2.4.2. Improve the Trajectory Optimization of Particle Swarm Optimization
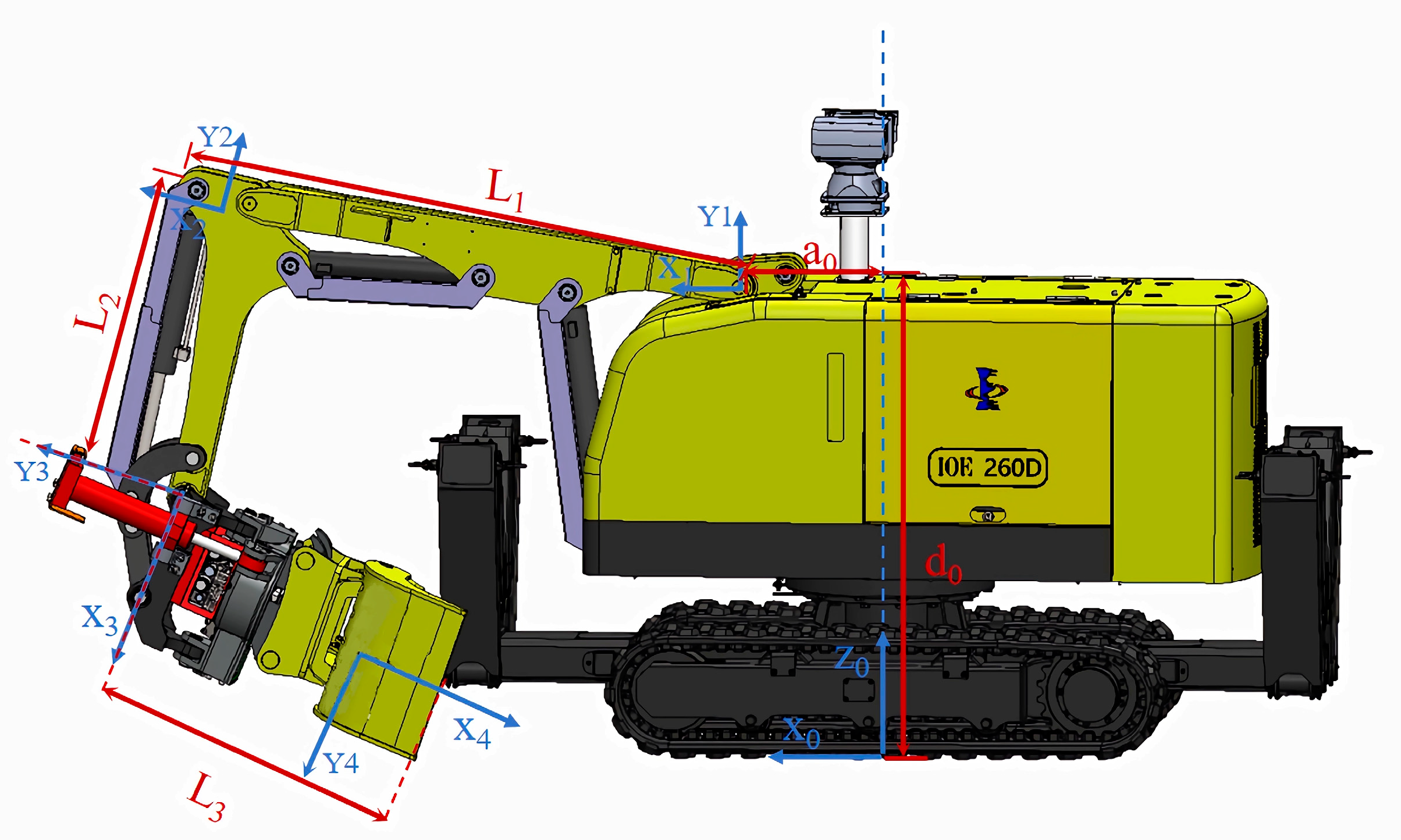
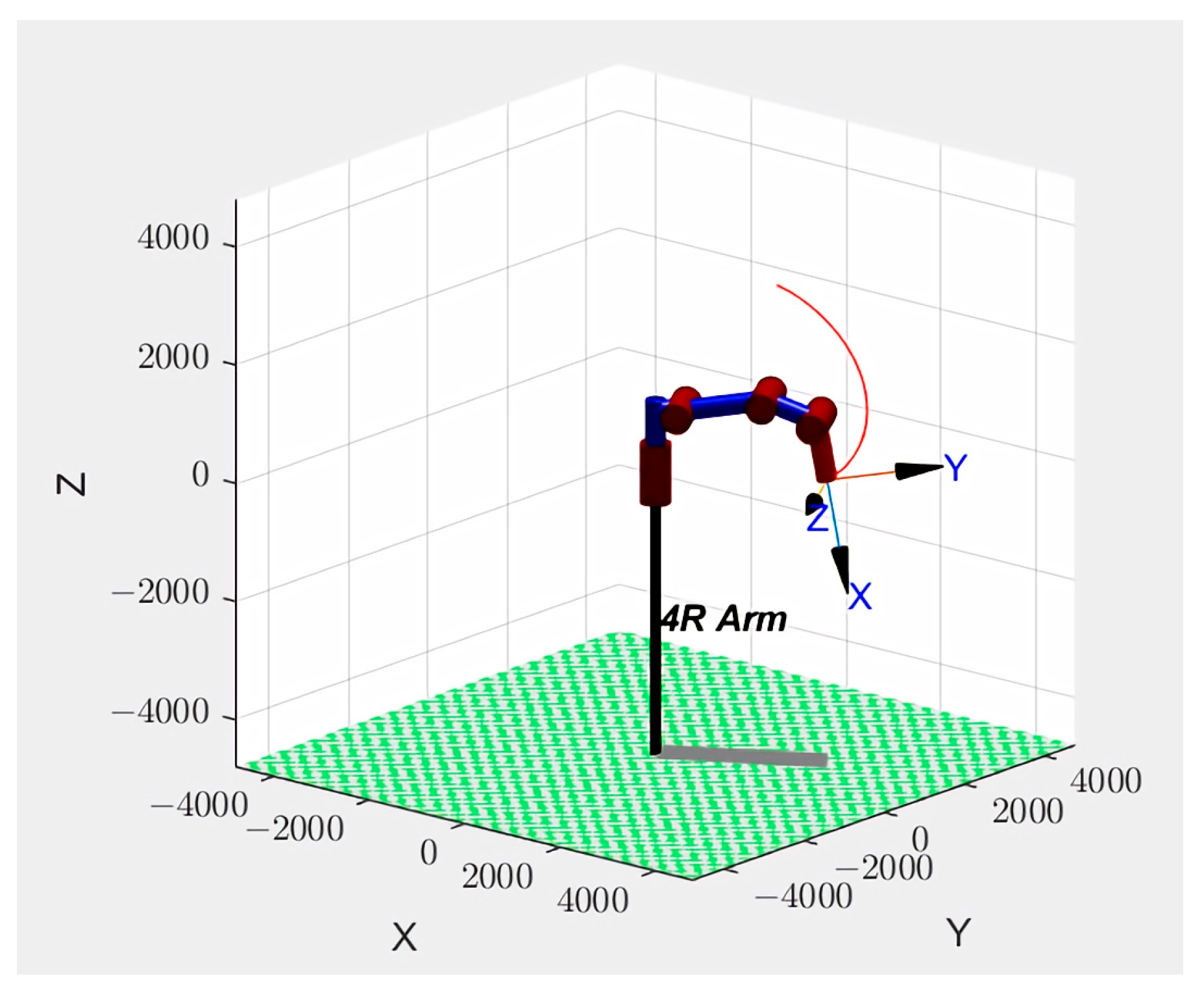
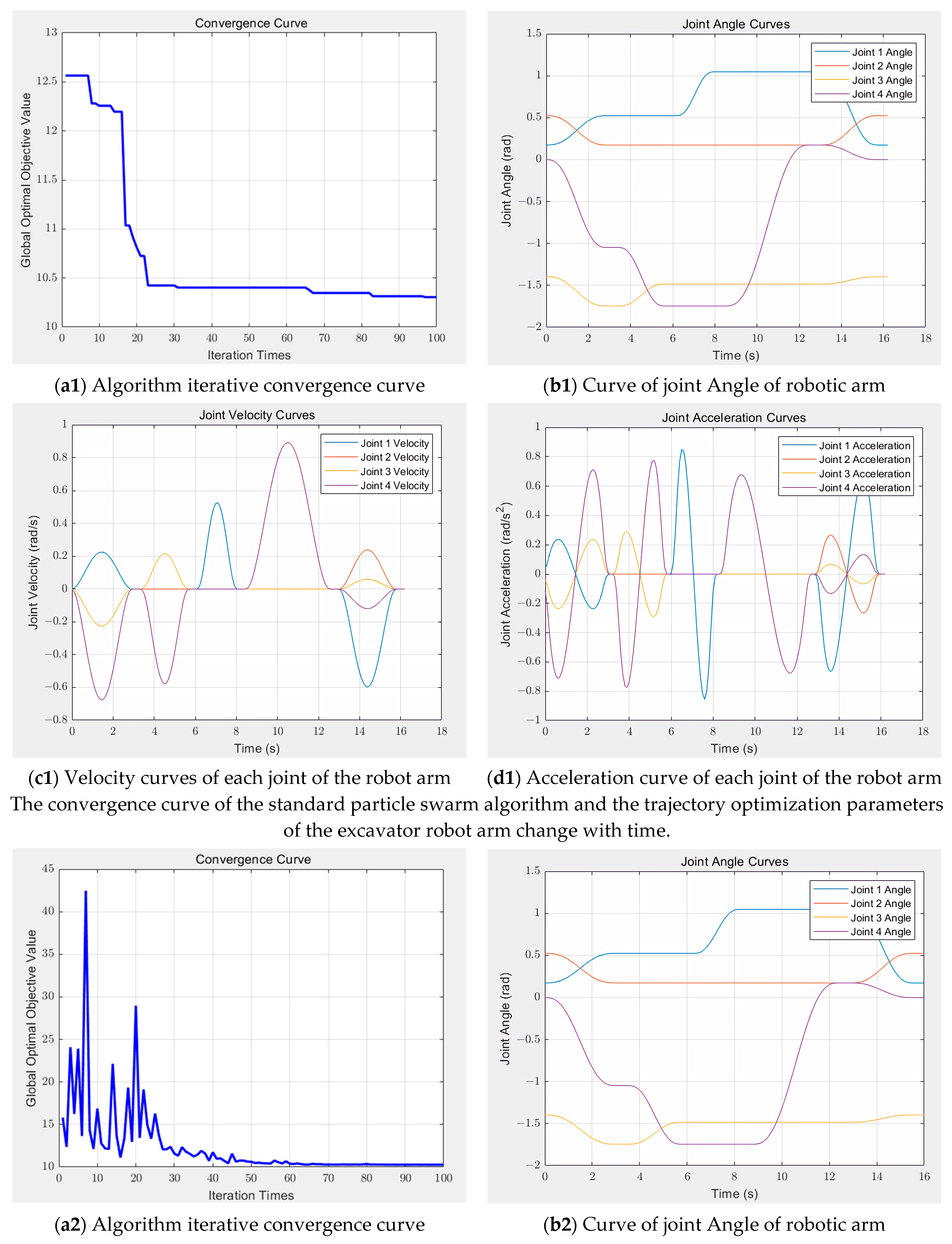
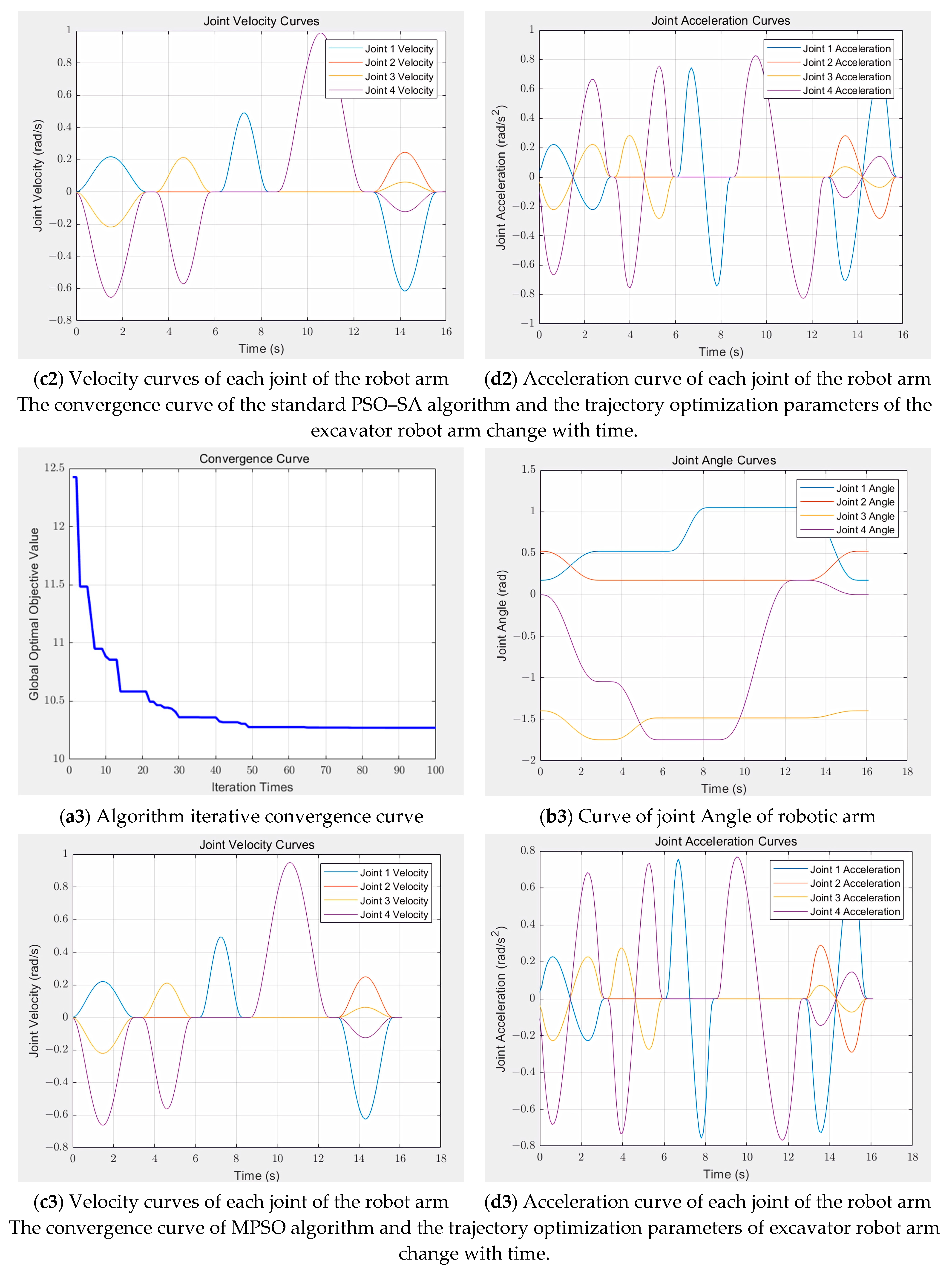
In this study, the improved PSO–SA optimization algorithm was used to plan the trajectory of the excavator manipulator arm with 4 degrees of freedom. The five-order B-spline curve was used to plan the trajectory in the joint space, and the improved PSO–SA algorithm was used to optimize the node vector of the trajectory planning of the five-stage operation task so that the excavator manipulator arm bucket completed a complete trajectory movement for the excavation task.
In this study, the simulated annealing algorithm and the particle swarm optimization algorithm are combined to improve the performance of the particle swarm optimization algorithm. The simulated annealing algorithm [
24] is a stochastic optimization algorithm based on the physical annealing process, and its core idea is to simulate the physical phenomena in the annealing process of solid matter, allowing the algorithm to accept the better solution with a certain probability in the search process, so as to effectively avoid falling into the local optimal solution. In the simulated annealing process, the solid matter is heated to high temperatures and then cooled slowly, and the particles are more energetic at high temperatures and are able to move and rearrange freely. As the temperature gradually decreases, the particles gradually tend to a low-energy steady state. The simulated annealing algorithm draws on this process to continuously find the global optimal solution of the objective function in the search space, which provides an effective improvement strategy for the particle swarm optimization algorithm, helpful in improving its global optimization ability and search efficiency.
PSO–SA improves several aspects compared to standard PSO in global search capability and the avoidance of precocious convergence and convergence speed. Firstly, the inertia weight
ω is adjusted by random generation, and the learning factors
and
are adjusted according to the progress ratio of the iteration,
decreases linearly with the increase in the progress ratio,
gradually increases with the increase in the progress ratio, and
gradually decreases and
gradually increases with the progress of the iteration, which helps to enhance the global search ability of particles in the early stage and improve the local search accuracy of particles in the later stage. This dynamic adjustment strategy not only improves the global search ability of the algorithm, but also enhances the convergence speed and the quality of the solution. Secondly, diversity monitoring was used for particle populations and, when the diversity was below the threshold, some particles were reset to avoid premature convergence. Combined with the perturbation mechanism of SA, some particles are randomly perturbed, the new solution is accepted according to the Metropolis criterion, and the global search ability is enhanced to balance the exploration and development capabilities. The cooling rate and perturbation ratio of SA are dynamically adjusted according to the ratio of the accepted solution so that the algorithm can adapt according to the search situation and balance global search and local search capabilities. The individual learning factor ranges from 1.0 to 2.0, with higher values in the early stages, leading particles to overly rely on their own experience and become trapped in local regions. As the individual learning factor decreases, particles gradually balance their own and collective experiences, thus expanding the search scope and increasing the likelihood of finding the global optimal solution. The social learning factor is set between 1.0 and 2.5, with lower values in the initial phase, which helps maintain diversity and prevent premature convergence. This gradually increases later on to enhance global search capabilities. The inertia weight [
25] is controlled within the range of 0.6 to 0.8, avoiding both the weakening of global search capabilities due to too low values and the slowing down of convergence or solution domain oscillation caused by excessively high values. The initial population size is set at 50, ensuring algorithm efficiency while keeping computational costs within a reasonable range. One hundred iterations can achieve stable convergence, fully exploring the search space while avoiding resource wastage. In the simulated annealing phase, the initial temperature is set to 350 to enhance early global exploration, the termination temperature is 1 × 10
−3 to ensure high solution domain accuracy later on, the initial cooling rate is 0.98 to balance global exploration with local development, and the perturbation ratio is 0.2 to control the local disturbance amplitude of particles, maintaining solution domain stability. Here are the main elements of the algorithm improvements:
- (1)
Dynamically update the inertia weight , learning factors and
Randomly generate adjusted inertia weights, where
and
are the maximum and minimum weight values, respectively:
The learning factors
c1 and
c2 adopt an exponential dynamic adjustment strategy,
c1s is the initial individual learning factor,
c2S is the initial social learning factor,
c2e is the final social learning factor,
is the iteration progress ratio, ITER is the current number of iterations, Max-Iter is the maximum number of iterations, and the range of rand () is between [0, 1].
- (2)
The diversity of particle swarms is calculated by Euclidean distance:
where:
n is the number of particles,
d is the dimension,
xi,j is the position of the particles
i on the dimension
j, and
μj is the mean of all the particles in the dimension
j.- (3)
The SA parameters are adaptively adjusted, where
is the cooling rate,
the perturbation ratio,
the acceptance rate of the new solution, and
T is the temperature update formula in each iteration. In order to ensure that the improved algorithm maintains high temperature enhancement exploration in the early stage, and rapid cooling strengthens the development in the later stage,
T is adaptively adjusted after each iteration:
- (4)
Simulated annealing algorithm in the original solution
The neighborhood randomly generates a new solution by perturbating
. The Metropolis criterion determines the probability of accepting a new solution in simulated annealing [
26], and the
rand() range is between [0, 1]:
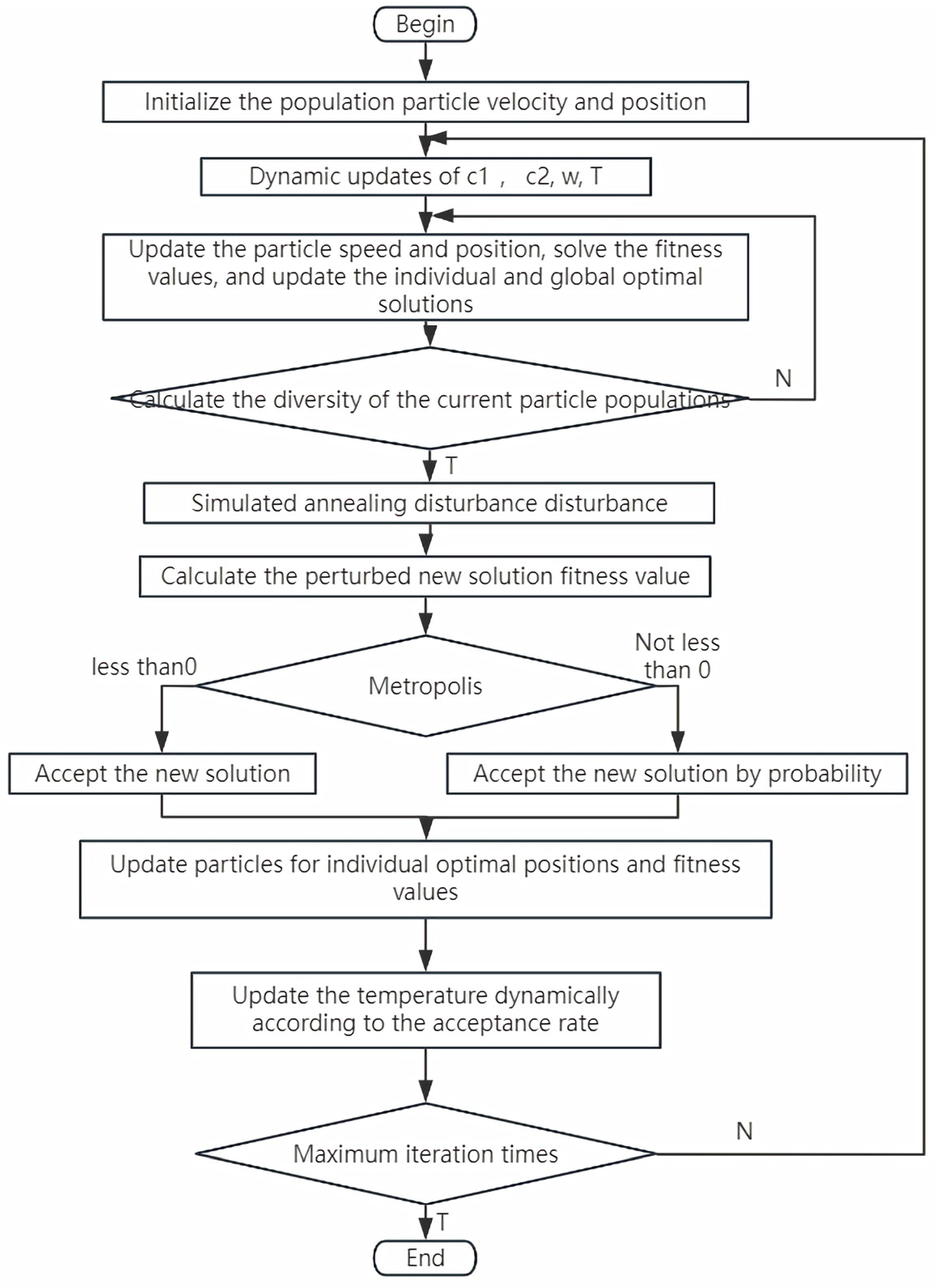
Here are the specific steps to improve the PSO algorithm. The specific flow chart is shown in
Figure 5.
(1) The initial parameters are set as follows: the inertia weight range for the PSO algorithm is set to 0.6–0.8, the individual learning factor range is 1.0–2.0, and the social learning factor range is 1.0–2.5. An initial population of 50 particles is randomly generated in the search space, with each particle representing five sets of node vector time parameters. The number of iterations is 100. For the SA algorithm, the initial temperature is 350, and the termination temperature is 1 × 10−3.
(2) Initialize the velocity and position of the particles in the population and set the initial position of m particles to the individual optimal position pib of each particle. Compare the magnitude of the fitness function value of m particles, and the position of the particle with the smallest fitness function value is set to the historical optimal position of the particle swarm gb.
(3) The individual learning factor was calculated by Formula (19), the social learning factor was calculated by Formula (19), and the inertia weight ω was calculated by Formula (18) for the dynamic parameter update.
(4) Use the velocity update formula of PSO to update the velocity of the particles by combining the current particle position, individual optimal position, and global optimal position. Based on the updated velocity, the new position of the particle is calculated, and the position is within the set boundary. For each particle’s new position, the objective function is called to calculate its fitness value. The new fitness value is compared with the individual optimal fitness value of the particle and, if it is better, the individual optimal position and fitness value are updated. The individual optimal fitness value and the global optimal fitness value were further compared, and the global optimal position and fitness value were updated if it was better.
(5) Calculate the diversity of the current particle swarm and evaluate it by measuring the Euclidean distance between the particles and the population mean. If the diversity falls below the set threshold, the position and velocity of some particles are randomly reset to introduce new solutions and avoid premature convergence.
(6) If the diversity is greater than the set threshold, 40% of the individual historical optimal solutions (pbest) are randomly selected, the mixed stochastic strategy is used to simulate the annealing perturbation with Gaussian perturbation, a new candidate solution is generated, and the objective function is called to calculate the fitness value of the candidate solution, according to the Metropolis acceptance criterion. If the calculation is less than zero using Equation (25), the acceptance is forced, otherwise the acceptance probability is calculated, it is decided to accept the new solution and, if the new solution is better than gbest, the global optimal is updated.
(7) Dynamically adjust the cooling rate according to the search effect; if the acceptance rate of step (6) is greater than 40%, accelerate cooling; if the acceptance rate of step (6) is less than 20%, decelerate cooling, and use Equation (23) to calculate and update the temperature parameter T, so that it gradually decreases, and the simulated annealing process gradually converges.
(8) Judge whether the maximum number of iterations is reached, return to step (3) if it is not satisfied, and exit the loop if it is satisfied.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}