
Pig-Posture Recognition Based on Computer Vision: Dataset and Exploration


Abstract
Simple Summary
Abstract
1. Introduction
2. Related Work
2.1. YOLOv5-Based Detection Network for a Single Pig
2.2. DeepLabv3+-Based Edge-Extraction Network for a Single Pig
2.3. Feature-Extraction Network
2.3.1. Resnet
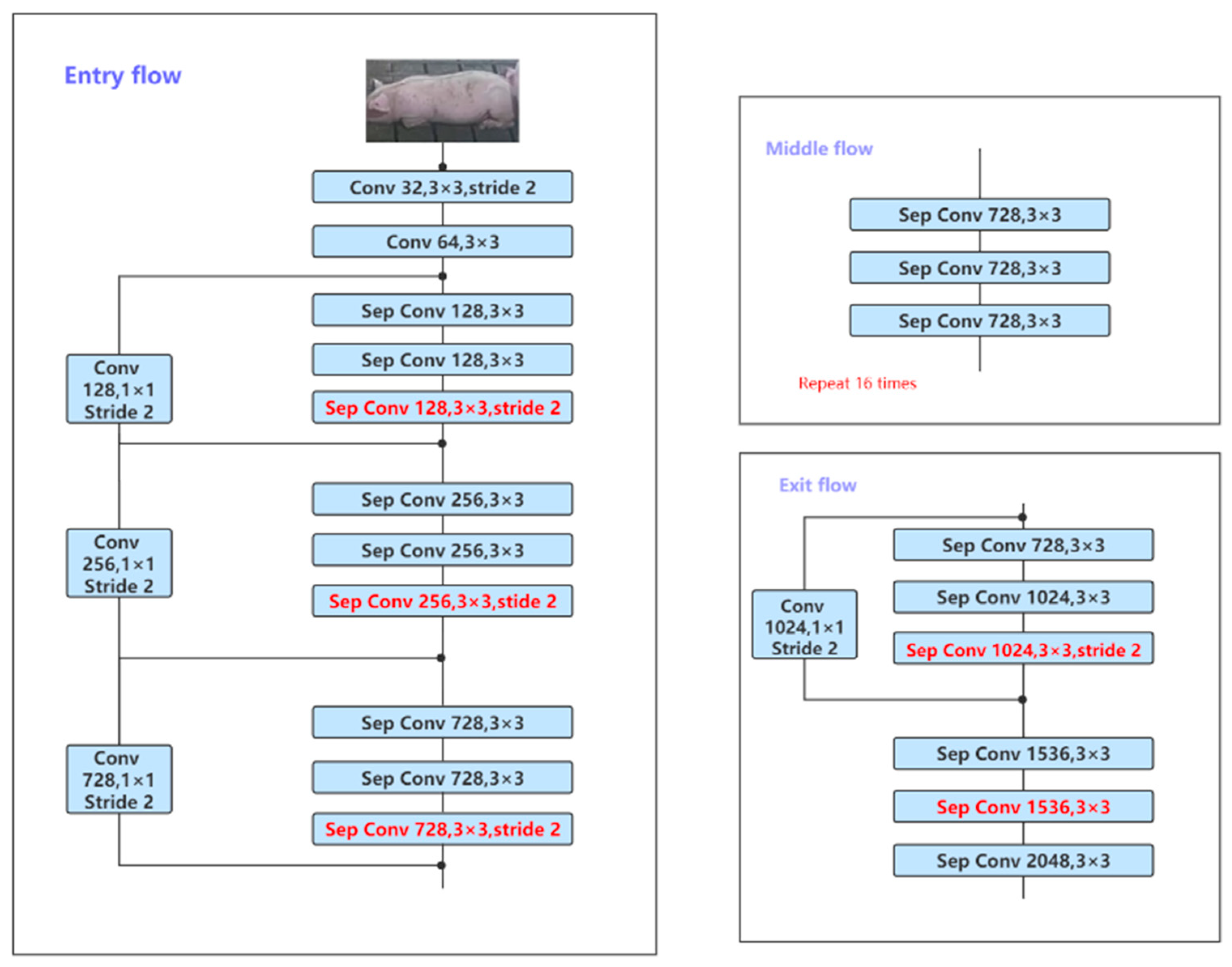
2.3.2. Xception
2.3.3. MobileNet
3. Materials and Methods
3.1. Dataset
3.2. Image Pre-Processing
3.2.1. Single-Target Extraction by Target Detection
3.2.2. Noise Reduction
3.3. DeepLabv3+ Network Structure
3.4. Experimental Environment
3.5. Experimental Evaluation Index
- (1)
- True positive (TP): the prediction result is positive, and the prediction is correct.
- (2)
- True negative (TN): the prediction result is negative, and the prediction is correct.
- (3)
- False positive (FP): the prediction result is positive, but the prediction is wrong.
- (4)
- False negative (FN): the prediction result is negative, but the prediction is wrong.
4. Results
4.1. Model-Training Method
4.2. Experimental Comparative Analysis
- Through the above experimental process, for the feature extraction models Resnet-101, Xception, and MobileNet, there were oscillations in the early training process, but the convergence effect was good in the later period.
- Resnet had the best classification effect on this dataset, with a classification accuracy of up to 92.26%.
- Although MobileNet had an absolute advantage in terms of its training speed, and its accuracy in the later training period was close to that of the Resnet training, the accuracy curve fluctuated significantly in the training process and lacked stability.
- Based on the dataset used in this paper, the Resnet training lasted 7 h and 30 min, the Xception training lasted 7 h and 23 min, and the MobileNet training lasted 1 h and 50 min.
4.3. Discussion
- (1)
- In terms of the recognition accuracy, since our current experimental data source was based on a single camera to the side of the pigs, the observation angle of the pig posture was singular, and the identification of postures by cameras in front or to the side of moving pigs had a certain influence. Therefore, in practical applications, a pig farm should install multiple cameras to collect data in all directions in the environment and assign different weights to calculate pig postures based on different angles.
- (2)
- In terms of the processing speed, in order to realize the real-time monitoring of pig postures, data could be extracted from one frame every 2 s in practical applications. In terms of the computational speed of the model, both YOLOv5 and DeepLab v3+ have good processing speeds, as explained in Section 2.1 and Section 2.3.
- (3)
- This method also has certain limitations. For example, after extracting frames from a video to obtain a static image, it is impossible to determine whether a pig is moving. In the future, video recognition or a recurrent neural network (RNN) could be used to generate a sequence of pictures with which to classify behaviors in order to solve this problem.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Statistical Communiqué of the People’s Republic of China on the 2019 National Economic and Social Development. Available online: http://www.stats.gov.cn/tjsj/zxfb/202002/t20200228_1728913.html (accessed on 4 January 2021).
- 2019 China Pig Industry Research and Commercial Investment Decision Analysis Report. Available online: https://report.iimedia.cn/repo1-0/38822.html (accessed on 4 January 2021).
- Yang, H.; Zhou, L. Swine disease epidemic in 2018 and 2019 epidemic trend and prevention and control countermeasures. Swine Sci. 2019, 36, 38–40. [Google Scholar] [CrossRef]
- Wu, S.; Bao, Y.; Chen, G.; Chen, Q. Non-contact recognition system for pig behavior activity based on machine vision technology. Comput. Syst. Appl. 2020, 29, 113–117. [Google Scholar] [CrossRef]
- Ren, G.; Jin, C. Pig individual characteristics and identification methods. Mod. Agric. Sci. Technol. 2019, 18, 171–173. [Google Scholar]
- Hao, F. Monitoring of Abnormal Behavior of Pigs Based on Micro-Inertial Sensors; Taiyuan University of Technology, 2018. Available online: https://kns.cnki.net/KCMS/detail/detail.aspx?dbname=CMFD201802&filename=1018959077.nh (accessed on 29 April 2021).
- Ringgenberg, N.; Bergeron, R.; Devillers, N. Validation of accelerometers to automatically record sow postures and stepping behaviour. Anim. Behav. Sci. 2010, 128, 37–44. [Google Scholar] [CrossRef]
- Martínez-Avilés, M.; Fernández-Carrión, E.; López García-Baones, J.M.; Sánchez-Vizcaíno, J.M. Early detection of infection in pigs through an online monitoring system. Transbound. Emerg. Dis. 2017, 64, 364–373. [Google Scholar] [CrossRef] [PubMed]
- Madsen, T.N.; Kristensen, A.R. A model for monitoring the condition of young pigs by their drinking behaviour. Comput. Electron. Agric. 2005, 48, 138–154. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Leroy, T.; Vranken, E.; Van Brecht, A.; Struelens, E.; Sonck, B.; Berckmans, D. A computer vision method for on-line behavioral quantification of individually caged poultry. Trans. Am. Soc. Agric. Biol. Eng. 2006, 49, 795–802. [Google Scholar]
- Han, J. Research on Behavior Recognition Method of Dairy Goat Based on Convolutional Neural Network; Northwest Sci-Tech University of Agriculture and Forestry, 2019. Available online: https://kns.cnki.net/KCMS/detail/detail.aspx?dbname=CMFD201902&filename=1019902149.nh (accessed on 29 April 2021).
- Xu, D.; Wang, L.; Li, F. Summary of research on typical target detection algorithms for deep learning. Comput. Eng. Appl. 2021, 57, 10–25. [Google Scholar]
- Lu, X.; Liu, Z. Summarization of Image Semantic Segmentation Technology Based on Deep Learning. Softw. Guide 2021, 20, 242–244. [Google Scholar]
- Lin, X.; Zhu, S.; Zhang, J.; Liu, D. An image classification method of rice planthopper based on transfer learning and Mask R-CNN. Trans. Chin. Soc. Agric. Mach. 2019, 50, 201–207. [Google Scholar]
- Liao, H. Research on Individual Segmentation of Pig Images Based on RGB-D Group; Huazhong Agricultural University, 2020. Available online: https://kns.cnki.net/KCMS/detail/detail.aspx?dbname=CMFD202101&filename=1020366500.nh (accessed on 29 April 2021).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the CVPR 2016: IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the ECCV 2016: European Conference on Computer Vision, Amsterdam, The Netherlands, 7–12 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the CVPR 2017: IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. In Proceedings of the CVPR 2018: IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 18–22 June 2018. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the Computer Vision ECCV 2018; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11211, pp. 833–851. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the CVPR 2016: IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv 2016, arXiv:1610.02357. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2012. [Google Scholar] [CrossRef]
- Howard, A.G.; Chen, B.; Kalenichenko, D.; Weyand, T.C.; Zhu, M.; Andreetto, M.; Wang, W. Efficient Convolutional Neural Networks and Techniques to Reduce Associated Computational Costs. U.S. Patent 15/707,064, 17 May 2018. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.M. A non-local algorithm for image denoising. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 60–65. [Google Scholar]
- Ko, S.J.; Lee, Y.H. Center weighted median filter and their applications to image enhancement. IEEE Trans. Circuits Syst. 1991, 38, 984–993. [Google Scholar] [CrossRef]
- Ding, Y.; Yang, J. Comparison between Euclidean distance and standardized Euclidean distance in k-nearest neighbor algorithm. Software 2020, 41, 135–136, 140. [Google Scholar]
- Li, D.; Chen, Y.; Li, X.; Pu, D. Research progress in the application of computer vision technology in pig behavior recognition. China Agric. Sci. Technol. Rev. 2019, 21, 59–69. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | MIoU in Val |
|---|---|
| Resnet | 78.43% |
| MobileNet | 70.81% |
| Xception | / |
| Expected Results | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual Results | Positive | TP | FP |
| Negative | FN | TN | |
| Category | Epoch10 | Epoch20 | Epoch30 | Epoch40 | Epoch50 | |
|---|---|---|---|---|---|---|
| Resnet | Acc | 84.85 | 85.16 | 89.72 | 90.58 | 92.45 |
| AccClass | 82.22 | 83.8 | 88.37 | 89.67 | 92.26 | |
| Xception | Acc | 66.1 | 73.7 | 83.7 | 83.66 | 87.53 |
| AccClass | 57.99 | 66.4 | 79.98 | 80.19 | 85.68 | |
| MobileNet | Acc | 84.86 | 83.58 | 79.04 | 89.6 | 91.69 |
| AccClass | 82.82 | 83.53 | 77.14 | 88.62 | 91.03 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, H.; Pu, J.; Mu, J. Pig-Posture Recognition Based on Computer Vision: Dataset and Exploration. Animals 2021, 11, 1295. https://doi.org/10.3390/ani11051295
Shao H, Pu J, Mu J. Pig-Posture Recognition Based on Computer Vision: Dataset and Exploration. Animals. 2021; 11(5):1295. https://doi.org/10.3390/ani11051295
Chicago/Turabian StyleShao, Hongmin, Jingyu Pu, and Jiong Mu. 2021. "Pig-Posture Recognition Based on Computer Vision: Dataset and Exploration" Animals 11, no. 5: 1295. https://doi.org/10.3390/ani11051295
APA StyleShao, H., Pu, J., & Mu, J. (2021). Pig-Posture Recognition Based on Computer Vision: Dataset and Exploration. Animals, 11(5), 1295. https://doi.org/10.3390/ani11051295