1. Introduction
Due to their simple mechanical structure and flexible control, skid-steering distributed drive vehicles have been widely applied in various scenarios, including wheeled robots [
1,
2], agricultural vehicles [
3], military vehicles [
4,
5], and so on. Generally, a skid-steering vehicle has four independent driving wheels, forming a redundant actuator system, which delivers remarkable maneuverability and more options for FTC methods [
6]. With the development of meta-RL algorithms, some recent studies applied meta-RL algorithms to the FTC problem of actuator faults, providing new insights into the FTC mechanism of skid-steering vehicles [
7,
8]. Meta-RL learns an initial meta-trained model from a set of fault situations that have high-level similarity. However, in the real world, skid-steering vehicles might experience different types of fault situations, where the dynamical models can be significantly different from one another [
9]. The single initial meta-trained model in conventional meta-RL algorithms limits the ability to learn fault situations that do not have strong similarity to the learned faults, leading to low generalizability to novel fault situations [
10,
11].
Meta-RL approaches were successfully applied to adapt to system failures and external disturbances, especially the most representative model-agnostic meta-learning (MAML) [
12]. In [
13,
14,
15,
16], the authors presented a series of methods based on meta-RL to quickly adapt their control policies to maintain degraded performance when faults occur in aircraft fuel transfer systems. The scheme of FTC methods includes offline meta-training and online meta-testing stages. In [
17], the authors presented a reference trajectory update method based on meta-RL, to improve the trajectory tracking performance of unmanned aerial vehicles (UAVs) under actuator faults and disturbances. They leveraged meta-RL to quickly adapt the system model at runtime, as well as to update the reference trajectory without needing access to the control inputs. In [
18], an impact-angle guidance law was proposed for the interception of a maneuvering target using a varying velocity interceptor under partial actuator failures, based on meta-RL and model predictive path integral (MPPI). The deep neural dynamic can learn the changes and perturbations in the environment through the online adaption ability of meta-learning, which endows the proposed method with better tracking performance than the standard MPPI method. In [
19], an adaptive controller based on meta-RL was proposed for automatic train velocity regulation. The velocity regulation problem, under the complicated railway environment and uncertain dynamics of the system, is expressed as a sequence of stationary Markov decision process (MDP) with unknown transition probabilities. The meta-RL algorithm learns to track the desired speed under changing conditions. In [
20], the authors proposed meta twin-delayed deep deterministic policy gradient (meta-TD3) to realize the control of UAVs, allowing the UAVs to quickly track a target characterized by uncertain motion. As meta-RL showed great potential in quickly adapting to system failures and external disturbances in recent years, it can provides new insights into the FTC problem of skid-steering vehicles and, as such, is incorporated into our work.
A major limitation of conventional meta-RL methods is that they seek a common initialization in the entire task distribution, which substantially limits their application in multi-task distribution [
21,
22]. To mitigate this limitation, some methods have extended MAML with the capability to identify the mode of tasks sampled from a multi-modal task distribution. In [
23,
24], the authors developed a Multi-Modal Model-Agnostic Meta-Learner (MuMoMAML). The model-based learner first effectively recognizes the mode of the task distribution through a few samples from the target task, and then adapts to the target task through gradient updates. In [
25], the authors introduced a task encoder into the meta-RL framework and developed a new meta-RL method; namely TESP. TESP trains a shared policy and a stochastic gradient descent (SGD) optimizer coupled to a task encoder network from a set of tasks. The SGD optimizer is applied to quickly learn a task encoder for each task, which generates the corresponding task embedding based on past experience. Meanwhile, the shared policy is learned across all tasks and conditioned on task embeddings. To exploit information about task relationship, in [
26], the authors proposed a task embedding of visual classification tasks, named Task2Vec, which provides a fixed-dimensional embedding of the task that is independent of details and does not require any understanding of the class label semantics. In [
27], the authors proposed a novel representation, named MATE (model-aware task embedding), which is able to efficiently fuse the data distribution and model inductive bias. MATE introduces a model-dependent surrogate function to improve the current kernel mean embedding, which can be incorporated into deep neural networks. In [
28], the authors proposed an algorithm called FAMLE to learn the multi-modal task distribution by meta-training several initial models and allowing the robot to select the most suitable initial model as the starting point to adapt to the current situation. FAMLE leverages the embedding of the meta-trained models to select the starting point, making it able to adapt faster than a single meta-trained model. In fact, our method uses FAMLE as the situation-embedding model, to select the most suitable meta-trained model for the fault situation of a skid-steering vehicle as a starting point for online adaption.
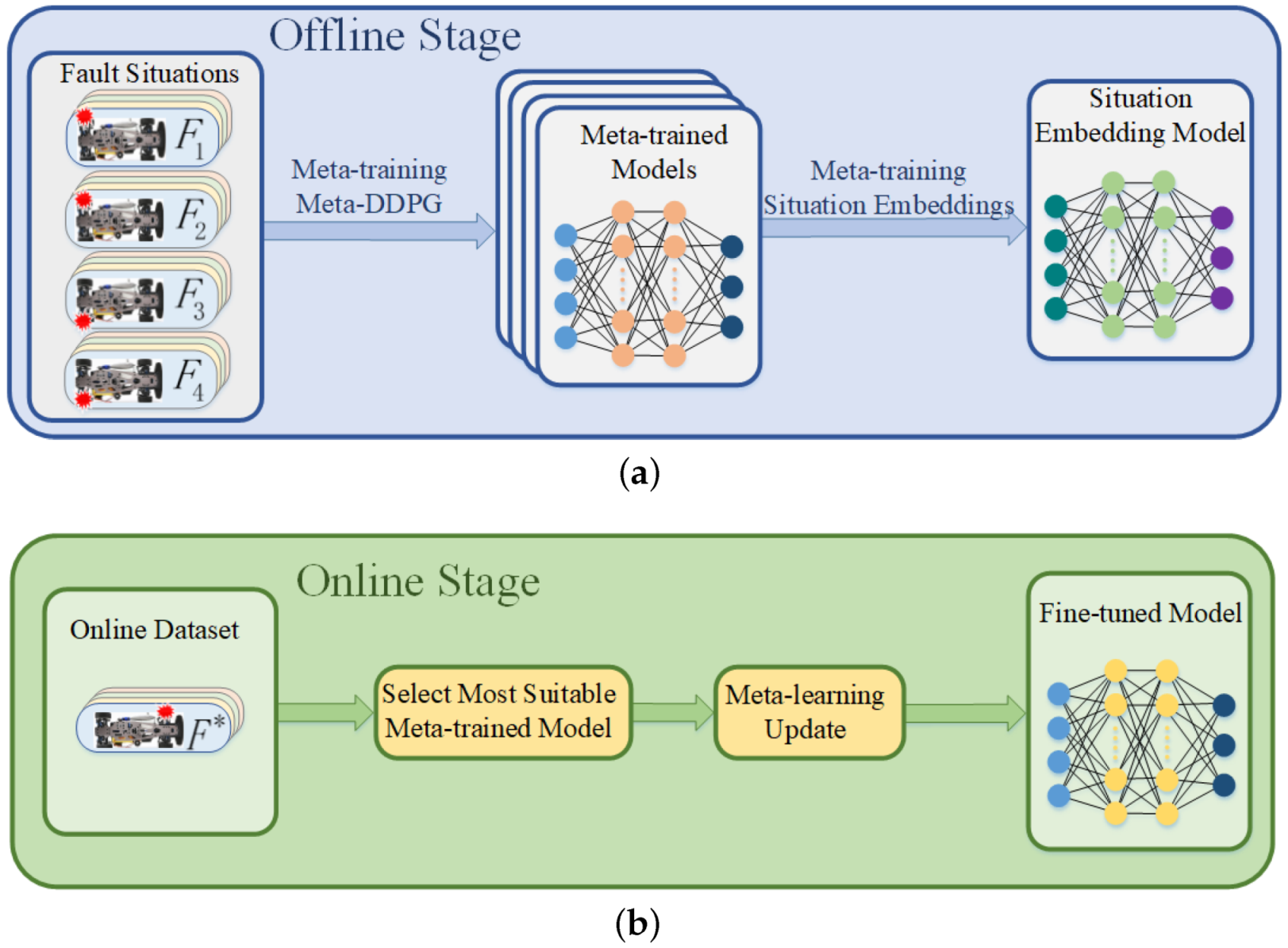
The main purpose of this study is to develop an FTC method based on meta-RL which allows skid-steering vehicles to adapt to different types of fault situations. From the analysis above, meta-training multiple initial models and selecting the most suitable one could more quickly and better optimize a policy for the fault situation than using a single initial meta-trained model. The questions that arise here are how to meta-train multiple initial meta-trained models and how to select the most suitable one among them, based on the online dataset.
Based on the above motivation, we introduce a situation embedding model into the current meta-DDPG-based FTC framework, and develop a new FTC method, which achieves better performance on adapting different types of fault situations; namely meta-DDPGSE (meta-DDPG with situation embedding). The situation embedding model generates a d-dimensional vector, which is a specific parameter of meta-trained models, named situation-embeddings. We first apply the meta-DDPG algorithm to train multiple meta-trained models for different types of fault situations. Then, states and actions generated from the meta-trained models under the corresponding fault situations are used as the input for the situation embedding model in the offline stage. We can use the online data set as input for the situation embedding model, to select the most suitable meta-trained model for current fault situation as the starting point for online adaptation. In summary, we combine the meta-DDPG algorithm and the situation embedding model to facilitate rapid adaptation to the fault situation through selection of the most suitable initial meta-trained model.
The main contributions of this study are as follows: (1) We develop a meta-DDPGSE-based FTC method for skid steering vehicles, which achieves high performance on different types of fault situations; (2) a situation embedding model is introduced into the conventional meta-RL-based FTC framework, in order to select the most suitable meta-trained model for the current fault situation; and (3) selecting the most suitable meta-trained model based on online data set allows the agent to quickly adapt the policy to different types of fault situations. To the best of our knowledge, this is the first work to introduce the situation embedding model into the meta-RL-based FTC framework and apply it to the FTC problem of skid-steering vehicles.
The remainder of this paper is structured as follows.
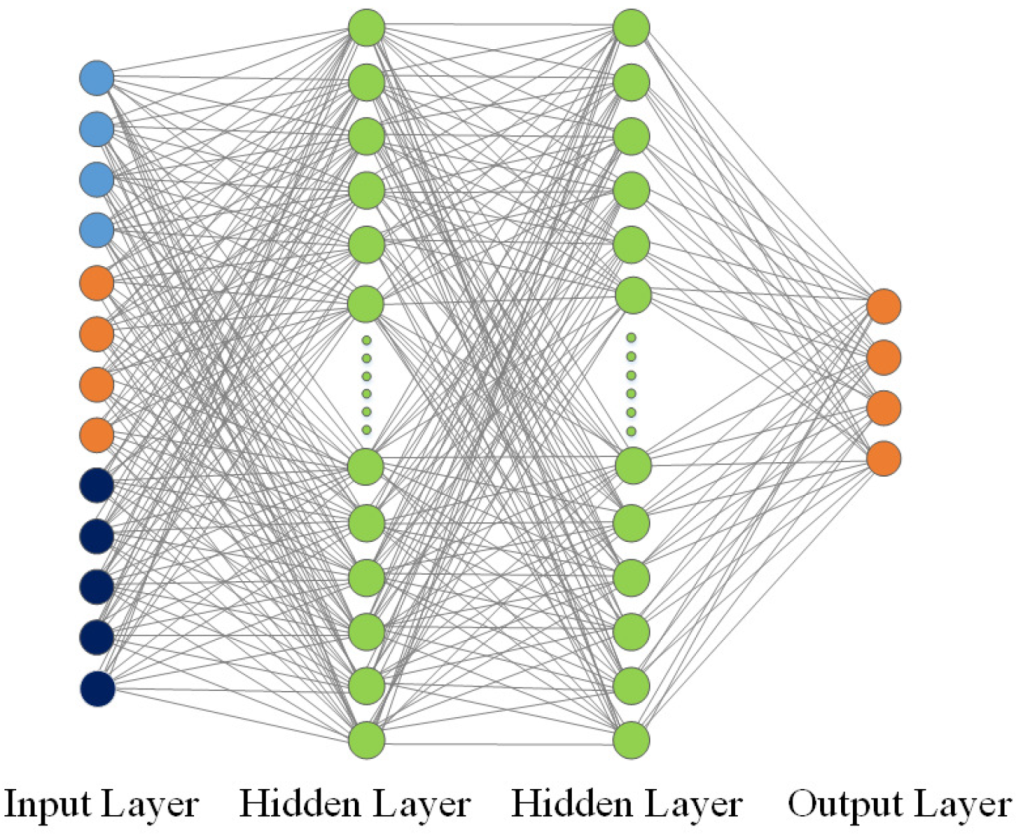
Section 2 introduces the torque distribution agent design and the problem formulation for the meta-DDPGSE-based FTC method.
Section 3 provides the framework of the meta-DDPGSE-based FTC method. In
Section 4, the simulation environment and setting are detailed. We validate the proposed method with simulation in
Section 5. Finally, our conclusions are provided in
Section 6.
5. Results
In this section, we evaluate the performance of the meta-DDPGSE-based FTC method through simulation, and compare it with the baseline methods. The baselines included the DDPG-based torque distribution controller and the meta-DDPG-based FTC method. The simulation was conducted in two scenarios: A straight scenario and a cornering scenario. In each scenario, we evaluated the proposed FTC method through its desired value tracking performance and the fine-tuning steps under fault situations. The study cases are listed in
Table 6:
As a commonly used evaluation method, the integrals of the quadratic function of the deviations of both the longitudinal speed and the yaw rate from the desired value were used to evaluate the longitudinal speed tracking performance and yaw rate tracking performance of vehicles. These two integrals are denoted as
and
, respectively [
40]:
5.1. Simulations in the Straight Scenario
Simulations in the straight scenario were performed with a constant zero steering angle, in order to identify the drifts of the faulty vehicle. Fault situations
and
were employed in the simulations. The simulation results for the straight scenario are shown in
Figure 7 and
Figure 8, respectively.
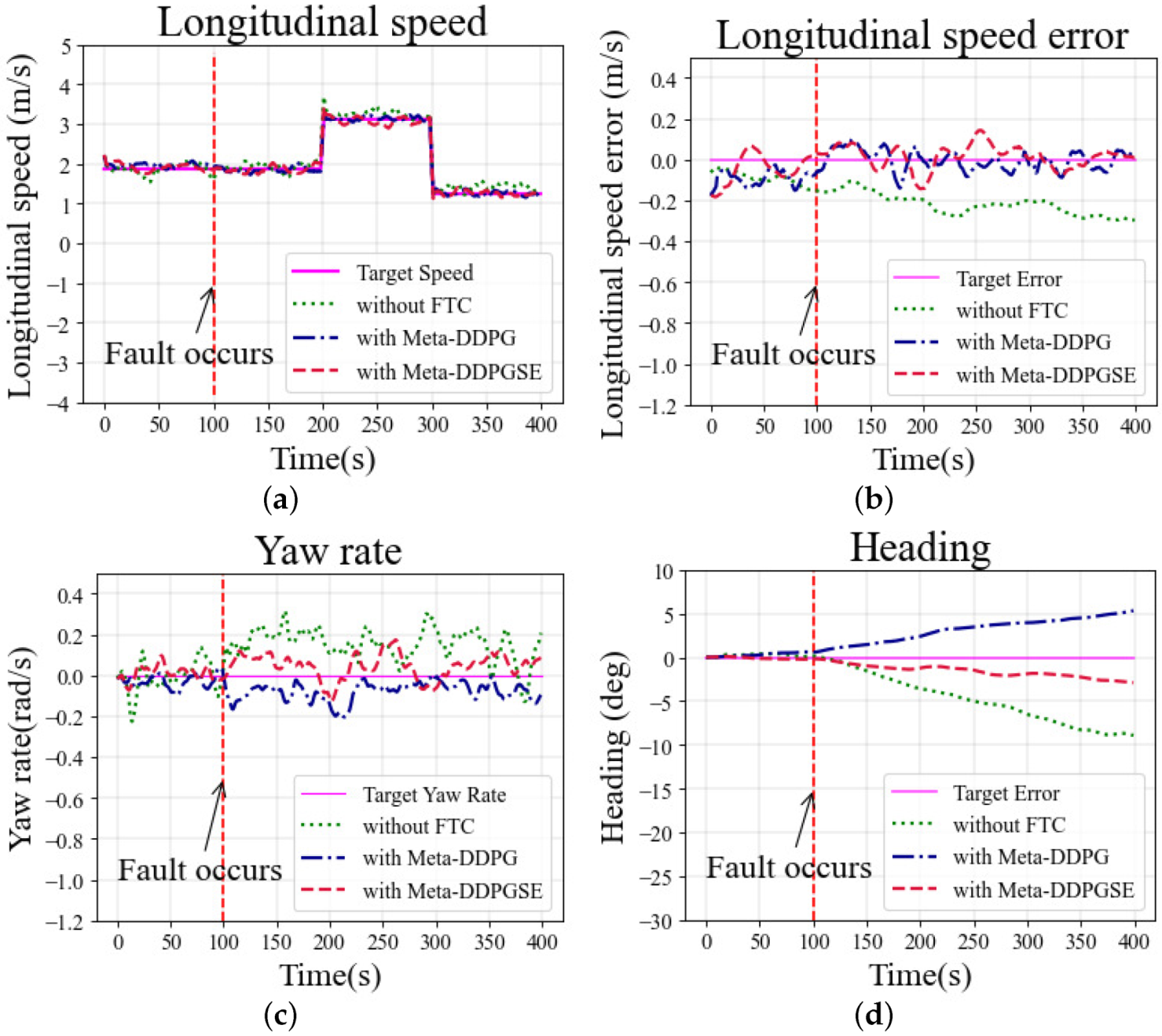
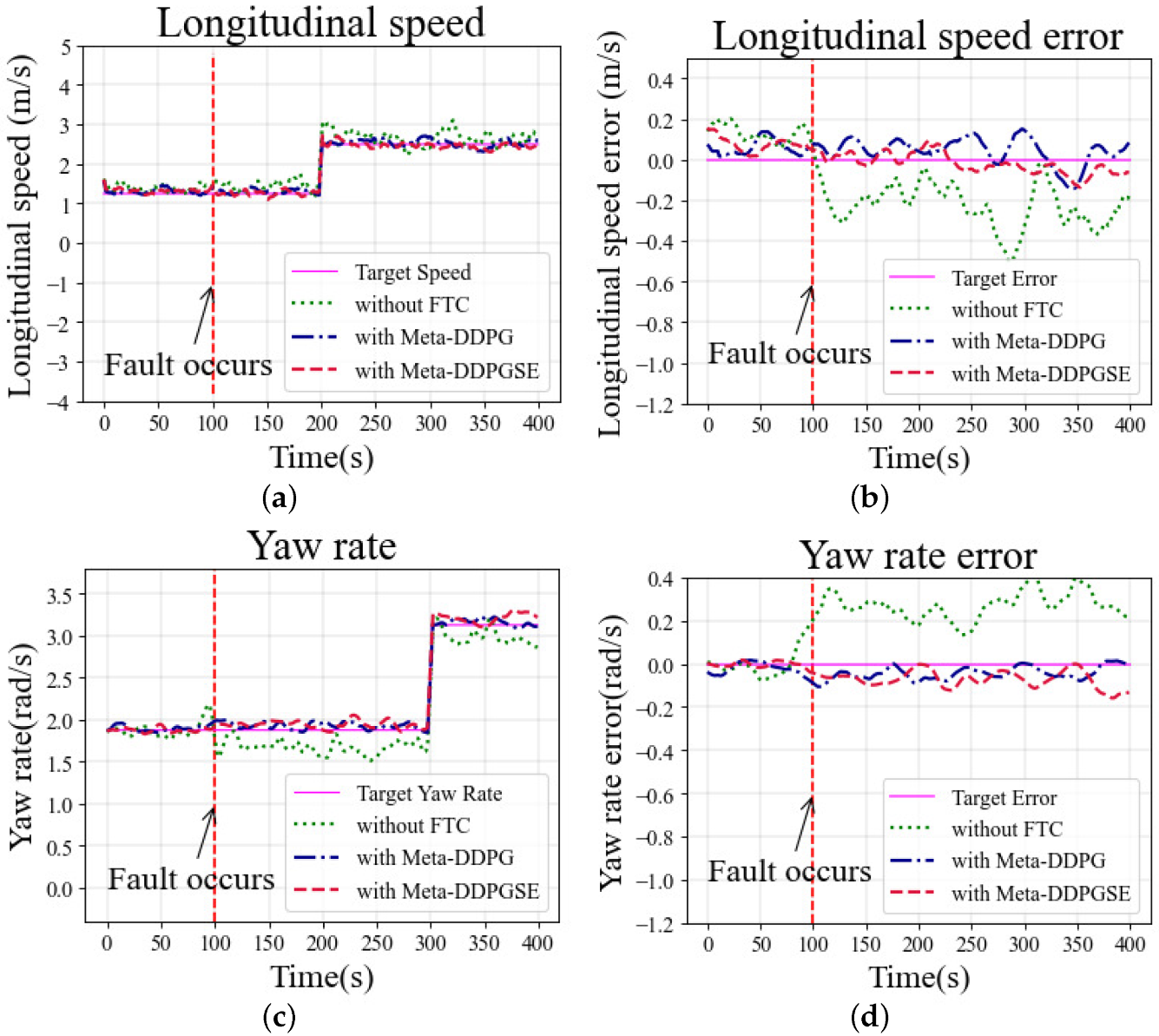
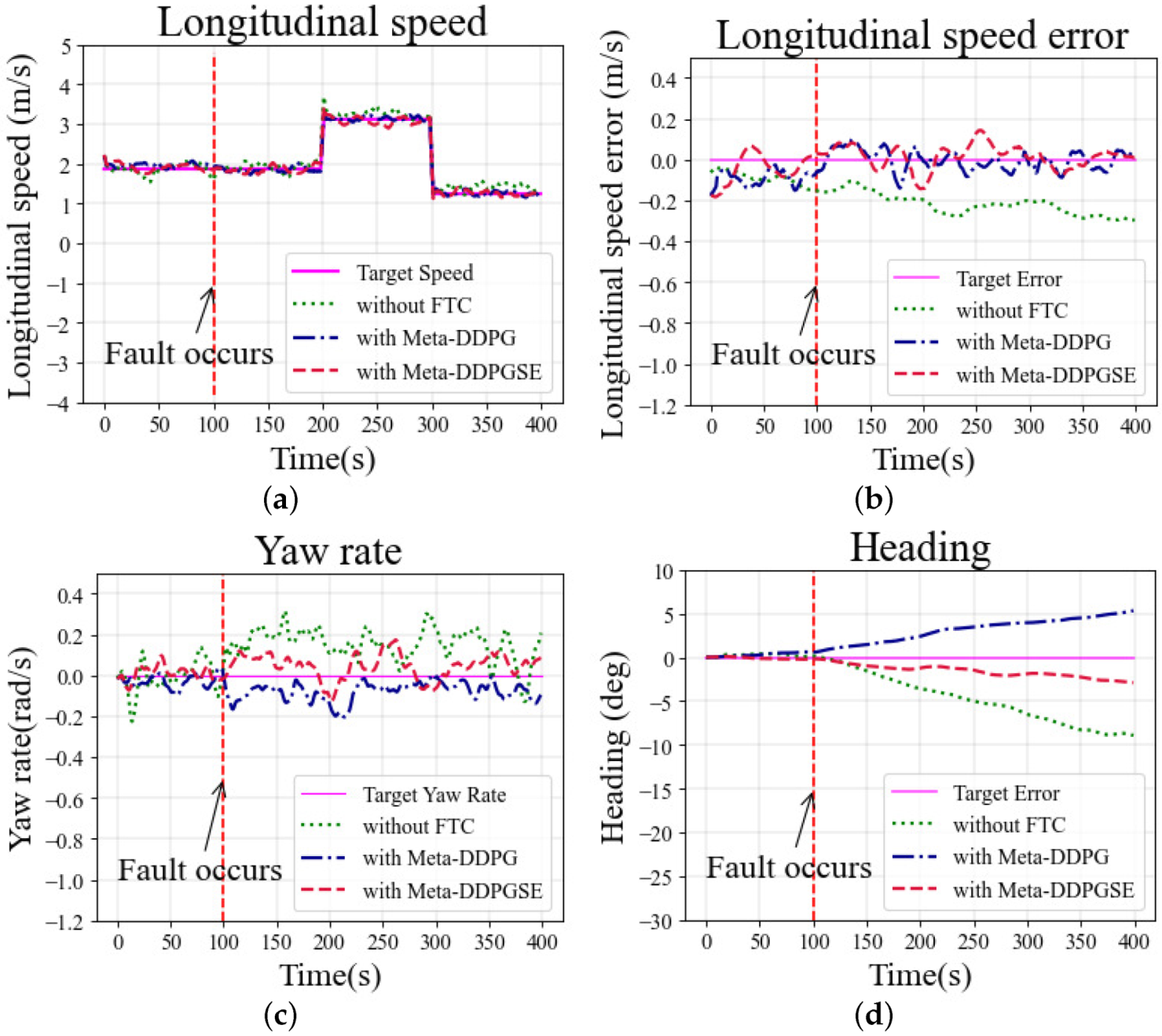
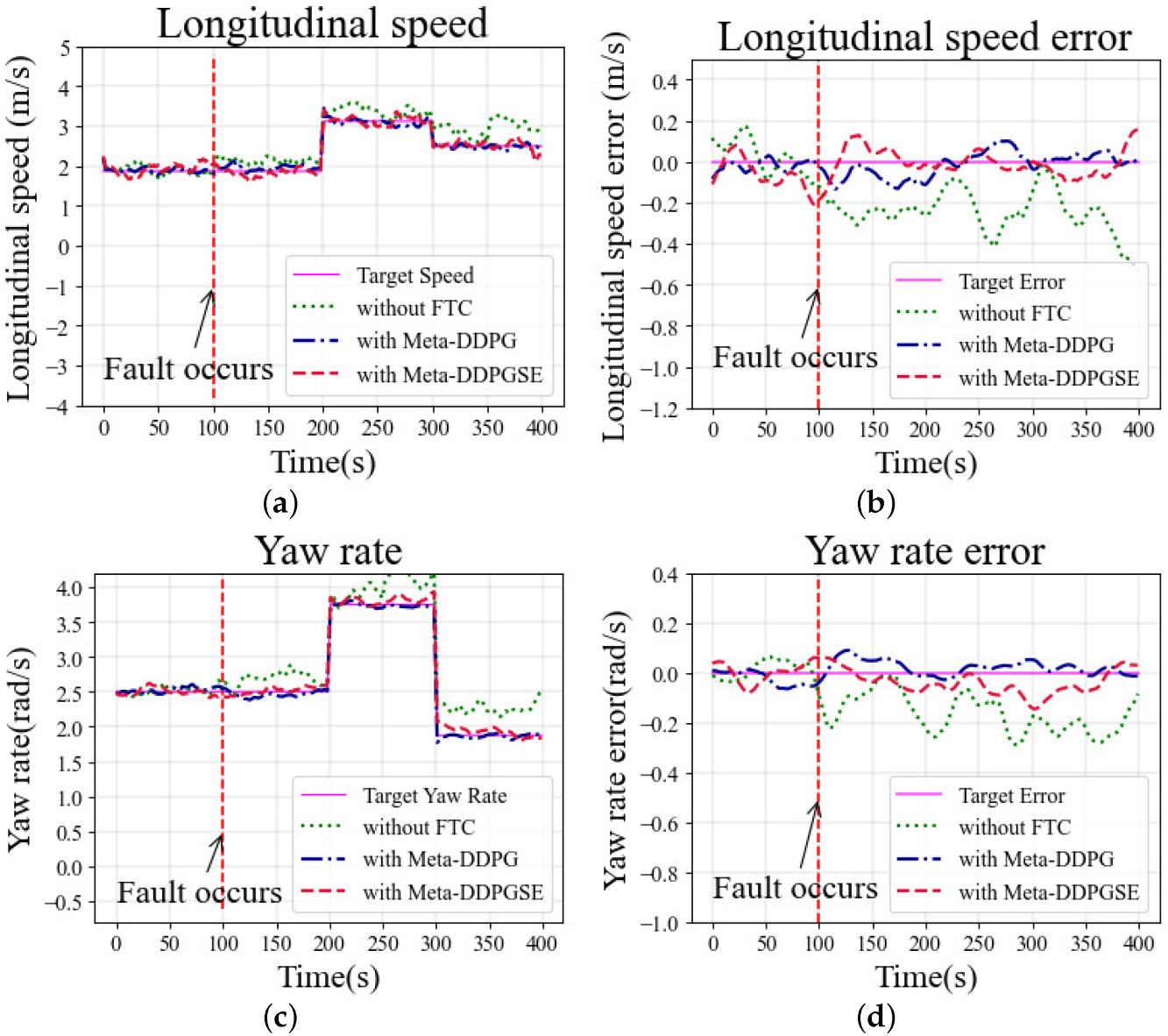
The longitudinal speed was set as 2.0 m/s at the beginning, 3.1 m/s at 200 s, and 1.2 m/s at 300 s, which was maintained until the end. The yaw rate was always 0 rad/s during the simulation in the straight scenario. The fault situation occurred at 100 s, and continued until the end of the simulation. The selected initial meta-trained model was fine-tuned for 200 steps to obtain a fine-tuned model, which was then used for vehicle control under fault situations.
The longitudinal speeds at different moments in the simulation are shown in
Figure 7a. As observed in
Figure 7b, the error in the case with the DDPG-based controller exceeded 0.2 m/s, significantly greater than in other cases. The yaw rates in different cases are shown in
Figure 7c. The desired yaw rate was zero in the straight scenario. The cases with FTC methods maintained the yaw rate error within 0.2 rad/s; however, without FTC, the error exceeded 0.2 rad/s and fluctuated more drastically than in other cases. As shown in
Figure 7d, the heading deviation was also larger in the case without FTC than other cases using FTC methods.
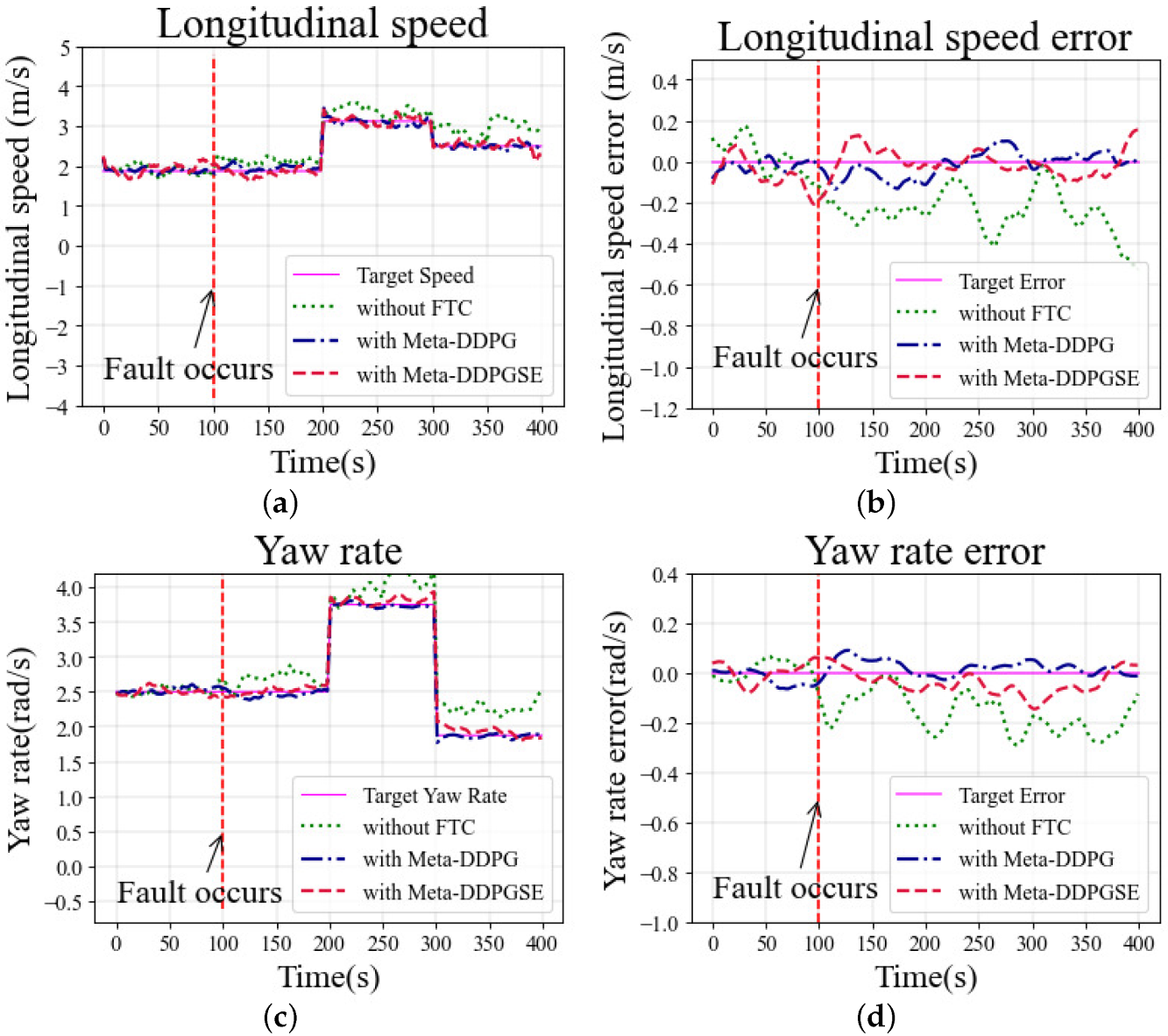
The second simulation in the straight scenario was conducted under fault situation
. The simulation results are shown in
Figure 8, which had a similar trend to the simulation of fault situation
. Without FTC, the longitudinal speed error exceeded 0.2 m/s after the fault occurred, and the maximum error even reached 0.4 m/s, as shown in
Figure 8a,b. The tracking performance showed no significant difference between cases with different FTC methods, and the errors in both cases were kept within 0.2 m/s, better than in the case without FTC. As observed in
Figure 8c, the yaw rate errors in the cases with FTC methods were kept within 0.2 rad/s; however, without FTC, the maximum error exceeded 0.2 rad/s during the simulation. From
Figure 8d, it can be observed that the heading deviation in the case without FTC exceeded 0.2 deg, which was greater than in other cases usingFTC methods. The above analysis indicates that both our proposed FTC method and the meta-DDPG-based FTC method worked well.
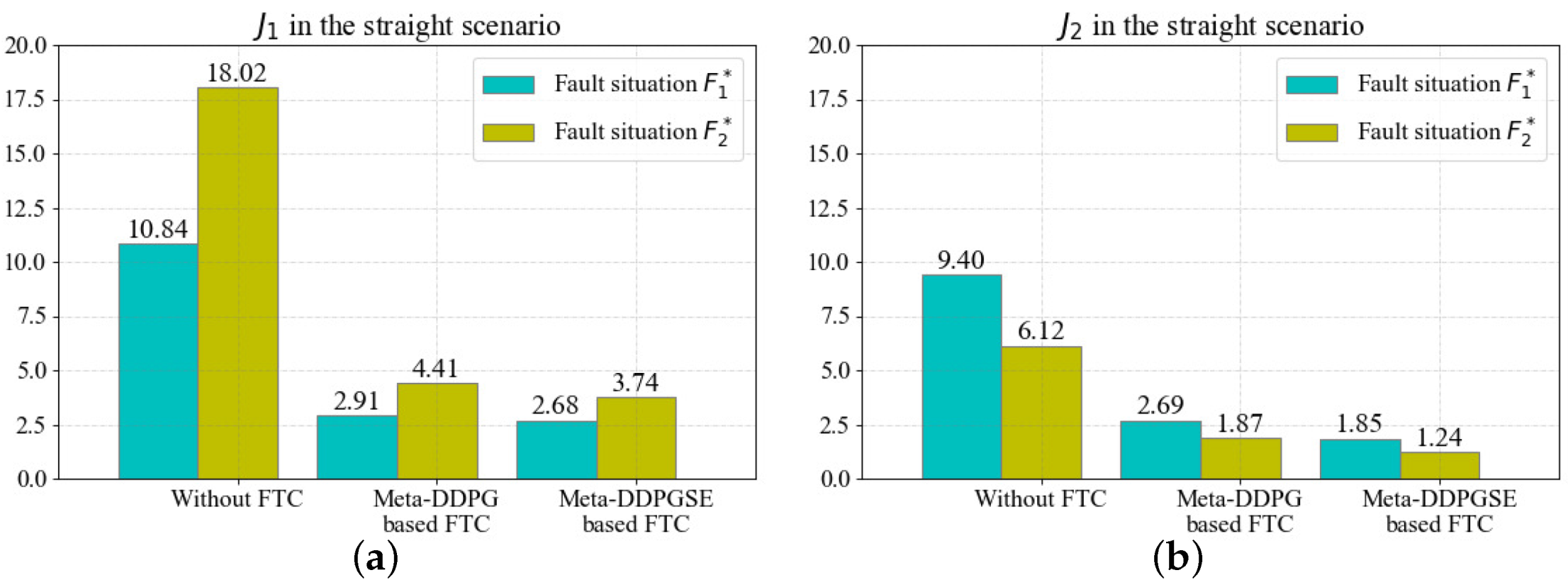
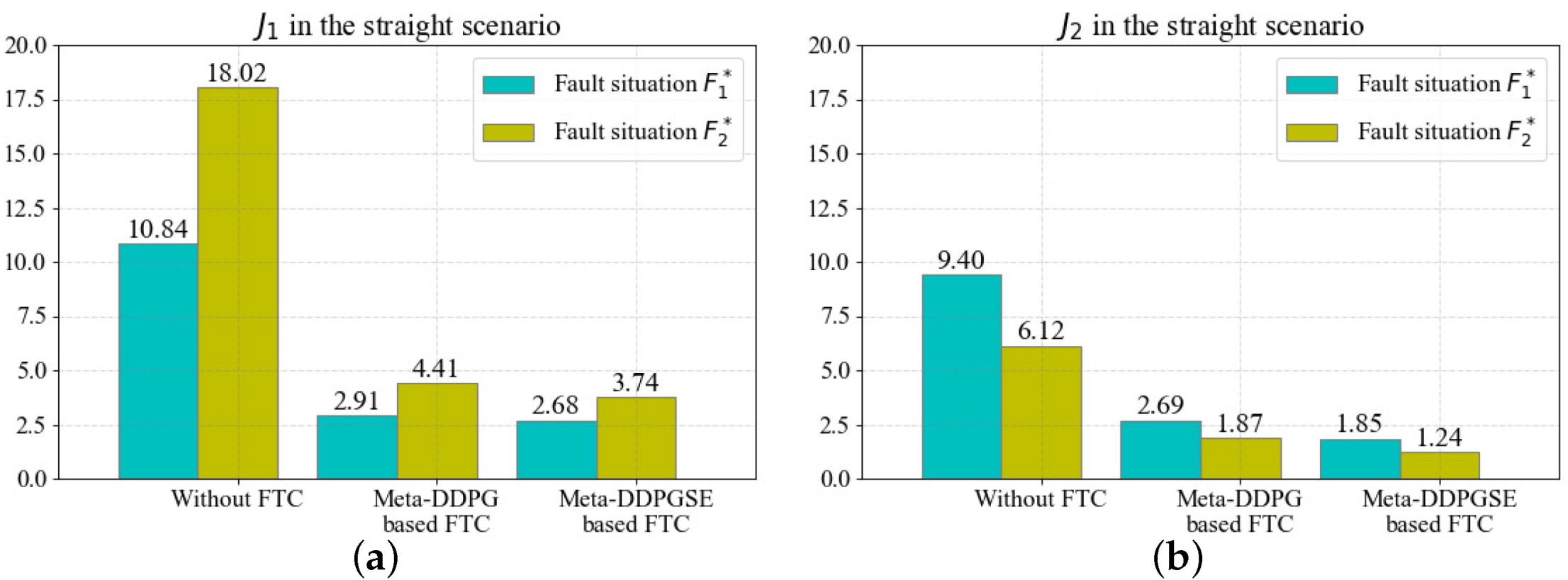
The above results show that fault situations severely affect the performance of desired value tracking, which can be overcome by the FTC methods. To illustrate the improvement when using our proposed FTC method more specifically, we quantitatively compared it with the meta-DDPG-based FTC method. Equation (
24) was used to evaluate the desired value tracking performance. The quantitative evaluation results in the straight scenario are displayed in
Figure 9.
The results for and in different cases were obtained based on the aforementioned simulations. The FTC method based on meta-DDPG reduced by in the fault situation and in the fault situation , and reduced by in the fault situation and in the fault situation . Similarly, the FTC method based on meta-DDPGSE reduced by in the fault situation and in the fault situation , and reduced by in the fault situation and in the fault situation . The quantitative evaluation results in the straight scenario demonstrate that both FTC methods can effectively reduce the severity of fault situations; however, the meta-DDPGSE-based FTC method performed better.
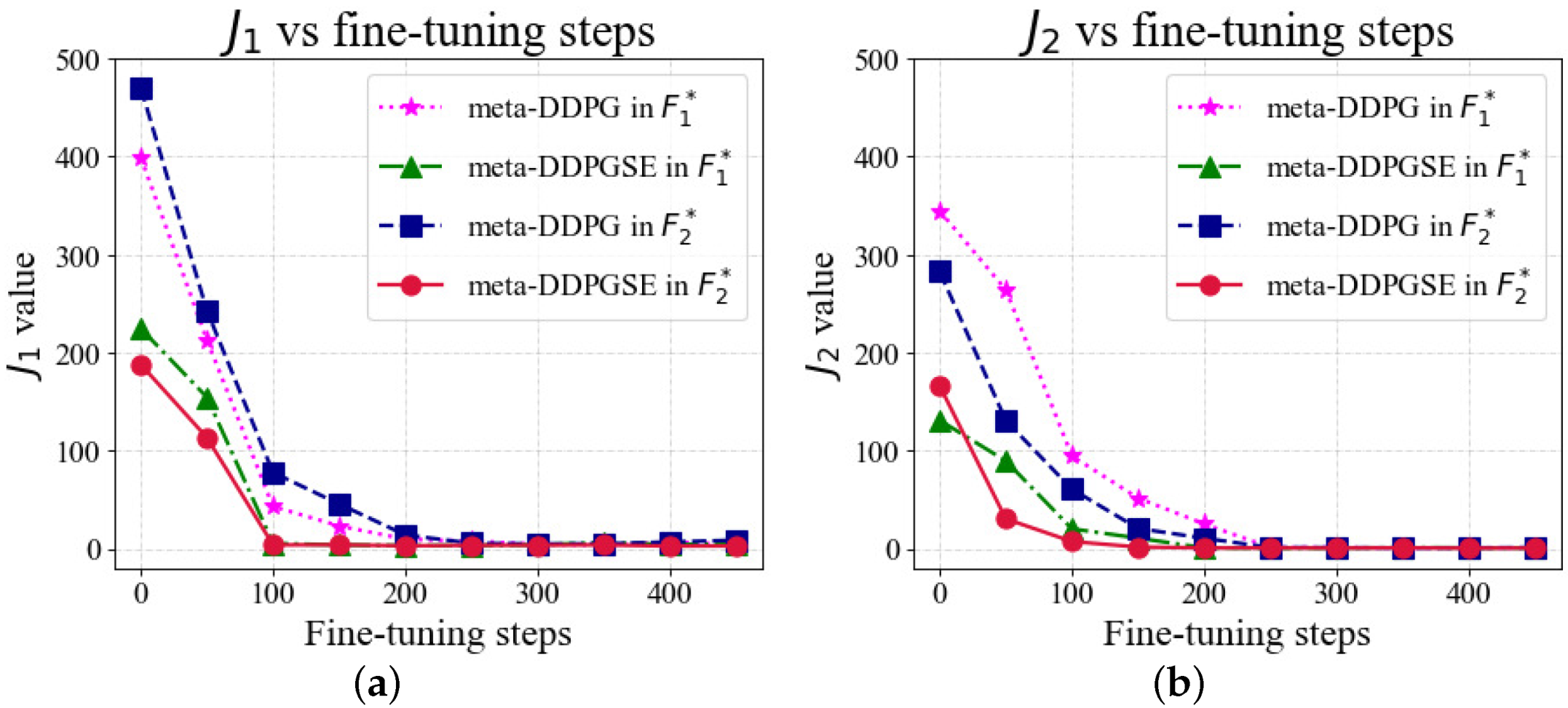
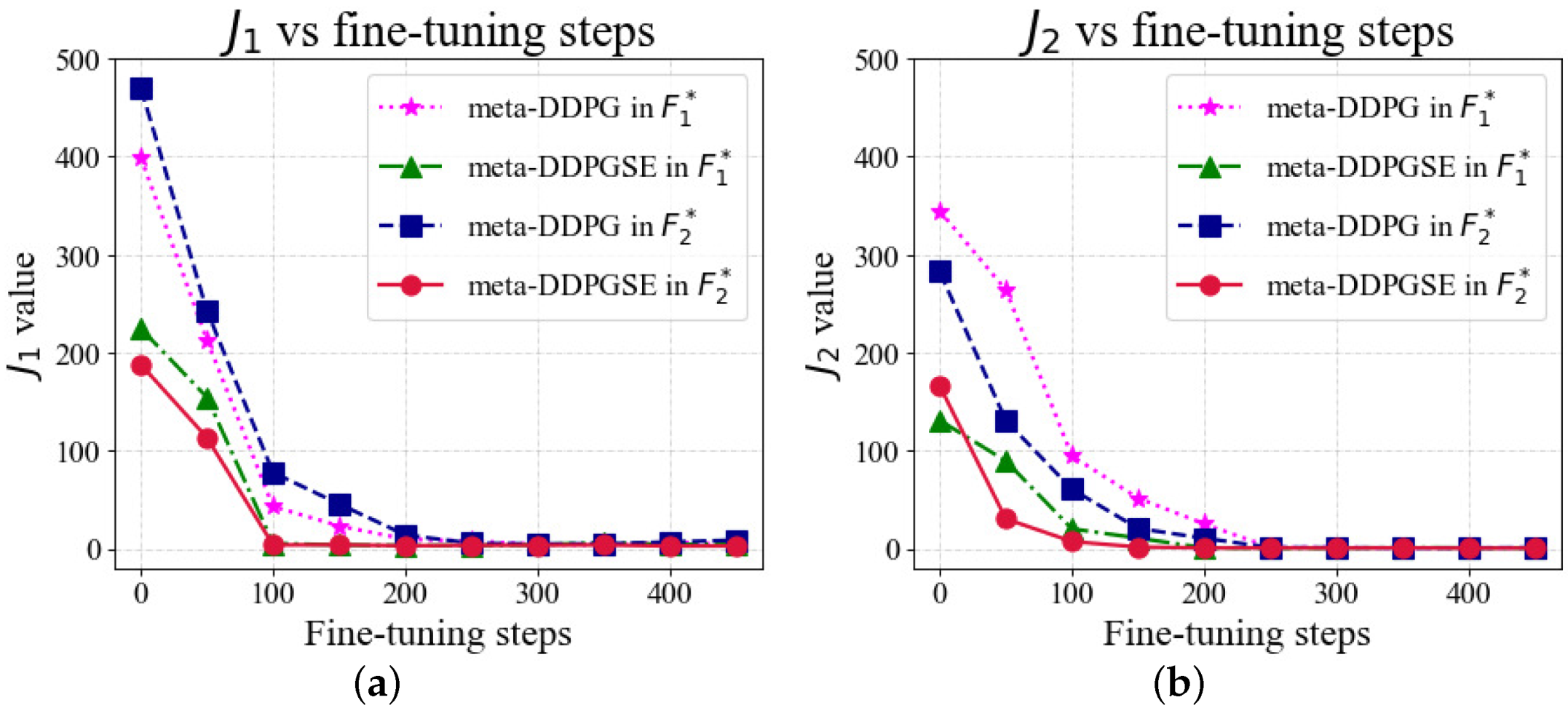
In the above simulations, the number of online fine-tuning steps of the meta-trained models was 200 in the different FTC methods. We also evaluated the online adaptation speed of different FTC methods through the effect of the online fine-tuning steps on the desired value tracking performance. In this simulation, vehicles were assigned the same desired values and fault situations and as in previous simulations, but we set different online fine-tuning steps. We analyzed and of the two FTC methods with numbers of different fine-tuning steps. When the number of fine-tuning steps was 0, the offline meta-trained model was directly used to control the vehicle after the fault occurred.
The simulation results are shown in
Figure 10. Each data point in the figure is an average of the same process repeated five times. When the number of fine-tuning steps was 0,
and
obtained by the meta-DDPGSE-based FTC method were significantly smaller than those obtained by the meta-DDPG-based FTC method. This result indicates that the meta-DDPGSE-based FTC method can select a suitable meta-trained model for the current fault situation as the starting point of online adaptation. The meta-DDPGSE-based FTC method could achieve high performance after 100 steps of online fine-tuning, while the meta-DDPG-based FTC method needed 200 steps to achieve the same results, thus demonstrating that the meta-DDPGSE-based FTC method was able to adapt to fault situations more quickly than the meta-DDPG-based FTC method.
5.2. Simulations in the Cornering Scenario
Simulations of the cornering scenario were conducted to identify the vehicle’s cornering ability under fault situations. The fault situations assigned to the vehicle were consistent with those in
Section 5.1 and are listed in
Table 3.
Figure 11 and
Figure 12 show the simulation results of the vehicle under fault situations
and
in the cornering scenarios, respectively.
The longitudinal speed tracking results for the vehicle with fault situation
in the cornering scenario are shown in
Figure 11a,b. Without FTC, the longitudinal speed fluctuated sharply, and the maximum error exceeded 0.4 m/s, significantly worse than that in the cases using FTC methods. With FTC, the longitudinal speed tracking performance in the fault situation did not deteriorate significantly, and errors remained within 0.2 m/s. The yaw rate tracking results are shown in
Figure 11c,d. After the fault situation
occurred, the desired yaw rates were still well-tracked in the cases with FTC methods. However, without FTC, the yaw rate fluctuated sharply, and the error became significantly larger, which demonstrates that the case without FTC had no ability to track the desired yaw rate after the fault occurred.
Similar trends were observed in the simulation with fault situation
in the cornering scenario, as shown in
Figure 12. Without FTC, the longitudinal speed and yaw rate fluctuated more severely after fault situation
occurred. The DDPG-based controller had no ability to track the desired value as accurately as before the fault situation
occurred. With FTC, the tracking performance of the longitudinal speed and yaw rate was not significantly degraded, being similar to the tracking performance before the fault situation
occurred. The longitudinal speed errors and yaw rate errors could be kept within 0.2 m/s and 0.2 rad/s, respectively. The results demonstrate that fault situations
and
can impose serious impacts on the desired value tracking performance; however, such impacts can be overcome by implementing FTC methods such as those based on meta-DDPG and meta-DDPGSE.
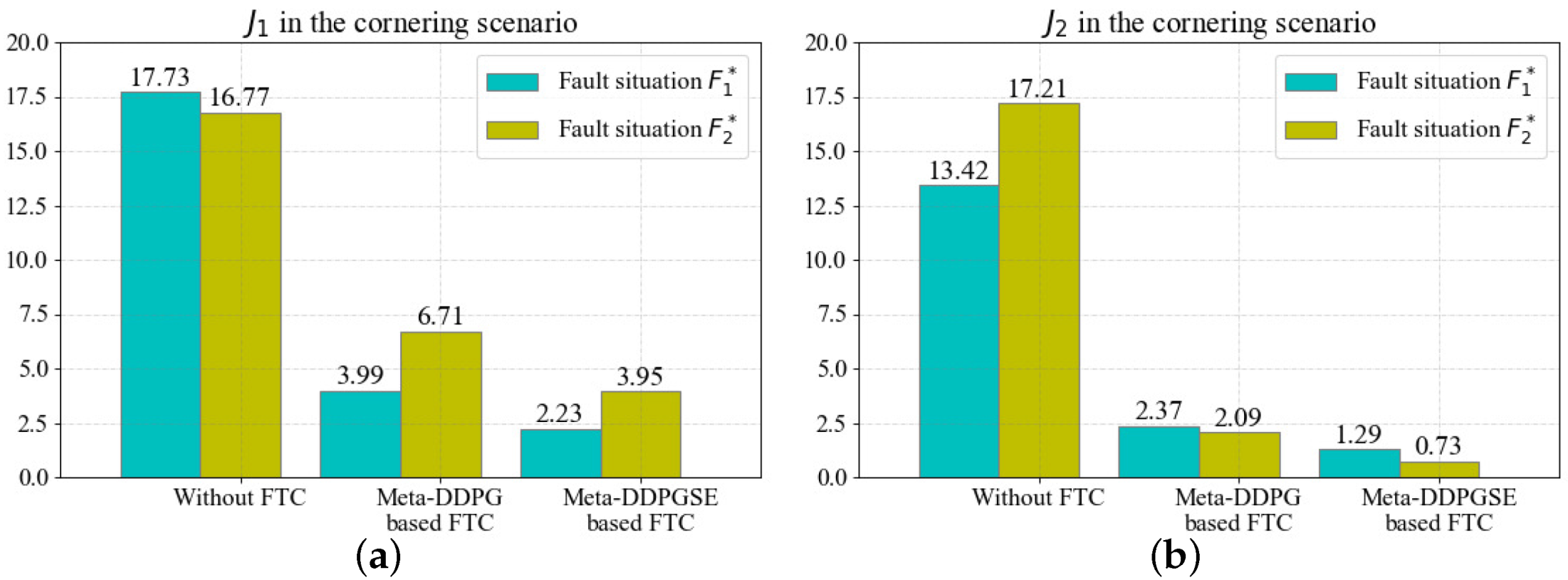
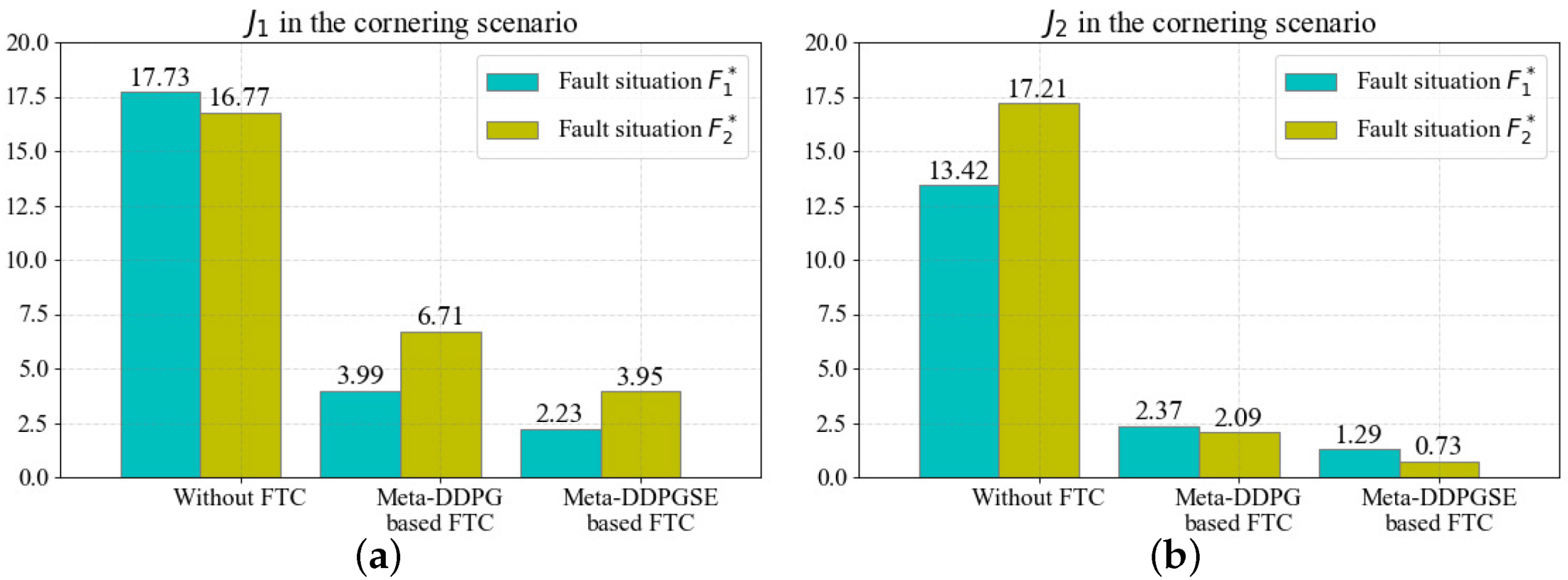
The results for
and
in the cornering scenario are shown in
Figure 13. The FTC method based on meta-DDPG reduced
by
in the fault situation
and
in the fault situation
, and reduced
by
in the fault situation
and
in the fault situation
. Similarly, the FTC method based on meta-DDPGSE reduced
by
in the fault situation
and
in the fault situation
, and reduced
by
in the fault situation
and
in the fault situation
. The quantitative evaluations in the cornering scenario had the same results as in the straight scenario, indicating that the FTC methods can effectively improve the tracking performance of vehicles with faults.
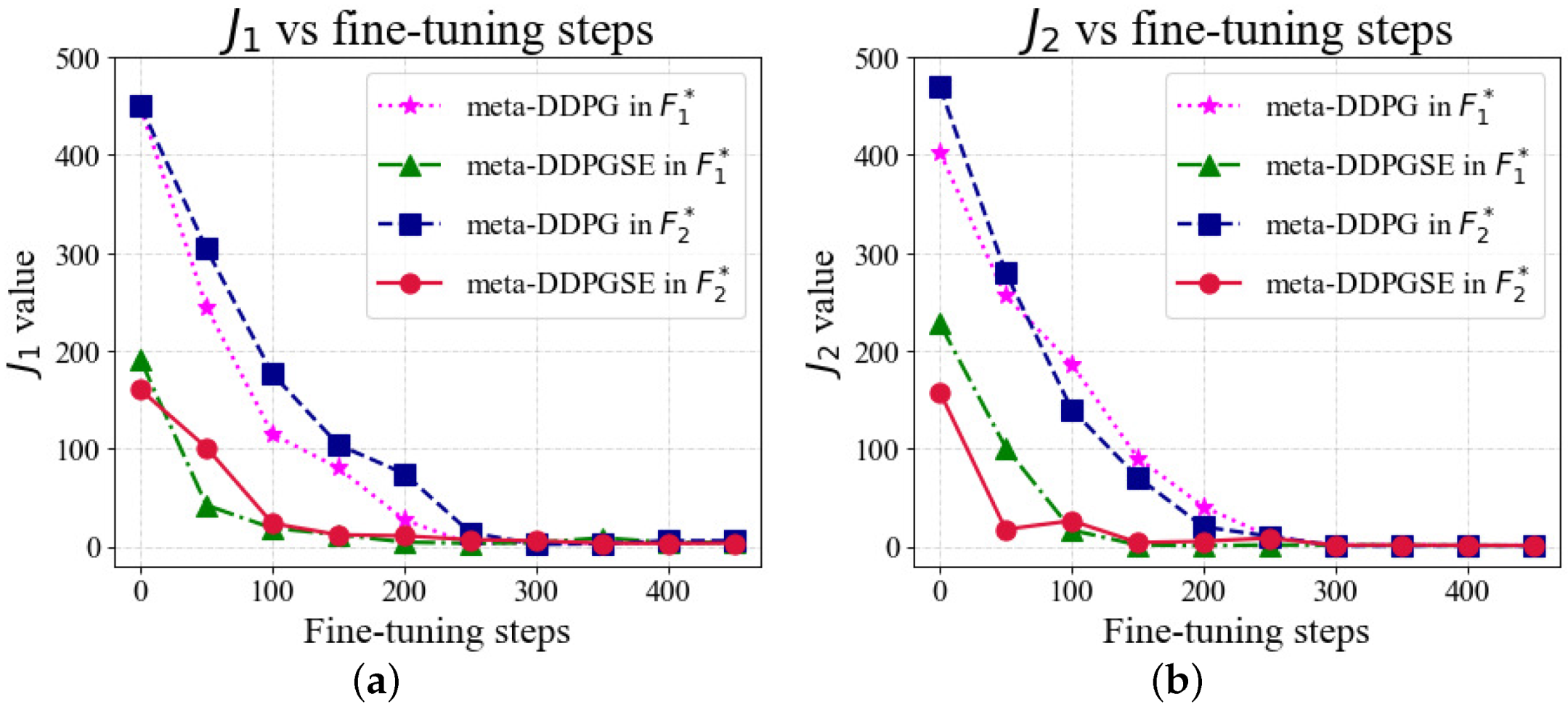
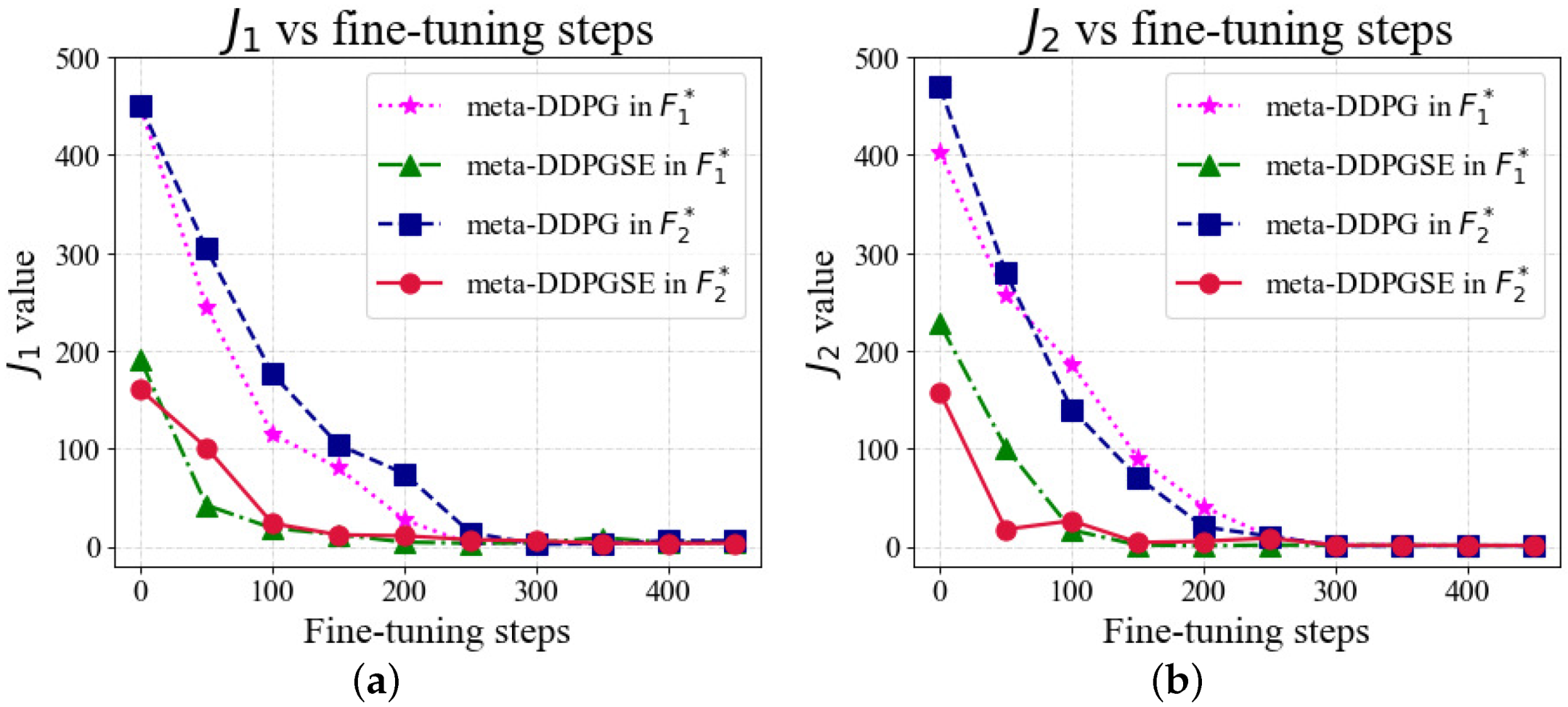
To better reflect the performance of our proposed FTC method, we set different numbers of online fine-tuning steps in the cornering scenario. The simulation results are shown in
Figure 14. As the number of fine-tuning steps increased,
and
decreased with a similar trend as in the straight scenario. The meta-DDPGSE-based FTC method had the ability to select a suitable meta-trained model as the starting point for online adaptation, according to the current fault situation. The meta-DDPGSE-based FTC method could obtain good testing error results after 100 steps of online fine-tuning, while the meta-DDPG-based FTC method needed 200 steps to achieve the same results. Therefore, the proposed FTC method benefits from the selection of the most suitable initial meta-trained model, which makes it able to more quickly adapt to fault situations than the meta-DDPG-based FTC method.
6. Conclusions
In this work, we proposed a meta-DDPGSE-based FTC method for skid-steering vehicles, which could maintain the desired value tracking performance under different types of fault situations. Based on the DDPG algorithm, we developed an agent that can perform dual-channel control over the longitudinal speed and yaw rate of skid steering vehicles. Differing from conventional meta-RL methods, which only use a single meta-trained model for the entire task distribution, multiple initial meta-trained models were trained for different types of fault situations in the offline stage. We introduced the situation embedding model into the current meta-DDPG-based framework and developed a new FTC method based on meta-DDPGSE. Based on the online data set, the situation embedding model could select the most suitable initial meta-trained model as the starting point for adapting to the current fault situation. The simulation results from four testing scenarios demonstrated that, thanks to the selection of the most suitable meta-trained model, the meta-DDPGSE-based FTC method was able to more quickly adapt different types of fault situations, performing better than the considered baseline methods.
This work opens an exciting path for the FTC method of skid-steering vehicles using meta-RL methods under multiple types of fault situations. At present, we are exploring ways to extend this work by incorporating fault detection techniques. We also plan to apply the proposed FTC method to different vehicle systems, such as independent driving electric vehicles, as they are also prone to different types of fault situations.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}