.54 (0.05) | |
| CR (−0.04) | 0.37 | 0.42 (0.05) | 0.37 | 0.39 (0.06) | 0.30 | 0.39 (0.06) | 0.39 | 0.39 (0.06) | |
| RMW (−0.09) | 0.47 | 0.61 (0.06) | 0.47 | 0.53 (0.07) | 0.43 | 0.50 (0.06) | 0.43 | 0.52 (0.06) | |
| Meat quality traits | EMA12 (+0.06) | 0.32 | 0.24 (0.07) | 0.32 | 0.25 (0.07) | 0.27 | 0.23 (0.07) | 0.32 | 0.26 (0.07) |
| EMA13 (+0.06) | 0.29 | 0.21 (0.07) | 0.28 | 0.24 (0.07) | 0.30 | 0.24 (0.07) | 0.29 | 0.22 (0.07) | |
| MB (+0.07) | 0.34 | 0.27 (0.07) | 0.31 | 0.26 (0.07) | 0.32 | 0.25 (0.07) | 0.34 | 0.26 (0.07) | |
| Traits 1 | GBLUP | BayesA | BayesB | BayesCπ | |||||
|---|---|---|---|---|---|---|---|---|---|
| LD 2 | HD 3 | LD | HD | LD | HD | LD | HD | ||
| Growth traits | ADG | 0.914 | 0.989 | 1.397 | 1.022 | 1.198 | 0.970 | 1.198 | 1.039 |
| LW | 1.175 | 1.011 | 1.300 | 0.971 | 1.342 | 0.926 | 1.150 | 1.045 | |
| Carcass traits | CW | 0.812 | 1.102 | 0.928 | 0.967 | 1.198 | 1.202 | 0.852 | 1.082 |
| DP | 0.922 | 1.075 | 1.379 | 0.976 | 1.331 | 1.057 | 1.022 | 1.151 | |
| LP | 0.904 | 0.963 | 1.343 | 0.910 | 1.323 | 1.041 | 1.008 | 1.025 | |
| ST | 1.023 | 1.064 | 1.387 | 1.225 | 1.210 | 1.082 | 1.210 | 1.077 | |
| TD | 1.106 | 1.064 | 1.389 | 1.056 | 1.271 | 0.974 | 1.201 | 1.082 | |
| SR | 1.094 | 1.059 | 1.388 | 1.093 | 1.242 | 0.993 | 1.158 | 0.965 | |
| CR | 0.923 | 1.040 | 1.170 | 1.092 | 1.199 | 1.148 | 1.199 | 1.094 | |
| RMW | 1.164 | 1.039 | 1.203 | 0.944 | 1.234 | 1.031 | 1.257 | 0.991 | |
| Meat quality traits | EMA12 | 0.924 | 1.116 | 1.460 | 0.983 | 1.263 | 0.958 | 0.937 | 1.082 |
| EMA13 | 0.764 | 1.025 | 1.419 | 1.117 | 1.293 | 1.167 | 0.790 | 1.142 | |
| MB | 1.372 | 1.125 | 1.561 | 1.122 | 1.430 | 1.210 | 1.367 | 1.159 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, L.; Niu, Q.; Chen, Y.; Wang, Z.; Xu, L.; Li, H.; Xu, L.; Gao, X.; Zhang, L.; Gao, H.; et al. Validation of the Prediction Accuracy for 13 Traits in Chinese Simmental Beef Cattle Using a Preselected Low-Density SNP Panel. Animals 2021, 11, 1890. https://doi.org/10.3390/ani11071890
Xu L, Niu Q, Chen Y, Wang Z, Xu L, Li H, Xu L, Gao X, Zhang L, Gao H, et al. Validation of the Prediction Accuracy for 13 Traits in Chinese Simmental Beef Cattle Using a Preselected Low-Density SNP Panel. Animals. 2021; 11(7):1890. https://doi.org/10.3390/ani11071890
Chicago/Turabian StyleXu, Ling, Qunhao Niu, Yan Chen, Zezhao Wang, Lei Xu, Hongwei Li, Lingyang Xu, Xue Gao, Lupei Zhang, Huijiang Gao, and et al. 2021. "Validation of the Prediction Accuracy for 13 Traits in Chinese Simmental Beef Cattle Using a Preselected Low-Density SNP Panel" Animals 11, no. 7: 1890. https://doi.org/10.3390/ani11071890
APA StyleXu, L., Niu, Q., Chen, Y., Wang, Z., Xu, L., Li, H., Xu, L., Gao, X., Zhang, L., Gao, H., Cai, W., Zhu, B., & Li, J. (2021). Validation of the Prediction Accuracy for 13 Traits in Chinese Simmental Beef Cattle Using a Preselected Low-Density SNP Panel. Animals, 11(7), 1890. https://doi.org/10.3390/ani11071890