An RGB-D Vision-Guided Robotic Depalletizing System for Irregular Camshafts with Transformer-Based Instance Segmentation and Flexible Magnetic Gripper


Abstract
1. Introduction
- An intelligent depalletizing system is developed, integrating an RGB-D perception module and a flexible magnetic adsorption device tailored for irregular camshaft handling.
- A novel instance segmentation network, MaskNet, is proposed. It leverages dual-branch Vision Transformers and attention-based feature fusion, achieving accurate segmentation under stacking and occlusion.
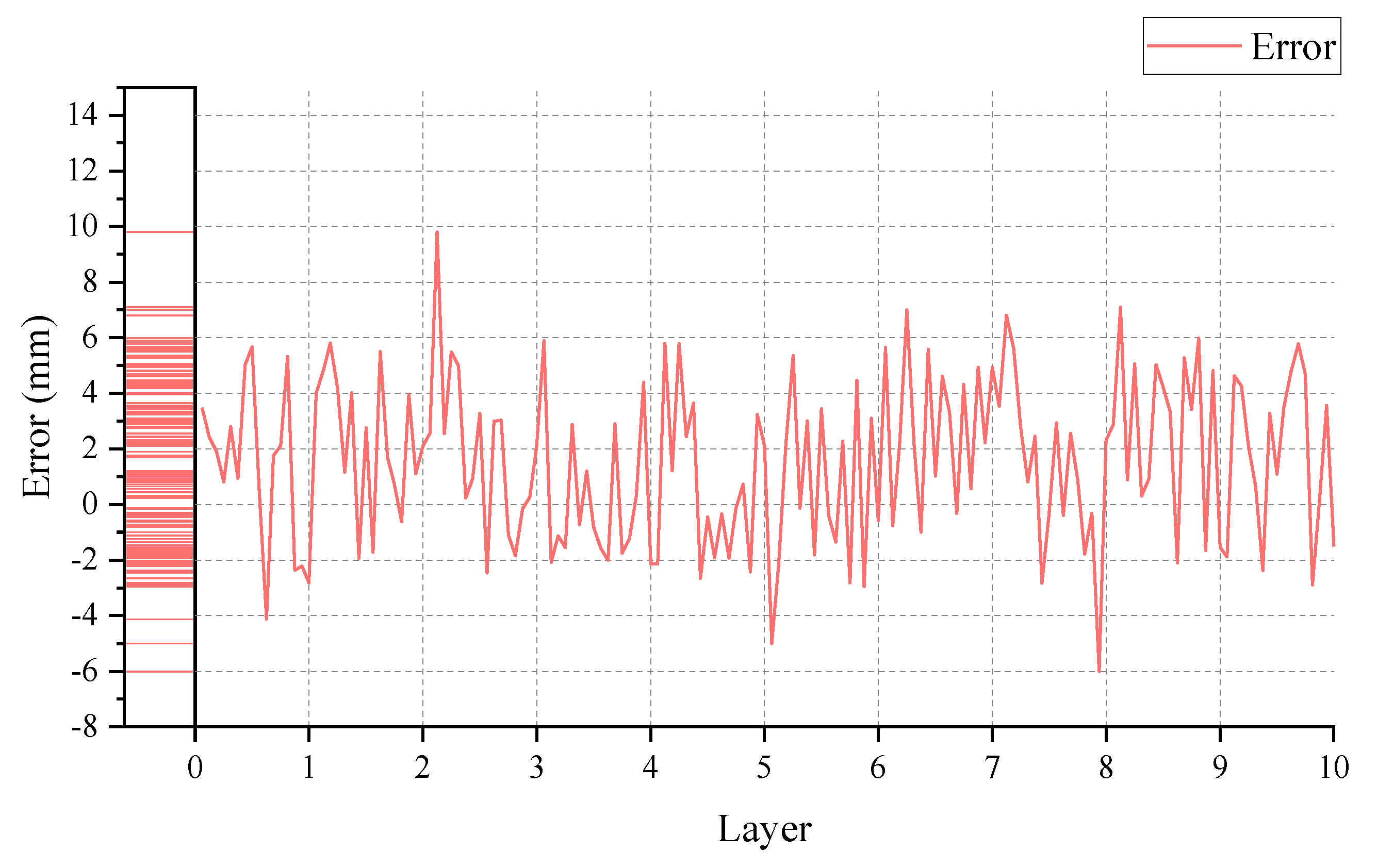
- Comparative and real-world deployment experiments are conducted. The results show that MaskNet significantly outperforms YOLO11 in segmentation accuracy, and the integrated system achieves stable grasping performance with a maximum error of 9.85 mm and a 98% success rate in structured unloading tasks.
2. System Construction
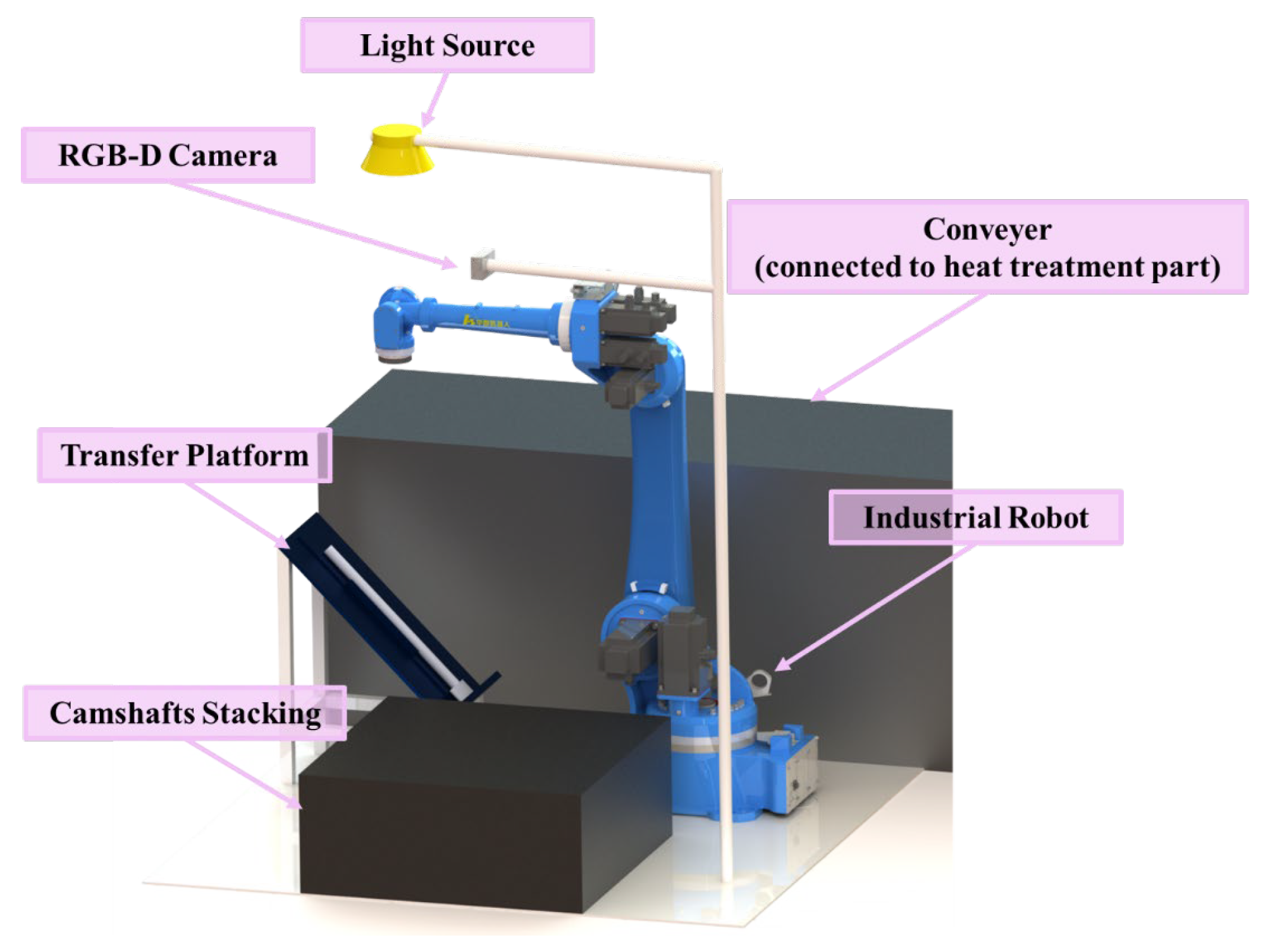
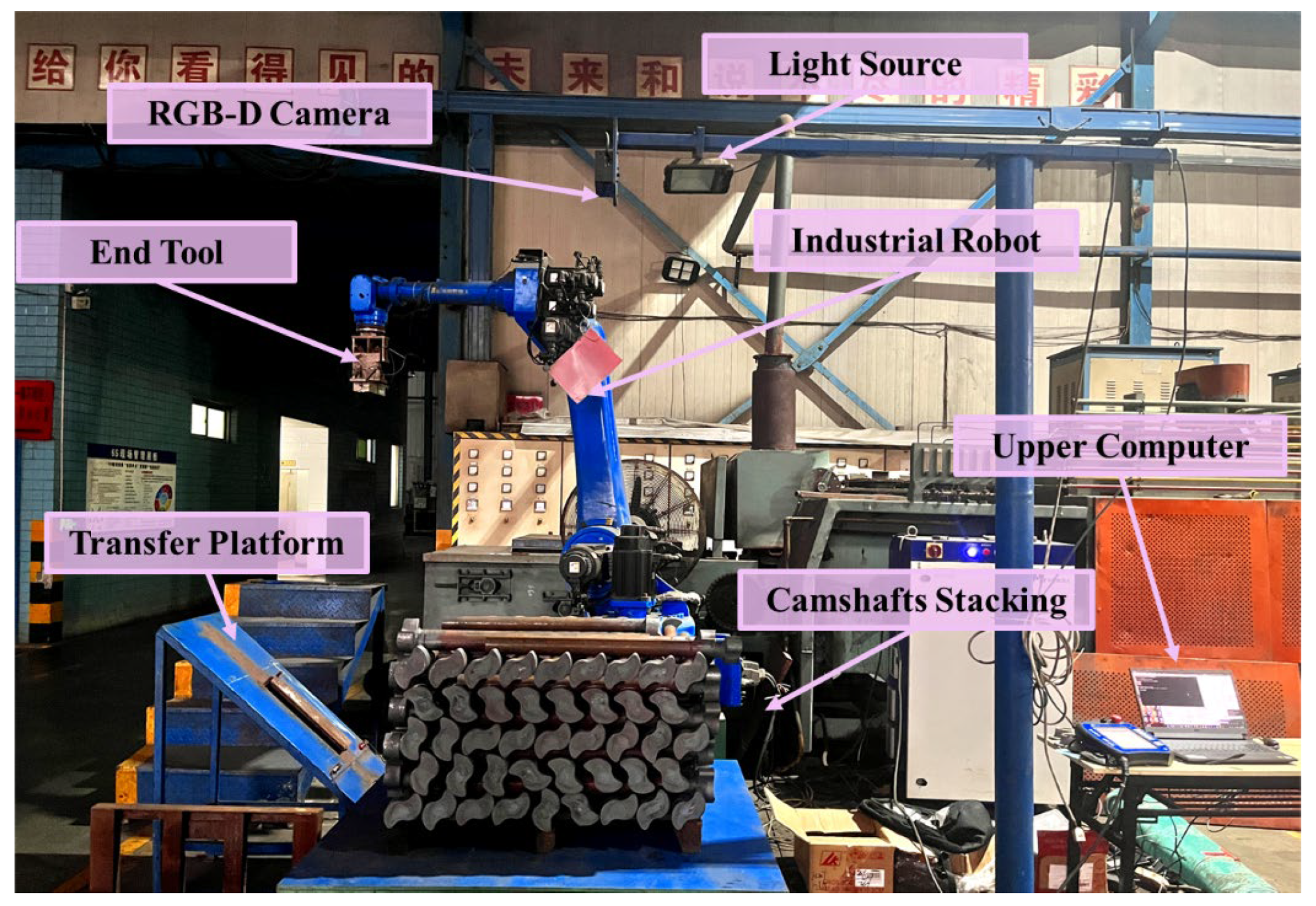
2.1. Palletizing Object and Hardware Overview
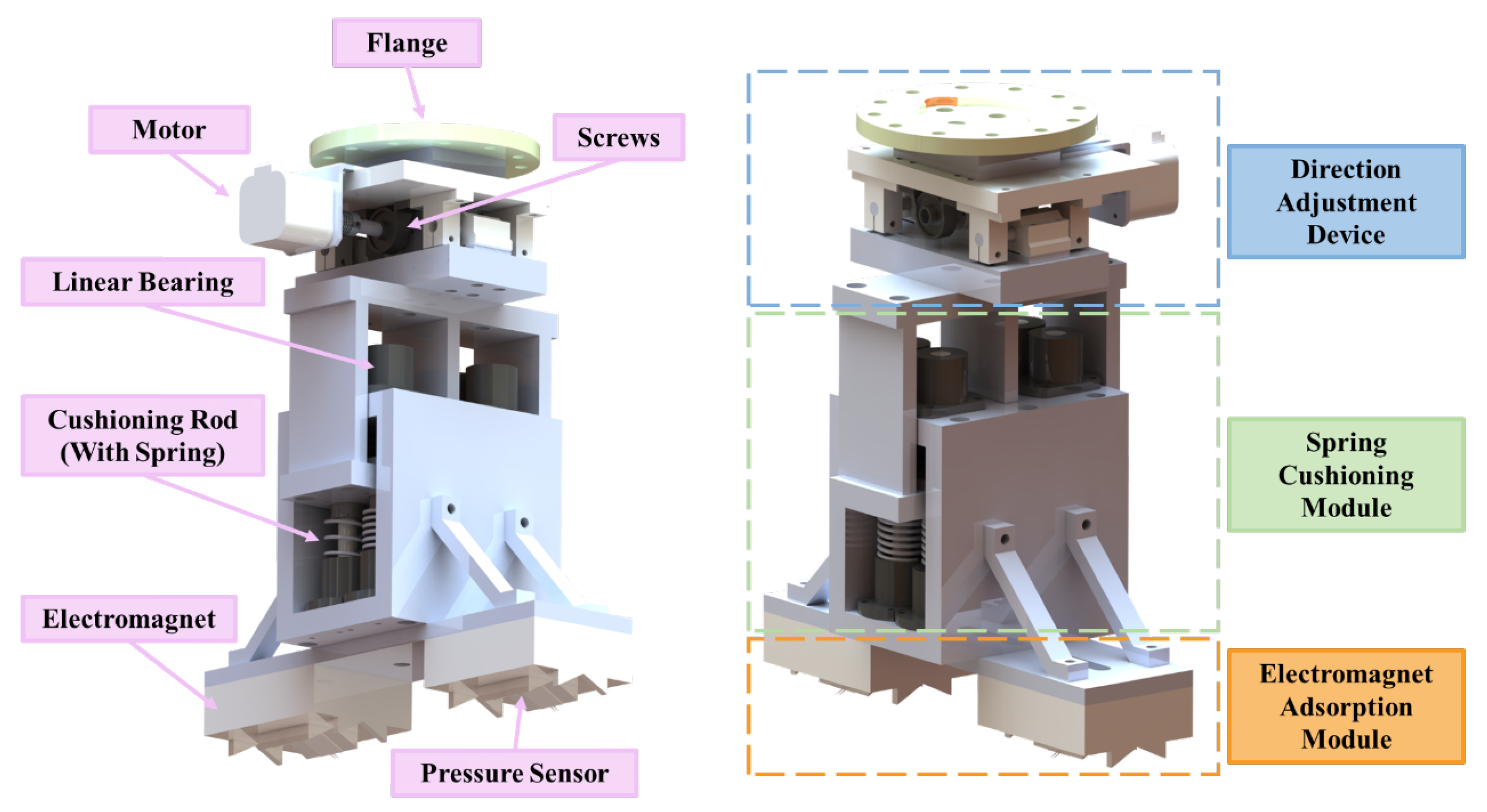
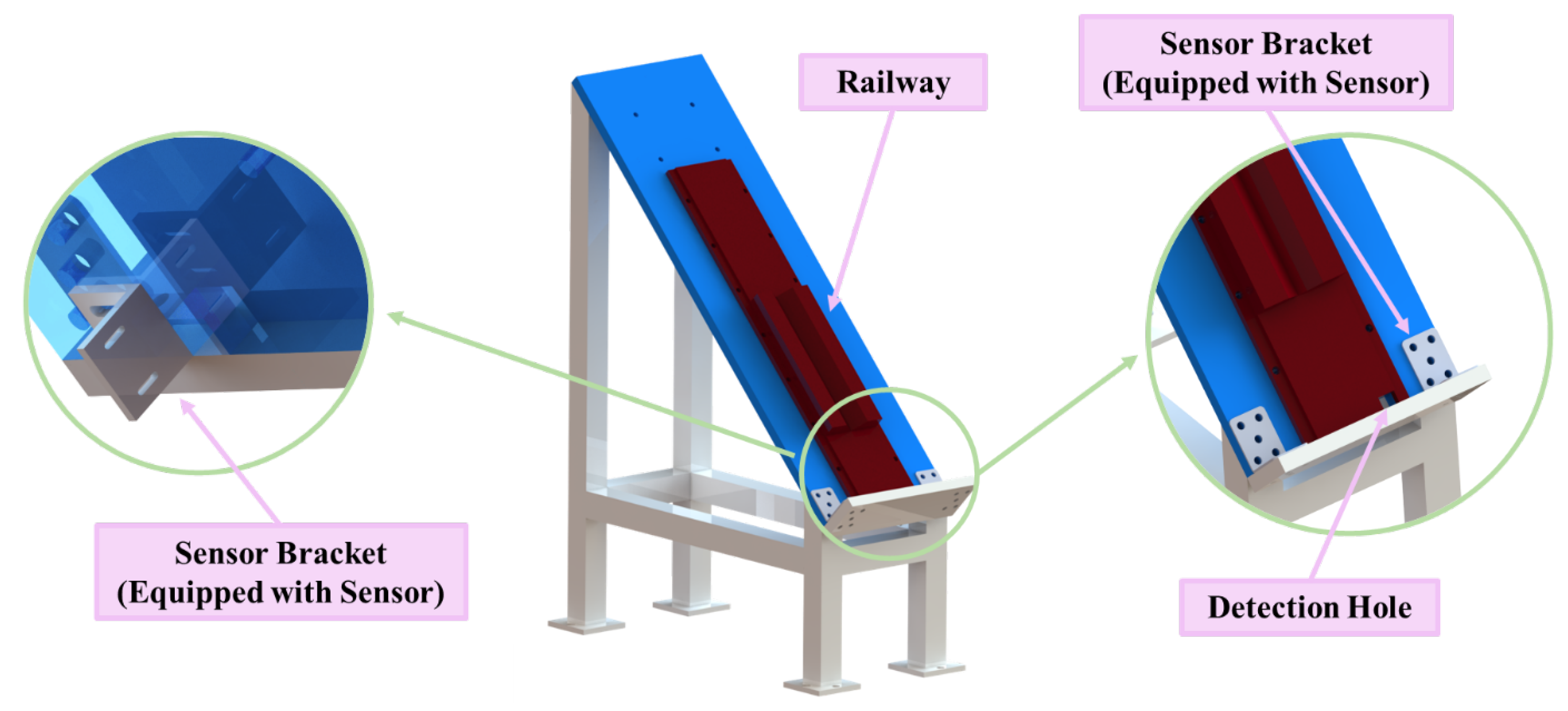
2.2. End Adsorption Device
3. Transformer-Based RGB-D Instance Segmentation: The MaskNet Approach
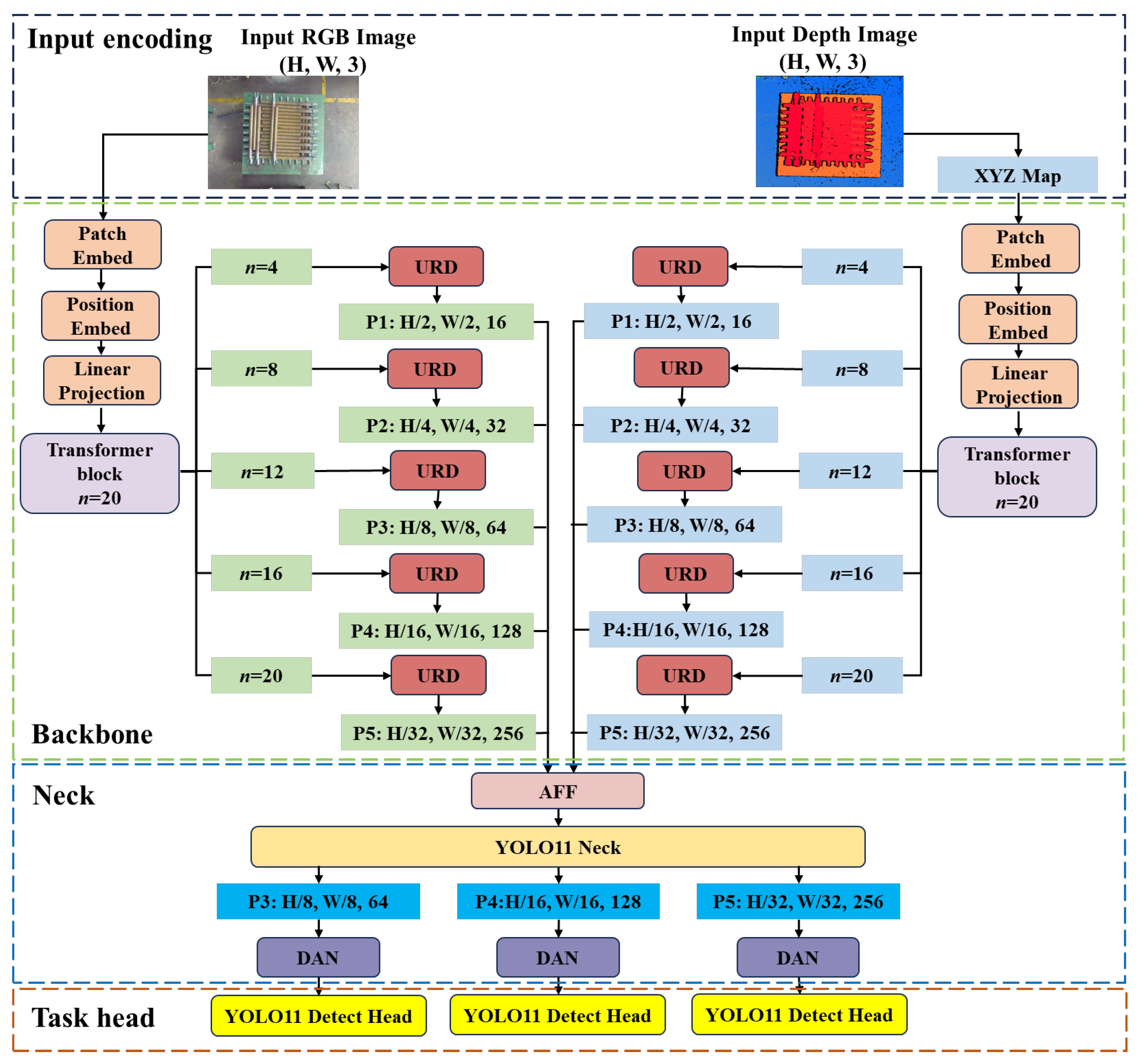
3.1. Overall Architecture of the MaskNet
- (1)
- A depth modality is incorporated as an additional input. Specifically, the raw depth image is converted into an XYZ feature map through a tailored encoding strategy, providing rich spatial cues to complement the RGB data.
- (2)
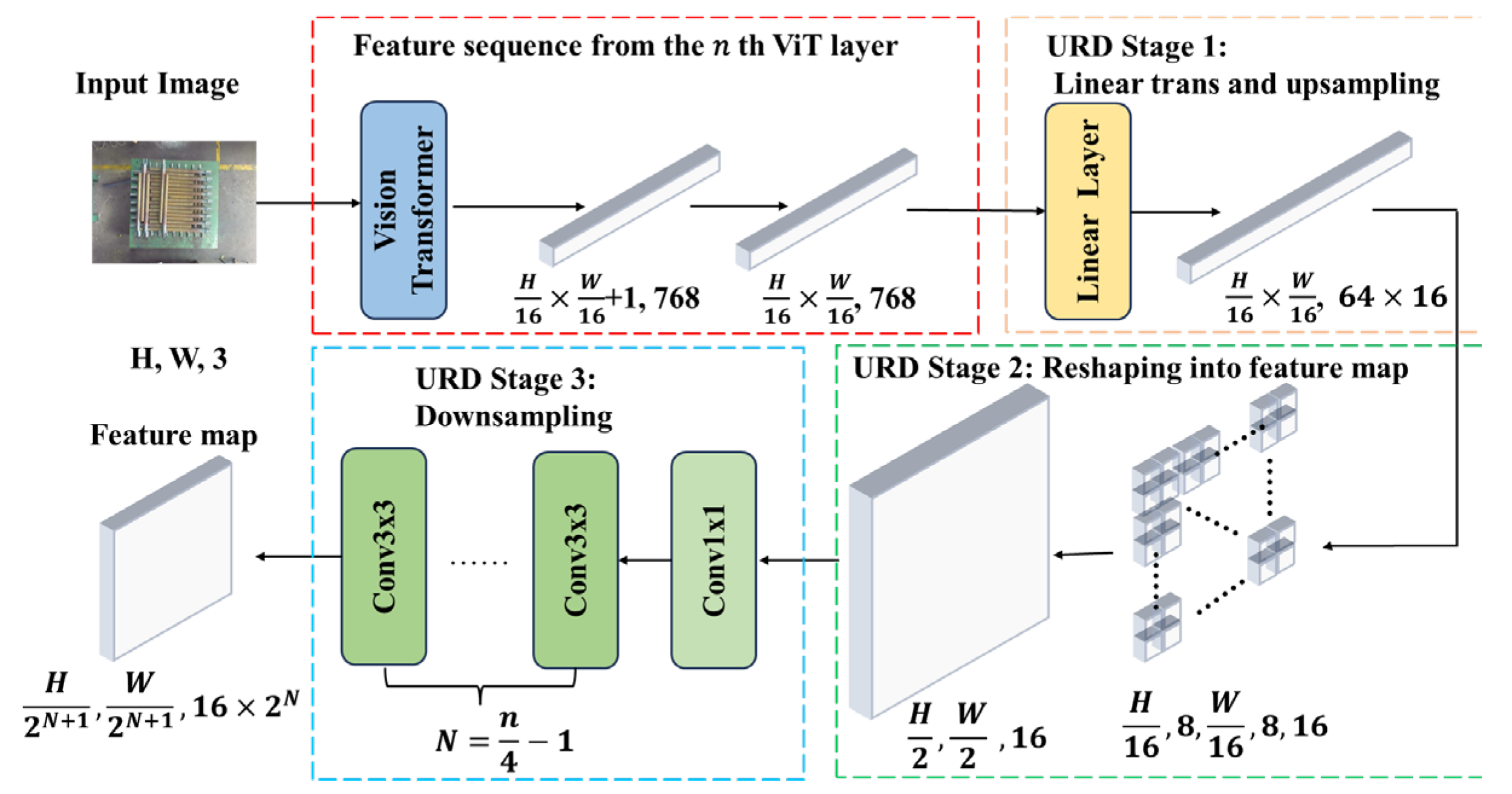
- In the backbone, conventional bonvolution–BatchNorm–SiLU (CBS) and C3K2 modules are replaced by a Vision Transformer (ViT) with a depth of 20 layers. This substitution enables more efficient and expressive feature extraction while reducing architectural complexity. A dedicated Up-sample Reshape Down-sample (URD) module is introduced to reshape the ViT output vector into a feature map format, preparing it for subsequent multi-modal fusion.
- (3)
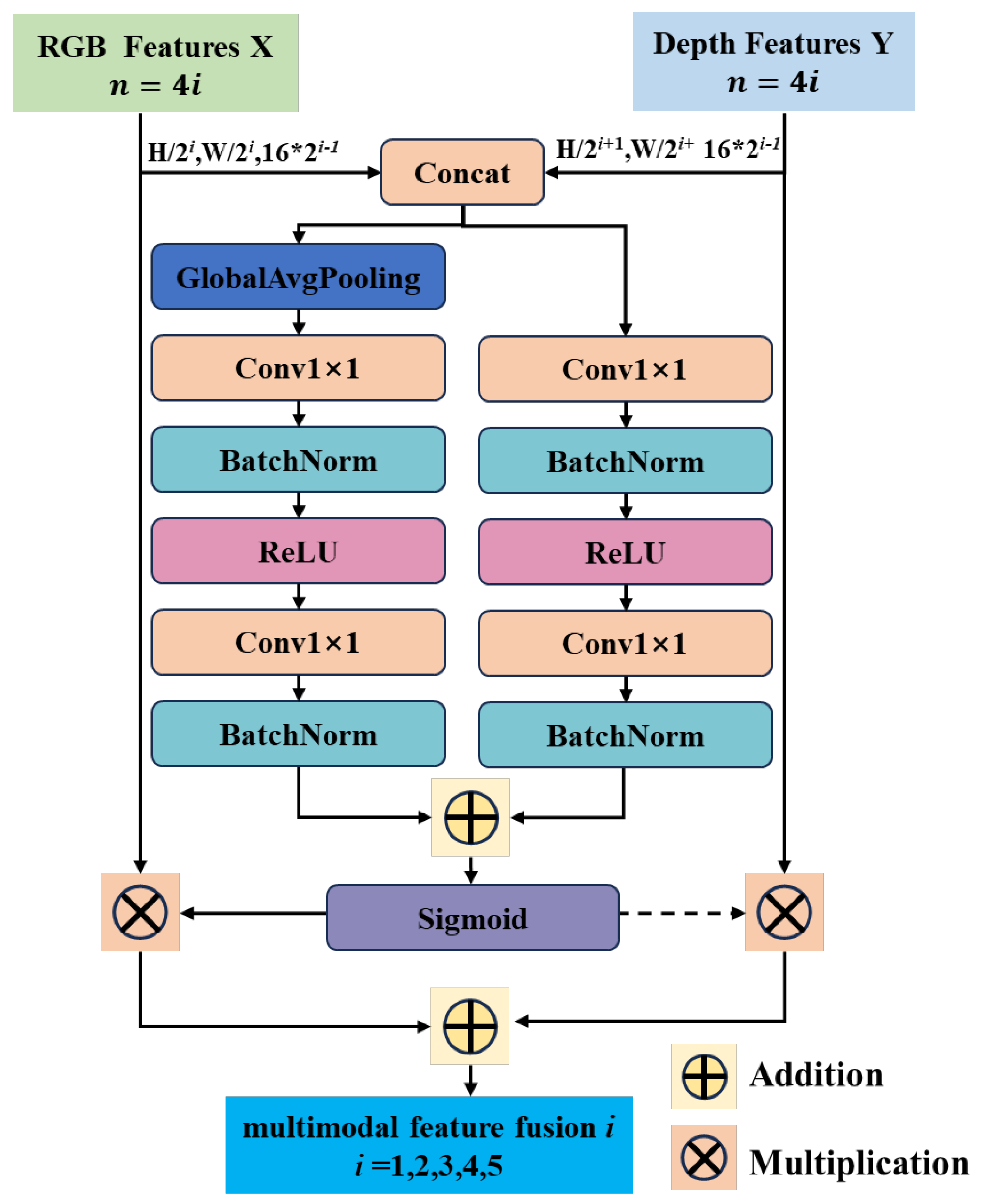
- To facilitate multi-modal feature fusion, an attention-based Attentional Feature Fusion (AFF) module is appended to the end of the neck network. This module operates in conjunction with the original YOLO11 neck to construct a multi-modal, multi-scale feature pyramid.
- (4)
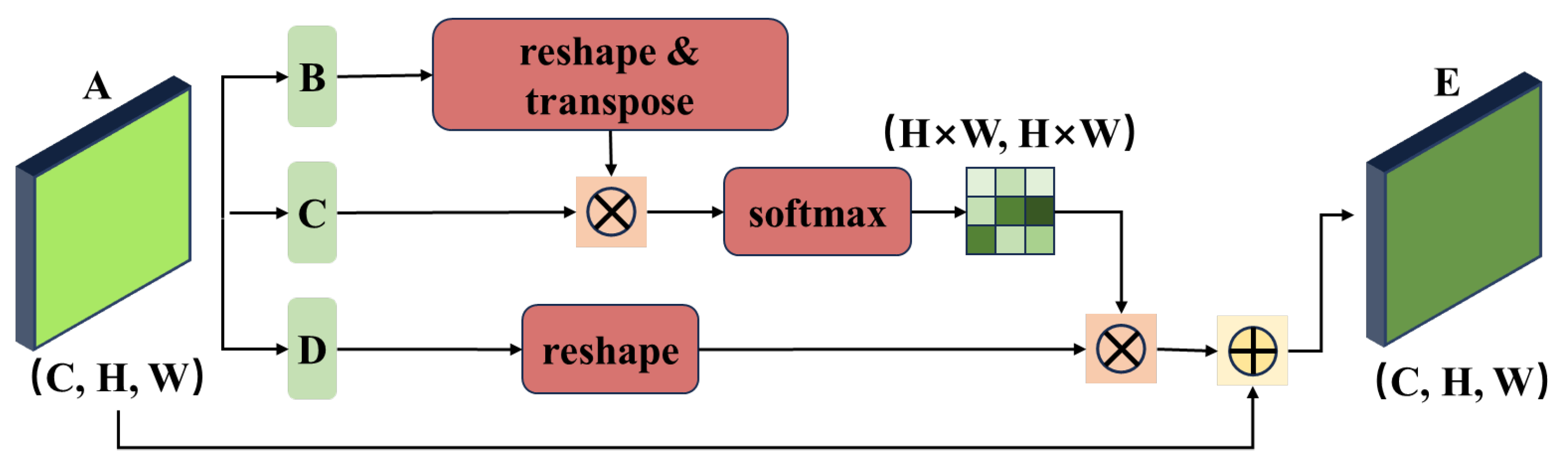
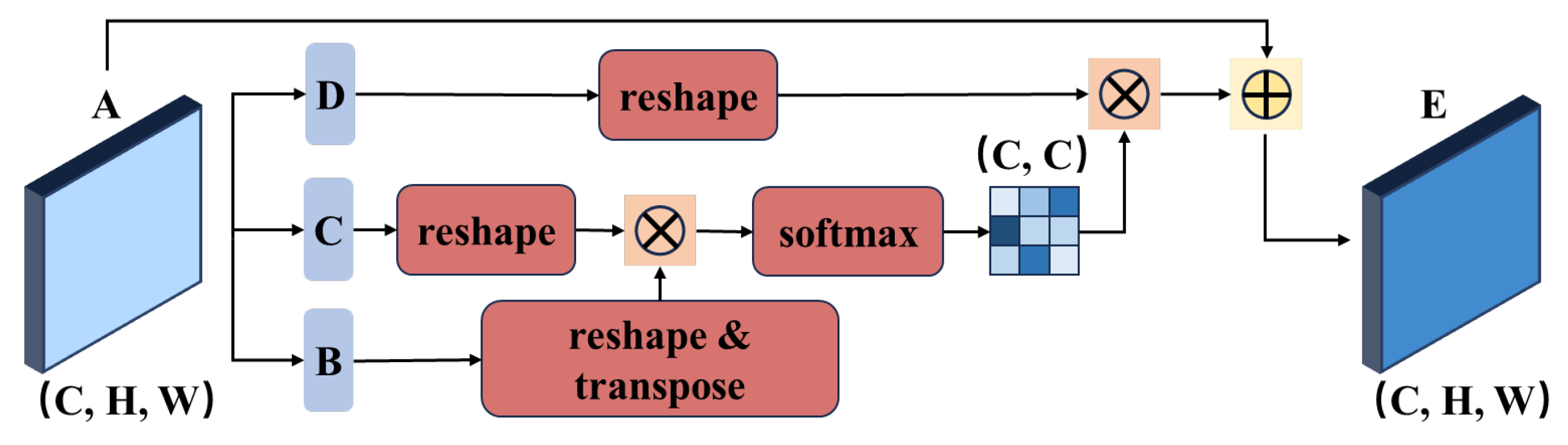
- To further enhance mask segmentation accuracy, three lightweight Dual Attention Network (DAN) modules are integrated at the head stage. These modules capture dependencies along spatial and channel dimensions, strengthening feature expressiveness. Multi-scale feature maps are simultaneously fed into the YOLO11 detection head for bounding box and class prediction, and used to generate mask parameters that are combined to produce final instance masks.
3.2. Vision Transformer-Based Feature Extraction
3.3. Attention-Based Multi-Modal Feature Fusion
3.4. Spatial and Channel Feature Fusion with Attention Mechanism
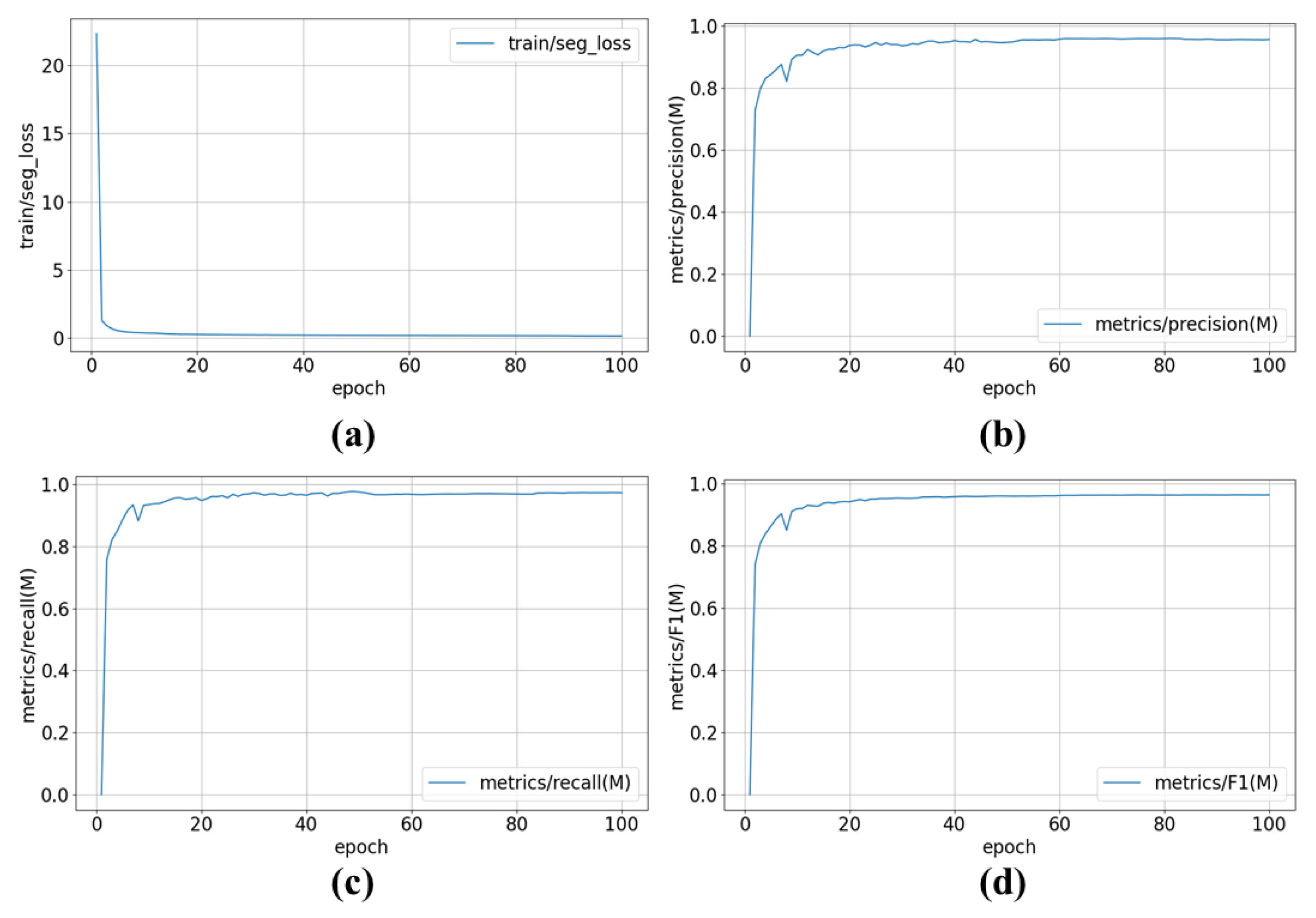
3.5. Network Performance Evaluation
3.5.1. Comparison Experiment
- (1)
- Precision Comparison
- (2)
- Recall Comparison
- (3)
- F1-Score Comparison
- (4)
- Horizontal Comparison with State-of-the-Art Methods
3.5.2. Ablation Study
- A.
- Indicates whether ViT + URD is used for feature extraction; otherwise, the original YOLO11 backbone (CBS + C3K2 + SPPF + C2PSA) is used.
- B.
- Denotes the use of attention-based multi-modal fusion; B1 and B2 represent fusion via element-wise addition or feature map concatenation, respectively.
- C.
- Indicates whether the DAN module is used for spatial and channel attention enhancement.
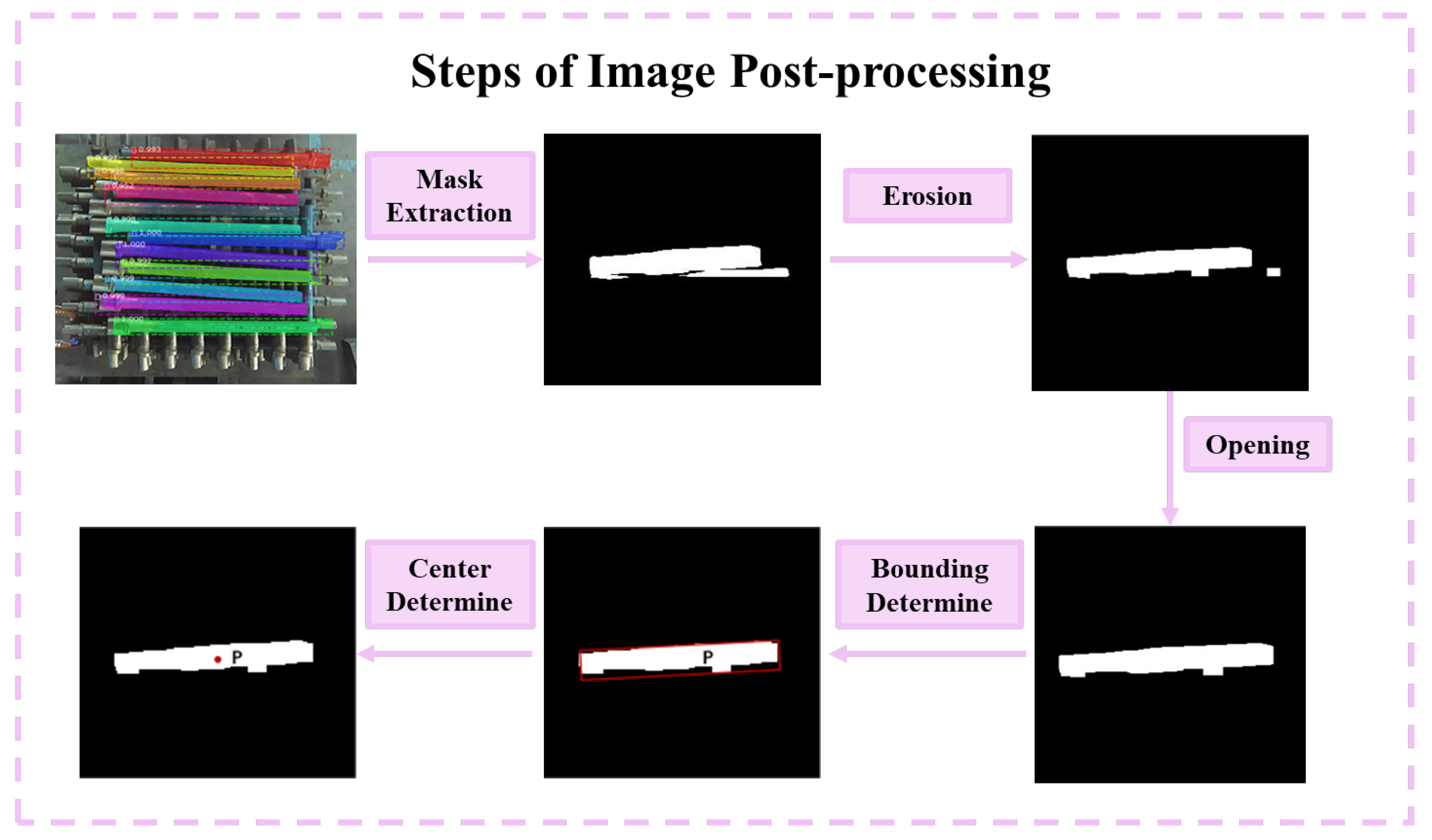
4. Depalletizing Strategy and Real-World Validation
4.1. Depalletizing Strategy
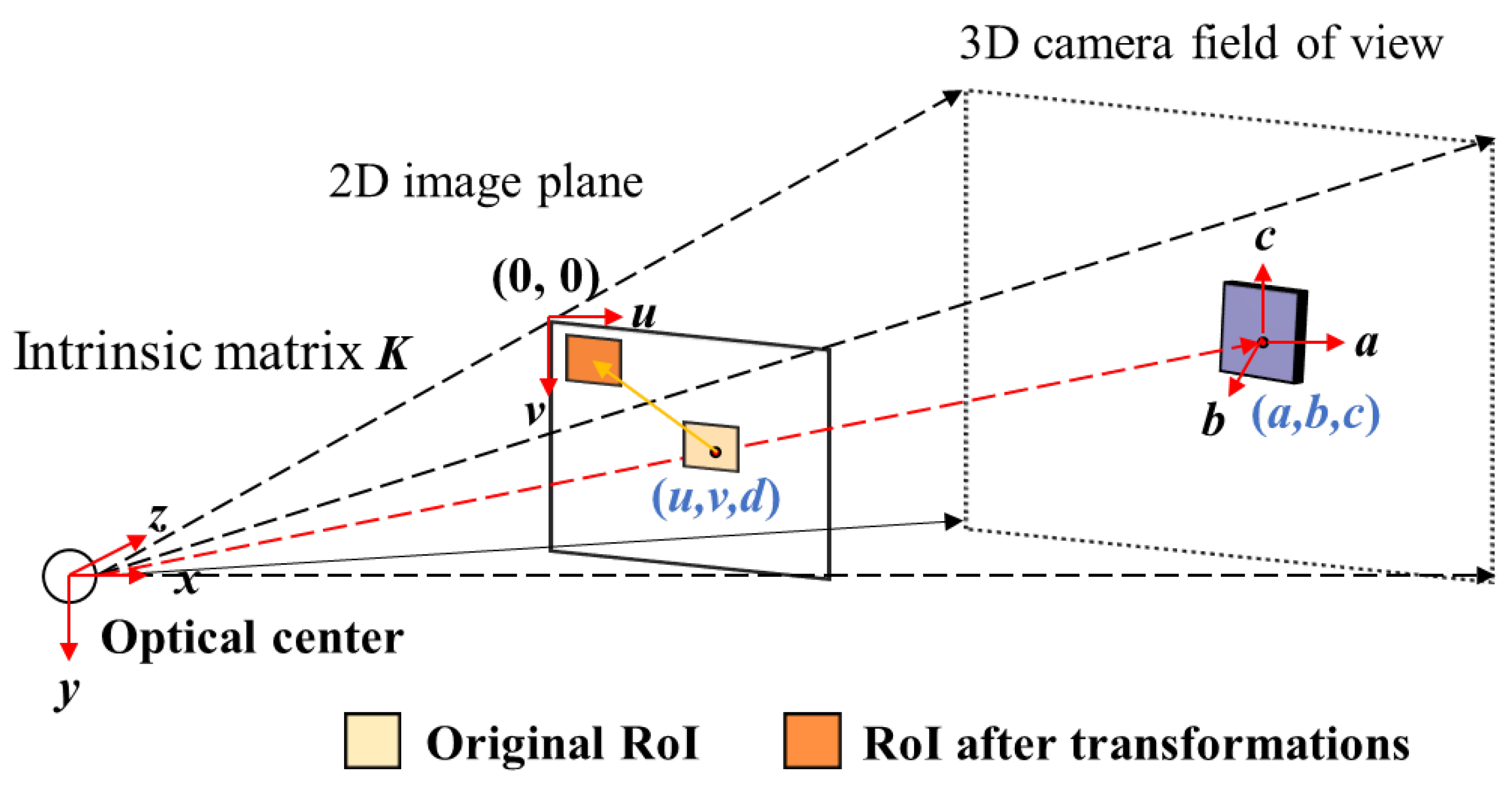
4.2. Hand–Eye Calibration
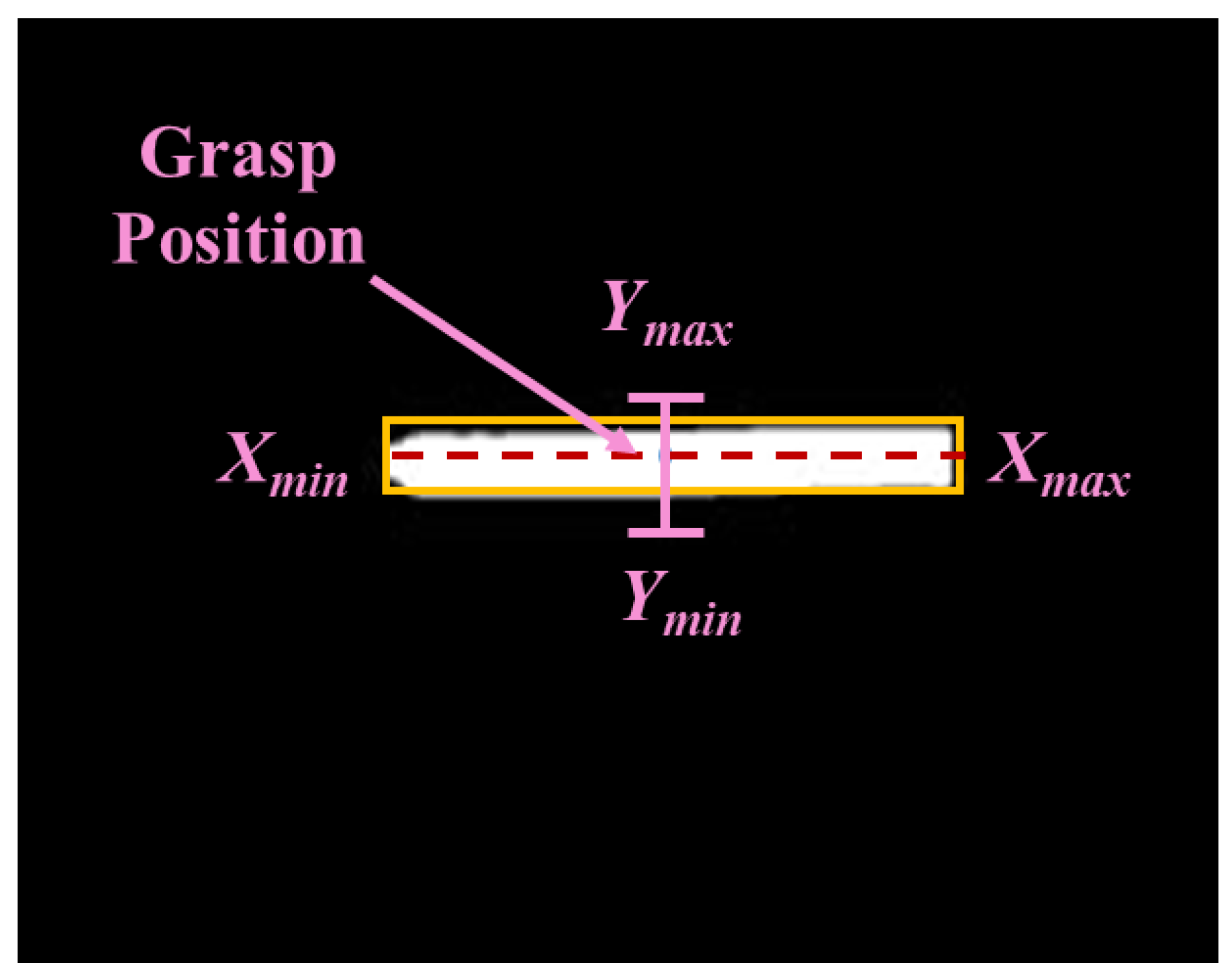
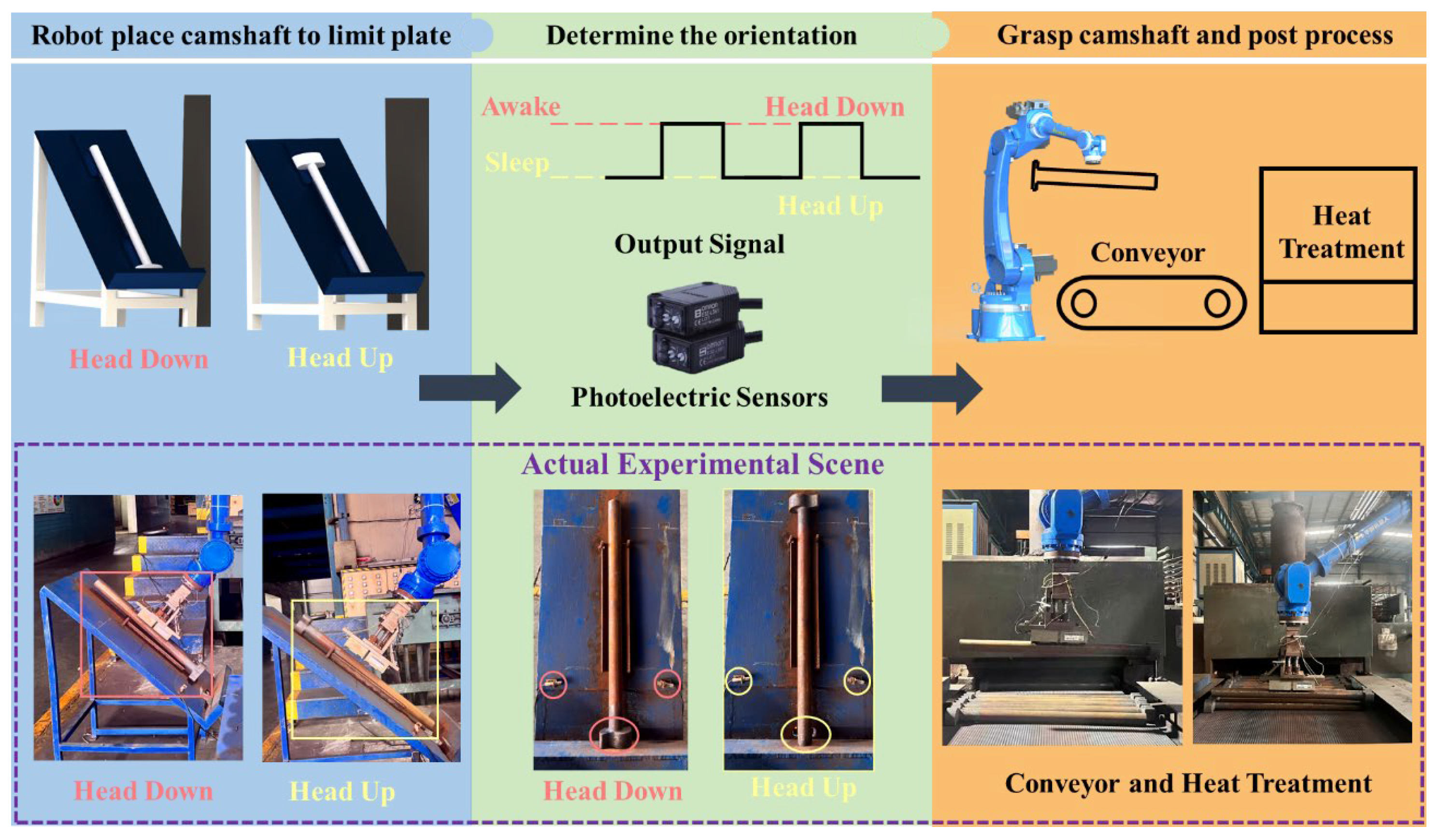
4.3. Transfer Platform for Center Point Positioning and Orientation Judgment
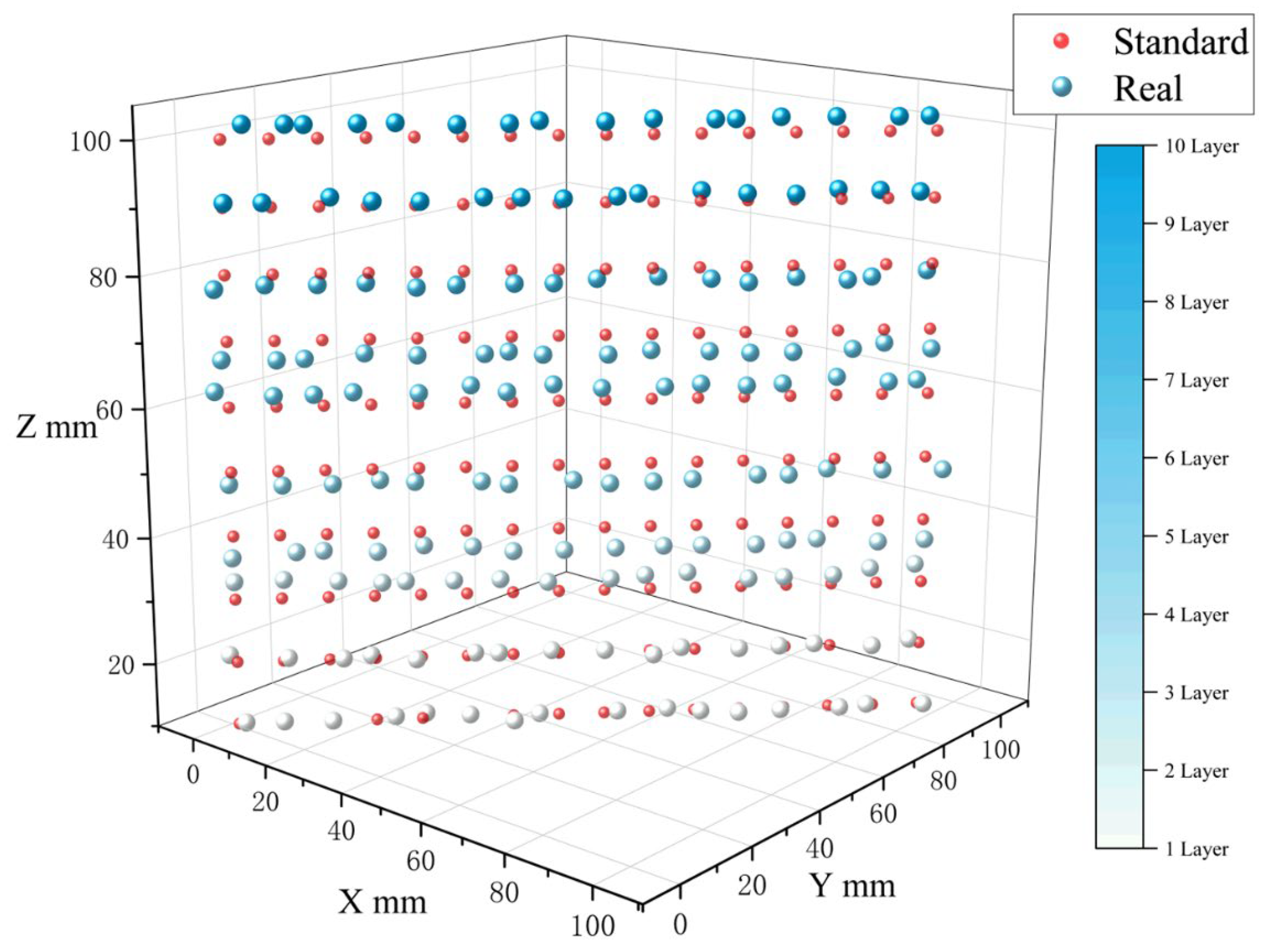
4.4. Depalletizing Experiments
5. Conclusions
- A complete RGB-D-based robotic depalletizing system is developed for irregular camshaft handling, featuring flexible magnetic adsorption and real-time orientation sensing.
- A novel instance segmentation framework, MaskNet, is proposed, which fuses RGB and depth modalities through dual-branch Vision Transformers and attention-based mechanisms, achieving high segmentation accuracy under occlusion and dense stacking.
- Real-world experiments validate the practical effectiveness of the system. The integration of hand–eye calibration and a structured grasping strategy enables accurate re-adsorption and alternating placement, achieving robust performance in complex industrial scenarios.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Stibinger, P.; Broughton, G.; Majer, F.; Rozsypalek, Z.; Wang, A.; Jindal, K.; Zhou, A.; Thakur, D.; Loianno, G.; Krajnik, T.; et al. Mobile Manipulator for Autonomous Localization, Grasping and Precise Placement of Construction Material in a Semi-Structured Environment. IEEE Robot. Autom. Lett. 2021, 6, 2595–2602. [Google Scholar] [CrossRef]
- Baldassarri, A.; Innero, G.; Di Leva, R.; Palli, G.; Carricato, M. Development of a Mobile Robotized System for Palletizing Applications. In Proceedings of the 25th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Vienna, Austria, 8–11 September 2020. [Google Scholar]
- Katsoulas, D.; Kosmopoulos, D.I. An Efficient Depalletizing System Based on 2D Range Imagery. In Proceedings of the IEEE International Conference on Robotics and Automation, Seoul, Republic of Korea, 21–26 May 2001; Volume 1, pp. 305–312. [Google Scholar]
- Nakamoto, H.; Eto, H.; Sonoura, T.; Tanaka, J.; Ogawa, A. High-Speed and Compact Depalletizing Robot Capable of Handling Packages Stacked Complicatedly. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Daejeon, Republic of Korea, 9–14 October 2016; pp. 344–349. [Google Scholar]
- Tanaka, J.; Ogawa, A.; Nakamoto, H.; Sonoura, T.; Eto, H. Suction Pad Unit Using a Bellows Pneumatic Actuator as a Support Mechanism for an End Effector of Depalletizing Robots. Robomech J. 2020, 7, 2. [Google Scholar] [CrossRef]
- Echelmeyer, W.; Kirchheim, A.; Wellbrock, E. Robotics-Logistics: Challenges for Automation of Logistic Processes. In Proceedings of the IEEE International Conference on Automation and Logistics, Qingdao, China, 1–3 September 2008; pp. 2099–2103. [Google Scholar]
- Zhang, Y.; Luo, W.; Wang, P.; Lei, X. Irregular Cigarette Package Matching Algorithm Based on Palletizing System. In Proceedings of the 2018 International Conference on Robots & Intelligent System (ICRIS), Changsha, China, 26–27 May 2018; pp. 274–278. [Google Scholar]
- Hu, J.; Li, Q.; Bai, Q. Research on Robot Grasping Based on Deep Learning for Real-Life Scenarios. Micromachines 2023, 14, 1392. [Google Scholar] [CrossRef]
- Dong, X.; Jiang, Y.; Zhao, F.; Xia, J. A Practical Multi-Stage Grasp Detection Method for Kinova Robot in Stacked Environments. Micromachines 2023, 14, 117. [Google Scholar] [CrossRef]
- Valero, S.; Martinez, J.C.; Montes, A.M.; Marín, C.; Bolaños, R.; Álvarez, D. Machine Vision-Assisted Design of End Effector Pose in Robotic Mixed Depalletizing of Heterogeneous Cargo. Sensors 2025, 25, 1137. [Google Scholar] [CrossRef] [PubMed]
- Aheritanjani, S.; Haladjian, J.; Neumaier, T.; Hodaie, Z.; Bruegge, B. 2D Orientation and Grasp Point Computation for Bin Picking in Overhaul Processes. In Proceedings of the 9th International Conference on Pattern Recognition Applications and Methods (ICPRAM), Valletta, Malta, 22–24 February 2020; pp. 395–402. [Google Scholar] [CrossRef]
- Ye, B.; Wu, Z.; He, S.; Li, H. Recognition and Robot Grasping of Disordered Workpieces with 3D Laser Line Profile Sensor. Syst. Sci. Control Eng. 2023, 11, 789–799. [Google Scholar] [CrossRef]
- Schwarz, M.; Milan, A.; Periyasamy, A.S.; Behnke, S. RGB-D Object Detection and Semantic Segmentation for Autonomous Manipulation in Clutter. Int. J. Robot. Res. 2018, 37, 437–451. [Google Scholar] [CrossRef]
- Fu, Y.; Zhang, X.; Song, H.; Liu, M. RGB-D Instance Segmentation-Based Suction Point Detection for Grasping. In Proceedings of the 2022 IEEE International Conference on Robotics and Biomimetics (ROBIO), Jinghong, China, 6–10 December 2022; pp. 1643–1650. [Google Scholar]
- Xu, W.; Cao, J.; Nie, X. The Design of a Heavy-Load Palletizing Robotic Structure for Coating Handling. In Proceedings of the International Symposium on Mechanical Engineering and Material Science (ISMEMS-16), Jeju Island, Republic of Korea, 17–19 November 2016; Atlantis Press: Dordrecht, The Netherlands, 2016; pp. 467–473. [Google Scholar]
- Zhang, L.; Mei, J.; Zhao, X.; Gong, J.; Gong, Y.; Jiang, Y.; Sheng, J.; Sun, L. Layout Analysis and Path Planning of a Robot Palletizing Production Line. In Proceedings of the IEEE International Conference on Automation and Logistics, Qingdao, China, 1–3 September 2008; pp. 2420–2425. [Google Scholar]
- Fu, K.; Dang, X.; Zhang, Q.; Peng, J. Fast UOIS: Unseen Object Instance Segmentation with Adaptive Clustering for Industrial Robotic Grasping. Actuators 2024, 13, 305. [Google Scholar] [CrossRef]
- Uhrig, J.; Rehder, E.; Fröhlich, B.; Franke, U.; Thomas, J. Box2Pix: Single-Shot Instance Segmentation by Assigning Pixels to Object Boxes. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 292–299. [Google Scholar]
- Luo, J.; Zhang, Z.; Wang, Y.; Feng, R. Robot Closed-Loop Grasping Based on Deep Visual Servoing Feature Network. Actuators 2025, 14, 25. [Google Scholar] [CrossRef]
- Kong, S.; Fowlkes, C.C. Recurrent Pixel Embedding for Instance Grouping. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9018–9028. [Google Scholar]
- Yoon, J.; Han, J.; Nguyen, T.P. Logistics Box Recognition in Robotic Industrial De-Palletising Procedure with Systematic RGB-D Image Processing Supported by Multiple Deep Learning Methods. Eng. Appl. Artif. Intell. 2023, 123, 106311. [Google Scholar] [CrossRef]
- Dai, J.; He, K.; Sun, J. Instance-Aware Semantic Segmentation via Multi-Task Network Cascades. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3150–3158. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Tan, C.; Li, L.; Yuan, L.; Wang, J. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14454–14463. [Google Scholar]
- Fang, Y.; Yang, S.; Wang, X.; Li, Y.; Wang, Q.; Lin, D. Instances as Queries. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6910–6919. [Google Scholar]
- Dong, B.; Zeng, F.; Wang, T.; Lin, Y.; Liu, W.; Luo, P. SOLQ: Segmenting Objects by Learning Queries. Adv. Neural Inf. Process. Syst. 2021, 34, 21898–21909. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT: Real-Time Instance Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- Chen, H.; Sun, K.; Tian, Z.; Shen, C.; Wang, Y.; Yuan, J. BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8573–8581. [Google Scholar]
- Wei, Y.; Liao, C.; Zhang, L.; Zhang, Q.; Shen, Y.; Zang, Y.; Li, S.; Huang, H. Enhanced Hand–Eye Coordination Control for Six-Axis Robots Using YOLOv5 with Attention Module. Actuators 2024, 13, 374. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the 31st Conference on Neural Information Processing Systems (NeurIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Mask Transformer for Universal Image Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 1290–1299. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.; Lo, W.-Y.; et al. Segment Anything Model. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–7 October 2023. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Camshaft | Weight (kg) | Length (mm) | Section Diameter (mm) | Number of Layers |
|---|---|---|---|---|
| Short axis | 10–12 | 500–600 | 42.5–44.5 | 8–10 |
| Medium axis | 12–14 | 600–700 | 43–45 | 8–10 |
| Long axis | 14–16 | 700–800 | 42–44 | 10–12 |
| Product Name | Model | Main Specifications |
|---|---|---|
| Upper computer | - | RTX 3060 GPU |
| RGB-D camera | Percipio FM811(Percipio, Shanghai, China) | Accuracy: 4.44 mm (XY)/8.23 mm (Z) @ 2000 mm |
| Industrial robots | HSR-JR650(Huashu Robot, Foshan, China) | Repeatability: ±0.08 mm, Payload: 50 kg |
| end effector suction | Electromagnet | Maximum Suction Force: 50 kg |
| Transfer platform | - | - |
| Model | mAP@0.5 | F1-Score (IoU@0.6) | FPS | Deployment Difficulty | Real-Time Suitable |
|---|---|---|---|---|---|
| MaskNet | 0.980 | 0.975 | ~35 | Low | Yes |
| YOLO 11 | 0.94 | 0.86 | ~45 | Low | Yes |
| Mask2Former-S [33] | 0.990 | 0.965 | ~8 | Medium | No |
| SAM-B [34] | 0.994 | 0.970 | ~6 | High | No |
| Experiment | A (ViT + URD) | B (Fusion) | B1 (Add) | B2 (Concat) | C (DAN) | P | R | F1 |
|---|---|---|---|---|---|---|---|---|
| 1 | ✓ | ✓ | ✗ | ✗ | ✓ | 0.980 | 0.971 | 0.975 |
| 2 | ✗ | ✓ | ✗ | ✗ | ✓ | 0.890 | 0.865 | 0.843 |
| 3 | ✓ | ✗ | ✓ | ✗ | ✓ | 0.847 | 0.862 | 0.854 |
| 4 | ✓ | ✗ | ✗ | ✓ | ✓ | 0.832 | 0.854 | 0.843 |
| 5 | ✓ | ✓ | ✗ | ✗ | ✗ | 0.949 | 0.936 | 0.942 |
| Length of Camshaft | Quantity of Grasps | Success Rate | Accumulated Time of Manual Handling | Accumulated Time of Robot Transportation |
|---|---|---|---|---|
| 600 mm | 160 | 98% | 120 min | 80 min |
| 700 mm | 160 | 98% | 110 min | 80 min |
| 800 mm | 160 | 96% | 130 min | 80 min |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, R.; Yang, P. An RGB-D Vision-Guided Robotic Depalletizing System for Irregular Camshafts with Transformer-Based Instance Segmentation and Flexible Magnetic Gripper. Actuators 2025, 14, 370. https://doi.org/10.3390/act14080370
Wu R, Yang P. An RGB-D Vision-Guided Robotic Depalletizing System for Irregular Camshafts with Transformer-Based Instance Segmentation and Flexible Magnetic Gripper. Actuators. 2025; 14(8):370. https://doi.org/10.3390/act14080370
Chicago/Turabian StyleWu, Runxi, and Ping Yang. 2025. "An RGB-D Vision-Guided Robotic Depalletizing System for Irregular Camshafts with Transformer-Based Instance Segmentation and Flexible Magnetic Gripper" Actuators 14, no. 8: 370. https://doi.org/10.3390/act14080370
APA StyleWu, R., & Yang, P. (2025). An RGB-D Vision-Guided Robotic Depalletizing System for Irregular Camshafts with Transformer-Based Instance Segmentation and Flexible Magnetic Gripper. Actuators, 14(8), 370. https://doi.org/10.3390/act14080370