
Fixed-Time Incremental Neural Control for Manipulator Based on Composite Learning with Input Saturation



Abstract
1. Introduction
- A new INN adaptive algorithm based on the composite learning technique is designed. By dynamically generating network nodes and introducing some persistence conditions to adapt to the NN weights, the estimation error information can be properly integrated into the adaptive law, and the estimation performance is improved on the basis of relaxing the traditional PE conditions. Even though the works [14,15,16,17] studied composite learning control, they did not consider dynamically activating network nodes to adjust the NN input, let alone ensuring that the estimation error converged in a fixed time.
- In the framework of the backstepping composite learning approach, the challenge of devising a fixed-time controller with asymmetric actuator saturation of the manipulator system is effectively tackled. Although the authors in [18,19,22,23,24] considered the problem of actuator input saturation, they all solved symmetric saturation by introducing auxiliary systems, which is not tenable for the asymmetric scenario. Instead, this paper not only proposes a feasible asymmetric saturation control scheme, but also ensures fixed-time convergence under the composite learning framework.
2. System Description
3. Radial Basis Function NN Approximator
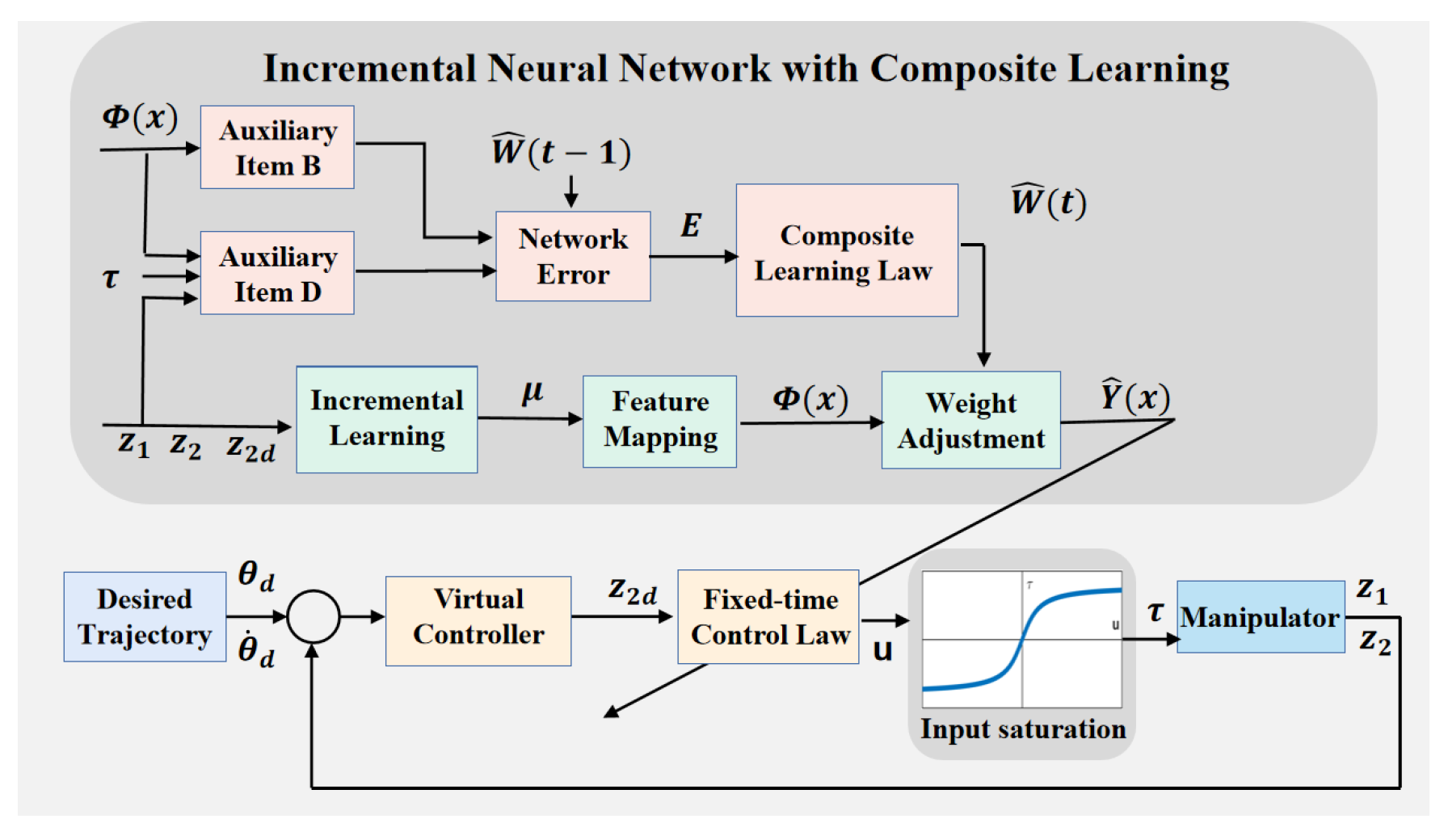
4. Controller Design and Stability Analysis
4.1. Controller Design
4.2. Stability Analysis
- (1)
- All the error signals are guaranteed to converge in a fixed time;
- (2)
- The position signal θ converges to a small neighborhood of the desired position in a fixed time;
- (3)
- The joint torque is guaranteed not to transgress the constraints sets.
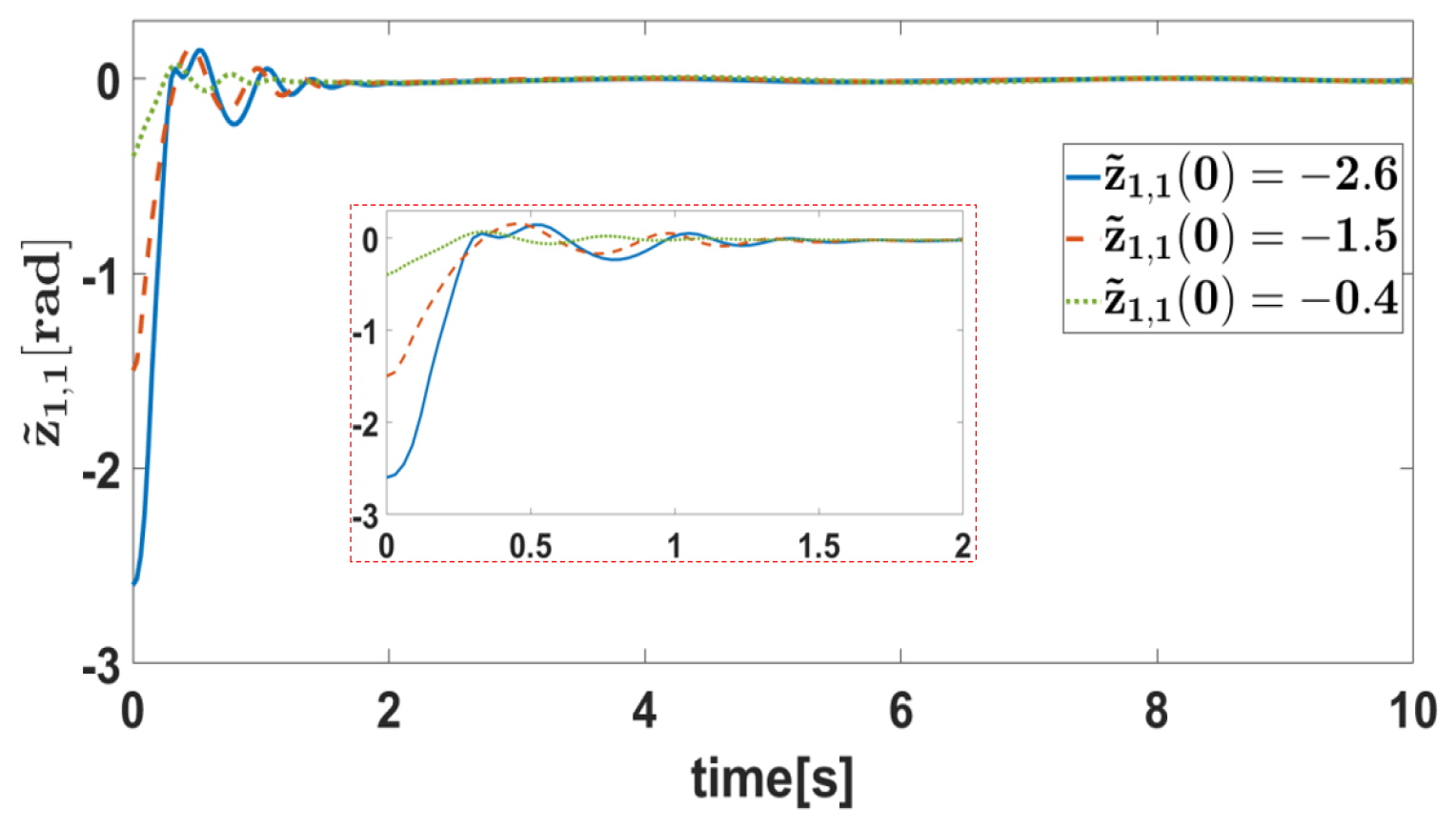
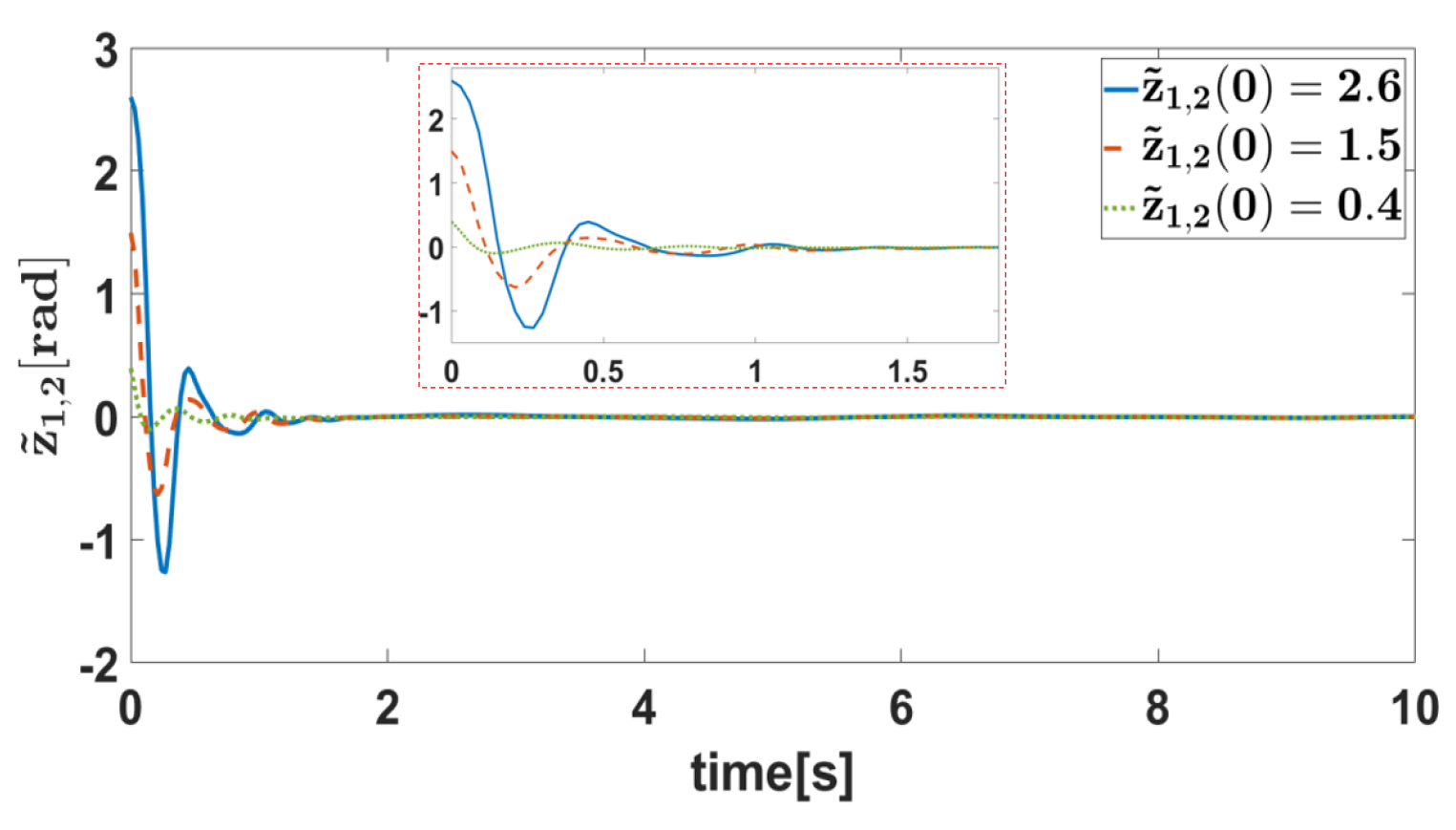
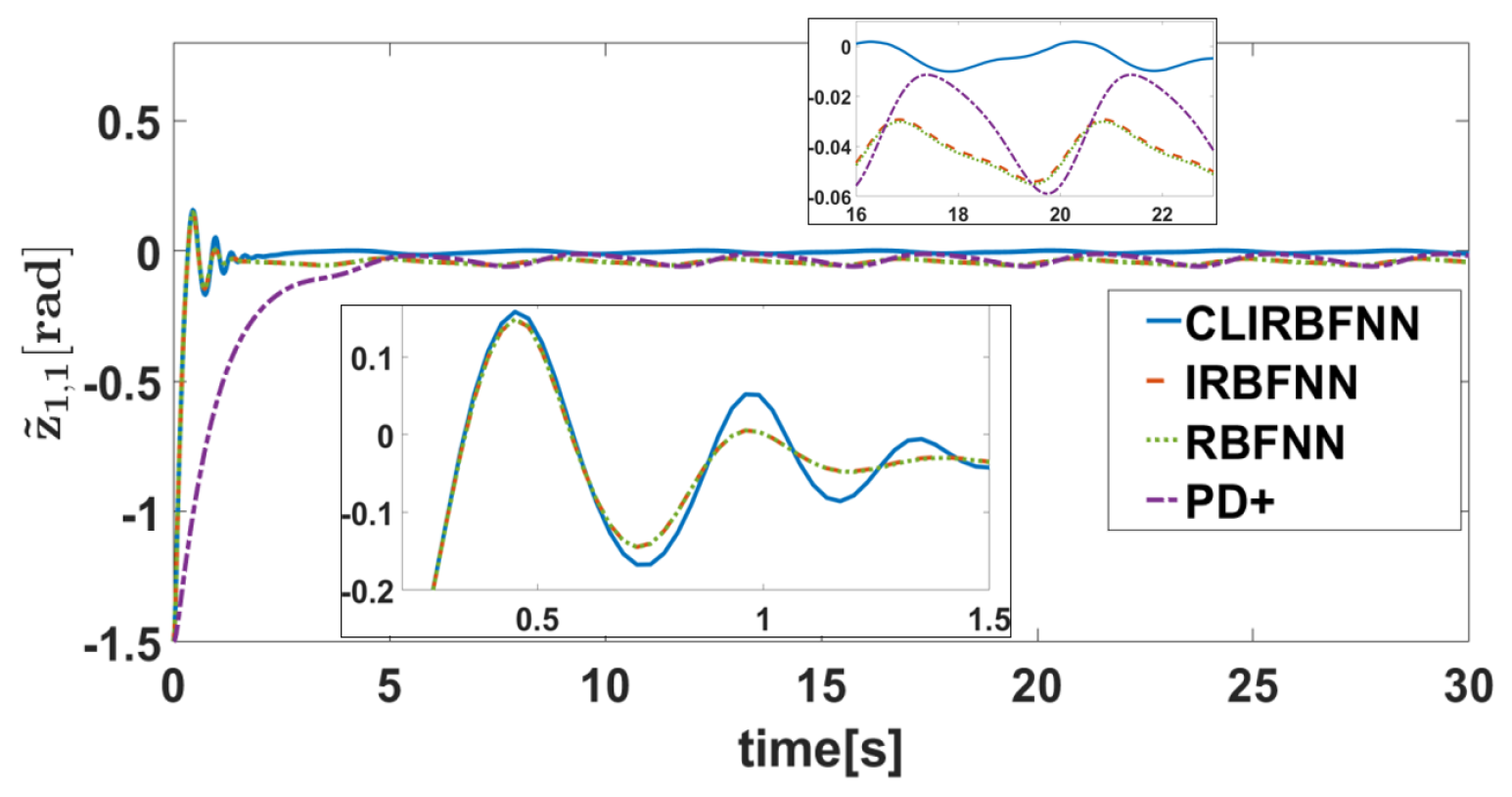
5. Simulation Verification
5.1. Simulation Settings
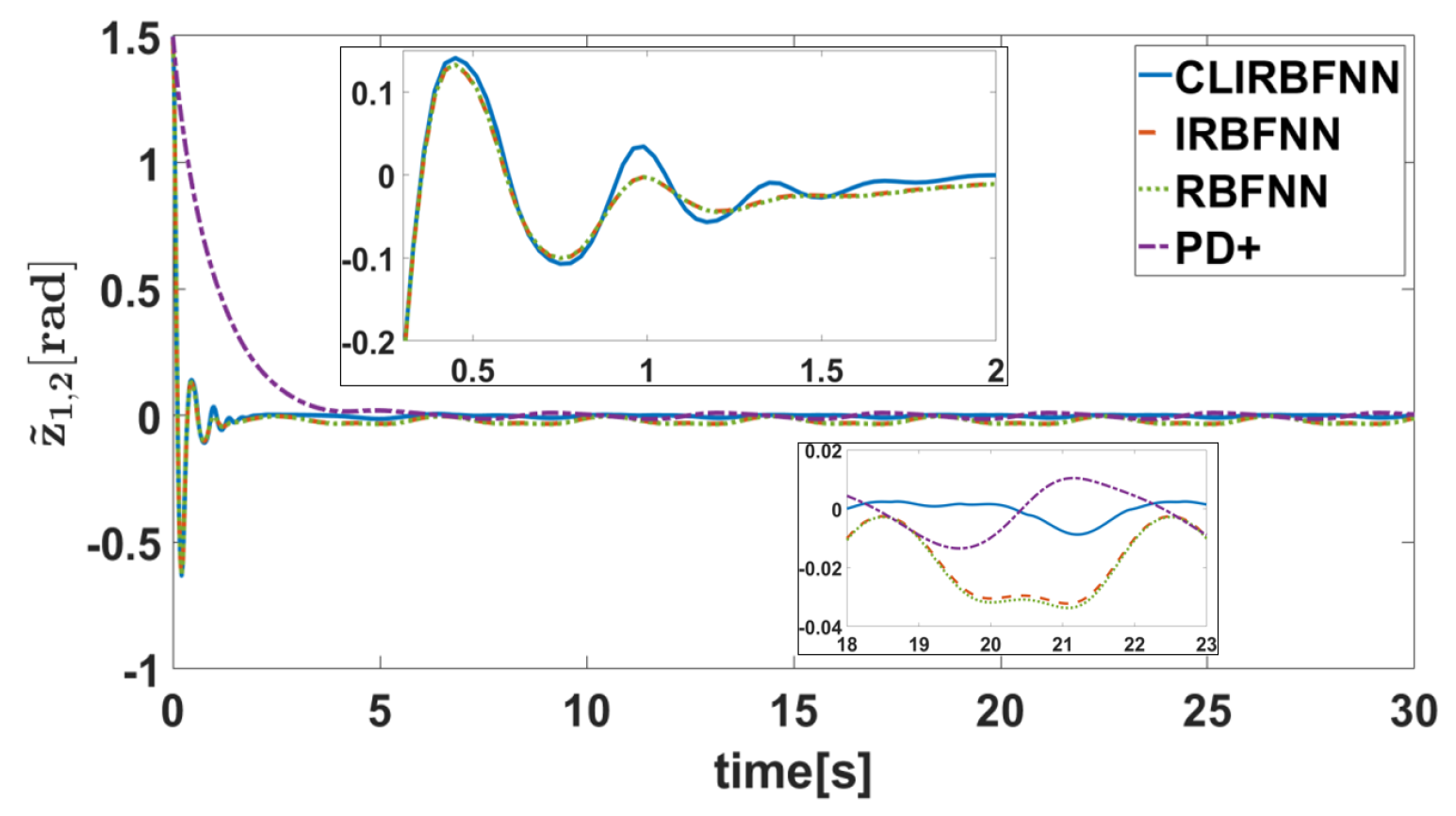
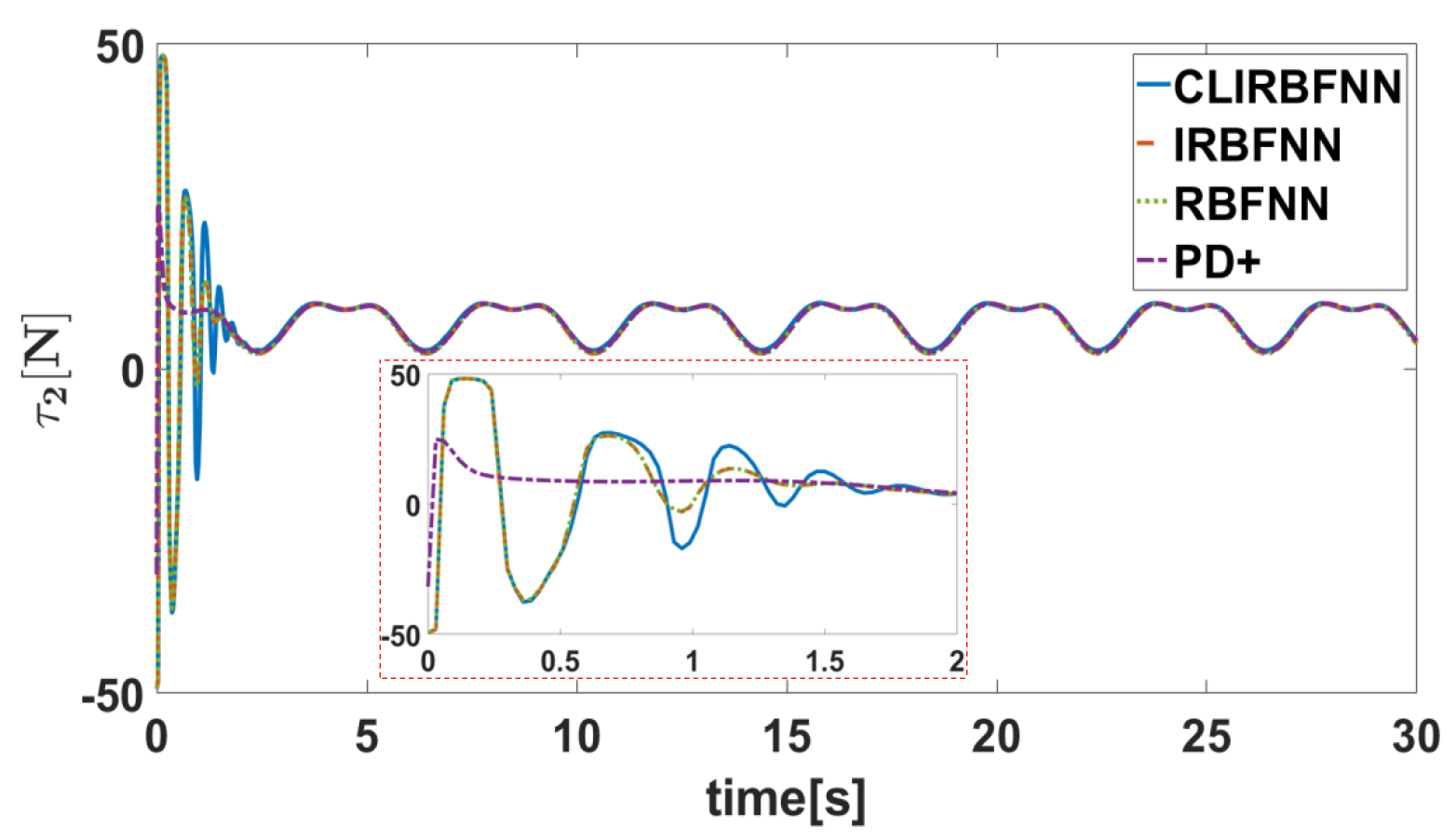
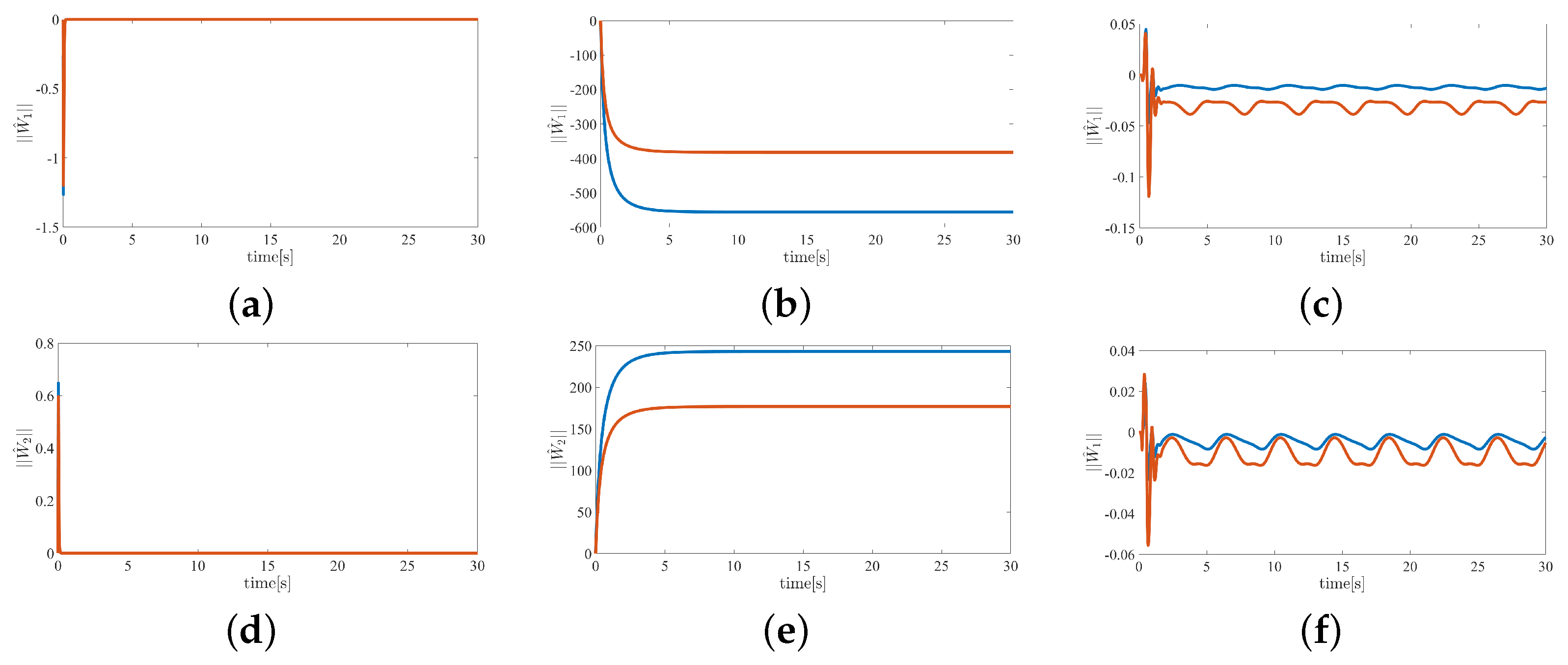
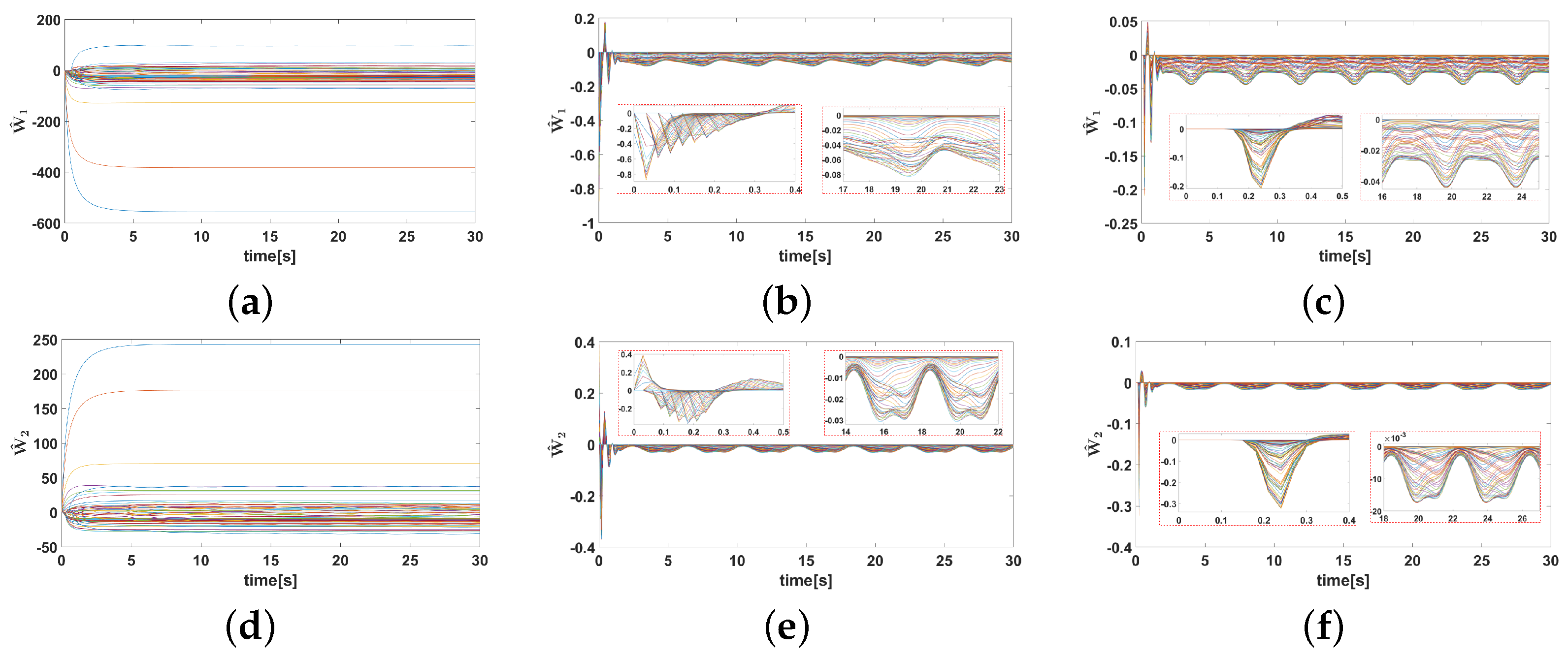
5.2. Result Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Z.; Huang, B.; Ajoudani, A.; Yang, C.; Su, C.; Bicchi, A. Asymmetric bimanual control of dual-arm exoskeletons for human-cooperative manipulations. IEEE Trans. Robot. 2017, 34, 264–271. [Google Scholar] [CrossRef]
- Li, R.; Qiao, H. A survey of methods and strategies for high-precision robotic grasping and assembly tasks—Some new trends. IEEE/ASME Trans. Mechatron. 2019, 24, 2718–2732. [Google Scholar] [CrossRef]
- Zeng, C.; Yang, C.; Chen, Z. Bio-inspired robotic impedance adaptation for human-robot collaborative tasks. Sci. China Inf. Sci. 2020, 63, 170201. [Google Scholar] [CrossRef]
- Lewis, F.L.; Liu, K.; Yesildirek, A. Neural net robot controller with guaranteed tracking performance. IEEE Trans. Neural Netw. 1995, 6, 703–715. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Liu, Y.; He, W.; Qiao, H.; Ji, H. Adaptive-neural-network-based trajectory tracking control for a nonholonomic wheeled mobile robot with velocity constraints. IEEE Trans. Ind. Electron. 2020, 68, 5057–5067. [Google Scholar] [CrossRef]
- Yang, C.; Chen, C.; He, W.; Cui, R.; Li, Z. Robot learning system based on adaptive neural control and dynamic movement primitives. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 777–787. [Google Scholar] [CrossRef]
- Zhao, K.; Song, Y. Neuroadaptive robotic control under time-varying asymmetric motion constraints: A feasibility-condition-free approach. IEEE Trans. Cybern. 2018, 50, 15–24. [Google Scholar] [CrossRef]
- Ma, Z.; Huang, P.; Kuang, Z. Fuzzy approximate learning-based sliding mode control for deploying tethered space robot. IEEE Trans. Fuzzy Syst. 2020, 29, 2739–2749. [Google Scholar] [CrossRef]
- Su, H.; Qi, W.; Chen, J.; Zhang, D. Fuzzy Approximation-based Task-Space Control of Robot Manipulators with Remote Center of Motion Constraint. IEEE Trans. Fuzzy Syst. 2022, 30, 1564–1573. [Google Scholar] [CrossRef]
- Yang, C.; Jiang, Y.; Na, J.; Li, Z.; Cheng, L.; Su, C. Finite-time convergence adaptive fuzzy control for dual-arm robot with unknown kinematics and dynamics. IEEE Trans. Fuzzy Syst. 2018, 27, 574–588. [Google Scholar] [CrossRef]
- Huang, H.; Zhang, T.; Yang, C.; Chen, C.P. Motor learning and generalization using broad learning adaptive neural control. IEEE Trans. Ind. Electron. 2019, 67, 8608–8617. [Google Scholar] [CrossRef]
- Miao, Z.; Liu, Y.; Wang, Y.; Chen, H.; Zhong, H.; Fierro, R. Consensus with persistently exciting couplings and its application to vision-based estimation. IEEE Trans. Cybern. 2019, 51, 2801–2812. [Google Scholar] [CrossRef]
- Wang, C.; Hill, D.J. Learning from neural control. IEEE Trans. Neural Netw. 2006, 17, 130–146. [Google Scholar] [CrossRef]
- Yang, C.; Teng, T.; Xu, B.; Li, Z.; Na, J.; Su, C. Global adaptive tracking control of robot manipulators using neural networks with finite-time learning convergence. Int. J. Control Autom. Syst. 2017, 15, 1916–1924. [Google Scholar] [CrossRef]
- Wang, C.; Wang, M.; Liu, T.; Hill, D.J. Learning from ISS-modular adaptive NN control of nonlinear strict-feedback systems. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1539–1550. [Google Scholar] [CrossRef]
- Pan, Y.; Sun, T.; Liu, Y.; Yu, H. Composite learning from adaptive backstepping neural network control. Neural Netw. 2017, 95, 134–142. [Google Scholar] [CrossRef]
- Guo, K.; Pan, Y.; Yu, H. Composite learning robot control with friction compensation: A neural network-based approach. IEEE Trans. Ind. Electron. 2018, 66, 7841–7851. [Google Scholar] [CrossRef]
- Chen, M.; Ge, S.S.; Ren, B. Adaptive tracking control of uncertain MIMO nonlinear systems with input constraints. Automatica 2011, 47, 452–465. [Google Scholar] [CrossRef]
- Bai, W.; Zhou, Q.; Li, T.; Li, H. Adaptive reinforcement learning neural network control for uncertain nonlinear system with input saturation. IEEE Trans. Cybern. 2019, 50, 3433–3443. [Google Scholar] [CrossRef]
- Wen, C.; Zhou, J.; Liu, Z.; Su, H. Robust adaptive control of uncertain nonlinear systems in the presence of input saturation and external disturbance. IEEE Trans. Autom. Control 2011, 56, 1672–1678. [Google Scholar] [CrossRef]
- Zhou, Q.; Wang, L.; Wu, C.; Li, H.; Du, H. Adaptive fuzzy control for nonstrict-feedback systems with input saturation and output constraint. IEEE Trans. Syst. Man Cybern. Syst. 2016, 47, 1–12. [Google Scholar] [CrossRef]
- He, W.; Dong, Y.; Sun, C. Adaptive neural impedance control of a robotic manipulator with input saturation. IEEE Trans. Syst. Man Cybern. Syst. 2015, 46, 334–344. [Google Scholar] [CrossRef]
- Du, J.; Hu, X.; Krstić, M.; Sun, Y. Robust dynamic positioning of ships with disturbances under input saturation. Automatica 2016, 73, 207–214. [Google Scholar] [CrossRef]
- Li, Y.; Wang, T.; Liu, W.; Tong, S. Neural network adaptive output-feedback optimal control for active suspension systems. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 4021–4032. [Google Scholar] [CrossRef]
- Bhat, S.P.; Bernstein, D.S. Finite-time stability of continuous autonomous systems. SIAM J. Control Optim. 2000, 38, 751–766. [Google Scholar] [CrossRef]
- Cui, B.; Xia, Y.; Liu, K.; Shen, G. Finite-time tracking control for a class of uncertain strict-feedback nonlinear systems with state constraints: A smooth control approach. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4920–4932. [Google Scholar] [CrossRef]
- Wang, F.; Chen, B.; Lin, C.; Zhang, J.; Meng, X. Adaptive neural network finite-time output feedback control of quantized nonlinear systems. IEEE Trans. Cybern. 2017, 48, 1839–1848. [Google Scholar] [CrossRef]
- Fan, Y.; Li, Y.; Tong, S. Adaptive finite-time fault-tolerant control for interconnected nonlinear systems. Int. J. Robust Nonlinear Control 2021, 31, 1564–1581. [Google Scholar] [CrossRef]
- Lv, M.; Li, Y.; Pan, W.; Baldi, S. Finite-time fuzzy adaptive constrained tracking control for hypersonic flight vehicles with singularity-free switching. IEEE/ASME Trans. Mechatron. 2022, 27, 1594–1605. [Google Scholar] [CrossRef]
- Polyakov, A. Nonlinear feedback design for fixed-time stabilization of linear control systems. IEEE Trans. Autom. Control 2011, 57, 2106–2110. [Google Scholar] [CrossRef]
- Jin, X. Adaptive fixed-time control for MIMO nonlinear systems with asymmetric output constraints using universal barrier functions. IEEE Trans. Autom. Control 2018, 64, 3046–3053. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, F. Observer-based fixed-time neural control for a class of nonlinear systems. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 2892–2902. [Google Scholar] [CrossRef]
- Huang, C.; Liu, Z.; Chen, C.P.; Zhang, Y. Adaptive Fixed-Time Neural Control for Uncertain Nonlinear Multiagent Systems. IEEE Trans. Neural Netw. Learn. Syst. 2022. early access. [Google Scholar] [CrossRef]
- He, W.; Kang, F.; Kong, L.; Feng, Y.; Cheng, G.; Sun, C. Vibration Control of a Constrained Two-Link Flexible Robotic Manipulator With Fixed-Time Convergence. IEEE Trans. Cybern. 2021, 52, 5973–5983. [Google Scholar] [CrossRef]
- Huang, H.; Lu, Z.; Wang, N.; Yang, C. Fixed-time Adaptive Neural Control for Robot Manipulators with Input Saturation and Disturbance. In Proceedings of the 2022 27th International Conference on Automation and Computing (ICAC), Bristol, UK, 1–3 September 2022; p. 22136904. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, Y.; Huang, H.; Yang, C. Fixed-Time Incremental Neural Control for Manipulator Based on Composite Learning with Input Saturation. Actuators 2022, 11, 373. https://doi.org/10.3390/act11120373
Fan Y, Huang H, Yang C. Fixed-Time Incremental Neural Control for Manipulator Based on Composite Learning with Input Saturation. Actuators. 2022; 11(12):373. https://doi.org/10.3390/act11120373
Chicago/Turabian StyleFan, Yanli, Haiqi Huang, and Chenguang Yang. 2022. "Fixed-Time Incremental Neural Control for Manipulator Based on Composite Learning with Input Saturation" Actuators 11, no. 12: 373. https://doi.org/10.3390/act11120373
APA StyleFan, Y., Huang, H., & Yang, C. (2022). Fixed-Time Incremental Neural Control for Manipulator Based on Composite Learning with Input Saturation. Actuators, 11(12), 373. https://doi.org/10.3390/act11120373