
HPV DeepSeq: An Ultra-Fast Method of NGS Data Analysis and Visualization Using Automated Workflows and a Customized Papillomavirus Database in CLC Genomics Workbench

Abstract
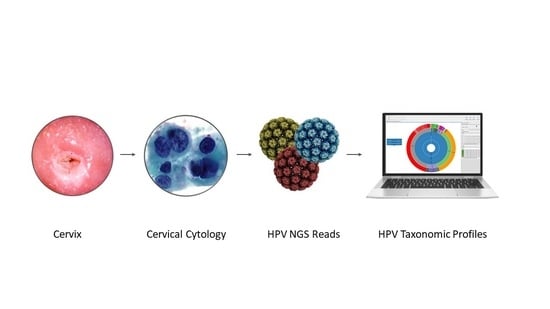
:
1. Introduction
2. Results
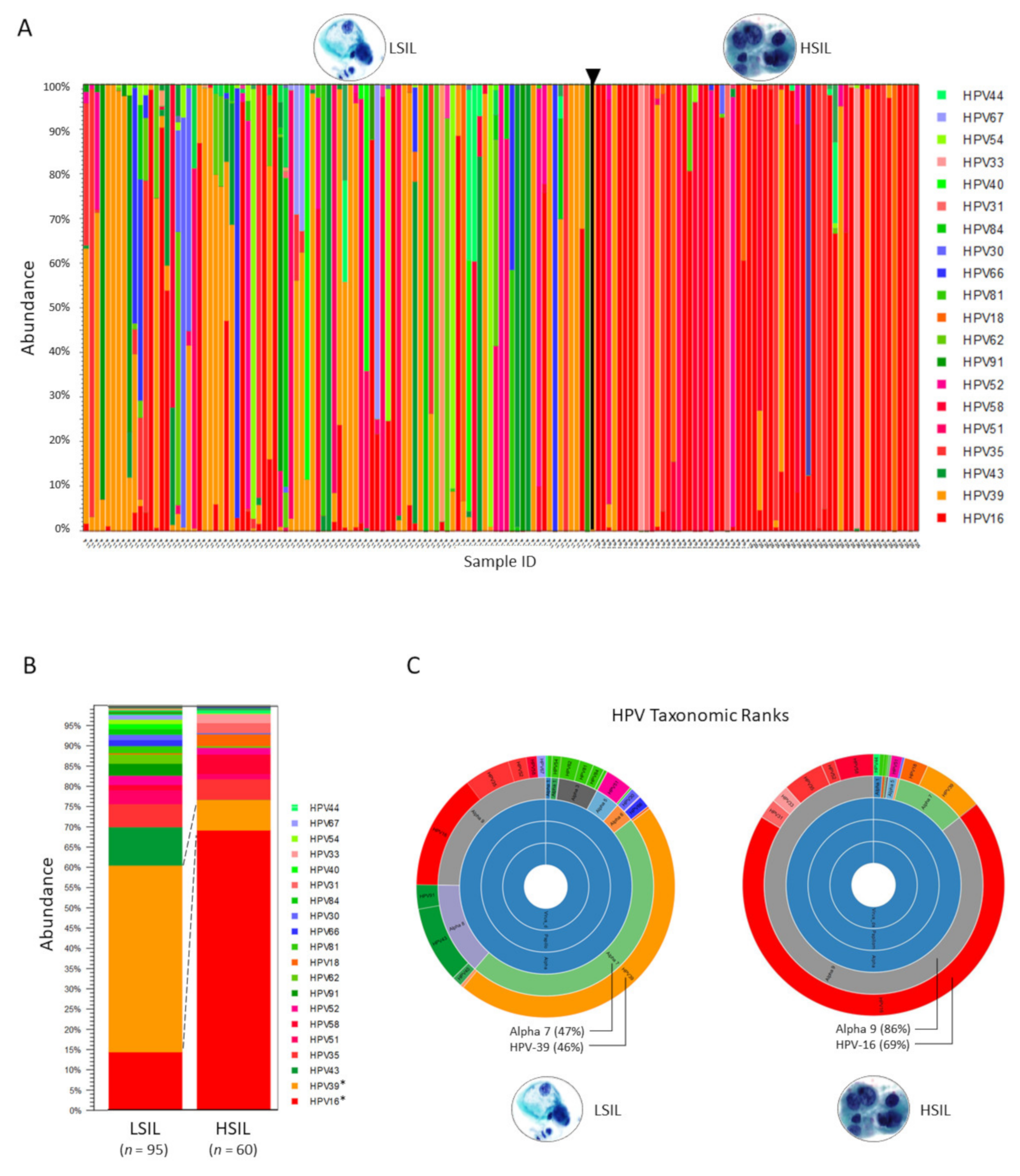
2.1. Taxonomic Classification and Visualization of HPV Metagenomes
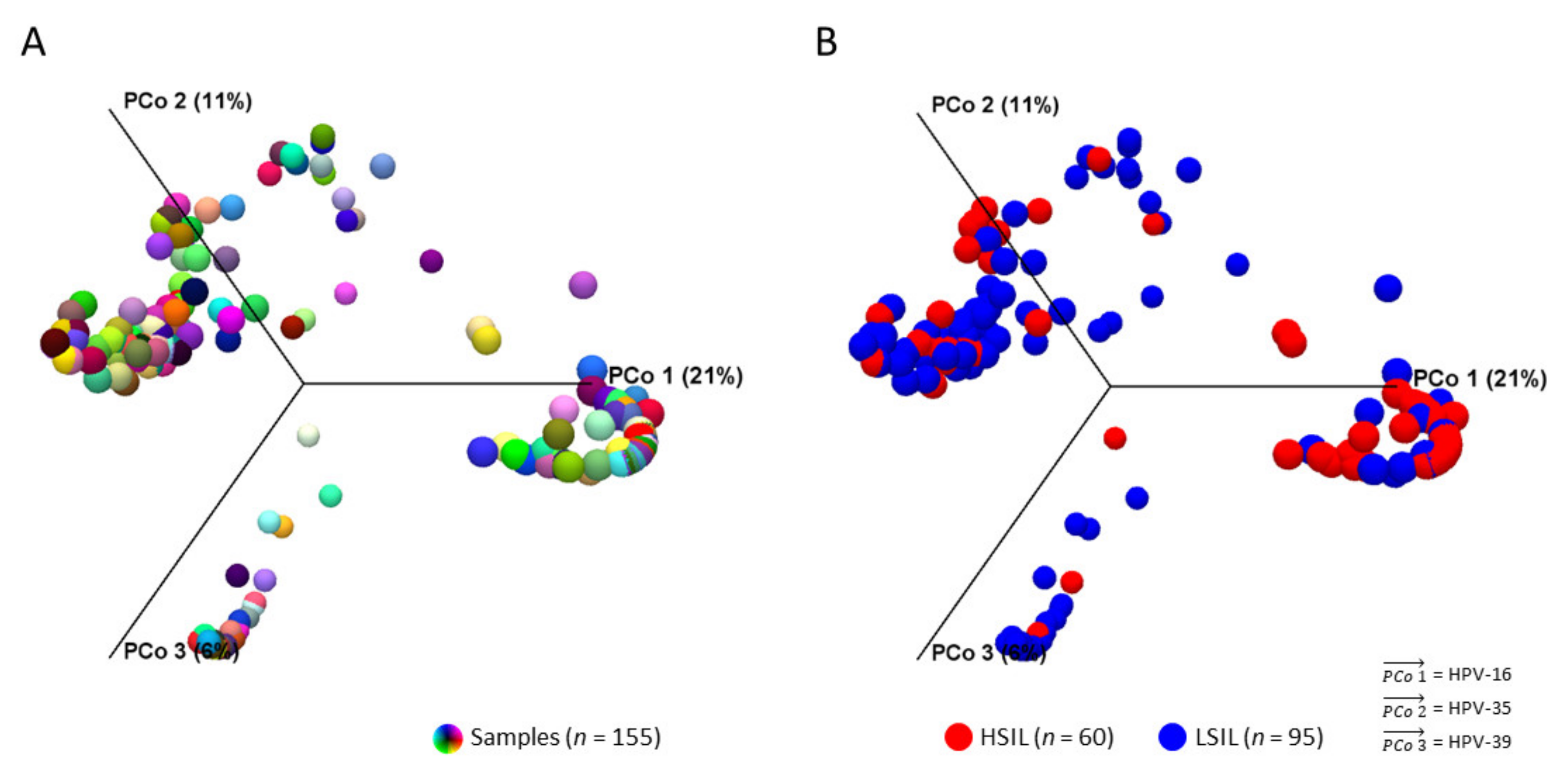
2.2. Diversity Analysis and Visualization of LSIL/HSIL HPV Communities
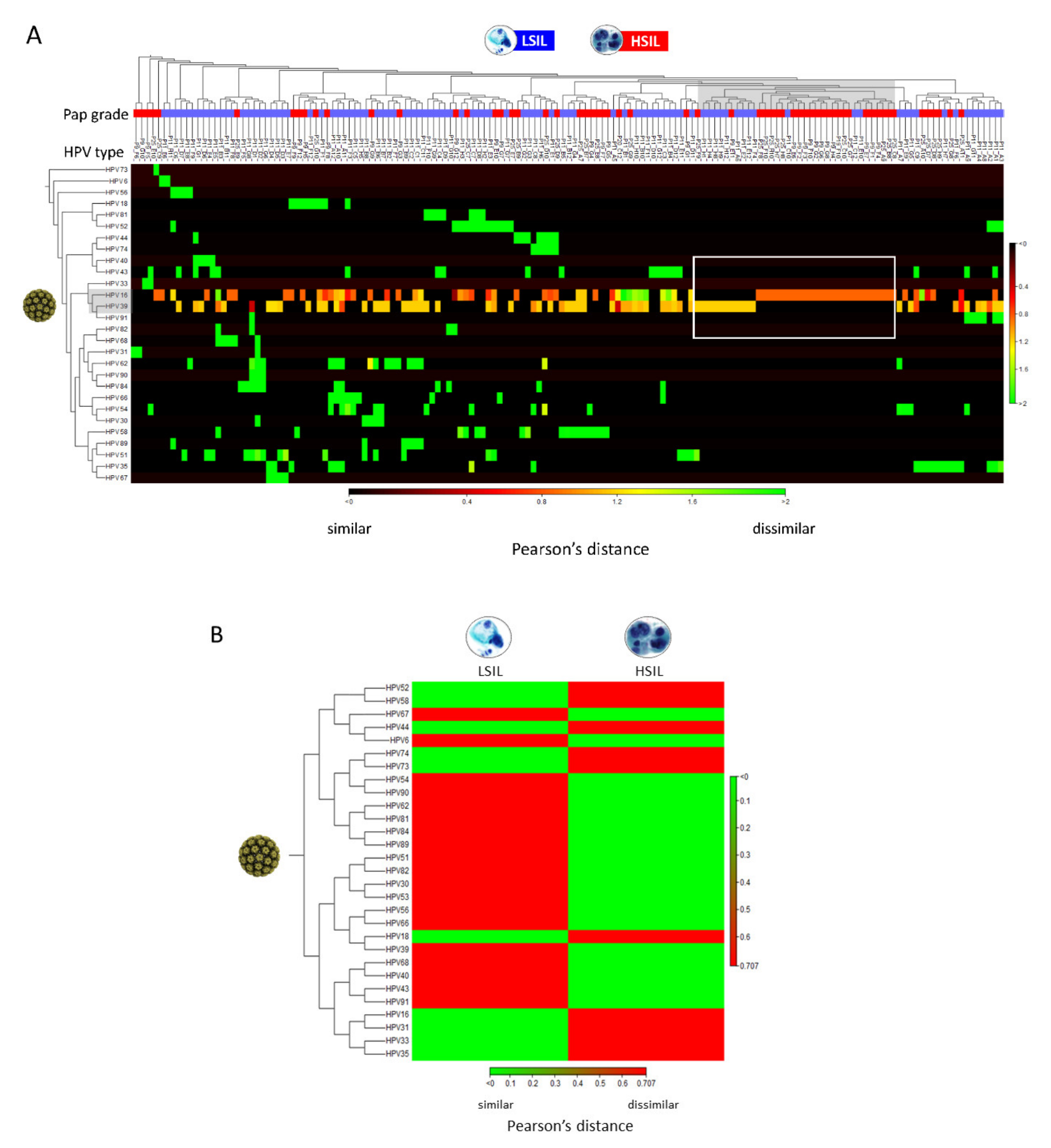
2.3. Differential Abundance Analysis and Visualization of LSIL/HSIL HPV Communities
2.4. Read Mapping and Visualization of Mapped Tracks
3. Discussion
4. Materials and Methods
4.1. Subjects, Samples, and Deep Sequencing
4.2. Customized HPV Reference Databases for CLC Workflows
4.3. Data Quality Control (QC) and Taxonomic Profiling Workflow
4.4. Estimate Alpha and Beta Diversities Workflow
4.5. Differential Abundance Analysis Methods
4.6. Map Reads to Reference Workflow
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mammas, I.N.; Spandidos, D.A. Four historic legends in human papillomaviruses research. J. BUON. 2015, 20, 658–661. [Google Scholar] [PubMed]
- Durst, M.; Gissmann, L.; Ikenberg, H.; Hausen, H.Z. A papillomavirus DNA from a cervical carcinoma and its prevalence in cancer biopsy samples from different geographic regions. Proc. Natl. Acad. Sci. USA 1983, 80, 3812–3815. [Google Scholar] [CrossRef] [Green Version]
- Hausen, H.Z. Cancers in humans: A lifelong search for contributions of infectious agents, autobiographic notes. Annu. Rev. Virol. 2019, 6, 1–28. [Google Scholar] [CrossRef]
- Javier, R.T.; Butel, J.S. The history of tumor virology. Cancer Res. 2008, 68, 7693–7706. [Google Scholar] [CrossRef] [Green Version]
- International Agency for Research on Cancer. Monographs on the Evaluation of Carcinogenic Risks to Humans-Human Papillomaviruses; World Health Organization: Geneva, Switzerland, 2012; pp. 255–313. [Google Scholar]
- Mastoraki, A.; Schizas, D.; Gkiala, A.; Ntella, V.; Hasemaki, N.; Pentara, I.; Ntomi, V.; Kapelouzou, A.; Liakakos, T. Human Papilloma Virus infection and breast cancer development: Challenging theories and controversies with regard to their potential association. J. BUON 2020, 25, 1295–1301. [Google Scholar]
- Liyanage, S.S.; Rahman, B.; Ridda, I.; Newall, A.T.; Tabrizi, S.N.; Garland, S.M.; Segelov, E.; Seale, H.; Crowe, P.J.; Moa, A.; et al. The aetiological role of human papillomavirus in oesophageal squamous cell carcinoma: A meta-analysis. PLoS ONE 2013, 8, e69238. [Google Scholar] [CrossRef] [Green Version]
- De Martel, C.; Plummer, M.; Vignat, J.; Franceschi, S. Worldwide burden of cancer attributable to HPV by site, country and HPV type. Int. J. Cancer 2017, 141, 664–670. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wild, C.P.; Weiderpass, E.; Stewart, B.W. World Cancer Report: Cancer Research for Cancer Prevention. Lyon: International Agency for Research on Cancer; International Agency for Research on Cancer: Lyon, France, 2020; Available online: http://publications.iarc.fr/586 (accessed on 13 August 2021).
- Willemsen, A.; Bravo, I.G. Origin and evolution of papillomavirus (onco)genes and genomes. Philos. Trans. R. Soc. B: Biol. Sci. 2019, 374, 20180303. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bravo, I.G.; Alonso, A. Mucosal human papillomaviruses encode four different e5 proteins whose chemistry and phylogeny correlate with malignant or benign growth. J. Virol. 2004, 78, 13613–13626. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; DeSalle, R.; Schiffman, M.; Herrero, R.; Wood, C.E.; Ruiz, J.C.; Clifford, G.M.; Chan, P.K.S.; Burk, R.D. Niche adaptation and viral transmission of human papillomaviruses from archaic hominins to modern humans. PLoS Pathog. 2018, 14, e1007352. [Google Scholar] [CrossRef]
- Mandishora, R.S.D.; Gjøtterud, K.S.; Lagström, S.; Stray-Pedersen, B.; Duri, K.; Chin’Ombe, N.; Nygård, M.; Christiansen, I.K.; Ambur, O.H.; Chirenje, M.Z.; et al. Intra-host sequence variability in human papillomavirus. Papillomavirus Res. 2018, 5, 180–191. [Google Scholar] [CrossRef]
- Shen-Gunther, J.; Wang, Y.; Lai, Z.; Poage, G.M.; Perez, L.; Huang, T.H.M. Deep sequencing of HPV E6/E7 genes reveals loss of genotypic diversity and gain of clonal dominance in high-grade intraepithelial lesions of the cervix. BMC Genom. 2017, 18, 231. [Google Scholar] [CrossRef] [Green Version]
- Heather, J.M.; Chain, B. The sequence of sequencers: The history of sequencing DNA. Genomics 2016, 107, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Berry, I.M.; Melendrez, M.C.; Bishop-Lilly, K.A.; Rutvisuttinunt, W.; Pollett, S.; Talundzic, E.; Morton, L.; Jarman, R.G. Next generation sequencing and bioinformatics methodologies for infectious disease research and public health: Approaches, applications, and considerations for development of laboratory capacity. J. Infect. Dis. 2019, 221, S292–S307. [Google Scholar] [CrossRef] [Green Version]
- Ladoukakis, E.; Kolisis, F.N.; Chatziioannou, A.A. Integrative workflows for metagenomic analysis. Front. Cell Dev. Biol. 2014, 2. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Misra, B.; Langefeld, C.D.; Olivier, M.; Cox, L.A. Integrated omics: Tools, advances and future approaches. J. Mol. Endocrinol. 2019, 62, R21–R45. [Google Scholar] [CrossRef] [Green Version]
- International Committee on Taxonomy of Viruses Executive Committee The new scope of virus taxonomy: Partitioning the virosphere into 15 hierarchical ranks. Nat. Microbiol. 2020, 5, 668–674. [CrossRef]
- Bokulich, N.A.; Kaehler, B.D.; Rideout, J.R.; Dillon, M.; Bolyen, E.; Knight, R.; Huttley, G.A.; Caporaso, J.G. Optimizing taxonomic classification of marker-gene amplicon sequences with QIIME 2’s q2-feature-classifier plugin. Microbiome 2018, 6, e3208v2. [Google Scholar] [CrossRef] [PubMed]
- Van Doorslaer, K.; Li, Z.; Xirasagar, S.; Maes, P.; Kaminsky, D.; Liou, D.; Sun, Q.; Kaur, R.; Huyen, Y.; McBride, A.A. The Papillomavirus Episteme: A major update to the papillomavirus sequence database. Nucleic Acids Res. 2017, 45, D499–D506. [Google Scholar] [CrossRef]
- Phrap and Phred for Windows, MacOS, Linux, and Unix. Available online: https://www.phrap.com/index.htm (accessed on 7 August 2021).
- Gunasekera, S.; Abraham, S.; Stegger, M.; Pang, S.; Wang, P.; Sahibzada, S.; O’Dea, M. Evaluating coverage bias in next-generation sequencing of Escherichia coli. PLoS ONE 2021, 16, e0253440. [Google Scholar] [CrossRef] [PubMed]
- Van Dijk, E.L.; Auger, H.; Jaszczyszyn, Y.; Thermes, C. Ten years of next-generation sequencing technology. Trends Genet. 2014, 30, 418–426. [Google Scholar] [CrossRef] [PubMed]
- Sato, M.P.; Ogura, Y.; Nakamura, K.; Nishida, R.; Gotoh, Y.; Hayashi, M.; Hisatsune, J.; Sugai, M.; Takehiko, I.; Hayashi, T. Comparison of the sequencing bias of currently available library preparation kits for Illumina sequencing of bacterial genomes and metagenomes. DNA Res. 2019, 26, 391–398. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- From Humble Tool to Global Icon. Available online: http://news.bbc.co.uk/2/hi/europe/8172917.stm (accessed on 5 June 2021).
- Latsuzbaia, A.; Wienecke-Baldacchino, A.; Tapp, J.; Arbyn, M.; Karabegović, I.; Chen, Z.; Fischer, M.; Mühlschlegel, F.; Weyers, S.; Pesch, P.; et al. Characterization and diversity of 243 complete human papillomavirus genomes in cervical swabs using next generation sequencing. Viruses 2020, 12, 1437. [Google Scholar] [CrossRef] [PubMed]
- Langmead, B.; Salzberg, S.L. Fast gapped-read alignment with Bowtie 2. Nat. Methods 2012, 9, 357–359. [Google Scholar] [CrossRef] [Green Version]
- Bankevich, A.; Nurk, S.; Antipov, D.; Gurevich, A.A.; Dvorkin, M.; Kulikov, A.S.; Lesin, V.M.; Nikolenko, S.I.; Pham, S.; Prjibelski, A.D.; et al. SPAdes: A new genome assembly algorithm and its applications to single-cell sequencing. J. Comput. Biol. 2012, 19, 455–477. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shean, R.C.; Makhsous, N.; Stoddard, G.D.; Lin, M.J.; Greninger, A.L. VAPiD: A lightweight cross-platform viral annotation pipeline and identification tool to facilitate virus genome submissions to NCBI GenBank. BMC Bioinform. 2019, 20, 1–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Katoh, K.; Rozewicki, J.; Yamada, K.D. MAFFT online service: Multiple sequence alignment, interactive sequence choice and visualization. Brief. Bioinform. 2019, 20, 1160–1166. [Google Scholar] [CrossRef] [Green Version]
- Stamatakis, A. RAxML version 8: A tool for phylogenetic analysis and post-analysis of large phylogenies. Bioinformatics 2014, 30, 1312–1313. [Google Scholar] [CrossRef]
- Kumar, S.; Stecher, G.; Tamura, K. MEGA7: Molecular evolutionary genetics analysis version 7.0 for bigger datasets. Mol. Biol. Evol. 2016, 33, 1870–1874. [Google Scholar] [CrossRef] [Green Version]
- Letunic, I.; Bork, P. Interactive Tree Of Life (iTOL) v4: Recent updates and new developments. Nucleic Acids Res. 2019, 47, W256–W259. [Google Scholar] [CrossRef] [Green Version]
- Huson, D.H.; Scornavacca, C. Dendroscope 3: An interactive tool for rooted phylogenetic trees and networks. Syst. Biol. 2012, 61, 1061–1067. [Google Scholar] [CrossRef] [Green Version]
- Lenth, R.; Singmann, H.; Love, J.; Buerkner, P.; Herve, M. Estimated Marginal Means, Aka Least-Squares Means. CRAN Re-pository. 2020. Available online: https://cran.r-project.org (accessed on 5 June 2021).
- List of Sequence Alignment Software. Available online: https://en.wikipedia.org/wiki/List_of_sequence_alignment_software (accessed on 5 June 2021).
- Arteche-López, A.; Ávila-Fernández, A.; Romero, R.; Riveiro-Álvarez, R.; López-Martínez, M.A.; Giménez-Pardo, A.; Vélez-Monsalve, C.; Gallego-Merlo, J.; García-Vara, I.; Almoguera, B.; et al. Sanger sequencing is no longer always necessary based on a single-center validation of 1109 NGS variants in 825 clinical exomes. Sci. Rep. 2021, 11, 1–7. [Google Scholar] [CrossRef]
- De Cario, R.; Kura, A.; Suraci, S.; Magi, A.; Volta, A.; Marcucci, R.; Gori, A.M.; Pepe, G.; Giusti, B.; Sticchi, E. Sanger validation of high-throughput sequencing in genetic diagnosis: Still the best practice? Front. Genet. 2020, 11, 59258. [Google Scholar] [CrossRef] [PubMed]
- Shen-Gunther, J.; Xia, Q.; Stacey, W.; Asusta, H.B. Molecular Pap Smear: Validation of HPV Genotype and host methylation profiles of ADCY8, CDH8, AND ZNF582 as a predictor of cervical cytopathology. Front. Microbiol. 2020, 11, 595902. [Google Scholar] [CrossRef] [PubMed]
- CLC Microbial Genomics Module User Manual: Taxonomic Profiling. QIAGEN Digital Insights. Available online: https://digitalinsights.qiagen.com/products-overview/plugins/ (accessed on 6 June 2021).
- Breitwieser, F.P.; Lu, J.; Salzberg, S.L. A review of methods and databases for metagenomic classification and assembly. Brief. Bioinform. 2019, 20, 1125–1136. [Google Scholar] [CrossRef]
- Simpson, E.H. Measurement of diversity. Nature 1949, 163, 688. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Techn. J. 1948, 27, 623–656. [Google Scholar] [CrossRef]
- Bray, J.R.; Curtis, J.T. An ordination of the upland forest communities of Southern Wisconsin. Ecol. Monogr. 1957, 27, 326–349. [Google Scholar] [CrossRef]
- Baggerly, K.A.; Deng, L.; Morris, J.S.; Aldaz, C.M. Differential expression in SAGE: Accounting for normal between-library variation. Bioinformatics 2003, 19, 1477–1483. [Google Scholar] [CrossRef]
- How to BLAST Guide. National Center for Biotechnology Information. Available online: https://ftp.ncbi.nlm.nih.gov/pub/factsheets/HowTo_BLASTGuide.pdf (accessed on 6 June 2021).

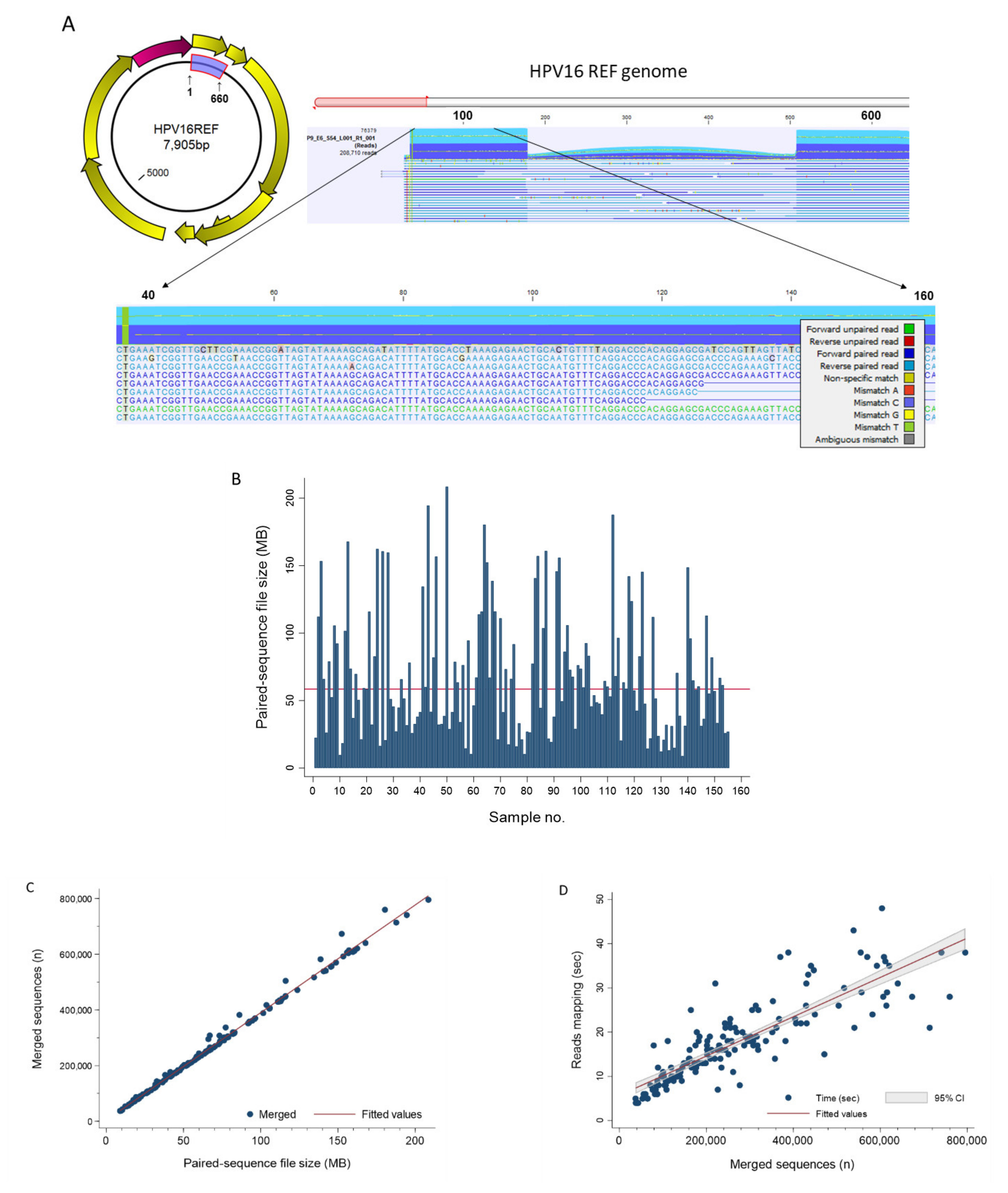
 ) is utilized as the input file for downstream diversity analysis shown in (C). (C) Merge and Estimate Alpha and Beta Diversities workflow generates diversity plots and statistical results (left). Map Reads to Reference workflow incorporating the HPV Sequence List (● HPV) generates an alignment map of the reads on the reference HPV genomes (right).
) is utilized as the input file for downstream diversity analysis shown in (C). (C) Merge and Estimate Alpha and Beta Diversities workflow generates diversity plots and statistical results (left). Map Reads to Reference workflow incorporating the HPV Sequence List (● HPV) generates an alignment map of the reads on the reference HPV genomes (right).
) is utilized as the input file for downstream diversity analysis shown in (C). (C) Merge and Estimate Alpha and Beta Diversities workflow generates diversity plots and statistical results (left). Map Reads to Reference workflow incorporating the HPV Sequence List (● HPV) generates an alignment map of the reads on the reference HPV genomes (right).
) is utilized as the input file for downstream diversity analysis shown in (C). (C) Merge and Estimate Alpha and Beta Diversities workflow generates diversity plots and statistical results (left). Map Reads to Reference workflow incorporating the HPV Sequence List (● HPV) generates an alignment map of the reads on the reference HPV genomes (right).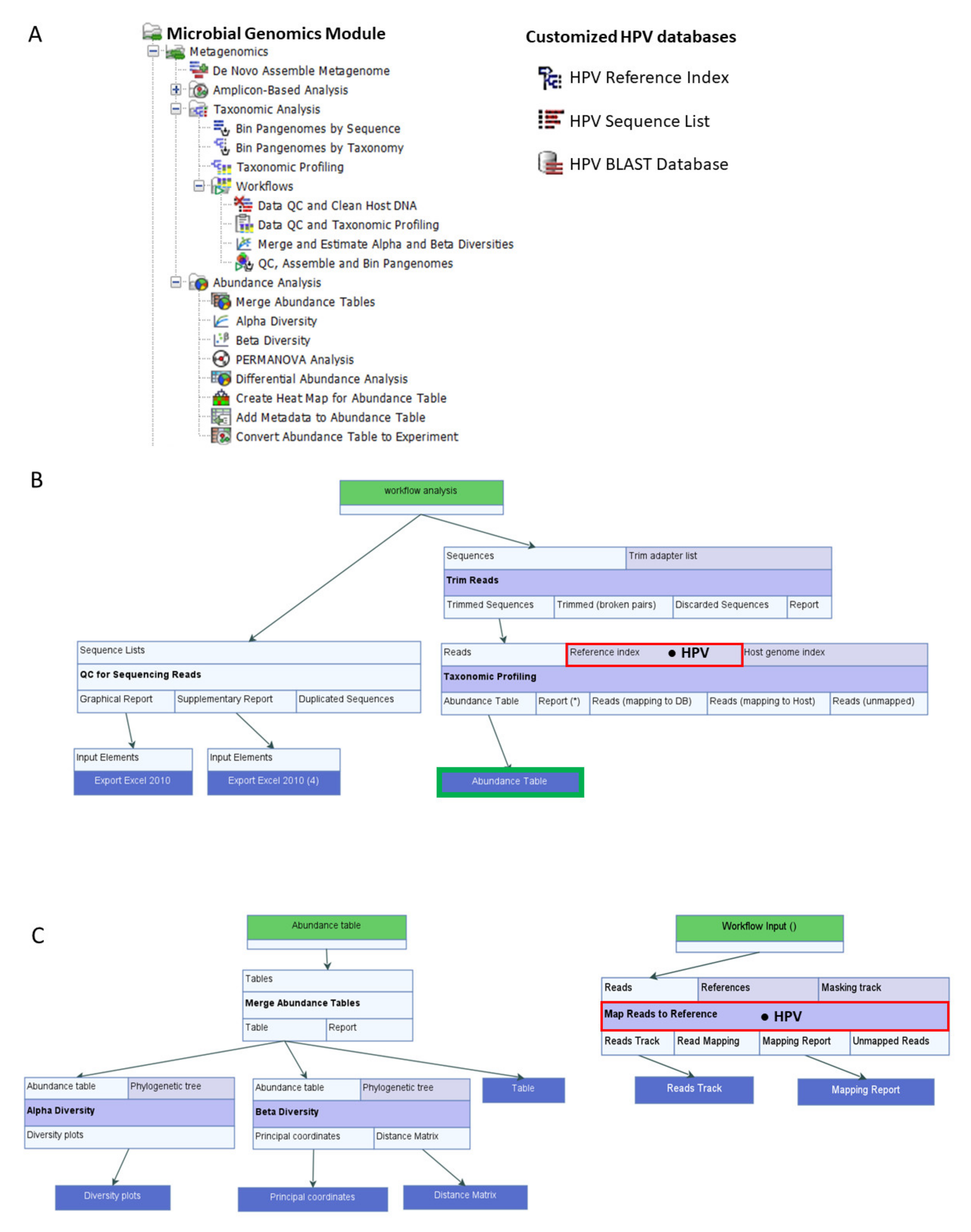

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Workflow/Tool 1 | Input File | Output | Runtime 2 | |||
|---|---|---|---|---|---|---|
| n | Type | Size | File/Report/Table | Total | Unit | |
| Import sequencing files | 310 | .fastq 3 | 4.4 GB | Merged paired-end reads in .clc format 4 | 00:03:20 | <00:00:01 |
| Data QC & Taxonomic profiling | 155 | .clc 4 | 10.6 GB | QC graphical reports Abundance table 5 | 00:36:23 | 00:00:14 |
| Alpha and Beta diversities | 1 | .clc 6 | 4 KB | Diversity plots Distance matrix table 5 | 00:00:05 | <00:00:01 |
| Map reads to reference | 155 | .clc 4 | 10.6 GB | Mapping report Reads track | 00:45:24 | 00:00:18 |
| Differential abundance analysis | 1 | .clc 6 | 4 KB | Experiment table Statistical result table | 00:00:03 | <00:00:01 |
| Convert abundance table to exp | 1 | .clc 6 | 4 KB | Experiment table Statistical result table | 00:00:02 | <00:00:01 |
| Create heat map for abundance table | 1 | .clc 6 | 4 KB | Heat map chart | 00:00:01 | <00:00:01 |
| BLAST 7 | 155 | .phd 8 | 947 KB | BLAST table | 00:00:12 | <00:00:01 |
| Agreement Statistic | LSIL | HSIL | LSIL/HSIL |
|---|---|---|---|
| Samples 1 (n) | 95 | 60 | 155 |
| Discordant 2 (n, %) | 4 (4.21%) | 5 (8.33%) | 9 (5.81%) |
| Agreement 3 (n, %) | 91 (95.79%) | 55 (93.22%) | 146 (94.81%) |
| Expected Agreement | 12.95% | 34.50% | 15.11% |
| Kappa | 0.9516 | 0.8965 | 0.9388 |
| Std. Error | 0.0345 | 0.0613 | 0.03 |
| p-value | <0.0001 | <0.0001 | <0.0001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen-Gunther, J.; Xia, Q.; Cai, H.; Wang, Y. HPV DeepSeq: An Ultra-Fast Method of NGS Data Analysis and Visualization Using Automated Workflows and a Customized Papillomavirus Database in CLC Genomics Workbench. Pathogens 2021, 10, 1026. https://doi.org/10.3390/pathogens10081026
Shen-Gunther J, Xia Q, Cai H, Wang Y. HPV DeepSeq: An Ultra-Fast Method of NGS Data Analysis and Visualization Using Automated Workflows and a Customized Papillomavirus Database in CLC Genomics Workbench. Pathogens. 2021; 10(8):1026. https://doi.org/10.3390/pathogens10081026
Chicago/Turabian StyleShen-Gunther, Jane, Qingqing Xia, Hong Cai, and Yufeng Wang. 2021. "HPV DeepSeq: An Ultra-Fast Method of NGS Data Analysis and Visualization Using Automated Workflows and a Customized Papillomavirus Database in CLC Genomics Workbench" Pathogens 10, no. 8: 1026. https://doi.org/10.3390/pathogens10081026
APA StyleShen-Gunther, J., Xia, Q., Cai, H., & Wang, Y. (2021). HPV DeepSeq: An Ultra-Fast Method of NGS Data Analysis and Visualization Using Automated Workflows and a Customized Papillomavirus Database in CLC Genomics Workbench. Pathogens, 10(8), 1026. https://doi.org/10.3390/pathogens10081026