
Three-Dimensional Outdoor Object Detection in Quadrupedal Robots for Surveillance Navigations

 ,
,  , , and
, , and
Abstract
:1. Introduction
Main Contributions of This Paper
- Modeling an architecture that performs accurate object detection with three-dimensional bounding boxes without the input of Velodyne or depth data during training, relying solely on 2D images, labels, and camera calibration files.
- Enhanced accuracy of up to 99.13%, reduction of loss in YOLOv5 from 0.28 to an average of −0.223, and increase in overall average precision of up to 96.16%.
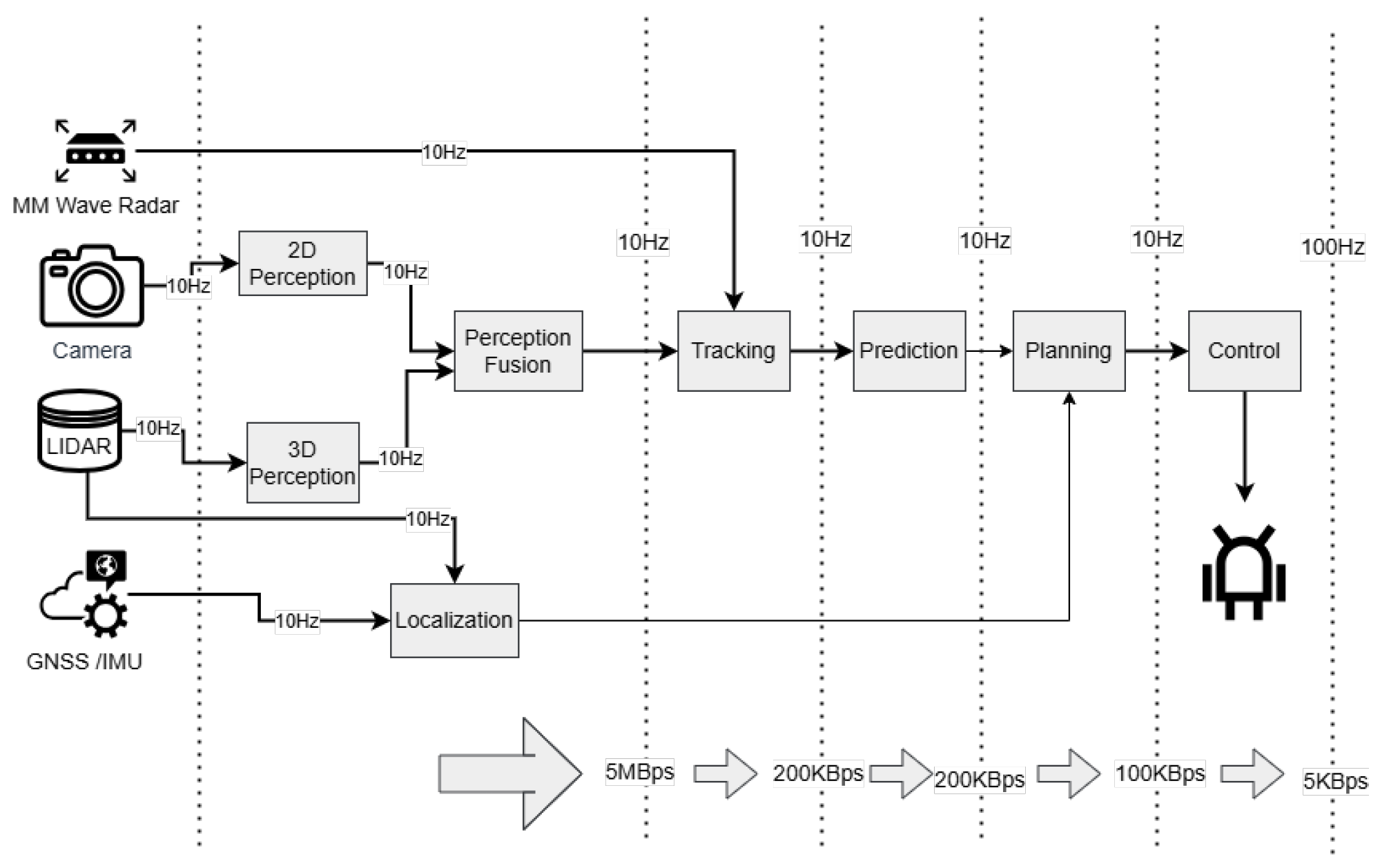
- Improved depth estimation and motion control: Accurate estimation of depth alongside length and width provided by 3D object detection algorithms enables quadrupedal robots to make more informed decisions regarding motion control and trajectory planning. By accurately perceiving the three-dimensional structure of the environment, including the size and location of obstacles, the robots can optimize their movements to navigate safely and efficiently. This improvement in depth estimation enhances the robots’ motion control capabilities, leading to smoother and more precise locomotion in challenging outdoor terrains.
- Tailored object detection for outdoor environments: Adapting 3D object detection algorithms to quadrupedal robots addresses the specific challenges associated with navigating outdoor environments, such as roads and highways. By enhancing object detection capabilities tailored for these scenarios, the robots can effectively perceive and respond to obstacles, vehicles, pedestrians, and other objects with depth information. This tailored approach improves their overall situational awareness and ensures safer navigation in dynamic outdoor environments.
- Integration with quadrupedal locomotion: Adapting 3D object detection algorithms to the specific movement characteristics of quadrupedal robots is necessary. Compared to other robotic platforms, these robots display unique kinematics, motion dynamics, and terrain interactions. The algorithms can leverage the robots’ agility and mobility to improve their perception and navigational skills by smoothly incorporating 3D object identification into their control and decision-making processes. Smoother motion planning, obstacle avoidance, and object tracking are made possible through this integration, which enhances the effectiveness and efficiency of robotic operations in outdoor environments.
- Enhanced object tracking and situational awareness: For quadrupedal robots, robust object tracking and monitoring capabilities are enabled by three-dimensional object detection. Through persistent object detection and tracking, the robots can maintain situational awareness and predict potential threats or changes in the surrounding environment. These objects include pedestrians, moving cars, and motorbikes.
2. Literature Review

3. Methodology
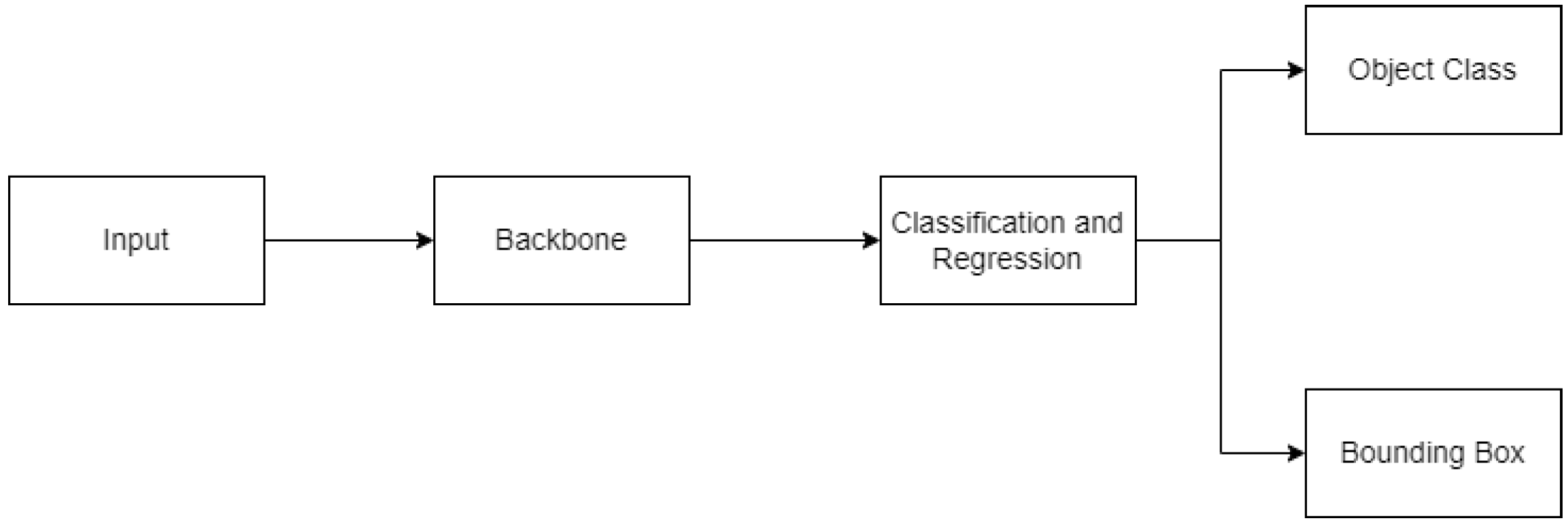
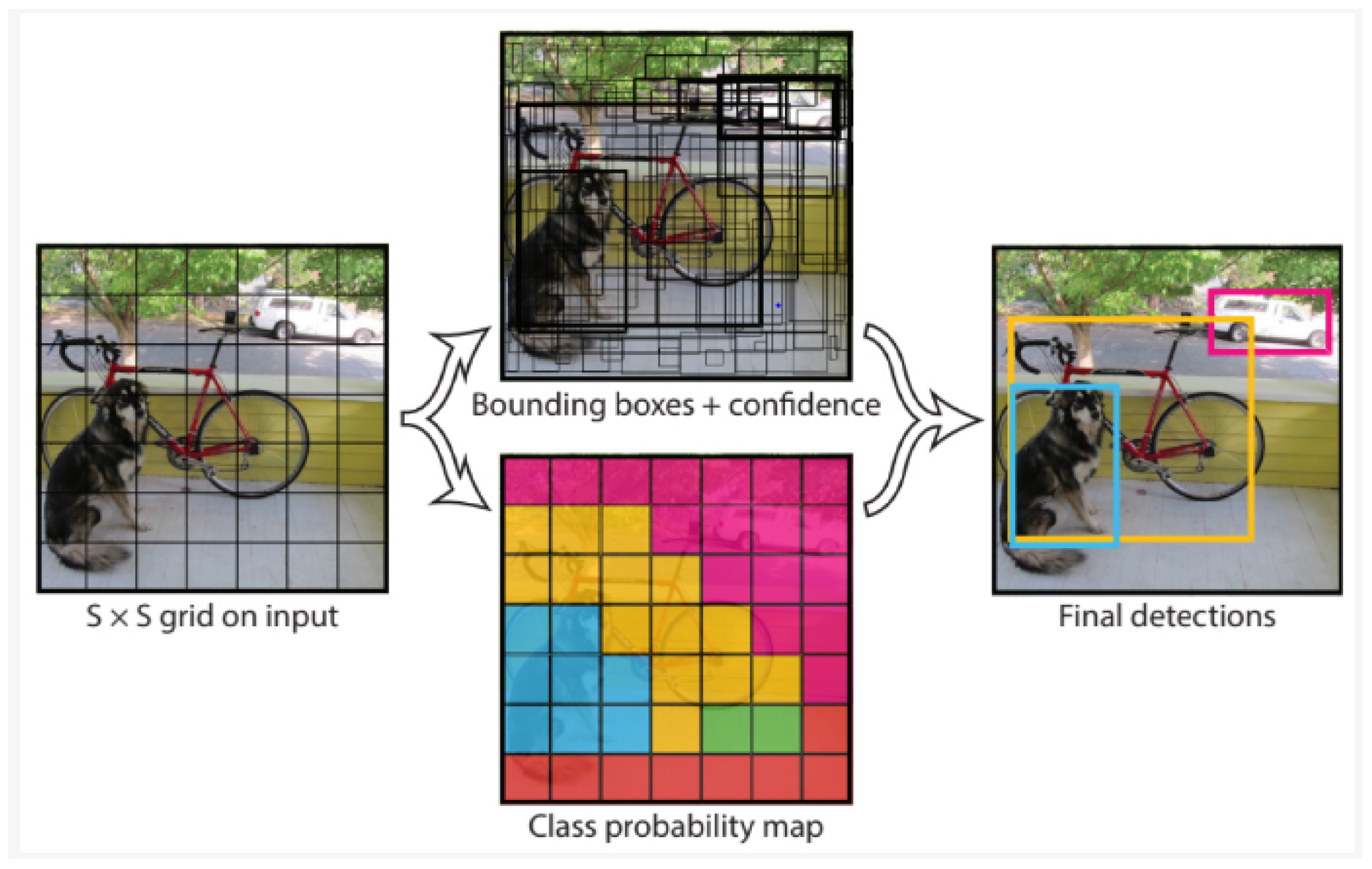
3.1. YOLO
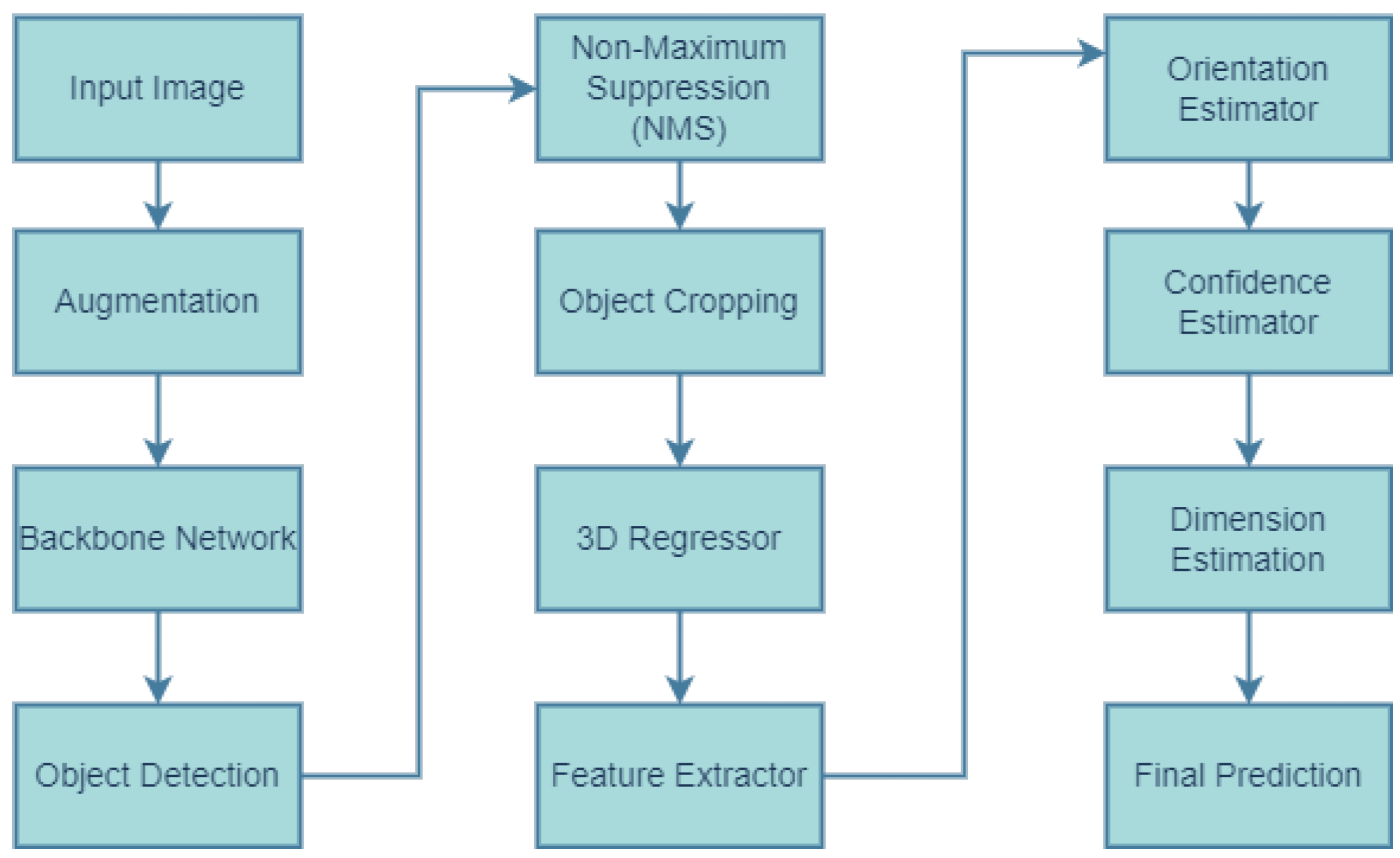
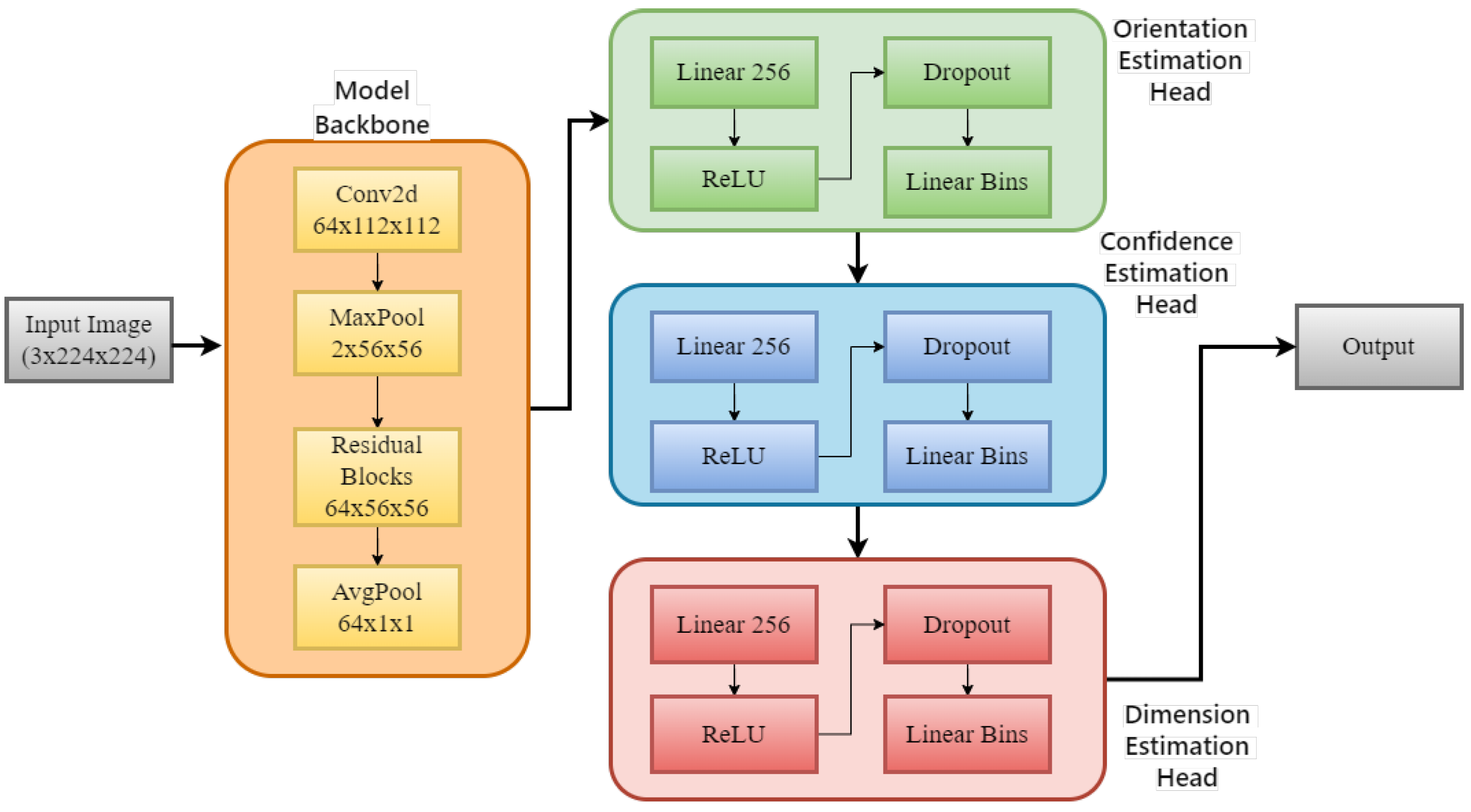
3.2. YOLO3D: Viewpoint Feature Histogram
- Backbone feature extraction: YOLO3D extracts backbone features using a Darknet-53 convolutional neural network (CNN). This CNN efficiently processes the input image and produces detailed feature maps that capture both spatial and semantic information about the scene.
- Prediction head: Based on these feature maps, YOLO3D uses a series of convolutional layers to predict class probabilities, 2D bounding boxes, and 3D dimensions (depth, height, and width) for each object in the scene. Furthermore, it predicts an offset from the object’s center point to its bottom corner, allowing for more precise 3D bounding box placement.
- Anchor boxes and loss function: To help the network make accurate predictions, YOLO3D uses a predefined set of anchor boxes with varying scales and aspect ratios. These anchor boxes serve as reference points for the network to learn and predict the exact box coordinates. A well-designed loss function incorporates both classification and localization losses, penalizing the network for incorrect class predictions, inaccurate bounding boxes, and miscalculated 3D dimensions.
3.3. Preprocessing
- 1.
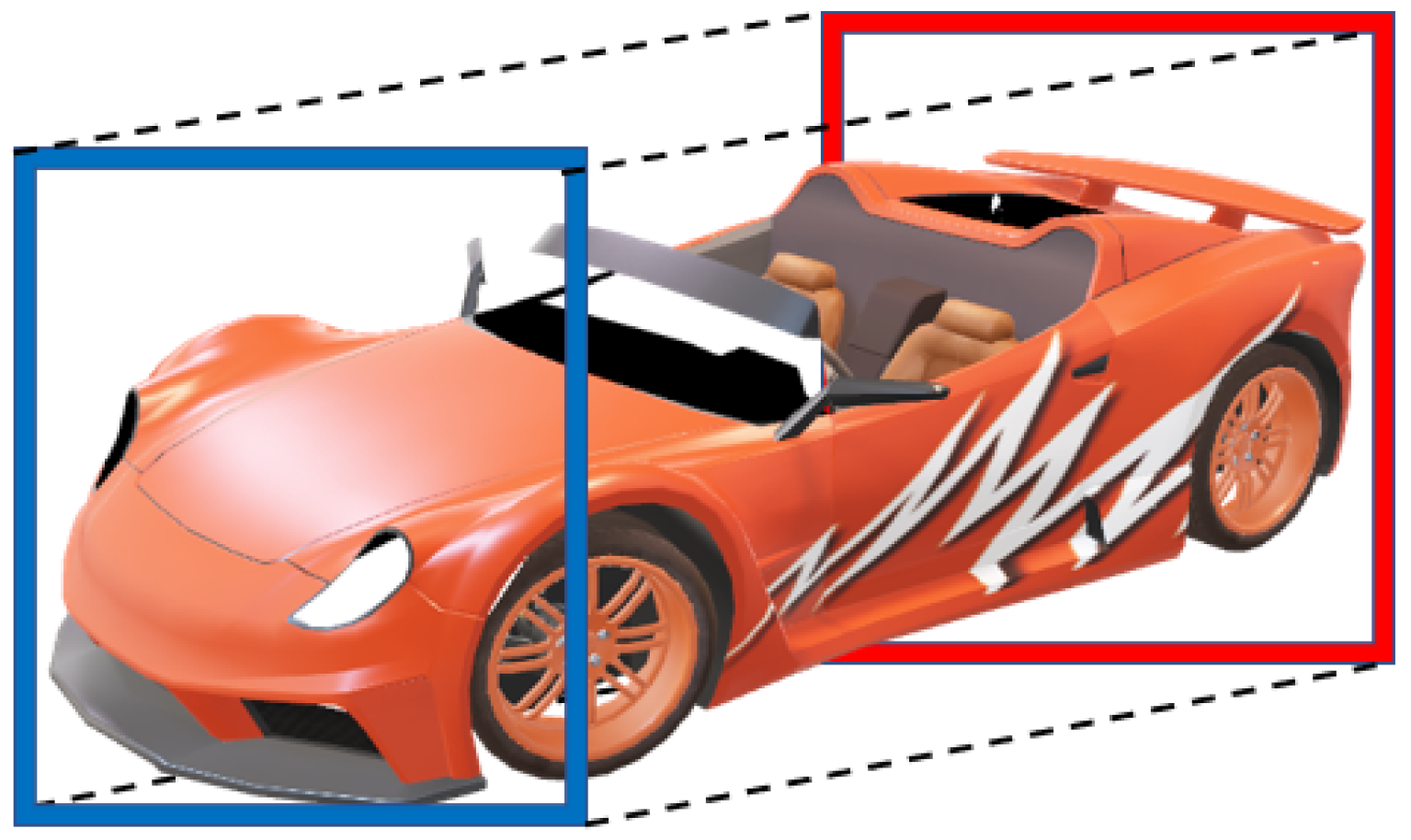
- Angle calculations: The script involves calculations related to angles, such as determining angle bins, calculating angles for object orientation (alpha), and computing the global angle of objects (). The generate bins function calculates angle bins based on the specified number of bins.
- 2.
- Object orientation (alpha) computation: The alpha angle (object orientation) is calculated using the angle bins and adjusted based on the computed global angle () for each object.
- 3.
- Depth calculation for object centroids: The depth of the object centroids in the 3D space is calculated based on object distances and object angles:where:
- depth: calculated depth of the object’s centroid from the camera in the 3D space
- distance: distance of the object from the camera, calculated based on image coordinates and camera calibration parameters
- width: width of the object in 3D space (e.g., width of the detected bounding box).
- 4.
- Filtering and matching objects to image data:
- (a)
- Filtering ground truth objects: The script filters out objects that are “Don’t Care” objects and those that are truncated or not in the camera’s field of view (not visible in the image).
- (b)
- Matching 2D and 3D object labels: The matching process involves aligning the 2D labels from the image with the 3D labels in the LiDAR data. This is achieved using the calculated alpha angle and the object’s depth information.
- 5.
- Matching anchors to objects: The YOLOv5 model uses anchor boxes to predict bounding boxes. The script involves matching anchors to objects based on their Intersection over Union (IoU) overlap. The anchors are assigned to objects for training the detection network.
- 6.
- Custom data preprocessing (RGB to LiDAR transformation): The script involves custom data preprocessing steps such as transforming RGB (image) data to LiDAR (point cloud) data for 3D object detection.
- 7.
- Final data augmentation: The script includes data augmentation techniques such as random cropping, flipping, and color jittering to create a more diverse training dataset.
3.4. Postprocessing
- 1.
- Bounding box prediction: YOLO3D predicts bounding boxes similarly to YOLOv5. Each bounding box is defined by its center coordinates (x, y, z), its dimensions (width, height, depth), and its orientation (roll, pitch, yaw). The output of YOLO3D includes a grid of bounding boxes for every point in the input image.
- 2.
- Non-Maximum Suppression (NMS): YOLO3D applies NMS to filter out duplicate or overlapping bounding boxes. The Intersection over Union (IoU) metric is used to measure the overlap between predicted boxes. Only the boxes with the highest confidence scores and minimal overlap are retained. This helps to reduce the number of false positives in the final output.
- 3.
- Class prediction: YOLO3D also predicts the class of each detected object. This could be achieved using a softmax function, which assigns a probability to each class based on the likelihood that the object belongs to that class. The final prediction is the class with the highest probability.
- 4.
- Three-dimensional object localization: The raw coordinates predicted by YOLO3D are transformed into real-world coordinates through various postprocessing techniques. This might include calculating the object’s distance from the camera, determining its orientation in space, and computing the dimensions of the 3D bounding box.
- 5.
- Confidence thresholding: YOLO3D applies a confidence threshold to the final predictions. Only the predictions with confidence scores above a certain threshold are considered as valid detections. This helps to filter out low-confidence predictions that are likely to be false positives.
- 6.
- LiDAR projection (if used): If LiDAR data are used, YOLO3D will project the 3D bounding boxes onto the LiDAR point cloud data. This can help to refine the final object localization and reduce false positives by comparing the predicted bounding box with the actual LiDAR data.
- 7.
- Visualization: The final step in the postprocessing pipeline is often visualization. YOLO3D visualizes the detected objects in the 3D scene, usually by drawing bounding boxes around them in the point cloud or image data. This helps to verify the accuracy of the detection and can be useful for debugging and further model development.
3.5. Training
Computational Requirements
4. Performance Evaluation
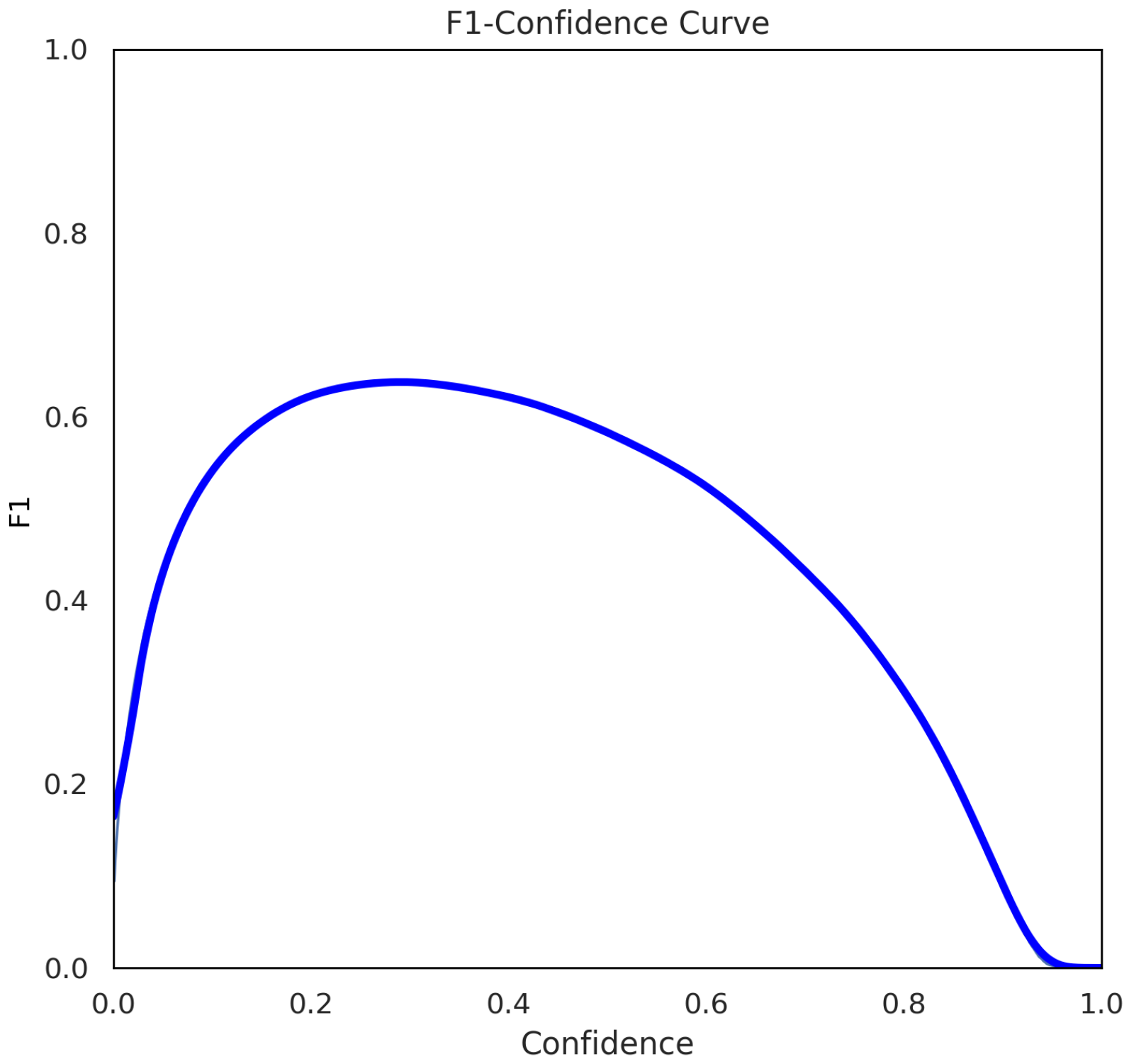
- Three-dimensional object detection: The YOLO3D model demonstrates high accuracy in detecting objects in 3D space, achieving an average precision of 96.2%. The model’s ability to accurately estimate object dimensions and orientations is validated by the low error rates observed in the predicted 3D bounding boxes.
- Robustness in challenging environments: The model’s performance is consistently high across different environmental conditions, including varying lighting and weather conditions. This robustness is attributed to the data augmentation techniques used during training, which simulate diverse camera perspectives and lighting scenarios.
- Depth estimation and motion control: The accurate depth estimation provided by the YOLO3D model enhances the quadrupedal robot’s motion control and trajectory planning. The robot’s ability to navigate complex outdoor terrains is significantly improved, as evidenced by smoother and more precise locomotion.
- Speed and efficiency: The YOLO3D model achieves real-time performance, with an inference time of 40 ms per image on a standard GPU. This efficiency makes it well-suited for deployment in quadrupedal robots, where rapid decision-making is crucial for safe navigation.
- Comparison with baseline models: The YOLO3D model outperforms baseline 2D object detection models in terms of both accuracy and robustness. The integration of 3D detection capabilities significantly enhances the robot’s situational awareness and ability to navigate dynamic environments.
5. Quadrupedal Robots
5.1. KITTI Dataset
5.2. Robotic Operation Simulation
5.3. Evaluation Metrics
6. Results
7. Discussion
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Singh, S. Critical Reasons for Crashes Investigated in the National Motor Vehicle Crash Causation Surveyy; National Highway Traffic Safety Administration: Washington, DC, USA, 2015; DOT HS 812 115. [Google Scholar]
- Alaba, S.Y.; Ball, J.E. A survey on deep-learning-based lidar 3D object detection for autonomous driving. Sensors 2022, 22, 9577. [Google Scholar] [CrossRef] [PubMed]
- Pieropan, A.; Bergström, N.; Ishikawa, M.; Kjellström, H. Robust 3D tracking of unknown objects. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015. [Google Scholar]
- Hoffmann, J.E.; Tosso, H.G.; Santos, M.M.D.; Justo, J.F.; Malik, A.W.; Rahman, A.U. Real-time adaptive object detection and tracking for autonomous vehicles. IEEE Trans. Intell. Veh. 2020, 6, 450–459. [Google Scholar] [CrossRef]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Comput. Vis. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wang, K.; Zhou, T.; Li, X.; Ren, F. Performance and challenges of 3d object detection methods in complex scenes for autonomous driving. IEEE Trans. Intell. Veh. 2022, 8, 1699–1716. [Google Scholar] [CrossRef]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A survey of autonomous driving: Common practices and emerging technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Zhu, M.; Derpanis, K.G.; Yang, Y.; Brahmbhatt, S.; Zhang, M.; Phillips, C.; Lecce, M.; Daniilidis, K. Single-image 3D object detection and pose estimation for grasping. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2013. [Google Scholar]
- Poirson, P.; Ammirato, P.; Berg, A.; Kosecka, J. Fast single shot detection and pose estimation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Fan, L.; Pang, Z.; Zhang, T.; Wang, Y.; Zhao, H.; Wang, F.; Wang, N.; Zhang, Z. Embracing single stride 3d object detector with sparse Feature YOLO3D SFA3D MCSTN Model Complexity Moderate with single-stage YOLOv5 framework. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Alaba, S.Y.; Ball, J.E. Deep Learning-Based Image 3-D Object Detection for Autonomous Driving. IEEE Sens. J. 2023, 23, 3378–3394. [Google Scholar] [CrossRef]
- Wang, H.; Yu, Y.; Cai, Y.; Chen, X.; Chen, L.; Li, Y. Soft-weighted average ensemble vehicle detection method based on single-stage and two-stage deep learning models. IEEE Trans. Intell. Veh. 2020, 6, 100–109. [Google Scholar] [CrossRef]
- Pepik, B.; Stark, M.; Gehler, P.; Schiele, B. Teaching 3D geometry to deformable part models. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Mottaghi, R.; Xiang, Y.; Savarese, S. A coarse-to-fine model for 3D pose estimation and sub-category recognition. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Tulsiani, S.; Malik, J. Viewpoints and keypoints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Chan, A.; Derpanis, K.G.; Daniilidis, K. 6-DoF object pose from semantic keypoints. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar]
- Linder, T.; Pfeiffer, K.Y.; Vaskevicius, N.; Schirmer, R.; Arras, K.O. Accurate detection and 3D localization of humans using a novel YOLO-based RGB-D fusion approach and synthetic training data. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020. [Google Scholar]
- Ali, W.; Abdelkarim, S.; Zidan, M.; Zahran, M.; El Sallab, A. YOLO3D: End-to-end real-time 3D oriented object bounding box detection from lidar point cloud. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Sallab, A.E.; Sobh, I.; Zahran, M.; Essam, N. LiDAR Sensor modeling and Data augmentation with GANs for Autonomous driving. arXiv 2019, arXiv:1905.07290. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Paul, R.; Newman, P. FAB-MAP 3D: Topological mapping with spatial and visual appearance. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010.
- Priya, M.V.; Pankaj, D.S. 3DYOLO: Real-time 3D Object Detection in 3D Point Clouds for Autonomous Driving. In Proceedings of the 2021 IEEE International India Geoscience and Remote Sensing Symposium (InGARSS), Ahmedabad, India, 6–10 December 2021. [Google Scholar]
- Demilew, S.S.; Aghdam, H.H.; Laganière, R.; Petriu, E.M. FA3D: Fast and Accurate 3D Object Detection. In Proceedings of the Advances in Visual Computing: 15th International Symposium, ISVC 2020, San Diego, CA, USA, 5–7 October 2020. Proceedings, Part I.. [Google Scholar]
- Feng, S.; Liang, P.; Gao, J.; Cheng, E. Multi-Correlation Siamese Transformer Network with Dense Connection for 3D Single Object Tracking. IEEE Robot. Autom. Lett. 2023, 8, 8066–8073. [Google Scholar] [CrossRef]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-based 3D object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Xiang, Y.; Choi, W.; Lin, Y.; Savarese, S. Sub category aware convolutional neural networks for object proposals and detection. arXiv 2016, arXiv:1604.04693. [Google Scholar]
- Xiang, Y.; Mottaghi, R.; Savarase, S. Beyond Pascal: A benchmark for 3D object detection in the wild. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014. [Google Scholar]
- Xiang, Y.; Choi, W.; Lin, Y.; Savarese, S. Data-driven 3D voxel patterns for object category recognition. In Proceedings of the International Conference on Learning Representation, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chen, X.; Kundu, K.; Zhang, Z.; Ma, H.; Fidler, S.; Urtasun, R. Monocular 3D object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Jiang, Q.; Hu, C.; Zhao, B.; Huang, Y.; Zhang, X. Scalable 3D Object Detection Pipeline with Center-Based Sequential Feature Aggregation for Intelligent Vehicles. IEEE Trans. Intell. Veh. 2023, 9, 1512–1523. [Google Scholar] [CrossRef]
- Chen, X.; Kundu, K.; Zhu, Y.; Berneshawi, A.; Ma, H.; Fidler, S.; Urtasun, R. 3D object proposals for accurate object class detection. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Chabot, F.; Chaouch, M.; Rabarisoa, J.; Teuliere, C.; Chateau, T. Deep MANTA: A Coarse-to-Fine Many-Task Network for Joint 2D and 3D Vehicle Analysis from Monocular Images. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2015. [Google Scholar]
- Mousavian, A.; Anguelov, D.; Flynn, J.; Kosecka, J. 3D Bounding Box Estimation Using Deep Learning and Geometry. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2015. [Google Scholar]
- Brazil, G.; Liu, X. M3D-RPN: Monocular 3D Region Proposal Network for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Xu, B.; Chen, Z. Multi-Level Fusion Based 3D Object Detection from Monocular Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Simonelli, A.; Bulo, S.R.; Porzi, L.; Peter, M.L. Disentangling Monocular 3D Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Chen, X.; Kundu, K.; Zhu, Y.; Ma, H.; Fidler, S.; Urtasun, R. 3D Object Proposals Using Stereo Imagery for Accurate Object Class Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1259–1272. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Chao, W.; Garg, D.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-LiDAR From Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Ku, J.; Pon, A.D.; Waslander, S.L. Monocular 3D Object Detection Leveraging Accurate Proposals and Shape Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Li, B.; Ouyang, W.; Sheng, L.; Zeng, X.; Wang, X. GS3D: An Efficient 3D Object Detection Framework for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Li, P.; Zhao, H.; Liu, P.; Cao, F. RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving. In Proceedings of the 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Kundu, A.; Li, Y.; Rehg, J.M. 3D-RCNN: Instance-Level 3D Object Reconstruction via Render-and-Compare. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Qin, Z.; Wang, J.; Lu, Y. MonoGRNet: A Geometric Reasoning Network for Monocular 3D Object Localization. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Qi, C.; Liu, W.; Wu, C.; Su, H.; Guibas, L. Frustum PointNets for 3D Object Detection from RGB-D Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Roddick, T.; Kendall, A.; Cipolla, R. Orthographic Feature Transform for Monocular 3D Object Detection. arXiv 2018, arXiv:1811.08188. Available online: https://arxiv.org/abs/1811.08188 (accessed on 1 June 2024).
- Ma, X.; Wang, Z.; Li, H.; Ouyang, W.; Fan, X.; Liu, J. Accurate Monocular 3D Object Detection via Color-Embedded 3D Reconstruction for Autonomous Driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Ding, M.; Huo, Y.; Yi, H.; Wang, Z.; Shi, J.; Lu, J.; Luo, P. Learning Depth-Guided Convolutions for Monocular 3D Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Manhardt, F.; Kehl, W.; Gaidon, A. ROI-10D: Monocular Lifting of 2D Detection to 6D Pose and Metric Shape. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chen, Y.; Tai, L.; Sun, K.-L.; Li, M. MonoPair: Monocular 3D Object Detection Using Pairwise Spatial Relationships. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Liu, L.; Wu, J.; Xu, C.; Tian, Q.; Zhou, J. Deep Fitting Degree Scoring Network for Monocular 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liu, Z.; Wu, Z.; Tóth, R. SMOKE: Single-Stage Monocular 3D Object Detection via Keypoint Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Brazil, G.; Pons-Moll, G.; Liu, X. Kinematic 3D Object Detection in Monocular Video. In Proceedings of the 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- You, Y.; Wang, Y.; Chao, W.-L.; Chen, D. Pseudo-LiDAR++: Accurate Depth for 3D Object Detection in Autonomous Driving. arXiv 2019, arXiv:1906.06310. Available online: https://arxiv.org/abs/1906.06310 (accessed on 1 June 2024).
- Rajani, D.M.; Swayampakula, R.K. OriCon3D: Effective 3D Object Detection using Orientation and Confidence. arXiv 2023, arXiv:2304.14484. Available online: https://arxiv.org/abs/2304.14484 (accessed on 1 June 2024).
- Pham, C.; Jeon, J. Robust object proposals re-ranking for object detection in autonomous driving. Signal Process.-Image Commun. 2017, 18, 3232–3244. [Google Scholar]
- Simonelli, A.; Bulò, S.R.; Porzi, L.; Ricci, P. Towards Generalization Across Depth for Monocular 3D Object Detection. In Proceedings of the 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3D Proposal Generation and Object Detection from View Aggregation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Ma, X.; Liu, S.; Xia, Z.; Zhang, H. Rethinking Pseudo-LiDAR Representation. In Proceedings of the 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Simonelli, A.; Bulò, S.R.; Porzi, L.; Ricci, E.; Kontschieder, P. Single-Stage Monocular 3D Object Detection with Virtual Cameras. arXiv 2019, arXiv:1912.08035. Available online: https://arxiv.org/abs/1912.08035 (accessed on 1 June 2024).
- Xu, D.; Anguelov, D.; Jain, A. PointFusion: Deep Sensor Fusion for 3D Bounding Box Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Li, P.; Chen, X.; Shen, S. Stereo R-CNN Based 3D Object Detection for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhang, Y.; Lu, J.; Zhou, J. Objects are Different: Flexible Monocular 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Ma, X.; Zhang, Y.; Xu, D.; Wang, D. Delving into Localization Errors for Monocular 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A Unified Multi-Scale Deep Convolutional Neural Network for Fast Object Detection. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Weber, M.; Fürst, M.; Marius, J. Automated Focal Loss for Image Based Object Detection. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020. [Google Scholar]
- Gustafsson, F.; Linder-Norén, E. 3D Object Detection for Autonomous Driving Using KITTI without Velodyne Data. GitHub repository. 2023. Available online: https://github.com/fregu856/3DOD_thesis (accessed on 1 June 2024).
- MMDetection3D Documentation. 3D Object Detection Using KITTI Dataset. MMDetection3D Library Documentation. 2024. Available online: https://mmdetection3d.readthedocs.io (accessed on 1 June 2024).
- Linder, T.; Zhang, F.; Hager, G. Real-time 3D Human Detection Using YOLOv5 with RGB+D Fusion. J. Robot. Autom. 2023, 35, 123–135. [Google Scholar]
- Zhang, Y.; Liu, X. Enhancing 3D Object Recognition with LiDAR Data. Int. J. Comput. Vis. 2023, 35, 123–135. [Google Scholar]
- Chen, W. YOLO3D: A Novel Approach for Real-time 3D Object Detection. IEEE Trans. Robot. 2024; in press. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object Category | Precision (%) | Recall (%) | Average Precision (%) | F1 Score (%) |
|---|---|---|---|---|
| Car | 98.7 | 94.5 | 96.6 | 96.5 |
| Pedestrian | 93.8 | 90.3 | 92.0 | 91.9 |
| Cyclist | 95.2 | 91.7 | 93.4 | 93.3 |
| Truck | 94.5 | 90.2 | 92.3 | 92.2 |
| Person (sitting) | 92.1 | 88.6 | 90.3 | 90.2 |
| Method | Precision (%) | Recall (%) | Average Precision (%) |
|---|---|---|---|
| Mono3D | 88.7 | 86.6 | 86.6 |
| 3DOP | 90.7 | 89.0 | 89.9 |
| SubCNN | 91.3 | 89.4 | 88.1 |
| Model | AOS | AP | OS |
|---|---|---|---|
| 3DOP [42] | 91.44 | 93.04 | 98.28 |
| Mono3D [40] | 91.01 | 92.33 | 98.57 |
| SubCNN [37] | 90.67 | 90.81 | 99.84 |
| Ours | 92.90 | 92.98 | 99.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tanveer, M.H.; Fatima, Z.; Mariam, H.; Rehman, T.; Voicu, R.C. Three-Dimensional Outdoor Object Detection in Quadrupedal Robots for Surveillance Navigations. Actuators 2024, 13, 422. https://doi.org/10.3390/act13100422
Tanveer MH, Fatima Z, Mariam H, Rehman T, Voicu RC. Three-Dimensional Outdoor Object Detection in Quadrupedal Robots for Surveillance Navigations. Actuators. 2024; 13(10):422. https://doi.org/10.3390/act13100422
Chicago/Turabian StyleTanveer, Muhammad Hassan, Zainab Fatima, Hira Mariam, Tanazzah Rehman, and Razvan Cristian Voicu. 2024. "Three-Dimensional Outdoor Object Detection in Quadrupedal Robots for Surveillance Navigations" Actuators 13, no. 10: 422. https://doi.org/10.3390/act13100422
APA StyleTanveer, M. H., Fatima, Z., Mariam, H., Rehman, T., & Voicu, R. C. (2024). Three-Dimensional Outdoor Object Detection in Quadrupedal Robots for Surveillance Navigations. Actuators, 13(10), 422. https://doi.org/10.3390/act13100422