While the above content compared domain adaptation methods with CNN and fusion domain adaptation methods with general domain adaptation methods, variations in parameter settings, as well as differences in training and test set allocations for each method may still affect the diagnostic efficiency, accuracy, and the fairness of the comparisons. The following section discusses the impact of parameter settings on the fault diagnosis accuracy for each method.
4.3.1. Dropout-Rate Parameters
A Dropout layer was added after the fully connected layer in various domain adaptation methods to enhance the model’s performance when generalizing to the target domain. The most critical hyperparameter in the Dropout layer is the Dropout rate. A rate that is too high results in discarding too many neurons, leading to unstable model classification and underfitting. Conversely, a rate that is too low may cause the model to overly rely on the source domain training data. Furthermore, the premise of enhancing generalization by adding Dropout is that the diagnostic accuracy of the model trained on the source domain dataset remains unaffected.
To investigate the impact of the Dropout rate on diagnostic performance, experiments were conducted using the 25 °C LNA hard fault diagnosis as an example. The experimental results are presented in
Table 6.
From the experimental results, as the Dropout rate increases, the test set accuracy gradually becomes slightly higher than that of the training set, indicating an improvement in the model’s generalization ability. Up to a Dropout rate of 0.5, although the test set continues to exhibit good generalization performance, the accuracies of both the training and test sets begin to decline. This suggests that the proportion of discarded neurons has started to negatively impact the model’s diagnostic performance, and this effect intensifies as the Dropout rate increases further. Therefore, to maintain the model’s performance in the source domain, the Dropout rate is set to 0.4.
4.3.2. Training–Testing Set Ratio
During domain adaptation training, the ratio of the training set to the test set can significantly affect the results. A larger training set provides the model with more data to learn feature relationships, potentially leading to a better fit on the training data. Selecting an appropriate training-to-test-set ratio can enhance the model’s accuracy. Using the FDA method as an example, this study examines the optimal training-to-test-set ratio.
Table 7 presents the fault diagnosis accuracy of the FDA method under various training set ratios across different cross-domain conditions.
The training set is used to fit the model, while the test set evaluates the model’s performance on unseen data. During domain adaptation training, the ratio of the training set to the test set can significantly affect the results. A larger training set provides the model with more data to learn the relationships between features, potentially improving its ability to fit the training data. Selecting an appropriate training-to-test-set ratio can enhance the model’s accuracy. Using the FDA method as an example, this study investigates the optimal training-to-test-set ratio.
Table 7 presents the fault diagnosis accuracy of the FDA method under various training set ratios across different cross-domain conditions.
Analysis of the table shows that the proportion of training and testing sets does not significantly affect the training accuracy in the target domain. However, the overall trend indicates that as the proportion of the testing set increases, diagnostic accuracy decreases. Nonetheless, it is evident that when the testing set comprises 20% of the entire dataset, higher diagnostic accuracy is observed. Therefore, this study uses a 20% testing set as the experimental reference.
4.3.3. Parameters of Each Method
- (1)
AdaBN Influence of Training Parameters
AdaBN offers two updating methods for the BN (Batch Normalization) layer: batch updating and full dataset updating. To determine the optimal updating method for the BN layer, we will use the dataset from the 25 °C state as the source domain and the dataset from the 0 °C state as the target domain for fault diagnosis. When using the batch updating method for the BN layer, the batch size directly influences AdaBN’s domain adaptation capability. Therefore, experiments are conducted to examine the impact of batch size on domain adaptation performance, aiming to identify the optimal batch size for BN layer updating. The experimental results are presented in
Table 8.
From the comparison experiments on BN layer update batch sizes, it is observed that as the batch size increases beyond 64, the accuracy of the source domain test set begins to gradually decrease. This finding is consistent with the results from CNN batch-size experiments. An excessively large batch size reduces the frequency of updates to the BN layer’s statistical parameters in the target domain, leading to a corresponding decrease in target domain test accuracy. Conversely, an excessively small batch size can make the BN layer’s statistical parameters more susceptible to outlier data, resulting in reduced accuracy in the target domain. Based on the experimental results, a batch size of 64 is identified as optimal for BN layer updates when using batch updating.
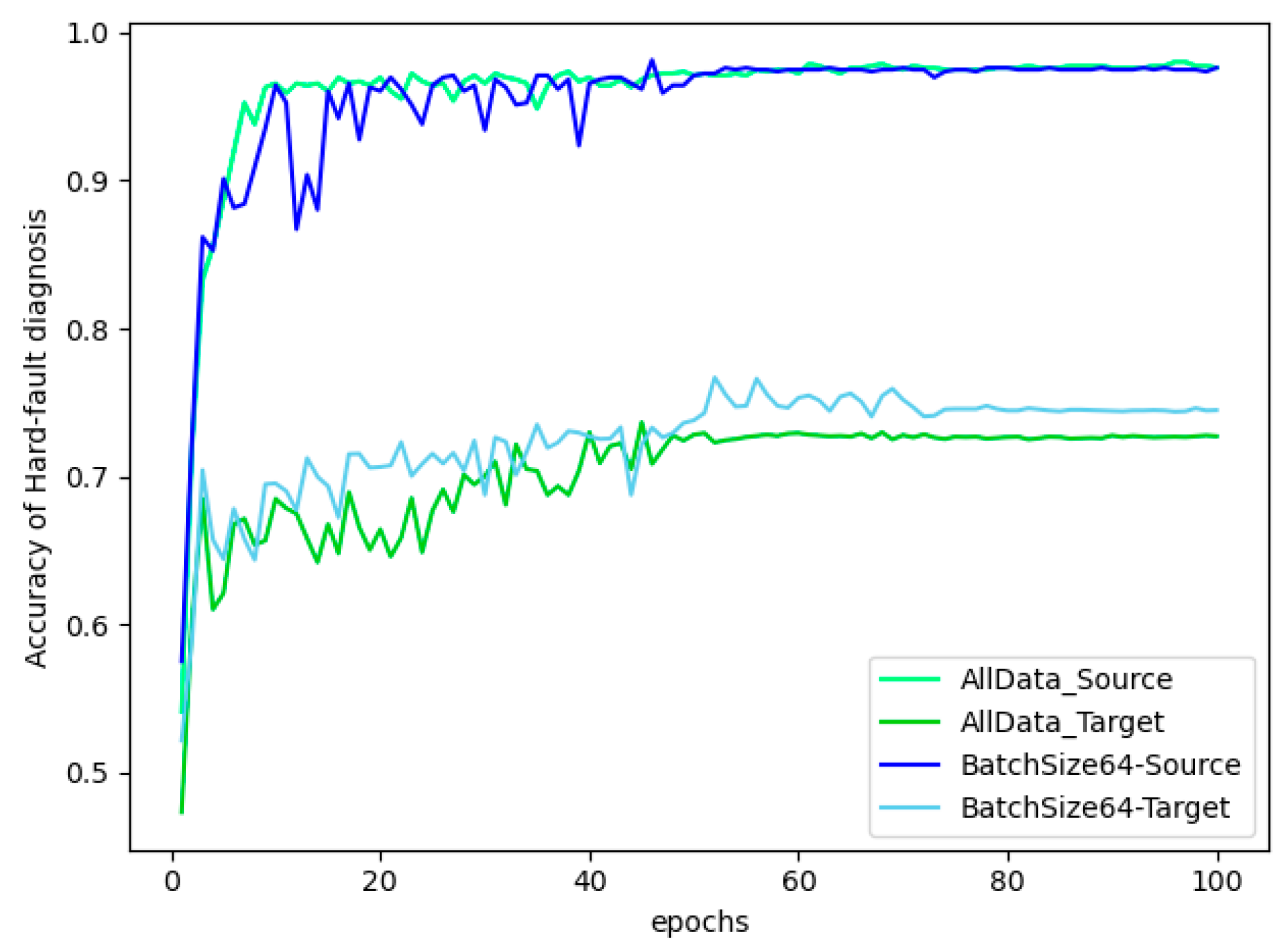
When the BN layer updates using the complete target domain dataset, its domain adaptation performance is not influenced by other hyperparameters. However, the effectiveness of this method compared to the batch update approach still needs to be validated through comparative experiments. Therefore, experiments were conducted using a batch size of 64 for comparison, and the results are shown in
Figure 13.
From the comparative experimental results, it can be observed that whether using batch updates or updating the entire target domain dataset, there is no significant impact on the final diagnostic results of the source domain test set. However, the diagnostic results in the target domain, which reflect the model’s domain adaptation characteristics, do differ. With a batch size of 64, the stable accuracy in the target domain is 74.47%, while the stable accuracy with full data updates is 72.71%. Therefore, updating the BN layer using batch mode demonstrates stronger adaptation capabilities in the target domain compared to full data updates.
- (2)
Feature Mapping Training Parameters
The domain adaptation capability of the feature mapping method is directly related to the mapping distance metric function, which in turn depends on the accuracy of domain distance calculation and the parameters involved in this process. Specifically, MK-MMD and JMMD are significantly influenced by the type of mapping kernel function (kernel type) and the number of kernels (kernel size).
The choice of kernel function type directly affects the model’s nonlinear mapping capability and domain adaptation generalization performance. Currently, five kernel functions are commonly used: linear, polynomial, sigmoid, Laplacian, and Gaussian Radial Basis Function (RBF). Each has its own characteristics. The Gaussian RBF kernel function is the most widely used and versatile in practical applications, making it the most effective choice for the kernel function in both MK-MMD and JMMD mapping methods.
The choice of kernel size directly impacts the density and dimensionality of the feature space. Additionally, the kernel size affects the bandwidth parameter
γ of the RBF, which in turn influences the smoothness and complexity of the model’s decision boundary. Typically, a kernel size that is too large increases both the feature space dimensionality and the bandwidth
γ, making the model more complex and raising the risk of overfitting. Conversely, a kernel size that is too small simplifies the feature space and reduces
γ, which enhances generalization but sacrifices the model’s ability to capture complex data features. Therefore, determining the appropriate kernel size through gradient change experiments is crucial for measuring distribution differences and improving feature alignment between the source and target domains. Diagnostic tests were conducted using kernel size gradient change experiments and the results are shown in
Table 9.
According to the experimental results, the performance of both MK-MMD and JMMD is influenced by changes in kernel size. The performance of MK-MMD is more significantly affected by kernel size, with its performance exhibiting a trend of increasing and then decreasing. For MK-MMD, the highest diagnostic accuracy in the target domain is achieved with a kernel size of 5, whereas for JMMD, the highest diagnostic accuracy is attained with a kernel size of 6. However, the difference in accuracy between kernel sizes 5 and 6 is only 0.53%.
- (3)
Domain adversarial discriminator network structure parameters
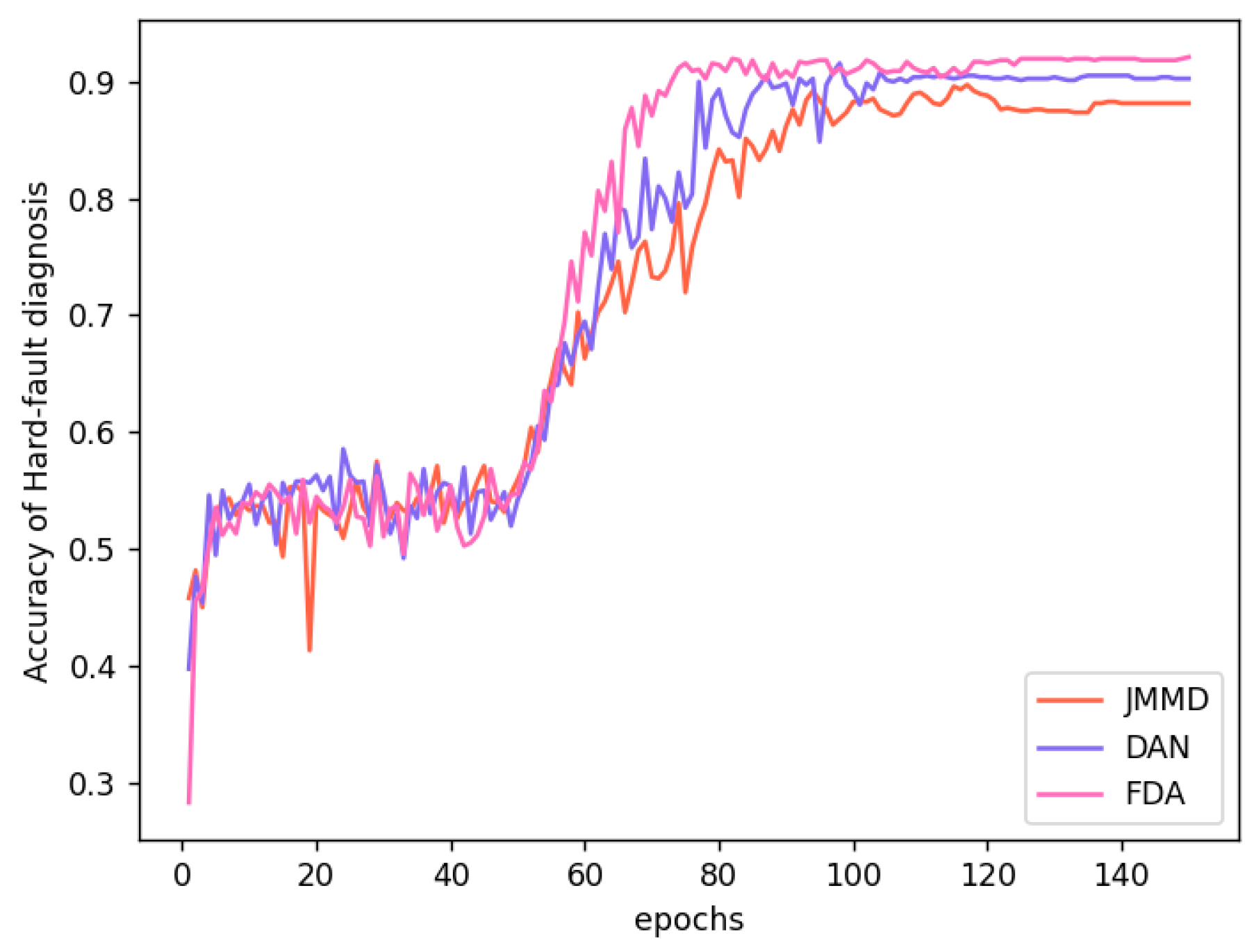
In adversarial networks, the discriminator primarily consists of fully connected layers. Therefore, the structure of these layers directly impacts the performance of the discriminator in domain adversarial discrimination tasks. The number of layers and the number of neurons in each fully connected layer are hyperparameters that need to be optimized through experiments. For cross-domain diagnostic tasks, the optimized experimental results for the fully connected layer parameters in the discriminators of DAN (Domain Adversarial Network) and JAN (Joint Adversarial Network) are shown in
Table 10 and
Table 11.
From the experimental results, it can be observed that for DAN, the discriminator performs well with a single fully connected layer, achieving effective feature alignment between domains during domain adversarial training. The optimal number of neurons for this configuration is 256. In contrast, the JAN discriminator demonstrates the strongest adaptation capability to the target domain with two fully connected layers, each containing 128 neurons. This improved performance may be attributed to the inclusion of joint distributions between output and input, which increases the dimensionality and complexity of the adversarial training features. Consequently, the discriminator benefits from deeper fully connected layers to enhance its nonlinear expression capability and improve domain adaptation. In summary, the optimal structure for DAN is a single layer with 256 neurons, while for JAN, it is two layers with 128 neurons each, which yields the best results for fault diagnosis.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}