Privacy Threats and Protection Recommendations for the Use of Geosocial Network Data in Research




Abstract
1. Geosocial Network Data in Research
2. Background on Inferences, Users, and Policies
2.1. Inference Attacks vs. Risk of Re-Identification
2.2. Users’ Privacy Preferences
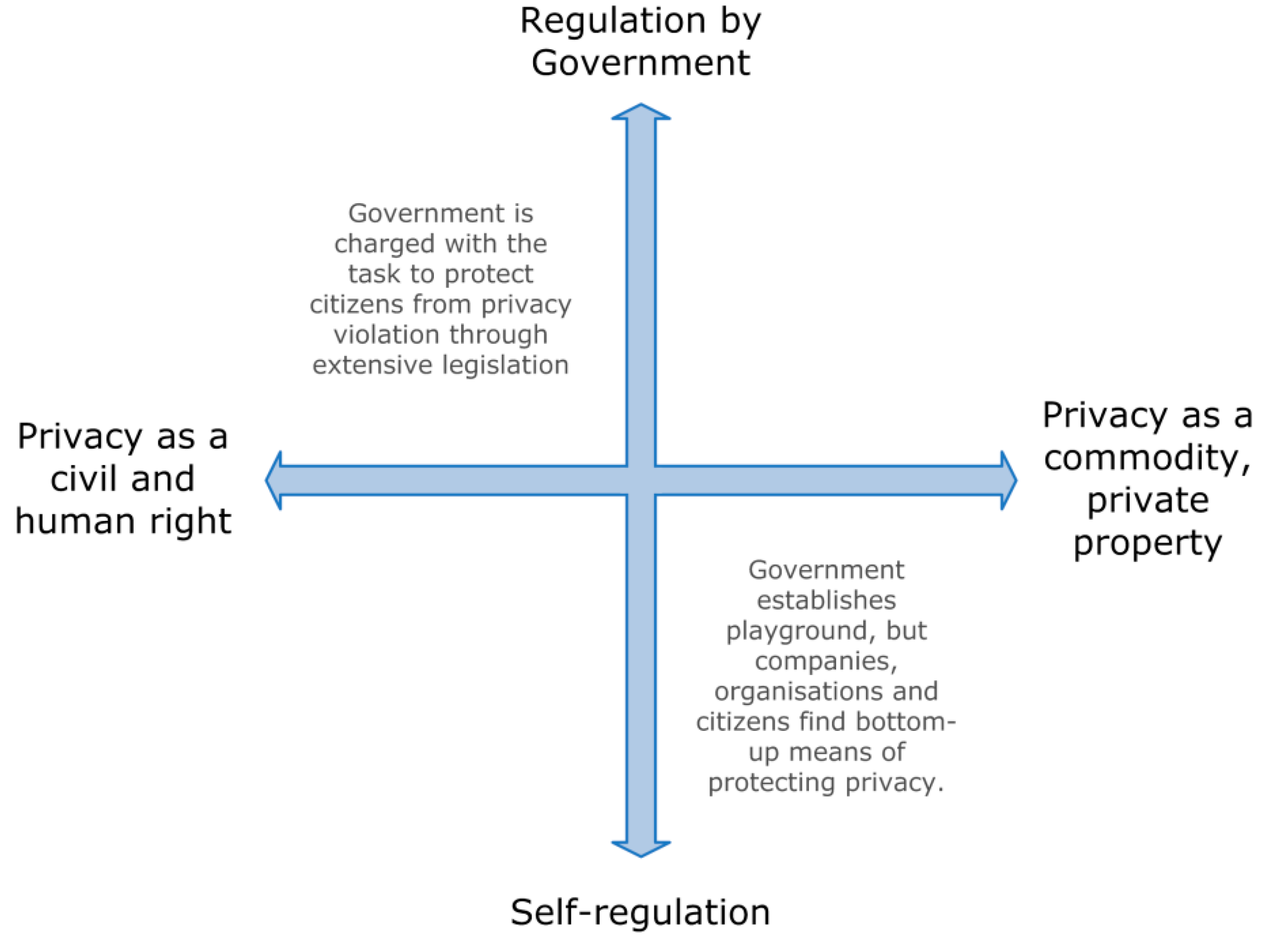
2.3. Privacy Policies in LBSN
- Registration information: How much personal information from users is needed for registration?
- Real identities versus pseudonyms: Are users allowed to use pseudonyms instead of their real name?
- Information available to others (friends, public, and third parties): What personal information about users is disclosed to other parties operating on the LBSN?
- Privacy settings: Do users have control over how their data is collected, used and disseminated?
- Terms of use and privacy policy: Does the LBSN provide an explicit and easily understandable policy in which users are informed about how their data are used?
- Policy of data retention in case of account deletion: Does the LSBN delete all data from a user after they delete their network account?
- Mobility data collection and management: Are location data collected continuously or only when a user action requires location data access?
- Security features: Does the LBSN implement reasonable IT security measures to prevent data theft?
3. Data Sharing
Recommendations:
|
4. Anonymised Data
Recommendations:
|
5. Publication of Maps
Recommendations:
|
6. Data Storing
Recommendations:
|
7. Privacy Concepts and Protection Methods
8. Discussion and Future Research Directions
8.1. The EU Open Data Portal and the General Data Protection Guideline (GDPR)
- Lawful basis for processing: if no user consent for data processing has been provided, there needs to be a legal basis for analysing data, such as public interest, contractual obligations or to protect the interest of the subject
- Responsibility and accountability: responsibility and the liability of the data controller to implement effective data and privacy protection measures
- Data protection by design and by default: high level of privacy by default, including encryption, and rules for the analysis of data
- Pseudonymisation: replacing bits of information with random information (e.g., replacing names with random names) to avoid re-identification
- Right of access: a subject’s right to access their personal data
- Right to erasure: a subject may request the erasure of all their personal data
- Records of processing activities: documentation of the data processing steps, including their purpose, the categories of used personal data, the projected time limits for erasure, or a general description of taken security measures
- Data protection officer: a data protection manager has to be assigned in every institution
- Data breaches: the data controller is legally obliged to notify the supervisory authority about any data breach
- Sanctions: warnings, audits or fines can be issued
- Business to business (B2B) marketing: allowed, provided consent or legitimate interest is given
- Lawful interception, national security, military, police, justice
- Statistical and scientific analysis
- Deceased persons are subject to national legislation
- There is a dedicated law on employer-employee relationships
- Processing of personal data by a natural person in the course of a purely personal or household activity
8.2. The Challenges of Diverging National and Supra-national Legislation
8.3. Future Research Directions
Author Contributions
Funding
Conflicts of Interest
References
- Alrayes, Fatma, and Alia Abdelmoty. 2014. No place to hide: A study of privacy concerns due to location sharing on geo-social networks. International Journal On Advances in Security 7: 62–75. [Google Scholar]
- Arase, Yuki, Xing Xie, Manni Duan, Takahiro Hara, and Shojiro Nishio. 2009. A game based approach to assign geographical relevance to web images. Paper presented at the 18th International Conference on World Wide Web, Madrid, Spain, April 20–24. [Google Scholar]
- Armstrong, Marc P., Gerard Rushton, and Dale. L. Zimmerman. 1999. Geographically masking health data to preserve confidentiality. Statistics in Medicine 18: 497–525. [Google Scholar] [CrossRef]
- Armstrong, Marc P., Ming-Hsiang Tsou, and Dara E. Seidl. 2018. Geoprivacy. In Comprehensive Geographic Information Systems. Amsterdam: Elsevier, pp. 415–30. [Google Scholar]
- Baden, Randy, Adam Bender, Neil Spring, Bobby Bhattacharjee, and Daniel Starin. 2009. Persona: An online social network with user-defined privacy. In ACM SIGCOMM Computer Communication Review. Barcelona: ACM, vol. 39, pp. 135–46. [Google Scholar]
- Beldad, Ardion, and Margareta Citra Kusumadewi. 2015. Here’s my location, for your information: The impact of trust, benefits, and social influence on location sharing application use among Indonesian university students. Computers in Human Behavior 49: 102–10. [Google Scholar] [CrossRef]
- Benisch, Michael, Patric G. Kelley, Norman Sadeh, and Lorrie F. Cranor. 2011. Capturing location-privacy preferences: Quantifying accuracy and user-burden tradeoffs. Personal and Ubiquitous Computing 15: 679–94. [Google Scholar] [CrossRef]
- Bluemke, Matthias, Bernd Resch, Clemens Lechner, René Westerholt, and Jan-Philipp Kolb. 2017. Integrating Geographic Information into Survey Research: Current Applications, Challenges and Future Avenues. Survey Research Methods 11: 307–27. [Google Scholar] [CrossRef]
- Boulos, Maged N. Kamel, Andrew J. Curtis, and Philip AbdelMalik. 2009. Musings on privacy issues in health research involving disaggregate geographic data about individuals. International Journal of Health Geographics 8: 46. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Boulos, Maged N. Kamel, Bernd Resch, David N. Crowley, John G. Breslin, Gunho Sohn, Russ Burtner, William A. Pike, Eduardo Jezierski, and Kuo-Yu Slayer Chuang. 2011. Crowdsourcing, citizen sensing and sensor web technologies for public and environmental health surveillance and crisis management: Trends, OGC standards and application examples. International Journal of Health Geographics 10: 67. [Google Scholar] [CrossRef] [PubMed]
- Brownstein, John S., Christopher A. Cassa, Isaac S. Kohane, and Keneth D. Mandl. 2006. An unsupervised classification method for inferring original case locations from low-resolution disease maps. International Journal of Health Geographics 5: 56. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Cassa, Christopher A., Schaun J. Grannis, Overhage J. Marc, and Keneth D. Mandl. 2006. A context-sensitive approach to anonymizing spatial surveillance data: Impact on outbreak detection. Journal of the American Medical Informatics Association 13: 160–65. [Google Scholar] [CrossRef] [PubMed]
- Cassa, Christopher A., Shannon C. Wieland, and Keneth D. Mandl. 2008. Re-identification of home addresses from spatial locations anonymized by Gaussian skew. International Journal of Health Geographics 7: 45. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Chatzikokolakis, Konstantinos, Catuscia Palamidessi, and Marco Stronati. 2015. Geo-indistinguishability: A principled approach to location privacy. International Conference on Distributed Computing and Internet Technology. In International Conference on Distributed Computing and Internet Technology. Berlin: Springer, pp. 49–72. [Google Scholar]
- Chen, Deyan, and Hong Zhao. 2012. Data security and privacy protection issues in cloud computing. Paper presented at 2012 International Conference on Computer Science and Electronics Engineering, Hangzhou, China, March 23–25; pp. 647–51. [Google Scholar]
- Chen, Yixin, James Ze Wang, and Robert Krovetz. 2005. CLUE: Cluster-based retrieval of images by unsupervised learning. IEEE Transactions on Image Processing 14: 1187–201. [Google Scholar] [CrossRef] [PubMed]
- Cormode, Graham, Cecilia Procopiuc, Divesh Srivastava, Entong Shen, and Ting Yu. 2012. Differentially private spatial decompositions. Paper presented at 2012 IEEE 28th International Conference on Data Engineering, Arlington, VA, USA, April 1–5; pp. 20–31. [Google Scholar]
- Croft, William Lee, Wei Shi, Jörg-Rüdiger Sack, and Jean-Pierre Corriveau. 2017. Comparison of approaches of geographic partitioning for data anonymization. Journal of Geographical Systems 19: 211–48. [Google Scholar] [CrossRef]
- Custers, Bart, Francien Dechesne, Alan M. Sears, Tommaso Tani, and Simone van der Hof. 2017. A comparison of data protection legislation and policies across the EU. Computer Law & Security Review 34: 234–43. [Google Scholar]
- De Montjoye, Yves-Alexandre, César A. Hidalgo, Michel Verleysen, and Vincent D. Blondel. 2013. Unique in the crowd: The privacy bounds of human mobility. Scientific Reports 3: 1376. [Google Scholar] [CrossRef] [PubMed]
- Dwork, Cynthia. 2006. Differential Privacy. In Automata, Languages and Programming: 33rd International Colloquium, ICALP 2006, Venice, Italy, July 10–14, 2006, Proceedings, Part II. Edited by Michele Bugliesi, Bart Preneel, Vladimiro Sassone and Ingo Wegener. Berlin and Heidelberg: Springer, pp. 1–12. [Google Scholar]
- Dwork, Cynthia. 2008. Differential Privacy: A Survey of Results. In Theory and Applications of Models of Computation. TAMC 2008. Lecture Notes in Computer Science. Berlin and Heidelberg: Springer, vol. 4978. [Google Scholar]
- European Parliament. 2001. Regulation (EC) No 45/2001 of the European Parliament and of the Council of 18 December 2000 on the Protection of Individuals with regard to the Processing of Personal Data by the Community Institutions and Bodies and on the Free Movement of such Data. Available online: https://publications.europa.eu/en/publication-detail/-/publication/0177e751-7cb7-404b-98d8-79a564ddc629/language-en (accessed on 11 October 2018).
- European Parliament. 2011. Commission Decision of 12 December 2011 on the reuse of Commission documents. Official Journal of the European Union 54: L 330. [Google Scholar]
- European Parliament. 2016. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation) (Text with EEA relevance). Official Journal of the European Union 59: L 119. [Google Scholar]
- Foth, Marcus, Laura Forlano, Christine Satchell, and Martin Gibbs. 2011. From Social Butterfly to Engaged Citizen: Urban Informatics, Social Media, Ubiquitous Computing, and Mobile Technology to Support Citizen Engagement. Cambridge: MIT Press. [Google Scholar]
- Freni, Dario, Carmen Ruiz Vicente, Sergio Mascetti, Claudio Bettini, and Christian S. Jensen. 2010. Preserving location and absence privacy in geo-social networks. Paper presented at the 19th ACM International Conference on Information and Knowledge Management, Toronto, ON, Canada, October 26–30; pp. 309–18. [Google Scholar]
- Furini, Marco, and Valentina Tamanini. 2015. Location privacy and public metadata in social media platforms: Attitudes, behaviors and opinions. Multimedia Tools and Applications 74: 9795–825. [Google Scholar] [CrossRef][Green Version]
- Gambs, Sebastian, Marc-Oliver Killijian, and Miguel N. del Prado Cortez. 2010. Show me how you move and I will tell you who you are. In Proceedings of the 3rd ACM SIGSPATIAL International Workshop on Security and Privacy in GIS and LBS. New York: ACM, pp. 34–41. [Google Scholar]
- Gambs, Sébastien, Olivier Heen, and Christophe Potin. 2011. A comparative privacy analysis of geosocial networks. In Proceedings of the 4th ACM SIGSPATIAL International Workshop on Security and Privacy in GIS and LBS. New York: ACM, pp. 33–40. [Google Scholar]
- Ganta, Srivatsava Ranjit, Shiva Prasad Kasiviswanathan, and Adam Smith. 2008. Composition attacks and auxiliary information in data privacy. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, pp. 265–73. [Google Scholar]
- Girardin, Fabien, Francesco Calabrese, Filippo Dal Fiore, Carlo Ratti, and Josep Blat. 2008. Digital footprinting: Uncovering tourists with user-generated content. IEEE Pervasive Computing 7: 36–43. [Google Scholar] [CrossRef]
- Graham, Christopher. 2012. Anonymisation: Managing Data Protection Risk Code of Practice. Wilmslow and Cheshire: Information Commissioner’s Office. [Google Scholar]
- Gruteser, Marco, and Dirk Grunwald. 2003. Anonymous Usage of Location-Based Services Through Spatial and Temporal Cloaking. In Proceedings of the 1st International Conference on Mobile Systems, Applications and Services. New York: ACM, pp. 31–42. [Google Scholar]
- Hampton, Khrisen H., Molly K. Fitch, William B. Allshouse, Irene A. Doherty, Dionne C. Gesink, Peter A. Leone, Marc L. Serre, and William C. Miller. 2010. Mapping Health Data: Improved Privacy Protection With Donut Method Geomasking. American Journal of Epidemiology 172: 1062–69. [Google Scholar] [CrossRef] [PubMed]
- Hasan, Samiul, and Satish V. Ukkusuri. 2014. Urban activity pattern classification using topic models from online geo-location data. Transportation Research Part C: Emerging Technologies 44: 363–81. [Google Scholar] [CrossRef]
- Hays, James, and Alexei A. Efros. 2008. IM2GPS: Estimating geographic information from a single image. Paper presented at CVPR 2008. IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, June 23–28; pp. 1–8. [Google Scholar]
- Hu, Peizhao, Sherman SM Chow, and Asma Alou. 2017. Geosocial query with User-Controlled Privacy. In Proceedings of the 10th ACM Conference on Security and Privacy in Wireless and Mobile Networks. New York: ACM, pp. 163–72. [Google Scholar]
- ICO. 2012. Crime-Mapping and Geo-Spatial Crime Data: Privacy and Transparency Principles. Wilmslow: Information Commissioner’s Office. [Google Scholar]
- Kalnis, Panos, Gabriel Ghinita, Kyriakos Mouratidis, and Dimitris Papadias. 2007. Preventing location-based identity inference in anonymous spatial queries. IEEE Transactions on Knowledge and Data Engineering 19: 1719–33. [Google Scholar] [CrossRef]
- Kawakubo, Hidetoshi, and Keiji Yanai. 2011. Geovisualrank: A ranking method of geotagged imagesconsidering visual similarity and geo-location proximity. In Proceedings of the 20th International Conference Companion on World Wide Web. New York: ACM, pp. 69–70. [Google Scholar]
- Keßler, Carsten, and Grant McKenzie. 2018. A geoprivacy manifesto. Transactions in GIS 22: 3–19. [Google Scholar] [CrossRef]
- Kounadi, Ourania, and Michael Leitner. 2016. Adaptive areal elimination (AAE): A transparent way of disclosing protected spatial datasets. Computers, Environment and Urban Systems 57: 59–67. [Google Scholar] [CrossRef]
- Kounadi, Ourania, and Bernd Resch. 2018. A Geoprivacy by Design Guideline for Research Campaigns That Use Participatory Sensing Data. Journal of Empirical Research on Human Research Ethics 13: 203–22. [Google Scholar] [CrossRef] [PubMed]
- Kounadi, Ourania, Alina Ristea, Michael Leitner, and Chad Langford. 2018. Population at risk: Using areal interpolation and Twitter messages to create population models for burglaries and robberies. Cartography and Geographic Information Science 45: 205–20. [Google Scholar] [CrossRef] [PubMed]
- Kovacs-Gyori, Anna, Alina Ristea, Clemens Havas, Bernd Resch, and Pablo Cabrera-Barona. 2018. London2012: Towards Citizen-Contributed Urban Planning Through Sentiment Analysis of Twitter Data. Urban Planning 3: 75–100. [Google Scholar] [CrossRef]
- Krumm, John. 2007. Inference attacks on location tracks. In Pervasive Computing. Edited by Anthony LaMarca, Marc Langheinrich and Khai N. Truong. Berlin and Heidelberg: Springer, pp. 127–43. [Google Scholar]
- Laituri, Melinda, and Kris Kodrich. 2008. On line disaster response community: People as sensors of high magnitude disasters using internet GIS. Sensors 8: 3037–55. [Google Scholar] [CrossRef] [PubMed]
- Lampoltshammer, Thomas J., Ourania Kounadi, Izabela Sitko, and Bartosz Hawelka. 2014. Sensing the public’s reaction to crime news using the ‘Links Correspondence Method’. Applied Geography 52: 57–66. [Google Scholar] [CrossRef] [PubMed]
- Leitner, Michael, Jacqueline W. Mills, and Andrew Curtis. 2007. Can Novices to Geospatial Technology Compromise Spatial Confidentially? Kartographische Nachrichten(‘Cartographic News’) 57: 78–84. [Google Scholar]
- Li, Linna, and Michael F. Goodchild. 2013. Is privacy still an issue in the era of big data?—Location disclosure in spatial footprints. Paper presented at 21st International Conference on Geoinformatics (GEOINFORMATICS), Kaifeng, June 20–22. [Google Scholar]
- Li, Yunpeng, Noah Snavely, and Daniel P. Huttenlocher. 2010. Location recognition using prioritized feature matching. In European Conference on Computer Vision. Berlin and Heidelberg: Springer, pp. 791–804. [Google Scholar]
- Li, Huaxin, Haojin Zhu, Suguo Du, Xiaohui Liang, and Xuemin Shen. 2016. Privacy leakage of location sharing in mobile social networks: Attacks and defense. IEEE Transactions on Dependable and Secure Computing 15: 646–60. [Google Scholar] [CrossRef]
- Li, Jin, Hongyang Yan, Zheli Liu, Xiaofeng Chen, Xinyi Huang, and Duncan S. Wong. 2017. Location-sharing systems with enhanced privacy in mobile online social networks. IEEE Systems Journal 11: 439–48. [Google Scholar] [CrossRef]
- Lv, Qin, Moses Charikar, and Kai Li. 2004. Image similarity search with compact data structures. In Proceedings of the Thirteenth ACM International Conference on Information and Knowledge Management. New York: ACM, pp. 208–17. [Google Scholar]
- Machanavajjhala, Ashwin, Daniel Kifer, Johannes Gehrke, and Muthuramakrishnan Venkitasubramaniam. 2007. l-diversity: Privacy beyond k-anonymity. ACM Transactions on Knowledge Discovery from Data (TKDD) 1: 3. [Google Scholar] [CrossRef]
- Malleson, Nick, and Martin A. Andresen. 2015. The impact of using social media data in crime rate calculations: Shifting hot spots and changing spatial patterns. Cartography and Geographic Information Science 42: 112–21. [Google Scholar] [CrossRef]
- McKenzie, Grant, Krzysztof Janowicz, and Dara Seidl. 2016. Geo-privacy beyond coordinates. In Geospatial Data in a Changing World. Berlin and Heidelberg: Springer, pp. 157–75. [Google Scholar]
- Mokbel, Mohamed F., Chi-Yin Chow, and Aref Walid G. 2006. The new Casper: Query processing for location services without compromising privacy. Paper presented at 32nd International Conference On Very Large Data Bases, Seoul, Korea, September 12–15; pp. 763–74. [Google Scholar]
- Noorda, Catrien W, and Stefan Hanloser. 2011. E-Discovery and Data Privacy: A Practical Guide. Alphen aan den Rijn: Kluwer Law International. [Google Scholar]
- Pan, Bei, Yu Zheng, David Wilkie, and Cyrus Shahabi. 2013. Crowd sensing of traffic anomalies based on human mobility and social media. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems. New York: ACM, pp. 344–53. [Google Scholar]
- Pontes, Tatiana, Marisa Vasconcelos, Jussara Almeida, Ponnurangam Kumaraguru, and Virgilio Almeida. 2012. We know where you live: Privacy characterization of foursquare behavior. In Proceedings of the 2012 ACM Conference On Ubiquitous Computing. New York: ACM, pp. 898–905. [Google Scholar]
- Preoţiuc-Pietro, Daniel, and Trevor Cohn. 2013. Mining user behaviours: A study of check-in patterns in location based social networks. In Proceedings of the 5th Annual ACM Web Science Conference. New York: ACM, pp. 306–15. [Google Scholar]
- Puttaswamy, Krishna P. N., and Ben Y. Zhao. 2010. Preserving privacy in location-based mobile social applications. In Proceedings of the Eleventh Workshop on Mobile Computing Systems & Applications. New York: ACM, pp. 1–6. [Google Scholar]
- Resch, B. 2013. People as sensors and collective sensing-contextual observations complementing geo-sensor network measurements. In Progress in Location-Based Services. Berlin and Heidelberg: Springer, pp. 391–406. [Google Scholar]
- Resch, Bernd, Anja Summa, Peter Zeile, and Michael Strube. 2016. Citizen-centric urban planning through extracting emotion information from Twitter in an interdisciplinary space-time-linguistics algorithm. Urban Planning 1: 114–27. [Google Scholar] [CrossRef]
- Resch, Bernd, Florian Usländer, and Clemens Havas. 2018. Combining machine-learning topic models and spatiotemporal analysis of social media data for disaster footprint and damage assessment. Cartography and Geographic Information Science 45: 362–76. [Google Scholar] [CrossRef]
- Resch, Bernd, Alexander Zipf, Euro Beinat, and Marc Boher. 2012. Towards the Live City–Paving the Way to Real-time Urbanism. International Journal on Advances in Intelligent Systems 5: 470–82. [Google Scholar]
- Ristea, Alina, Justin Kurland, Bernd Resch, Michael Leitner, and Chad Langford. 2018. Estimating the spatial distribution of crime events around a football stadium from georeferenced tweets. ISPRS International Journal of Geo-Information 7: 43. [Google Scholar] [CrossRef]
- Sagl, Günther, Bernd Resch, Bartosz Hawelka, and Euro Beinat. 2012. From social sensor data to collective human behaviour patterns: Analysing and visualising spatio-temporal dynamics in urban environments. In Proceedings of the GI-Forum. Berlin: Herbert Wichmann Verlag, pp. 54–63. [Google Scholar]
- Sakaki, Takeshi, Makoto Okazaki, and Yutaka Matsuo. 2010. Earthquake shakes Twitter users: Real-time event detection by social sensors. In Proceedings of the 19th International Conference on World Wide Web. New York: ACM, pp. 851–60. [Google Scholar]
- Santillana, Mauricio, André T. Nguyen, Mark Dredze, Michael J. Paul, Elaine O. Nsoesie, and John S. Brownstein. 2015. Combining search, social media, and traditional data sources to improve influenza surveillance. PLoS Computational Biology 11: e1004513. [Google Scholar] [CrossRef] [PubMed]
- Schulz, Axel, Aristotelis Hadjakos, Heiko Paulheim, Johannes Nachtwey, and Max Mühlhäuser. 2013. A Multi-Indicator Approach for Geolocalization of Tweets. Paper presented at Seventh International AAAI Conference on Weblogs and Social Media, Cambridge, MA, USA, July 8–11; pp. 573–82. [Google Scholar]
- Shokri, Reza, George Theodorakopoulos, Jean-Yves Le Boudec, and Jean-Pierre Hubaux. 2011. Quantifying location privacy. Paper presented at 2011 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, May 22–25; pp. 247–62. [Google Scholar]
- Steiger, Enrico, Bernd Resch, João Porto de Albuquerque, and Alexander Zipf. 2016a. Mining and correlating traffic events from human sensor observations with official transport data using self-organizing-maps. Transportation Research Part C: Emerging Technologies 73: 91–104. [Google Scholar] [CrossRef]
- Steiger, Enrico, Bernd Resch, and Alexander Zipf. 2016b. Exploration of spatiotemporal and semantic clusters of Twitter data using unsupervised neural networks. International Journal of Geographical Information Science 30: 1694–716. [Google Scholar] [CrossRef]
- Steiger, Enrico, René Westerholt, Bernd Resch, and Alexander Zipf. 2015. Twitter as an indicator for whereabouts of people? Correlating Twitter with UK census data. Computers, Environment and Urban Systems 54: 255–65. [Google Scholar] [CrossRef]
- Sun, Yongqiang, Nan Wang, Xiao-Liang Shen, and Jacky Xi Zhang. 2015. Location information disclosure in location-based social network services: Privacy calculus, benefit structure, and gender differences. Computers in Human Behavior 52: 278–92. [Google Scholar] [CrossRef]
- Sweeney, Latanya. 2002. K-anonymity: A model for protecting privacy. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems 10: 557–70. [Google Scholar]
- Vicente, Carmen Ruiz, Dario Freni, Claudio Bettini, and Christian S. Jensen. 2011. Location-related privacy in geo-social networks. IEEE Internet Computing 15: 20–27. [Google Scholar] [CrossRef]
- Wang, Shuo, Richard Sinnott, and Surya Nepal. 2016. Protecting the location privacy of mobile social media users. In 2016 IEEE International Conference on Big Data. Piscataway: IEEE, pp. 1143–50. [Google Scholar]
- Wei, Wei, Fengyuan Xu, and Qun Li. 2012. Mobishare: Flexible privacy-preserving location sharing in mobile online social networks. Paper presented at 2012 Proceedings IEEE INFOCOM, Orlando, FL, March 25–30; pp. 2616–20. [Google Scholar]
- Xue, Di, Li-Fa Wu, Hua-Bo Li, Zheng Hong, and Zhen-Ji Zhou. 2017. A novel destination prediction attack and corresponding location privacy protection method in geo-social networks. International Journal of Distributed Sensor Networks 13. [Google Scholar] [CrossRef]
- Zakhary, Victor, Cetin Sahin, Theodore Georgiou, and Amr El Abbadi. 2017. Locborg: Hiding social media user location while maintaining online persona. In Proceedings of the 25th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems. New York: ACM, p. 12. [Google Scholar]
- Zang, Hui, and Jean Bolot. 2011. Anonymization of location data does not work: A large-scale measurement study. In Proceedings of the 17th Annual International Conference on Mobile Computing and Networking. New York: ACM, pp. 145–56. [Google Scholar]
- Zhang, Jia Dong, Gabriel Ghinita, and Chi Yin Chow. 2014. Differentially private location recommendations in geosocial networks. Paper presented at 2014 IEEE 15th International Conference on Mobile Data Management, Brisbane, QLD, Australia, July 14–18, vol. 1, pp. 59–68. [Google Scholar]
- Zhang, Wei, and Jana Kosecka. 2006. Image Based Localization in Urban Environments. Paper presented at Third International Symposium on 3D Data Processing, Visualization, and Transmission (3DPVT’06), Chapel Hill, NC, USA, June 14–16, vol. 6, pp. 33–40. [Google Scholar]
- Zimmerman, Dale L., and Claire Pavlik. 2008. Quantifying the effects of mask metadata disclosure and multiple releases on the confidentiality of geographically masked health data. Geographical Analysis 40: 52–76. [Google Scholar] [CrossRef]


{kind=link}
| Inferred or Re-Identified Information | Location Data | |
|
|
|
| Inference Approach | Validation Data | Countermeasures |
|
|
|
| Study (Reference, Study Area (If Stated), Data, and Subjects) | ||
| ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kounadi, O.; Resch, B.; Petutschnig, A. Privacy Threats and Protection Recommendations for the Use of Geosocial Network Data in Research. Soc. Sci. 2018, 7, 191. https://doi.org/10.3390/socsci7100191
Kounadi O, Resch B, Petutschnig A. Privacy Threats and Protection Recommendations for the Use of Geosocial Network Data in Research. Social Sciences. 2018; 7(10):191. https://doi.org/10.3390/socsci7100191
Chicago/Turabian StyleKounadi, Ourania, Bernd Resch, and Andreas Petutschnig. 2018. "Privacy Threats and Protection Recommendations for the Use of Geosocial Network Data in Research" Social Sciences 7, no. 10: 191. https://doi.org/10.3390/socsci7100191
APA StyleKounadi, O., Resch, B., & Petutschnig, A. (2018). Privacy Threats and Protection Recommendations for the Use of Geosocial Network Data in Research. Social Sciences, 7(10), 191. https://doi.org/10.3390/socsci7100191