
Gender in Engineering Departments: Are There Gender Differences in Interruptions of Academic Job Talks?

 ,
,
Abstract
:1. Introduction
2. Theoretical Framework and Research Questions
- RQ1a:
- Among job candidates, do women experience more questions than men?
- RQ1b:
- Relative to men, is a higher share of women’s candidate time taken up by audience speech?
- RQ2:
- Net of gender, do candidates presenting in departments with a smaller proportion of women on the faculty experience more questions than candidates presenting in departments with a larger proportion of women on the faculty?
- RQ3:
- Do junior candidates experience more questions than more senior candidates?
3. Data and Methods
3.1. Data
3.2. Defining Types of Interruptions, Our Dependent Variables
- (1)
- If the presenter is presenting (rather than answering a question), then we expect an audience member to raise a hand, and so an unacknowledged interruption is defined by the audience member speaking without first raising his or her hand, even if the presenter has completed a sentence or a section of the talk. Thus, this definition relies on the lack of audience member hand gesture and presenter acknowledgement.
- (2)
- If the presenter is answering a question, then an unacknowledged interruption is defined by an audience member speaking before the presenter has finished their answer. (In a few rare cases, an interruption arises from an audience member having a speaking overlap with another audience member). Our distinction between this case and the earlier definition of a follow-up question depends upon the contextual information about the presenter’s completion of an answer.
3.3. Meanings of Zero Questions
- (1)
- The talk is very clear, so no questions are needed.
- (2)
- The talk is way below the bar, so nobody bothers asking questions.
- (3)
- The departmental culture does not involve asking questions before the formal Q & A period.
4. Descriptive Results
4.1. Explanatory Variables
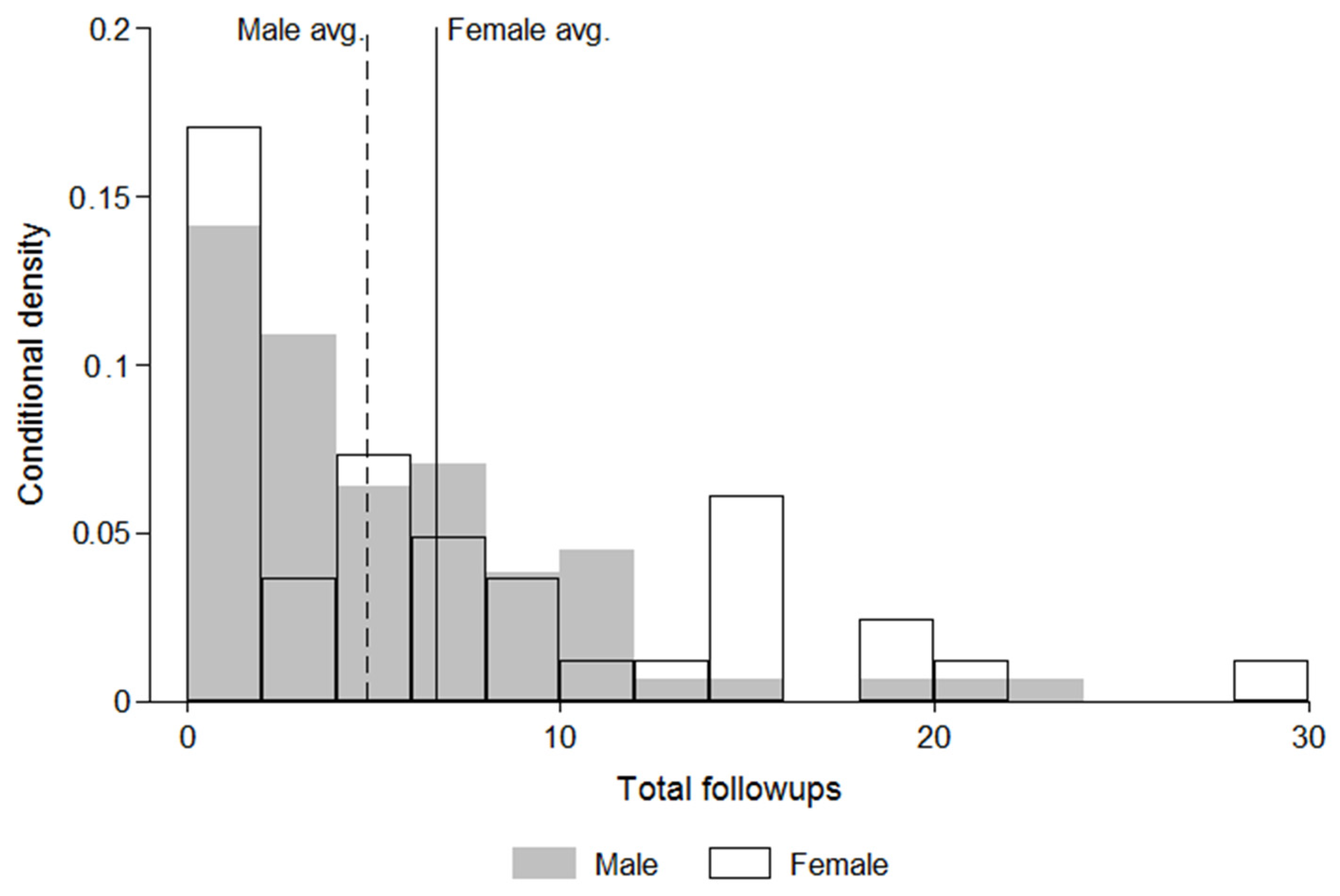
4.2. Graphical Results
5. Multivariate Results
6. Discussion
6.1. Policy Recommendations
6.2. Limitations
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Jacob Clark Blickenstaff. “Women and Science Careers: Leaky Pipeline or Gender Filter? ” Gender and Education 17 (2005): 369–86. [Google Scholar] [CrossRef]
- National Academy of Sciences Committee. Who Will Do the Science in the Future? A Symposium on Careers of Women in Science. Edited by National Academy of Sciences Committee on Women in Science and Engineering. Washington: National Academy Press, 2000. [Google Scholar]
- National Academy of Science Committee. Beyond Bias and Barriers: Fulfilling the Potential of Women in Academic Science and Engineering. Edited by National Academy of Science Committee on Maximizing the Potential of Women in Academic Science and Engineering, National Academy of Engineering and Institute of Medicine. Washington: National Academies Press, 2007. [Google Scholar]
- Melanie C. Page, Lucy E. Bailey, and Jean Van Delinder. “The Blue Blazer Club: Masculine Hegemony in Science, Technology, Engineering, and Math Fields.” Forum on Public Policy 2009 (2009): 1–23. [Google Scholar]
- Jeffrey J. Kuenzi. Science, Technology, and Engineering, and Mathematics (Stem) Education: Background, Federal Policy, and Legislative Action. Congressional Research Service Reports Paper 35; Washington: Congressional Research Service, 2008. [Google Scholar]
- Domestic Policy Council. American Competitiveness Initiative. Washington: Office of Science and Technology Policy, 2006. [Google Scholar]
- Presidents Council of Advisors on Science and Technology. Engage to Excel: Producing One Million Additional College Graduates with Degrees in Science, Technology, Engineering, and Mathematics. Washington: Executive Office of the President, 2012. [Google Scholar]
- Donna K. Ginther, and Shulamit Kahn. “Education and Academic Career Outcomes for Women of Color in Science and Engineering.” Washington, DC, USA: the Women in Science, Engineering, and Medicine, 8 October 2012. [Google Scholar]
- National Science Foundation. “Women, Minorities and Persons with Disabilities in Science and Engineering.” 2008. Available online: http://www.nsf.gov/statistics/wmpd/pdf/tab9-37.pdf (accessed on 8 July 2016). [Google Scholar]
- National Science Foundation. “Women, Minorities and Persons with Disabilities in Science and Engineering.” 2012. Available online: http://www.nsf.gov/statistics/wmpd/sex.cfm-degrees (accessed on 8 July 2016). [Google Scholar]
- Martha Foschi. “Double Standards for Competence: Theory and Research.” Annual Review of Sociology 26 (2000): 21–42. [Google Scholar] [CrossRef]
- Martha Foschi. “Double Standards in the Evaluation of Men and Women.” Social Psychology Quarterly 59 (1996): 237–54. [Google Scholar] [CrossRef]
- Monica Biernat, and Diane Kobrynowicz. “Gender- and Race-Based Standards of Competence: Lower Minimum Standards but Higher Ability Standards for Devalued Groups.” Journal of Personality and Social Psychology 72 (1997): 544–57. [Google Scholar] [CrossRef] [PubMed]
- Martha Foschi. “Status Characteristics, Standards, and Attributions.” In Sociological Theories in Progress: New Formulations. Edited by Joseph Berger, Morris Zelditch Jr. and Bo Anderson. Newbury Park: SAGE, 1989. [Google Scholar]
- Wendy M. Williams, and Stephen J. Ceci. “National Hiring Experiments Reveal 2:1 Faculty Preference for Women on Stem Tenure Track.” Proceedings of the National Academy of Sciences of the United States of America 112 (2015): 5360–65. [Google Scholar] [CrossRef] [PubMed]
- Cecilia L. Ridgeway. Framed by Gender: How Gender Inequality Persists in the Modern World. Oxford: Oxford University Press, 2011. [Google Scholar]
- Amy J. C. Cuddy, Susan T. Fiske, and Peter Glick. “When Professionals Become Mothers, Warmth Doesn’t Cut the Ice.” Journal of Social Issues 60 (2004): 701–18. [Google Scholar] [CrossRef]
- Joan Williams, and Rachel Dempsey. What Works for Women at Work: Four Patterns Working Women Need to Know. New York: New York University Press, 2014. [Google Scholar]
- Cecilia L. Ridgeway, and Lynn Smith-Lovin. “The Gender System and Interaction.” Annual Review of Sociology 25 (1999): 191–216. [Google Scholar] [CrossRef]
- Linda L. Carli. “Gender and Social Influence.” Journal of Social Issues 57 (2001): 725–41. [Google Scholar] [CrossRef]
- Abigail Powell, Barbara Bagihole, and Andrew Dainty. “How Women Engineers Do and Undo Gender: Consequences for Gender Equality.” Gender, Work and Organizations 16 (2009): 411–28. [Google Scholar] [CrossRef]
- Julia Evetts. “Managing the Technology but Not the Organization: Women and Career in Engineering.” Women in Management Review 13 (1998): 283–90. [Google Scholar] [CrossRef]
- Sarah-Jane Leslie, Andrei Cimpian, Meredith Meyer, and Edward Freeland. “Expectations of Brilliance Underlie Gender Distributions across Academic Disciplines.” Science 347 (2015): 262–65. [Google Scholar] [CrossRef] [PubMed]
- Christine Wenneras, and Agnes Wold. “Nepotism and Sexism in Peer-Review.” Nature 387 (1997): 341–43. [Google Scholar] [CrossRef] [PubMed]
- Rhea E. Steinpreis, Katie A. Anders, and Dawn Ritzke. “The Impact of Gender on the Review of the Curricula Vitae of Job Applicants and Tenure Candidates: A National Empirical Study.” Sex Roles 41 (1999): 509–28. [Google Scholar] [CrossRef]
- Corinne A. Moss-Racusin, John F. Dovidio, Victoria L. Brescoll, Mark J. Graham, and Jo Handelsman. “Science Faculty’s Subtle Gender Biases Favor Male Students.” Proceedings of the National Academy of Sciences of the United States of America 109 (2012): 16474–79. [Google Scholar] [CrossRef] [PubMed]
- Martha Foschi, Larissa Lai, and Kirsten Sigerson. “Gender and Double Standards in the Assessment of Job Applicants.” Social Psychology Quarterly 57 (1994): 326–39. [Google Scholar] [CrossRef]
- Monica Biernat, and Kathleen Fuegen. “Shifting Standards and the Evaluation of Competence: Complexity in Gender-Based Judgment and Decision Making.” Journal of Social Issues 57 (2001): 707–24. [Google Scholar] [CrossRef]
- Monica Biernat, Christian S. Crandall, Lissa V. Young, Diane Kobrynowicz, and Stanley M. Halpin. “All That You Can Be: Stereotyping of Self and Others in a Military Context.” Journal of Personality and Social Psychology 75 (1998): 301–17. [Google Scholar] [CrossRef] [PubMed]
- Mary Blair-Loy, and Amy S. Wharton. “Employee’s Use of Work-Family Policies and the Workplace Social Context.” Social Forces 80 (2002): 813–45. [Google Scholar] [CrossRef]
- Don H. Zimmerman, and Candace West. “Sex Roles, Interruptions and Silences in Conversation.” Amsterdamn Studies in the Theory and History of Linguistic Science Series 4 (1975): 211–36. [Google Scholar]
- Lynn Smith-Lovin, and Charles Brody. “Interruptions in Group Discussions: The Effects of Gender and Group Composition.” American Sociological Review 54 (1989): 424–53. [Google Scholar] [CrossRef]
- Dawn T. Robinson, and Smith-Lovin Lynn. “Timing of Interruptions in Group Discussions.” Advances in Group Processes 7 (1990): 45–73. [Google Scholar]
- Julie Irish, and Judith A. Hall. “Interruptive Patterns in Medical Visits: The Effects of Role, Status and Gender.” Social Science & Medicine 41 (1995): 873–81. [Google Scholar] [CrossRef]
- Cathryn Johnson. “Gender, Legitimate Authority, and Leader-Subordinate Conversations.” American Sociological Review 59 (1994): 122–35. [Google Scholar] [CrossRef]
- Carol W. Kennedy, and Carl T. Camden. “A New Look at Interruptions.” Western Journal of Speech Communication 47 (1983): 45–58. [Google Scholar] [CrossRef]
- Kristin J. Anderson, and Campbell Leaper. “Meta-Analyses of Gender Effects on Conversation Interruption: Who, What, When, Where, and How.” Sex Roles 39 (1998): 225–52. [Google Scholar] [CrossRef]
- Xiaoquan Zhao, and Walter Gantz. “Disruptive and Cooperative Interruptions in Prime-Time Television Fiction: The Role of Gender, Status, and Topic.” Journal of Communication 53 (2003): 347–62. [Google Scholar] [CrossRef]
- Deborah James, and Sandra Clarke. “Women, Men, and Interruptions: A Critical Review.” In Gender and Conversational Interaction. Edited by Deborah Tannen. New York: Oxford University Press, 1993, pp. 231–80. [Google Scholar]
- Matt L. Huffman, Philip N. Cohen, and Jessica Pearlman. “Engendering Change: Organizational Dynamics and Workplace Gender Desegregation, 1975–2005.” Administrative Science Quarterly 55 (2010): 255–77. [Google Scholar] [CrossRef]
- Robin J. Ely. “The Effects of Organizational Demographics and Social Identity on Relationships among Professional Women.” Administrative Science Quarterly 39 (1994): 203–38. [Google Scholar] [CrossRef]
- Charles C. Ragin. The Comparative Method: Moving Beyond Qualitative and Quantitative Strategies. Berkeley: University of California Press, 1987. [Google Scholar]
- Michele Lamont, and Patricia White. “Workshop on Interdisciplinary Standards for Systematic Qualitative Research.” Arlington, VA, USA: National Science Foundation Workshop 2005, 19–20 May 2005. [Google Scholar]
- Mary Blair-Loy, and Erin A. Cech. “Demands & Devotion: Cultural Meanings of (over)Work among Women in Science and Technology Industries.” Sociological Forum 32 (2017): 5–27. [Google Scholar]
- Elizabeth E. Armstrong, and Laura T. Hamilton. Paying for the Party: How College Maintains Inequality. Cambridge: Harvard University Press, 2013. [Google Scholar]
- Arlie Russell Hochschild. The Time Bind: When Work Becomes Home and Home Becomes Work. New York: Metropolitan Books, 1997. [Google Scholar]
- Emilio Castilla. “Gender, Race, and Meritocracy in Organizational Careers.” American Journal of Sociology 113 (2008): 1479–526. [Google Scholar] [CrossRef]
- Erin A. Cech, and Tom Waidzunas. “Navigating the Heteronormativity of Engineering: The Experience of Lesbian, Gay, and Bisexual Students.” Engineering Studies 3 (2011): 1–24. [Google Scholar] [CrossRef]
- Candace West, and Don H. Zimmerman. “Small Insults: A Study of Interruptions in Cross-Sex Conversations with Unacquainted Persons.” In Language, Gender and Society. Edited by Barrie Thorne, Cheris Kramarae and Nancy Henley. Rowley: Newbury House, 1983, pp. 102–17. [Google Scholar]
- David Gibson. “Opportunistic Interruptions: Interactional Vulnerabilities Deriving from Linearization.” Social Psychology Quarterly 68 (2005): 316–37. [Google Scholar] [CrossRef]
- Dina G. Okamoto, Lisa Slattery Rashotte, and Lynn Smith-Lovin. “Measuring Interruption: Syntactic and Contextual Methods of Coding Conversation.” Social Psychology Quarterly 65 (2002): 38–55. [Google Scholar] [CrossRef]
- Marie-Noelle Guillot. “Revisiting the Methodological Debate on Interruptions: From Measurement to Classification in the Annotation of Data for Cross-Cultural Research.” Pragmatics 15 (2005): 25–47. [Google Scholar] [CrossRef]
- Richard E. Petty, and Timothy C. Brock. “Effects of Responding or Not Responding to Hecklers on Audience Agreement with a Speaker.” Journal of Applied Social Psychology 6 (1976): 1–17. [Google Scholar] [CrossRef]
- Robert K. Tiemens, Malcolm O. Sillars, Dennis C. Alexander, and David Werling. “Television Coverage of Jesse Jackson’s Speech to the 1984 Democratic National Convention.” Journal of Broadcasting & Electronic Media 32 (1988): 1–22. [Google Scholar] [CrossRef]
- A. Colin Cameron, and Pravin K. Trivedi. “Essentials of Count Data Regression.” In A Companion to Theoretical Econometrics. Edited by Badi H. Baltagi. Malden: Blackwell Publishing, Ltd., 2001, p. 331. [Google Scholar]
- Leslie E. Papke, and Jeffrey M. Wooldbridge. “Econometric Methods for Fractional Response Variables with an Application to 401(K) Plan Participation Rates.” Journal of Applied Econometrics 11 (1996): 619–32. [Google Scholar] [CrossRef]
- J. Scott Long, and Mary Frank Fox. “Scientific Careers: Universalism and Particularism.” Annual Review of Sociology 21 (1995): 45–71. [Google Scholar] [CrossRef]
- Michele Lamont. How Professors Think: Inside the Curious World of Academic Judgment. Cambridge: President and Fellows of Harvard University, 2009. [Google Scholar]
- 1Each university is an elite research-focused institution, ranked as a “Highest Research Activity” university in the Carnegie Classification of Institutions of Higher Education and has an engineering school ranked among the top 50.
- 2Foschi’s ([11], p. 31) review of experimental research shows “substantial support” for these predictions.
- 3A third, weaker candidate was added as a foil.
- 4Williams and Ceci [15] supplemented the study of narratives (they received 711 evaluations) with “control studies” on small groups of hypothetical CVs. In the male-dominated field of engineering, they sent out the hypothetical applicant CVs to only 35 faculty.
- 6Following common usage at the university level in the United States, we use the term “department” to mean an academic unit devoted to one academic discipline, typically lead by a Chair. The terms “division” and “school”, led by a Dean, are used synonymously as in “engineering school” to mean the set of engineering departments within a university.
- 7We did not include the total population of archived videos, due to the time and expense involved in the coding of each video.
- 8In contrast, one department we had originally considered—Biomedical Engineering—had zero questions during the pre Q & A period in 81% of the talks, indicating a departmental culture of few to no questions. Our research questions entail understanding how gender may affect audience responses to the talk and affect the amount of time the presenter has to conclude the presentation. We therefore excluded the Biomedical Engineering Department from analysis.
- 9Capping or not capping the experience variable at 12 years did not affect the substance or statistical significance of results.
- 10In addition to the reasons for selecting the ZINB model given above, a statistical model selection procedure can also guide model choice. The software program Stata has a user-written routine, countfit, which provides diagnostics on which models to use. The models fit the dependent variable to the exponential of the right-hand side variable, thus constraining the predictions to be positive. For the zero-inflated models, we also specify a separate model for zeros to try to explain why some observations are zero. The decision of whether to use a Poisson or negative binomial is based on the mean of the dependent variable relative to its variance, after taking into account control variables. The Poisson model assumes that the variance of the dependent variable is equal to the mean. Table 2 suggests that this is not true, so we should also expect to prefer a negative binomial model. We fit the model predictions to the actual data at different levels of the dependent variable (results available upon request). These diagnostics indicate that for zero questions, both the Poisson (PRM) and negative binomial (NBRM) models are highly inaccurate. Both of the zero-inflated models perform well at zero, by construction. For positive numbers of questions, the Poisson and zero-inflated negative binomial (ZINB) models are the most accurate. From the fitting model predictions test, ZINB model is preferred.
- 11Because of limited variation, including the control variable university in the Table 4 model leads to numerical convergence issues for the acknowledged and follow-up question models. Therefore we exclude university from the model for positive values. We exclude university for the same reason in Table 6, below.
- 12In separate models (not shown), we substituted percent departmental faculty who are women with dummy variables for department (with CS as the excluded reference department). The results were substantively the same, with the same pattern of statistical significant coefficients for women candidates receiving more follow up and more total questions. For numerical reasons, we have also chosen to exclude the university control variable from the model for positive values.
- 13In cases where the variable is binary, the exponentiated coefficient has an interpretation very similar to the predicted value; it gives the relative increase or decrease in the dependent variable that results from being part of the group indicated by the dummy variable (female).
- 14The interpretation of the coefficients for the positive values is similar to a log-linear model, so all coefficient values can also be read as approximate percent changes. This approximation is accurate for values less than about 0.1. For exact percent changes, take the coefficient, exponentiate, and subtract 1.
- 15We found virtually identical results for the effect of female when department dummies (with CS as the excluded reference category) were substituted for percent of the faculty who are women. Results not shown.



{kind=link}
{kind=link}
| Female, Ph.D. + 4 YEARS | Start | End | Duration |
|---|---|---|---|
| Presenting | 0:01:22 | 0:11:25 | 10:03 |
| Acknowledged Question | 0:11:26 | 0:11:33 | 00:07 |
| Answer | 0:11:34 | 0:11:46 | 00:12 |
| Presenting | 0:11:47 | 0:15:40 | 03:53 |
| Unacknowledged Interruption | 0:15:40 | 0:15:44 | 00:04 |
| Answer | 0:15:45 | 0:15:51 | 00:06 |
| Follow-up Question | 0:15:51 | 0:15:54 | 00:03 |
| Answer | 0:15:55 | 0:16:09 | 00:14 |
| Unacknowledged Interruption | 0:16:09 | 0:16:11 | 00:02 |
| Answer | 0:16:12 | 0:16:18 | 00:06 |
| Presenting | 0:16:19 | 0:19:02 | 02:43 |
| Dependent Variables | Men | Women | Diff./(SE) |
|---|---|---|---|
| Mean/(SD) | Mean/(SD) | ||
| Unacknowledged interruptions | 3.77 | 4.95 | −1.18 |
| (4.87) | (6.21) | (1.04) | |
| Acknowledged questions | 5.49 | 5.39 | 0.097 |
| (4.89) | (4.07) | (0.89) | |
| Follow-up questions | 4.83 | 6.66 | −1.83 |
| (4.76) | (7.02) | (1.09) | |
| Total questions | 14.1 | 17 | −2.91 |
| (11.6) | (13.9) | (2.40) | |
| Audience time proportion | 0.038 | 0.050 | −0.012 |
| (0.031) | (0.038) | (0.0065) | |
| N talks | 78 | 41 |
| Explanatory Variables | Men | Women |
|---|---|---|
| Years since Ph.D. (mean/SD) | 3.12 | 3.17 |
| (3.84) | (4.35) | |
| Proportion female faculty in department (mean/SD) | 0.11 | 0.11 |
| (0.06) | (0.06) | |
| University | ||
| University 1 (frequency, %) | 60 (77%) | 32 (78%) |
| University 2 (frequency, %) | 18 (23%) | 9 (22%) |
| Department | ||
| CS (frequency, %) | 43 (55%) | 21 (51%) |
| EE (frequency, %) | 32 (41%) | 18 (44%) |
| ME (frequency, %) | 3 (4%) | 2 (5%) |
| N talks | 78 | 41 |
| Model Number | (1) | (2) | (3) | (4) |
|---|---|---|---|---|
| Num. Interruptions | Num. Acknowledged | Num. Follow-Ups | Total Questions | |
| Model for positive values | ||||
| Female | 0.26 | −0.011 | 0.35 ** | 0.22 * |
| 1.3 | 0.99 | 1.4 | 1.2 | |
| (0.27) | (0.14) | (0.16) | (0.13) | |
| Proportion female faculty | −8.83 *** | −2.59 * | −7.44 *** | −7.19 *** |
| 0.0001 | 0.08 | 0.0006 | 0.001 | |
| (2.61) | (1.39) | (1.54) | (1.20) | |
| Constant | 2.32 *** | 2.07 *** | 2.36 *** | 3.41 *** |
| 10.2 | 7.9 | 10.6 | 30.3 | |
| (0.22) | (0.19) | (0.17) | (0.14) | |
| Model for zeros | ||||
| Female | −0.52 | 0.18 | 1.84 * | 0.75 |
| 0.59 | 1.2 | 6.3 | 2.1 | |
| (1.10) | (0.83) | (1.07) | (0.78) | |
| Pct. female faculty | 56.3 *** | −34.7 *** | 28.8 | −30.4 *** |
| 2.8 × 1024 | 0.00 | 3.2 × 1012 | 0.00 | |
| (20.7) | (11.7) | (106.5) | (11.3) | |
| University 1 | 2.24 | −6.89 *** | −18.7 *** | −6.70 *** |
| 9.4 | 0.001 | 0.00 | 0.001 | |
| (1.79) | (1.10) | (3.13) | (1.12) | |
| Constant | −10.6 *** | 5.52 ** | −5.94 | 4.47 ** |
| 0.00 | 249.6 | 0.003 | 87.4 | |
| (4.08) | (2.22) | (19.1) | (2.08) | |
| ln(alpha) | −0.22 | −1.11 *** | −0.70 *** | −0.98 *** |
| (0.23) | (0.21) | (0.21) | (0.18) | |
| N talks | 119 | 119 | 119 | 119 |
| Variables Predicting Audience Time | Binomial |
|---|---|
| Audience time | |
| Female | 0.26 * |
| (0.15) | |
| Proportion female faculty | −5.74 *** |
| (1.24) | |
| Constant | −2.63 *** |
| (0.15) | |
| N talks | 119 |
| Model Number | (1) | (2) | (3) |
|---|---|---|---|
| Num. Follow-Ups | Num. Follow-Ups | Num. Follow-Ups | |
| Model for positive values | |||
| Female | 0.35 ** | 0.35 ** | 0.45 ** |
| 1.42 | 1.42 | 1.57 | |
| (0.16) | (0.16) | (0.18) | |
| Proportion female faculty | −7.44 *** | −7.70 *** | −7.38 *** |
| 0.001 | 0.0005 | 0.001 | |
| (1.54) | (1.49) | (1.55) | |
| Years since Ph.D. | −0.041 * | ||
| 0.96 | |||
| (0.024) | |||
| Years since Ph.D. × female | −0.036 | ||
| 0.96 | |||
| (0.040) | |||
| Constant | 2.36 *** | 2.50 *** | 2.35 *** |
| 10.59 | 12.18 | 10.49 | |
| (0.17) | (0.16) | (0.17) | |
| Model for zeros | |||
| Female | 1.84 * | 1.85 * | 1.84 * |
| 6.30 | 6.36 | 6.30 | |
| (1.07) | (1.07) | (1.07) | |
| Proportion female faculty | 28.8 | 30.0 | 30.6 |
| 3.2 × 1012 | 1.1 × 1013 | 1.95 × 1013 | |
| (106.5) | (106.6) | (106.6) | |
| University 1 | −18.7 *** | −18.4 *** | −18.6 *** |
| 7.6 × 10−9 | 1.02 × 10−8 | 8.4 × 10−9 | |
| (3.13) | (3.87) | (3.82) | |
| Constant | −5.94 | −6.17 | −6.27 |
| 0.003 | 0.002 | 0.002 | |
| (19.1) | (19.1) | (19.2) | |
| ln(alpha) | −0.70 *** | −0.74 *** | −0.71 *** |
| (0.21) | (0.21) | (0.22) | |
| N talks | 119 | 119 | 119 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Blair-Loy, M.; Rogers, L.E.; Glaser, D.; Wong, Y.L.A.; Abraham, D.; Cosman, P.C. Gender in Engineering Departments: Are There Gender Differences in Interruptions of Academic Job Talks? Soc. Sci. 2017, 6, 29. https://doi.org/10.3390/socsci6010029
Blair-Loy M, Rogers LE, Glaser D, Wong YLA, Abraham D, Cosman PC. Gender in Engineering Departments: Are There Gender Differences in Interruptions of Academic Job Talks? Social Sciences. 2017; 6(1):29. https://doi.org/10.3390/socsci6010029
Chicago/Turabian StyleBlair-Loy, Mary, Laura E. Rogers, Daniela Glaser, Y. L. Anne Wong, Danielle Abraham, and Pamela C. Cosman. 2017. "Gender in Engineering Departments: Are There Gender Differences in Interruptions of Academic Job Talks?" Social Sciences 6, no. 1: 29. https://doi.org/10.3390/socsci6010029
APA StyleBlair-Loy, M., Rogers, L. E., Glaser, D., Wong, Y. L. A., Abraham, D., & Cosman, P. C. (2017). Gender in Engineering Departments: Are There Gender Differences in Interruptions of Academic Job Talks? Social Sciences, 6(1), 29. https://doi.org/10.3390/socsci6010029