Measurement Invariance of a Direct Behavior Rating Multi Item Scale across Occasions

 ,
,  and
and
Abstract
:1. Introduction
2. Present Study
- Question 1: Are the QMBS results comparable between the first and last measurement point? We expect to find acceptable measurement invariance between these two measurement points.
- Question 2: Does the QMBS scale fit an IRT Rasch model? We expect the INFIT and OUTFIT values for our items to be within an acceptable range (0.8 and 1.2) for initial test development.
- Question 3: Does the QMBS scale fit a four factor structure, and is this structure invariant across gender, migration background, and school level at the final measurement point? We expect that the test will perform similarly for all three groupings.
- Question 4: Do QMBS scores change over time? As we have a brief measurement period, we expect that in a latent growth model, QMBS scores will remain relatively stable, and that participant gender, special education needs, or migration background will not affect any change in scores over time.
- Question 5: Is there a significant rater effect upon QMBS scores? Due to the objective nature of the test questions, we expect the ICC within raters to remain relatively low.
3. Methods
3.1. Sample and Data Collection
3.2. Instrument
Initial Validation and Further Data Collection
3.3. Analyses
4. Results
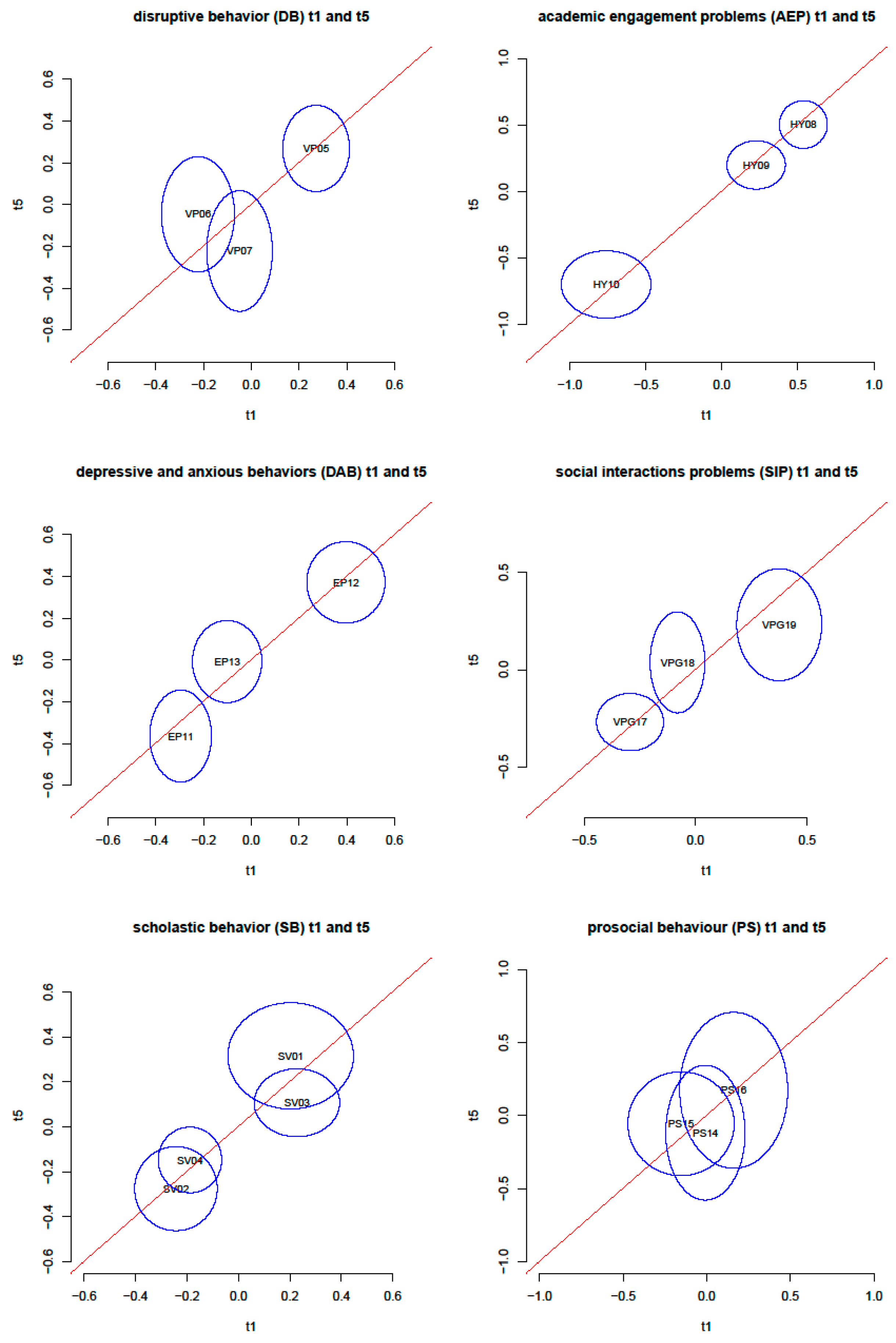
4.1. Measurement Invariance between Time Points One and Five
4.2. Rasch Modeling
4.3. Measurement Invariance at Measurement Point Five
4.4. Latent Growth Models
4.5. Intraclass Correlations of Different Raters
5. Discussion
5.1. Limitations and Future Work
5.2. Implications for Research and Practice
6. Conclusions
Ethical Statement
Author Contributions
Funding
Conflicts of Interest
Appendix A
Appendix A.1. Instructions and procedures for the “Questionnaire for Monitoring Behavior in Schools” (QMBS)
Appendix A.2. Questionnaire for Monitoring Behavior in Schools (QMBS)
| Nr. | Items | Never | Always | |||||
| Externalizing Behavior | ||||||||
| Disruptive Behavior (DB) | ||||||||
| 1 | Has temper tantrums or a hot temper, has a low frustration tolerance. | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 2 | Disobeys rules and does not listen to the teacher | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 3 | Argues with classmates/provokes classmates with his/her behavior | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Academic Engagement Problems (AEP) | ||||||||
| 4 | Fidgets or squirms, is restless/overactive | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 5 | Frequently quits tasks early | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 6 | Easily distracted | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Internalizing Behavior | ||||||||
| Depressive and anxious behaviors (DAB) | ||||||||
| 7 | Seems worried, sad, or depressed | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | Seems Fearful | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 9 | Seems nervous. | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Social interactions problems (SIP) | ||||||||
| 10 | Works/plays mostly alone, prefers to be alone | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 11 | Teased or bullied by classmates, easily provoked | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 12 | Gets along better with adults than with other children | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Positive Behavior in School | ||||||||
| Scholastic Behavior (SB) | ||||||||
| 13 | Participates in class | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 14 | Follows rules for speaking in class (i.e., raises hand) | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 15 | Concentrates on his/her schoolwork | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 16 | Works quietly at his/her desk/does not refuse assignments | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Prosocial Behavior (PS) | ||||||||
| 17 | Considerate of other people's feelings | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 18 | Helpful to others | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 19 | Cooperative in partner and group situations | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
References
- Achenbach, Thomas M., and Craig S. Edelbrock. 1978. The classification of child psychopathology: A review and analysis of empirical efforts. Psychological Bulletin 85: 1275–301. [Google Scholar] [CrossRef] [PubMed]
- Briesch, Amy M., Sandra M. Chafouleas, and T. Christ Riley-Tillman. 2010. Generalizability and Dependability of Behavior Assessment Methods to Estimate Academic Engagement: A Comparison of Systematic Direct Observation and Direct Behavior Rating. School Psychology Review 39: 408–21. [Google Scholar]
- Briesch, Amy M., Robert J. Volpe, and Tyler D. Ferguson. 2014. The influence of student characteristics on the dependability of behavioral observation data. School Psychology Quarterly 29: 171–81. [Google Scholar] [CrossRef] [PubMed]
- Casale, Gino, Thomas Hennemann, Robert J. Volpe, Amy M. Briesch, and Michael Grosche. 2015. Generalisierbarkeit und Zuverlässigkeit von Direkten Verhaltensbeurteilungen des Lern- und Arbeitsverhaltens in einer inklusiven Grundschulklasse [Generalizability and dependability of direct behavior ratings of academically engaged behavior in an inclusive classroom setting]. Empirische Sonderpädagogik 7: 258–68. [Google Scholar]
- Center, David B., and John M. Callaway. 1999. Self-Reported Job Stress and Personality in Teachers of Students with Emotional or Behavioral Disorders. Behavioral Disorders 25: 41–51. [Google Scholar] [CrossRef]
- Chafouleas, Sandra M. 2011. Direct behavior rating: A review of the issues and research in its development. Education and Treatment of Children 34: 575–91. [Google Scholar] [CrossRef]
- Chopin, Bruce. 1968. Item Bank using Sample-free Calibration. Nature 219: 870–72. [Google Scholar] [CrossRef]
- Christ, Theodore J., T. Chris Riley-Tillman, and Sandra M. Chafouleas. 2009. Foundation for the Development and Use of Direct Behavior Rating (DBR) to Assess and Evaluate Student Behavior. Assessment for Effective Intervention 34: 201–13. [Google Scholar] [CrossRef]
- Costello, E. Jane, Sarah Mustillo, Alaattin Erkanli, Gordon Keeler, and Adrian Angold. 2003. Prevalence and development of psychiatric disorders in childhood and adolescence. Archives of General Psychiatry 60: 837–44. [Google Scholar] [CrossRef]
- Cronbach, Lee J., Goldine C. Gleser, Harinder Nanda, and Nageswari Rajaratnam. 1972. The Dependability of Behavioral Measures. Theory of Generalizability of Scores and Profiles. New York: Jon Wiley & Sons. [Google Scholar]
- Daniels, Brian, Robert J. Volpe, Amy M. Briesch, and Gregory A. Fabiano. 2014. Development of a problem-focused behavioral screener linked to evidence-based intervention. School Psychology Quarterly 29: 438–51. [Google Scholar] [CrossRef]
- Deno, Stanley L. 2005. Problem solving assessment. In Assessment for Intervention: A Problem-Solving Approach. Edited by Rachel Brown-Chidsey. New York: Guilford Press, pp. 10–42. [Google Scholar]
- DeVries, Jeffrey M., Stefan Voß, and Markus Gebhardt. 2018. Do learners with special education needs really feel included? Evidence from the Perception of Inclusion Questionnaire and Strengths and Difficulties Questionnaire. Research in Developmental Disabilities 83: 28–36. [Google Scholar] [CrossRef]
- Dimitrov, Dimiter M. 2017. Testing for Factorial Invariance in the Context of Construct Validation. Measurement and Evaluation in Counseling and Development 43: 121–49. [Google Scholar] [CrossRef]
- Durlak, Joseph A., Roger P. Weissberg, Allison B. Dymnicki, Rebecca D. Taylor, and Kriston B. Schellinger. 2011. The impact of enhancing students’ social and emotional learning: A meta-analysis of school-based universal interventions. Child Development 82: 405–32. [Google Scholar] [CrossRef]
- Eklund, Katie, Tyler L. Renshaw, Erin Dowdy, Shane J. Jimerson, Shelley R. Hart, Camille N. Jones, and James Earhart. 2009. Early Identification of Behavioral and Emotional Problems in Youth: Universal Screening versus Teacher-Referral Identification. The California School Psychologist 14: 89–95. [Google Scholar] [CrossRef]
- Fabiano, Gregory A., and Kellina K. Pyle. 2018. Best Practices in School Mental Health for Attention-Deficit/Hyperactivity Disorder: A Framework for Intervention. School Mental Health, 1–20. [Google Scholar] [CrossRef]
- Gebhardt, Markus, Jörg-Henrik Heine, Nina Zeuch, and Natalie Förster. 2015. Lernverlaufsdiagnostik im Mathematikunterricht der zweiten Klasse: Raschanalysen und Empfehlungen zur Adaptation eines Testverfahrens für den Einsatz in inklusiven Klassen. [Learning progress assessment in mathematic in second grade: Rasch analysis and recommendations for adaptation of a test instrument for inclusive classrooms]. Empirische Sonderpädagogik 7: 206–22. [Google Scholar]
- Gebhardt, Markus, Jeffrey M. de Vries, Jana Jungjohann, and Gino Casale. 2018. Questionnaire Monitoring Behavior in Schools (QMBS) DBR-MIS. Description of the scale “Questionnaire Monitoring Behavior in Schools” (QMBS) in English and German language. Available online: https://eldorado.tu-dortmund.de/handle/2003/37143 (accessed on 4 February 2019).
- Good, Roland H., and G. Jefferson. 1998. Contemporary perspectives on curriculum-based measurement validity. In Advanced Applications of Curriculum-Based Measurement. Edited by Mark R. Shinn. The Guilford School Practitioner Series; New York: Guilford Press, pp. 61–88. [Google Scholar]
- Goodman, Robert. 1997. The strengths and difficulties questionnaire: A research note. Journal of Child Psychology and Psychiatry 38: 581–86. [Google Scholar] [CrossRef]
- Goodman, Robert. 2001. Psychometric properties of the Strengths and Difficulties Questionnaire. Journal of the American Academy of Child and Adolescent Psychiatry 40: 1337–45. [Google Scholar] [CrossRef]
- Goodman, Anna, Donna L. Lamping, and George B. Ploubidis. 2010. When to use broader internalising and externalising subscales instead of the hypothesised five subscales on the Strengths and Difficulties Questionnaire (SDQ): Data from British parents, teachers and children. Journal of Abnormal Child Psychology 38: 1179–91. [Google Scholar] [CrossRef]
- Heine, Jörg H. 2014. Pairwise: Rasch Model Parameters by Pairwise Algorithm. Munich: Computer Software. [Google Scholar]
- Heine, Jörg H., and Christian Tarnai. 2015. Pairwise Rasch model item parameter recovery under sparse data conditions. Psychological Test and Assessment Modeling 57: 3–36. [Google Scholar]
- Heine, Jörg H., Markus Gebhardt, Susanne Schwab, Phillip Neumann, Julia Gorges, and Elke Wild. 2018. Testing psychometric properties of the CFT 1-R for students with special educational needs. Psychological Test and Assessment Modeling 60: 3–27. [Google Scholar]
- Huber, Christian, and Christian Rietz. 2015. Direct Behavior Rating (DBR) als Methode zur Verhaltensverlaufsdiagnostik in der Schule: Ein systematisches Review von Methodenstudien. Empirische Sonderpädagogik 7: 75–98. [Google Scholar]
- Krull, Johanna, Jürgen Wilbert, and Thomas Hennemann. 2018. Does social exclusion by classmates lead to behaviour problems and learning difficulties or vice versa? A cross-lagged panel analysis. European Journal of Special Needs Education 33: 235–53. [Google Scholar] [CrossRef]
- Levine, Douglas W., Robert M. Kaplan, Daniel F. Kripke, Deborah J. Bowen, Michelle J. Naughton, and Sally A. Shumaker. 2003. Factor structure and measurement invariance of the Women’s Health Initiative Insomnia Rating Scale. Psychological Assessment 15: 123–36. [Google Scholar] [CrossRef]
- Linacre, John M. 1994. Sample size and item calibration stability. Rasch Measurement Transactions 7: 328. [Google Scholar]
- Linacre, John M. 2002. Optimizing rating scale category effectiveness. Journal of Applied Measurement 3: 85–106. [Google Scholar]
- Moffitt, Terrie E., Avshalom Caspi, Honalee Harrington, and Barry J. Milne. 2002. Males on the life-course-persistent and adolescence-limited antisocial pathways: Follow-up at age 26 years. Development and Psychopathology 14: 179–207. [Google Scholar] [CrossRef]
- Owens, Julie S., and Steven W. Evans. 2017. Progress Monitoring Change in Children’s Social, Emotional, and Behavioral Functioning: Advancing the State of the Science. Assessment for Effective Intervention 43: 67–70. [Google Scholar] [CrossRef]
- R Core Team. 2013. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. [Google Scholar]
- Reinke, Wendy M., Keith C. Herman, Hanno Petras, and Nicholas S. Ialongo. 2008. Empirically derived subtypes of child academic and behavior problems: Co-occurrence and distal outcomes. Journal of Abnormal Child Psychology 36: 759–70. [Google Scholar] [CrossRef]
- Volpe, Robert J., and Amy M. Briesch. 2012. Generalizability and Dependability of Single-Item and Multiple-Item Direct Behavior Rating Scales for Engagement and Disruptive Behavior. School Psychology Review 41: 246–61. [Google Scholar]
- Volpe, Robert J., and Amy M. Briesch. 2015. Multi-item direct behavior ratings: Dependability of two levels of assessment specificity. School Psychology Quarterly 30: 431–42. [Google Scholar] [CrossRef]
- Volpe, Robert J., James C. DiPerna, John M. Hintze, and Edward S. Shapiro. 2005. Observing students in classroom settings: A review of seven coding schemes. School Psychology Review 34: 454–74. [Google Scholar]
- Volpe, Robert J., Amy M. Briesch, and Sandra M. Chafouleas. 2010. Linking Screening for Emotional and Behavioral Problems to Problem-Solving Efforts: An Adaptive Model of Behavioral Assessment. Assessment for Effective Intervention 35: 240–44. [Google Scholar] [CrossRef]
- Volpe, Robert J., Amy M. Briesch, and Kenneth D. Gadow. 2011. The efficiency of behavior rating scales to assess inattentive-overactive and oppositional-defiant behaviors: Applying generalizability theory to streamline assessment. Journal of School Psychology 49: 131–55. [Google Scholar] [CrossRef]
- Volpe, Robert J., Gino Casale, Changiz Mohiyeddini, Michael Grosche, Thomas Hennemann, Amy M. Briesch, and Brian Daniels. 2018. A universal behavioral screener linked to personalized classroom interventions: Psychometric characteristics in a large sample of German schoolchildren. Journal of School Psychology 66: 25–40. [Google Scholar] [CrossRef]
- Voss, Stefan, and Markus Gebhardt. 2017. Monitoring der sozial-emotionalen Situation von Grundschülerinnen und Grundschülern—Ist der SDQ ein geeignetes Verfahren? [Monitoring of the social emotional situation of elementary school students—Is the SDQ a suitable instrument?]. Empirische Sonderpädagogik 1: 19–35. [Google Scholar]
- Warm, Thomas A. 1989. Weighted Likelihood Estimation of Ability in Item Response Theory. Psychometrika 54: 427–50. [Google Scholar] [CrossRef]
- Waschbusch, Daniel A., Rosanna P. Breaux, and Dara E. Babinski. 2018. School-Based Interventions for Aggression and Defiance in Youth: A Framework for Evidence-Based Practice. School Mental Health, 1–14. [Google Scholar] [CrossRef]
- Wright, Benjamin D., and John M. Linacre. 1994. Reasonable mean-square fit values. Rasch Measurement Transactions 8: 370–71. [Google Scholar]
- Wright, Benjamin D., and Geofferey N. Masters. 1982. Rating Scale Analysis. Chicago: Mesa Press. [Google Scholar]


{kind=link}
{kind=link}
| Items | Short Descriptor | Response Level | Rout-Mean-Square Statistics | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | InfitMSQ | OutfitMSQ | ||
| Disruptive Behavior | |||||||||
| DB01 | Temper | −0.70 | −0.11 | 0.13 | 0.23 | 0.40 | 0.62 | 0.97 | 1.00 |
| DB02 | Disobeys | −0.62 | −0.22 | 0.04 | 0.26 | 0.33 | 0.62 | 1.07 | 1.06 |
| DB03 | Argues | −0.70 | −0.14 | 0.04 | 0.21 | 0.37 | 0.66 | 0.96 | 0.94 |
| Academic Engagement | |||||||||
| AEP04 | Fidgets | −0.67 | −0.09 | −0.01 | 0.16 | 0.29 | 0.58 | 1.05 | 1.09 |
| AEP05 | Quits Early | −0.62 | −0.28 | −0.06 | 0.16 | 0.36 | 0.53 | 1.05 | 1.05 |
| AEP06 | Distracted | −0.54 | −0.39 | −0.25 | −0.03 | 0.20 | 0.68 | 0.90 | 0.85 * |
| Depressive and Anxious Behaviors | |||||||||
| DAB07 | Sad | −0.70 | −0.18 | 0.02 | 0.25 | 0.23 | 0.54 | 0.97 | 0.92 |
| DAB08 | Fearful | −0.67 | 0.10 | 0.08 | 0.21 | 0.29 | 0.42 | 1.07 | 1.09 * |
| DAB09 | Nervous | −0.70 | 0.04 | 0.08 | 0.36 | 0.28 | 0.45 | 0.97 | 0.97 |
| Social Interaction Problems | |||||||||
| SIP10 | Loner | −0.65 | −0.16 | 0.01 | 0.25 | 0.35 | 0.63 | 1.03 | 1.00 |
| SIP11 | Teased | −0.71 | 0.00 | 0.18 | 0.29 | 0.41 | 0.57 | 0.96 | 0.96 |
| SIP12 | Prefers Adults | −0.67 | −0.10 | 0.06 | 0.29 | 0.38 | 0.59 | 1.01 | 1.05 |
| Scholastic Behavior | |||||||||
| SB13 | Participate | −0.41 | −0.14 | 0.01 | 0.06 | 0.35 | 0.39 | 1.49 * | 1.49 * |
| SB14 | Rules | −0.49 | −0.30 | −0.17 | 0.08 | 0.26 | 0.55 | 0.97 | 0.98 |
| SB15 | Concentrates | −0.55 | −0.36 | −0.04 | 0.20 | 0.46 | 0.51 | 0.74 | 0.72 |
| SB16 | Works quietly | −0.48 | −0.35 | −0.17 | 0.10 | 0.34 | 0.59 | 0.80 | 0.80 |
| Prosocial Behavior | |||||||||
| PS17 | Considerate | −0.62 | −0.34 | −0.16 | 0.10 | 0.40 | 0.56 | 1.02 | 1.04 |
| PS18 | Helpful | −0.63 | −0.36 | −0.16 | 0.10 | 0.37 | 0.61 | 0.94 | 0.92 |
| PS19 | Cooperative | −0.63 | −0.33 | −0.13 | 0.17 | 0.38 | 0.58 | 1.04 | 1.04 |
| Dimension | RMSEA (90% CI) | CFI | SRMR |
|---|---|---|---|
| Externalizing (AEP + DB) | 0.00 (0.00–0.01) | 1.00 | 0.02 |
| Internalizing (DAB + SIP) | 0.00 (0.00–0.03) | 1.00 | 0.01 |
| Prosocial Behavior | 0.06 (0.02–0.09) | 0.99 | 0.03 |
| Scholastic Behavior | 0.00 (0.00–0.04) | 1.00 | 0.02 |
| Dimension | Model | Intercept | Slope |
|---|---|---|---|
| Externalizing (AEP + DB) | Overall | −2.02 *** | −0.03 |
| Gender | 0.95 * | −0.02 | |
| Migration Status | 0.48 * | 0.03 | |
| Secondary School | 0.08 | −0.01 | |
| Clinical School | 0.18 | 0.06 | |
| Internalizing (DAB + SIP) | Overall | −0.61 * | −0.03 |
| Gender | −0.01 | −0.04 | |
| Migration Status | 0.00 | 0.05 | |
| Secondary School | 0.24 | 0.06 * | |
| Clinical School | 0.43 *** | 0.08 **** | |
| Prosocial Behavior | Overall | 1.09 *** | 0.02 |
| Gender | −1.42 *** | 0.08 | |
| Migration Status | −0.55 | −0.06 | |
| Secondary School | −0.2 | −0.07 | |
| Clinical School | −0.03 | −0.13 * | |
| Scholastic Behavior | Overall | 2.63 *** | −0.03 |
| Gender | −0.74 *** | 0.01 | |
| Migration Status | −0.35 | 0.01 | |
| Secondary School | −0.04 | −0.01 | |
| Clinical School | 0.51 * | −0.13 ** |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gebhardt, M.; DeVries, J.M.; Jungjohann, J.; Casale, G.; Gegenfurtner, A.; Kuhn, J.-T. Measurement Invariance of a Direct Behavior Rating Multi Item Scale across Occasions. Soc. Sci. 2019, 8, 46. https://doi.org/10.3390/socsci8020046
Gebhardt M, DeVries JM, Jungjohann J, Casale G, Gegenfurtner A, Kuhn J-T. Measurement Invariance of a Direct Behavior Rating Multi Item Scale across Occasions. Social Sciences. 2019; 8(2):46. https://doi.org/10.3390/socsci8020046
Chicago/Turabian StyleGebhardt, Markus, Jeffrey M. DeVries, Jana Jungjohann, Gino Casale, Andreas Gegenfurtner, and Jörg-Tobias Kuhn. 2019. "Measurement Invariance of a Direct Behavior Rating Multi Item Scale across Occasions" Social Sciences 8, no. 2: 46. https://doi.org/10.3390/socsci8020046
APA StyleGebhardt, M., DeVries, J. M., Jungjohann, J., Casale, G., Gegenfurtner, A., & Kuhn, J.-T. (2019). Measurement Invariance of a Direct Behavior Rating Multi Item Scale across Occasions. Social Sciences, 8(2), 46. https://doi.org/10.3390/socsci8020046