
Deep Learning-Based Speech Recognition and LabVIEW Integration for Intelligent Mobile Robot Control

 ,
,  ,
,  , and
, and
Abstract
1. Introduction
1.1. Research Motivation
1.2. Research Background
1.2.1. Voice Recognition Technology
1.2.2. Mobile Control Systems
1.2.3. LabVIEW
1.3. Research Objectives
- (a)
- To develop an AI model for voice recognition and optimize its speed and accuracy;
- (b)
- To design a robotic mobile mechanism and control program;
- (c)
- To integrate the voice recognition model with the robotic control system;
- (d)
- To test and evaluate the results, identifying strengths, weaknesses, and potential improvements.
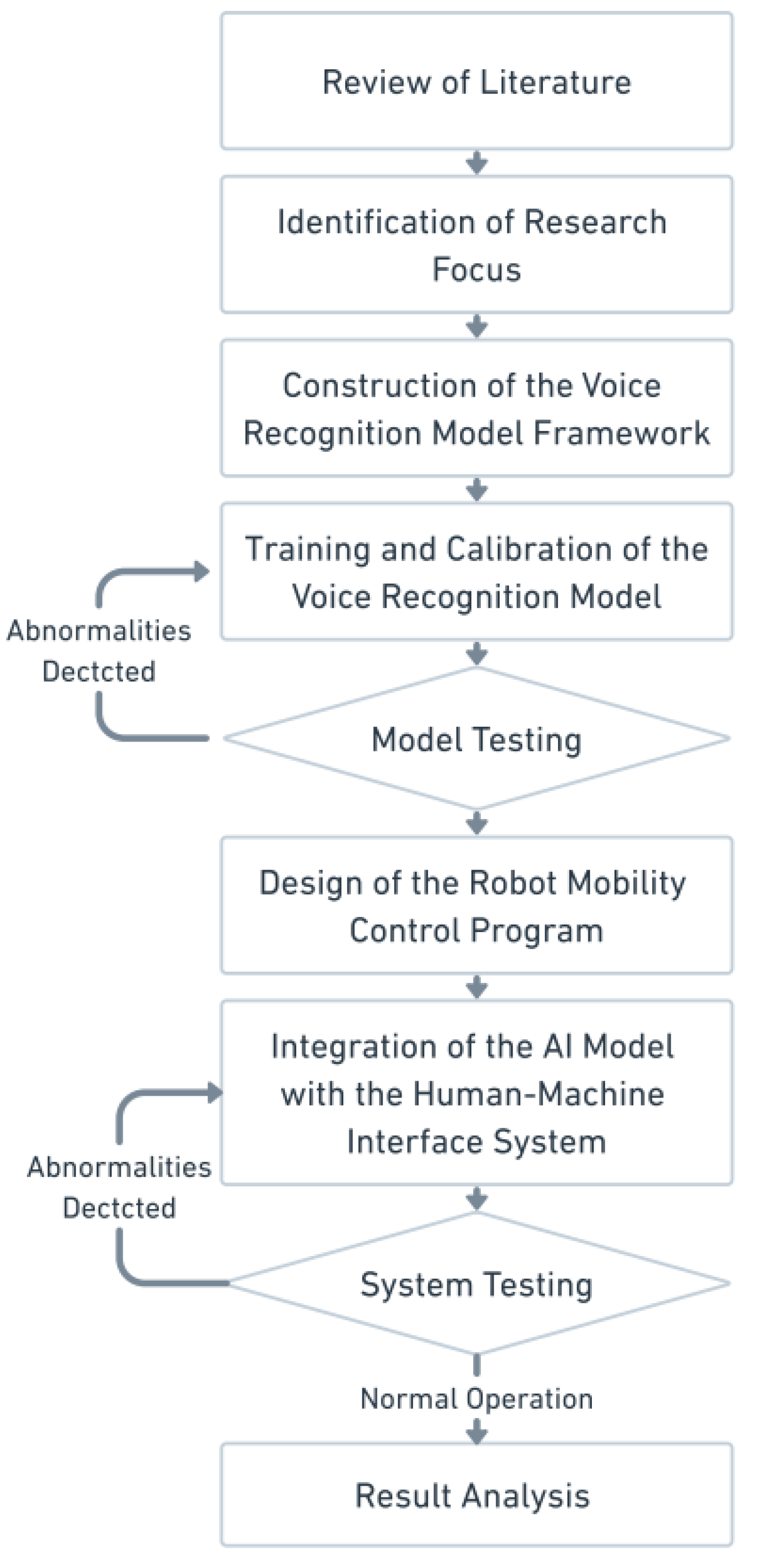
1.4. Research Methods and Procedures
2. Literature Review
2.1. Development of Voice Recognition Technology
2.1.1. Early Research and Techniques
2.1.2. The Era of Machine Learning
2.2. Applications of Deep Learning in Voice Recognition
2.2.1. Deep Neural Networks (DNNs)
2.2.2. Convolutional Neural Networks (CNNs)
2.2.3. Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM)
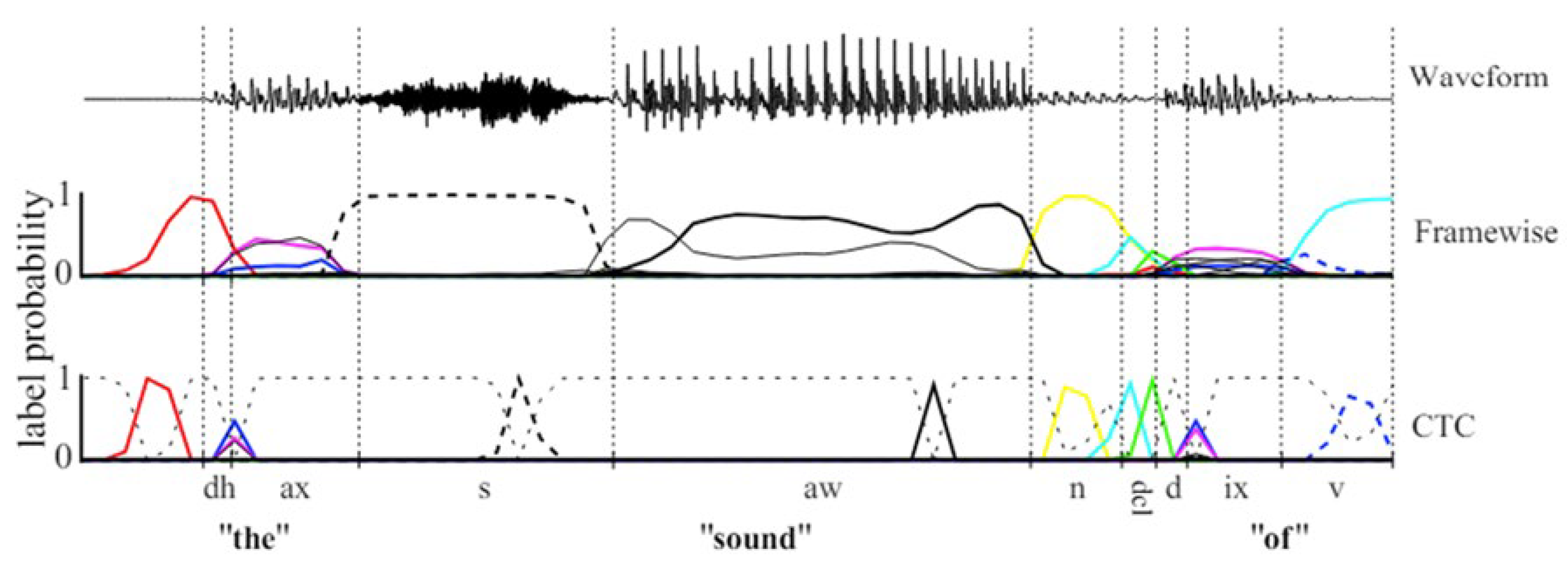
2.3. Connectionist Temporal Classification (CTC)
2.3.1. Basic Principles
2.3.2. Loss Calculation
2.3.3. Application Example
2.4. The DeepSpeech2 Model
3. System Architecture
3.1. Speech Recognition System
3.1.1. Front-End Processing
- (a)
- Omnidirectional
- (b)
- Cardioid Directionality
- (c)
- Bidirectional
- (d)
- Stereo
3.1.2. Speech Databases
- (a)
- Text Annotations: Each audio file is accompanied by corresponding text annotations, which include the transcribed text of the audiobook passages;
- (b)
- Audio Format: All audio files are 16 kHz mono WAV files;
- (c)
- Speaker Diversity: The dataset includes recordings from multiple speakers, with varying backgrounds and accents, helping to train models with better generalization capabilities.
3.1.3. Data Preprocessing
- (a)
- Audio Processing:
- (b)
- Text Processing:
- (c)
- Sequence Padding:
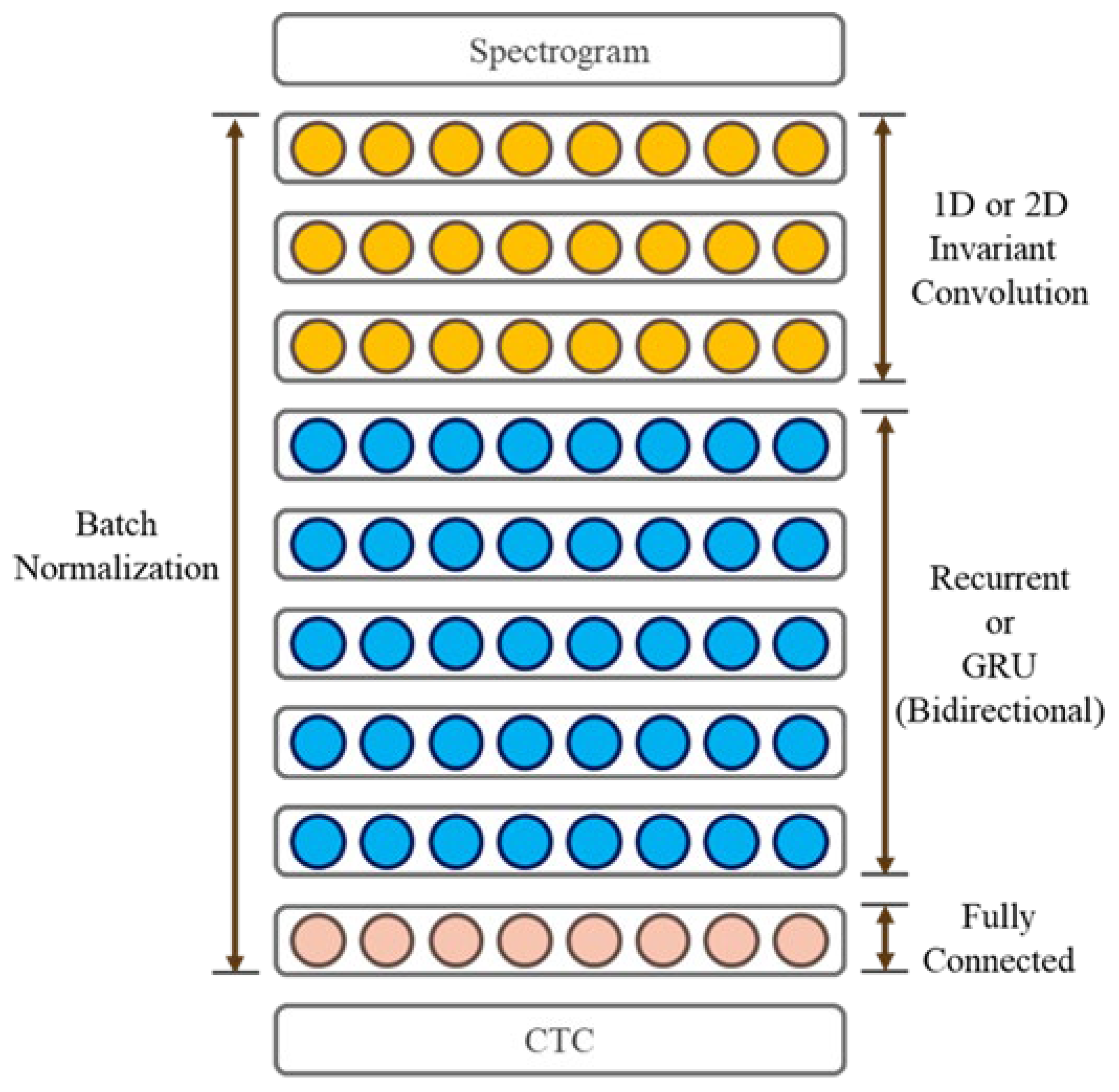
3.1.4. Model Training and Inference
- (a)
- Convolutional Layer (CNN): Responsible for capturing local features of the audio signal and reducing data size to decrease the computational burden of subsequent layers.
- (b)
- Bidirectional Recurrent Neural Networks (RNNs): These layers handle “memory and comprehension” and use Gated Recurrent Units (GRUs) to capture long-term dependencies and contextual information in speech, enabling the model to understand the meaning of entire sentences.
- (c)
- Fully Connected Layer (FC): Transforms the RNN output into a probability distribution for each character, essentially translating the speech signal into text.
- (d)
- CTC Loss Function: This function allows the model to learn how to align audio and text sequences. Even if their lengths are not the same, the model can directly learn from unaligned audio-text pairs.
- (e)
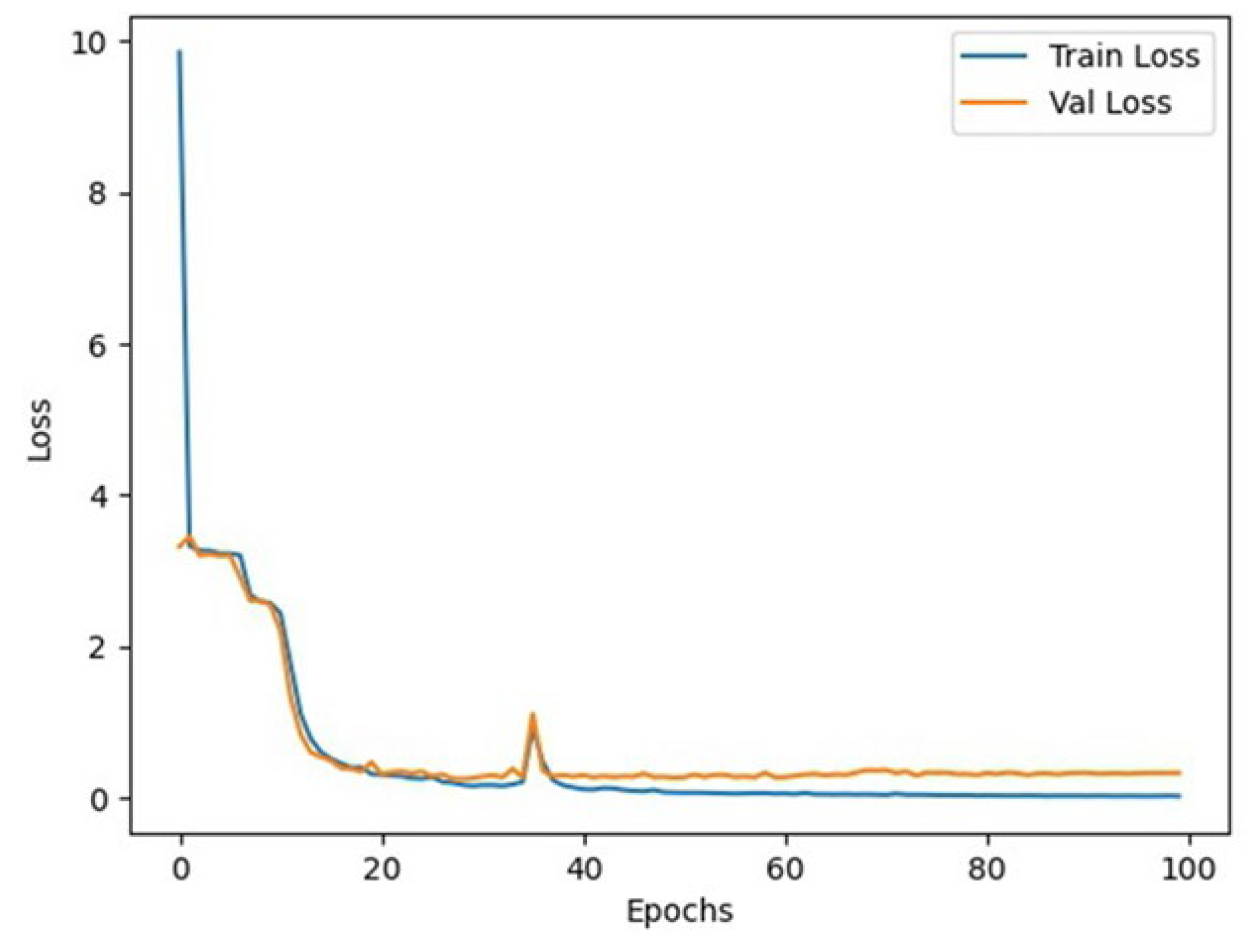
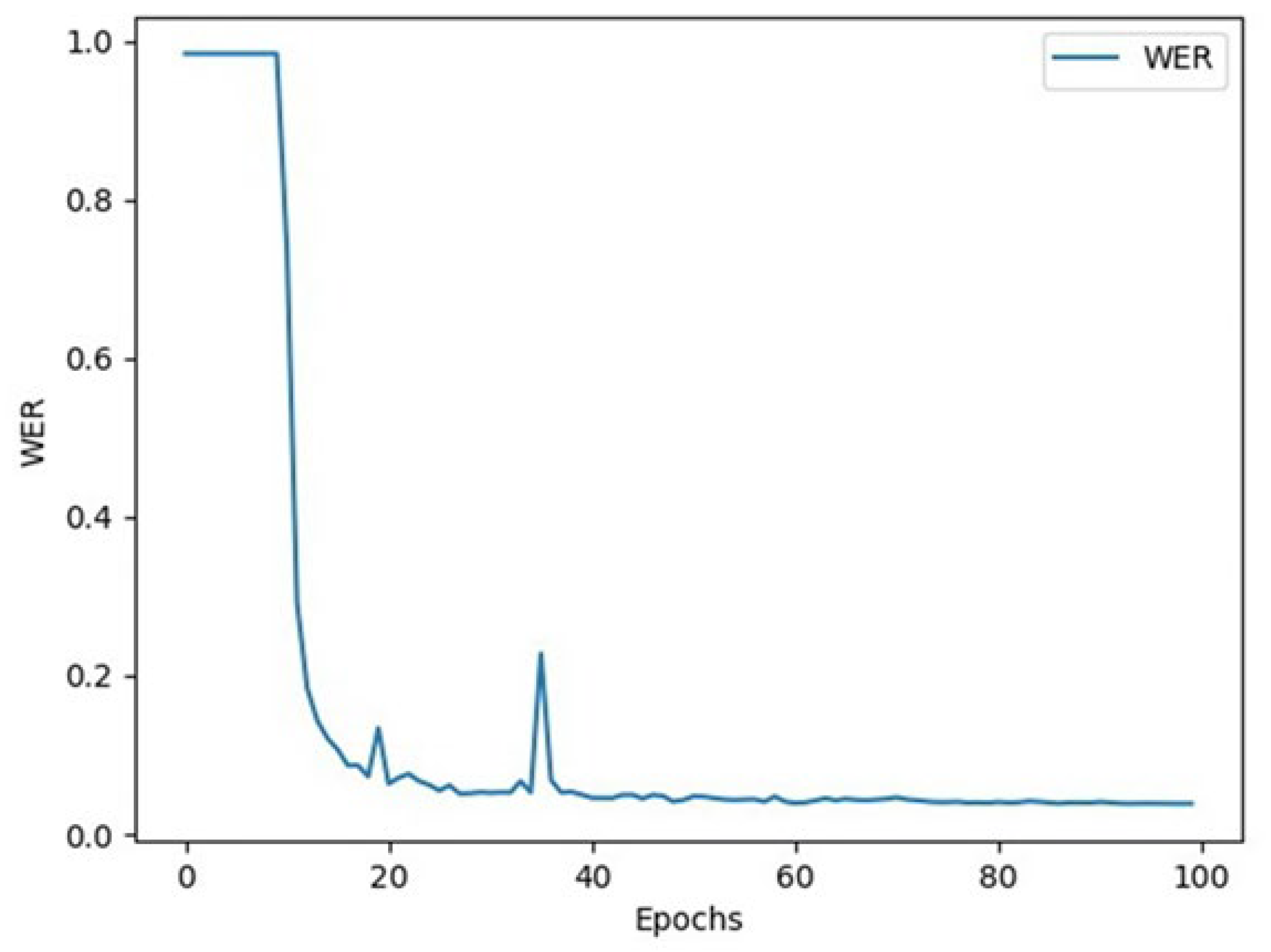
- Learning Rate: The learning rate is dynamically adjusted using the OneCycleLR scheduler in PyTorch v2.2.0. This scheduler gradually increases the learning rate to a maximum value and then decreases it to a very low value (Refer to Figure 6). This strategy helps the model quickly explore the parameter space while stabilizing at a good solution in the later stages, accelerating convergence and improving final model performance.
3.1.5. Post-Processing and Output
- (a)
- Post-processing
- Decoding: Greedy decoding is used to convert the probability distribution output by the model into the most likely character sequence. Greedy decoding selects the most probable character at each time step, quickly generating the most likely character sequence.
- Evaluation Metrics: Word Error Rate (WER) is used to evaluate model performance. This metric measures the difference between the model output and the ground truth label.
- (b)
- Result Output
3.2. Mobile Control Robot
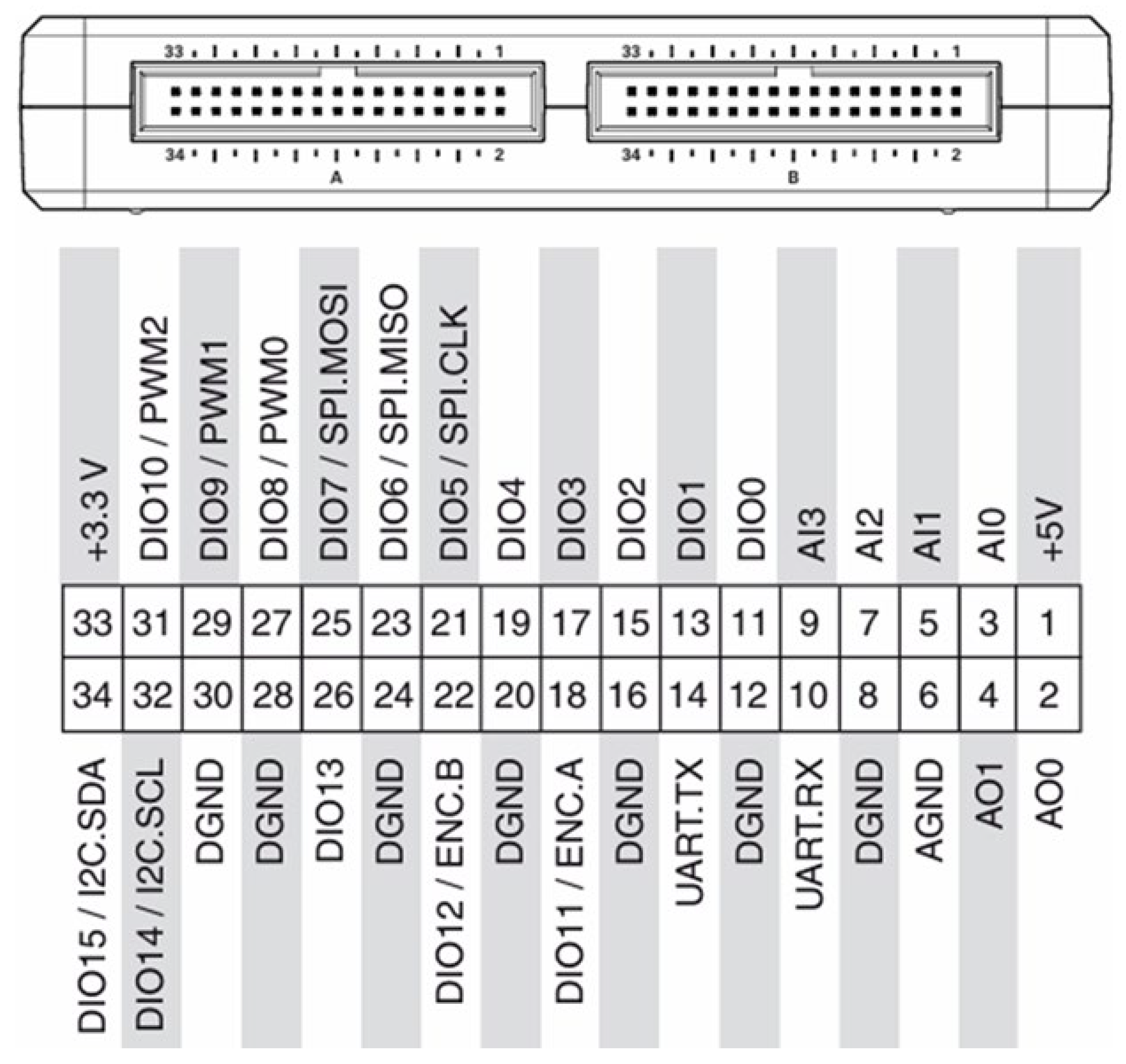
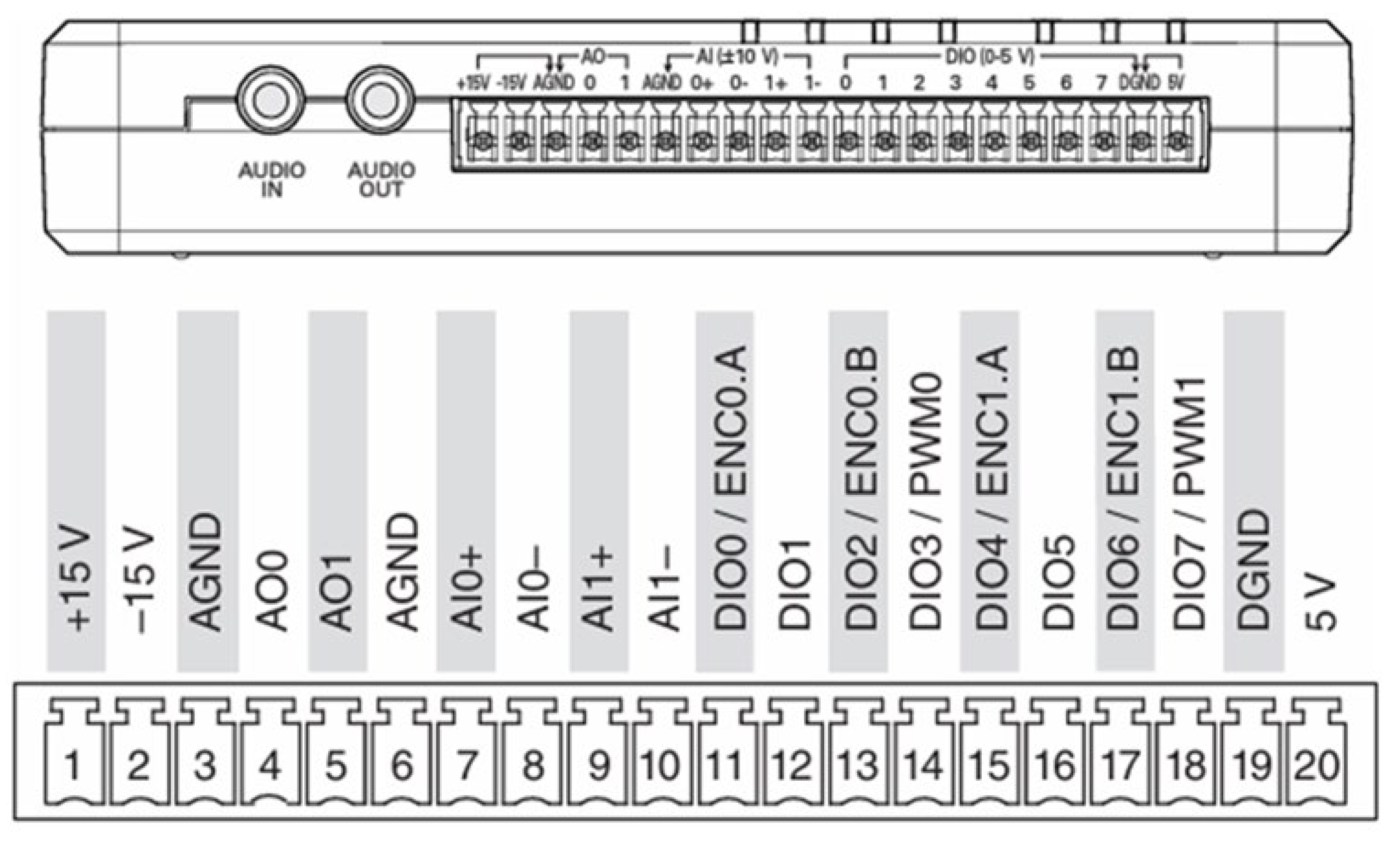
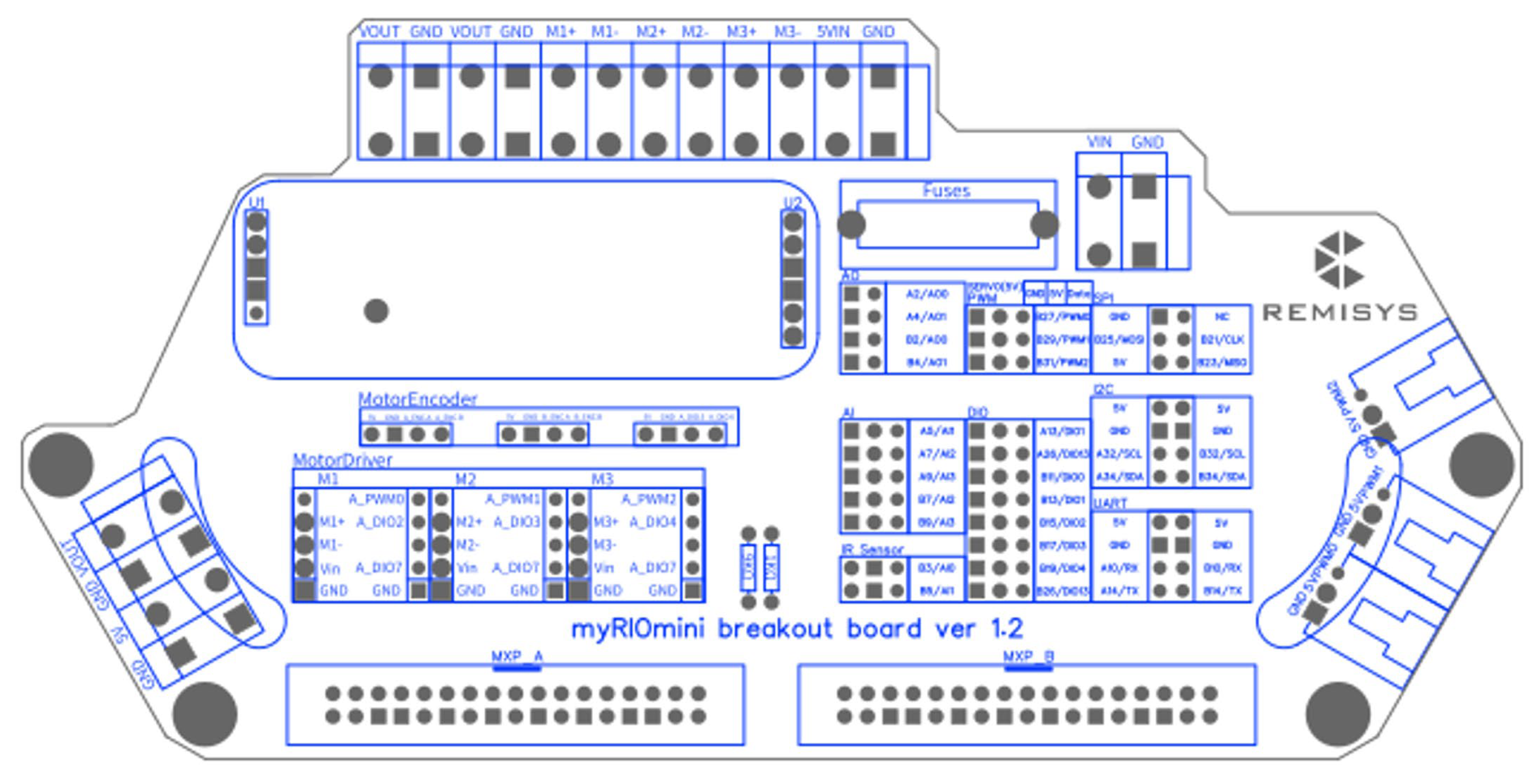
3.2.1. Mobile Robot Hardware Architecture
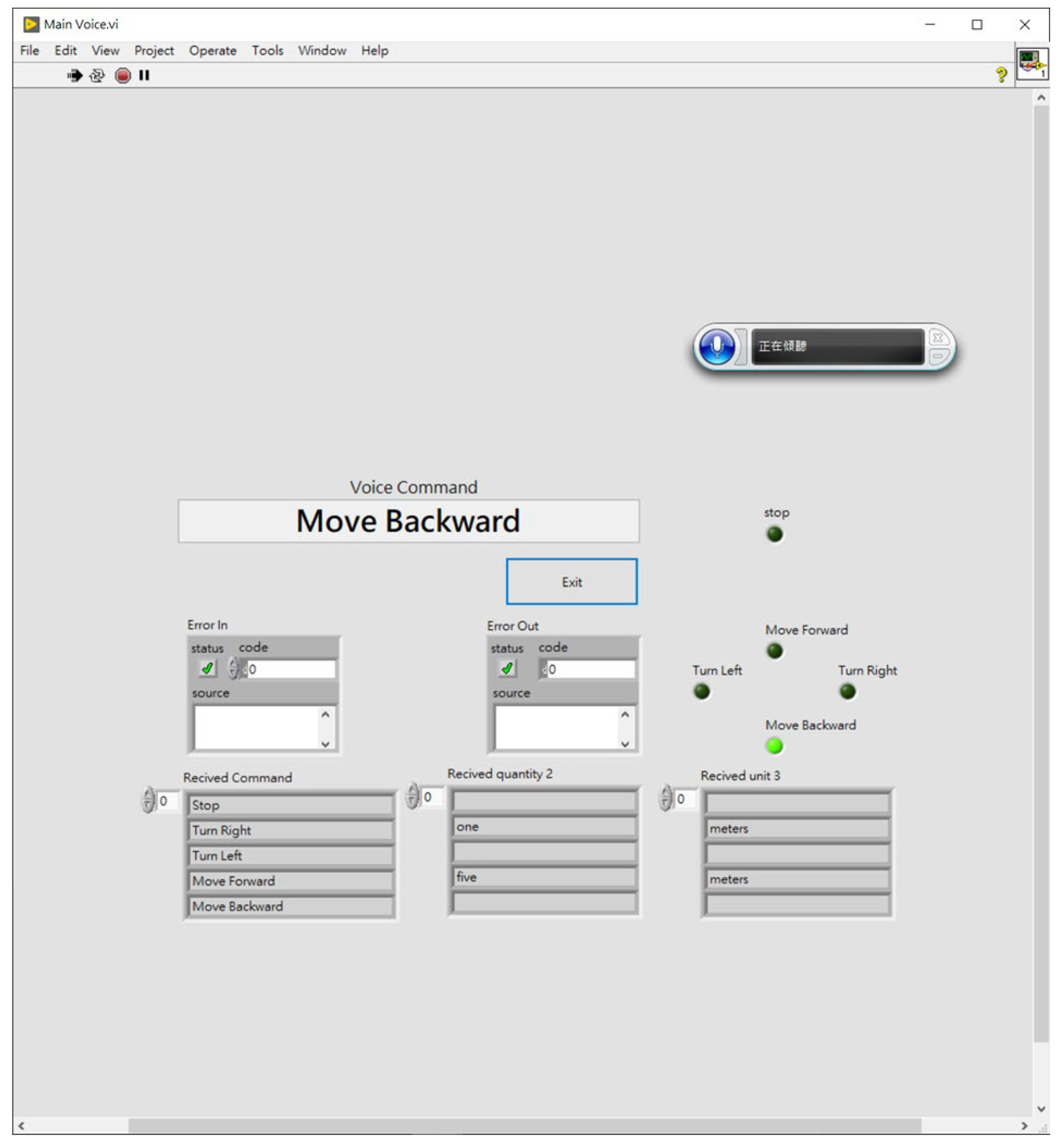
3.2.2. Mobile Robot Control Program
- (a)
- Setting up the LabVIEW Environment
- (b)
- Movement Program
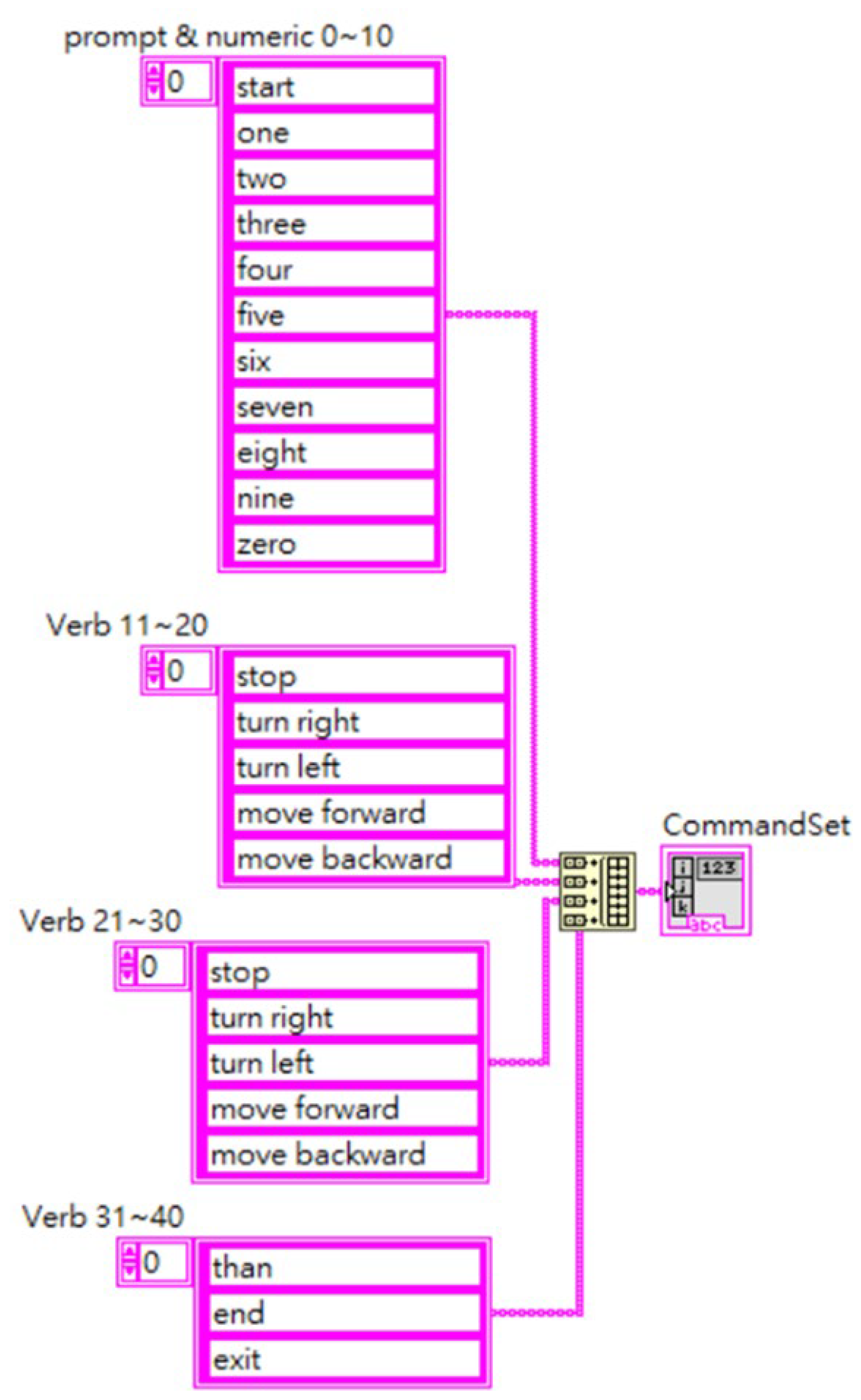
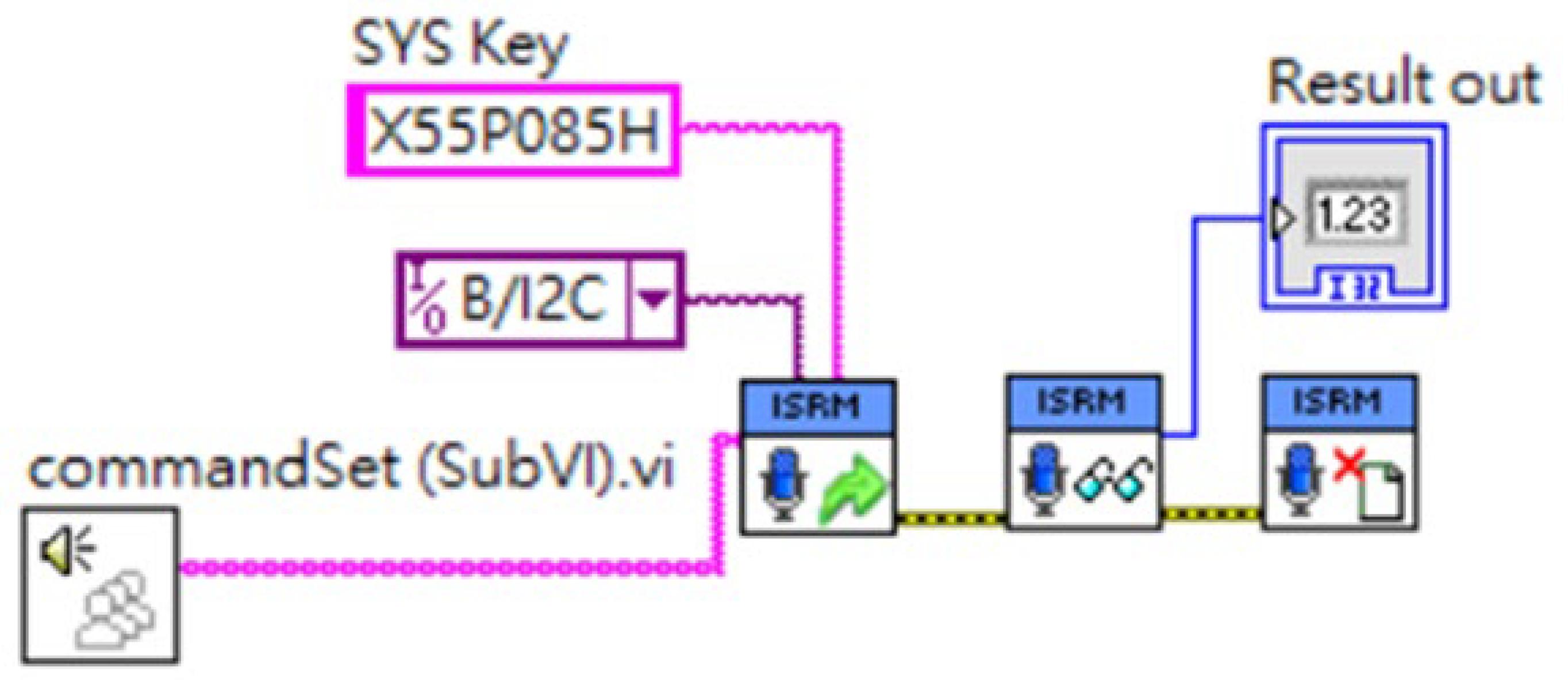
3.3. LabVIEW-Based Integration of the Speech Recognition Model with the Mobile Control System
4. Conclusions and Future Outlook
4.1. Conclusions
4.2. Future Outlook
- Technical Aspects
- 2.
- User Experience Aspects
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yao, K.-C.; Huang, W.-T.; Chen, T.-Y.; Wu, C.-C.; Ho, W.-S. Establishing an Intelligent Emotion Analysis System for Long-Term Care Application Based on LabVIEW. Sustainability 2022, 14, 8932. [Google Scholar] [CrossRef]
- Chen, Q.; Guo, Z.; Zhu, D.; Yu, H. The research of application of hidden Markov model in the speech recognition. In Proceedings of the 2021 IEEE International Conference on Power, Intelligent Computing and Systems (ICPICS), Shenyang, China, 29–31 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 202–206. [Google Scholar] [CrossRef]
- Jiang, W. A Hidden Markov Model-Based Performance Recognition System for Marching Wind Bands. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 420–431. [Google Scholar] [CrossRef]
- Zarrouk, E.; Ben Ayed, Y.; Gargouri, F. Hybrid continuous speech recognition systems by HMM, MLP and SVM: A comparative study. Int. J. Speech Technol. 2014, 17, 223–233. [Google Scholar] [CrossRef]
- Woodland, P.C.; Povey, D. Large scale discriminative training of hidden Markov models for speech recognition. Comput. Speech Lang. 2002, 16, 25–47. [Google Scholar] [CrossRef]
- Iwana, B.K.; Frinken, V.; Uchida, S. DTW-NN: A novel neural network for time series recognition using dynamic alignment between inputs and weights. Knowl. Based Syst. 2020, 188, 104971. [Google Scholar] [CrossRef]
- Ismail, A.; Abdlerazek, S.; El-Henawy, I.M. Development of smart healthcare system based on speech recognition using support vector machine and dynamic time warping. Sustainability 2020, 12, 2403. [Google Scholar] [CrossRef]
- Sood, M.; Jain, S. Speech recognition employing mfcc and dynamic time warping algorithm. In Innovations in Information and Communication Technologies (IICT-2020), Proceedings of the International Conference on ICRIHE-2020, Delhi, India, 14–15 February 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 235–242. [Google Scholar] [CrossRef]
- Al-Zakarya, M.A.; Al-Irhaim, Y.F. Unsupervised and Semi-Supervised Speech Recognition System: A Review. AL-Rafidain J. Comput. Sci. Math. 2023, 17, 34–42. [Google Scholar] [CrossRef]
- Mohammed, T.S.; Aljebory, K.M.; Rasheed, M.A.A.; Al-Ani, M.S.; Sagheer, A.M. Analysis of Methods and Techniques Used for Speaker Identification, Recognition, and Verification: A Study on Quarter-Century Research Outcomes. Iraqi J. Sci. 2021, 62, 3256–3281. [Google Scholar] [CrossRef]
- Rajarajeswari, P.; Anwar Beg, O. An executable method for an intelligent speech and call recognition system using a machine learning-based approach. J. Mech. Med. Biol. 2021, 21, 2150055. [Google Scholar] [CrossRef]
- O’Shaughnessy, D. Recognition and processing of speech signals using neural networks. Circuits Syst. Signal Process. 2019, 38, 3454–3481. [Google Scholar] [CrossRef]
- Prabhavalkar, R.; Hori, T.; Sainath, T.N.; Schlüter, R.; Watanabe, S. End-to-end speech recognition: A survey. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 32, 325–351. [Google Scholar] [CrossRef]
- Sainath, T.N.; Ramabhadran, B.; Nahamoo, D.; Kanevsky, D.; Van Compernolle, D.; Demuynck, K.; Gemmeke, J.F.; Bellegarda, J.R.; Sundaram, S. Exemplar-based processing for speech recognition: An overview. IEEE Signal Process. Mag. 2012, 29, 98–113. [Google Scholar] [CrossRef]
- Zhang, Z.; Cummins, N.; Schuller, B. Advanced data exploitation in speech analysis: An overview. IEEE Signal Process. Mag. 2017, 34, 107–129. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional neural networks for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef]
- Dahl, G.E.; Sainath, T.N.; Hinton, G.E. Improving deep neural networks for LVCSR using rectified linear units and dropout. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; IEEE: Piscataway, NJ, USA; pp. 8609–8613. [Google Scholar] [CrossRef]
- Sainath, T.N.; Parada, C. Convolutional neural networks for small-footprint keyword spotting. In Proceedings of the Interspeech, Dresden, Germany, 6–10 September 2015; pp. 1478–1482. Available online: https://www.isca-archive.org/interspeech_2015/sainath15b_interspeech.pdf (accessed on 12 May 2025).
- Abotaleb, M.; Dutta, P.K. Optimizing Long Short-Term Memory Networks for Univariate Time Series Forecasting: A Comprehensive Guide. In Hybrid Information Systems: Non-Linear Optimization Strategies with Artificial Intelligence; De Gruyter: Berlin, Germany, 2024; p. 427. [Google Scholar] [CrossRef]
- Bharadiya, J.P. Exploring the use of recurrent neural networks for time series forecasting. Int. J. Innov. Sci. Res. Technol. 2023, 8, 2023–2027. [Google Scholar] [CrossRef]
- Mienye, I.D.; Swart, T.G.; Obaido, G. Recurrent Neural Networks: A Comprehensive Review of Architectures, Variants, and Applications. Information 2024, 15, 517. [Google Scholar] [CrossRef]
- Weerakody, P.B.; Wong, K.W.; Wang, G.; Ela, W. A review of irregular time series data handling with gated recurrent neural networks. Neurocomputing 2021, 441, 161–178. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; IEEE: Piscataway, NJ, USA; pp. 6645–6649. [Google Scholar] [CrossRef]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 173–182. Available online: http://proceedings.mlr.press/v48/amodei16.pdf (accessed on 12 May 2025).
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 5206–5210. [Google Scholar] [CrossRef]
- Zhang, C.; Yu, T.; Hansen, J.H. Microphone array processing for distance speech capture: A probe study on whisper speech detection. In Proceedings of the 2010 Conference Record of the Forty Fourth Asilomar Conference on Signals, Systems and Computers, Pacific Grobe, CA, USA, 7–10 November 2010; IEEE: Piscataway, NJ, USA, 2011; pp. 1707–1710. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Name | Duration | Description |
|---|---|---|---|
| Training Data | train-clean-100 | 100 h | High-quality recordings, low noise |
| Training Data | train-clean-360 | 360 h | High-quality recordings, low noise |
| Training Data | train-other-500 | 500 h | Lower-quality recordings, more noise |
| Validation Data | dev-clean | 5.4 h | High-quality recordings, low noise |
| Validation Data | dev-other | 5.3 h | Lower-quality recordings, more noise |
| Test Data | test-clean | 5.4 h | High-quality recordings, low noise |
| Test Data | test-other | 5.1 h | Lower-quality recordings, more noise |
| Test Scenario | TP | FP | FN | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|
| Quiet Environment | 95 | 2 | 5 | 97.94% | 95.00% | 96.45% |
| Indoor Background Noise | 87 | 5 | 13 | 94.57% | 87.00% | 90.62% |
| Outdoor Noise | 78 | 10 | 22 | 88.64% | 78.00% | 82.98% |
| Multi-Speaker Background | 72 | 8 | 28 | 90.00% | 72.00% | 80.00% |
| Mechanical Noise | 65 | 12 | 35 | 84.42% | 65.00% | 73.45% |
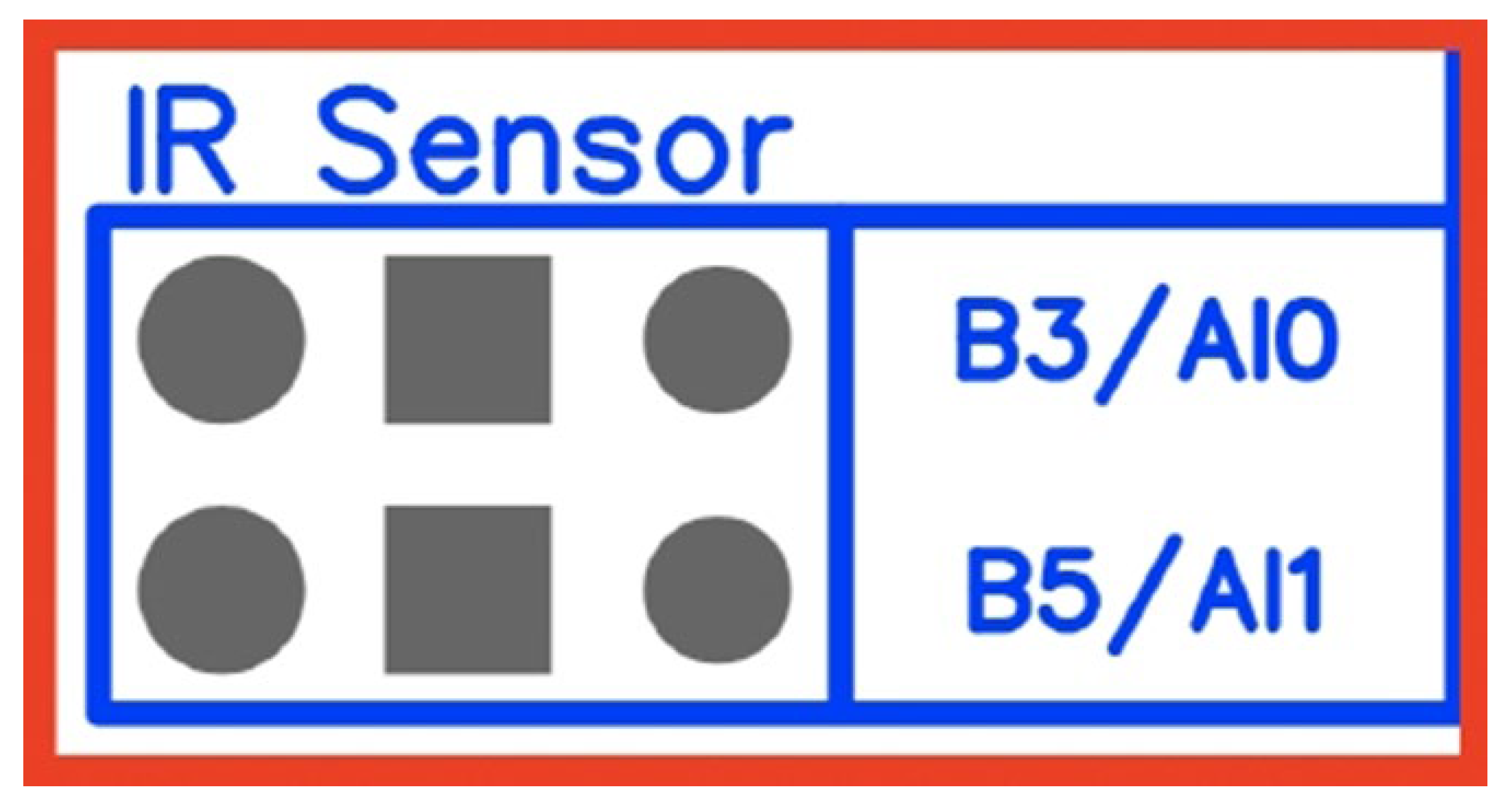
| Sensor Position | Analog Input |
|---|---|
| Left | B_AI0 |
| Right | B_AI1 |
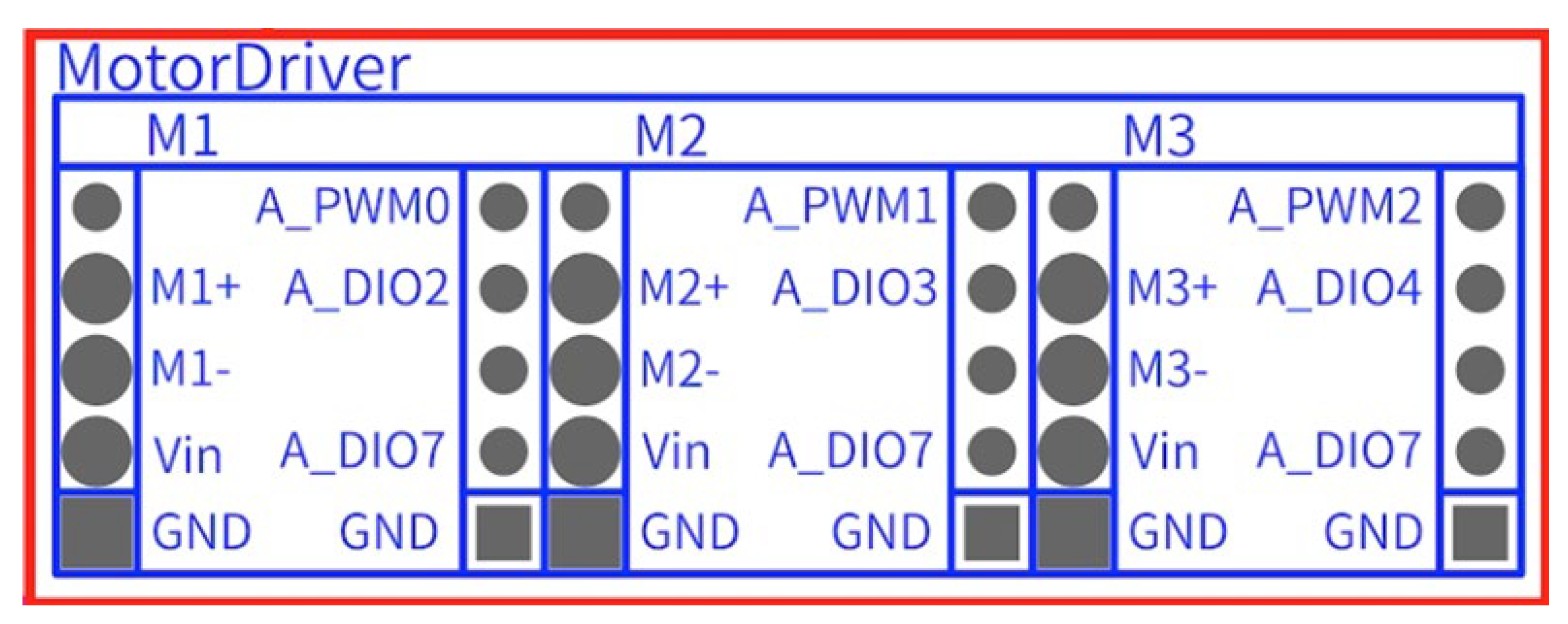
| Motor Number | PWM | DIR | ENA |
|---|---|---|---|
| M1 (A) | A_PWM0 | A_DIO2 | A_DIO7 |
| M2 (B) | A_PWM1 | A_DIO3 | A_DIO7 |
| M3 (C) | A_PWM2 | A_DIO4 | A_DIO7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, K.-C.; Huang, W.-T.; Hsieh, H.-H.; Chen, T.-Y.; Ho, W.-S.; Fang, J.-S.; Huang, W.-L. Deep Learning-Based Speech Recognition and LabVIEW Integration for Intelligent Mobile Robot Control. Actuators 2025, 14, 249. https://doi.org/10.3390/act14050249
Yao K-C, Huang W-T, Hsieh H-H, Chen T-Y, Ho W-S, Fang J-S, Huang W-L. Deep Learning-Based Speech Recognition and LabVIEW Integration for Intelligent Mobile Robot Control. Actuators. 2025; 14(5):249. https://doi.org/10.3390/act14050249
Chicago/Turabian StyleYao, Kai-Chao, Wei-Tzer Huang, Hsi-Huang Hsieh, Teng-Yu Chen, Wei-Sho Ho, Jiunn-Shiou Fang, and Wei-Lun Huang. 2025. "Deep Learning-Based Speech Recognition and LabVIEW Integration for Intelligent Mobile Robot Control" Actuators 14, no. 5: 249. https://doi.org/10.3390/act14050249
APA StyleYao, K.-C., Huang, W.-T., Hsieh, H.-H., Chen, T.-Y., Ho, W.-S., Fang, J.-S., & Huang, W.-L. (2025). Deep Learning-Based Speech Recognition and LabVIEW Integration for Intelligent Mobile Robot Control. Actuators, 14(5), 249. https://doi.org/10.3390/act14050249